

「實事求是」(Grounding)對於生成式 AI 應用來說絕對至關重要。
沒有實事求是的依據,大型語言模型(LLM)更容易產生幻覺和不準確的資訊,尤其是當它們的訓練資料缺乏最新或特定知識時。無論 LLM 的推理能力有多強,如果這個資訊是在其知識截止日期之後才出現的,它就無法提供正確的答案。
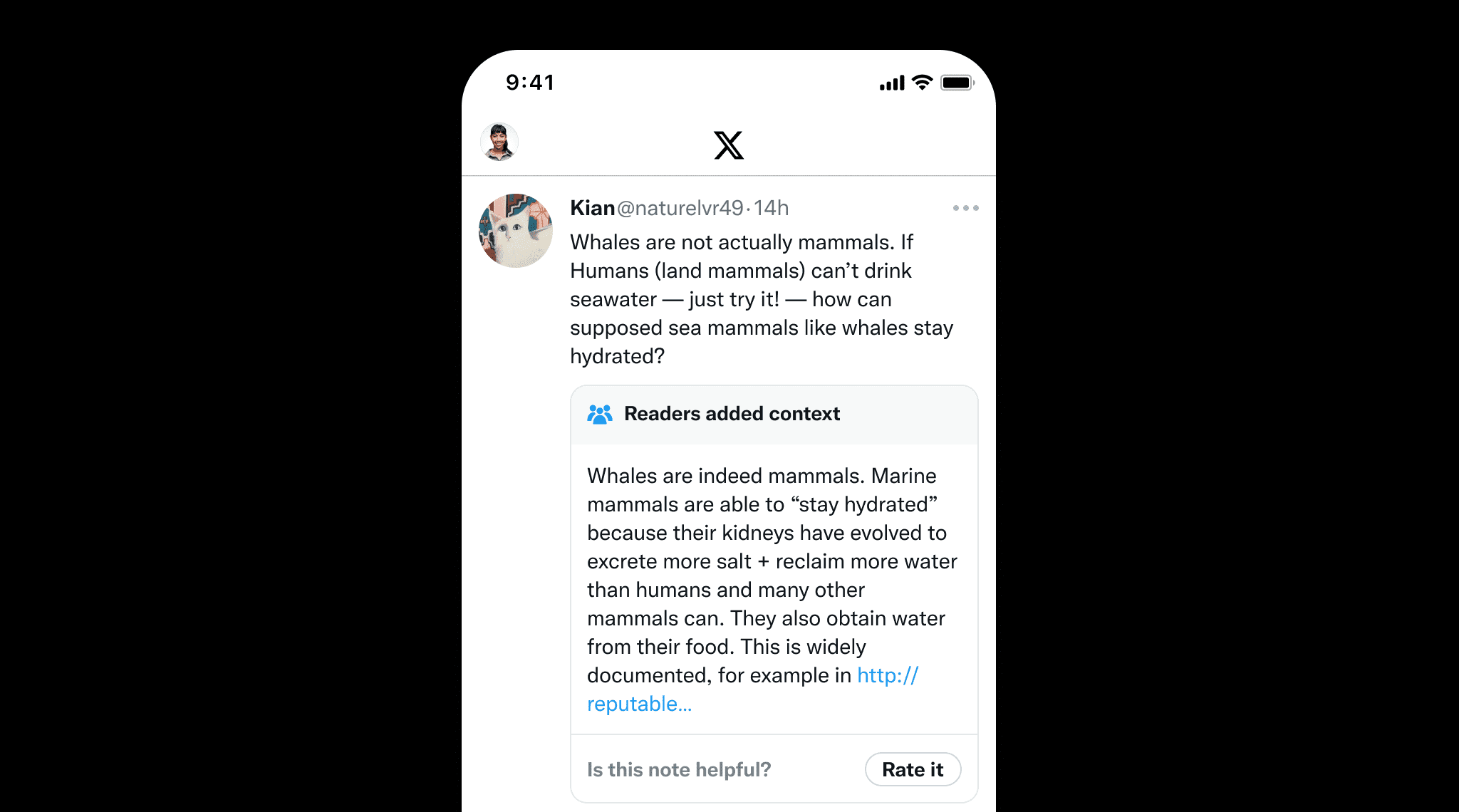
實事求是不僅對 LLM 很重要,對於人工撰寫的內容防止錯誤資訊也很重要。一個很好的例子是 X 的 Community Notes,使用者可以協作為可能具有誤導性的貼文添加上下文。這突顯了實事求是的價值,通過提供明確的來源和參考資料來確保事實的準確性,就像 Community Notes 幫助維護資訊完整性一樣。
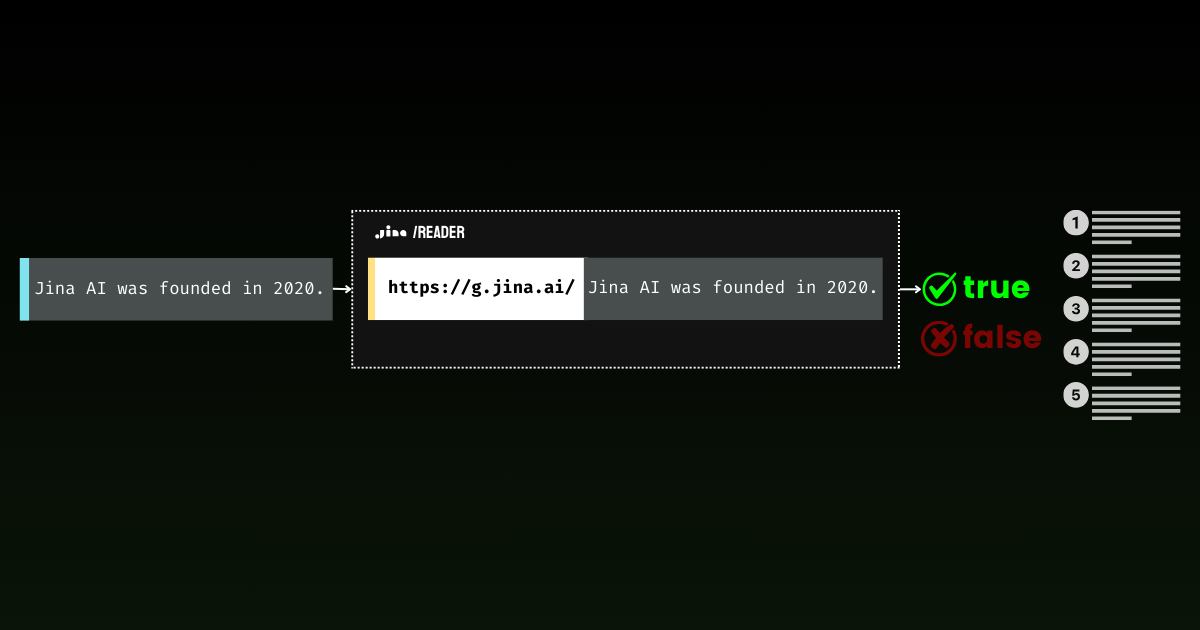
透過 Jina Reader,我們一直在積極開發一個易於使用的實事求是解決方案。例如,r.jina.ai 將網頁轉換為 LLM 友好的 markdown 格式,而 s.jina.ai 則根據給定的查詢將搜尋結果整合成統一的 markdown 格式。

今天,我們很高興向這個系列介紹一個新的端點:g.jina.ai。這個新的 API 接收一個給定的陳述,使用即時網路搜尋結果進行事實核查,並返回一個事實性分數和使用的確切參考資料。我們的實驗顯示,這個 API 在事實核查方面達到了比 GPT-4、o1-mini 和 Gemini 1.5 Flash & Pro 搜尋實事求是更高的 F1 分數。

g.jina.ai 與 Gemini 的搜尋實事求是的不同之處在於,每個結果包含多達 30 個 URL(通常至少提供 10 個),每個 URL 都附有直接引用,這些引用都有助於得出結論。以下是使用 g.jina.ai 對陳述 "The latest model released by Jina AI is jina-embeddings-v3"(截至 2024 年 10 月 14 日)進行事實核查的範例。您可以在 API playground 探索完整功能。請注意限制條件:
curl -X POST https://g.jina.ai \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_JINA_TOKEN" \
-d '{
"statement":"the last model released by Jina AI is jina-embeddings-v3"
}'YOUR_JINA_TOKEN 是您的 Jina AI API 金鑰。您可以從我們的首頁獲得 100 萬個免費 token,這允許約三到四次免費試用。按目前的 API 定價每 100 萬個 token 0.02 美元計算,每次實事求是請求的成本約為 0.006 美元。
{
"code": 200,
"status": 20000,
"data": {
"factuality": 0.95,
"result": true,
"reason": "The majority of the references explicitly support the statement that the last model released by Jina AI is jina-embeddings-v3. Multiple sources, such as the arXiv paper, Jina AI's news, and various model documentation pages, confirm