



Die multimodale Suche, die Text und Bilder zu einem nahtlosen Sucherlebnis verbindet, hat dank Modellen wie OpenAIs CLIP an Bedeutung gewonnen. Diese Modelle überbrücken effektiv die Lücke zwischen visuellen und textuellen Daten und ermöglichen es uns, Bilder mit relevantem Text und umgekehrt zu verbinden.
Während CLIP und ähnliche Modelle leistungsstark sind, haben sie bemerkenswerte Einschränkungen, insbesondere bei der Verarbeitung längerer Texte oder beim Umgang mit komplexen textuellen Beziehungen. Hier kommt jina-clip-v1 ins Spiel.
Entwickelt zur Bewältigung dieser Herausforderungen bietet jina-clip-v1 ein verbessertes Textverständnis bei gleichzeitiger Beibehaltung robuster Text-Bild-Matching-Fähigkeiten. Es bietet eine optimierte Lösung für Anwendungen, die beide Modalitäten nutzen, vereinfacht den Suchprozess und macht es überflüssig, zwischen separaten Modellen für Text und Bilder zu jonglieren.
In diesem Beitrag werden wir untersuchen, was jina-clip-v1 für multimodale Suchanwendungen bringt und Experimente vorstellen, die zeigen, wie es sowohl die Genauigkeit als auch die Vielfalt der Ergebnisse durch integrierte Text- und Bild-Embeddings verbessert.
tagWas ist CLIP?
CLIP (Contrastive Language–Image Pretraining) ist eine von OpenAI entwickelte KI-Modellarchitektur, die Text und Bilder durch das Lernen gemeinsamer Repräsentationen verbindet. CLIP ist im Wesentlichen ein Textmodell und ein Bildmodell, die miteinander verschmolzen sind - es transformiert beide Eingabearten in einen gemeinsamen Embedding-Raum, in dem ähnliche Texte und Bilder nahe beieinander positioniert werden. CLIP wurde mit einem riesigen Datensatz von Bild-Text-Paaren trainiert, wodurch es die Beziehung zwischen visuellem und textuellem Inhalt verstehen kann. Dies ermöglicht eine gute Generalisierung über verschiedene Domänen hinweg und macht es hocheffektiv in Zero-Shot-Learning-Szenarien wie der Generierung von Bildunterschriften oder Bildabruf.
Seit der Veröffentlichung von CLIP haben andere Modelle wie SigLiP, LiT und EvaCLIP auf dessen Grundlage aufgebaut und Aspekte wie Trainingseffizienz, Skalierung und multimodales Verständnis verbessert. Diese Modelle nutzen häufig größere Datensätze, verbesserte Architekturen und ausgefeiltere Trainingstechniken, um die Grenzen der Text-Bild-Ausrichtung zu erweitern und das Feld der Bild-Sprach-Modelle weiter voranzubringen.
Während CLIP zwar auch mit reinem Text arbeiten kann, hat es erhebliche Einschränkungen. Erstens wurde es nur mit kurzen Bildunterschriften trainiert, nicht mit langen Texten, und verarbeitet maximal etwa 77 Wörter. Zweitens ist CLIP zwar hervorragend darin, Text mit Bildern zu verbinden, hat aber Schwierigkeiten beim Vergleich von Text mit anderem Text, wie zum Beispiel zu erkennen, dass die Zeichenfolgen a crimson fruit und a red apple sich auf dasselbe beziehen können. Hier glänzen spezialisierte Textmodelle wie jina-embeddings-v3.
