


Entwickler und Betriebsingenieure schätzen Infrastrukturen, die sich einfach einrichten, schnell starten und später ohne zusätzlichen Aufwand effizient in einer skalierten Produktionsumgebung bereitstellen lassen. Aus diesem Grund ist Milvus Lite, das neueste lightweight Vector Database Angebot unseres Partners Milvus, ein wichtiges Werkzeug für Python-Entwickler, um schnell Suchanwendungen zu entwickeln, insbesondere in Kombination mit hochwertigen und einfach zu verwendenden Search Foundation Models.
In diesem Artikel beschreiben wir, wie Milvus Lite Jina Embeddings v2 und Jina Reranker v1 integriert. Dies wird am Beispiel einer Retrieval Augmented Generation (RAG) Anwendung demonstriert, die auf den öffentlichen Channel-Chats eines fiktiven Unternehmens aufbaut, um Mitarbeitern präzise und hilfreiche Antworten auf ihre organisationsbezogenen Fragen zu geben.
tagÜberblick über Milvus Lite, Jina Embeddings und Jina Reranker
Milvus Lite ist eine neue, leichtgewichtige Version der führenden Vector Database Milvus, die jetzt auch als Python-Bibliothek angeboten wird. Milvus Lite nutzt die gleiche API wie Milvus auf Docker oder Kubernetes, kann aber einfach über einen einzigen pip-Befehl installiert werden, ohne einen Server einrichten zu müssen.
Mit der Integration von Jina Embeddings v2 und Jina Reranker v1 in pymilvus, dem Python SDK von Milvus, haben Sie nun die Möglichkeit, Dokumente direkt über denselben Python-Client für jeden Deployment-Modus von Milvus, einschließlich Milvus Lite, einzubetten. Details zur Integration von Jina Embeddings und Reranker finden Sie in der Dokumentation von pymilvus.
Mit seinem 8k-Token Kontextfenster und mehrsprachigen Fähigkeiten kodiert Jina Embeddings v2 die breite Semantik von Text und gewährleistet ein präzises Retrieval. Durch das Hinzufügen von Jina Reranker v1 zur Pipeline können Sie Ihre Ergebnisse weiter verfeinern, indem Sie die abgerufenen Ergebnisse direkt mit der Abfrage kreuz-kodieren für ein tieferes kontextuelles Verständnis.
tagMilvus und Jina AI Models in Aktion
Dieses Tutorial konzentriert sich auf einen praktischen Anwendungsfall: Die Abfrage des Slack-Chat-Verlaufs eines Unternehmens, um eine breite Palette von Fragen auf Basis vergangener Konversationen zu beantworten.
