Reader
Convert a URL to LLM-friendly input, by simply adding
r.jina.ai in front.Reader API
Convert a URL to LLM-friendly input, by simply adding
r.jina.ai in front.chevron_leftchevron_right
globe_book
Use
r.jina.ai to read a URL and fetch its contenttravel_explore
Use
s.jina.ai to search the web and get SERP
Add
mcp.jina.ai as your MCP server to access our API in LLMsupload
Request
GET
curl "https://r.jina.ai/https://www.example.com"
Jina VLM: Small Multilingual Vision Language Model
A 2.4B parameter vision-language model that achieves state-of-the-art multilingual visual question answering among open 2B-scale VLMs.

ReaderLM v2: Small Language Model for HTML to Markdown and JSON
ReaderLM-v2 is a 1.5B parameter language model specialized in HTML-to-Markdown conversion and HTML-to-JSON extraction. It supports documents up to 512K tokens across 29 languages and offers 20% higher accuracy compared to its predecessor.


Feeding web information into LLMs is an important step of grounding, yet it can be challenging. The simplest method is to scrape the webpage and feed the raw HTML. However, scraping can be complex and often blocked, and raw HTML is cluttered with extraneous elements like markups and scripts. The Reader API addresses these issues by extracting the core content from a URL and converting it into clean, LLM-friendly text, ensuring high-quality input for your agent and RAG systems.
Raw HTML
Reader Output

Reader can be used as SERP API. It allows you to feed your LLM with the content behind the search results engine page. Simply prepend
https://s.jina.ai/?q= to your query, and Reader will search the web and return the top five results with their URLs and contents, each in clean, LLM-friendly text. This way, you can always keep your LLM up-to-date, improve its factuality, and reduce hallucinations.info Please note that unlike the demo shown above, in practice you do not search the original question on the web for grounding. What people often do is rewrite the original question or use multi-hop questions. They read the retrieved results and then generate additional queries to gather more information as needed before arriving at a final answer.

