

Es gibt viele Hürden beim Verständnis von AI-Modellen, einige davon ziemlich große, und sie können die Implementierung von AI-Prozessen erschweren. Aber die erste, auf die viele Menschen stoßen, ist das Verständnis dessen, was wir meinen, wenn wir von Tokens sprechen.

Einer der wichtigsten praktischen Parameter bei der Auswahl eines AI-Sprachmodells ist die Größe seines Kontextfensters — die maximale Eingabetextgröße —, die in Tokens angegeben wird, nicht in Wörtern oder Zeichen oder anderen automatisch erkennbaren Einheiten.
Darüber hinaus werden Embedding-Services typischerweise „pro Token" berechnet, was bedeutet, dass Tokens wichtig für das Verständnis Ihrer Rechnung sind.
Dies kann sehr verwirrend sein, wenn man nicht genau weiß, was ein Token ist.
Aber von allen verwirrenden Aspekten der modernen AI sind Tokens wahrscheinlich die am wenigsten komplizierten. Dieser Artikel wird versuchen zu erklären, was Tokenisierung ist, was sie bewirkt und warum wir sie auf diese Weise durchführen.
tagtl;dr
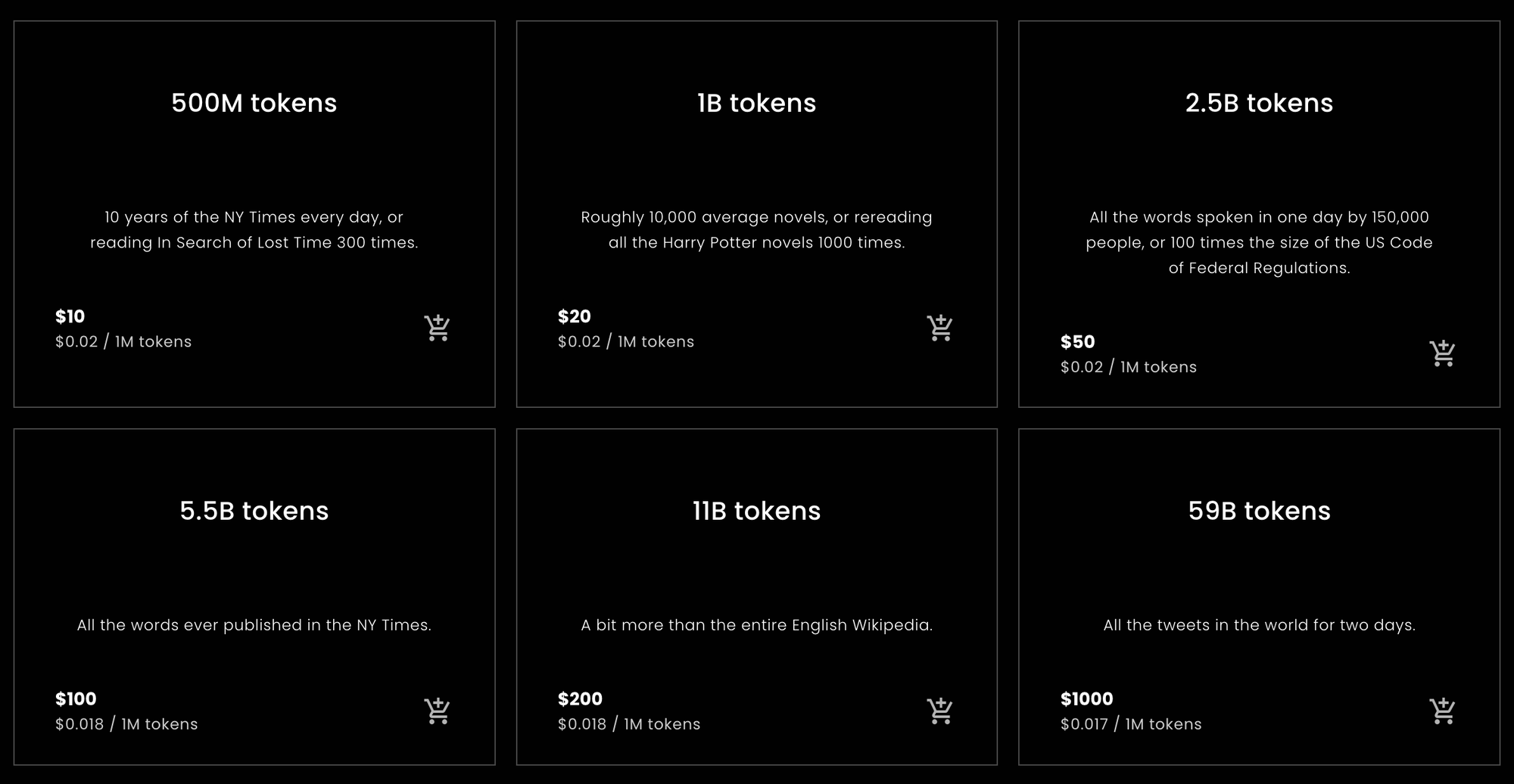
Für diejenigen, die eine schnelle Antwort suchen, um herauszufinden, wie viele Tokens sie von Jina Embeddings kaufen sollten oder eine Schätzung, wie viele sie voraussichtlich kaufen müssen, sind die folgenden Statistiken das, wonach Sie suchen.
