

Ich habe mich kürzlich mit DSPy beschäftigt, einem hochmodernen Framework der Stanford NLP-Gruppe, das darauf abzielt, Language Model (LM) Prompts algorithmisch zu optimieren. In den letzten drei Tagen habe ich einige erste Eindrücke und wertvolle Erkenntnisse über DSPy gesammelt. Beachten Sie, dass meine Beobachtungen nicht die offizielle Dokumentation von DSPy ersetzen sollen. Ich empfehle sogar dringend, ihre Dokumentation und README mindestens einmal zu lesen, bevor Sie sich in diesen Beitrag vertiefen. Meine Ausführungen hier spiegeln ein vorläufiges Verständnis von DSPy wider, nachdem ich einige Tage seine Möglichkeiten erkundet habe. Es gibt mehrere fortgeschrittene Funktionen wie DSPy Assertions, Typed Predictor und LM-Gewichtsanpassung, die ich noch nicht gründlich erforscht habe.
 stanfordnlp
stanfordnlpTrotz meines Hintergrunds bei Jina AI, das sich hauptsächlich auf die Search-Grundlagen konzentriert, wurde mein Interesse an DSPy nicht direkt durch sein Potenzial im Retrieval-Augmented Generation (RAG) geweckt. Stattdessen hat mich die Möglichkeit fasziniert, DSPy für automatisches Prompt-Tuning zu nutzen, um bestimmte Generierungsaufgaben zu lösen.
Wenn Sie neu bei DSPy sind und einen zugänglichen Einstiegspunkt suchen, oder wenn Sie mit dem Framework vertraut sind, aber die offizielle Dokumentation verwirrend oder überwältigend finden, ist dieser Artikel für Sie gedacht. Ich entscheide mich auch dafür, mich nicht streng an DSPys Idiom zu halten, das für Neulinge einschüchternd erscheinen mag. Lassen Sie uns nun tiefer eintauchen.
tagWas mir an DSPy gefällt
tagDSPy schließt den Kreislauf des Prompt Engineering
Was mich an DSPy am meisten begeistert, ist sein Ansatz, den Kreislauf des Prompt-Engineering-Zyklus zu schließen und einen oft manuellen, handgefertigten Prozess in einen strukturierten, klar definierten Machine-Learning-Workflow zu verwandeln: d.h. Datensätze vorbereiten, Modell definieren, trainieren, evaluieren und testen. In meinen Augen ist dies der revolutionärste Aspekt von DSPy.
Auf meinen Reisen in der Bay Area und in Gesprächen mit vielen Startup-Gründern, die sich auf LLM-Evaluation konzentrieren, bin ich häufig auf Diskussionen über Metriken, Halluzinationen, Beobachtbarkeit und Compliance gestoßen. Diese Gespräche gehen jedoch oft nicht zu den kritischen nächsten Schritten über: Was machen wir mit all diesen Metriken in der Hand? Kann das Anpassen der Formulierung in unseren Prompts, in der Hoffnung, dass bestimmte magische Wörter (z.B. "meine Oma stirbt") unsere Metriken verbessern könnten, als strategischer Ansatz betrachtet werden? Diese Frage blieb von vielen LLM-Evaluations-Startups unbeantwortet, und auch ich konnte sie nicht angehen - bis ich DSPy entdeckte. DSPy führt eine klare, programmatische Methode zur Optimierung von Prompts basierend auf spezifischen Metriken ein, oder sogar zur Optimierung der gesamten LLM-Pipeline, einschließlich Prompts und LLM-Gewichten.
Harrison, der CEO von LangChain, und Logan, der ehemalige OpenAI Head of Developer Relations, haben beide im Unsupervised Learning Podcast erklärt, dass 2024 voraussichtlich ein entscheidendes Jahr für die LLM-Evaluation sein wird. Aus diesem Grund glaube ich, dass DSPy mehr Aufmerksamkeit verdient als es derzeit bekommt, da DSPy das entscheidende fehlende Puzzlestück liefert.
tagDSPy trennt Logik von textueller Darstellung
Ein weiterer Aspekt von DSPy, der mich beeindruckt, ist, dass es Prompt Engineering in ein reproduzierbares und LLM-unabhängiges Modul umwandelt. Um das zu erreichen, trennt es die Logik vom Prompt und schafft eine klare Trennung zwischen der Logik und der textuellen Darstellung, wie unten dargestellt.