Diese Einschränkungen erschweren Suchaufgaben, die sowohl Text als auch Bilder beinhalten, zum Beispiel einen "Shop the Look" Online-Shop, in dem ein Benutzer Modeprodukte entweder mit einer Textzeichenfolge oder einem Bild suchen kann. Beim Indexieren Ihrer Produkte müssen Sie jedes mehrmals verarbeiten - einmal für das Bild, einmal für den Text und noch einmal mit einem textspezifischen Modell. Ebenso muss Ihr System bei einer Produktsuche durch den Benutzer mindestens zweimal suchen, um sowohl Text- als auch Bildziele zu finden:
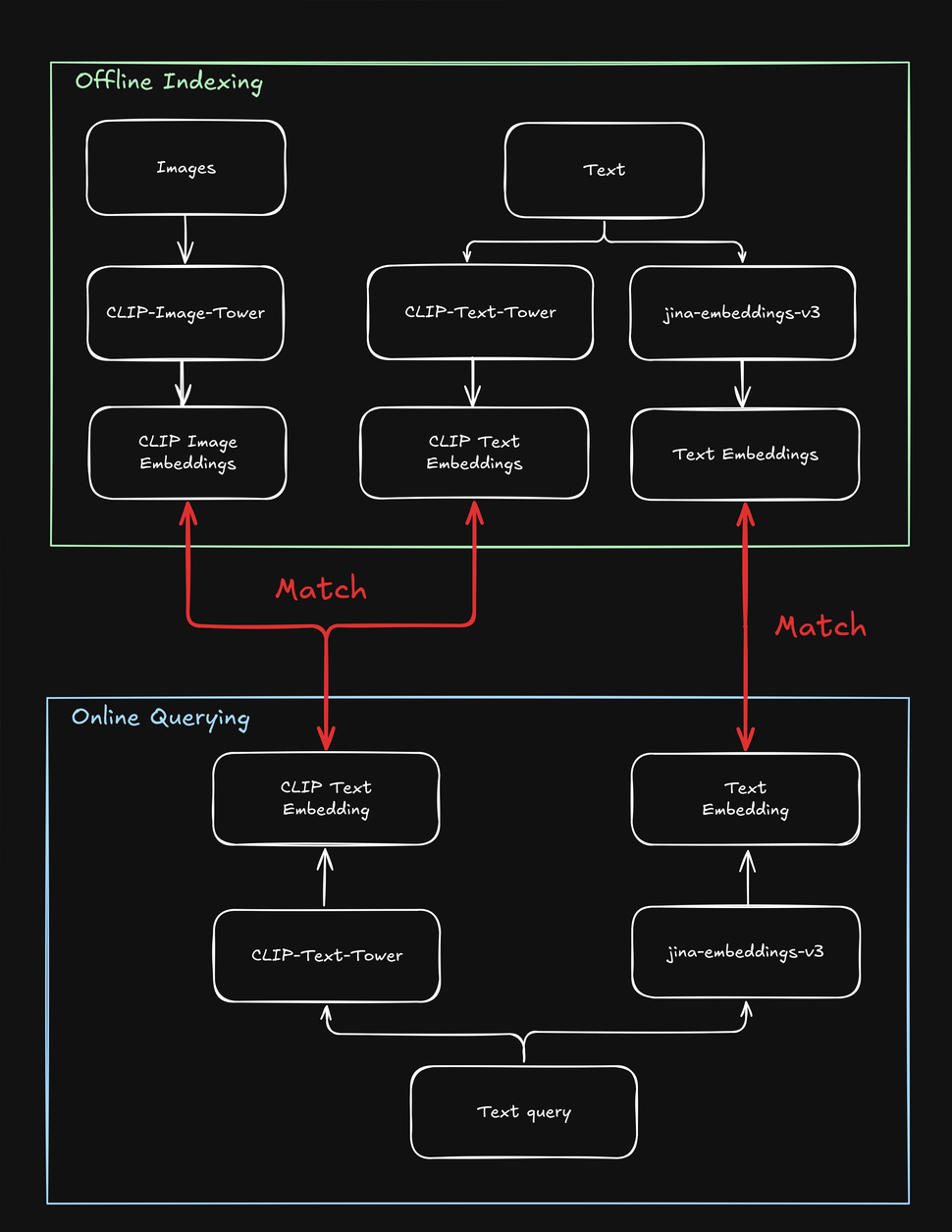
tagWie jina-clip-v1 CLIPs Schwächen löst
Um CLIPs Einschränkungen zu überwinden, haben wir jina-clip-v1 entwickelt, um längere Texte zu verstehen und Textanfragen effektiver sowohl mit Texten als auch mit Bildern abzugleichen. Was macht jina-clip-v1 so besonders? Erstens verwendet es ein intelligenteres Textverständnismodell (JinaBERT), das längere und kompliziertere Texte (wie Produktbeschreibungen) versteht, nicht nur kurze Bildunterschriften (wie Produktnamen). Zweitens haben wir jina-clip-v1 trainiert, gleichzeitig zwei Dinge gut zu können: sowohl das Matching von Text zu Bildern als auch das Matching von Text zu anderen Texten.
