




Eine der zentralen Herausforderungen bei mehrsprachigen Modellen ist die "Sprachlücke" — ein Phänomen, bei dem Phrasen mit der gleichen Bedeutung in verschiedenen Sprachen nicht so eng ausgerichtet oder gruppiert sind, wie sie es sein sollten. Idealerweise sollten ein Text in einer Sprache und sein Äquivalent in einer anderen ähnliche Repräsentationen haben — d.h. Embeddings, die sehr nahe beieinander liegen — damit sprachübergreifende Anwendungen bei Texten in verschiedenen Sprachen identisch funktionieren können. Allerdings repräsentieren Modelle oft subtil die Sprache eines Textes, wodurch eine "Sprachlücke" entsteht, die zu suboptimaler sprachübergreifender Leistung führt.
In diesem Beitrag untersuchen wir diese Sprachlücke und ihren Einfluss auf die Leistung von Text-Embedding-Modellen. Wir haben Experimente durchgeführt, um die semantische Ausrichtung von Paraphrasen in der gleichen Sprache und von Übersetzungen zwischen verschiedenen Sprachpaaren zu bewerten, wobei wir unser jina-xlm-roberta Modell und das neueste jina-embeddings-v3 verwendet haben. Diese Experimente zeigen, wie gut sich Phrasen mit ähnlicher oder identischer Bedeutung unter verschiedenen Trainingsbedingungen gruppieren.

Wir haben auch Trainingstechniken erprobt, um die sprachübergreifende semantische Ausrichtung zu verbessern, insbesondere die Einführung von parallelen mehrsprachigen Daten während des kontrastiven Lernens. In diesem Artikel teilen wir unsere Erkenntnisse und Ergebnisse.
tagMehrsprachiges Modelltraining erzeugt und reduziert die Sprachlücke
Das Training von Text-Embedding-Modellen umfasst typischerweise einen mehrstufigen Prozess mit zwei Hauptteilen:
- Masked Language Modeling (MLM): Das Vortraining beinhaltet typischerweise sehr große Textmengen, bei denen einige der Token zufällig maskiert werden. Das Modell wird darauf trainiert, diese maskierten Token vorherzusagen. Diese Vorgehensweise lehrt dem Modell die Muster der Sprache oder Sprachen in den Trainingsdaten, einschließlich Auswahlabhängigkeiten zwischen Token, die sich aus Syntax, lexikalischer Semantik und pragmatischen Einschränkungen der realen Welt ergeben können.
- Contrastive Learning: Nach dem Vortraining wird das Modell mit kuratierten oder semi-kuratierten Daten weiter trainiert, um die Embeddings semantisch ähnlicher Texte näher zusammenzubringen und (optional) unähnliche weiter auseinander zu schieben. Dieses Training kann Paare, Tripel oder sogar Gruppen von Texten verwenden, deren semantische Ähnlichkeit bereits bekannt oder zumindest zuverlässig geschätzt ist. Es kann mehrere Unterstufen haben und es gibt verschiedene Trainingsstrategien für diesen Teil des Prozesses, wobei häufig neue Forschungsergebnisse veröffentlicht werden und kein klarer Konsens über den optimalen Ansatz besteht.
Um zu verstehen, wie die Sprachlücke entsteht und wie sie geschlossen werden kann, müssen wir die Rolle beider Stufen betrachten.
tagMasked Language Pretraining
Ein Teil der sprachübergreifenden Fähigkeit von Text-Embedding-Modellen wird während des Vortrainings erworben.
Verwandte und entlehnte Wörter ermöglichen es dem Modell, aus großen Textmengen eine gewisse sprachübergreifende semantische Ausrichtung zu lernen. Zum Beispiel sind das englische Wort banana und das französische Wort banane (und deutsche Banane) häufig und in der Schreibweise ähnlich genug, dass ein Embedding-Modell lernen kann, dass Wörter, die wie "banan-" aussehen, über Sprachen hinweg ähnliche Verteilungsmuster haben. Es kann diese Information nutzen, um bis zu einem gewissen Grad zu lernen, dass auch andere Wörter, die über Sprachen hinweg nicht gleich aussehen, ähnliche Bedeutungen haben, und sogar herausfinden, wie grammatikalische Strukturen übersetzt werden.
Dies geschieht jedoch ohne explizites Training.
