



In letzter Zeit wurde viel über die Gefahren diskutiert, wie KI-Unternehmen alle Daten aus dem Internet absaugen - ob sie nun die "Erlaubnis" dazu haben oder nicht. Auf das Thema "Erlaubnis" kommen wir später noch zu sprechen - es gibt einen Grund, warum wir das Wort in Anführungszeichen gesetzt haben. Aber was bedeutet es für LLMs, wenn das offene Web komplett ausgeschöpft ist, Content-Anbieter ihre Türen verschließen und es kaum noch neue Daten zum Scrapen gibt?
tagDie Gefahren des KI-Scrapings
KI-Unternehmen behandeln das Internet wie ein All-you-can-eat-Datenbuffet und kümmern sich nicht um Tischmanieren. Man schaue sich nur an, wie Runway YouTube-Videos für das Training ihres Modells erntet (gegen YouTubes Nutzungsbedingungen), wie Anthropic iFixit eine Million Mal am Tag aufruft und wie die New York Times OpenAI und Microsoft wegen der Nutzung urheberrechtlich geschützter Werke verklagt.
Der Versuch, Scraper in Ihrer robots.txt oder in den Nutzungsbedingungen zu blockieren, hilft nicht wirklich. Die Scraper, denen es egal ist, scrapen trotzdem, während die rücksichtsvolleren blockiert werden. Es gibt keinen Anreiz für Scraper, sich fair zu verhalten. Das sehen wir in der aktuellen Studie der Data Provenance Initiative:
Dies ist kein abstraktes Problem - iFixit verliert Geld und bindet DevOps-Ressourcen. ReadTheDocs verursachte über 5.000 Dollar Bandbreitenkosten in nur einem Monat, mit fast 10 TB an einem einzigen Tag, aufgrund missbräuchlicher Crawler. Wenn Sie eine Website betreiben und von einem Crawler getroffen werden, der sich nicht an die Regeln hält? Das könnte das Aus bedeuten.
Was also soll eine Website tun? Wenn sich KI-Unternehmen nicht an die Regeln halten wollen, werden mehr Paywalls entstehen und frei verfügbare Inhalte abnehmen. Das freie Web gibt es nicht mehr. Alles was bleibt ist Pay-to-play.
tagIst Scraping überhaupt legal?
Eine Reihe kleinerer Rechtsordnungen hat ebenfalls festgestellt, dass es legal ist, und nach meinem besten Wissen hat bisher keine es für illegal erklärt.
Das europäische Urheberrecht erlaubt es Inhabern urheberrechtlich geschützter Daten, die Verwendung ihrer Werke für KI-Training einzuschränken, indem sie dies „in geeigneter Weise" anzeigen. Derzeit gibt es keine Anleitung, wie sie dies tun sollten.
Das japanische Urheberrecht beschränkt die Verwendung urheberrechtlich geschützter Materialien, wenn dies „die Interessen des Urheberrechtsinhabers unangemessen beeinträchtigen könnte". Dies bedeutet typischerweise, dass ein Urheberrechtsinhaber nachweisen müsste, wie ein bestimmtes KI-Modell den wirtschaftlichen Wert ihres Werks mindert, um einen Fall aufbauen zu können.
Wir sollten beachten, dass Google, Microsoft, OpenAI, Adobe und Shutterstock angeboten haben, jeden Nutzer ihrer generativen KI-Produkte zu entschädigen, der mit rechtlichen Herausforderungen bezüglich des Urheberrechts konfrontiert wird. Dies ist ein starker Hinweis darauf, dass ihre Anwälte der Meinung sind, dass ihr Handeln nach US-Recht legal ist.
tagWas gefräßiges Scraping für KI bedeutet
Der KI-Scraping-Boom verwandelt das Web in einen digitalen Wilden Westen. Diese Scraper behandeln robots.txt wie Schnee von gestern und bombardieren Websites wie iFixit mit endlosen Anfragen. Das ist nicht nur lästig - es ist potenziell web-zerstörend und zwingt uns, die Funktionsweise des offenen Internets zu überdenken. Oder wie es in naher Zukunft möglicherweise nicht mehr funktionieren wird. Allein aus wirtschaftlicher und sozialer Sicht könnte sich vieles ändern:
Vertrauensverlust: Dieser KI-Fütterungswahn könnte zu einem massiven Vertrauensbruch im Web führen. Stellen Sie sich eine Zukunft vor, in der jede Website Sie mit skeptischem Blick begrüßt und Sie beweisen müssen, dass Sie ein Mensch sind, bevor Sie überhaupt einen Blick auf deren Inhalte werfen können. Wir sprechen von mehr CAPTCHAs, mehr Login-Walls, mehr "Klicken Sie alle Ampeln an"-Tests. Es ist, als würde man versuchen, in eine Speakeasy zu kommen, aber statt eines geheimen Passworts muss man den Türsteher davon überzeugen, dass man keine sehr clevere Maschine ist.