tagTokens pro englisches Wort
Während empirischer Tests, die weiter unten in diesem Artikel beschrieben werden, wurden verschiedene englische Texte mit einer Rate von etwa 10% mehr Tokens als Wörter in Tokens umgewandelt, wenn die englischsprachigen Modelle von Jina Embeddings verwendet wurden. Dieses Ergebnis war ziemlich robust.
Jina Embeddings v2 Modelle haben ein Kontextfenster von 8192 Tokens. Das bedeutet, dass wenn Sie einem Jina-Modell einen englischen Text mit mehr als 7.400 Wörtern übergeben, dieser mit hoher Wahrscheinlichkeit abgeschnitten wird.
tagTokens pro chinesisches Zeichen
Für Chinesisch sind die Ergebnisse variabler. Je nach Textart variierten die Verhältnisse von 0,6 bis 0,75 Tokens pro chinesischem Zeichen (汉字). Englische Texte, die an Jina Embeddings v2 für Chinesisch übergeben werden, erzeugen ungefähr die gleiche Anzahl von Tokens wie Jina Embeddings v2 für Englisch: etwa 10% mehr als die Anzahl der Wörter.
tagTokens pro deutsches Wort
Deutsche Wort-zu-Token-Verhältnisse sind variabler als Englisch, aber weniger als Chinesisch. Je nach Textgenre erhielt ich durchschnittlich 20% bis 30% mehr Tokens als Wörter. Wenn man englische Texte an Jina Embeddings v2 für Deutsch und Englisch übergibt, werden etwas mehr Tokens verwendet als bei den reinen Englisch- und Chinesisch/Englisch-Modellen: 12% bis 15% mehr Tokens als Wörter.
tagVorsicht!
Dies sind einfache Berechnungen, aber sie sollten für die meisten natürlichsprachlichen Texte und die meisten Benutzer ungefähr stimmen. Letztendlich können wir nur versprechen, dass die Anzahl der Tokens immer nicht mehr als die Anzahl der Zeichen in Ihrem Text plus zwei beträgt. Praktisch wird es immer viel weniger sein, aber wir können im Voraus keine spezifische Anzahl versprechen.
Dies sind Schätzungen basierend auf statistisch naiven Berechnungen. Wir garantieren nicht, wie viele Tokens eine bestimmte Anfrage benötigen wird.
Wenn Sie nur einen Rat brauchen, wie viele Tokens Sie für Jina Embeddings kaufen sollten, können Sie hier aufhören. Andere Embedding-Modelle von anderen Unternehmen als Jina AI haben möglicherweise nicht die gleichen Token-zu-Wort- und Token-zu-Chinesisches-Zeichen-Verhältnisse wie Jina-Modelle, aber sie werden sich im Allgemeinen nicht sehr stark unterscheiden.
Wenn Sie verstehen möchten, warum das so ist, bietet der Rest dieses Artikels einen tieferen Einblick in die Tokenisierung für Sprachmodelle.
tagWörter, Tokens, Zahlen
Tokenisierung ist schon länger Teil der Verarbeitung natürlicher Sprache als moderne AI-Modelle existieren.
Es ist ein bisschen klischeehaft zu sagen, dass alles in einem Computer nur eine Zahl ist, aber es stimmt größtenteils. Sprache ist jedoch von Natur aus nicht nur ein Haufen Zahlen. Sie kann Sprache sein, die aus Schallwellen besteht, oder Schrift, die aus Zeichen auf Papier besteht, oder sogar ein Bild eines gedruckten Textes oder ein Video von jemandem, der Gebärdensprache verwendet. Aber meistens, wenn wir über die Verarbeitung natürlicher Sprache mit Computern sprechen, meinen wir Texte, die aus Sequenzen von Zeichen bestehen: Buchstaben (a, b, c usw.), Ziffern (0, 1, 2…), Interpunktion und Leerzeichen in verschiedenen Sprachen und Textkodierungen.
Computeringenieure nennen diese „Strings".