Wir haben das jina-xlm-roberta Modell, das vortrainierte Rückgrat von jina-embeddings-v3, getestet, um zu sehen, wie gut es sprachübergreifende Äquivalenzen aus dem maskierten Sprach-Vortraining gelernt hat. Wir haben zweidimensionale UMAP Satzrepräsentationen einer Reihe von englischen Sätzen geplottet, die ins Deutsche, Niederländische, vereinfachte Chinesisch und Japanische übersetzt wurden. Die Ergebnisse sind in der folgenden Abbildung dargestellt:
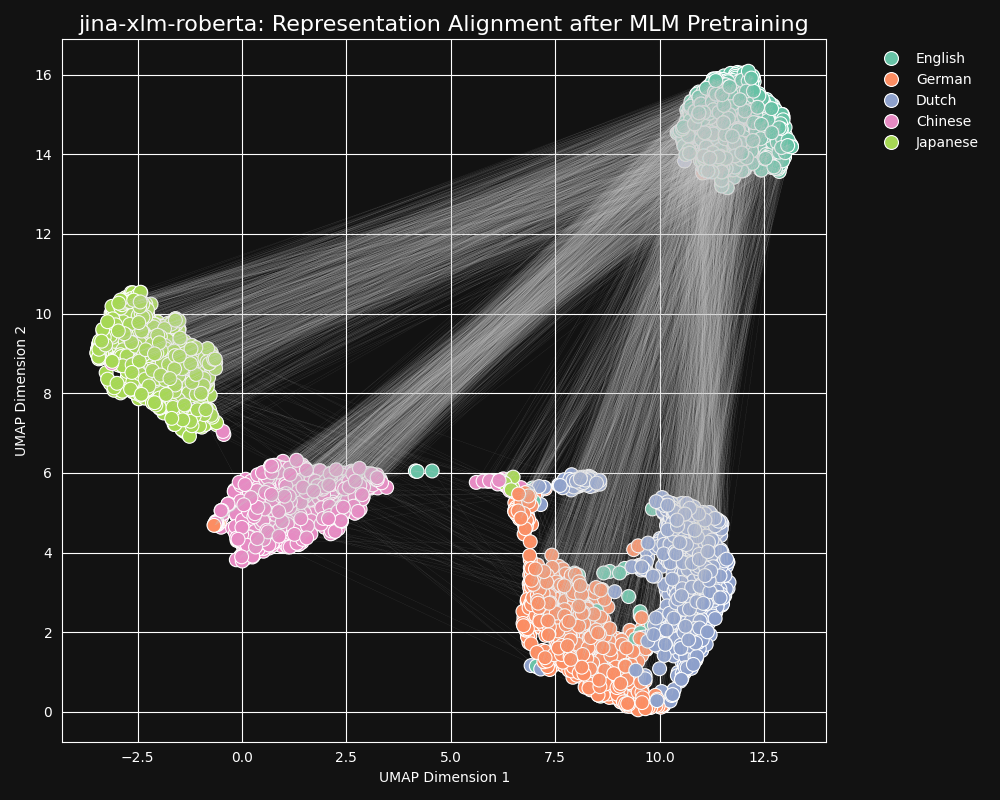
Diese Sätze neigen dazu, im
jina-xlm-roberta Embedding-Raum stark sprachspezifische Cluster zu bilden, obwohl Sie in dieser Projektion einige Ausreißer sehen können, die möglicherweise ein Nebeneffekt der zweidimensionalen Projektion sind.Man kann sehen, dass das Vortraining die Embeddings von Sätzen in der gleichen Sprache sehr stark zusammengruppiert hat. Dies ist eine Projektion in zwei Dimensionen einer Verteilung in einem viel höherdimensionalen Raum, sodass es immer noch möglich ist, dass zum Beispiel ein deutscher Satz, der eine gute Übersetzung eines englischen ist, trotzdem der deutsche Satz ist, dessen Embedding dem Embedding seiner englischen Quelle am nächsten kommt. Aber es zeigt, dass ein Embedding eines englischen Satzes wahrscheinlich näher an einem anderen englischen Satz liegt als an einem semantisch identischen oder fast identischen deutschen.
Beachten Sie auch, wie Deutsch und Niederländisch viel engere Cluster bilden als andere Sprachpaare. Dies ist nicht überraschend für zwei relativ eng verwandte Sprachen. Deutsch und Niederländisch sind sich so ähnlich, dass sie manchmal teilweise gegenseitig verständlich sind.
Japanisch und Chinesisch scheinen sich ebenfalls näher beieinander zu befinden als zu anderen Sprachen. Obwohl sie nicht auf die gleiche Weise verwandt sind, verwendet das geschriebene Japanisch typischerweise kanji (漢字), oder hànzì im Chinesischen. Japanisch teilt die meisten dieser geschriebenen Zeichen mit dem Chinesischen, und die beiden Sprachen teilen viele Wörter, die mit einem oder mehreren kanji/hànzì zusammen geschrieben werden. Aus der Perspektive des MLM ist dies die gleiche Art von sichtbarer Ähnlichkeit wie zwischen Niederländisch und Deutsch.
Wir können diese "Sprachlücke" auf einfachere Weise sehen, wenn wir nur zwei Sprachen mit jeweils zwei Sätzen betrachten:

Da MLM Texte natürlicherweise nach Sprachen clustert, werden "my dog is blue" und "my cat is red" zusammen gruppiert, weit entfernt von ihren deutschen Entsprechungen. Anders als die "Modalitätslücke", die in einem früheren Blogbeitrag diskutiert wurde, glauben wir, dass dies aus oberflächlichen Ähnlichkeiten und Unähnlichkeiten zwischen Sprachen entsteht: ähnliche Schreibweisen, Verwendung der gleichen Zeichenfolgen im Druck und möglicherweise Ähnlichkeiten in Morphologie und syntaktischer Struktur — gemeinsame Wortstellungen und gemeinsame Arten der Wortbildung.
Kurz gesagt, in welchem Maße ein Modell auch immer sprachübergreifende Äquivalenzen im MLM-Vortraining lernt, es reicht nicht aus, um eine starke Tendenz zur Gruppierung von Texten nach Sprachen zu überwinden. Es hinterlässt eine große Sprachlücke.
tagContrastive Learning
Idealerweise wollen wir ein Embedding-Modell, das gegenüber der Sprache indifferent ist und nur allgemeine Bedeutungen in seinen Embeddings kodiert. In einem solchen Modell würden wir keine Gruppierung nach Sprachen sehen und keine Sprachlücke haben. Sätze in einer Sprache sollten sehr nahe an guten Übersetzungen und weit entfernt von anderen Sätzen sein, die etwas anderes bedeuten, auch in der gleichen Sprache, wie in der folgenden Abbildung:

MLM-Vortraining erreicht das nicht, daher verwenden wir zusätzliche kontrastive Lerntechniken, um die semantische Repräsentation von Texten in Embeddings zu verbessern.
Kontrastives Lernen beinhaltet die Verwendung von Textpaaren, von denen bekannt ist, dass sie in ihrer Bedeutung ähnlich oder unterschiedlich sind, und Tripeln, bei denen bekannt ist, dass ein Paar ähnlicher ist als das andere. Die Gewichte werden während des Trainings angepasst, um diese bekannte Beziehung zwischen Textpaaren und Tripeln widerzuspiegeln.
