
Grounding ist für GenAI-Anwendungen absolut essentiell.
Ohne Grounding neigen LLMs stärker zu Halluzinationen und der Generierung ungenauer Informationen, besonders wenn ihre Trainingsdaten aktuelles oder spezifisches Wissen nicht enthalten. Egal wie stark die Schlussfolgerungsfähigkeit eines LLM ist, es kann einfach keine korrekte Antwort liefern, wenn die Information nach seinem Wissens-Stichtag eingeführt wurde.
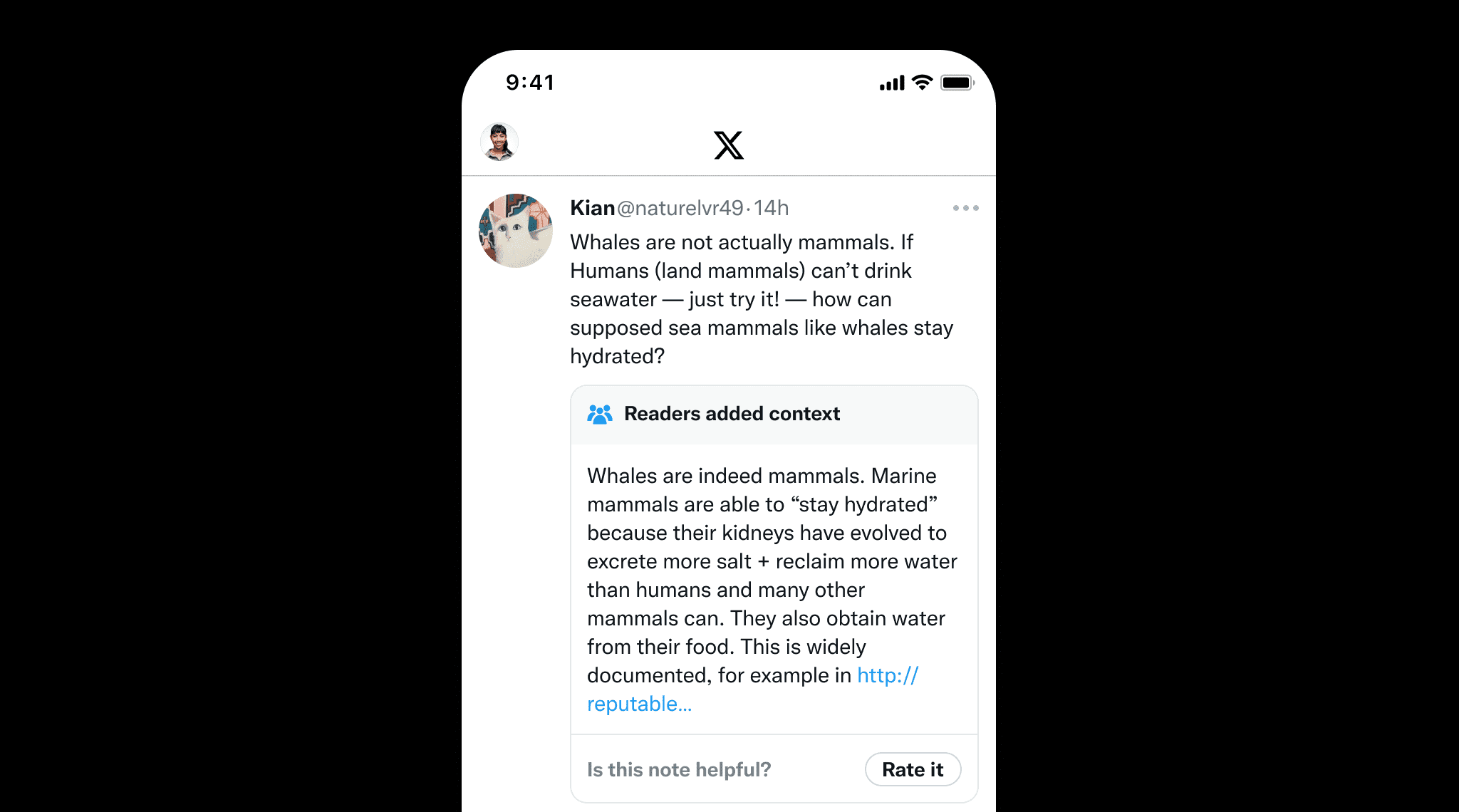
Grounding ist nicht nur für LLMs wichtig, sondern auch für von Menschen geschriebene Inhalte, um Fehlinformationen zu verhindern. Ein hervorragendes Beispiel sind X's Community Notes, wo Nutzer gemeinsam Kontext zu potenziell irreführenden Beiträgen hinzufügen. Dies unterstreicht den Wert von Grounding, das die faktische Genauigkeit durch klare Quellen und Referenzen sicherstellt, ähnlich wie Community Notes hilft, die Informationsintegrität zu wahren.
