
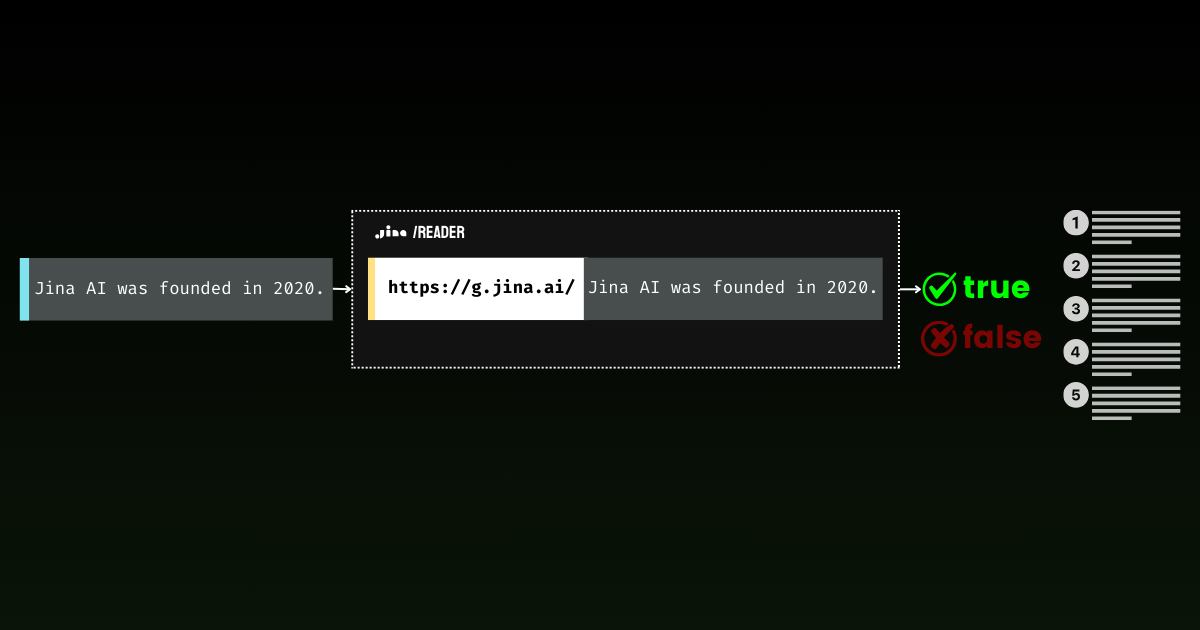

对于 GenAI 应用来说,知识落地是绝对至关重要的。
如果没有知识落地,LLM 更容易产生幻觉和生成不准确的信息,特别是当它们的训练数据缺乏最新或特定知识时。无论 LLM 的推理能力有多强,如果信息是在其知识截止日期之后引入的,它就无法提供正确的答案。
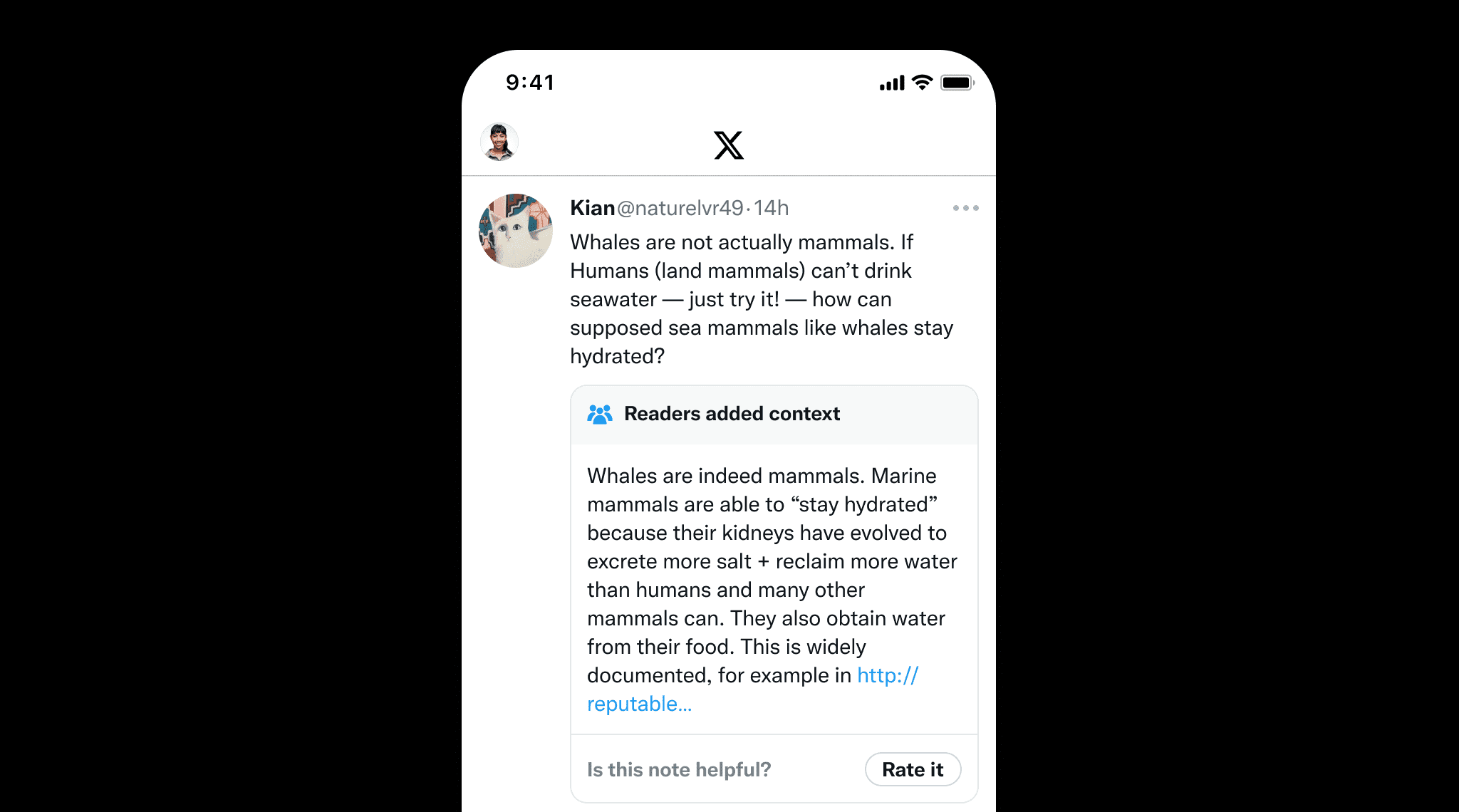
知识落地不仅对于 LLM 很重要,对于人工撰写的内容来说也很重要,这可以防止错误信息的传播。一个很好的例子是 X 的社区笔记,用户可以协作为潜在误导性帖子添加上下文。这凸显了知识落地的价值,它通过提供清晰的来源和参考来确保事实准确性,就像社区笔记帮助维护信息完整性一样。
通过 Jina Reader,我们一直在积极开发一个易于使用的知识落地解决方案。例如,r.jina.ai 将网页转换为 LLM 友好的 markdown 格式,而 s.jina.ai 则根据给定的查询将搜索结果聚合成统一的 markdown 格式。

今天,我们很高兴向这套服务中引入一个新的端点:g.jina.ai。这个新的 API 接收给定的陈述,使用实时网络搜索结果进行知识落地,并返回事实性评分和所使用的确切参考资料。我们的实验表明,与 GPT-4、o1-mini 和 Gemini 1.5 Flash & Pro 等使用搜索落地的模型相比,这个 API 在事实核查方面实现了更高的 F1 分数。

g.jina.ai 与 Gemini 的搜索落地的区别在于,每个结果最多包含 30 个 URL(通常至少提供 10 个),每个 URL 都附带有助于得出结论的直接引用。以下是使用 g.jina.ai 对陈述"Jina AI 发布的最新模型是 jina-embeddings-v3"进行知识落地的示例(截至 2024 年 10 月 14 日)。请在 API 演示场探索完整功能。请注意使用限制:
curl -X POST https://g.jina.ai \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_JINA_TOKEN" \
-d '{
"statement":"the last model released by Jina AI is jina-embeddings-v3"
}'YOUR_JINA_TOKEN是你的 Jina AI API 密钥。你可以从我们的主页获得 100 万个免费令牌,这允许三到四次免费试用。按照目前的 API 定价每 100 万令牌 0.02 美元计算,每次知识落地请求大约需要 0.006 美元。
{
"code": 200,
"status": 20000,
"data": {
"factuality": 0.95,
"result": true,
"reason": "The majority of the references explicitly support the statement that the last model released by Jina AI is jina-embeddings-v3. Multiple sources, such as the arXiv paper, Jina AI's news, and various model documentation pages, confirm this assertion. Although there are a few references to the