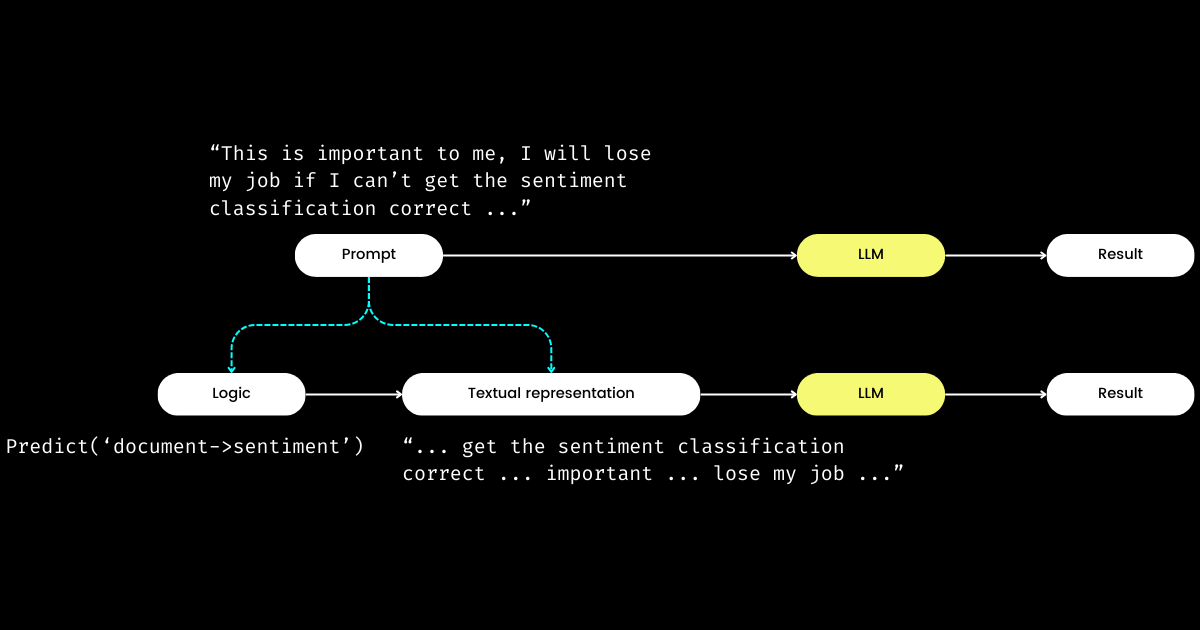
dspy.Module) und ihrer textuellen Darstellung. Die Logik ist unveränderlich, reproduzierbar, testbar und LLM-unabhängig. Die textuelle Darstellung ist lediglich die Konsequenz der Logik.DSPys Konzept der Logik als unveränderliche, testbare und LLM-unabhängige "Ursache", mit textueller Darstellung lediglich als deren "Konsequenz", mag zunächst verwirrend erscheinen. Dies gilt besonders angesichts der weit verbreiteten Überzeugung, dass "die Zukunft der Programmiersprache die natürliche Sprache ist". Wenn man die Idee vertritt, dass "Prompt Engineering die Zukunft ist", könnte man beim Kennenlernen von DSPys Designphilosophie einen Moment der Verwirrung erleben. Entgegen der Erwartung einer Vereinfachung führt DSPy eine Reihe von Modulen und Signatur-Syntaxen ein, die das natürlichsprachliche Prompting scheinbar zur Komplexität der C-Programmierung zurückführen!