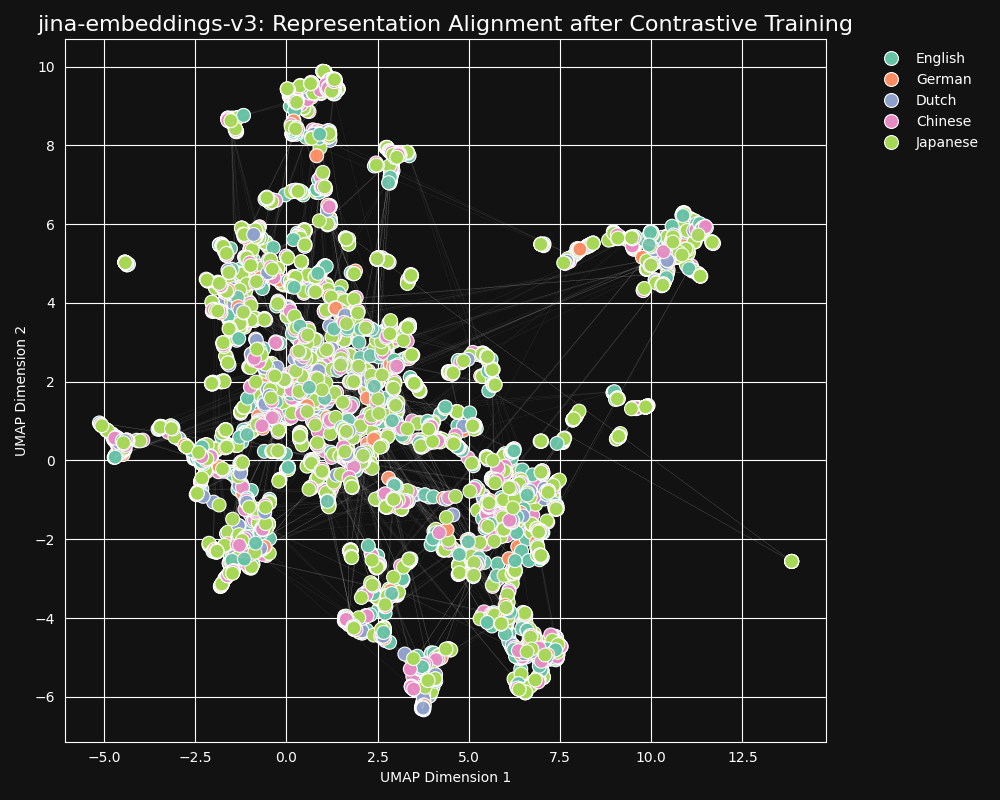
In unserem kontrastiven Lerndatensatz sind 30 Sprachen vertreten, aber 97% der Paare und Tripel sind in nur einer Sprache, und nur 3% beinhalten sprachübergreifende Paare oder Tripel. Aber diese 3% reichen aus, um ein dramatisches Ergebnis zu erzielen: Die Embeddings zeigen sehr wenig Sprachgruppierung, und semantisch ähnliche Texte produzieren nahe beieinander liegende Embeddings, unabhängig von ihrer Sprache, wie in der UMAP-Projektion von Embeddings aus jina-embeddings-v3 gezeigt wird.
Um dies zu bestätigen, haben wir die Spearman-Korrelation der von jina-xlm-roberta und jina-embeddings-v3 generierten Repräsentationen auf dem STS17-Datensatz gemessen.
Die folgende Tabelle zeigt die Spearman-Korrelation zwischen semantischen Ähnlichkeitsrankings für übersetzte Texte in verschiedenen Sprachen. Wir nehmen eine Reihe englischer Sätze und messen dann die Ähnlichkeit ihrer Embeddings mit einem Embedding eines bestimmten Referenzsatzes und sortieren sie der Reihe nach von der ähnlichsten zur am wenigsten ähnlichen. Dann übersetzen wir all diese Sätze in eine andere Sprache und wiederholen den Ranking-Prozess. In einem idealen sprachübergreifenden Embedding-Modell wären die beiden geordneten Listen identisch und die Spearman-Korrelation wäre 1,0.
Die untenstehende Grafik und Tabelle zeigen unsere Ergebnisse beim Vergleich von Englisch mit den sechs anderen Sprachen im STS17-Benchmark unter Verwendung von sowohl jina-xlm-roberta als auch jina-embeddings-v3.
