

Eines der lang bestehenden Probleme von KI-Modellen ist, dass neuronale Netze nicht erklären, wie sie ihre Ausgaben produzieren. Es ist nicht immer klar, wie sehr dies ein echtes Problem für künstliche Intelligenz darstellt. Wenn wir Menschen bitten, ihre Denkweise zu erklären, rationalisieren sie routinemäßig, typischerweise völlig unbewusst, und geben die plausibelsten Erklärungen für sich selbst, ohne jeden Hinweis darauf, was wirklich in ihren Köpfen vorgeht.
Wir wissen bereits, wie wir KI-Modelle dazu bringen können, plausible Antworten zu erfinden. Vielleicht ist künstliche Intelligenz den Menschen in dieser Hinsicht ähnlicher, als wir zugeben möchten.
Vor fünfzig Jahren schrieb der amerikanische Philosoph Thomas Nagel einen einflussreichen Essay mit dem Titel What Is It Like To Be A Bat? Er behauptete, dass es etwas geben muss, wie es ist, eine Fledermaus zu sein: Die Welt so zu sehen, wie eine Fledermaus sie sieht, und die Existenz so wahrzunehmen, wie eine Fledermaus es tut. Laut Nagel würden wir jedoch selbst dann, wenn wir jede erkennbare Tatsache über die Funktionsweise von Fledermausgehirnen, Fledermaussinnen und Fledermauskörpern kennen würden, immer noch nicht wissen, wie es ist, eine Fledermaus zu sein.
Die Erklärbarkeit von KI ist die gleiche Art von Problem. Wir kennen jede Tatsache über ein bestimmtes KI-Modell. Es sind nur viele endlich-präzise Zahlen, die in einer Sequenz von Matrizen angeordnet sind. Wir können trivial überprüfen, dass jede Modellausgabe das Ergebnis korrekter Arithmetik ist, aber diese Information ist als Erklärung nutzlos.
Es gibt für KI genauso wenig eine allgemeine Lösung für dieses Problem wie für Menschen. Die ColBERT-Architektur jedoch, und insbesondere wie sie "Late Interaction" als Reranker verwendet, ermöglicht es Ihnen, aussagekräftige Einblicke von Ihren Modellen darüber zu erhalten, warum es in bestimmten Fällen spezifische Ergebnisse liefert.
Dieser Artikel zeigt Ihnen, wie Late Interaction Erklärbarkeit ermöglicht, unter Verwendung des Jina-ColBERT-Modells jina-colbert-v1-en und der Matplotlib Python-Bibliothek.
tagEin kurzer Überblick über ColBERT
ColBERT wurde in Khattab & Zaharia (2020) als Erweiterung des 2018 von Google eingeführten BERT-Modells vorgestellt. Jina AIs Jina-ColBERT-Modelle basieren auf dieser Arbeit und der späteren ColBERT v2-Architektur, die in Santhanam, et al. (2021) vorgeschlagen wurde. ColBERT-Modelle können zur Erstellung von Embeddings verwendet werden, haben aber einige zusätzliche Funktionen, wenn sie als Reranking-Modell eingesetzt werden. Der Hauptvorteil ist Late Interaction, eine andere Art, das Problem der semantischen Textähnlichkeit im Vergleich zu Standard-Embedding-Modellen zu strukturieren.
tagEmbedding-Modelle
In einem traditionellen Embedding-Modell vergleichen wir zwei Texte, indem wir repräsentative Vektoren für sie erstellen, die sogenannten Embeddings, und dann diese Embeddings über Distanzmetriken wie Kosinus- oder Hamming-Distanz vergleichen. Die Quantifizierung der semantischen Ähnlichkeit von zwei Texten folgt im Allgemeinen einem gemeinsamen Verfahren.
Zunächst erstellen wir Embeddings für die beiden Texte separat. Für jeden einzelnen Text:
- Ein Tokenizer zerlegt den Text in etwa wortgroße Stücke.
- Jedes Token wird auf einen Vektor abgebildet.
- Die Token-Vektoren interagieren über das Attention-System und Faltungsschichten und fügen der Repräsentation jedes Tokens Kontextinformationen hinzu.
- Eine Pooling-Schicht transformiert diese modifizierten Token-Vektoren in einen einzelnen Embedding-Vektor.