Eingeschränkte von Menschen generierte Inhalte: Content-Ersteller, die bereits vorsichtig sind, dass ihre Arbeit geklaut wird, beginnen, die Luken zu schließen. Wir könnten einen Anstieg von Paywalls, Nur-für-Abonnenten-Bereichen und Content-Sperren sehen. Die Tage des freien Surfens und Lernens könnten zu einer nostalgischen Erinnerung werden, wie Einwahlmodem-Geräusche oder AIM-Away-Messages. Wenn normale Menschen nicht darauf zugreifen können, macht es das für einen abtrünnigen Scraper umso schwieriger, hineinzukommen.
Rechtsfälle: Es könnte Jahre oder sogar Jahrzehnte dauern, bis alle rechtlichen Fragen rund um KI geklärt sind. Wir haben das Internet seit etwa dreißig Jahren, und einige seiner rechtlichen Fragen sind heute noch ungeklärt. Ob Sie nun im Recht sind oder nicht, wenn Sie es sich nicht leisten können, jahrelang vor Gericht herauszufinden, was erlaubt ist und was nicht, haben Sie Grund zur Sorge.
Kleine gehen pleite, Große werden fetter: Diese Scraping-Manie ist nicht nur lästig - sie belastet die Web-Infrastruktur real. Websites, die mit KI-induzierten Verkehrsstaus zu kämpfen haben, müssen möglicherweise auf leistungsfähigere Server aufrüsten, was nicht billig ist. Kleinere Websites und coole Hobbyprojekte könnten aus dem Spiel gedrängt werden, was uns ein Web (und LLM-Trainingsdaten) hinterlässt, das von denen dominiert wird, die groß genug sind, um den Sturm zu überstehen oder Lizenzverträge mit den KI-Unternehmen abzuschließen. Es ist ein "Überleben der Reichsten"-Szenario, das das Internet (und LLM-Wissen) viel weniger vielfältig und interessant machen könnte. Indem sie die Tür zu frei verfügbaren Daten schließen, können sie dann eine Eintrittsgebühr von den KI-Unternehmen verlangen oder einfach an den Höchstbietenden lizenzieren. Kein Geld? Der Türsteher wird Ihnen den Weg zur Tür zeigen.
tagKI-generierte Daten zur Rettung?
Der Daten-Grab erschüttert nicht nur Websites - er bereitet den Boden für eine potenzielle KI-Wissensdürre. Während das offene Web seine Zugbrücken hochzieht, werden KI-Modelle nach frischen, hochwertigen Daten hungern.
Diese Datenknappheit könnte zu einem üblen Fall von KI-Tunnelblick führen. Ohne einen stetigen Strom neuer Informationen riskieren KI-Modelle, zu Echokammern veralteten Wissens zu werden. Stellen Sie sich vor, Sie fragen eine KI nach aktuellen Ereignissen und bekommen Antworten, die klingen, als wären sie vom letzten Jahr - oder schlimmer, aus einem Paralleluniversum, in dem Fakten Urlaub machen.
Wenn von Menschen generierte Daten weggesperrt sind, müssen Unternehmen ihre Trainingsdaten trotzdem irgendwoher bekommen. Ein Beispiel dafür sind synthetische Daten: Daten, die von LLMs erstellt wurden, um andere LLMs zu trainieren. Dies umfasst weit verbreitete Techniken wie Modelldestillation und die Generierung von Trainingsdaten zum Ausgleich von Verzerrungen.