Aber warum dieser Ansatz? Mein Verständnis ist, dass im Kern des Prompt-Programmierens die grundlegende Logik liegt, wobei die Kommunikation als Verstärker dient, der ihre Effektivität potenziell verbessern oder verschlechtern kann. Die Anweisung "Do sentiment classification" repräsentiert die Kernlogik, während ein Satz wie "Follow these demonstrations or I will fire you" eine Art ist, diese zu kommunizieren. Ähnlich wie bei realen Interaktionen entstehen Schwierigkeiten bei der Aufgabenbewältigung oft nicht aus fehlerhafter Logik, sondern aus problematischer Kommunikation. Dies erklärt, warum viele, besonders Nicht-Muttersprachler, Prompt Engineering als herausfordernd empfinden. Ich habe beobachtet, wie hochkompetente Softwareingenieure in meinem Unternehmen mit Prompt Engineering kämpfen, nicht wegen mangelnder Logik, sondern weil sie nicht "den richtigen Ton treffen". Durch die Trennung der Logik vom Prompt ermöglicht DSPy die deterministische Programmierung von Logik über dspy.Module, sodass sich Entwickler auf die Logik konzentrieren können, wie sie es in der traditionellen Entwicklung tun würden, unabhängig vom verwendeten LLM.
Wenn sich also Entwickler auf die Logik konzentrieren, wer kümmert sich dann um die textuelle Darstellung? DSPy übernimmt diese Rolle und nutzt Ihre Daten und Evaluationsmetriken, um die textuelle Darstellung zu verfeinern - von der Bestimmung des narrativen Fokus bis zur Optimierung von Hinweisen und der Auswahl guter Demonstrationen. Bemerkenswerterweise kann DSPy sogar Evaluationsmetriken verwenden, um die LLM-Gewichte feinzutunen!
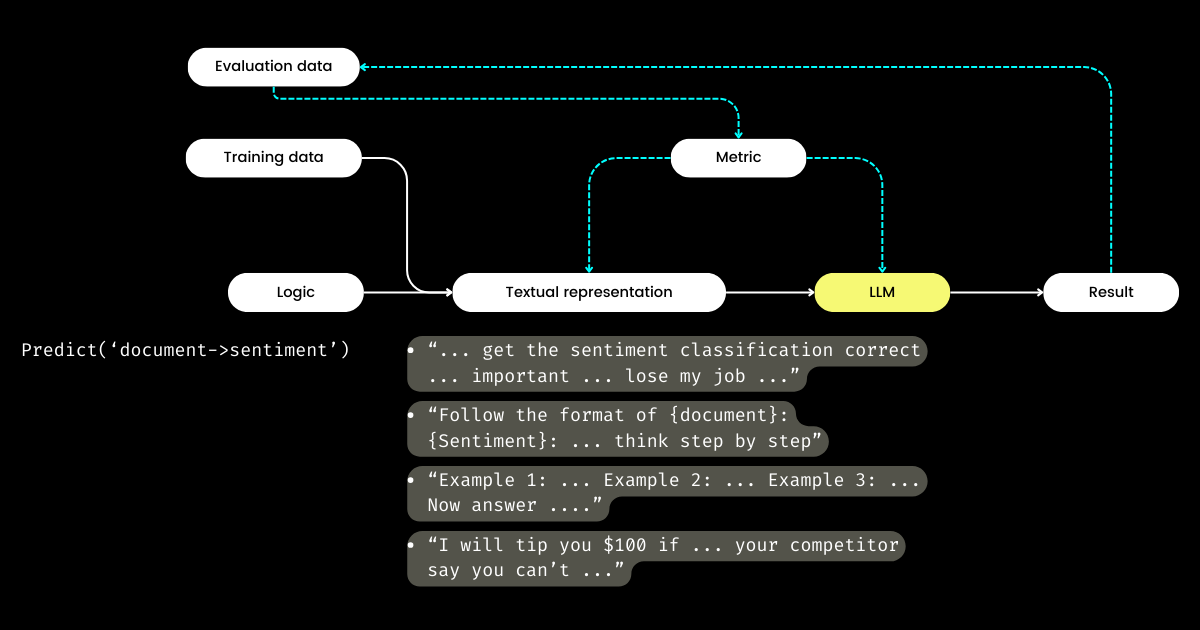
Für mich unterstreichen DSPys Hauptbeiträge - das Schließen des Kreislaufs von Training und Evaluation im Prompt Engineering und die Trennung von Logik und textueller Darstellung - seine potenzielle Bedeutung für LLM/Agent-Systeme. Eine ambitionierte Vision, aber definitiv notwendig!