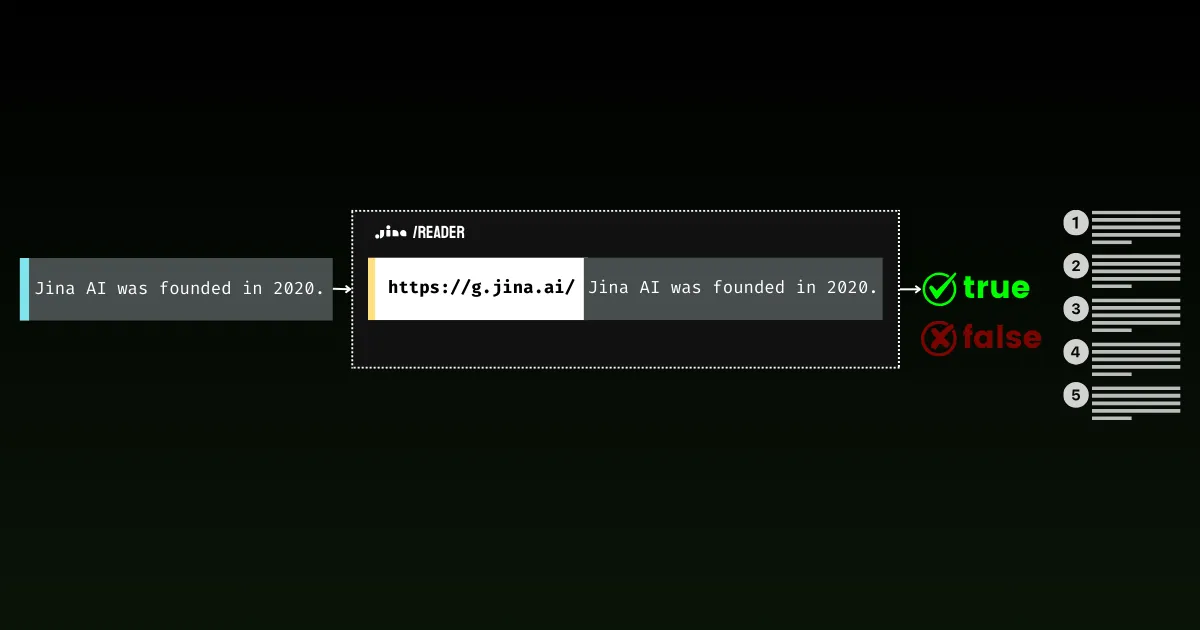
Mit Jina Reader haben wir aktiv an einer benutzerfreundlichen Grounding-Lösung gearbeitet. Zum Beispiel wandelt r.jina.ai Webseiten in LLM-freundliches Markdown um, und s.jina.ai aggregiert Suchergebnisse basierend auf einer gegebenen Anfrage in ein einheitliches Markdown-Format.