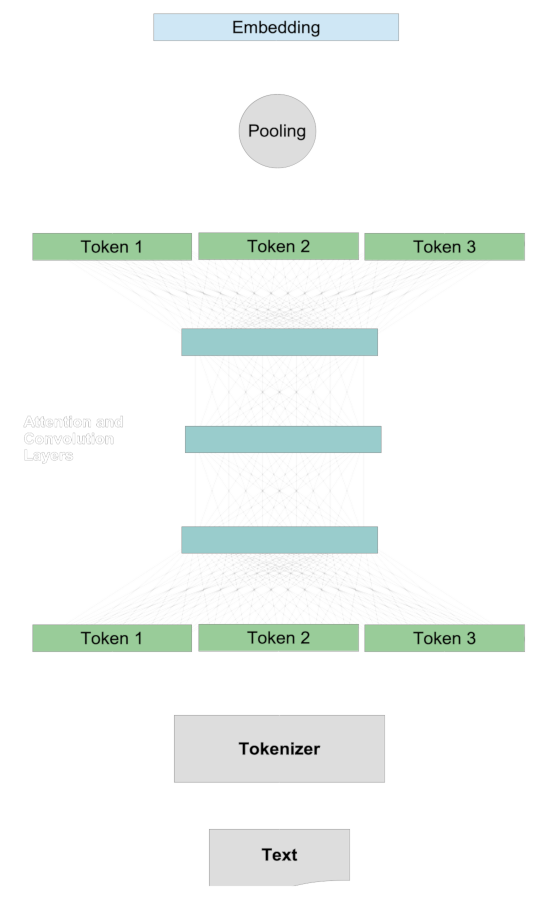
Wenn dann für jeden Text ein Embedding vorliegt, vergleichen wir sie miteinander, typischerweise mit der Kosinus-Metrik oder Hamming-Distanz.
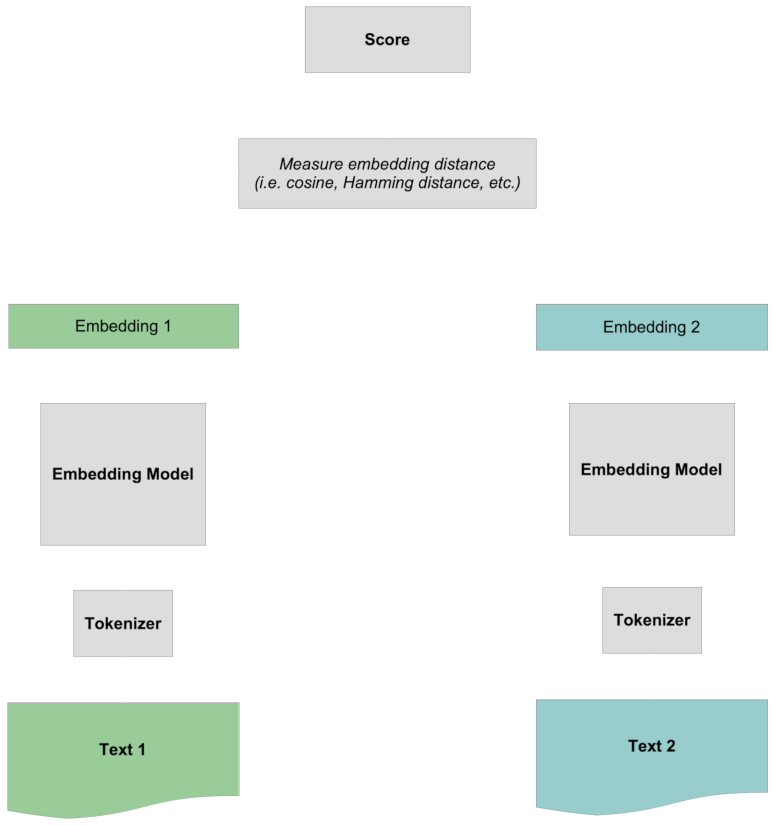
Die Bewertung erfolgt durch Vergleich der beiden vollständigen Embeddings miteinander, ohne spezifische Informationen über die Tokens. Die gesamte Interaktion zwischen Tokens erfolgt "früh", da sie stattfindet, bevor die beiden Texte miteinander verglichen werden.
tagReranking-Modelle
Reranking-Modelle arbeiten anders.
Anstatt ein Embedding für einen Text zu erstellen, nimmt es zunächst einen Text, genannt Query, und eine Sammlung anderer Texte, die wir Zieldokumente nennen, und bewertet dann jedes Zieldokument in Bezug auf den Query-Text. Diese Zahlen sind nicht normalisiert und nicht wie der Vergleich von Embeddings, aber sie sind sortierbar. Die Zieldokumente, die in Bezug auf die Query am höchsten punkten, sind nach dem Modell die Texte, die semantisch am stärksten mit der Query verwandt sind.
Schauen wir uns an, wie das konkret mit dem jina-colbert-v1-en Reranker-Modell funktioniert, unter Verwendung der Jina Reranker API und Python.
Der folgende Code ist auch in einem Notebook verfügbar, das Sie herunterladen oder in Google Colab ausführen können.
Sie sollten zuerst die neueste Version der requests-Bibliothek in Ihre Python-Umgebung installieren. Sie können dies mit folgendem Befehl tun:
pip install requests -U
Besuchen Sie als Nächstes die Jina Reranker API-Seite und holen Sie sich einen kostenlosen API-Token, der für bis zu einer Million Token Textverarbeitung gültig ist. Kopieren Sie den API-Token-Schlüssel vom unteren Ende der Seite, wie unten gezeigt:
Wir verwenden folgenden Query-Text:
- "Elephants eat 150 kg of food per day."
Und vergleichen diese Query mit drei Texten:
- "Elephants eat 150 kg of food per day."