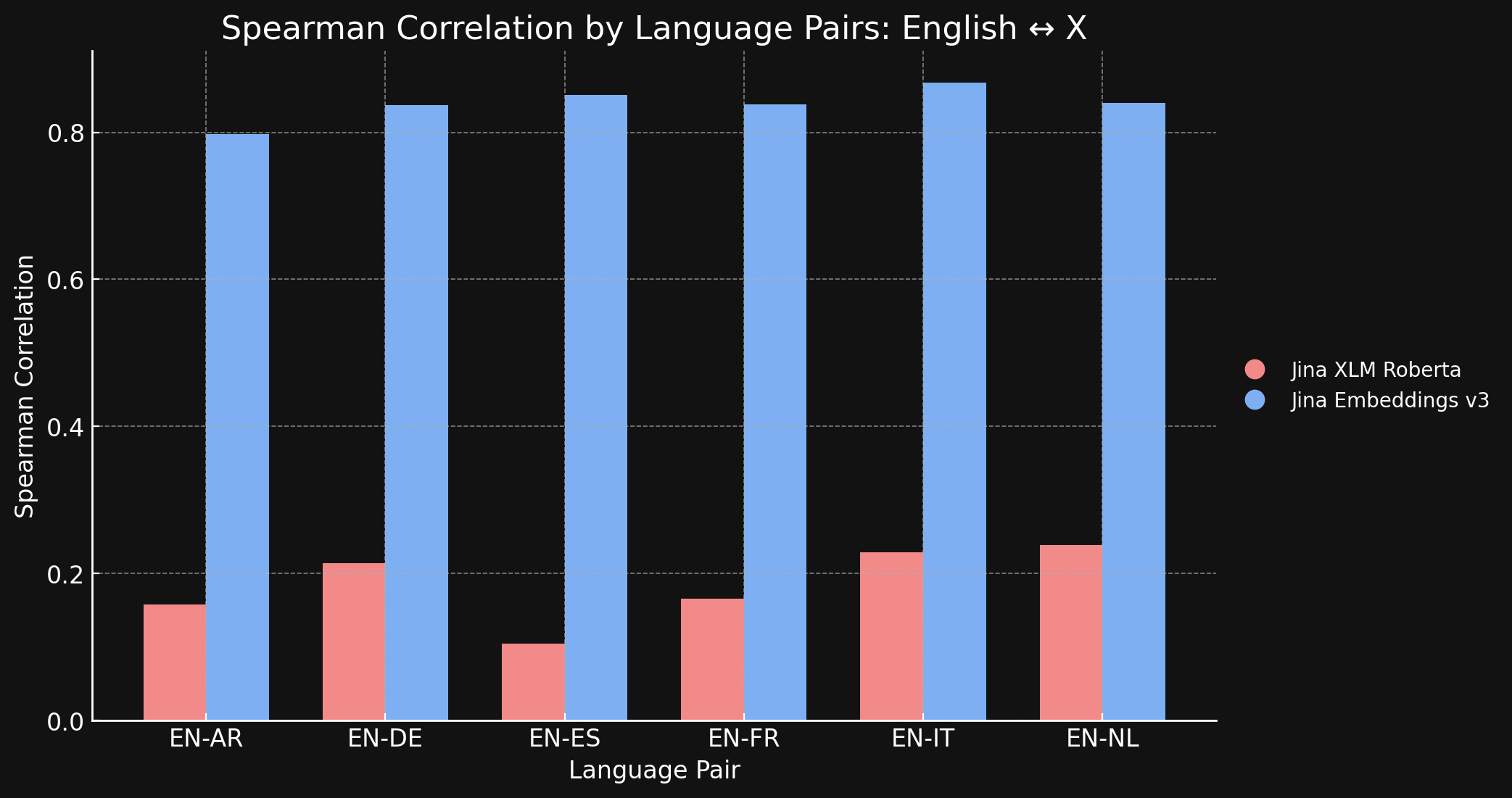
| Task | jina-xlm-roberta |
jina-embeddings-v3 |
|---|---|---|
| English ↔ Arabic | 0.1581 | 0.7977 |
| English ↔ German | 0.2136 | 0.8366 |
| English ↔ Spanish | 0.1049 | 0.8509 |
| English ↔ French | 0.1659 | 0.8378 |
| English ↔ Italian | 0.2293 | 0.8674 |
| English ↔ Dutch | 0.2387 | 0.8398 |
Hier sehen Sie den enormen Unterschied, den das kontrastive Lernen im Vergleich zum ursprünglichen Pre-training macht. Obwohl nur 3 % sprachübergreifende Daten im Trainingsmix enthalten waren, hat das jina-embeddings-v3 Modell genug sprachübergreifende Semantik gelernt, um die Sprachlücke, die es im Pre-training erworben hat, fast vollständig zu eliminieren.
tagEnglisch gegen den Rest der Welt: Können andere Sprachen bei der Ausrichtung mithalten?
Wir haben jina-embeddings-v3 mit 89 Sprachen trainiert, mit besonderem Fokus auf 30 sehr weit verbreitete Schriftsprachen. Trotz unserer Bemühungen, ein umfangreiches mehrsprachiges Trainingskorpus aufzubauen, macht Englisch immer noch fast die Hälfte der Daten aus, die wir im kontrastiven Training verwendet haben. Andere Sprachen, einschließlich weit verbreiteter globaler Sprachen, für die reichlich Textmaterial verfügbar ist, sind im Vergleich zur enormen Menge englischer Daten im Trainingssatz immer noch relativ unterrepräsentiert.
Sind angesichts dieser Dominanz des Englischen die englischen Repräsentationen besser aufeinander abgestimmt als die anderer Sprachen? Um dies zu untersuchen, führten wir ein Folgeexperiment durch.
Wir erstellten einen Datensatz, parallel-sentences, der aus 1.000 englischen Textpaaren besteht, einem "Anker" und einem "Positiv", wobei der positive Text logisch aus dem Ankertext folgt.

Zum Beispiel die erste Zeile der folgenden Tabelle. Diese Sätze haben keine identische Bedeutung, aber sie haben kompatible Bedeutungen. Sie beschreiben informativ die gleiche Situation.
Wir übersetzten diese Paare dann mit GPT-4 in fünf Sprachen: Deutsch, Niederländisch, Chinesisch (Vereinfacht), Chinesisch (Traditionell) und Japanisch. Schließlich überprüften wir sie manuell, um die Qualität sicherzustellen.
