


jina-embeddings-v2-base-zh zeichnet sich durch seine außergewöhnliche Qualität und Leistung aus, die durch rigoroses und ausgewogenes Vortraining mit hochwertigen bilingualen Daten erreicht wurde. Dieser Ansatz gewährleistet eine signifikante Reduzierung von Verzerrungen, die häufig bei Modellen auftreten, die mit unausgewogenen mehrsprachigen Daten trainiert wurden.
tagHighlights
- Bilinguales Modell: Dieses Modell codiert Texte sowohl in Englisch als auch in Chinesisch und ermöglicht die Verwendung beider Sprachen als Abfrage oder Zieldokument. Texte mit äquivalenten Bedeutungen in diesen Sprachen werden in denselben Embedding-Raum abgebildet und bilden die Grundlage für zahlreiche mehrsprachige Anwendungen.
- Erweiterte 8K Token-Länge: Unser Modell kann signifikant große Textpassagen verarbeiten, eine Funktion, die die Fähigkeiten der meisten anderen Open-Source-Modelle übertrifft.
- Kompakt und effizient: Mit einer Größe von 322MB (161 Millionen Parameter) und Ausgabedimensionen von 768 ist unser Modell für hohe Leistung auf Standard-Computerhardware ohne GPU ausgelegt, was seine Zugänglichkeit erhöht.
tagFührende Leistung auf C-MTEB
In der Chinese MTEB Bestenliste hebt sich unser Jina Embeddings v2, das sowohl Chinesisch als auch Englisch unterstützt, als eines der Top-Modelle unter 0,5GB hervor. Was es besonders auszeichnet, ist seine beeindruckende 8K Token-Längen-Fähigkeit, ein einzigartiges Merkmal in seiner Kategorie.
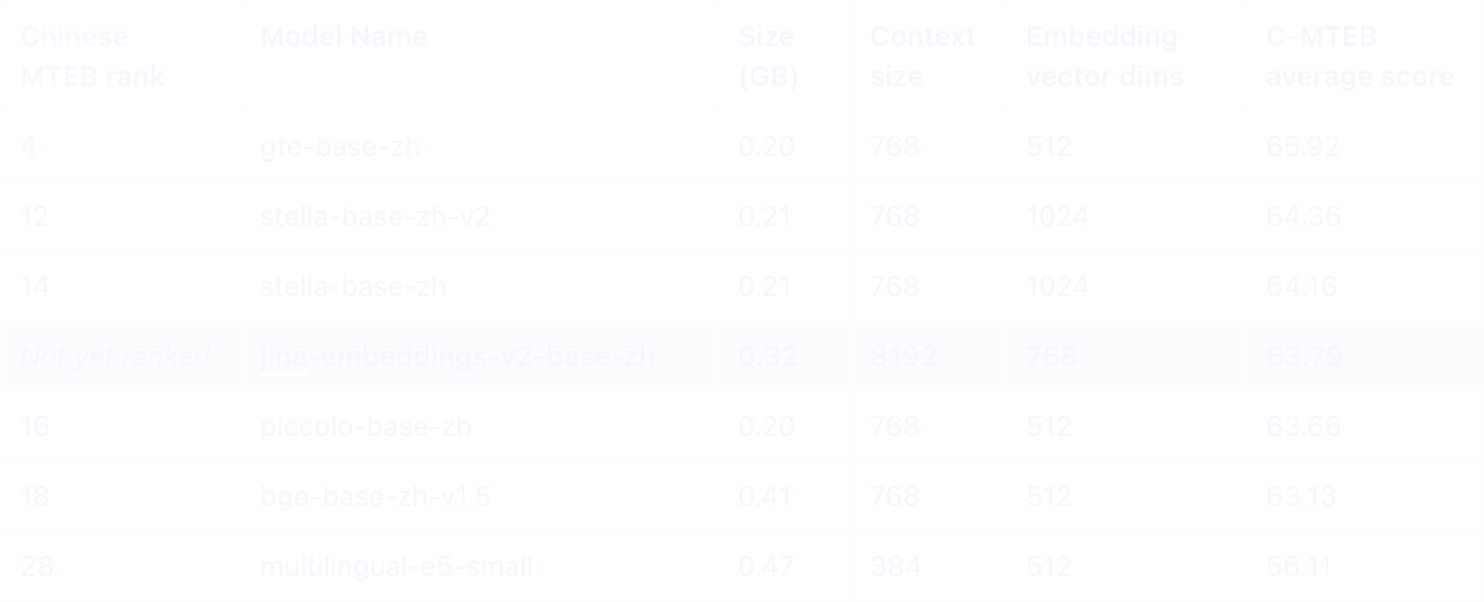
Unter den chinesischen Modellen ähnlicher Größe bieten nur das E5 Multilingual Modell und unser jina-embeddings-v2-base-zh Unterstützung für Englisch, was effektive sprachübergreifende Anwendungen ermöglicht. Bemerkenswert ist, dass Jina in allen Kategorien, die die chinesische Sprache betreffen, deutlich überlegene Leistung zeigt.