jina-embeddings-v2 model, they do not provide evidence contradicting the release of a subsequent version (jina-embeddings-v3). Therefore, the statement that 'the last model released by Jina AI is jina-embeddings-v3' is well-supported by the provided documentation.",
"references": [
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "arXiv September 18, 2024 jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens.",
"isSupportive": true
},
{
"url": "https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-embeddings-v3?tab=Overview",
"keyQuote": "jina-embeddings-v3 is a multilingual multi-task text embedding model designed for a variety of NLP applications.",
"isSupportive": true
},
{
"url": "https://docs.pinecone.io/models/jina-embeddings-v3",
"keyQuote": "Jina Embeddings v3 is the latest iteration in the Jina AI's text embedding model series, building upon Jina Embedding v2.",
"isSupportive": true
},
{
"url": "https://haystack.deepset.ai/integrations/jina",
"keyQuote": "Recommended Model: jina-embeddings-v3 : We recommend jina-embeddings-v3 as the latest and most performant embedding model from Jina AI.",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "We offer an `encode` function to deal with this.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jinaai/jina-embeddings-v3 Feature Extraction • Updated 3 days ago • 278k • 375",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "the latest version (3.1.0) of [SentenceTransformers] also supports jina-embeddings-v3",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://jina.ai/embeddings/",