- "Every day, the average elephant consumes roughly 150 kg of plants."
- "The rain in Spain falls mainly on the plain."
Das erste Dokument ist identisch mit der Query, das zweite ist eine Umformulierung des ersten, und der letzte Text ist völlig unzusammenhängend.
Verwenden Sie den folgenden Python-Code, um die Scores zu erhalten, wobei Sie Ihren Jina Reranker API-Token der Variable jina_api_key zuweisen:
import requests
url = "<https://api.jina.ai/v1/rerank>"
jina_api_key = "<YOUR JINA RERANKER API TOKEN HERE>"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {jina_api_key}"
}
data = {
"model": "jina-colbert-v1-en",
"query": "Elephants eat 150 kg of food per day.",
"documents": [
"Elephants eat 150 kg of food per day.",
"Every day, the average elephant consumes roughly 150 kg of food.",
"The rain in Spain falls mainly on the plain.",
],
"top_n": 3
}
response = requests.post(url, headers=headers, json=data)
for item in response.json()['results']:
print(f"{item['relevance_score']} : {item['document']['text']}")
Die Ausführung dieses Codes aus einer Python-Datei oder in einem Notebook sollte folgendes Ergebnis liefern:
11.15625 : Elephants eat 150 kg of food per day.
9.6328125 : Every day, the average elephant consumes roughly 150 kg of food.
1.568359375 : The rain in Spain falls mainly on the plain.
Die exakte Übereinstimmung hat die höchste Punktzahl, wie wir erwarten würden, während die Umformulierung die zweithöchste Punktzahl hat und ein völlig unzusammenhängender Text eine viel niedrigere Punktzahl aufweist.
tagScoring mit ColBERT
Was ColBERT-Reranking von Embedding-basierter Bewertung unterscheidet, ist, dass die Tokens der beiden Texte während des Bewertungsprozesses miteinander verglichen werden. Die beiden Texte haben nie ihre eigenen Embeddings.
Zunächst verwenden wir die gleiche Architektur wie Embedding-Modelle, um neue Repräsentationen für jedes Token zu erstellen, die Kontextinformationen aus dem Text enthalten. Dann vergleichen wir jedes Token aus der Query mit jedem Token aus dem Dokument.
Für jedes Token in der Query identifizieren wir das Token im Dokument, das die stärkste Interaktion damit hat, und summieren diese Interaktionswerte auf, um einen endgültigen numerischen Wert zu berechnen.
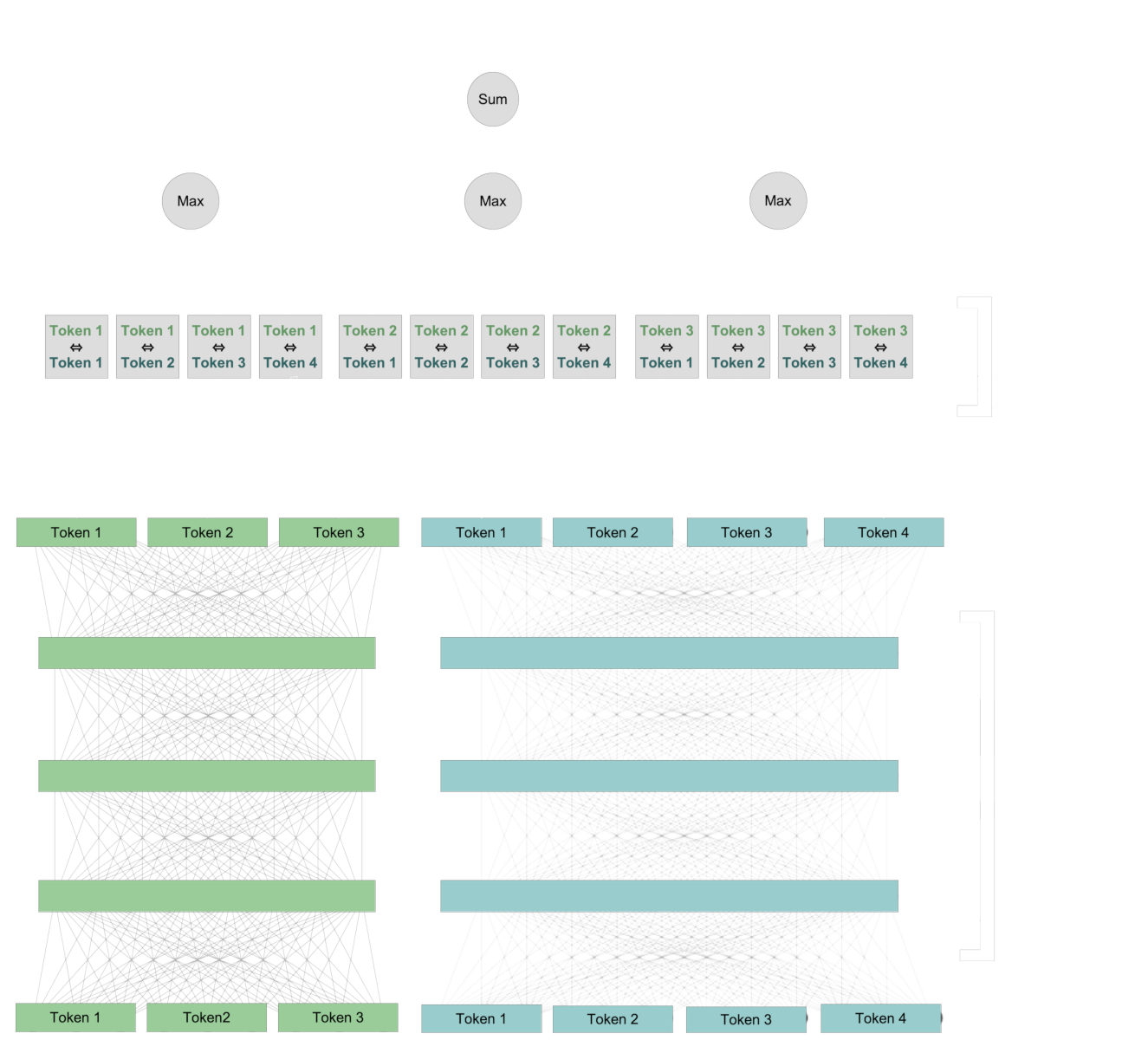
Diese Interaktion ist „spät": Die Token interagieren über die beiden Texte hinweg, wenn wir sie miteinander vergleichen. Aber denken Sie daran: Die „späte" Interaktion schließt die „frühe" Interaktion nicht aus. Die verglichenen Token-Vektorpaare enthalten bereits Informationen über ihre spezifischen Kontexte.
