

Berlin, Deutschland - 15. Januar 2023 – In Anlehnung an JFKs ikonisches "Ich bin ein Berliner" überbrücken wir bei Jina AI Sprachen auf unsere eigene Weise. Heute präsentieren wir stolz unsere neueste Innovation: jina-embeddings-v2-base-de, ein deutsch-englisches Embedding-Modell. Dieses hochmoderne bilinguale Modell stellt einen bedeutenden Fortschritt in der Sprachrepräsentation dar und verfügt über eine Kontextlänge von 8.192 Token. Was es besonders auszeichnet, ist seine bemerkenswerte Effizienz: Es erzielt Spitzenleistungen bei nur 1/7 der Größe vergleichbarer Modelle.
Embeddings sind entscheidend für deutsche Unternehmen, die in den US-Markt expandieren möchten. Laut dem German American Business Outlook (GABO) 2022 erwirtschaftet etwa ein Drittel der deutschen Unternehmen mehr als 20% ihrer globalen Umsätze und Gewinne in den USA, wobei 93% einen Anstieg der US-Umsätze erwarten. Dieser Trend setzt sich fort, da 93% planen, ihre US-Investitionen in den nächsten drei Jahren zu erhöhen, wobei 85% ein Nettoumsatzwachstum erwarten und einen bedeutenden Fokus auf digitale Transformation legen. Gute Embeddings können bei dieser Expansion eine entscheidende Rolle spielen, indem sie ein besseres Verständnis der Kundenpräferenzen ermöglichen, effektivere Kommunikation fördern und kulturell resonante Produkte positionieren.
Unser Durchbruch ist besonders vorteilhaft für deutsche Unternehmen, die bilinguale Anwendungen in englischsprachigen Ländern implementieren möchten. Mit jina-embeddings-v2-base-de sind wir gespannt darauf zu sehen, wie deutsche Unternehmen in einer zunehmend vernetzten Welt innovativ sein und erfolgreich sein werden.
tagModell-Highlights
- Modernste Leistung: jina-embeddings-v2-base-de rangiert konstant an der Spitze relevanter Benchmarks und führt unter Open-Source-Modellen ähnlicher Größe.
- Bilinguales Modell: Dieses Modell kodiert Texte sowohl auf Deutsch als auch auf Englisch und ermöglicht die Verwendung beider Sprachen als Abfrage oder Zieldokument in Retrieval-Anwendungen. Texte mit äquivalenten Bedeutungen in beiden Sprachen werden in denselben Embedding-Raum abgebildet und bilden die Grundlage für mehrsprachige Anwendungen.
- Erweiterter Kontext: Eine Token-Länge von 8192 ermöglicht es jina-embeddings-v2-base-de, längere Texte und Dokumentfragmente zu unterstützen, weit über Modelle hinaus, die nur wenige hundert Token gleichzeitig unterstützen.
- Kompakte Größe: jina-embeddings-v2-base-de ist für hohe Leistung auf Standard-Computerhardware ausgelegt. Mit nur 161 Millionen Parametern ist das gesamte Modell 322MB groß und passt in den Speicher handelsüblicher Computer. Die Embeddings selbst haben 768 Dimensionen, eine relativ kleine Vektorgröße im Vergleich zu vielen Modellen, was Speicherplatz und Laufzeit für Anwendungen spart.
- Minimierung von Verzerrungen: Aktuelle Forschung zeigt, dass mehrsprachige Modelle ohne spezifisches Sprachtraining starke Verzerrungen zu englischen grammatikalischen Strukturen in Embeddings aufweisen. Embedding-Modelle sollten sich auf die Erfassung von Bedeutung konzentrieren und nicht Satzpaare bevorzugen, die nur oberflächlich ähnlich sind.