Images on the webpage are automatically captioned using a vision language model in the reader and formatted as image alt tags in the output. This gives your downstream LLM just enough hints to incorporate those images into its reasoning and summarizing processes. This means you can ask questions about the images, select specific ones, or even forward their URLs to a more powerful VLM for deeper analysis!
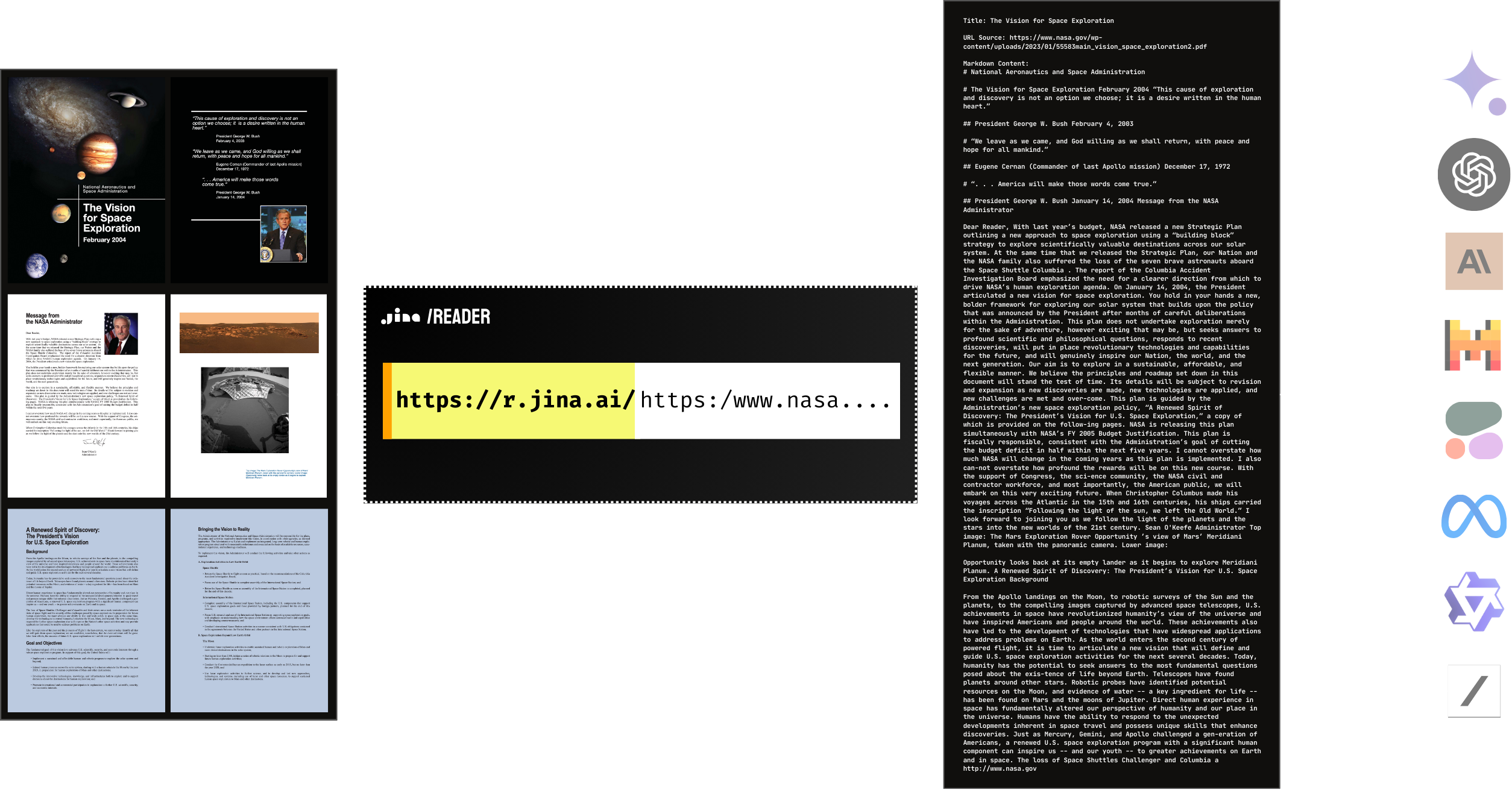
Yes, Reader natively supports PDF reading. It's compatible with most PDFs, including those with many images, and it's lightning fast! Combined with an LLM, you can easily build a ChatPDF or document analysis AI in no time.
The best part? It's free!
Reader API is available for free and offers flexible rate limit and pricing. Built on a scalable infrastructure, it offers high accessibility, concurrency, and reliability. We strive to be your preferred grounding solution for your LLMs.
Rate Limit
Rate limits are tracked in three ways: RPM (requests per minute), and TPM (tokens per minute). Limits are enforced per IP/API key and will be triggered when either the RPM or TPM threshold is reached first. When you provide an API key in the request header, we track rate limits by key rather than IP address.
| Product | API Endpoint | Descriptionarrow_upward | w/o API Keykey_off | w/ Free API Keykey | w/ Paid API Keykey | w/ Premium API Keykey | Average Latency | Token Usage Counting | Allowed Request | |
|---|---|---|---|---|---|---|---|---|---|---|
| Reader API | https://r.jina.ai | Convert URL to LLM-friendly text | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Count the number of tokens in the output response. | GET/POST | |
| Reader API | https://s.jina.ai | Search the web and convert results to LLM-friendly text | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Every request costs a fixed number of tokens, starting from 10000 tokens | GET/POST | |
| Embedding API | https://api.jina.ai/v1/embeddings | Convert text/images to fixed-length vectors | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart depends on the input size help | Count the number of tokens in the input request. | POST | |
| Reranker API | https://api.jina.ai/v1/rerank | Rank documents by query | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart depends on the input size help | Count the number of tokens in the input request. | POST | |
| Classifier API | https://api.jina.ai/v1/train | Train a classifier using labeled examples | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depends on the input size | Tokens counted as: input_tokens × num_iters | POST | |
| Classifier API (Few-shot) | https://api.jina.ai/v1/classify | Classify inputs using a trained few-shot classifier | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depends on the input size | Tokens counted as: input_tokens | POST | |
| Classifier API (Zero-shot) | https://api.jina.ai/v1/classify | Classify inputs using zero-shot classification | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depends on the input size | Tokens counted as: input_tokens + label_tokens | POST | |
| Segmenter API | https://api.jina.ai/v1/segment | Tokenize and segment long text | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | Token is not counted as usage. | GET/POST | |
| DeepSearch | https://deepsearch.jina.ai/v1/chat/completions | Reason, search and iterate to find the best answer | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Count the total number of tokens in the whole process. | POST |





Don't panic! Every new API key contains ten millions free tokens!
API Pricing
API pricing is based on the token usage. One API key gives you access to all search foundation products.