Dieses späte Interaktionsschema bewahrt die Token-Level-Informationen, auch wenn diese Informationen kontextspezifisch sind. Das ermöglicht uns teilweise zu sehen, wie das ColBERT-Modell seinen Score berechnet, da wir identifizieren können, welche Paare von kontextualisierten Token zum finalen Score beitragen.
tagRankings mit Heatmaps erklären
Heatmaps sind eine Visualisierungstechnik, die nützlich ist, um zu sehen, was in Jina-ColBERT bei der Erstellung von Scores passiert. In diesem Abschnitt werden wir die seaborn und matplotlib Bibliotheken verwenden, um Heatmaps aus der späten Interaktionsschicht von jina-colbert-v1-en zu erstellen und zu zeigen, wie die Query-Token mit den Zieltext-Token interagieren.
tagEinrichtung
Wir haben eine Python-Bibliotheksdatei erstellt, die den Code für den Zugriff auf das jina-colbert-v1-en Modell und die Verwendung von seaborn, matplotlib und Pillow zur Erstellung von Heatmaps enthält. Sie können diese Bibliothek direkt von GitHub herunterladen, oder das bereitgestellte Notebook auf Ihrem eigenen System oder auf Google Colab verwenden.
Installieren Sie zuerst die Anforderungen. Sie benötigen die neueste Version der requests Bibliothek in Ihrer Python-Umgebung. Wenn Sie dies noch nicht getan haben, führen Sie aus:
pip install requests -U
Installieren Sie dann die Kernbibliotheken:
pip install matplotlib seaborn torch Pillow
Laden Sie als Nächstes jina_colbert_heatmaps.py von GitHub herunter. Sie können dies über einen Webbrowser tun oder in der Kommandozeile, wenn wget installiert ist:
wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/heatmaps/jina_colbert_heatmaps.py
Mit den installierten Bibliotheken müssen wir für den Rest dieses Artikels nur noch eine Funktion deklarieren:
from jina_colbert_heatmaps import JinaColbertHeatmapMaker
def create_heatmap(query, document, figsize=None):
heat_map_maker = JinaColbertHeatmapMaker(jina_api_key=jina_api_key)
# get token embeddings for the query
query_emb = heat_map_maker.embed(query, is_query=True)
# get token embeddings for the target document
document_emb = heat_map_maker.embed(document, is_query=False)
return heat_map_maker.compute_heatmap(document_emb[0], query_emb[0], figsize)
tagErgebnisse
Nachdem wir nun Heatmaps erstellen können, lassen Sie uns einige erstellen und sehen, was sie uns sagen.