Bei OpenAI CLIP ist das nicht der Fall: Sowohl beim Indexieren als auch beim Abfragen müssen Sie zwei Modelle aufrufen (CLIP für Bilder und kurze Texte wie Bildunterschriften, ein weiteres Text-Embedding für längere Texte wie Beschreibungen). Das verursacht nicht nur Overhead, sondern verlangsamt auch die Suche, eine Operation, die eigentlich sehr schnell sein sollte. jina-clip-v1 erledigt all das in einem Modell, ohne Geschwindigkeitseinbußen:

Dieser einheitliche Ansatz eröffnet neue Möglichkeiten, die mit früheren Modellen schwierig waren, und verändert möglicherweise unsere Herangehensweise an die Suche. In diesem Beitrag haben wir zwei Experimente durchgeführt:
- Verbesserung der Suchergebnisse durch Kombination von Text- und Bildsuche: Können wir das, was jina-clip-v1 aus Text versteht, mit dem kombinieren, was es aus Bildern versteht? Was passiert, wenn wir diese beiden Arten des Verstehens vermischen? Verändert das Hinzufügen visueller Informationen unsere Suchergebnisse? Kurz gesagt, können wir bessere Ergebnisse erzielen, wenn wir gleichzeitig mit Text und Bildern suchen?
- Verwendung von Bildern zur Diversifizierung der Suchergebnisse: Die meisten Suchmaschinen maximieren Text-Matches. Aber können wir das Bildverständnis von jina-clip-v1 als "visuelles Shuffle" nutzen? Anstatt nur die relevantesten Ergebnisse anzuzeigen, könnten wir visuell diverse einbeziehen. Es geht nicht darum, mehr verwandte Ergebnisse zu finden – sondern darum, ein breiteres Spektrum an Perspektiven zu zeigen, auch wenn sie weniger eng verwandt sind. Dadurch können wir möglicherweise Aspekte eines Themas entdecken, die wir vorher nicht bedacht hatten. Zum Beispiel im Kontext der Modesuche: Wenn ein Benutzer nach "mehrfarbiges Cocktailkleid" sucht, möchte er, dass die Top-Listings alle gleich aussehen (d.h. sehr enge Übereinstimmungen) oder eine größere Auswahl zur Verfügung haben (durch visuelles Shuffle)?
Beide Ansätze sind wertvoll für verschiedene Anwendungsfälle, bei denen Benutzer entweder mit Text oder Bildern suchen können, wie zum Beispiel im E-Commerce, in den Medien, in Kunst und Design, in der medizinischen Bildgebung und darüber hinaus.
tagDurchschnittliche Text- und Bild-Embeddings für überdurchschnittliche Leistung
Wenn ein Benutzer eine Anfrage eingibt (normalerweise als Textzeichenfolge), können wir den Text-Tower von jina-clip-v1 verwenden, um die Anfrage in ein Text-Embedding zu codieren. Die Stärke von jina-clip-v1 liegt in seiner Fähigkeit, sowohl Text als auch Bilder zu verstehen, indem es Text-zu-Text- und Text-zu-Bild-Signale im gleichen semantischen Raum ausrichtet.
Können wir die Abrufergebnisse verbessern, wenn wir die vorindexierten Text- und Bild-Embeddings jedes Produkts durch Mittelwertbildung kombinieren?