| Language | Anchor | Positive |
|---|---|---|
| English | Two young girls are playing outside in a non-urban environment. | Two girls are playing outside. |
| German | Zwei junge Mädchen spielen draußen in einer nicht urbanen Umgebung. | Zwei Mädchen spielen draußen. |
| Dutch | Twee jonge meisjes spelen buiten in een niet-stedelijke omgeving. | Twee meisjes spelen buiten. |
| Chinese (Simplified) | 两个年轻女孩在非城市环境中玩耍。 | 两个女孩在外面玩。 |
| Chinese (Traditional) | 兩個年輕女孩在非城市環境中玩耍。 | 兩個女孩在外面玩。 |
| Japanese | 2人の若い女の子が都市環境ではない場所で遊んでいます。 | 二人の少女が外で遊んでいます。 |
Anschließend kodierten wir jedes Textpaar mit jina-embeddings-v3 und berechneten die Kosinus-Ähnlichkeit zwischen ihnen. Die folgende Abbildung und Tabelle zeigen die Verteilung der Kosinus-Ähnlichkeitswerte für jede Sprache und die durchschnittliche Ähnlichkeit:
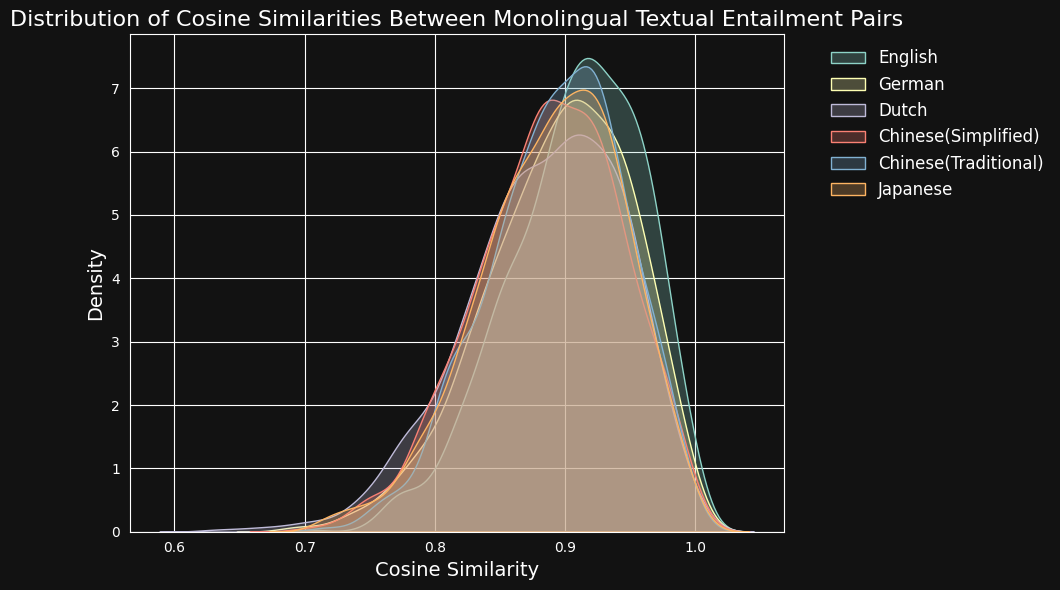
| Language | Average Cosine Similarity |
|---|---|
| English | 0.9078 |
| German | 0.8949 |
| Dutch | 0.8844 |
| Chinese (Simplified) | 0.8876 |
| Chinese (Traditional) | 0.8933 |
| Japanese | 0.8895 |
Trotz der Dominanz des Englischen in den Trainingsdaten erkennt jina-embeddings-v3 semantische Ähnlichkeiten in Deutsch, Niederländisch, Japanisch und beiden Formen des Chinesischen etwa genauso gut wie im Englischen.
tagSprachbarrieren überwinden: Sprachübergreifende Ausrichtung jenseits des Englischen
Untersuchungen zur Angleichung sprachübergreifender Repräsentationen konzentrieren sich typischerweise auf Sprachpaare mit Englisch. Diese Fokussierung könnte theoretisch verschleiern, was tatsächlich passiert. Ein Modell könnte einfach darauf optimiert sein, alles so nah wie möglich an seinem englischen Äquivalent darzustellen, ohne zu prüfen, ob andere Sprachpaare angemessen unterstützt werden.
Um dies zu untersuchen, führten wir einige Experimente mit dem parallel-sentences Datensatz durch, wobei wir uns auf die sprachübergreifende Angleichung über englische Sprachpaare hinaus konzentrierten.
Die untenstehende Tabelle zeigt die Verteilung der Kosinus-Ähnlichkeiten zwischen äquivalenten Texten in verschiedenen Sprachpaaren — Texte, die Übersetzungen einer gemeinsamen englischen Quelle sind. Idealerweise sollten alle Paare einen Kosinus von 1 haben — d.h. identische semantische Einbettungen. In der Praxis könnte dies nie passieren, aber wir würden von einem guten Modell sehr hohe Kosinus-Werte für Übersetzungspaare erwarten.
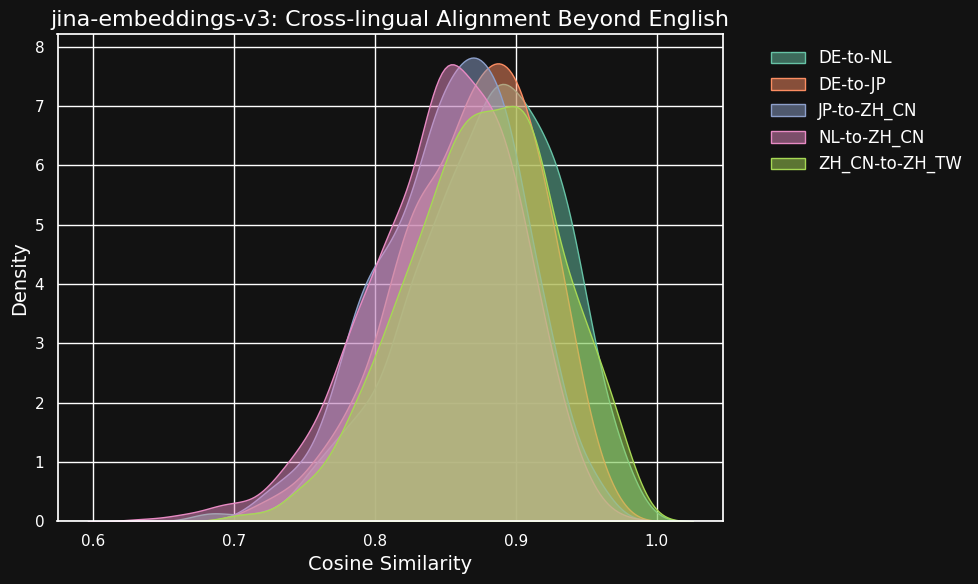
| Language Pair | Average Cosine Similarity |
|---|---|
| German ↔ Dutch | 0.8779 |
| German ↔ Japanese | 0.8664 |
| Chinese (Simplified) ↔ Japanese | 0.8534 |
| Dutch ↔ Chinese (Simplified) | 0.8479 |
| Chinese (Simplified) ↔ Chinese (Traditional) | 0.8758 |
Obwohl die Ähnlichkeitswerte zwischen verschiedenen Sprachen etwas niedriger sind als bei kompatiblen Texten in derselben Sprache, sind sie immer noch sehr hoch. Die Kosinus-Ähnlichkeit von niederländisch/deutschen Übersetzungen ist fast so hoch wie zwischen kompatiblen Texten auf Deutsch.
