


Spät in der Nacht findet ein Polizist einen betrunkenen Mann, der auf Händen und Knien unter einer Straßenlaterne herumkriecht. Der Betrunkene erklärt dem Polizisten, er suche seine Brieftasche. Als der Polizist fragt, ob er sich sicher sei, dass er die Brieftasche hier verloren habe, antwortet der Mann, dass er sie wahrscheinlich auf der anderen Straßenseite verloren habe. Warum suchen Sie dann hier? fragt der verwirrte Polizist. Weil hier das Licht besser ist, erklärt der Betrunkene.
David H. Friedman, Why Scientific Studies Are So Often Wrong: The Streetlight Effect, Discover magazine, Dez. 2010
Benchmarks sind ein zentraler Bestandteil moderner Machine Learning-Praktiken und das schon seit einiger Zeit, aber sie haben ein sehr ernstes Problem: Wir können nicht feststellen, ob unsere Benchmarks überhaupt etwas Nützliches messen.
Dies ist ein großes Problem, und dieser Artikel wird einen Teil einer Lösung vorstellen: Den AIR-Bench. Dieses gemeinsame Projekt mit der Beijing Academy of Artificial Intelligence ist ein neuartiger Ansatz für KI-Metriken, der die Qualität und Nützlichkeit unserer Benchmarks verbessern soll.


tagDer Laterneneffekt
Wissenschaftliche und operative Forschung legt viel Wert auf Messungen, aber Messungen sind keine einfache Sache. In einer Gesundheitsstudie möchten Sie vielleicht wissen, ob ein Medikament oder eine Behandlung die Empfänger gesünder gemacht, ihr Leben verlängert oder ihren Zustand in irgendeiner Weise verbessert hat. Aber Gesundheit und verbesserte Lebensqualität sind schwer direkt zu messen, und es kann Jahrzehnte dauern, um herauszufinden, ob eine Behandlung jemandes Leben verlängert hat.
Also verwenden Forscher Proxys. In einer Gesundheitsstudie könnte das etwa körperliche Kraft, reduzierte Schmerzen, gesenkter Blutdruck oder eine andere Variable sein, die sich leicht messen lässt. Eines der Probleme bei der Gesundheitsforschung ist, dass der Proxy möglicherweise nicht wirklich auf das bessere Gesundheitsergebnis hinweist, das Sie von einem Medikament oder einer Behandlung erwarten.
Eine Messung ist ein Proxy für etwas Nützliches, das Ihnen wichtig ist. Sie können diese Sache vielleicht nicht messen, also messen Sie etwas anderes, etwas, das Sie messen können und von dem Sie Gründe haben zu glauben, dass es mit der nützlichen Sache korreliert, die Sie wirklich interessiert.
Der Fokus auf Messungen war eine wichtige Entwicklung der operativen Forschung des 20. Jahrhunderts und hatte einige tiefgreifende und positive Auswirkungen. Total Quality Management, eine Reihe von Doktrinen, denen Japans Aufstieg zur wirtschaftlichen Dominanz in den 1980er Jahren zugeschrieben wird, dreht sich fast vollständig um die kontinuierliche Messung von Proxy-Variablen und die Optimierung von Praktiken auf dieser Basis.
Aber ein Fokus auf Messungen birgt einige bekannte, große Probleme:
- Eine Messung kann aufhören, ein guter Proxy zu sein, wenn Sie Entscheidungen darauf basieren.
- Es gibt oft Möglichkeiten, eine Messung aufzublähen, die nichts verbessern, was zur Möglichkeit des Betrugs führt oder zum Glauben, dass man Fortschritte macht, indem man Dinge tut, die nicht helfen.
Einige Menschen glauben, dass die meiste medizinische Forschung einfach falsch sein könnte, teilweise wegen dieses Problems. Die Diskrepanz zwischen den Dingen, die man messen kann, und den tatsächlichen Zielen ist einer der Gründe, die für das Desaster des amerikanischen Kriegs in Vietnam genannt werden.
Dies wird manchmal als "Laterneneffekt" bezeichnet, nach Geschichten wie der am Anfang dieser Seite, vom Betrunkenen, der etwas nicht dort sucht, wo er es verloren hat, sondern wo das Licht besser ist. Eine Proxy-Messung ist wie das Suchen dort, wo Licht ist, weil kein Licht auf der Sache ist, die wir sehen wollen.