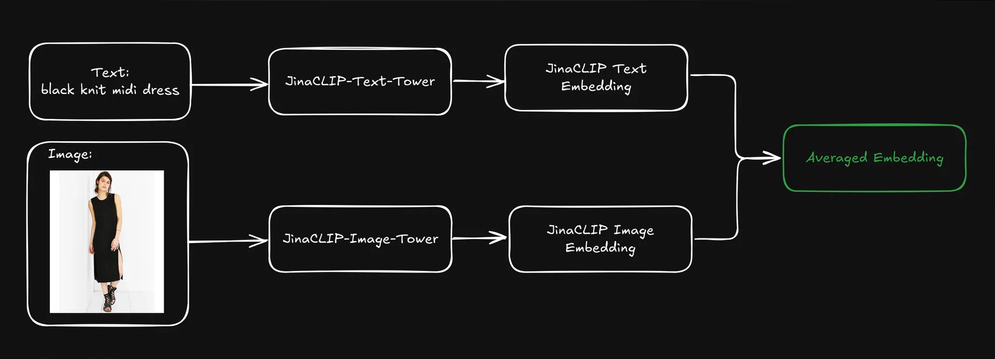
Dies erzeugt eine einzige Repräsentation, die sowohl textuelle Informationen (z.B. Produktbeschreibung) als auch visuelle Informationen (z.B. Produktbild) enthält. Wir können dann das Text-Query-Embedding verwenden, um diese gemischten Repräsentationen zu durchsuchen. Wie wirkt sich das auf unsere Suchergebnisse aus?
Um das herauszufinden, verwendeten wir den Fashion200k Datensatz, einen umfangreichen Datensatz, der speziell für Aufgaben im Zusammenhang mit Mode-Bildabruf und modalitätsübergreifendem Verständnis erstellt wurde. Er besteht aus über 200.000 Bildern von Modeartikel wie Kleidung, Schuhe und Accessoires, zusammen mit entsprechenden Produktbeschreibungen und Metadaten.
 xthan
xthanWir haben jedes Element weiter in eine breite Kategorie (zum Beispiel dress) und eine feingranulare Kategorie (wie knit midi dress) eingeordnet.
tagAnalyse von drei Retrieval-Methoden
Um herauszufinden, ob die Mittelung von Text- und Bild-Embeddings bessere Retrieval-Ergebnisse liefert, haben wir drei Arten der Suche getestet, die alle eine Textzeichenfolge (z.B. red dress) als Query verwenden:
- Query to Description mit Text-Embeddings: Suche in Produktbeschreibungen basierend auf Text-Embeddings.
- Query to Image mit Cross-Modal-Suche: Suche in Produktbildern basierend auf Bild-Embeddings.
- Query to Average Embedding: Suche in gemittelten Embeddings von Produktbeschreibungen und Produktbildern.
Wir haben zunächst den gesamten Datensatz indiziert und dann zufällig 1.000 Queries generiert, um die Performance zu evaluieren. Wir haben jede Query in ein Text-Embedding umgewandelt und das Embedding separat nach den oben beschriebenen Methoden abgeglichen. Die Genauigkeit haben wir daran gemessen, wie gut die Kategorien der zurückgelieferten Produkte mit der Eingabe-Query übereinstimmten.
Bei der Query multicolor henley t-shirt dress erreichte die Query-to-Description-Suche die höchste Top-5-Präzision, aber die letzten drei der am besten bewerteten Kleider waren visuell identisch. Das ist nicht ideal, da eine effektive Suche Relevanz und Diversität ausbalancieren sollte, um die Aufmerksamkeit des Nutzers besser zu gewinnen.

Die Query-to-Image Cross-Modal-Suche verwendete dieselbe Query und verfolgte den gegenteiligen Ansatz, indem sie eine sehr diverse Kollektion von Kleidern präsentierte. Während zwei von fünf Ergebnissen mit der korrekten breiten Kategorie übereinstimmten, passte keines zur feingranularen Kategorie.

