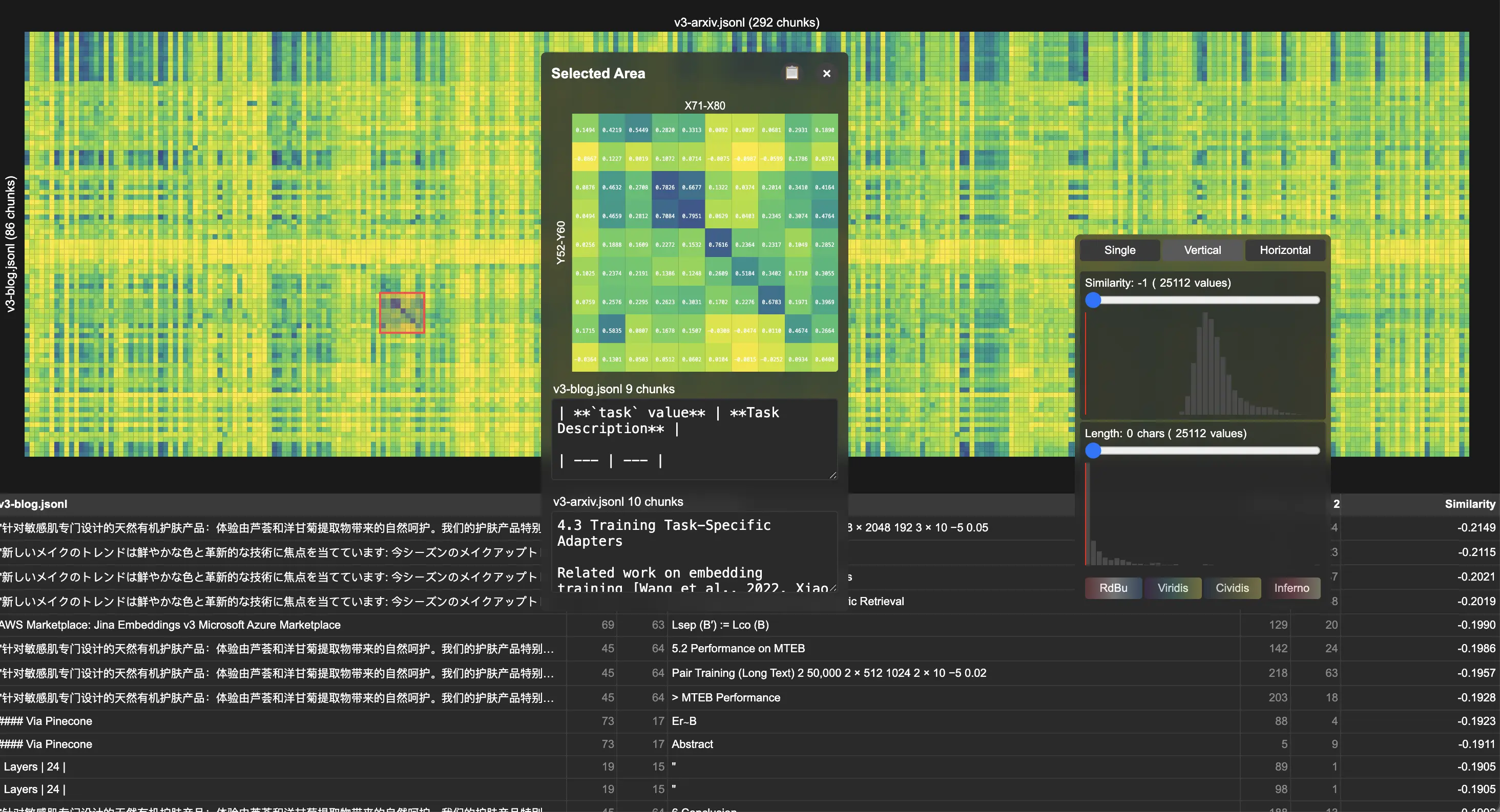


Eine der interessanten Fragen, die uns gestellt werden, lautet: "Wie überprüfen Sie Ihre Vektormodelle (Embeddings)?" Sicher, es gibt MTEB für eine seriöse und quantitative Bewertung anhand öffentlicher Benchmarks, aber was tun Sie bei Open-Domain- oder neuen Problemen? Heute möchten wir ein kleines internes Tool vorstellen, das wir für das Debuggen und die Visualisierung verwenden. Sie können es als unser Vibe-Testing-Toolkit bezeichnen. Wir nennen es Correlations und es ist Open Source auf GitHub verfügbar.