Während beide Modelle eine 8K Token-Kontextgröße haben, übertrifft jina-embeddings-v2-base-zh OpenAIs text-embedding-ada-002 deutlich, besonders bei Aufgaben mit der chinesischen Sprache.

tagStärkung chinesischer Unternehmen für die globale Expansion
Unser chinesisch-englisches Embedding-Modell ist ein leistungsstarkes Werkzeug für chinesische Unternehmen, die global expandieren wollen (出海). Es verarbeitet chinesische Texte nahtlos und liefert hochwertige Embeddings, die sich mühelos in führende Vektordatenbanken, Suchsysteme und RAG-Anwendungen integrieren lassen.
jina-embeddings-v2-base-zh ist besonders vorteilhaft für die Entwicklung von KI-Anwendungen, die auf chinesisch-englische Kontexte zugeschnitten sind, was für international expandierende Unternehmen entscheidend ist. Hier sind einige spezifische Anwendungsfälle:
- Dokumentenanalyse und -verwaltung: Es kann eine Vielzahl von Dokumenten analysieren und verwalten und unterstützt internationale Rechts- und Geschäftstransaktionen.
- KI-gestützte Suchanwendungen: Verbessert Suchfunktionen in mehrsprachigen Umgebungen und erleichtert globalen Nutzern das Auffinden relevanter Informationen in Chinesisch und Englisch.
- Retrieval-Augmented Chatbots und Frage-Antwort-Systeme: Entwickelt effiziente, zweisprachige Kundenservice-Bots und verbessert die Interaktion mit Kunden weltweit.
- Natural Language Processing Anwendungen: Dies umfasst Stimmungsanalyse zum Verständnis globaler Markttrends, Themenmodellierung für internationale Marketingstrategien und Textklassifizierung für die Verwaltung globaler Kommunikation.
- Empfehlungssysteme: Passt Produkt- und Inhaltsempfehlungen für verschiedene globale Zielgruppen an, basierend auf Erkenntnissen aus chinesischen und englischen Daten.
tagErste Schritte mit jina-embeddings-v2-base-zh über API
Beginnen Sie sofort mit der Integration unseres Modells in Ihren Workflow über die Embeddings API. Besuchen Sie einfach das Embeddings Portal, holen Sie sich Ihren kostenlosen Zugangsschlüssel oder laden Sie einen bestehenden Schlüssel auf, und wählen Sie dann jina-embeddings-v2-base-zh aus dem Dropdown-Menü. So einfach ist der Einstieg!

tagWas kommt als Nächstes: Erweiterung der Sprachunterstützung und AWS Sagemaker Integration
jina-embeddings-v2-base-zh wird bald über AWS Sagemaker und Hugging Face verfügbar sein.



Bei Jina AI ist unser Engagement, führend in erschwinglicher und zugänglicher Embedding-Technologie für ein globales Publikum zu sein, ungebrochen. Wir entwickeln aktiv weitere mehrsprachige Angebote mit Fokus auf wichtige europäische und andere internationale Sprachen, um unsere Reichweite zu vergrößern. Bleiben Sie dran für diese spannenden Updates, einschließlich der Integration mit AWS SageMaker, während wir unsere Fähigkeiten weiter ausbauen.
tagEin besonderer Dank an unsere frühen Tester
Wir sind den ausgewählten Mitgliedern unserer chinesischen Nutzer-Community, die die Vorschauversion (jina-embeddings-v2-base-zh-preview) getestet haben, äußerst dankbar. Ihr aufschlussreiches Feedback war entscheidend für die Verbesserung der Leistung der offiziellen Version. Wenn Sie Beobachtungen oder Vorschläge zur Qualität unserer Modelle haben, laden wir Sie herzlich ein, unserem Discord-Server beizutreten und Ihre Gedanken mit uns zu teilen. Ihr Input ist wertvoll für unsere kontinuierliche Verbesserung.