Die gemittelte Text- und Bild-Embedding-Suche lieferte das beste Ergebnis: Alle fünf Ergebnisse stimmten mit der breiten Kategorie überein und zwei von fünf passten zur feingranularen Kategorie. Zusätzlich wurden visuell duplizierte Artikel eliminiert, was eine abwechslungsreichere Auswahl bot. Die Verwendung von Text-Embeddings zur Suche in gemittelten Text- und Bild-Embeddings scheint die Suchqualität beizubehalten und gleichzeitig visuelle Hinweise zu integrieren, was zu vielfältigeren und ausgewogeneren Ergebnissen führt.

tagSkalierung: Evaluierung mit mehr Queries
Um zu sehen, ob dies auch im größeren Maßstab funktionieren würde, führten wir das Experiment mit zusätzlichen breiten und feingranularen Kategorien fort. Wir führten mehrere Iterationen durch und riefen dabei jeweils eine unterschiedliche Anzahl von Ergebnissen ("k-Werte") ab.
Sowohl bei den breiten als auch bei den feingranularen Kategorien erzielte das Query to Average Embedding durchgehend die höchste Präzision über alle k-Werte (10, 20, 50, 100). Dies zeigt, dass die Kombination von Text- und Bild-Embeddings die genauesten Ergebnisse für das Abrufen relevanter Artikel liefert, unabhängig davon, ob die Kategorie breit oder spezifisch ist:

| k | Search Type | Broad Category Precision (cosine similarity) | Fine-grained Category Precision (cosine similarity) |
|---|---|---|---|
| 10 | Query to Description | 0.9026 | 0.2314 |
| 10 | Query to Image | 0.7614 | 0.2037 |
| 10 | Query to Avg Embedding | 0.9230 | 0.2711 |
| 20 | Query to Description | 0.9150 | 0.2316 |
| 20 | Query to Image | 0.7523 | 0.1964 |
| 20 | Query to Avg Embedding | 0.9229 | 0.2631 |
| 50 | Query to Description | 0.9134 | 0.2254 |
| 50 | Query to Image | 0.7418 | 0.1750 |
| 50 | Query to Avg Embedding | 0.9226 | 0.2390 |
| 100 | Query to Description | 0.9092 | 0.2139 |
| 100 | Query to Image | 0.7258 | 0.1675 |
| 100 | Query to Avg Embedding | 0.9150 | 0.2286 |
- Query to Description mit Text-Embeddings zeigte in beiden Kategorien gute Leistungen, lag aber leicht hinter dem gemittelten Embedding-Ansatz zurück. Dies deutet darauf hin, dass textuelle Beschreibungen allein wertvolle Informationen liefern, besonders für breitere Kategorien wie "dress", aber möglicherweise die nötige Feinheit für präzise feingranulare Klassifizierung fehlt (z.B. bei der Unterscheidung verschiedener Kleidertypen).
- Query to Image mit Cross-Modal-Suche hatte durchgehend die niedrigste Präzision in beiden Kategorien. Dies deutet darauf hin, dass visuelle Merkmale zwar bei der Identifizierung breiter Kategorien helfen können, aber weniger effektiv sind, wenn es um die feingranularen Unterscheidungen spezifischer Mode-Artikel geht. Die Herausforderung, feingranulare Kategorien rein anhand visueller Merkmale zu unterscheiden, wird besonders deutlich, wenn visuelle Unterschiede subtil sein können und zusätzlichen Kontext durch Text erfordern.
- Insgesamt erreichte die Kombination von textueller und visueller Information (durch gemittelte Embeddings) eine hohe Präzision sowohl bei breiten als auch bei feingranularen Mode-Retrieval-Aufgaben. Textuelle Beschreibungen spielen eine wichtige Rolle, besonders bei der Identifizierung breiter Kategorien, während Bilder allein in beiden Fällen weniger effektiv sind.