Führen Sie den folgenden Befehl in Python aus:
create_heatmap("Elephants eat 150 kg of food per day.", "Elephants eat 150 kg of food per day.")Das Ergebnis wird eine Heatmap sein, die so aussieht:
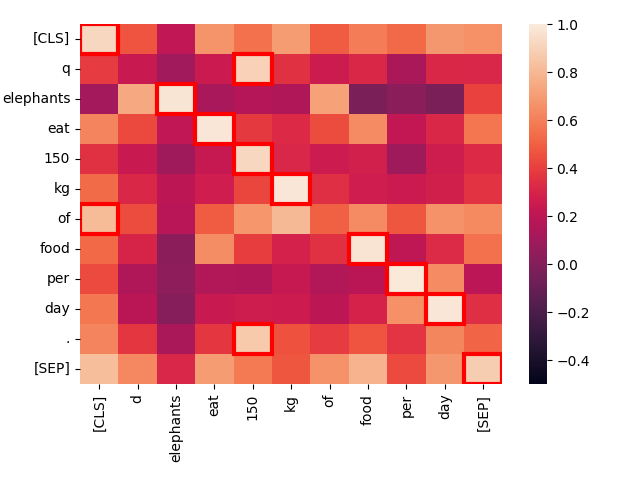
Dies ist eine Heatmap der Aktivierungslevel zwischen Token-Paaren, wenn wir zwei identische Texte vergleichen. Jedes Quadrat zeigt die Interaktion zwischen zwei Token, jeweils eines aus jedem Text. Die zusätzlichen Token [CLS] und [SEP] kennzeichnen jeweils den Anfang und das Ende des Textes, und q und d werden direkt nach dem [CLS]-Token in Queries bzw. Zieldokumenten eingefügt. Dies ermöglicht es dem Modell, Interaktionen zwischen Token und dem Anfang und Ende von Texten zu berücksichtigen, erlaubt aber auch Token-Repräsentationen, die sensitiv dafür sind, ob sie sich in Queries oder Zielen befinden.
Je heller das Quadrat, desto mehr Interaktion gibt es zwischen den beiden Token, was auf eine semantische Verwandtschaft hinweist. Der Interaktionsscore jedes Token-Paars liegt im Bereich von -1,0 bis 1,0. Die rot umrahmten Quadrate sind diejenigen, die zum finalen Score beitragen: Für jedes Token in der Query ist sein höchstes Interaktionslevel mit einem beliebigen Dokument-Token der Wert, der zählt.
Die besten Übereinstimmungen — die hellsten Stellen — und die rot umrahmten Maximalwerte liegen fast alle genau auf der Diagonale und haben eine sehr starke Interaktion. Die einzigen Ausnahmen sind die „technischen" Token [CLS], q und d sowie das Wort „of", das ein hochfrequentes „Stoppwort" im Englischen ist und sehr wenig eigenständige Information trägt.
Lassen Sie uns einen strukturell ähnlichen Satz nehmen — "Cats eat 50 g of food per day." — und sehen, wie die Token darin interagieren:
create_heatmap("Elephants eat 150 kg of food per day.", "Cats eat 50 g of food per day.")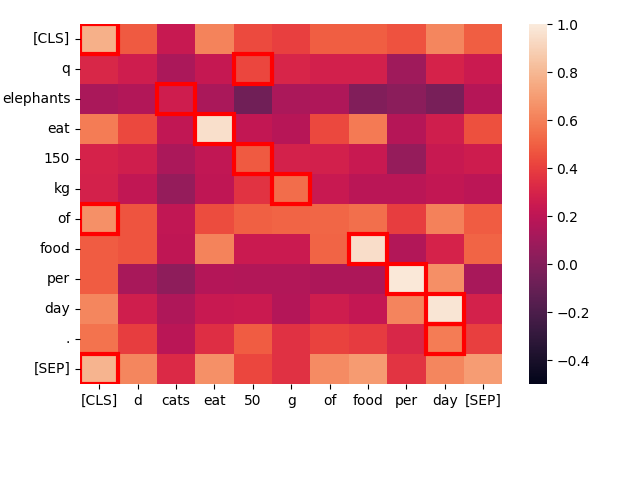
Auch hier liegen die besten Übereinstimmungen hauptsächlich auf der Diagonale, da die Wörter häufig dieselben sind und die Satzstruktur fast identisch ist. Selbst „cats" und „elephants" stimmen aufgrund ihrer gemeinsamen Kontexte überein, wenn auch nicht sehr gut.
Je weniger ähnlich der Kontext ist, desto schlechter ist die Übereinstimmung. Betrachten wir den Text "Employees eat at the company canteen."
create_heatmap("Elephants eat 150 kg of food per day.", "Employees eat at the company canteen.")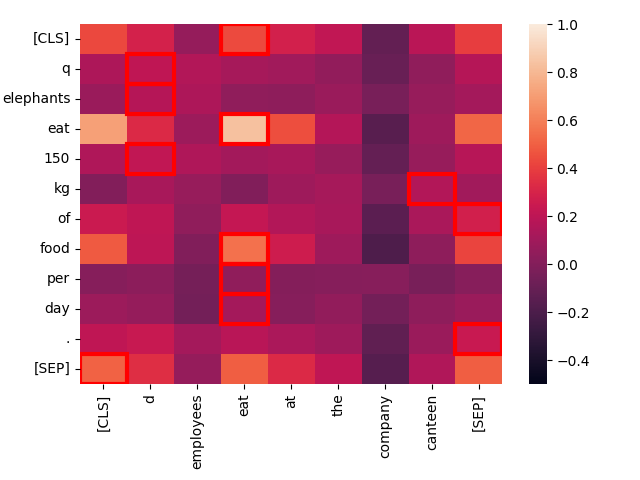
Obwohl strukturell ähnlich, ist die einzige starke Übereinstimmung hier zwischen den beiden Instanzen von „eat". Thematisch sind dies sehr unterschiedliche Sätze, auch wenn ihre Struktur sehr parallel ist.