Verbesserte Punkteverteilung vs. jina-embeddings-v2-base-zh-preview
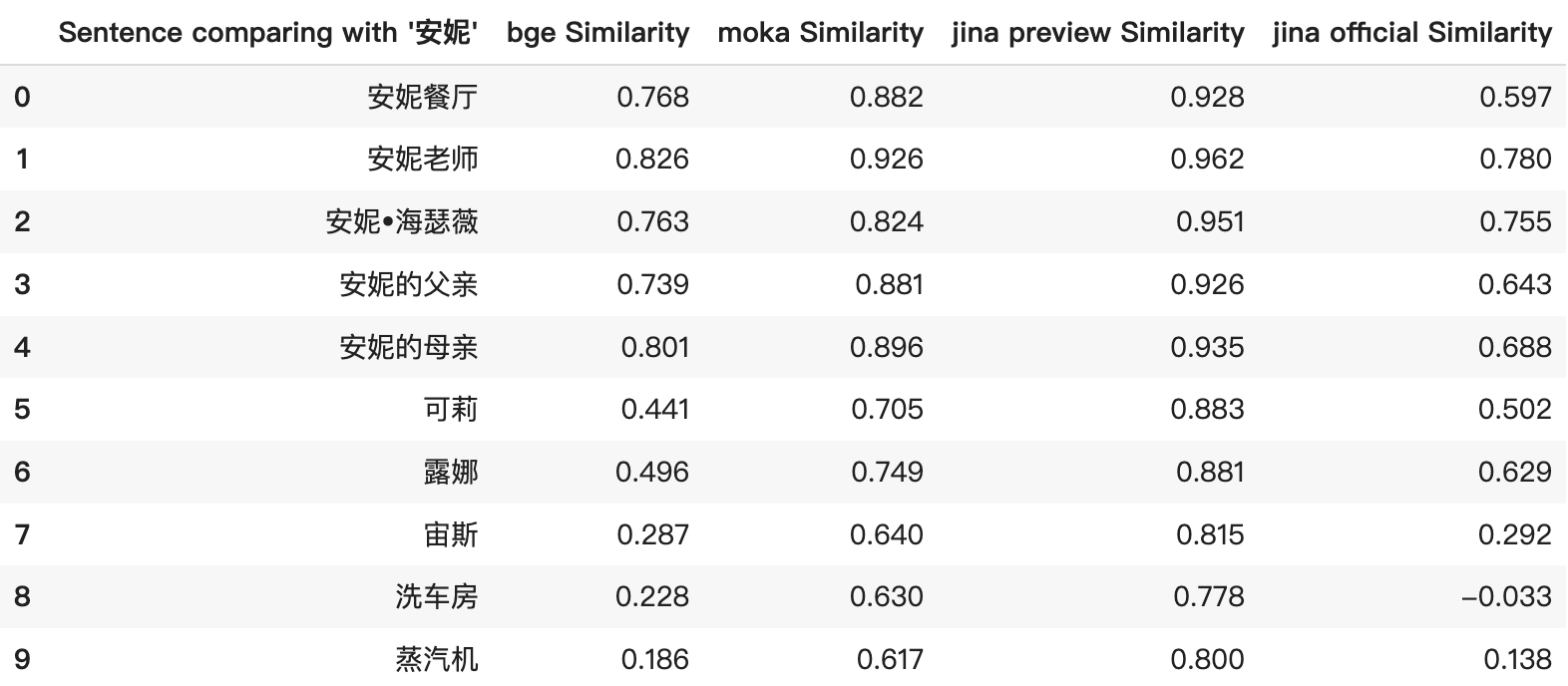
jina-embeddings-v2-base-zh-preview litt unter überhöhten Ähnlichkeitswerten, die selbst bei nicht verwandten Elementen zu hohen Cosinus-Werten führten. Dies war besonders in den Top-5-Ergebnissen des Screenshots unten ersichtlich. Die Ähnlichkeitswerte waren durchweg hoch und spiegelten die tatsächliche Beziehung zwischen den Elementen nicht genau wider. Zum Beispiel erhielt der Vergleich zwischen "安妮" und "蒸汽机" irreführend hohe Ähnlichkeitswerte.
In der offiziellen Version haben wir das Modell optimiert, um aussagekräftigere und logischere Ähnlichkeitswerte zu erzeugen und damit eine genauere Darstellung der Beziehungen zwischen den Elementen zu gewährleisten. Die überarbeitete Bewertung präsentiert nun beispielsweise eine breitere Spanne und bietet einen klareren Einblick in die relative Ähnlichkeit zwischen den Elementen.