In der technischeren Literatur wird der "Laterneneffekt" typischerweise mit Goodharts Gesetz in Verbindung gebracht, das auf die Kritik des britischen Ökonomen Charles Goodhart an der Thatcher-Regierung zurückgeht, die viel Wert auf Proxy-Messungen des Wohlstands legte. Goodharts Gesetz hat mehrere Formulierungen, aber die unten stehende ist die am häufigsten zitierte:
[J]ede Messung, die zum Ziel wird, wird zu einer schlechten Messung[…]
Keith Hoskins, 1996 The 'awful idea of accountability': inscribing people into the measurement of objects.00s
In der KI ist ein berühmtes Beispiel dafür die BLEU-Metrik, die in der maschinellen Übersetzungsforschung verwendet wird. BLEU wurde 2001 bei IBM entwickelt und war ein entscheidender Faktor im Boom der maschinellen Übersetzung der 00er Jahre. Sobald es einfach war, Ihrem System eine Bewertung zu geben, konnten Sie daran arbeiten, es zu verbessern. Und die BLEU-Scores verbesserten sich kontinuierlich. Um 2010 war es fast unmöglich, eine Forschungsarbeit über maschinelle Übersetzung in einer Zeitschrift oder Konferenz zu veröffentlichen, wenn sie nicht den State-of-the-Art BLEU-Score übertraf, egal wie innovativ die Arbeit war oder wie gut sie ein spezifisches Problem löste, das andere Systeme schlecht handhabten.
Der einfachste Weg, auf eine Konferenz zu kommen, war, einen kleinen Weg zu finden, die Parameter Ihres Modells zu optimieren, einen BLEU-Score zu erhalten, der geringfügig höher war als der von Google Translate, und dann einzureichen. Diese Ergebnisse waren im Wesentlichen nutzlos. Schon das Testen mit einigen neuen Texten zeigte, dass sie selten besser und häufig schlechter waren als der State-of-the-Art.
Anstatt BLEU zu verwenden, um den Fortschritt in der maschinellen Übersetzung zu evaluieren, wurde das Erreichen eines besseren BLEU-Scores zum Ziel. Sobald das geschah, hörte es auf, ein nützlicher Weg zur Evaluierung des Fortschritts zu sein.
tagSind unsere KI-Benchmarks gute Proxys?