tagDesign
Correlations generiert interaktive Heatmaps, in denen jede Zelle die Kosinusähnlichkeit zwischen zwei Elementen anzeigt – egal, ob es sich um Chunks aus derselben oder verschiedenen Dokumentsammlungen, Modalitäten, Hyperparametern oder Modellen handelt. Es unterstützt verschiedene Interaktionen:
- Hover-Inspektion: Originaltext/-bild und Ähnlichkeitswerte für einzelne Zellenpaare
- Bereichsauswahl: Interaktive Bereichsauswahl für die fokussierte Analyse von Ähnlichkeitsmustern
- Schwellenwertfilterung: Ähnlichkeitswert- und Textlängenfilter zur Reduzierung von Rauschen
Das Tool arbeitet über eine zweistufige Pipeline:
npm run embed: Verwenden der Jina Embeddings API mit konfigurierbaren Chunking-Strategien (Zeilenumbruch, Interpunktion, Zeichenbasiert oder Regex-Muster)npm run corr: Browserbasierte Benutzeroberfläche, die Korrelations-Heatmaps mit Echtzeit-Interaktivität bereitstellt
So legen Sie los:
npm install
export JINA_API_KEY=your_jina_key_here
npm run embed -- https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model -o v3-blog.jsonl -t retrieval.query
npm run embed -- https://arxiv.org/pdf/2409.10173 -o v3-arxiv.jsonl -t retrieval.passage
npm run corr -- v3-blog.jsonl v3-arxiv.jsonlJINA_API_KEY wird zum Einbetten und Lesen von Inhalten von einer URL verwendet, wenn dies erforderlich ist. Das Lesen aus einer lokalen Textdatei wird selbstverständlich unterstützt. Sie können auch Ihre eigenen Vektormodelle (Embeddings) mitbringen und npm run corr nur zur Visualisierung ausführen. In diesem Fall benötigen Sie keine JINA_API_KEY. Das Tool unterstützt sowohl die Selbstkorrelationsanalyse (innerhalb einer einzelnen Sammlung) als auch die Kreuzkorrelationsanalyse (zwischen zwei Sammlungen).
tagAnwendungsfälle
tagInhaltsdeduplizierung und Alignment-Analyse
Wir demonstrieren den Nutzen des Tools anhand der Analyse unserer jina-embeddings-v3-Veröffentlichungen. Durch den Vergleich von dem wissenschaftlichen Artikel mit der Versionshinweis zeigte die Visualisierung deutliche diagonale Muster in der Korrelations-Heatmap, die eine starke Chunk-to-Chunk-Übereinstimmung zwischen Dokumenten anzeigten. Eine detaillierte Untersuchung zeigte eine systematische Wiederverwendung von Inhalten, insbesondere in technischen Abschnitten, in denen LoRA-Aufgabentypen beschrieben werden.
tagValidierung von Zitaten und Referenzen
Das Tool erweist sich als wertvoll für die Validierung der Zitiergenauigkeit in Retrieval-Augmented-Generation-Systemen, wo es entscheidend ist, zu überprüfen, ob abgerufene Passagen generierte Behauptungen tatsächlich unterstützen. Die ähnlichkeitsbasierte Analyse ist ein leistungsstarkes und intuitives Tool zum Erkunden großer Datensätze, beispielsweise um Muster aufzudecken, indem Elemente nach Ähnlichkeit gruppiert werden.
tagChunking-Strategie-Erkundung
Spätes Chunking und andere Segmentierungsstrategien können evaluiert werden, indem untersucht wird, wie sich verschiedene Ansätze auf die semantische Kohärenz innerhalb und zwischen Textsegmenten auswirken. Die Visualisierung hilft, den Effekt des späten Chunkings und die optimalen Chunk-Grenzen zu identifizieren, indem sie Ähnlichkeitsmuster aufzeigt, die mit der semantischen Struktur übereinstimmen.
tagCrossmodale Analyse
Das Tool geht über Text hinaus und unterstützt auch Bild-Vektormodelle (Embeddings) über jina-clip-v2, wodurch die Analyse von Text-Bild-Korrelationsmustern für multimodale Anwendungen ermöglicht wird.