Das mag nicht überraschend sein, da Deutsch und Niederländisch sehr ähnliche Sprachen sind. Ähnlich verhält es sich bei den beiden hier getesteten chinesischen Varianten, die nicht wirklich zwei verschiedene Sprachen sind, sondern nur stilistisch unterschiedliche Formen derselben Sprache. Aber man kann sehen, dass selbst sehr unterschiedliche Sprachpaare wie Niederländisch und Chinesisch oder Deutsch und Japanisch immer noch sehr starke Ähnlichkeiten zwischen semantisch äquivalenten Texten aufweisen.
Wir zogen die Möglichkeit in Betracht, dass diese sehr hohen Ähnlichkeitswerte ein Nebeneffekt der Verwendung von ChatGPT als Übersetzer sein könnten. Um dies zu testen, luden wir von Menschen übersetzte Transkripte von TED Talks auf Englisch und Deutsch herunter und überprüften, ob die ausgerichteten übersetzten Sätze die gleiche hohe Korrelation aufweisen würden.
Das Ergebnis war sogar stärker als bei unseren maschinell übersetzten Daten, wie man in der Abbildung unten sehen kann.
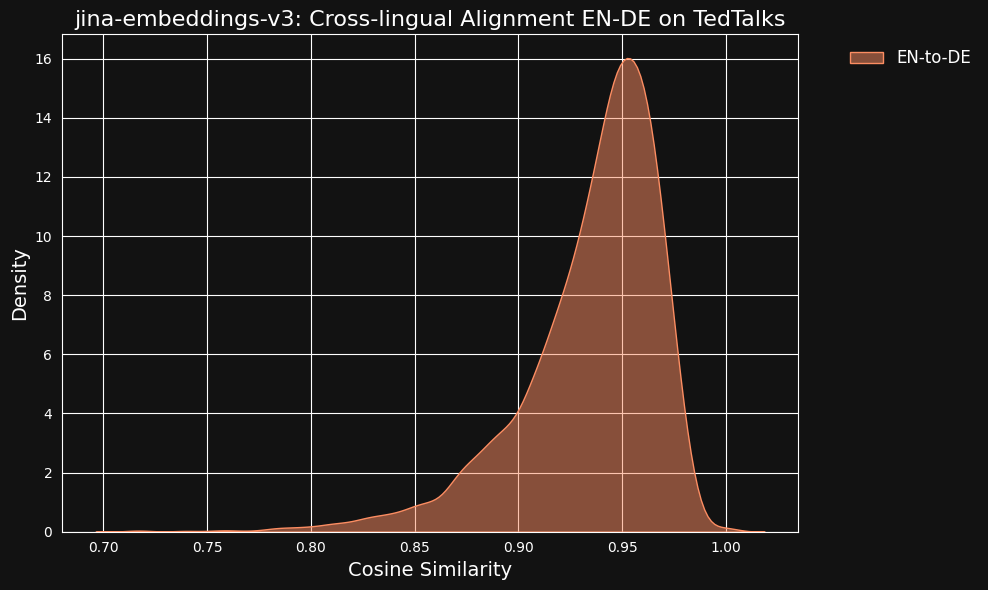
tagWie stark tragen sprachübergreifende Daten zur sprachübergreifenden Angleichung bei?
Die verschwindende Sprachlücke und das hohe Niveau der sprachübergreifenden Leistung scheinen unverhältnismäßig im Vergleich zu dem sehr kleinen Teil der Trainingsdaten, der explizit sprachübergreifend war. Nur 3% der kontrastiven Trainingsdaten lehren das Modell explizit, wie Angleichungen zwischen Sprachen vorzunehmen sind.
Also führten wir einen Test durch, um zu sehen, ob sprachübergreifende Daten überhaupt einen Beitrag leisten.