Wenn wir die Dunkelheit der Farben in den rot umrahmten Quadraten betrachten, können wir sehen, wie das Modell sie als Übereinstimmungen für "Elephants eat 150 kg of food per day" einstufen würde, und jina-colbert-v1-en bestätigt diese Intuition:
| Score | Text |
|---|---|
| 11.15625 | Elephants eat 150 kg of food per day. |
| 8.3671875 | Cats eat 50 g of food per day. |
| 3.734375 | Employees eat at the company canteen. |
Vergleichen wir nun "Elephants eat 150 kg of food per day." mit einem Satz, der im Wesentlichen die gleiche Bedeutung hat, aber anders formuliert ist: "Every day, the average elephant consumes roughly 150 kg of food."
create_heatmap("Elephants eat 150 kg of food per day.", "Every day, the average elephant consumes roughly 150 kg of food.")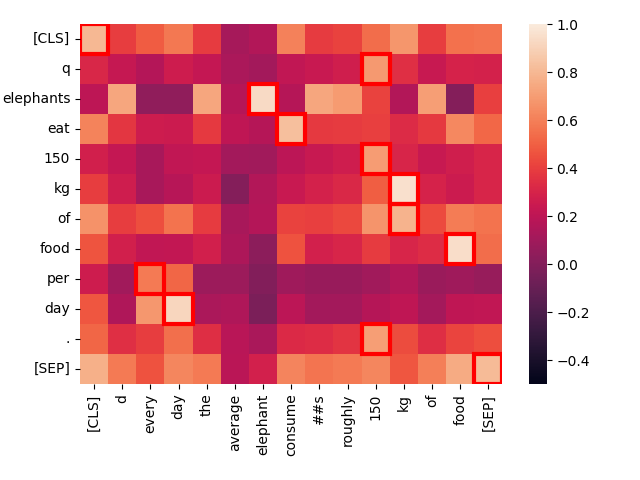
Beachten Sie die starke Interaktion zwischen "eat" im ersten Satz und "consume" im zweiten. Der Unterschied im Vokabular hindert Jina-ColBERT nicht daran, die gemeinsame Bedeutung zu erkennen.
Auch "every day" entspricht stark "per day", obwohl sie sich an völlig unterschiedlichen Stellen befinden. Nur das niedrigwertige Wort "of" ist eine anomale Nicht-Übereinstimmung.
Vergleichen wir nun dieselbe Anfrage mit einem völlig unzusammenhängenden Text: "The rain in Spain falls mainly on the plain."
create_heatmap("Elephants eat 150 kg of food per day.", "The rain in Spain falls mainly on the plain.")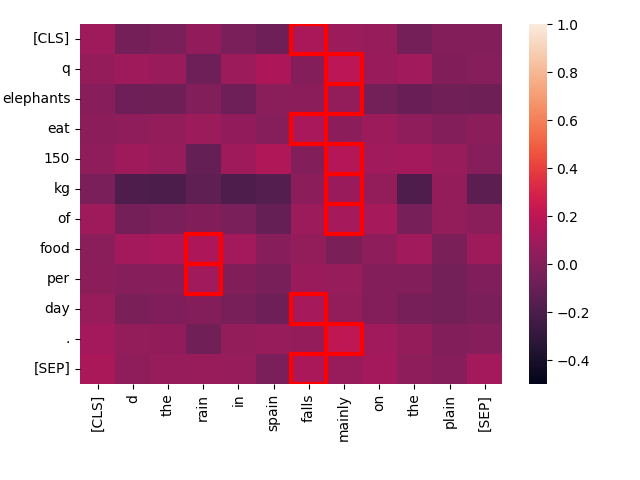
Sie können sehen, dass die "beste Übereinstimmung" Interaktionen für dieses Paar viel niedriger ausfallen und es sehr wenig Interaktion zwischen den Wörtern der beiden Texte gibt. Intuitiv würden wir erwarten, dass es im Vergleich zu "Every day, the average elephant consumes roughly 150 kg of food" schlecht abschneidet, und jina-colbert-v1-en stimmt dem zu:
| Score | Text |
|---|---|
| 9.6328125 | Every day, the average elephant consumes roughly 150 kg of food. |
| 1.568359375 | The rain in Spain falls mainly on the plain. |
tagLange Texte
Dies sind Beispiele zur Demonstration der Funktionsweise von ColBERT-Style Reranker-Modellen. In Information-Retrieval-Kontexten, wie bei der Retrieval-Augmented Generation, sind Anfragen üblicherweise kurze Texte, während die zu vergleichenden Kandidatendokumente länger sind, oft so lang wie das Eingabe-Kontextfenster des Modells.
Jina-ColBERT-Modelle unterstützen alle 8192 Token-Eingabekontexte, was etwa 16 Standardseiten einzeilig geschriebenem Text entspricht.