"keyQuote": "v3: Frontier Multilingual Embeddings is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model",
"keyQuote": "Jina Embeddings v3: A Frontier Multilingual Embedding Model jina-embeddings-v3 is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model/",
"keyQuote": "As of its release on September 18, 2024, jina-embeddings-v3 is the best multilingual model ...",
"isSupportive": true
}
],
"usage": {
"tokens": 112073
}
}
}使用 g.jina.ai 对"Jina AI 发布的最新模型是 jina-embeddings-v3"这一陈述进行知识落地的响应结果(截至 2024 年 10 月 14 日)。
tag它是如何工作的?
在核心上,g.jina.ai 封装了 s.jina.ai 和 r.jina.ai,通过思维链(Chain of Thought,CoT)添加多跳推理。这种方法确保每个落地的陈述都能在在线搜索和文档阅读的帮助下得到彻底分析。

s.jina.ai 和 r.jina.ai 的封装,增加了用于规划和推理的思维链。tag逐步解释
让我们通过整个过程来更好地理解 g.jina.ai 如何从输入到最终输出处理事实核查:
- 输入陈述:
当用户提供一个需要进行事实核查的陈述时,过程开始,例如"Jina AI 发布的最新模型是 jina-embeddings-v3。"注意,不需要在陈述前添加任何事实核查指令。 - 生成搜索查询:
系统使用 LLM 生成一系列与陈述相关的独特搜索查询。这些查询旨在针对不同的事实元素,确保搜索全面涵盖陈述的所有关键方面。 - 为每个查询调用
s.jina.ai:
对于每个生成的查询,g.jina.ai使用s.jina.ai执行网络搜索。搜索结果包含与查询相关的多个网站或文档。在后台,s.jina.ai调用r.jina.ai来获取页面内容。 - 从搜索结果中提取参考信息:
LLM 从搜索检索到的每个文档中提取关键参考信息。这些参考信息包括:url:来源网址keyQuote:文档中的直接引用或摘录isSupportive:布尔值,表示该参考是支持还是反驳原始陈述
- 汇总和精简参考信息:
将从检索文档中获得的所有参考信息合并成一个列表。如果参考总数超过 30 个,系统会随机选择 30 个参考以保持输出的可管理性。 - 评估陈述:
评估过程涉及使用 LLM 基于收集的参考信息(最多 30 个)来评估陈述。除了这些外部参考外,模型的内部知识也在评估中发挥作用。最终结果包括:factuality:0 到 1 之间的分数,用于估计陈述的事实准确性result:布尔值,表示陈述是真还是假reason:详细解释为什么判断陈述正确或错误,并引用支持或反驳的来源
- 输出结果:
当陈述完全评估后,生成输出。这包括事实性分数、陈述的判断、详细推理和参考列表(包含引用和 URL)。参考信息仅限于引用、URL 和是否支持陈述,保持输出清晰简洁。
tag基准测试