Der am häufigsten verwendete Benchmark für Embedding-Modelle ist der MTEB-Testset, der aus 56 spezifischen Tests besteht. Diese werden nach Kategorie und insgesamt gemittelt, um eine Sammlung klassenspezifischer Scores zu erstellen. Zum Zeitpunkt des Schreibens sieht die Spitze der MTEB-Rangliste so aus:
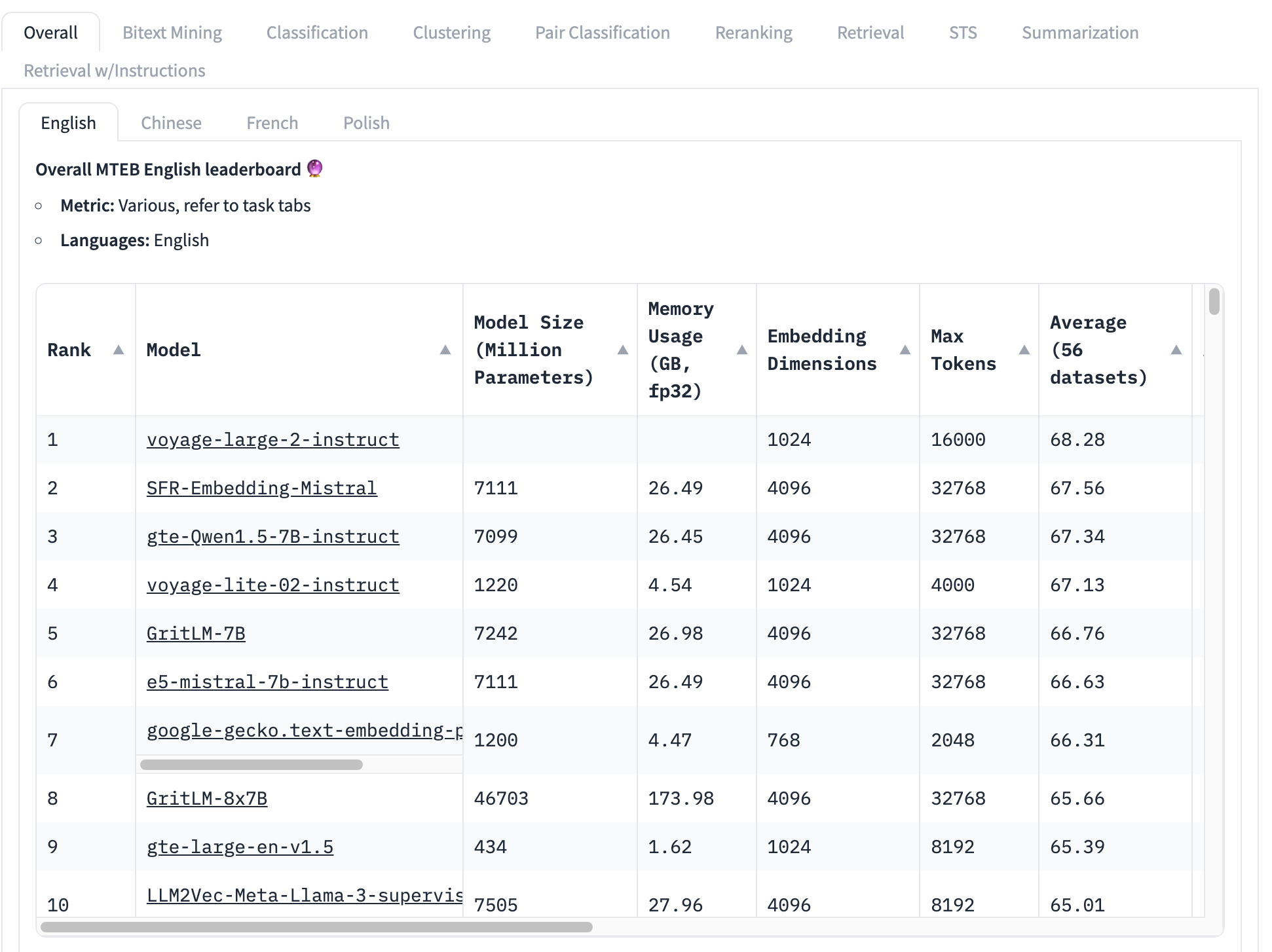
Das bestplatzierte Embedding-Modell hat einen Gesamtdurchschnittsscore von 68,28, das nächsthöhere 67,56. Es ist sehr schwierig, wenn man diese Tabelle betrachtet, zu wissen, ob das ein großer Unterschied ist oder nicht. Wenn es ein kleiner Unterschied ist, könnten andere Faktoren wichtiger sein als welches Modell den höchsten Score hat:
- Modellgröße: Modelle haben unterschiedliche Größen, die verschiedene Rechenressourcenanforderungen widerspiegeln. Kleine Modelle laufen schneller, mit weniger Speicher und benötigen weniger teure Hardware. Wir sehen in dieser Top-10-Liste Modelle von 434 Millionen bis über 46 Milliarden Parameter – ein 100-facher Unterschied!
- Embedding-Größe: Embedding-Dimensionen variieren. Kleinere Dimensionalität bedeutet, dass Embedding-Vektoren weniger Speicher und Speicherplatz verbrauchen und Vektorvergleiche (der Kernnutzen von Embeddings) viel schneller sind. In dieser Liste sehen wir Embedding-Dimensionen von 768 bis 4096 – nur ein fünffacher Unterschied, aber dennoch signifikant beim Aufbau kommerzieller Anwendungen.
- Kontext-Eingabefenstergröße: Kontextfenster variieren sowohl in Größe als auch Qualität, von 2048 Tokens bis 32768. Darüber hinaus verwenden verschiedene Modelle unterschiedliche Ansätze zur Positionskodierung und Eingabeverwaltung, was Verzerrungen zugunsten bestimmter Eingabeteile erzeugen kann.
Kurz gesagt, der Gesamtdurchschnitt ist eine sehr unvollständige Methode, um zu bestimmen, welches Embedding-Modell das beste ist.
Selbst wenn wir uns aufgabenspezifische Scores ansehen, wie die unten für Retrieval, stehen wir vor denselben Problemen. Egal wie hoch der Score eines Modells bei dieser Testreihe ist, gibt es keine Möglichkeit zu wissen, welche Modelle für Ihren speziellen Anwendungsfall am besten geeignet sind.