Die Verwendung synthetischer Daten bedeutet, dass man keine Hindernisse überwinden muss, um von Menschen generierte Daten zu lizenzieren, was, wie wir gesehen haben, zunehmend schwieriger wird. Es hilft auch dabei, Dinge auszugleichen - viele Daten im Internet repräsentieren nicht die Vielfalt der realen Welt. Die Generierung synthetischer Daten kann dazu beitragen, ein Modell repräsentativer für die Realität zu machen (oder manchmal auch nicht). Schließlich eliminiert es für Gesundheits- und rechtliche Anwendungsfälle die Notwendigkeit, Daten zu bereinigen, um personenbezogene Informationen zu entfernen.
Die Kehrseite der Medaille ist jedoch, dass zukünftige Modelle auch mit KI-generierten Daten trainiert werden, die Sie wirklich nicht für das Training verwenden möchten, nämlich "Slop": minderwertige KI-generierte Daten, wie ein einst beliebter Tech-Blog, der jetzt minderwertige KI-generierte Artikel unter den Namen seiner ehemaligen Mitarbeiter veröffentlicht, KI-generierte Rezepte für unwahrscheinliche Gerichte wie Crockpot-Mojitos und Bratwurst-Eiscreme oder Garnelen-Jesus, der Facebook übernimmt.
Da dies viel billiger und einfacher zu erstellen ist als gute altmodische handgefertigte Inhalte, überflutet es das Internet rapide.
Basierend auf dem, was wir heute sehen, überholen KI-generierte Inhalte die verfügbaren von Menschen generierten Inhalte. GPT-5 wird (teilweise) mit Daten trainiert werden, die von GPT-4 erstellt wurden. GPT-6 wird wiederum mit Daten trainiert werden, die von GPT-5 erstellt wurden. Und so weiter und so fort.
tagModell-Kollaps und wie man ihn vermeidet
Die Verwendung der eigenen Outputs als Inputs ist sowohl für Menschen als auch für LLMs schlecht. Selbst wenn Sie sehr selektiv sind, wie viele synthetische Daten Sie verwenden und welcher Art, können Sie nicht garantieren, dass Ihr Modell nicht schlechter wird.
Für generative KI-Modelle als Ganzes ist der Qualitäts- und Diversitätsverlust der Outputs experimentell messbar und passiert ziemlich schnell. Bildgenerierende Modelle entwickeln nach wenigen Generationen Anomalien, und in einer Studie antwortete ein großes Sprachmodell, das mit Wikipedia-Daten trainiert wurde und kohärente und akkurate Antworten auf Prompts gab, in der neunten Generation des Trainings mit seinen eigenen Outputs nur noch mit der ständigen Wiederholung der Worte "tailed jackrabbits".
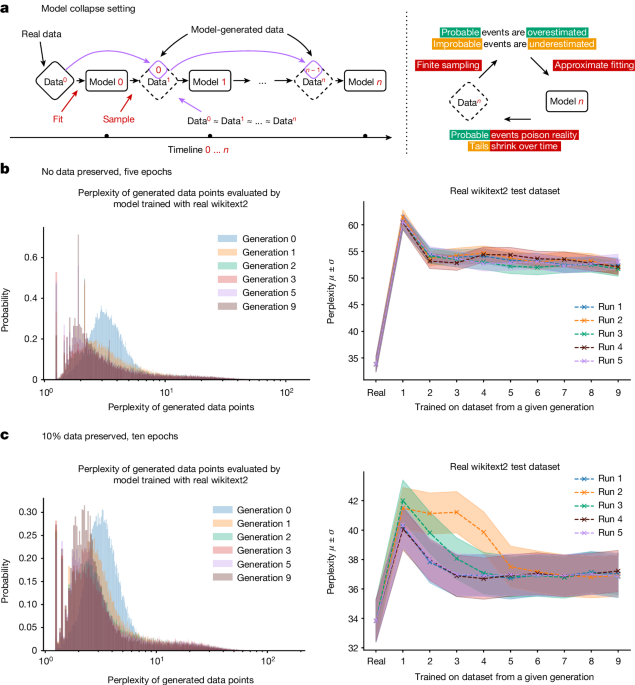
Das ist einfach zu erklären: Ein KI-Modell ist eine Approximation seiner Trainingsdaten. Ein KI-Modell, das mit KI-Modell-Output trainiert wird, ist eine Approximation einer Approximation. Bei jedem Trainingszyklus wird die Differenz zwischen der Approximation und den "wahren" realen Daten immer größer.
Wir nennen dies "Model Collapse".