tagVerwandte Arbeiten zur Visualisierung von Vektormodellen (Embedding)
Die Herausforderung der Interpretierbarkeit ist besonders akut, wenn mit hochdimensionalen Vektormodellen (Embeddings) gearbeitet wird. Die Landschaft der Techniken zur Visualisierung von Vektormodellen (Embedding) hat sich erheblich weiterentwickelt, wobei verschiedene Ansätze wie folgt kategorisiert werden können:
- Dimensionsreduktionsbasiert: Traditionelle Ansätze mit PCA, t-SNE, UMAP, die hochdimensionale Räume auf 2D/3D projizieren
- Interaktionsbasierte Erkundung: Tools wie Parallax und TextEssence, die eine direkte Manipulation und Erkundung ermöglichen
- Domänenspezifische Lösungen: Spezialisierte Tools wie Clustergrammer für biologische Daten
- Direkte Ähnlichkeitsvisualisierung: Unser Ansatz und ähnliche Heatmap-basierte Methoden, die vollständige relationale Informationen erhalten
| Methode | Ansatz | Anwendungsfälle |
|---|---|---|
| Correlations | Direkte paarweise Ähnlichkeits-Heatmaps | Textähnlichkeits-Debugging, Alignment-Analyse |
| Embedding Projector | PCA, t-SNE und benutzerdefinierte lineare Projektionen | Interaktive Visualisierung und Interpretation |
| Parallax | Algebraische Formeln für die semantische Erkundung | Verständnis semantischer Beziehungen |
| TextEssence | Vergleichende Korpusanalyse | Diachrone Analyse, Korpusvergleich |
| Nomic Atlas | Cloudbasierte skalierbare Visualisierung | Groß angelegte Datensätze, Zusammenarbeit |
| Clustergrammer | Interaktive Heatmap mit Clustering | Hochdimensionale biologische Daten |
| t-SNE | Nichtlineare Cluster-Visualisierung | Modelldebugging, Verwechslungsidentifizierung |
| UMAP | Erhaltung lokaler und globaler Strukturen | Mittelgroße bis große Datensätze, allgemeine Analyse |
| PCA | Lineare Dimensionsreduktion | Erste Erkundung, Baseline-Vergleich |
tagEinschränkungen punktweiser Ansätze
Bestehende Visualisierungstools konzentrieren sich hauptsächlich auf punktweise Darstellungen in 2D-Räumen, wodurch wichtige Informationen über paarweise Beziehungen verloren gehen können. Darüber hinaus sind die meisten Tools für die Analyse einzelner Vektormodellräume (Embedding) konzipiert und nicht für die vergleichende Bewertung zwischen verschiedenen Quellen, Modalitäten oder Vektormodellierungsstrategien (Embedding) (z. B. spätes Chunking ein vs. aus).
Wir sind beispielsweise kürzlich bei Jina auf zwei Anwendungsfälle gestoßen. Der erste betrifft die Gegenprüfung von Zitaten in DeepSearch, wo wir den generierten Bericht mit den Originalausschnitten aus dem Referenzmaterial abgleichen müssen. Der zweite ist die multimodale Suche, bei der wir die Bild-Text- und Bild-Bild-Ausrichtung auf neuen, unbeschrifteten Daten überprüfen müssen. In beiden Fällen müssen wir die Beziehungen zwischen zwei Sammlungen von Vektormodellen (Embeddings) untersuchen. Daher verwenden wir Correlations, um ein Gefühl dafür zu bekommen, wie gut die Übereinstimmungen übereinstimmen, und um zu validieren, ob die höchsten Korrelationen konsistent mit den korrekten Übereinstimmungen übereinstimmen.
tagFazit
Über die bloße Überprüfung der Stimmung hinaus kann correlations tiefere Einblicke in semantische Beziehungen bieten. Als Ausgangspunkt können verschiedene Schlüsselstatistiken aus der Korrelationsmatrix extrahiert werden:
- Matrixdichte: Der Anteil der Korrelationen, die über den angegebenen Schwellenwerten liegen und die den gesamten semantischen Zusammenhalt anzeigen
- Eigenwertverteilung: Die Hauptkomponentenanalyse zeigt die dominanten Muster in der Ähnlichkeitsstruktur
- Matrixrang: Gibt die effektive Dimensionalität der Ähnlichkeitsbeziehungen an
- Konditionszahl: Misst die numerische Stabilität und potenzielle Multikollinearitätsprobleme
Eine fortgeschrittene Analyse kann auch die Extraktion aussagekräftiger Submatrizen beinhalten, die kohärente semantische Regionen darstellen. Das Extrahieren der maximalen Hauptteilmatrix k-ter Ordnung aus einer realen Matrix n-ter Ordnung ist ein typisches kombinatorisches Optimierungsproblem, das die am stärksten korrelierten Segmente identifizieren kann.