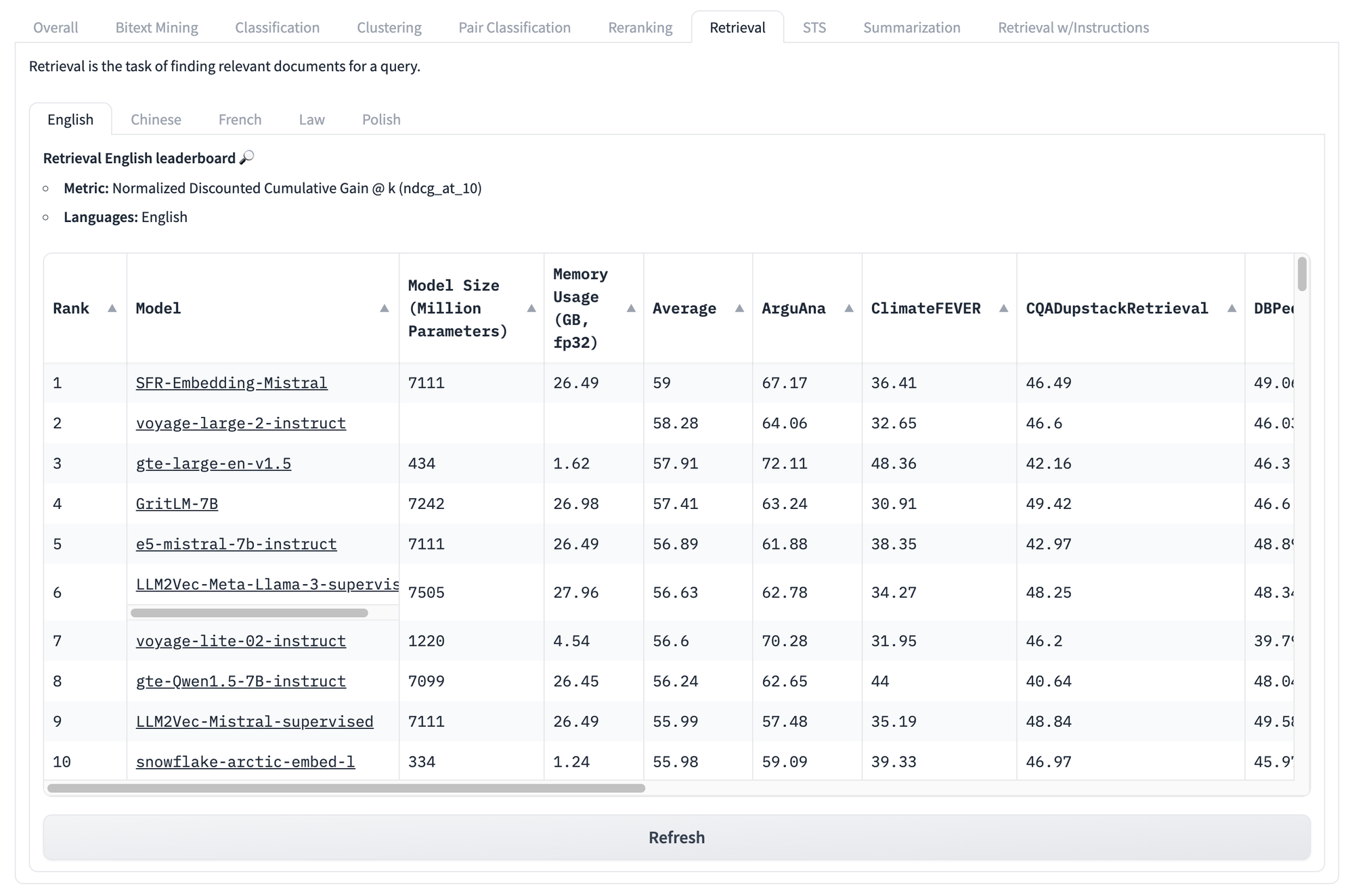
Aber das ist noch nicht das Ende der Probleme mit solchen Benchmarks.
Die Haupterkenntnis des Goodhartschen Gesetzes ist, dass eine Metrik immer manipuliert werden kann, oft auch unbeabsichtigt. Zum Beispiel bestehen MTEB-Benchmarks aus Daten öffentlicher Quellen, die wahrscheinlich in Ihren Trainingsdaten enthalten sind. Wenn Sie nicht gezielt daran arbeiten, Benchmark-Daten aus Ihrem Training zu entfernen, werden Ihre Benchmark-Ergebnisse statistisch unzuverlässig sein.