AI-Sprachmodelle nehmen Zahlensequenzen als Eingabe. Wenn Sie also den Satz schreiben:
What is today's weather in Berlin?
Aber nach der Tokenisierung erhält das AI-Modell als Eingabe:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
Tokenisierung ist der Prozess der Umwandlung einer Eingabezeichenkette in eine spezifische Zahlensequenz, die Ihr AI-Modell verstehen kann.
Wenn Sie ein AI-Modell über eine Web-API verwenden, die Benutzern pro Token berechnet wird, wird jede Anfrage in eine Zahlensequenz wie die obige umgewandelt. Die Anzahl der Tokens in der Anfrage ist die Länge dieser Zahlensequenz. Wenn Sie also Jina Embeddings v2 für Englisch bitten, Ihnen ein Embedding für „What is today's weather in Berlin?" zu geben, kostet Sie das 11 Tokens, weil es diesen Satz in eine Sequenz von 11 Zahlen umgewandelt hat, bevor es ihn an das AI-Modell weitergibt.
AI-Modelle, die auf der Transformer-Architektur basieren, haben ein Kontextfenster fester Größe, dessen Größe in Tokens gemessen wird. Manchmal wird dies auch „Eingabefenster", „Kontextgröße" oder „Sequenzlänge" genannt (besonders auf dem Hugging Face MTEB Leaderboard). Es bedeutet die maximale Textgröße, die das Modell auf einmal sehen kann.
Wenn Sie also ein Embedding-Modell verwenden möchten, ist dies die maximal erlaubte Eingabegröße.
Jina Embeddings v2 Modelle haben alle ein Kontextfenster von 8.192 Tokens. Andere Modelle werden unterschiedliche (typischerweise kleinere) Kontextfenster haben. Das bedeutet, dass egal wie viel Text Sie eingeben, der mit diesem Jina Embeddings-Modell verbundene Tokenizer ihn in nicht mehr als 8.192 Tokens umwandeln muss.
tagAbbildung von Sprache auf Zahlen
Die einfachste Art, die Logik von Tokens zu erklären, ist diese:
Bei Modellen für natürliche Sprache ist der Teil eines Strings, für den ein Token steht, ein Wort, ein Teil eines Wortes oder ein Interpunktionszeichen. Leerzeichen erhalten in der Regel keine explizite Darstellung in der Tokenizer-Ausgabe.
Tokenisierung ist Teil einer Gruppe von Techniken in der Verarbeitung natürlicher Sprache, die Textsegmentierung genannt wird, und das Modul, das die Tokenisierung durchführt, wird sehr logisch als Tokenizer bezeichnet.
Um zu zeigen, wie Tokenisierung funktioniert, werden wir einige Sätze mit dem kleinsten Jina Embeddings v2 Modell für Englisch tokenisieren: jina-embeddings-v2-small-en. Das andere rein englische Modell von Jina Embeddings — jina-embeddings-v2-base-en — verwendet den gleichen Tokenizer, also macht es keinen Sinn, extra Megabytes an AI-Modell herunterzuladen, die wir in diesem Artikel nicht verwenden werden.
Installieren Sie zuerst das transformers Modul in Ihrer Python-Umgebung oder Notebook. Verwenden Sie die-U Flag, um sicherzustellen, dass Sie auf die neueste Version aktualisieren, da dieses Modell mit einigen älteren Versionen nicht funktioniert:
pip install -U transformers
Laden Sie dann jina-embeddings-v2-small-en mit AutoModel.from_pretrained herunter:
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-small-en', trust_remote_code=True)
Um einen String zu tokenisieren, verwenden Sie die encode Methode des tokenizer Member-Objekts des Modells:
model.tokenizer.encode("What is today's weather in Berlin?")
Das Ergebnis ist eine Liste von Zahlen:
[101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102]
Um diese Zahlen wieder in String-Form umzuwandeln, verwenden Sie die convert_ids_to_tokens Methode des tokenizer Objekts:
model.tokenizer.convert_ids_to_tokens([101, 2054, 2003, 2651, 1005, 1055, 4633, 1999, 4068, 1029, 102])
Das Ergebnis ist eine Liste von Strings:
['[CLS]', 'what', 'is', 'today', "'", 's', 'weather', 'in',
'berlin', '?', '[SEP]']
Beachten Sie, dass der Tokenizer des Modells:
[CLS]am Anfang und[SEP]am Ende hinzugefügt hat. Dies ist aus technischen Gründen notwendig und bedeutet, dass jede Anfrage für ein Embedding zwei zusätzliche Token kostet, zusätzlich zu den Token, die der Text benötigt.- Interpunktion von Wörtern getrennt hat, wodurch aus „Berlin?":
berlinund?wird, und aus „today's":today,'unds. - Alles in Kleinbuchstaben umgewandelt hat. Nicht alle Modelle machen das, aber es kann beim Training mit Englisch hilfreich sein. Bei Sprachen, in denen Großschreibung eine andere Bedeutung hat, ist es möglicherweise weniger hilfreich.