Darüber hinaus ist Jina Embeddings jetzt das einzige Open-Source-Embedding-Modell, das 8192 Token unterstützt. Diese Funktion unterstreicht seine Fähigkeit, eine breite Palette von Datentypen zu verarbeiten, von umfangreichen Dokumenten bis hin zu kurzen Phrasen oder sogar einzelnen Wörtern/Namen wie "安妮" vs "露娜".
tagBrandneues zweisprachiges 8K-Vektor-Großmodell für Chinesisch und Englisch - Ein Muss für Unternehmen mit globalen Ambitionen!
Nach dem großen Erfolg unseres Embeddings V2 stellen wir heute unser neues zweisprachiges Text-Vektor-Großmodell vor: jina-embeddings-v2-base-zh. Dieses Modell übernimmt nicht nur alle Vorteile von V2 und kann Texte mit bis zu achttausend Token verarbeiten, sondern bewältigt auch problemlos chinesische und englische Inhalte, was neue Möglichkeiten für sprachübergreifende Anwendungen eröffnet.
Die herausragende Leistung von jina-embeddings-v2-base-zh basiert auf hochwertigen zweisprachigen Datensätzen und unserem strengen und ausgewogenen Vortraining sowie primärer und sekundärer Feinabstimmung. Dieser dreistufige Trainingsansatz hat nicht nur die zweisprachigen Fähigkeiten des Modells verallgemeinert, sondern auch effektiv Modellverzerrungen reduziert und das häufige Problem der "ungleichmäßigen Verteilung" bei mehrsprachigen Modellen gelöst.
tagModellmerkmale im Überblick
Merkmal 1: Nahtlose zweisprachige Integration
Das jina-embeddings-v2-base-zh-Modell kann sowohl chinesische als auch englische Texte problemlos verarbeiten, sei es als Suchanfrage oder Zieldokument. Inhaltlich ähnliche Texte in beiden Sprachen werden in denselben Vektorraum abgebildet, was eine solide Grundlage für mehrsprachige Anwendungen schafft.
Merkmal 2: Unterstützung für 8K Token Langtext
Unser Modell unterstützt die Verarbeitung von Texten mit bis zu 8K Token, was im Bereich der Open-Source-Vektormodelle einzigartig ist und einen deutlichen Vorteil bei der Verarbeitung längerer Textabschnitte bietet.
Merkmal 3: Effiziente, kompakte Modellstruktur
Das jina-embeddings-v2-base-zh-Modell hat mit 322MB (einschließlich 161 Millionen Parameter) eine schlanke Größe und eine Ausgabedimension von 768. Es kann auf gewöhnlicher Computer-Hardware effizient ohne GPU-Abhängigkeit ausgeführt werden, was seine Praktikabilität und Benutzerfreundlichkeit erheblich steigert.
tagHerausragende Modellleistung
Im harten Wettbewerb der CMTEB-Rangliste sticht unser Jina Embeddings v2 Modell in der Kategorie unter 0,5GB hervor. Es unterstützt nicht nur chinesische und englische Texte, sondern kann auch Texte mit bis zu 8K Token verarbeiten - eine Fähigkeit, die bei vergleichbaren Modellen selten zu finden ist.
Unter den Modellen gleicher Größe, die Chinesisch unterstützen, sind Multilingual E5 und unser jina-embeddings-v2-base-zh die einzigen beiden Modelle, die auch Englisch verarbeiten können, was sprachübergreifende Anwendungen ermöglicht.
Derzeit können weltweit nur OpenAIs proprietäres Modell text-embedding-ada-002 und Jina Embeddings Langtexteingaben von 8k Token unterstützen. Bei der Verarbeitung chinesischer Aufgaben zeigt Jina Embeddings dabei deutliche Leistungsvorteile.
tagUnterstützung für chinesische Unternehmen bei der globalen Expansion
Unser zweisprachiges Vektormodell jina-embeddings-v2-base-zh ist ein leistungsstarker Partner für chinesische Unternehmen, die in internationale Märkte expandieren. Es kann nahtlos chinesische und englische Texte verarbeiten, bietet hochwertige Textvektordarstellungen und lässt sich einfach in fortschrittliche Vektordatenbanken, Suchsysteme und RAG-Anwendungen integrieren.