Es gibt keine einfache, umfassende Lösung. Ein Benchmark ist ein Proxy, und wir können nie sicher sein, ob er das widerspiegelt, was wir wissen möchten, aber nicht direkt messen können.
Wir sehen jedoch drei Kernprobleme bei KI-Benchmarks, die wir abschwächen können:
- Benchmarks sind von Natur aus statisch: Die gleichen Aufgaben, mit den gleichen Texten.
- Benchmarks sind generisch: Sie sind wenig aussagekräftig für reale Szenarien.
- Benchmarks sind unflexibel: Sie können nicht auf verschiedene Anwendungsfälle reagieren.
KI schafft solche Probleme, bietet aber manchmal auch Lösungen. Wir glauben, dass wir KI-Modelle nutzen können, um diese Probleme anzugehen, zumindest was KI-Benchmarks betrifft.
tagKI mit KI benchmarken: AIR-Bench
AIR-Bench ist Open Source und unter der MIT-Lizenz verfügbar. Sie können den Code in seinem GitHub-Repository einsehen oder herunterladen.
 AIR-Bench
AIR-BenchtagWas macht es?
AIR-Bench bringt wichtige Funktionen für KI-Benchmarking:
- Spezialisierung für Retrieval und RAG-Anwendungen
Dieser Benchmark ist auf realistische Information Retrieval-Anwendungen und Retrieval-Augmented Generation Pipelines ausgerichtet. - Domain- und Sprachflexibilität
AIR macht es viel einfacher, Benchmarks aus domänenspezifischen Daten oder für eine andere Sprache oder sogar aus Ihren eigenen aufgabenspezifischen Daten zu erstellen. - Automatisierte Datengenerierung
AIR-Bench generiert Testdaten und der Datensatz wird regelmäßig aktualisiert, wodurch das Risiko von Datenlecks reduziert wird.
tagAIR-Bench Leaderboard auf HuggingFace
Wir betreiben ein Leaderboard, ähnlich dem MTEB-Leaderboard, für die aktuelle Version der AIR-Bench-generierten Aufgaben. Wir werden die Benchmarks regelmäßig neu generieren, neue hinzufügen und die Abdeckung auf mehr KI-Modelle erweitern.

tagWie funktioniert es?
Die Kernidee des AIR-Ansatzes ist, dass wir Large Language Models (LLMs) nutzen können, um neue Texte und Aufgaben zu generieren, die nicht in irgendeinem Trainingsdatensatz sein können.
AIR-Bench nutzt die kreativen Fähigkeiten von LLMs, indem es sie ein Szenario durchspielen lässt. Der Benutzer wählt eine Dokumentensammlung – eine reale, die möglicherweise Teil der Trainingsdaten einiger Modelle ist – und stellt sich dann einen Benutzer mit einer definierten Rolle und eine Situation vor, in der dieser die Dokumentensammlung nutzen müsste.

Dann wählt der Benutzer ein Dokument aus dem Korpus aus und übergibt es zusammen mit dem Benutzerprofil und der Situationsbeschreibung an das LLM. Das LLM wird aufgefordert, Anfragen zu erstellen, die für diesen Benutzer und diese Situation angemessen sind und die dieses Dokument finden sollten.