this assertion. Although there are a few references to the jina-embeddings-v2 model, they do not provide evidence contradicting the release of a subsequent version (jina-embeddings-v3). Therefore, the statement that 'the last model released by Jina AI is jina-embeddings-v3' is well-supported by the provided documentation.",
"references": [
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "arXiv September 18, 2024 jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens.",
"isSupportive": true
},
{
"url": "https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-embeddings-v3?tab=Overview",
"keyQuote": "jina-embeddings-v3 is a multilingual multi-task text embedding model designed for a variety of NLP applications.",
"isSupportive": true
},
{
"url": "https://docs.pinecone.io/models/jina-embeddings-v3",
"keyQuote": "Jina Embeddings v3 is the latest iteration in the Jina AI's text embedding model series, building upon Jina Embedding v2.",
"isSupportive": true
},
{
"url": "https://haystack.deepset.ai/integrations/jina",
"keyQuote": "Recommended Model: jina-embeddings-v3 : We recommend jina-embeddings-v3 as the latest and most performant embedding model from Jina AI.",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "We offer an `encode` function to deal with this.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jinaai/jina-embeddings-v3 Feature Extraction • Updated 3 days ago • 278k • 375",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "the latest version (3.1.0) of [SentenceTransformers] also supports jina-embeddings-v3",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://jina.ai/embeddings/",