Verschiedene Wörter-Zähl-Algorithmen in verschiedenen Programmen könnten die Wörter in diesem Satz unterschiedlich zählen. OpenOffice zählt dies als sechs Wörter. Der Unicode-Textsegmentierungsalgorithmus (Unicode Standard Annex #29) zählt sieben Wörter. Andere Software kann zu anderen Zahlen kommen, je nachdem, wie sie mit Interpunktion und Klitika wie "'s" umgeht.
Der Tokenizer für dieses Modell produziert neun Token für diese sechs oder sieben Wörter, plus die zwei zusätzlichen Token, die bei jeder Anfrage benötigt werden.
Versuchen wir es jetzt mit einem weniger gebräuchlichen Ortsnamen als Berlin:
token_ids = model.tokenizer.encode("I live in Kinshasa.")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Das Ergebnis:
['[CLS]', 'i', 'live', 'in', 'kin', '##sha', '##sa', '.', '[SEP]']
Der Name "Kinshasa" wird in drei Token aufgeteilt: kin, ##sha und ##sa. Das ## zeigt an, dass dieser Token nicht der Beginn eines Wortes ist.
Wenn wir dem Tokenizer etwas völlig Fremdes geben, erhöht sich die Anzahl der Token im Verhältnis zur Anzahl der Wörter noch mehr:
token_ids = model.tokenizer.encode("Klaatu barada nikto")
tokens = model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
['[CLS]', 'k', '##la', '##at', '##u', 'bar', '##ada', 'nik', '##to', '[SEP]']
Drei Wörter werden zu acht Token, plus die [CLS] und [SEP] Token.
Die Tokenisierung im Deutschen ist ähnlich. Mit dem Jina Embeddings v2 für Deutsch Modell können wir eine Übersetzung von "What is today's weather in Berlin?" auf die gleiche Weise tokenisieren wie beim englischen Modell.
german_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-de', trust_remote_code=True)
token_ids = german_model.tokenizer.encode("Wie wird das Wetter heute in Berlin?")
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Das Ergebnis:
['<s>', 'Wie', 'wird', 'das', 'Wetter', 'heute', 'in', 'Berlin', '?', '</s>']
Dieser Tokenizer unterscheidet sich ein wenig vom englischen darin, dass <s> und </s> [CLS] und [SEP] ersetzen, aber die gleiche Funktion erfüllen. Außerdem wird der Text nicht in Kleinbuchstaben normalisiert – Groß- und Kleinschreibung bleiben wie geschrieben – da Großschreibung im Deutschen eine andere Bedeutung hat als im Englischen.
(Um diese Darstellung zu vereinfachen, habe ich ein spezielles Zeichen entfernt, das den Wortanfang anzeigt.)
Versuchen wir es jetzt mit einem komplexeren Satz aus einem Zeitungstext:
Ein Großteil der milliardenschweren Bauern-Subventionen bleibt liegen – zu genervt sind die Landwirte von bürokratischen Gängelungen und Regelwahn.
sentence = """
Ein Großteil der milliardenschweren Bauern-Subventionen
bleibt liegen – zu genervt sind die Landwirte von
bürokratischen Gängelungen und Regelwahn.
"""
token_ids = german_model.tokenizer.encode(sentence)
tokens = german_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)Das tokenisierte Ergebnis:
['<s>', 'Ein', 'Großteil', 'der', 'mill', 'iarden', 'schwer',
'en', 'Bauern', '-', 'Sub', 'ventionen', 'bleibt', 'liegen',
'–', 'zu', 'gen', 'ervt', 'sind', 'die', 'Landwirte', 'von',
'büro', 'krat', 'ischen', 'Gän', 'gel', 'ungen', 'und', 'Regel',
'wahn', '.', '</s>']
Hier sehen Sie, dass viele deutsche Wörter in kleinere Teile zerlegt wurden, und zwar nicht unbedingt entlang der von der deutschen Grammatik erlaubten Linien. Das Ergebnis ist, dass ein langes deutsches Wort, das für einen Wortzähler als nur ein Wort zählen würde, für Jinas KI-Modell eine beliebige Anzahl von Token sein kann.