Heute freuen wir uns, einen neuen Endpunkt zu dieser Suite vorzustellen: g.jina.ai. Die neue API nimmt eine gegebene Aussage, überprüft sie mithilfe von Echtzeit-Websuchen und gibt einen Faktizitätswert sowie die genauen verwendeten Referenzen zurück. Unsere Experimente zeigen, dass diese API im Vergleich zu Modellen wie GPT-4, o1-mini und Gemini 1.5 Flash & Pro mit Suchgrounding einen höheren F1-Score beim Fact-Checking erreicht.

Was g.jina.ai von Geminis Search Grounding unterscheidet, ist, dass jedes Ergebnis bis zu 30 URLs enthält (typischerweise mindestens 10), jeweils mit direkten Zitaten, die zur Schlussfolgerung beitragen. Hier ist ein Beispiel für das Grounding der Aussage "The latest model released by Jina AI is jina-embeddings-v3," mit g.jina.ai (Stand 14. Oktober 2024). Erkunden Sie den API-Playground, um die vollständigen Funktionen zu entdecken. Beachten Sie, dass Einschränkungen gelten:
curl -X POST https://g.jina.ai \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_JINA_TOKEN" \
-d '{
"statement":"the last model released by Jina AI is jina-embeddings-v3"
}'YOUR_JINA_TOKEN ist Ihr Jina AI API-Schlüssel. Sie können 1M kostenlose Token von unserer Homepage erhalten, was etwa drei bis vier kostenlose Versuche ermöglicht. Mit dem aktuellen API-Preis von 0,02 USD pro 1M Token kostet jede Grounding-Anfrage etwa 0,006 USD.
{
"code": 200,
"status": 20000,
"data": {
"factuality": 0.95,
"result": true,
"reason": "The majority of the references explicitly support the statement that the last model released by Jina AI is jina-embeddings-v3. Multiple sources, such as the arXiv paper, Jina AI's news, and various model documentation pages, confirm this assertion. Although there are a few references to the jina-embeddings-v2 model, they do not provide evidence contradicting the release of a subsequent version (jina-embeddings-v3). Therefore, the statement that 'the last model released by Jina AI is jina-embeddings-v3' is well-supported by the provided documentation.",
"references": [
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "arXiv September 18, 2024 jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens.",
"isSupportive": true
},
{
"url": "https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-embeddings-v3?tab=Overview",
"keyQuote": "jina-embeddings-v3 is a multilingual multi-task text embedding model designed for a variety of NLP applications.",
"isSupportive": true
},
{
"url": "https://docs.pinecone.io/models/jina-embeddings-v3",
"keyQuote": "Jina Embeddings v3 is the latest iteration in the Jina AI's text embedding model series, building upon Jina Embedding v2.",
"isSupportive": true
},
{
"url": "https://haystack.deepset.ai/integrations/jina",
"keyQuote": "Recommended Model: jina-embeddings-v3 : We recommend jina-embeddings-v3 as the latest and most performant embedding model from Jina AI.",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "We offer an `encode` function to deal with this.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jinaai/jina-embeddings-v3 Feature Extraction • Updated 3 days ago • 278k • 375",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "the latest version (3.1.0) of [SentenceTransformers] also supports jina-embeddings-v3",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://jina.ai/embeddings/",
"keyQuote": "v3: Frontier Multilingual Embeddings is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model",
"keyQuote": "Jina Embeddings v3: A Frontier Multilingual Embedding Model jina-embeddings-v3 is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model/",
"keyQuote": "As of its release on September 18, 2024, jina-embeddings-v3 is the best multilingual model ...",
"isSupportive": true
}
],
"usage": {
"tokens": 112073
}
}
}Die Antwort auf das Grounding der Aussage „The latest model released by Jina AI is jina-embeddings-v3" mit g.jina.ai (Stand 14. Oktober 2024).
tagWie funktioniert es?