"keyQuote": "v3: Frontier Multilingual Embeddings is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model",
"keyQuote": "Jina Embeddings v3: A Frontier Multilingual Embedding Model jina-embeddings-v3 is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model/",
"keyQuote": "As of its release on September 18, 2024, jina-embeddings-v3 is the best multilingual model ...",
"isSupportive": true
}
],
"usage": {
"tokens": 112073
}
}
}使用 g.jina.ai 對陳述「Jina AI 最新發布的模型是 jina-embeddings-v3」進行實事求是的回應(截至 2024 年 10 月 14 日)。
tag它是如何運作的?
在其核心,g.jina.ai 封裝了 s.jina.ai 和 r.jina.ai,通過思維鏈(Chain of Thought,CoT)添加多跳推理。這種方法確保每個實事求是的陳述都能在線上搜尋和文件閱讀的幫助下得到徹底分析。

s.jina.ai 和 r.jina.ai 之上的封裝,加入了 CoT 規劃和推理能力。tag逐步解說
讓我們逐步了解 g.jina.ai 如何從輸入到最終輸出處理事實核查:
- 輸入陳述:
當使用者提供一個需要核查的陳述時,流程就開始了,例如「Jina AI 最新發布的模型是 jina-embeddings-v3」。注意,不需要在陳述句前加入任何事實核查指令。 - 產生搜尋查詢:
系統使用 LLM 生成一系列與陳述相關的獨特搜尋查詢。這些查詢旨在涵蓋陳述中的所有關鍵面向,確保搜尋全面完整。 - 為每個查詢呼叫
s.jina.ai:g.jina.ai使用s.jina.ai對每個生成的查詢執行網頁搜尋。搜尋結果包含與查詢相關的各種網站或文件。在背後,s.jina.ai會呼叫r.jina.ai來擷取頁面內容。 - 從搜尋結果中擷取參考資料:
LLM 從每個檢索到的文件中擷取關鍵參考資料。這些參考資料包括:url:來源的網址。keyQuote:文件中的直接引用或摘錄。isSupportive:布林值,表示該參考資料是支持還是反駁原始陳述。
- 彙整和篩選參考資料:
將所有檢索文件的參考資料合併成一個列表。如果參考資料總數超過 30 個,系統會隨機選取 30 個以維持可管理的輸出量。 - 評估陳述:
評估過程涉及使用 LLM 根據收集的參考資料(最多 30 個)來評估陳述。除了這些外部參考資料外,模型的內部知識也在評估中發揮作用。最終結果包括:factuality:介於 0 到 1 之間的分數,用於估計陳述的事實準確性。result:布林值,表示陳述是真還是假。reason:詳細解釋為什麼判斷陳述正確或錯誤,並引用支持或反駁的來源。
- 輸出結果:
完成陳述評估後,系統生成輸出。這包括事實性分數、陳述判斷、詳細推理以及參考資料列表,含引用和 URL。參考資料僅限於引用、URL 和是否支持陳述,保持輸出清晰簡潔。