Machen wir dasselbe auf Chinesisch und übersetzen "What is today's weather in Berlin?" als:
柏林今天的天气怎么样?
chinese_model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-zh', trust_remote_code=True)
token_ids = chinese_model.tokenizer.encode("柏林今天的天气怎么样?")
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
Das tokenisierte Ergebnis:
['<s>', '柏林', '今天的', '天气', '怎么样', '?', '</s>']
Im Chinesischen gibt es normalerweise keine Worttrennungen im geschriebenen Text, aber der Jina Embeddings Tokenizer fügt häufig mehrere chinesische Zeichen zusammen:
| Token string | Pinyin | Bedeutung |
|---|---|---|
| 柏林 | Bólín | Berlin |
| 今天的 | jīntiān de | heute |
| 天气 | tiānqì | Wetter |
| 怎么样 | zěnmeyàng | wie |
Verwenden wir einen komplexeren Satz aus einer Hongkonger Zeitung:
sentence = """
新規定執行首日,記者在下班高峰前的下午5時來到廣州地鐵3號線,
從繁忙的珠江新城站啟程,向機場北方向出發。
"""
token_ids = chinese_model.tokenizer.encode(sentence)
tokens = chinese_model.tokenizer.convert_ids_to_tokens(token_ids)
print(tokens)
(Übersetzung: „Am ersten Tag, an dem die neuen Bestimmungen in Kraft waren, traf dieser Reporter um 17 Uhr, während der Hauptverkehrszeit, an der Guangzhou Metro Linie 3 ein und war von der Station Zhujiang New Town in Richtung Flughafen unterwegs.")
Das Ergebnis:
['<s>', '新', '規定', '執行', '首', '日', ',', '記者', '在下', '班',
'高峰', '前的', '下午', '5', '時', '來到', '廣州', '地', '鐵', '3',
'號', '線', ',', '從', '繁忙', '的', '珠江', '新城', '站', '啟',
'程', ',', '向', '機場', '北', '方向', '出發', '。', '</s>']
Diese Tokens entsprechen keinem spezifischen chinesischen Wörterbuch (词典). Zum Beispiel wird "啟程" - qǐchéng (aufbrechen, sich auf den Weg machen) normalerweise als ein einzelnes Wort kategorisiert, wird hier aber in seine zwei Bestandteile aufgeteilt. Ähnlich verhält es sich mit "在下班", das üblicherweise als zwei Wörter erkannt würde, mit der Trennung zwischen "在" - zài (in, während) und "下班" - xiàbān (Feierabend, Hauptverkehrszeit), nicht zwischen "在下" und "班", wie es der Tokenizer hier macht.
In allen drei Sprachen stehen die Stellen, an denen der Tokenizer den Text aufteilt, in keinem direkten Zusammenhang mit den logischen Stellen, an denen ein menschlicher Leser sie trennen würde.
Dies ist keine spezifische Eigenschaft von Jina Embeddings Modellen. Dieser Ansatz zur Tokenisierung ist in der KI-Modellentwicklung nahezu universell. Auch wenn zwei verschiedene KI-Modelle möglicherweise keine identischen Tokenizer haben, werden sie im aktuellen Entwicklungsstand praktisch alle Tokenizer mit dieser Art von Verhalten verwenden.
Im nächsten Abschnitt wird der spezifische Algorithmus für die Tokenisierung und die dahinterstehende Logik erläutert.
tagWarum tokenisieren wir? Und warum auf diese Weise?
KI-Sprachmodelle nehmen als Eingabe Zahlensequenzen, die für Textsequenzen stehen, aber bevor das zugrunde liegende neuronale Netzwerk ausgeführt und ein Embedding erstellt wird, geschieht noch etwas mehr. Wenn eine Liste von Zahlen präsentiert wird, die kleine Textsequenzen repräsentieren, schlägt das Modell jede Zahl in einem internen Wörterbuch nach, das einen eindeutigen Vektor für jede Zahl speichert. Diese werden dann kombiniert und bilden die Eingabe für das neuronale Netzwerk.
Das bedeutet, dass der Tokenizer jeden Eingabetext, den wir ihm geben, in Tokens umwandeln können muss, die im Token-Vektor-Wörterbuch des Modells vorkommen. Wenn wir unsere Tokens aus einem konventionellen Wörterbuch nehmen würden, würde das gesamte Modell beim ersten Auftreten eines Rechtschreibfehlers oder eines seltenen Eigennamens oder Fremdworts stoppen. Es könnte diese Eingabe nicht verarbeiten.
In der Verarbeitung natürlicher Sprache wird dies als Out-of-Vocabulary (OOV) Problem bezeichnet, und es tritt in allen Textarten und allen Sprachen auf. Es gibt einige Strategien zur Bewältigung des OOV-Problems:
- Ignorieren. Alles, was nicht im Wörterbuch steht, durch ein "unbekannt"-Token ersetzen.