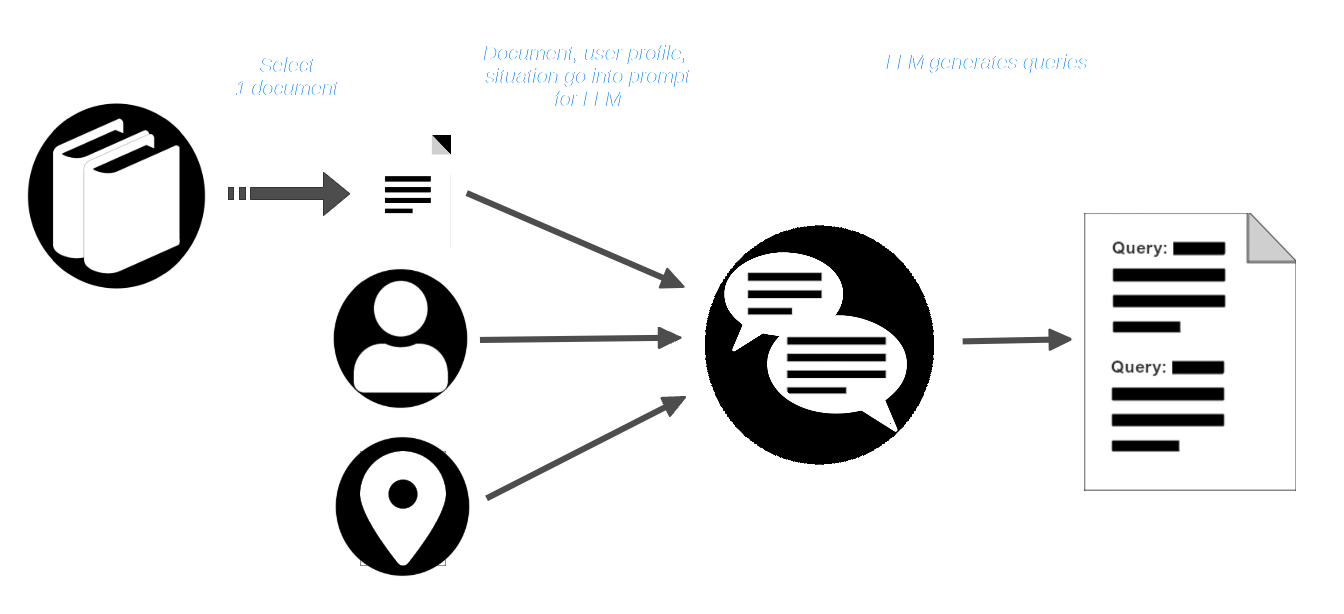
Die AIR-Bench-Pipeline fordert dann das LLM mit dem Dokument und der Anfrage auf und erstellt synthetische Dokumente, die dem bereitgestellten Dokument ähnlich sind, aber nicht zur Anfrage passen sollten.
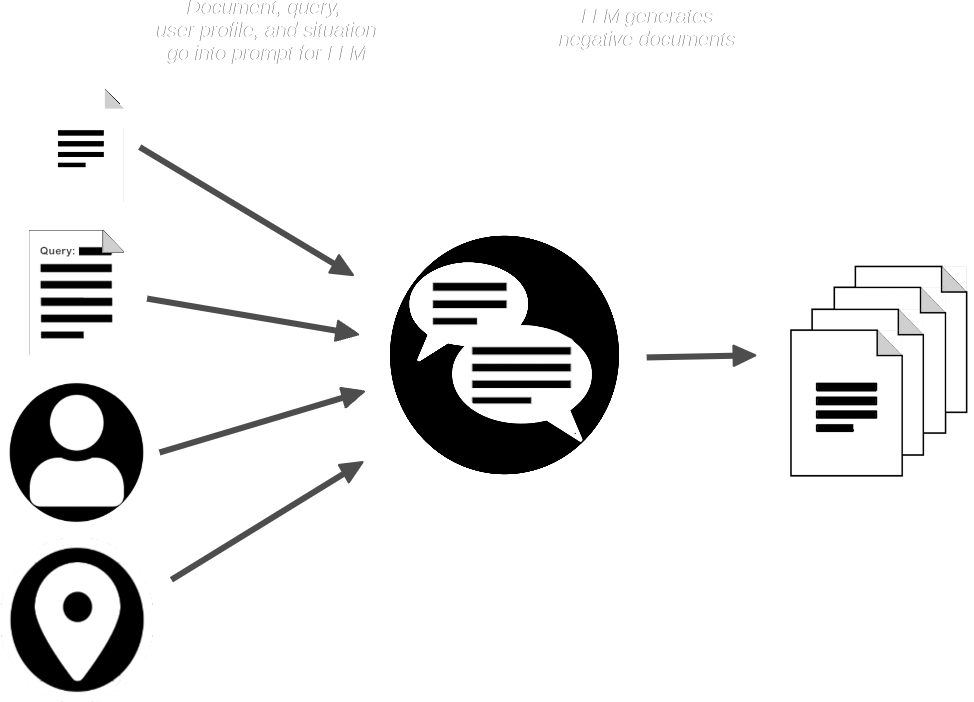
Wir haben jetzt:
- Eine Sammlung von Anfragen
- Ein passendes reales Dokument für jede Anfrage
- Eine kleine Sammlung von erwarteten nicht passenden synthetischen Dokumenten
AIR-Bench führt die synthetischen Dokumente mit der Sammlung realer Dokumente zusammen und verwendet dann ein oder mehrere Embedding- und Reranker-Modelle, um zu überprüfen, ob die Anfragen die passenden Dokumente auffinden sollten. Es verwendet auch das LLM, um zu überprüfen, ob jede Anfrage für die Dokumente relevant ist, die sie auffinden soll.