tag基準測試
我們手動收集了 100 個帶有真值標籤的陳述,其中 true(62 個陳述)或 false(38 個陳述),並使用不同方法來確定它們是否可以被事實核查。這個過程本質上將任務轉換為二元分類問題,最終性能通過精確度、召回率和 F1 分數來衡量—分數越高越好。
完整的陳述列表可以在這裡找到。
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Jina AI Grounding API (g.jina.ai) | 0.96 | 0.88 | 0.92 |
| Gemini-flash-1.5-002 w/ grounding | 1.00 | 0.73 | 0.84 |
| Gemini-pro-1.5-002 w/ grounding | 0.98 | 0.71 | 0.82 |
| gpt-o1-mini | 0.87 | 0.66 | 0.75 |
| gpt-4o | 0.95 | 0.58 | 0.72 |
| Gemini-pro-1.5-001 w/ grounding | 0.97 | 0.52 | 0.67 |
| Gemini-pro-1.5-001 | 0.95 | 0.32 | 0.48 |
注意,在實際應用中,某些 LLM 會在預測中返回第三種類別「我不知道」。在評估時,這些案例會被排除在分數計算之外。這種方法避免了對不確定性的嚴厲懲罰,就像對待錯誤答案那樣。承認不確定性比猜測更可取,以阻止模型做出不確定的預測。
tag限制
儘管結果令人期待,但我們想要指出目前版本 Grounding API 的一些限制:
- 高延遲和 Token 消耗:單次呼叫
g.jina.ai可能需要約30秒,並消耗高達30萬個 token,這是由於進行網頁搜尋、頁面閱讀和 LLM 的多跳推理所致。使用免費的 100 萬 token API 金鑰,這意味著你只能測試三到四次。為了維持付費用戶的服務可用性,我們也為g.jina.ai實施了較為保守的速率限制。按照我們目前每 100 萬 token 0.02 美元的 API 定價,每次事實核查請求的成本約為 0.006 美元。 - 適用性限制:並非每個陳述都可以或應該進行事實核查。個人意見或經歷,如「我覺得很懶」,不適合進行事實核查。同樣地,未來事件或假設性陳述也不適用。在許多情況下,事實核查可能無關或毫無意義。為避免不必要的 API 呼叫,我們建議用戶有選擇性地只提交真正需要事實核查的句子或章節。在伺服器端,我們實施了一套完整的錯誤代碼來解釋為什麼某些陳述可能被拒絕進行事實核查。
- 依賴網路資料品質:Grounding API 的準確性取決於它檢索的來源品質。如果搜尋結果包含低品質或有偏見的資訊,事實核查過程可能會反映這一點,可能導致不準確或誤導性的結論。為防止這個問題,我們允許用戶手動指定
references參數並限制系統搜尋的 URL。這讓用戶能更好地控制用於事實核查的來源,確保更專注和相關的事實核查過程。
tag結論
Grounding API 提供端到端、接近即時的事實核查體驗。研究人員可以使用它來找到支持或質疑其假設的參考資料,增加其工作的可信度。在公司會議中,它通過驗證假設和數據,確保策略建立在準確、最新的資訊基礎上。在政治討論中,它可以快速驗證聲明,為辯論帶來更多問責性。
展望未來,我們計劃通過整合私有數據源(如內部報告、數據庫和 PDF)來增強 API,以實現更個性化的事實核查。我們也計劃擴大每個請求檢查的來源數量,以進行更深入的評估。改進多跳問答將為分析增加深度,而提高一致性則是確保重複請求產生更可靠、一致結果的優先事項。