- Umgehen. Statt ein Wörterbuch zu verwenden, das Textsequenzen auf Vektoren abbildet, eines verwenden, das einzelne Zeichen auf Vektoren abbildet. Englisch verwendet meist nur 26 Buchstaben, daher muss dies kleiner und robuster gegen OOV-Probleme sein als jedes Wörterbuch.
- Häufige Teilsequenzen im Text finden, diese ins Wörterbuch aufnehmen und für den Rest Zeichen (Ein-Buchstaben-Tokens) verwenden.
Die erste Strategie bedeutet, dass viele wichtige Informationen verloren gehen. Das Modell kann nicht einmal aus den Daten lernen, die es gesehen hat, wenn sie die Form von etwas annehmen, das nicht im Wörterbuch steht. Viele Dinge in gewöhnlichem Text sind selbst in den größten Wörterbüchern einfach nicht vorhanden.
Die zweite Strategie ist möglich und wurde von Forschern untersucht. Sie bedeutet jedoch, dass das Modell viel mehr Eingaben akzeptieren und viel mehr lernen muss. Dies bedeutet ein viel größeres Modell und viel mehr Trainingsdaten für ein Ergebnis, das sich nie als besser erwiesen hat als die dritte Strategie.
KI-Sprachmodelle implementieren praktisch alle in irgendeiner Form die dritte Strategie. Die meisten verwenden eine Variante des Wordpiece-Algorithmus [Schuster und Nakajima 2012] oder eine ähnliche Technik namens Byte-Pair Encoding (BPE). [Gage 1994, Senrich et al. 2016] Diese Algorithmen sind sprachagnostisch. Das bedeutet, sie funktionieren für alle geschriebenen Sprachen gleich, ohne Kenntnisse über eine umfassende Liste möglicher Zeichen hinaus. Sie wurden für mehrsprachige Modelle wie Googles BERT entwickelt, die einfach beliebige Eingaben aus dem Internet-Scraping verarbeiten — hunderte von Sprachen und Texte, die keine menschliche Sprache sind, wie Computerprogramme — sodass sie ohne komplizierte Linguistik trainiert werden konnten.
Einige Forschungen zeigen signifikante Verbesserungen bei der Verwendung von sprachspezifischeren und sprachbewussteren Tokenizern. [Rust et al. 2021] Aber die Entwicklung solcher Tokenizer erfordert Zeit, Geld und Expertise. Die Implementierung einer universellen Strategie wie BPE oder Wordpiece ist viel günstiger und einfacher.
Als Konsequenz gibt es jedoch keine Möglichkeit zu wissen, wie viele Tokens ein bestimmter Text repräsentiert, außer ihn durch einen Tokenizer laufen zu lassen und dann die Anzahl der Tokens zu zählen, die dabei herauskommen. Da die kleinste mögliche Teilsequenz eines Textes ein Buchstabe ist, kann man sicher sein, dass die Anzahl der Tokens nicht größer sein wird als die Anzahl der Zeichen (minus Leerzeichen) plus zwei.
Um eine gute Schätzung zu erhalten, müssen wir unserem Tokenizer viel Text zuführen und empirisch berechnen, wie viele Tokens wir im Durchschnitt erhalten, verglichen mit der Anzahl der Wörter oder Zeichen, die wir eingeben. Im nächsten Abschnitt werden wir einige nicht sehr systematische empirische Messungen für alle derzeit verfügbaren Jina Embeddings v2 Modelle durchführen.
tagEmpirische Schätzungen der Token-Ausgabegrößen
Für Englisch und Deutsch habe ich den Unicode-Textsegmentierungsalgorithmus (Unicode Standard Annex #29) verwendet, um Wortzählungen für Texte zu erhalten. Dieser Algorithmus wird häufig verwendet, um Textausschnitte auszuwählen, wenn Sie doppelklicken. Er ist das Nächstbeste, was es an einem universellen objektiven Wortzähler gibt.
Ich habe die polyglot-Bibliothek in Python installiert, die diesen Textsegmentierer implementiert:
pip install -U polyglot
Um die Wortzahl eines Textes zu erhalten, können Sie Code wie dieses Snippet verwenden:
from polyglot.text import Text
txt = "What is today's weather in Berlin?"
print(len(Text(txt).words))
Das Ergebnis sollte 7 sein.