Weitere Details zu diesem KI-zentrierten Generierungs- und Qualitätskontrollprozess finden Sie in der Dokumentation zur Datengenerierung im AIR-Bench Repository auf GitHub.
AIR-BenchDas Ergebnis ist eine Sammlung hochwertiger Query-Match-Paare und ein semi-synthetischer Datensatz, gegen den diese ausgeführt werden können. Selbst wenn die ursprüngliche echte Dokumentensammlung Teil des Trainings war, sind die hinzugefügten synthetischen Dokumente und die Queries selbst neue, noch nie gesehene Daten, von denen es zuvor nicht lernen konnte.
tagDomänenspezifische Benchmarks und realitätsbasiertes Testen
Die Synthese von Queries und Dokumenten verhindert nicht nur das Durchsickern von Benchmark-Daten ins Training, sondern trägt auch erheblich zur Lösung des Problems generischer Benchmarks bei.
Indem AIR-Bench LLMs mit ausgewählten Daten, einem Benutzerprofil und einem Szenario versorgt, wird es sehr einfach, Benchmarks für bestimmte Anwendungsfälle zu erstellen. Durch die Konstruktion von Queries für einen spezifischen Benutzertyp und ein spezifisches Nutzungsszenario kann AIR-Bench Testabfragen erzeugen, die der realen Nutzung näher kommen als traditionelle Benchmarks. Die begrenzte Kreativität und Vorstellungskraft eines LLM mag ein reales Szenario nicht vollständig abbilden, ist aber dennoch besser als ein statischer Testdatensatz aus für Forscher verfügbaren Daten.
Als Nebenprodukt dieser Flexibilität unterstützt AIR-Bench alle Sprachen, die GPT-4 unterstützt.
Darüber hinaus konzentriert sich AIR-Bench speziell auf realistische KI-basierte Informationsabfrage, die bei weitem häufigste Anwendung von Embedding-Modellen. Es liefert keine Bewertungen für andere Arten von Aufgaben wie Clustering oder Klassifizierung.
tagDie AIR-Bench Distribution
AIR-Bench steht zum Download, zur Nutzung und zur Modifikation über sein GitHub Repository zur Verfügung.
AIR-BenchAIR-Bench unterstützt zwei Arten von Benchmarks:
- Eine Informationsabruf-Aufgabe, die auf der Bewertung des korrekten Abrufs von Dokumenten basiert, die für bestimmte Queries relevant sind.
- Eine "Long Document"-Aufgabe, die den Informationsabruf-Teil einer Retrieval-Augmented Generation Pipeline nachahmt.
Wir haben auch eine Reihe von Benchmarks vorgeneriert, in Englisch und Chinesisch, zusammen mit den Skripten zu ihrer Generierung als praktische Beispiele für die Verwendung von AIR-Bench. Diese nutzen Sätze von leicht verfügbaren Daten.
Zum Beispiel haben wir für eine Auswahl von 6.738.498 englischen Wikipedia-Seiten 1.727 Queries generiert, die 4.260 Dokumente matchen, plus weitere 7.882 synthetische nicht-matchende, aber ähnliche Dokumente. Wir bieten konventionelle Informationsabruf-Benchmarks für acht englischsprachige und sechs chinesische Datensätze an. Für die "Long Document"-Aufgaben stellen wir fünfzehn Benchmarks zur Verfügung, alle in Englisch.
Die vollständige Liste und weitere Details finden Sie auf der Available Tasks-Seite im AIR-Bench Repository auf GitHub.
AIR-BenchtagMitmachen
Der AIR-Benchmark wurde als Werkzeug für die Search Foundations Community entwickelt, damit engagierte Nutzer Benchmarks erstellen können, die besser zu ihren Bedürfnissen passen. Wenn Ihre Tests Aufschluss über Ihre Anwendungsfälle geben, informieren sie auch uns, sodass wir Produkte entwickeln können, die Ihren Anforderungen besser gerecht werden.