Wir können auch für diese asymmetrischen Fälle Heatmaps erstellen. Nehmen wir zum Beispiel den ersten Abschnitt der Wikipedia-Seite über Indische Elefanten:
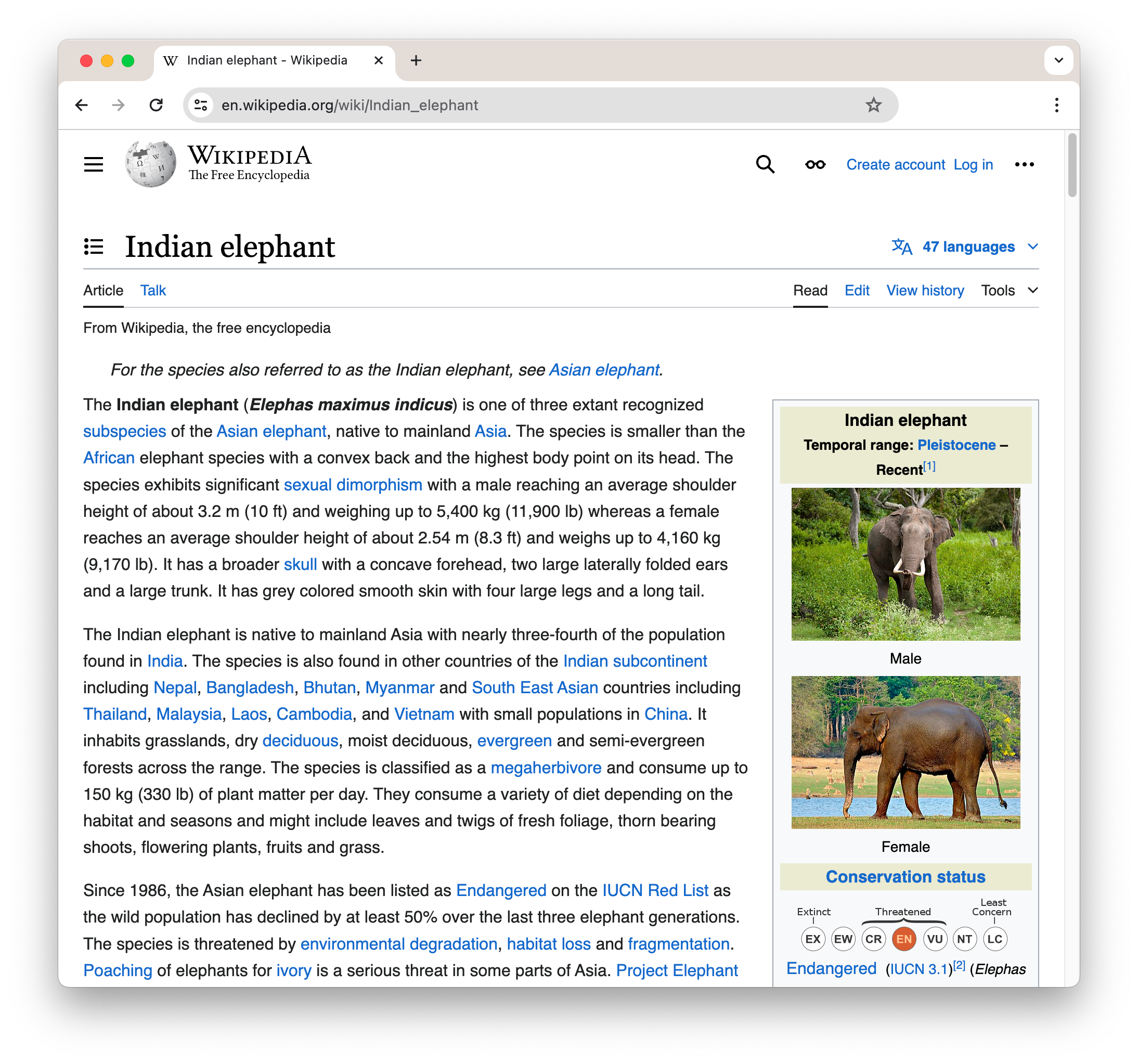
Um diesen Text als reinen Text zu sehen, wie er an jina-colbert-v1-en übergeben wird, klicken Sie diesen Link.