Im Kern umschließt g.jina.ai die Dienste s.jina.ai und r.jina.ai und fügt mehrstufiges Reasoning durch Chain of Thought (CoT) hinzu. Dieser Ansatz stellt sicher, dass jede überprüfte Aussage mit Hilfe von Online-Suchen und Dokumentenlesung gründlich analysiert wird.

s.jina.ai und r.jina.ai, der CoT für Planung und Argumentation hinzufügt.tagSchritt-für-Schritt-Erklärung
Lassen Sie uns den gesamten Prozess durchgehen, um besser zu verstehen, wie g.jina.ai das Grounding von der Eingabe bis zur endgültigen Ausgabe handhabt:
- Eingabeerklärung:
Der Prozess beginnt, wenn ein Benutzer eine Aussage eingibt, die er überprüfen möchte, wie zum Beispiel "Das neueste von Jina AI veröffentlichte Modell ist jina-embeddings-v3." Beachten Sie, dass keine Faktencheckinganleitungen vor der Aussage hinzugefügt werden müssen. - Suchanfragen generieren:
Ein LLM wird eingesetzt, um eine Liste einzigartiger Suchanfragen zu generieren, die für die Aussage relevant sind. Diese Anfragen zielen darauf ab, verschiedene faktische Elemente abzudecken und sicherzustellen, dass die Suche alle wichtigen Aspekte der Aussage umfassend abdeckt. - Aufruf von
s.jina.aifür jede Anfrage:
Für jede generierte Anfrage führtg.jina.aieine Websuche mits.jina.aidurch. Die Suchergebnisse bestehen aus einer vielfältigen Sammlung von Websites oder Dokumenten, die mit den Anfragen in Verbindung stehen. Im Hintergrund rufts.jina.air.jina.aiauf, um den Seiteninhalt abzurufen. - Referenzen aus Suchergebnissen extrahieren:
Aus jedem während der Suche abgerufenen Dokument extrahiert ein LLM die wichtigsten Referenzen. Diese Referenzen beinhalten:url: Die Webadresse der Quelle.keyQuote: Ein direktes Zitat oder ein Auszug aus dem Dokument.isSupportive: Ein Boolean-Wert, der angibt, ob die Referenz die ursprüngliche Aussage unterstützt oder widerlegt.
- Referenzen zusammenfassen und kürzen:
Alle Referenzen aus den abgerufenen Dokumenten werden in einer einzigen Liste zusammengefasst. Wenn die Gesamtzahl der Referenzen 30 übersteigt, wählt das System 30 zufällige Referenzen aus, um eine handhabbare Ausgabe zu gewährleisten. - Aussage auswerten:
Der Auswertungsprozess umfasst die Verwendung eines LLM zur Bewertung der Aussage basierend auf den gesammelten Referenzen (bis zu 30). Zusätzlich zu diesen externen Referenzen spielt auch das interne Wissen des Modells eine Rolle bei der Auswertung. Das Endergebnis enthält:factuality: Eine Punktzahl zwischen 0 und 1, die die faktische Genauigkeit der Aussage einschätzt.result: Ein Boolean-Wert, der angibt, ob die Aussage wahr oder falsch ist.reason: Eine detaillierte Erklärung, warum die Aussage als korrekt oder inkorrekt beurteilt wird, mit Verweisen auf die unterstützenden oder widersprechenden Quellen.
- Ergebnis ausgeben:
Sobald die Aussage vollständig ausgewertet wurde, wird die Ausgabe generiert. Diese enthält den Faktualitätswert, die Beurteilung der Aussage, eine detaillierte Begründung und eine Liste von Referenzen mit Zitaten und URLs. Die Referenzen beschränken sich auf das Zitat, die URL und die Information, ob sie die Aussage unterstützen oder nicht, um die Ausgabe klar und präzise zu halten.
tagBenchmark
Wir haben manuell 100 Aussagen mit Wahrheitswerten von entweder true (62 Aussagen) oder false (38 Aussagen) gesammelt und verschiedene Methoden verwendet, um zu bestimmen, ob sie überprüft werden können. Dieser Prozess verwandelt die Aufgabe im Wesentlichen in ein binäres Klassifikationsproblem, wobei die endgültige Leistung durch Präzision, Recall und F1-Score gemessen wird – je höher, desto besser.