tagWas DSPy meiner Meinung nach verbessern kann
Erstens präsentiert DSPy für Neueinsteiger eine steile Lernkurve aufgrund seiner Idiome. Begriffe wie signature, module, program, teleprompter, optimization und compile können überwältigend sein. Selbst für diejenigen, die im Prompt Engineering versiert sind, kann die Navigation durch diese Konzepte innerhalb von DSPy ein herausforderndes Labyrinth sein.
Diese Komplexität spiegelt meine Erfahrung mit Jina 1.0 wider, wo wir eine Reihe von Konzepten wie chunk, document, driver, executor, pea, pod, querylang und flow einführten (wir haben sogar niedliche Sticker entworfen, um den Nutzern beim Merken zu helfen!).






Die meisten dieser frühen Konzepte wurden in späteren Jina-Überarbeitungen entfernt. Heute haben nur Executor, Document und Flow "die große Säuberung" überlebt. Wir haben in Jina 3.0 ein neues Konzept, Deployment, hinzugefügt; das gleicht die Sache wieder aus. 🤷
Dieses Problem ist nicht einzigartig für DSPy oder Jina; erinnern Sie sich an die unzähligen Konzepte und Abstraktionen, die TensorFlow zwischen den Versionen 0.x und 1.x einführte. Ich glaube, dieses Problem tritt häufig in den frühen Phasen von Software-Frameworks auf, wo es einen Drang gibt, akademische Notationen direkt im Codebase widerzuspiegeln, um maximale Genauigkeit und Reproduzierbarkeit zu gewährleisten. Allerdings schätzen nicht alle Nutzer solch granulare Abstraktionen, wobei die Präferenzen von dem Wunsch nach einfachen Einzeilern bis hin zu Forderungen nach größerer Flexibilität reichen. Ich habe dieses Thema der Abstraktion in Software-Frameworks ausführlich in einem Blog-Beitrag von 2020 diskutiert, den interessierte Leser vielleicht aufschlussreich finden.


Zweitens lässt die Dokumentation von DSPy manchmal in Bezug auf Konsistenz zu wünschen übrig. Begriffe wie module und program, teleprompter und optimizer, oder optimize und compile (manchmal auch als training oder bootstrapping bezeichnet) werden austauschbar verwendet, was zur Verwirrung beiträgt. Folglich verbrachte ich meine ersten Stunden mit DSPy damit, genau zu entschlüsseln, was es optimizes und was der Prozess des bootstrapping beinhaltet.
Trotz dieser Hürden werden Sie wahrscheinlich, wenn Sie tiefer in DSPy eintauchen und die Dokumentation erneut durchgehen, Momente der Klarheit erleben, in denen alles anfängt, Sinn zu ergeben, und die Verbindungen zwischen seiner einzigartigen Terminologie und den vertrauten Konstrukten aus Frameworks wie PyTorch deutlich werden. Allerdings hat DSPy zweifellos Verbesserungspotenzial für zukünftige Versionen, insbesondere um das Framework für Prompt-Engineers ohne PyTorch-Hintergrund zugänglicher zu machen.
tagHäufige Stolpersteine für DSPy-Neulinge
In den folgenden Abschnitten habe ich eine Liste von Fragen zusammengestellt, die anfangs meinen Fortschritt mit DSPy behinderten. Mein Ziel ist es, diese Erkenntnisse zu teilen, in der Hoffnung, dass sie ähnliche Herausforderungen für andere Lernende klären können.
tagWas sind teleprompter, optimization und compile? Was genau wird in DSPy optimiert?
