

Die präzise Suche in Code und Dokumentation ist wichtiger denn je. Wir freuen uns, unsere neuesten Embeddings in der Coding-Welt vorzustellen: jina-embeddings-v2-base-code. Dieses neue Open-Source-Embedding-Modell für Programmiersprachen wurde entwickelt, um die Interaktion von Entwicklern mit Code und Dokumentation zu verbessern. Es unterstützt Englisch und 30 gängige Programmiersprachen und ist das einzige Open-Source-Modell seiner Art, das bis zu 8.192 Input-Tokens verarbeiten kann. Das jina-embeddings-v2-base-code ist jetzt auf HuggingFace unter einer Apache 2.0 Lizenz verfügbar und kann kostenlos über unsere Embedding API genutzt werden.
Besuchen Sie die Embedding API und wählen Sie jina-embeddings-v2-base-code aus der Dropdown-Liste. Genießen Sie 1M Tokens kostenlos.
tagWarum ein Embedding-Modell für Code entwickeln?
Entwickler navigieren häufig durch umfangreiche Codebasen, nicht auf der Suche nach Fehlern, sondern um bestimmte Funktionalitäten zu finden oder zu verstehen, wie bestimmte Prozesse implementiert sind. Diese Aufgabe kann zeitaufwendig sein und gleicht manchmal der Suche nach der Nadel im Heuhaufen. Integrierte Entwicklungsumgebungen (IDEs) haben diesen Prozess durch Tools und Funktionen, die die Informationssuche automatisieren, erheblich verbessert. Es gibt jedoch noch Potenzial für weitere Verbesserungen, und hier kommt unser Embedding-Modell ins Spiel.
tagAnwendungsfälle von jina-embeddings-v2-base-code
Durch die Integration von KI-gestützten Suchfunktionen erweitern wir nicht nur die bestehenden Funktionalitäten in IDEs, sondern verändern grundlegend die Art und Weise, wie Entwickler mit Codebasen interagieren. Diese Technologie geht über die einfache Textsuche hinaus und bietet ein semantisches Verständnis, das die Absicht hinter einer Anfrage interpretieren kann. Dadurch werden der Zeit- und Arbeitsaufwand für Code-Reviews, Unit-Tests und das allgemeine Qualitätsmanagement erheblich reduziert.
Verbesserte Code-Navigation
- Abfrageformat: Natürlichsprachige Beschreibung der Funktionalität oder des Code-Snippets, nach dem Sie suchen.
- Rückgabeformat: Relevante Code-Dateien oder -Snippets, in denen die beschriebene Funktionalität implementiert ist, zusammen mit Anmerkungen oder Hervorhebungen, die auf die spezifischen Code-Bereiche hinweisen.
Optimiertes Code-Review
- Abfrageformat: Beschreibung der Programmierkonzepte oder -muster, die Sie in der Codebasis überprüfen möchten.
- Rückgabeformat: Eine Liste von Code-Snippets oder Pull Requests, die den beschriebenen Konzepten, Mustern oder Best Practices entsprechen und es Reviewern ermöglichen, sich auf kritische Verbesserungsbereiche zu konzentrieren.
Automatisierte Dokumentationsunterstützung
- Abfrageformat: Code-Snippet, für das Sie Dokumentation oder eine Erklärung benötigen.
- Rückgabeformat: Vorgeschlagene Docstrings oder Dokumentationseinträge, die die Funktionalität des Codes, Parameter und Rückgabetypen erklären und es einfacher machen, eine aktuelle und umfassende Dokumentation zu pflegen.
Durch die Berücksichtigung dieser spezifischen Anwendungsfälle verbessert jina-embeddings-v2-base-code nicht nur die Entwicklungserfahrung, sondern fördert auch eine kollaborativere und effizientere Coding-Umgebung.
tagLeistungsbenchmarks
In einem Bereich, in dem Präzision und Genauigkeit von größter Bedeutung sind, hat jina-embeddings-v2-base-code seine Konkurrenten übertroffen und führt in neun von fünfzehn wichtigen CodeNetSearch-Benchmarks. Darüber hinaus erzielt unser Modell auch in den übrigen Benchmarks sehr wettbewerbsfähige Ergebnisse. Im Vergleich zu seinen nächsten Konkurrenten, einschließlich derer von Technologiegiganten wie Microsoft und Salesforce, rangiert jina-embeddings-v2-base-code nicht nur höher, sondern demonstriert auch sein überlegenes Design und seine Fähigkeiten.