With Jina Search Foundation API
The easiest way to access all of our products. Top-up tokens as you go.
Top up this API key with more tokens
Please input the right API key to top up
Understand the rate limit
Rate limits are the maximum number of requests that can be made to an API within a minute per IP address/API key (RPM). Find out more about the rate limits for each product and tier below.
keyboard_arrow_down

What are the costs associated with using the Reader API?
keyboard_arrow_down
How does the Reader API function?
keyboard_arrow_down
Is the Reader API open source?
keyboard_arrow_down
What is the typical latency for the Reader API?
keyboard_arrow_down
Why should I use the Reader API instead of scraping the page myself?
keyboard_arrow_down
Does the Reader API support multiple languages?
keyboard_arrow_down
What should I do if a website blocks the Reader API?
keyboard_arrow_down
Can the Reader API extract content from PDF files?
keyboard_arrow_down
Can the Reader API process media content from web pages?
keyboard_arrow_down
Is it possible to use the Reader API on local HTML files?
keyboard_arrow_down
Does Reader API cache the content?
keyboard_arrow_down
Can I use the Reader API to access content behind a login?
keyboard_arrow_down
Can I use the Reader API to access PDF on arXiv?
keyboard_arrow_down
How does image caption work in Reader?
keyboard_arrow_down
What is the scalability of the Reader? Can I use it in production?
keyboard_arrow_down
What is the rate limit of the Reader API?
keyboard_arrow_down
What is Reader-LM? How can I use it?
keyboard_arrow_down
How do I extract structured data from webpages?
keyboard_arrow_down
Does Reader actively bypass website anti-bot protection?
keyboard_arrow_down
Will upgrading from a free to a paid API key give me access to more websites?
keyboard_arrow_down
Rate Limit
Rate limits are tracked in three ways: RPM (requests per minute), and TPM (tokens per minute). Limits are enforced per IP/API key and will be triggered when either the RPM or TPM threshold is reached first. When you provide an API key in the request header, we track rate limits by key rather than IP address.
| Product | API Endpoint | Descriptionarrow_upward | w/o API Keykey_off | w/ Free API Keykey | w/ Paid API Keykey | w/ Premium API Keykey | Average Latency | Token Usage Counting | Allowed Request | |
|---|---|---|---|---|---|---|---|---|---|---|
| Reader API | https://r.jina.ai | Convert URL to LLM-friendly text | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Count the number of tokens in the output response. | GET/POST | |
| Reader API | https://s.jina.ai | Search the web and convert results to LLM-friendly text | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Every request costs a fixed number of tokens, starting from 10000 tokens | GET/POST | |
| Embedding API | https://api.jina.ai/v1/embeddings | Convert text/images to fixed-length vectors | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart depends on the input size help | Count the number of tokens in the input request. | POST | |
| Reranker API | https://api.jina.ai/v1/rerank | Rank documents by query | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart depends on the input size help | Count the number of tokens in the input request. | POST | |
| Classifier API | https://api.jina.ai/v1/train | Train a classifier using labeled examples | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depends on the input size | Tokens counted as: input_tokens × num_iters | POST | |
| Classifier API (Few-shot) | https://api.jina.ai/v1/classify | Classify inputs using a trained few-shot classifier | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depends on the input size | Tokens counted as: input_tokens | POST | |
| Classifier API (Zero-shot) | https://api.jina.ai/v1/classify | Classify inputs using zero-shot classification | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart depends on the input size | Tokens counted as: input_tokens + label_tokens | POST | |
| Segmenter API | https://api.jina.ai/v1/segment | Tokenize and segment long text | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | Token is not counted as usage. | GET/POST | |
| DeepSearch | https://deepsearch.jina.ai/v1/chat/completions | Reason, search and iterate to find the best answer | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Count the total number of tokens in the whole process. | POST |
API-related common questions
code
Can I use the same API key for reader, embedding, reranking, classifying and fine-tuning APIs?
keyboard_arrow_down
code
Can I monitor the token usage of my API key?
keyboard_arrow_down
code
What should I do if I forget my API key?
keyboard_arrow_down
code
Do API keys expire?
keyboard_arrow_down
code
Can I transfer tokens between API keys?
keyboard_arrow_down
code
Can I revoke my API key?
keyboard_arrow_down
code
Why is the first request for some models slow?
keyboard_arrow_down
code
Is my API data used to train your models?
keyboard_arrow_down
code
What are the rate limits for Jina APIs?
keyboard_arrow_down
code
Are there batch size limits for the APIs?
keyboard_arrow_down
Billing-related common questions
attach_money
Is billing based on the number of sentences or requests?
keyboard_arrow_down
attach_money
Is there a free trial available for new users?
keyboard_arrow_down
attach_money
Are tokens charged for failed requests?
keyboard_arrow_down
attach_money
What payment methods are accepted?
keyboard_arrow_down
attach_money
Is invoicing available for token purchases?
keyboard_arrow_down