Um eine Tokenzahl zu erhalten, wurden Segmente des Textes an die Tokenizer verschiedener Jina Embeddings Modelle übergeben, wie unten beschrieben, und jedes Mal habe ich zwei von der zurückgegebenen Tokenanzahl abgezogen.
tagEnglisch
(jina-embeddings-v2-small-en und jina-embeddings-v2-base-en)
Zur Berechnung von Durchschnittswerten habe ich zwei englische Textkorpora von Wortschatz Leipzig heruntergeladen, einer Sammlung frei herunterladbarer Korpora in verschiedenen Sprachen und Konfigurationen, die von der Universität Leipzig gehostet wird:
- Ein Ein-Millionen-Satz-Korpus von Nachrichtendaten in Englisch aus dem Jahr 2020 (
eng_news_2020_1M) - Ein Ein-Millionen-Satz-Korpus von englischen Wikipedia-Daten aus dem Jahr 2016 (
eng_wikipedia_2016_1M)
Beide sind auf ihrer englischen Download-Seite zu finden.
Für mehr Vielfalt habe ich auch die Hapgood-Übersetzung von Victor Hugos Les Misérables von Project Gutenberg und eine Kopie der King James Version der Bibel, übersetzt ins Englische 1611, heruntergeladen.
Für alle vier Texte habe ich die Wörter mit dem in polyglot implementierten Unicode-Segmentierer gezählt und dann die von jina-embeddings-v2-small-en erzeugten Tokens gezählt, wobei ich für jede Tokenisierungsanfrage zwei Tokens abgezogen habe. Die Ergebnisse sind wie folgt:
| Text | Wortzahl (Unicode Segmentierer) | Tokenzahl (Jina Embeddings v2 für Englisch) | Verhältnis Token zu Wörtern (auf 3 Dezimalstellen) |
|---|---|---|---|
eng_news_2020_1M | 22.825.712 | 25.270.581 | 1,107 |
eng_wikipedia_2016_1M | 24.243.607 | 26.813.877 | 1,106 |
les_miserables_en | 688.911 | 764.121 | 1,109 |
kjv_bible | 1.007.651 | 1.099.335 | 1,091 |
Die Verwendung präziser Zahlen bedeutet nicht, dass dies ein präzises Ergebnis ist. Dass Dokumente so unterschiedlicher Genres alle zwischen 9 % und 11 % mehr Tokens als Wörter aufweisen, deutet darauf hin, dass man wahrscheinlich etwa 10 % mehr Tokens als Wörter erwarten kann, gemessen am Unicode Segmenter. Textverarbeitungsprogramme zählen oft keine Satzzeichen, während der Unicode Segmenter dies tut, sodass die Wortzählungen aus Office-Software nicht unbedingt damit übereinstimmen müssen.
tagDeutsch
(jina-embeddings-v2-base-de)
Für Deutsch habe ich drei Korpora von der Wortschatz Leipzig Deutschen Seite heruntergeladen:
deu_mixed-typical_2011_1M— Eine Million Sätze aus einer ausgewogenen Mischung von Texten verschiedener Genres aus dem Jahr 2011.deu_newscrawl-public_2019_1M— Eine Million Sätze aus Nachrichtentexten von 2019.deu_wikipedia_2021_1M— Eine Million Sätze aus der deutschen Wikipedia von 2021.
Und für die Vielfalt habe ich auch alle drei Bände von Karl Marx' Kapital vom Deutschen Textarchiv heruntergeladen.
Dann bin ich nach dem gleichen Verfahren wie beim Englischen vorgegangen:
| Text | Wortzahl (Unicode Segmenter) | Token-Anzahl (Jina Embeddings v2 für Deutsch und Englisch) | Verhältnis von Tokens zu Wörtern (auf 3 Dezimalstellen) |
|---|---|---|---|
deu_mixed-typical_2011_1M | 7.924.024 | 9.772.652 | 1,234 |
deu_newscrawl-public_2019_1M | 17.949.120 | 21.711.555 | 1,210 |
deu_wikipedia_2021_1M | 17.999.482 | 22.654.901 | 1,259 |
marx_kapital | 784.336 | 1.011.377 | 1,289 |
Diese Ergebnisse haben eine größere Streuung als das rein englische Modell, deuten aber darauf hin, dass deutscher Text im Durchschnitt 20 % bis 30 % mehr Tokens als Wörter ergibt.