Dieser Text ist 364 Wörter lang, daher wird unsere Heatmap nicht sehr quadratisch aussehen:
create_heatmap("Elephants eat 150 kg of food per day.", wikipedia_elephants, figsize=(50,7))
Wir sehen, dass "elephants" an vielen Stellen im Text übereinstimmt. Das ist bei einem Text über Elefanten nicht überraschend. Aber wir können auch einen Bereich erkennen, wo es eine viel stärkere Interaktion gibt:
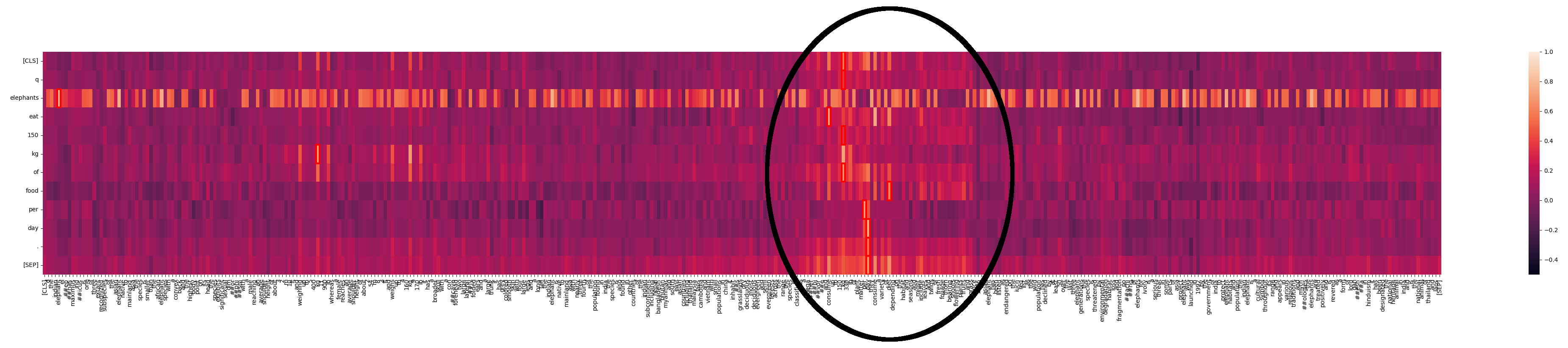
Was passiert hier? Mit Jina-ColBERT können wir den Teil des längeren Textes finden, dem dies entspricht. Es stellt sich heraus, dass es sich um den vierten Satz des zweiten Absatzes handelt:
The species is classified as a megaherbivore and consume up to 150 kg (330 lb) of plant matter per day.
Dies enthält die gleiche Information wie im Anfragetext. Wenn wir uns die Heatmap nur für diesen Satz ansehen, können wir die starken Übereinstimmungen erkennen:
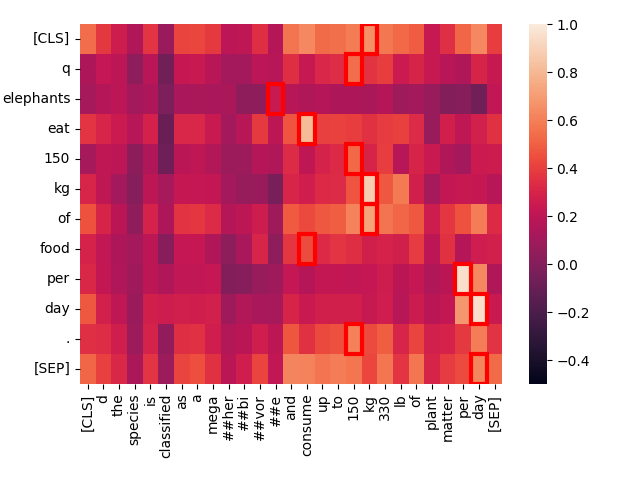
Jina-ColBERT bietet Ihnen die Möglichkeit, genau zu sehen, welche Bereiche in einem langen Text für die Übereinstimmung mit der Anfrage verantwortlich waren. Dies führt zu besserem Debugging, aber auch zu größerer Erklärbarkeit. Es braucht keine Komplexität, um zu verstehen, wie eine Übereinstimmung zustande kommt.
tagKI-Ergebnisse mit Jina-ColBERT erklären
Embeddings sind eine Kerntechnologie in der modernen KI. Fast alles, was wir tun, basiert auf der Idee, dass komplexe, lernbare Beziehungen in Eingabedaten in der Geometrie hochdimensionaler Räume ausgedrückt werden können. Allerdings ist es für Menschen sehr schwierig, räumliche Beziehungen in Tausenden bis Millionen von Dimensionen zu verstehen.
ColBERT ist ein Schritt zurück von dieser Abstraktionsebene. Es ist keine vollständige Antwort auf das Problem der Erklärung dessen, was ein KI-Modell tut, aber es zeigt uns direkt, welche Teile unserer Daten für unsere Ergebnisse verantwortlich sind.
Manchmal muss KI eine Black Box sein. Die riesigen Matrizen, die die ganze schwere Arbeit leisten, sind zu groß, als dass ein Mensch sie im Kopf behalten könnte. Aber die ColBERT-Architektur lässt ein wenig Licht in die Box scheinen und zeigt, dass mehr möglich ist.
Das Jina-ColBERT-Modell ist derzeit nur für Englisch verfügbar (jina-colbert-v1-en), aber weitere Sprachen und Anwendungskontexte sind in Vorbereitung. Diese Modellreihe, die nicht nur modernste Informationssuche durchführt, sondern Ihnen auch sagen kann, warum etwas übereinstimmt, demonstriert Jina AIs Engagement, KI-Technologien sowohl zugänglich als auch nützlich zu machen.