In DSPy ist "Teleprompters" der Optimizer (und es sieht so aus, als würde @lateinteraction die Dokumentation und den Code überarbeiten, um dies zu klären). Die compile-Funktion agiert im Zentrum dieses Optimizers, ähnlich wie der Aufruf von optimizer.optimize(). Denken Sie daran als DSPy-Äquivalent zum Training. Dieser compile()-Prozess zielt darauf ab, folgendes zu optimieren:
- die Few-Shot-Demonstrationen,
- die Anweisungen,
- die Gewichte des LLM
Allerdings werden die meisten DSPy-Tutorials für Anfänger nicht auf die Gewichts- und Anweisungsoptimierung eingehen, was zur nächsten Frage führt.
tagWorum geht es bei bootstrap in DSPy?
Bootstrap bezieht sich auf die Erstellung selbst generierter Demonstrationen für Few-Shot In-Context Learning, ein entscheidender Teil des compile()-Prozesses (d.h. Optimierung/Training wie oben erwähnt). Diese Few-Shot-Demos werden aus benutzerdefinierten gelabelten Daten generiert; und eine Demo besteht oft aus Input, Output, Begründung (z.B. in Chains of Thought) und Zwischen-Inputs & -Outputs (für mehrstufige Prompts). Natürlich sind qualitativ hochwertige Few-Shot-Demos der Schlüssel zur Outputexzellenz. Dafür erlaubt DSPy benutzerdefinierte Metrik-Funktionen, um sicherzustellen, dass nur Demos ausgewählt werden, die bestimmte Kriterien erfüllen, was zur nächsten Frage führt.
tagWas ist die DSPy Metrik-Funktion?
Nach praktischer Erfahrung mit DSPy bin ich zu der Überzeugung gelangt, dass die Metrik-Funktion weit mehr Beachtung verdient als in der aktuellen Dokumentation. Die Metrik-Funktion in DSPy spielt eine entscheidende Rolle in beiden Phasen, Evaluation und Training, und fungiert dank ihrer impliziten Natur (gesteuert durch trace=None) auch als "Loss"-Funktion:
def keywords_match_jaccard_metric(example, pred, trace=None):
# Jaccard similarity between example keywords and predicted keywords
A = set(normalize_text(example.keywords).split())
B = set(normalize_text(pred.keywords).split())
j = len(A & B) / len(A | B)
if trace is not None:
# act as a "loss" function
return j
return j > 0.8 # act as evaluationDieser Ansatz unterscheidet sich deutlich vom traditionellen maschinellen Lernen, wo die Loss-Funktion normalerweise kontinuierlich und differenzierbar ist (z.B. Hinge/MSE), während die Evaluationsmetrik völlig anders und diskret sein kann (z.B. NDCG). In DSPy sind die Evaluations- und Loss-Funktionen in der Metrik-Funktion vereint, die diskret sein kann und meist einen booleschen Wert zurückgibt. Die Metrik-Funktion kann auch ein LLM integrieren! Im folgenden Beispiel habe ich einen Fuzzy Match mit LLM implementiert, um zu bestimmen, ob der vorhergesagte Wert und die Goldstandard-Antwort in der Größenordnung ähnlich sind, z.B. würden "1 Million Dollar" und "$1M" true zurückgeben.
class Assess(dspy.Signature):
"""Assess the if the prediction is in the same magnitude to the gold answer."""
gold_answer = dspy.InputField(desc='number, could be in natural language')
prediction = dspy.InputField(desc='number, could be in natural language')
assessment = dspy.OutputField(desc='yes or no, focus on the number magnitude, not the unit or exact value or wording')
def same_magnitude_correct(example, pred, trace=None):
return dspy.Predict(Assess)(gold_answer=example.answer, prediction=pred.answer).assessment.lower() == 'yes'So leistungsfähig sie auch ist, die Metrik-Funktion beeinflusst die DSPy Benutzererfahrung maßgeblich, indem sie nicht nur die finale Qualitätsbewertung bestimmt, sondern auch die Optimierungsergebnisse beeinflusst. Eine gut entwickelte Metrik-Funktion kann zu optimierten Prompts führen, während eine schlecht gestaltete zum Scheitern der Optimierung führen kann. Wenn Sie ein neues Problem mit DSPy angehen, werden Sie möglicherweise genauso viel Zeit mit dem Entwickeln der Logik (d.h. DSPy.Module) wie mit der Metrik-Funktion verbringen. Diese doppelte Fokussierung auf Logik und Metriken kann für Neulinge entmutigend sein.
tag"Bootstrapped 0 full traces after 20 examples in round 0" was bedeutet das?