- Nahtlose Integration: Jina Embeddings v2 Modelle verfügen über native Integrationen mit wichtigen Vektordatenbanken, einschließlich MongoDB, Qdrant und Weaviate, sowie RAG- und LLM-Frameworks wie Haystack und LlamaIndex.
tagFührende Leistung in deutscher NLP
Wir haben jina-embeddings-v2-base-de gegen vier renommierte Baselines getestet, die ebenfalls sowohl Deutsch als auch Englisch unterstützen. Dazu gehören:
- Multilingual-E5-large und Multilingual-E5-base von Microsoft
- T-Systems' Cross English & German RoBERTa for Sentence Embeddings
- Sentence-BERT (
distiluse-base-multilingual-cased-v2)
Unsere Benchmarks umfassen die MTEB-Tasks für Englisch und unseren eigenen speziellen Benchmark. Angesichts des Fehlens einer umfassenden Benchmark-Suite für deutsche Embeddings haben wir die Initiative ergriffen, unsere eigene zu entwickeln, inspiriert von MTEB. Wir sind stolz darauf, unsere Erkenntnisse und Durchbrüche hier mit Ihnen zu teilen.
 jina-ai
jina-ai
tagKompakte Größe, überlegene Ergebnisse
jina-embeddings-v2-base-de zeigt außergewöhnliche Leistung, besonders bei deutschen Sprachaufgaben. Es übertrifft das E5 Base-Modell bei weniger als einem Drittel seiner Größe. Darüber hinaus kann es sich mit dem E5 Large-Modell messen, das siebenmal größer ist, was seine Effizienz und Leistungsfähigkeit demonstriert. Diese Effizienz macht jina-embeddings-v2-base-de zu einem Game-Changer, besonders im Vergleich zu anderen populären bi- und multilingualen Embedding-Modellen.
tagExzellente Leistung im deutsch-englischen Cross-Language Retrieval
Unser Modell überzeugt nicht nur durch Größe und Effizienz; es ist auch Spitzenreiter bei englisch-deutschen Cross-Language-Retrieval-Aufgaben. Dies zeigt sich in seiner Leistung in verschiedenen wichtigen Benchmarks:
- WikiCLIR, für Englisch zu Deutsch Retrieval
- STS17, Teil der MTEB-Evaluation für Englisch zu Deutsch Retrieval