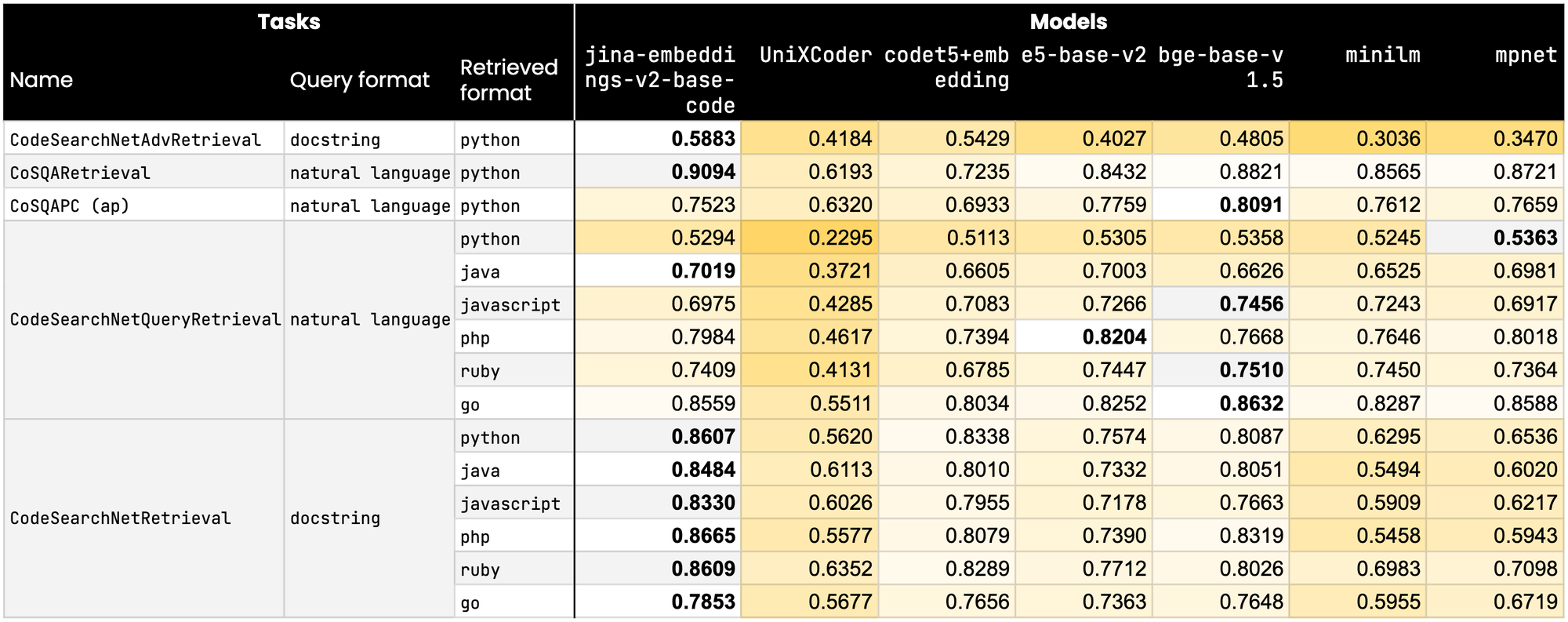
tagModell-Highlights
- State-of-the-Art Performance: Unser Engagement für Exzellenz spiegelt sich in der Leistung der Jina Embedding-Modelle wider, die durchgängig die Benchmark-Listen anführen und dabei sowohl andere Open-Source-Angebote als auch Modelle von Microsoft und Salesforce übertreffen.
- Kompakt und dennoch leistungsstark: In der KI-Welt ist Effizienz der Schlüssel. Mit 161 Millionen Parametern (307MB ohne Quantisierung) ist jina-embeddings-v2-base-code auf Effizienz ausgelegt und bietet hohe Geschwindigkeit und Kosteneinsparungen ohne Kompromisse bei der Leistungsfähigkeit.
- Erweiterte Kontextfähigkeit: Die Fähigkeit, bis zu 8192 Tokens zu verarbeiten, ermöglicht die Handhabung großer Funktionen und zahlreicher Objektdateien und bietet ein Verständnis und einen Kontext, der die Beschränkungen von Modellen, die nur wenige hundert Tokens unterstützen, übertrifft.
tagNahtlose API-Integration
jina-embeddings-v2-base-code wurde für eine einfache Integration entwickelt und unterstützt wichtige Vektor-Datenbanken wie MongoDB, Qdrant und Weaviate sowie Frameworks wie Haystack und LlamaIndex. Dies gewährleistet, dass Entwickler unser Model mühelos in ihre bestehenden Systeme integrieren und dessen Fähigkeiten zur Verbesserung ihrer Code-Abruf- und Dokumentationsprozesse nutzen können.
Ihr Feedback zu jina-embeddings-v2-base-code ist uns wichtig. Treten Sie unserem Community-Channel bei, um Feedback zu geben und über unsere Fortschritte informiert zu bleiben. Gemeinsam gestalten wir eine robustere und inklusivere KI-Zukunft.