Diese Meldung, die während compile() leise erscheint, verdient Ihre höchste Aufmerksamkeit, da sie im Wesentlichen bedeutet, dass die Optimierung/Kompilierung fehlgeschlagen ist und der Prompt, den Sie erhalten, nicht besser ist als einfaches Few-Shot-Learning. Was läuft schief? Ich habe einige Tipps zusammengefasst, die Ihnen beim Debugging Ihres DSPy-Programms helfen, wenn Sie auf diese Meldung stoßen:
Ihre Metrik-Funktion ist fehlerhaft
Ist die Funktion your_metric, die in BootstrapFewShot(metric=your_metric) verwendet wird, korrekt implementiert? Führen Sie einige Unit-Tests durch. Gibt your_metric jemals True zurück, oder gibt sie immer False zurück? Beachten Sie, dass die Rückgabe von True entscheidend ist, da dies das Kriterium für DSPy ist, um das Bootstrapping-Beispiel als "erfolgreich" zu betrachten. Wenn Sie jede Auswertung als True zurückgeben, wird jedes Beispiel im Bootstrapping als "Erfolg" gewertet! Das ist natürlich nicht ideal, aber so können Sie die Strenge der Metrik-Funktion anpassen, um das "Bootstrapped 0 full traces" Ergebnis zu ändern. Beachten Sie, dass, obwohl DSPy dokumentiert, dass Metriken auch Skalare zurückgeben können, ich nach Durchsicht des zugrunde liegenden Codes dies für Anfänger nicht empfehlen würde.
Ihre Logik (DSPy.Module) ist fehlerhaft
Wenn die Metrik-Funktion korrekt ist, müssen Sie überprüfen, ob Ihre Logik dspy.Module korrekt implementiert ist. Überprüfen Sie zunächst, ob die DSPy signature für jeden Schritt korrekt zugewiesen ist. Inline-Signatures wie dspy.Predict('question->answer') sind einfach zu verwenden, aber aus Qualitätsgründen empfehle ich dringend die Implementierung mit klassenbasierten Signatures. Fügen Sie insbesondere einige beschreibende Docstrings zur Klasse hinzu, füllen Sie die desc-Felder für InputField und OutputField aus - all dies gibt dem LM Hinweise zu jedem Feld. Unten habe ich zwei mehrstufige DSPy.Module zur Lösung von Fermi-Problemen implementiert, eines mit Inline-Signature, eines mit klassenbasierter Signature.
class FermiSolver(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict('question -> initial_guess')
self.step2 = dspy.Predict('question, initial_guess -> calculated_estimation')
self.step3 = dspy.Predict('question, initial_guess, calculated_estimation -> variables_and_formulae')
self.step4 = dspy.ReAct('question, initial_guess, calculated_estimation, variables_and_formulae -> gathering_data')
self.step5 = dspy.Predict('question, initial_guess, calculated_estimation, variables_and_formulae, gathering_data -> answer')
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Fermi-Problemlöser nur mit Inline-Signature
class FermiStep1(dspy.Signature):
question = dspy.InputField(desc='Fermi problems involve the use of estimation and reasoning')
initial_guess = dspy.OutputField(desc='Have a guess – don't do any calculations yet')
class FermiStep2(FermiStep1):
initial_guess = dspy.InputField(desc='Have a guess – don't do any calculations yet')
calculated_estimation = dspy.OutputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
class FermiStep3(FermiStep2):
calculated_estimation = dspy.InputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
variables_and_formulae = dspy.OutputField(desc='Write a formula or procedure to solve your problem')
class FermiStep4(FermiStep3):
variables_and_formulae = dspy.InputField(desc='Write a formula or procedure to solve your problem')
gathering_data = dspy.OutputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
class FermiStep5(FermiStep4):
gathering_data = dspy.InputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
answer = dspy.OutputField(desc='the final answer, must be a numerical value')
class FermiSolver2(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict(FermiStep1)
self.step2 = dspy.Predict(FermiStep2)
self.step3 = dspy.Predict(FermiStep3)
self.step4 = dspy.Predict(FermiStep4)
self.step5 = dspy.Predict(FermiStep5)
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Fermi-Problemlöser mit klassenbasierter Signature und umfassenderer Beschreibung für jedes Feld.