- STS22, für Deutsch zu Englisch Retrieval, ebenfalls Teil von MTEB
- BUCC, für Deutsch zu Englisch Retrieval, in MTEB enthalten
Die Leistung in diesen Benchmarks, insbesondere in den MTEB-Evaluierungstests (mit Ausnahme von WikiCLIR), unterstreicht die Effektivität von jina-embeddings-v2-base-de bei der Bewältigung komplexer bilingualer Aufgaben.
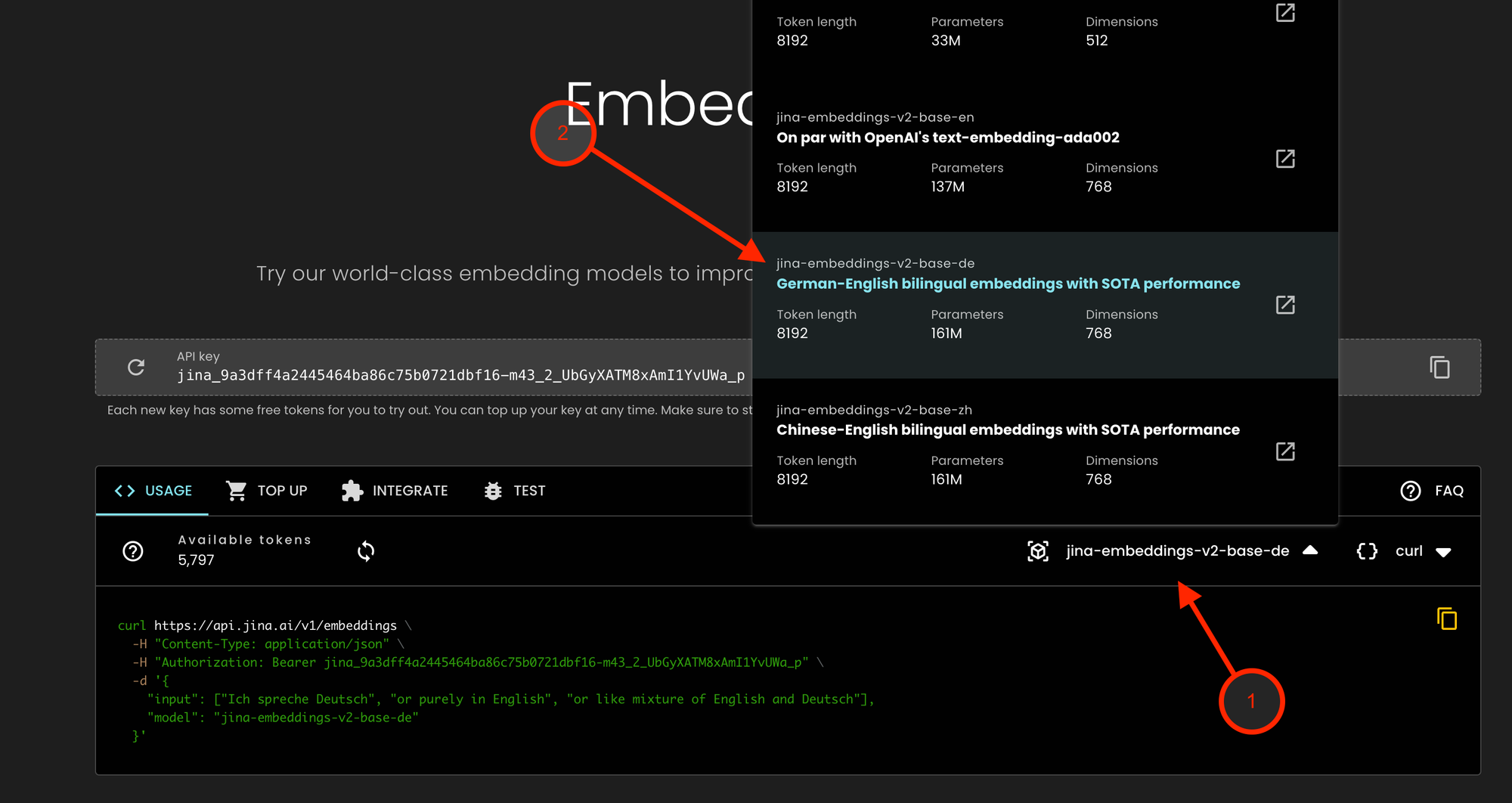
tagAPI-Zugang erhalten
Unsere Angebote für unsere Enterprise-Nutzer, die Wert auf Datenschutz und Compliance legen, einschließlich jina-embeddings-v2-base-de, sind über die Jina Embeddings API zugänglich:
- Besuchen Sie Jina Embeddings API und klicken Sie auf das Modell-Dropdown
- Wählen Sie jina-embeddings-v2-base-de

Wir werden dieses Modell in Kürze im AWS Sagemaker Marketplace für Amazon Cloud-Nutzer und zum Download auf HuggingFace verfügbar machen.
tagJina 8K Embeddings: Der Grundstein für vielfältige KI-Anwendungen
Embeddings sind entscheidend für ein breites Spektrum von KI-Anwendungen, einschließlich Informationsabruf, Qualitätskontrolle von Daten, Klassifizierung und Empfehlungen. Sie sind fundamental für die Verbesserung zahlreicher KI-Aufgaben.
Jina AI setzt sich dafür ein, den Stand der Technik in der Embedding-Technologie voranzutreiben und unsere zentralen KI-Komponenten transparent, zugänglich und erschwinglich für Unternehmen aller Art und Größe zu halten, die Wert auf Datenschutz und Compliance legen. Neben jina-embeddings-v2-base-de hat Jina AI modernste Embedding-Modelle für Chinesisch und leistungsstarke englische monolinguale Modelle veröffentlicht. Dies ist Teil unserer Mission, KI-Technologie inklusiver und global anwendbar zu machen.
Ihr Feedback ist uns wichtig. Treten Sie unserem Community-Channel bei, um Feedback zu geben und über unsere Fortschritte informiert zu bleiben. Gemeinsam gestalten wir eine robustere und inklusivere KI-Zukunft.