Englische Texte ergeben mit dem deutsch-englischen Tokenizer mehr Tokens als mit dem rein englischen:
| Text | Wortzahl (Unicode Segmenter) | Token-Anzahl (Jina Embeddings v2 für Deutsch und Englisch) | Verhältnis von Tokens zu Wörtern (auf 3 Dezimalstellen) |
|---|---|---|---|
eng_news_2020_1M | 24.243.607 | 27.758.535 | 1,145 |
eng_wikipedia_2016_1M | 22.825.712 | 25.566.921 | 1,120 |
Sie sollten erwarten, 12 % bis 15 % mehr Tokens als Wörter zu benötigen, um englische Texte mit dem zweisprachigen Deutsch/Englisch-Modell im Vergleich zum rein englischen zu embedden.
tagChinesisch
(jina-embeddings-v2-base-zh)
Chinesisch wird typischerweise ohne Leerzeichen geschrieben und hatte bis zum 20. Jahrhundert keinen traditionellen Begriff von "Wörtern". Folglich wird die Größe eines chinesischen Textes typischerweise in Zeichen (字数) gemessen. Anstatt den Unicode Segmenter zu verwenden, habe ich daher die Länge chinesischer Texte gemessen, indem ich alle Leerzeichen entfernt und dann einfach die Zeichenlänge ermittelt habe.
Ich habe drei Korpora von der chinesischen Korpus-Seite von Wortschatz Leipzig heruntergeladen:
zho_wikipedia_2018_1M— Eine Million Sätze aus der chinesischsprachigen Wikipedia, extrahiert 2018.zho_news_2007-2009_1M— Eine Million Sätze aus chinesischen Nachrichtenquellen, gesammelt von 2007 bis 2009.zho-trad_newscrawl_2011_1M— Eine Million Sätze aus Nachrichtenquellen, die ausschließlich traditionelle chinesische Zeichen (繁體字) verwenden.
Zusätzlich habe ich für mehr Vielfalt auch Die wahre Geschichte des Ah Q (阿Q正傳) verwendet, eine Novelle von Lu Xun (魯迅) aus den frühen 1920er Jahren. Ich habe die traditionelle Zeichenversion von Project Gutenberg heruntergeladen.
| Text | Zeichenzahl (字数) | Token-Anzahl (Jina Embeddings v2 für Chinesisch und Englisch) | Verhältnis von Tokens zu Zeichen (auf 3 Dezimalstellen) |
|---|---|---|---|
zho_wikipedia_2018_1M | 45.116.182 | 29.193.028 | 0,647 |
zho_news_2007-2009_1M | 44.295.314 | 28.108.090 | 0,635 |
zho-trad_newscrawl_2011_1M | 54.585.819 | 40.290.982 | 0,738 |
Ah_Q | 41.268 | 25.346 | 0,614 |
Diese Streuung der Token-zu-Zeichen-Verhältnisse ist unerwartet, und besonders der Ausreißer für das Korpus mit traditionellen Zeichen verdient weitere Untersuchung. Dennoch können wir schlussfolgern, dass man für Chinesisch weniger Token benötigt als es Zeichen im Text gibt. Je nach Inhalt kann man mit 25% bis 40% weniger rechnen.
Englische Texte in Jina Embeddings v2 für Chinesisch und Englisch ergaben ungefähr die gleiche Anzahl an Token wie im rein englischen Modell:
| Text | Wortanzahl (Unicode Segmenter) | Token-Anzahl (Jina Embeddings v2 für Chinesisch und Englisch) | Verhältnis Token zu Wörtern (auf 3 Dezimalstellen) |
|---|---|---|---|
eng_news_2020_1M | 24.243.607 | 26.890.176 | 1,109 |
eng_wikipedia_2016_1M | 22.825.712 | 25.060.352 | 1,097 |
tagToken ernst nehmen
Token sind ein wichtiges Gerüst für KI-Sprachmodelle, und die Forschung auf diesem Gebiet ist noch im Gange.
Einer der Bereiche, in denen sich KI-Modelle als revolutionär erwiesen haben, ist die Entdeckung, dass sie sehr robust gegenüber verrauschten Daten sind. Selbst wenn ein bestimmtes Modell keine optimale Tokenisierungsstrategie verwendet, kann es bei ausreichender Netzwerkgröße, genügend Daten und angemessenem Training lernen, das Richtige aus unvollkommenen Eingaben zu machen.
Folglich wird weniger Aufwand in die Verbesserung der Tokenisierung gesteckt als in andere Bereiche, aber das könnte sich ändern.
Als Nutzer von Embeddings, die man über eine API wie Jina Embeddings bezieht, kann man nicht genau wissen, wie viele Token man für eine bestimmte Aufgabe benötigt und muss möglicherweise eigene Tests durchführen, um verlässliche Zahlen zu erhalten. Aber die hier angegebenen Schätzungen – etwa 110% der Wortanzahl für Englisch, etwa 125% der Wortanzahl für Deutsch und etwa 70% der Zeichenanzahl für Chinesisch – sollten für eine grundlegende Budgetierung ausreichen.