Dieses Modell eignet sich besonders für die Entwicklung von KI-Anwendungen für zweisprachige Szenarien und ist für Unternehmen mit globalen Ambitionen von unschätzbarem Wert. Hier sind einige praktische Anwendungsfälle:
- Dokumentenanalyse und -verwaltung: Analyse und Verwaltung umfangreicher Dokumente zur Unterstützung internationaler rechtlicher und geschäftlicher Transaktionen.
- KI-gesteuerte Suchanwendungen: Verbesserung der Suchleistung in mehrsprachigen Umgebungen, um globalen Nutzern zu helfen, chinesische und englische Informationen einfach zu finden.
- Verbesserte Chatbots und Frage-Antwort-Systeme: Entwicklung effizienter zweisprachiger Kundenservice-Bots zur Optimierung der Kommunikation mit globalen Kunden.
- Natural Language Processing Anwendungen: Topic Modeling für globale Markttrends und internationale Marketingstrategien sowie Textklassifizierung für globales Kommunikationsmanagement.
- Empfehlungssysteme: Nutzung von chinesischen und englischen Datenerkenntnissen für personalisierte Produkt- und Content-Empfehlungen für ein globales, vielfältiges Publikum.
Mit diesem Modell können chinesische Unternehmen die Sprachbarriere im Bereich der KI-Anwendungen überwinden und sich einen Vorsprung im globalen Wettbewerb verschaffen.
tagEinfacher Einstieg in jina-embeddings-v2-base-zh
Möchten Sie unser zweisprachiges Embedding-Modell schnell in Ihren Workflow integrieren? Es sind nur wenige einfache Schritte nötig: Besuchen Sie https://jina.ai/embeddings, holen Sie sich Ihren kostenlosen API-Schlüssel oder aktualisieren Sie Ihren bestehenden Schlüssel, wählen Sie dann jina-embeddings-v2-base-zh aus dem Dropdown-Menü - und Ihr Modell ist sofort einsatzbereit für Ihre Exploration und Nutzung!
tagAusblick: Mehrsprachige Unterstützung und tiefe Integration mit AWS SageMaker
jina-embeddings-v2-base-zh wird bald auf AWS SageMaker und HuggingFace verfügbar sein, um Nutzern einen noch bequemeren Service zu bieten.
Wir arbeiten aktiv an mehrsprachigen Embedding-Modellen, insbesondere für europäische und andere internationale Sprachen, um den vielfältigen Bedürfnissen globaler Nutzer gerecht zu werden. Bleiben Sie gespannt auf unsere kommenden spannenden Updates, einschließlich der tiefen Integration mit AWS SageMaker, während wir unseren Serviceumfang kontinuierlich vertiefen und erweitern.
tagDanksagung: Wertvolle Beiträge unserer frühen Tester
Wir danken herzlich der chinesischen Community, die an den Tests von jina-embeddings-v2-base-zh-preview teilgenommen hat. Ihr wertvolles Feedback hat maßgeblich zur Optimierung unseres Modells beigetragen. Wenn Sie während der Nutzung Vorschläge oder Ideen haben, können Sie sich jederzeit an uns wenden. Jedes einzelne Feedback ist ein Antrieb für unsere kontinuierliche Verbesserung.
Die finale Version löst das Problem der Score-Inflation der Preview-Version
Im Vergleich zur vorherigen Preview-Version bietet das finale Modell besser verteilte und plausiblere Ähnlichkeitsbewertungen. Während der Tests der Preview-Version zeigte unser Modell eine Inflation der Ähnlichkeitsbewertungen, wobei selbst völlig unverwandte Wörter wie "Annie" und "Dampfmaschine" hohe Cosinus-Ähnlichkeiten erhielten. In der finalen Version haben wir das Modell optimiert, um sicherzustellen, dass die Ähnlichkeitsbewertungen angemessener sind und die Beziehungen zwischen Inhalten genauer widerspiegeln.
Darüber hinaus unterstützt Jina Embeddings jetzt die Verarbeitung von bis zu 8192 Token, ob lange Abhandlungen oder kurze Sätze, sogar einzelne Wörter oder Namen (wie der Vergleich von "Annie" und "Luna"). Dies zeigt die leistungsstarke Fähigkeit, verschiedene Arten von Daten zu verarbeiten. Diese Verbesserung steigert nicht nur die Genauigkeit des Modells, sondern auch seine Flexibilität und Praktikabilität bei der Verarbeitung vielfältiger Daten.