Überprüfen Sie auch den def forward(self, ) Teil. Bei mehrstufigen Modulen stellen Sie sicher, dass die Ausgabe (oder alle Ausgaben wie im FermiSolver) vom letzten Schritt als Eingabe für den nächsten Schritt verwendet wird.
Ihr Problem ist einfach zu schwierig
Wenn sowohl die Metrik als auch das Modul korrekt erscheinen, dann ist es möglich, dass Ihr Problem einfach zu anspruchsvoll ist und die implementierte Logik nicht ausreicht, um es zu lösen. Daher findet DSPy es unmöglich, ein Demo mit Ihrer Logik und Metrik-Funktion zu bootstrappen. An diesem Punkt können Sie folgende Optionen in Betracht ziehen:
- Verwenden Sie ein leistungsfähigeres LM. Zum Beispiel ersetzen Sie
gpt-35-turbo-instructdurchgpt-4-turboals Student-LM, verwenden Sie ein stärkeres LM als Lehrer. Dies kann oft sehr effektiv sein. Schließlich bedeutet ein stärkeres Modell ein besseres Verständnis der Prompts. - Verbessern Sie Ihre Logik. Fügen Sie Schritte in Ihrem
dspy.Modulehinzu oder ersetzen Sie sie durch komplexere. Z.B. ersetzen SiePredictdurchChainOfThoughtProgramOfThought, fügen Sie einenRetrieval-Schritt hinzu. - Fügen Sie mehr Trainingsbeispiele hinzu. Wenn 20 Beispiele nicht ausreichen, zielen Sie auf 100! Sie können dann hoffen, dass ein Beispiel die Metrik-Prüfung besteht und von
BootstrapFewShotausgewählt wird. - Formulieren Sie das Problem um. Oft wird ein Problem unlösbar, wenn die Formulierung falsch ist. Aber wenn Sie es aus einem anderen Blickwinkel betrachten, können die Dinge viel einfacher und offensichtlicher werden.
In der Praxis beinhaltet der Prozess eine Mischung aus Versuch und Irrtum. Zum Beispiel habe ich mich mit einem besonders anspruchsvollen Problem befasst: der Generierung eines SVG-Icons ähnlich den Google Material Design Icons basierend auf zwei oder drei Schlüsselwörtern. Meine anfängliche Strategie war die Verwendung eines einfachen DSPy.Module, das dspy.ChainOfThought('keywords -> svg') verwendet, gepaart mit einer Metrik-Funktion, die die visuelle Ähnlichkeit zwischen dem generierten SVG und dem Ground Truth Material Design SVG bewertete, ähnlich einem pHash-Algorithmus. Ich begann mit 20 Trainingsbeispielen, aber nach der ersten Runde endete ich mit "Bootstrapped 0 full traces after 20 examples in round 0", was darauf hinwies, dass die Optimierung fehlgeschlagen war. Durch die Erhöhung des Datensatzes auf 100 Beispiele, die Überarbeitung meines Moduls zur Einbeziehung mehrerer Stufen und die Anpassung des Schwellenwerts der Metrik-Funktion erreichte ich schließlich 2 bootstrapped Demonstrationen und konnte einige optimierte Prompts erhalten.