Da KI-generierte Daten immer weiter verbreitet werden, riskiert das Training neuer Modelle mit aus dem Internet gescrapter Daten eine Verschlechterung der Modellleistung. Wir haben Grund zur Annahme, dass solange die Menge echter, von Menschen erstellter Daten nicht abnimmt, unsere Modelle nicht viel schlechter werden, aber sie werden auch nicht besser. Sie werden jedoch länger zum Trainieren brauchen, wenn wir KI-erstellte Daten nicht von menschengemachten Daten trennen können. Neue Modelle werden teurer in der Herstellung, ohne sich zu verbessern.
Die Ironie ist hier deutlich zu spüren. Der unersättliche Datenhunger der KI könnte zu einer Datenhungersnot führen. Model Autophagy Disorder ist wie BSE (Rinderwahnsinn) für KI: Genau wie die Verfütterung von Rinderabfällen an Kühe zu einer neuen Art von parasitärer Gehirnkrankheit führte, führt das Training von KI mit wachsenden Mengen an KI-Output zu verheerenden mentalen Pathologien.
Die gute Nachricht ist, dass KI die Menschheit nicht ersetzen kann, weil sie unsere Daten braucht. Die schlechte Nachricht ist, dass sie ihr eigenes Wachstum hemmen könnte, indem sie ihre Datenquellen ruiniert.
Um diese absehbare KI-Wissenshungersnot zu vermeiden, müssen wir überdenken, wie wir KI-Modelle trainieren und nutzen. Wir sehen bereits Lösungen wie Retrieval-Augmented Generation, die versucht, KI-Modelle nicht als Quelle faktischer Informationen zu nutzen, sondern sie stattdessen als Werkzeuge zur Bewertung und Reorganisation externer Informationsquellen zu sehen. Ein anderer Weg führt über Spezialisierung, bei der wir Modelle anpassen, um bestimmte Arten von Aufgaben auszuführen, unter Verwendung kuratierter Trainingsdaten, die sich auf enge Domänen konzentrieren. Wir könnten vermeintliche Allzweckmodelle wie ChatGPT durch Spezial-KIs ersetzen: LawLLM, MedLLM, MyLittlePonyLLM und so weiter.
Es gibt andere Möglichkeiten, und es ist schwer zu sagen, welche neuen Techniken Forscher noch entdecken werden. Vielleicht gibt es einen besseren Weg, synthetische Daten zu generieren oder Wege, bessere Modelle aus weniger Daten zu erhalten. Aber es gibt keine Garantie, dass mehr Forschung das Problem lösen wird.
Letztendlich könnte diese Herausforderung die KI-Community dazu zwingen, kreativ zu werden. Schließlich ist Not die Mutter der Erfindung, und eine datenarme KI-Landschaft könnte einige wirklich innovative Lösungen hervorbringen. Wer weiß? Der nächste große Durchbruch in der KI könnte nicht aus mehr Daten kommen, sondern daraus, wie man mehr mit weniger erreicht.
tagWas passiert, wenn nur Megakonzerne sich Scraping leisten können?
Für viele Menschen heute ist das Internet Facebook, Instagram und X, betrachtet durch ein schwarzes Glasrechteck, das sie in der Hand halten. Es ist homogenisiert, "sicher" und wird von Torwächtern kontrolliert, die (durch Richtlinien und ihre Algorithmen) entscheiden, was (und wen) man sieht und was nicht.
Das war nicht immer so. Vor nur ein paar Jahrzehnten hatten wir nutzergenerierte Blogs, unabhängige Websites und vieles mehr. In den Achtzigern gab es Dutzende von konkurrierenden Betriebssystemen und Hardware-Standards. Aber bis in die 2010er Jahre hatten Apple und Microsoft die Oberhand gewonnen und den Trend zur Homogenisierung eingeleitet.
Dasselbe sehen wir bei Webbrowsern, Smartphones und Social-Media-Seiten. Wir beginnen mit einer Explosion von Vielfalt und neuen Ideen, bevor die großen Spieler den Ball an sich reißen und es allen anderen schwer machen mitzuspielen.