我们手动收集了 100 个带有真实标签的陈述,其中 true(62 个陈述)或 false(38 个陈述),并使用不同方法来确定它们是否可以被事实核查。这个过程本质上将任务转换为二分类问题,最终性能通过精确率、召回率和 F1 分数来衡量——分数越高越好。
完整的陈述列表可以在这里找到。
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Jina AI Grounding API (g.jina.ai) | 0.96 | 0.88 | 0.92 |
| Gemini-flash-1.5-002 w/ grounding | 1.00 | 0.73 | 0.84 |
| Gemini-pro-1.5-002 w/ grounding | 0.98 | 0.71 | 0.82 |
| gpt-o1-mini | 0.87 | 0.66 | 0.75 |
| gpt-4o | 0.95 | 0.58 | 0.72 |
| Gemini-pro-1.5-001 w/ grounding | 0.97 | 0.52 | 0.67 |
| Gemini-pro-1.5-001 | 0.95 | 0.32 | 0.48 |
注意,在实践中,一些 LLM 在预测中会返回第三类"我不知道"。在评估时,这些实例被排除在分数计算之外。这种方法避免了对不确定性的严厉惩罚,就像对错误答案那样。承认不确定性比猜测更可取,以阻止模型做出不确定的预测。
tag局限性
尽管结果令人鼓舞,我们仍想强调当前版本 Grounding API 的一些局限性:
- 高延迟和高 Token 消耗:单次调用
g.jina.ai可能需要大约30 秒,并消耗多达30 万个 token,这是由于主动网络搜索、页面读取和 LLM 多跳推理造成的。使用免费的 100 万 token API 密钥,这意味着你只能测试三到四次。为了维持付费用户的服务可用性,我们还为g.jina.ai实施了保守的速率限制。按照我们当前的 API 定价每 100 万 token 0.02 美元计算,每次事实核查请求的成本约为 0.006 美元。 - 适用性限制:并非每个陈述都可以或应该进行事实核查。个人观点或经历,如"我感觉懒惰",不适合进行事实核查。同样,未来事件或假设性陈述也不适用。在许多情况下,事实核查可能无关或毫无意义。为避免不必要的 API 调用,我们建议用户有选择地仅提交真正需要事实核查的句子或段落。在服务器端,我们实现了一套完整的错误代码,用于解释为什么某个陈述可能被拒绝进行事实核查。
- 依赖网络数据质量:Grounding API 的准确性取决于它检索到的来源质量。如果搜索结果包含低质量或有偏见的信息,事实核查过程可能会反映这一点,潜在导致不准确或误导性的结论。为防止这个问题,我们允许用户手动指定
references参数并限制系统搜索的 URL。这让用户能够更好地控制用于事实核查的来源,确保更加集中和相关的事实核查过程。
tag结论
Grounding API 提供端到端、近实时的事实核查体验。研究人员可以使用它来找到支持或挑战其假设的参考资料,从而增加其工作的可信度。在公司会议中,它通过验证假设和数据来确保策略建立在准确、最新的信息基础上。在政治讨论中,它可以快速验证声明,为辩论带来更多的责任感。
展望未来,我们计划通过整合内部报告、数据库和 PDF 等私有数据源来增强 API,实现更有针对性的事实核查。我们还计划扩大每个请求检查的来源数量,以进行更深入的评估。改进多跳问答将增加分析的深度,提高一致性也是一个优先事项,以确保重复请求能产生更可靠、一致的结果。