Insgesamt war die Präzision für breite Kategorien deutlich höher als für feingranulare Kategorien, hauptsächlich weil Artikel in breiten Kategorien (z.B. dress) im Datensatz stärker vertreten sind als in feingranularen Kategorien (z.B. henley dress), da letztere einfach eine Teilmenge der ersteren sind. Naturgemäß ist eine breite Kategorie leichter zu verallgemeinern als eine feingranulare Kategorie. Außerhalb des Mode-Beispiels ist es einfach zu erkennen, dass etwas im Allgemeinen ein Vogel ist. Es ist viel schwieriger, ihn als Vogelkop Superb Bird of Paradise zu identifizieren.
Ein weiterer wichtiger Punkt ist, dass die Information in einer Text-Query leichter mit anderen Texten (wie Produktnamen oder Beschreibungen) übereinstimmt als mit visuellen Merkmalen. Wenn also ein Text als Input verwendet wird, sind Texte ein wahrscheinlicheres Output als Bilder. Die besten Ergebnisse erzielen wir durch die Kombination von Bildern und Text (durch Mittelung der Embeddings) in unserem Index.
tagErgebnisse mit Text abrufen; sie mit Bildern diversifizieren
Im vorherigen Abschnitt haben wir das Problem visuell duplizierter Suchergebnisse angesprochen. Bei der Suche ist Präzision allein nicht immer ausreichend. In vielen Fällen ist die Aufrechterhaltung einer prägnanten, aber hochrelevanten und diversen Rangliste effektiver, besonders wenn die Query des Nutzers mehrdeutig ist (zum Beispiel, wenn ein Nutzer nach
black jacket - meinen sie eine schwarze Bikerjacke, Bomberjacke, einen Blazer oder eine andere Art?).Anstatt die Cross-Modal-Fähigkeit von jina-clip-v1 zu nutzen, verwenden wir jetzt die Text-Embeddings aus seinem Text-Tower für die erste Textsuche und wenden dann die Bild-Embeddings aus dem Image-Tower als "visuellen Reranker" an, um die Suchergebnisse zu diversifizieren. Dies wird im folgenden Diagramm veranschaulicht:
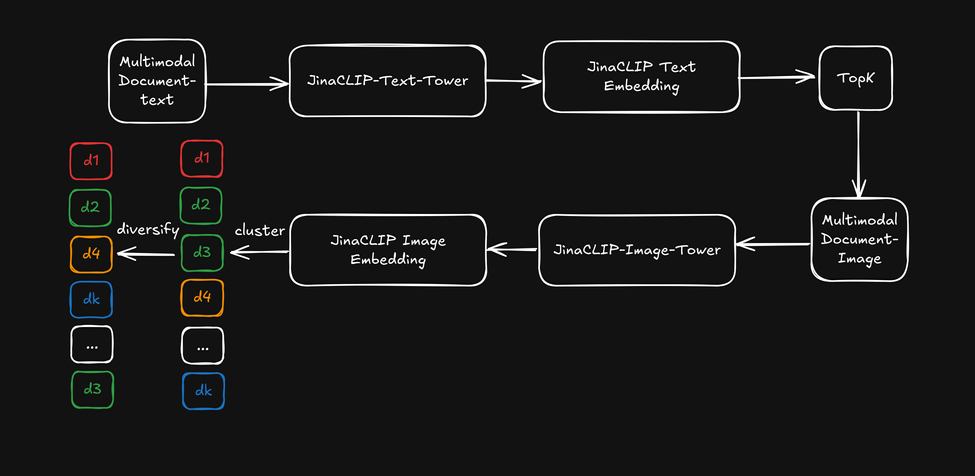
- Zuerst werden die Top-k-Suchergebnisse basierend auf Text-Embeddings abgerufen.
- Für jedes Top-Suchergebnis werden visuelle Merkmale extrahiert und mittels Bild-Embeddings geclustert.
- Die Suchergebnisse werden neu geordnet, indem ein Element aus jedem Cluster ausgewählt und dem Benutzer eine diversifizierte Liste präsentiert wird.