Allerdings konnten sich, während diese Spieler ein Monopol hatten, trotzdem einige kleinere Fische durchsetzen. (Nehmen wir Linux und Firefox als Beispiel). Bei LLMs ist es jedoch unwahrscheinlich, dass der "Underdog" erfolgreich sein wird. Wenn kleinen Akteuren die finanziellen Mittel fehlen, um Zugang zu vielfältigen und aktuellen Trainingsdaten zu erhalten, können sie keine hochwertigen Modelle erstellen. Und ohne das, wie können sie im Geschäft bleiben?
Die Giganten haben die Ressourcen, ihre KI-Modelle weiterhin mit einer stetigen Diät frischer Informationen zu füttern, während das weitere Web den Gürtel enger schnallt. Währenddessen müssen sich kleinere Akteure und Startups mit den Resten am Boden des Datenfasses begnügen und sich abmühen, ihre Algorithmen mit abgestandenen Krümeln zu ernähren. Es ist eine Wissenslücke, die sich aufschaukeln könnte. Während die Datenreichen in Bezug auf Erkenntnisse und Fähigkeiten reicher werden, laufen die Datenarmen Gefahr, weiter zurückzufallen, wobei ihre KIs von Tag zu Tag veralteter und weniger wettbewerbsfähig werden. Dabei geht es nicht nur darum, wer das glänzendste KI-Spielzeug hat - es geht darum, wer die Zukunft von Technologie, Handel und sogar unseren Informationszugang gestalten darf. Wir blicken in eine Zukunft, in der eine Handvoll Tech-Giganten die Schlüssel zu den fortschrittlichsten KI-Königreichen halten könnte, während alle anderen aus dem digitalen Mittelalter heraus zusehen müssen.
Bei all den interessanten Inhalten, die lizenziert werden können, ist es unwahrscheinlich, dass ein einziger Megakonzern alles lizenziert, wie Netflix in den alten Zeiten. Erinnern Sie sich? Man abonnierte einen Dienst und bekam jede Show, von der man je geträumt hatte. Heute sind Shows über Hulu, Netflix, Disney+ und wie auch immer HBO Max gerade heißt, verteilt. Manchmal kann eine Show, die man liebt, einfach in der Luft verschwinden. Dies könnte die Zukunft der LLMs sein: Google hat bevorzugten Zugang zu Reddit, während OpenAI Zugang zur Financial Times bekommt. iFixit? Diese Daten gibt es einfach nicht mehr, sie sind nur noch als verstaubte Embeddings gespeichert und werden nie aktualisiert. Statt einem Modell, sie alle zu beherrschen, könnten wir auf Fragmentierung und wechselnde Fähigkeiten blicken, während Lizenzrechte zwischen KI-Anbietern hin und her geschoben werden.
tagFazit
Ob es uns gefällt oder nicht - Scraping wird bleiben. Bereits jetzt errichten Content-Anbieter Barrieren, um den Zugang zu beschränken, während sie die Türen nur für diejenigen öffnen, die sich die Lizenzierung der Inhalte leisten können. Dies schränkt die Ressourcen, von denen ein LLM lernen kann, erheblich ein. Gleichzeitig werden kleinere Unternehmen aus dem Bieterkrieg um lukrative Inhalte verdrängt, während der Rest der Beute zwischen den LLMs der Tech-Giganten aufgeteilt wird. Es ist wie die Post-Netflix-Streaming-Ära, nur diesmal geht es um Wissen.
Während verfügbare von Menschen generierte Daten schwinden, boomt KI-generierter "Datenschrott". Das Training von Modellen damit kann zu einer Verlangsamung der Verbesserung oder sogar zum Modellkollaps führen. Der einzige Ausweg ist, über den Tellerrand hinauszudenken - etwas, wofür Startups mit ihrer Kultur der Innovation und Disruption ideal geeignet sind. Doch genau die Daten, die nur an die großen Player lizenziert werden, sind der Lebenssaft, den solche Startups zum Überleben brauchen.
Indem sie den fairen Zugang zu Daten einschränken, ersticken die Mega-Konzerne nicht nur den Wettbewerb - sie würgen die Zukunft der KI selbst ab und erdrosseln genau die Innovation, die uns über dieses potenzielle digitale dunkle Zeitalter hinausbringen könnte.
Die KI-Revolution ist nicht die Zukunft, KI ist Gegenwart. In den Worten von William Gibson: "[D]ie Zukunft ist bereits hier, sie ist nur nicht gleichmäßig verteilt." Sie kann leicht noch ungleichmäßiger verteilt werden.