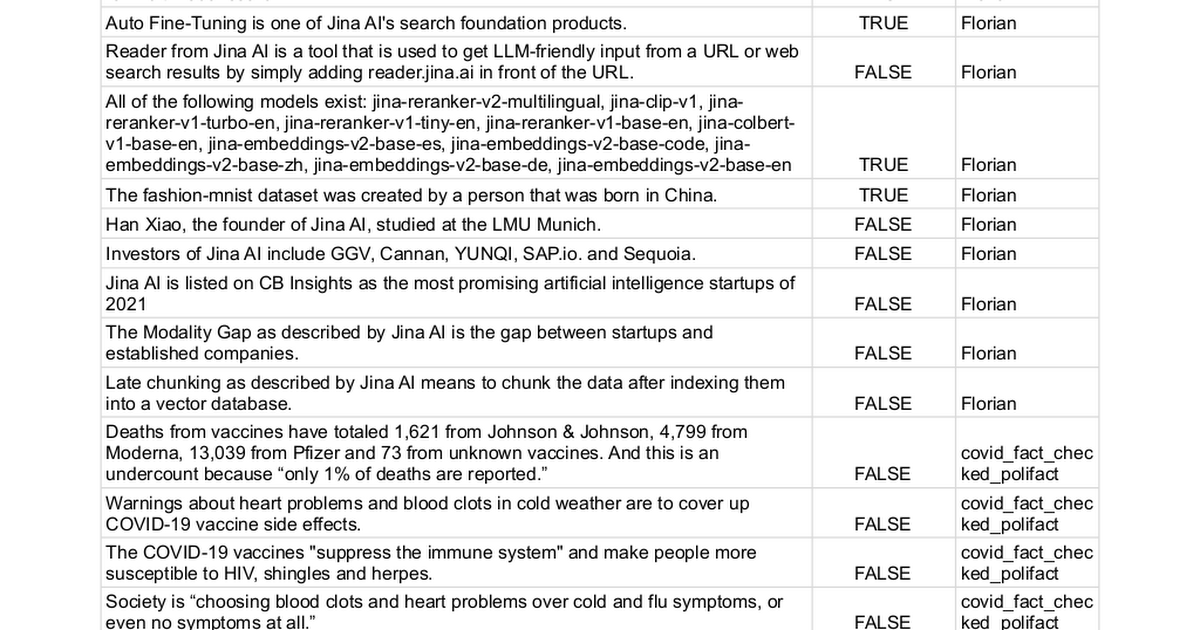
Die vollständige Liste der Aussagen finden Sie hier.
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Jina AI Grounding API (g.jina.ai) | 0.96 | 0.88 | 0.92 |
| Gemini-flash-1.5-002 w/ grounding | 1.00 | 0.73 | 0.84 |
| Gemini-pro-1.5-002 w/ grounding | 0.98 | 0.71 | 0.82 |
| gpt-o1-mini | 0.87 | 0.66 | 0.75 |
| gpt-4o | 0.95 | 0.58 | 0.72 |
| Gemini-pro-1.5-001 w/ grounding | 0.97 | 0.52 | 0.67 |
| Gemini-pro-1.5-001 | 0.95 | 0.32 | 0.48 |
Beachten Sie, dass in der Praxis einige LLMs eine dritte Klasse, Ich weiß es nicht, in ihren Vorhersagen zurückgeben. Für die Evaluierung werden diese Fälle von der Bewertungsberechnung ausgeschlossen. Dieser Ansatz vermeidet es, Unsicherheit so hart zu bestrafen wie falsche Antworten. Das Eingestehen von Unsicherheit wird gegenüber dem Raten bevorzugt, um Modelle davon abzuhalten, unsichere Vorhersagen zu treffen.