Ein vollständiges Neutraining von jina-embeddings-v3 ohne sprachübergreifende Daten wäre für ein kleines Experiment unverhältnismäßig teuer, also luden wir das xlm-roberta-base Modell von Hugging Face herunter und trainierten es weiter mit kontrastivem Lernen, wobei wir einen Teil der Daten verwendeten, die wir zum Training von jina-embeddings-v3 verwendet hatten. Wir passten speziell die Menge der sprachübergreifenden Daten an, um zwei Fälle zu testen: Einen ohne sprachübergreifende Daten und einen, bei dem 20% der Paare sprachübergreifend waren. Die Training-Metaparameter können Sie in der untenstehenden Tabelle sehen:
| Backbone | % Cross-Language | Learning Rate | Loss Function | Temperature |
xlm-roberta-base ohne X-language Daten | 0% | 5e-4 | InfoNCE | 0.05 |
xlm-roberta-base mit X-language Daten | 20% | 5e-4 | InfoNCE | 0.05 |
Anschließend evaluierten wir die sprachübergreifende Leistung beider Modelle mit den STS17 und STS22 Benchmarks aus dem MTEB und der Spearman-Korrelation. Die Ergebnisse präsentieren wir unten:
tagSTS17
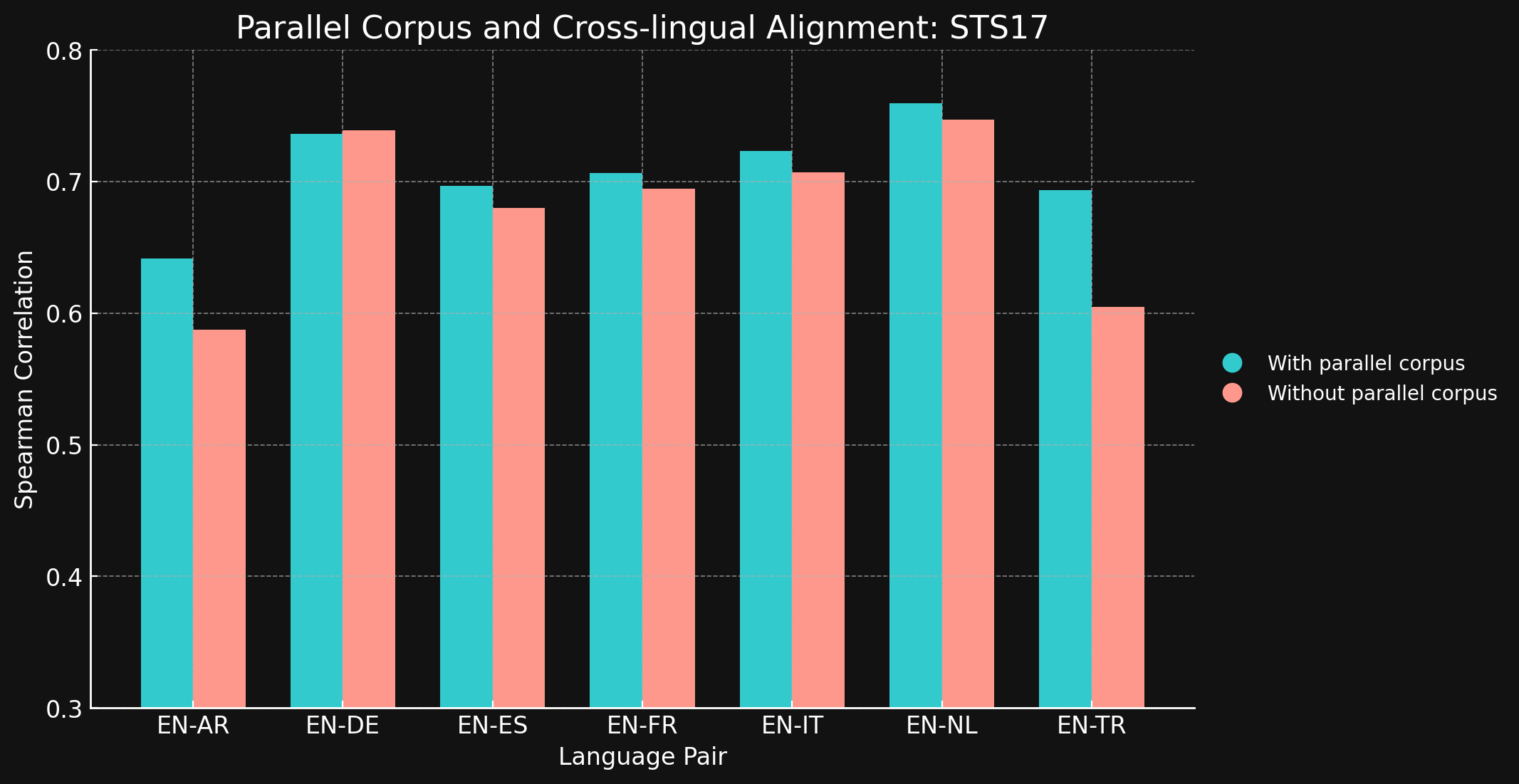
| Language Pair | Mit Parallelkorpora | Ohne Parallelkorpora |
| English ↔ Arabic | 0.6418 | 0.5875 |
| English ↔ German | 0.7364 | 0.7390 |
| English ↔ Spanish | 0.6968 | 0.6799 |
| English ↔ French | 0.7066 | 0.6944 |
| English ↔ Italian | 0.7232 | 0.7070 |
| English ↔ Dutch | 0.7597 | 0.7468 |
| English ↔ Turkish | 0.6933 | 0.6050 |
tagSTS22
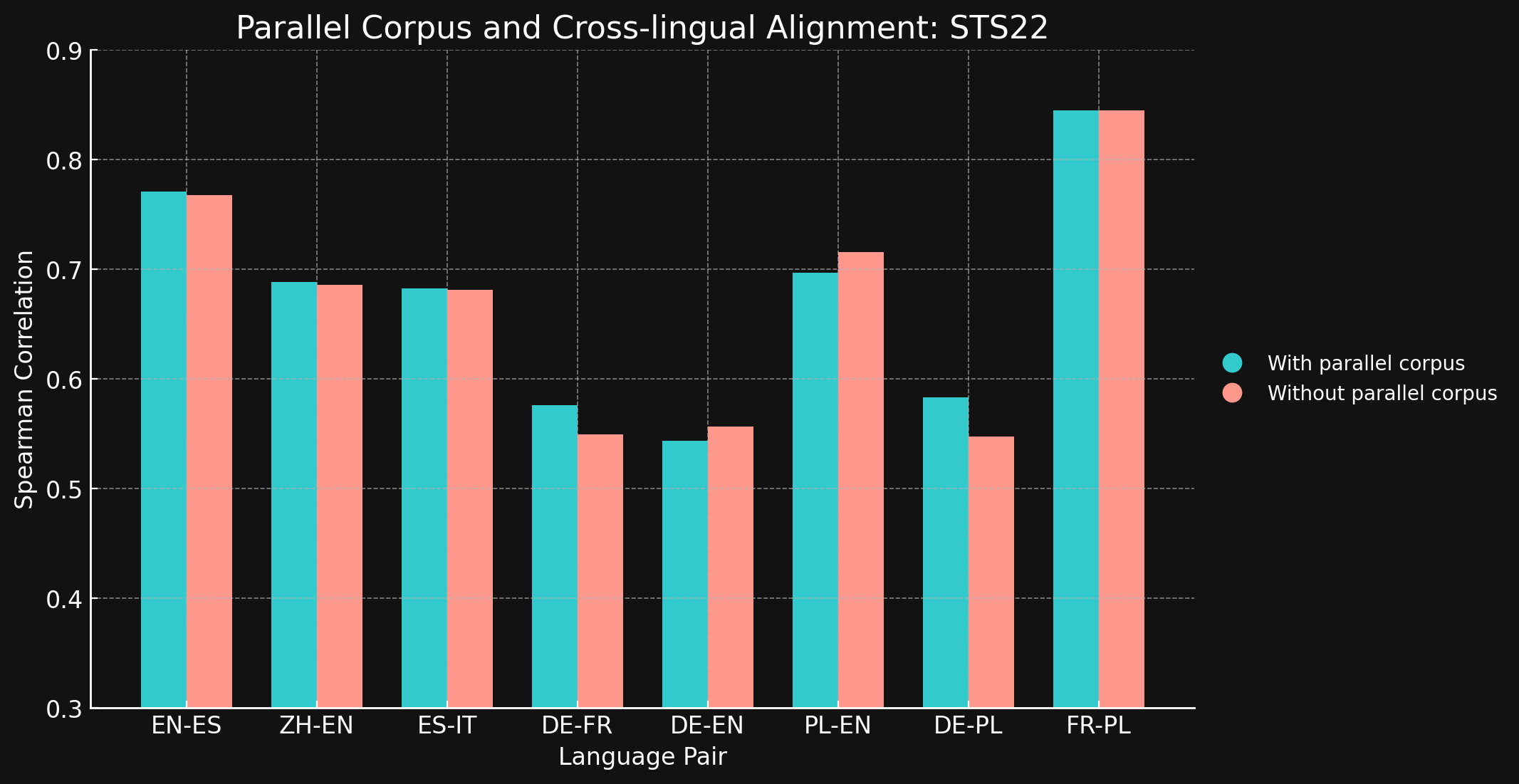
| Sprachpaar | Mit parallelen Korpora | Ohne parallele Korpora |
| English ↔ Spanish | 0.7710 | 0.7675 |
| Simplified Chinese ↔ English | 0.6885 | 0.6860 |
| Spanish ↔ Italian | 0.6829 | 0.6814 |
| German ↔ French | 0.5763 | 0.5496 |
| German ↔ English | 0.5439 | 0.5566 |
| Polish ↔ English | 0.6966 | 0.7156 |
| German ↔ English | 0.5832 | 0.5478 |
| French ↔ Polish | 0.8451 | 0.8451 |
Wir waren überrascht zu sehen, dass bei den meisten der getesteten Sprachpaare sprachübergreifende Trainingsdaten kaum oder gar keine Verbesserung brachten. Es ist schwer zu sagen, ob dies auch bei vollständig trainierten Modellen mit größeren Datensätzen der Fall wäre, aber es deutet darauf hin, dass explizites sprachübergreifendes Training nicht viel bringt.