Nach dem Abrufen der Top-50-Ergebnisse wendeten wir ein leichtgewichtiges k-means Clustering (k=5) auf die Bild-Embeddings an und wählten dann Elemente aus jedem Cluster aus. Die Kategoriepräzision blieb konsistent mit der Query-to-Description-Performance, da wir die Query-to-Product-Kategorie als Messmetrik verwendeten. Die geordneten Ergebnisse begannen jedoch durch die bildbasierte Diversifizierung mehr verschiedene Aspekte (wie Stoff, Schnitt und Muster) abzudecken. Hier ist als Referenz das Beispiel des mehrfarbigen Henley T-Shirt-Kleids von vorher:

Schauen wir uns nun an, wie sich die Diversifizierung auf die Suchergebnisse auswirkt, wenn wir die Text-Embedding-Suche kombiniert mit Bild-Embedding als Diversifizierungs-Reranker verwenden:

Die geordneten Ergebnisse stammen aus der textbasierten Suche, beginnen aber innerhalb der Top 5 Beispiele mehr diverse "Aspekte" abzudecken. Dies erzielt einen ähnlichen Effekt wie das Mitteln von Embeddings, ohne sie tatsächlich zu mitteln.
Dies hat jedoch seinen Preis: Wir müssen nach dem Abrufen der Top-k-Ergebnisse einen zusätzlichen Clustering-Schritt durchführen, was je nach Größe des initialen Rankings einige zusätzliche Millisekunden benötigt. Außerdem erfordert die Bestimmung des k-Wertes für das k-means Clustering einiges an heuristischem Raten. Das ist der Preis, den wir für eine verbesserte Diversifizierung der Ergebnisse zahlen!
tagFazit
jina-clip-v1 überbrückt effektiv die Lücke zwischen Text- und Bildsuche, indem es beide Modalitäten in einem einzigen, effizienten Modell vereint. Unsere Experimente haben gezeigt, dass seine Fähigkeit, längere und komplexere Texteingaben zusammen mit Bildern zu verarbeiten, im Vergleich zu traditionellen Modellen wie CLIP eine überlegene Suchleistung liefert.
Unsere Tests umfassten verschiedene Methoden, einschließlich des Abgleichs von Text mit Beschreibungen, Bildern und gemittelten Embeddings. Die Ergebnisse zeigten durchgängig, dass die Kombination von Text- und Bild-Embeddings die besten Resultate lieferte und sowohl die Genauigkeit als auch die Vielfalt der Suchergebnisse verbesserte. Wir entdeckten auch, dass die Verwendung von Bild-Embeddings als "visueller Reranker" die Ergebnisvielfalt erhöhte, während die Relevanz erhalten blieb.
Diese Fortschritte haben wichtige Implikationen für reale Anwendungen, bei denen Benutzer sowohl mit Textbeschreibungen als auch mit Bildern suchen. Durch das gleichzeitige Verständnis beider Datentypen optimiert jina-clip-v1 den Suchprozess, liefert relevantere Ergebnisse und ermöglicht vielfältigere Produktempfehlungen. Diese einheitliche Suchfunktion geht über den E-Commerce hinaus und kommt auch der Verwaltung von Medienbeständen, digitalen Bibliotheken und der Kuratierung visueller Inhalte zugute, wodurch es einfacher wird, relevante Inhalte über verschiedene Formate hinweg zu entdecken.
Während jina-clip-v1 derzeit nur Englisch unterstützt, arbeiten wir aktuell an jina-clip-v2. In der Nachfolge von jina-embeddings-v3 und jina-colbert-v2 wird diese neue Version ein state-of-the-art mehrsprachiger multimodaler Retriever sein, der 89 Sprachen unterstützt. Dieses Upgrade wird neue Möglichkeiten für Such- und Abrufaufgaben in verschiedenen Märkten und Branchen eröffnen und es zu einem leistungsfähigeren Embedding-Modell für globale Anwendungen im E-Commerce, in den Medien und darüber hinaus machen.