tagEinschränkungen
Trotz der vielversprechenden Ergebnisse möchten wir einige Einschränkungen der aktuellen Version der Grounding API hervorheben:
- Hohe Latenz & Token-Verbrauch: Ein einzelner Aufruf von
g.jina.aikann etwa 30 Sekunden dauern und bis zu 300K Token verbrauchen, aufgrund der aktiven Websuche, des Seitenlesens und der mehrstufigen Argumentation durch das LLM. Mit einem kostenlosen 1M-Token-API-Schlüssel bedeutet dies, dass Sie es nur etwa drei- bis viermal testen können. Um die Dienstverfügbarkeit für zahlende Nutzer aufrechtzuerhalten, haben wir auch ein konservatives Rate-Limit fürg.jina.aiimplementiert. Bei unseren aktuellen API-Preisen von 0,02 USD pro 1M Token kostet jede Grounding-Anfrage ungefähr 0,006 USD. - Anwendungseinschränkungen: Nicht jede Aussage kann oder sollte überprüft werden. Persönliche Meinungen oder Erfahrungen, wie "Ich fühle mich faul", eignen sich nicht für Grounding. Ebenso wenig gelten zukünftige Ereignisse oder hypothetische Aussagen. Es gibt viele Fälle, in denen Grounding irrelevant oder sinnlos wäre. Um unnötige API-Aufrufe zu vermeiden, empfehlen wir Benutzern, nur Sätze oder Abschnitte einzureichen, die tatsächlich eine Faktenprüfung erfordern. Serverseitig haben wir einen umfassenden Satz von Fehlercodes implementiert, um zu erklären, warum eine Aussage für Grounding abgelehnt werden könnte.
- Abhängigkeit von der Qualität der Webdaten: Die Genauigkeit der Grounding API ist nur so gut wie die Qualität der Quellen, die sie abruft. Wenn die Suchergebnisse qualitativ minderwertige oder voreingenommene Informationen enthalten, könnte sich dies im Grounding-Prozess widerspiegeln und möglicherweise zu ungenauen oder irreführenden Schlussfolgerungen führen. Um dieses Problem zu vermeiden, erlauben wir Benutzern, den Parameter
referencesmanuell festzulegen und die URLs einzuschränken, nach denen das System sucht. Dies gibt Benutzern mehr Kontrolle über die für das Grounding verwendeten Quellen und gewährleistet einen gezielteren und relevanteren Faktenprüfungsprozess.
tagFazit
Die Grounding API bietet eine End-to-End, nahezu Echtzeit-Faktenprüfungserfahrung. Forscher können sie nutzen, um Referenzen zu finden, die ihre Hypothesen unterstützen oder in Frage stellen und damit die Glaubwürdigkeit ihrer Arbeit erhöhen. In Unternehmensmeetings stellt sie sicher, dass Strategien auf genauen, aktuellen Informationen basieren, indem Annahmen und Daten validiert werden. In politischen Diskussionen überprüft sie schnell Behauptungen und bringt mehr Verantwortlichkeit in Debatten.
Für die Zukunft planen wir, die API durch die Integration privater Datenquellen wie interner Berichte, Datenbanken und PDFs für eine maßgeschneidertere Faktenprüfung zu verbessern. Wir streben auch an, die Anzahl der pro Anfrage überprüften Quellen für tiefere Auswertungen zu erweitern. Die Verbesserung der mehrstufigen Frage-Antwort-Funktion wird die Analyse vertiefen, und die Erhöhung der Konsistenz ist eine Priorität, um sicherzustellen, dass wiederholte Anfragen zuverlässigere, konsistentere Ergebnisse liefern.