Beachten Sie jedoch, dass STS17 auch Englisch/Arabisch- und Englisch/Türkisch-Paare enthält. Dies sind beides Sprachen, die in unseren Trainingsdaten deutlich unterrepräsentiert sind. Das verwendete XML-RoBERTa-Modell wurde mit Daten vortrainiert, die nur zu 2,25 % Arabisch und 2,32 % Türkisch waren, deutlich weniger als bei den anderen getesteten Sprachen. Der kleine kontrastive Lerndatensatz, den wir in diesem Experiment verwendeten, enthielt nur 1,7 % Arabisch und 1,8 % Türkisch.
Diese beiden Sprachpaare sind die einzigen getesteten Paare, bei denen das Training mit sprachübergreifenden Daten einen deutlichen Unterschied machte. Wir denken, dass explizite sprachübergreifende Daten bei Sprachen, die in den Trainingsdaten weniger gut repräsentiert sind, effektiver sind, müssen diesen Bereich aber noch weiter erforschen, bevor wir eine endgültige Schlussfolgerung ziehen können. Die Rolle und Wirksamkeit sprachübergreifender Daten beim kontrastiven Training ist ein Bereich, in dem Jina AI aktiv forscht.
tagFazit
Herkömmliche Methoden des Sprach-Pretrainings, wie Masked Language Modeling, hinterlassen eine „Sprachlücke", bei der semantisch ähnliche Texte in verschiedenen Sprachen nicht so eng übereinstimmen wie sie sollten. Wir haben gezeigt, dass das kontrastive Lernverfahren von Jina Embeddings sehr effektiv darin ist, diese Lücke zu reduzieren oder sogar zu eliminieren.
Die Gründe dafür sind nicht vollständig klar. Wir verwenden beim kontrastiven Training explizit sprachübergreifende Textpaare, aber nur in sehr kleinen Mengen, und es ist unklar, welche Rolle sie tatsächlich bei der Sicherstellung hochwertiger sprachübergreifender Ergebnisse spielen. Unsere Versuche, unter kontrollierten Bedingungen einen klaren Effekt nachzuweisen, brachten kein eindeutiges Ergebnis.
Allerdings ist klar, dass jina-embeddings-v3 die Pretraining-Sprachlücke überwunden hat und damit ein leistungsfähiges Werkzeug für mehrsprachige Anwendungen ist. Es ist einsatzbereit für jede Aufgabe, die eine starke, identische Leistung in mehreren Sprachen erfordert.
Sie können jina-embeddings-v3 über unsere Embeddings API (mit einer Million kostenloser Tokens) oder über AWS oder Azure nutzen. Wenn Sie es außerhalb dieser Plattformen oder vor Ort in Ihrem Unternehmen nutzen möchten, beachten Sie bitte, dass es unter CC BY-NC 4.0 lizenziert ist. Kontaktieren Sie uns, wenn Sie an einer kommerziellen Nutzung interessiert sind.