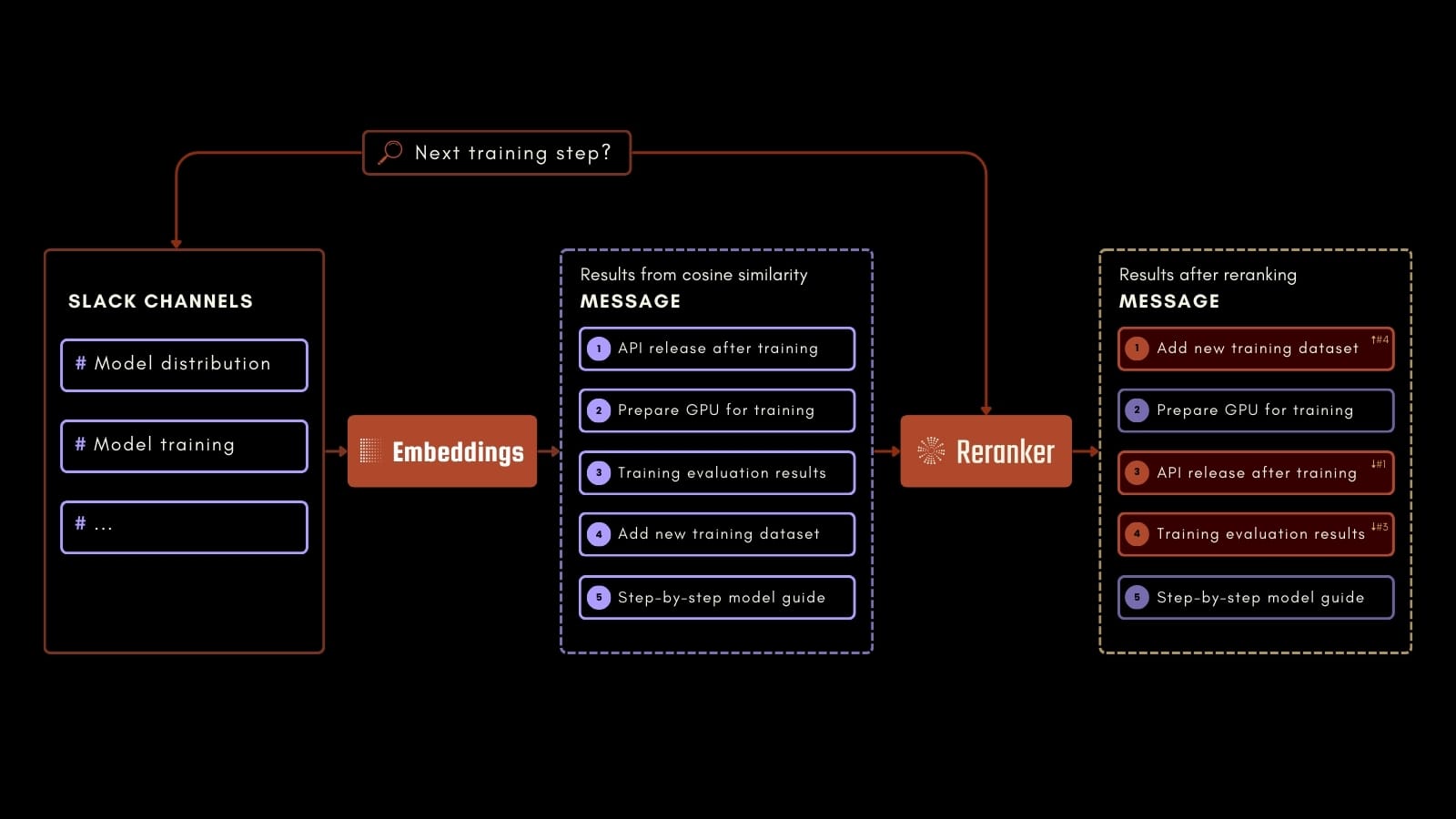
Ein Mitarbeiter könnte beispielsweise nach dem nächsten Schritt in einem KI-Trainingsprozess fragen, wie im obigen Prozessschema dargestellt. Durch die Verwendung von Jina Embeddings, Jina Reranker und Milvus können wir relevante Informationen in den protokollierten Slack-Nachrichten präzise identifizieren. Diese Anwendung kann die Arbeitsproduktivität steigern, indem sie den Zugriff auf wertvolle Informationen aus vergangenen Kommunikationen erleichtert.
Zur Generierung der Antworten verwenden wir Mixtral 7B Instruct über die HuggingFace-Integration in Langchain. Für die Nutzung des Models benötigen Sie einen HuggingFace Access Token, den Sie wie hier beschrieben generieren können.
Sie können in Colab mitarbeiten oder das Notebook herunterladen.


tagÜber den Datensatz
Der in diesem Tutorial verwendete Datensatz wurde mit GPT-4 generiert und soll die Chat-Verläufe der Slack-Kanäle von Blueprint AI nachbilden. Blueprint ist ein fiktives KI-Startup, das eigene Foundation Models entwickelt. Sie können den Datensatz hier herunterladen.
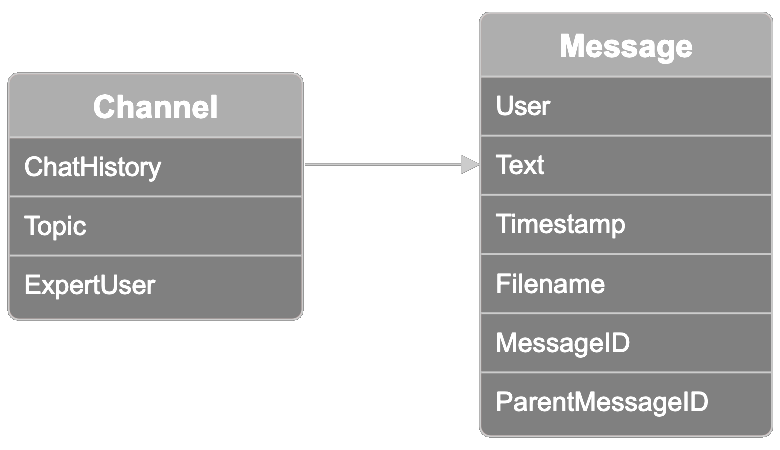
Die Daten sind in Channels organisiert, die jeweils eine Sammlung verwandter Slack-Threads repräsentieren. Jeder Channel hat ein Themen-Label, eines von zehn Themenoptionen: model distribution, model training, model fine-tuning, ethics and bias mitigation, user feedback, sales, marketing, model onboarding, creative design und product management. Ein Teilnehmer ist als „Experten-User" bekannt. Sie können dieses Feld nutzen, um die Ergebnisse der Suche nach dem erfahrensten Benutzer zu einem Thema zu validieren, was wir unten zeigen werden.
Jeder Channel enthält auch einen Chat-Verlauf mit Konversations-Threads von bis zu 100 Nachrichten pro Channel. Jede Nachricht im Datensatz enthält folgende Informationen:
- Der User, der die Nachricht gesendet hat
- Der Nachrichtentext, der vom User gesendet wurde
- Der Timestamp der Nachricht
- Der Name der Datei, die der User möglicherweise an die Nachricht angehängt hat
- Die Nachrichten-ID
- Die übergeordnete Nachrichten-ID, falls die Nachricht Teil eines Threads war, der von einer anderen Nachricht ausging
tagEinrichten der Umgebung
Installieren Sie zunächst alle notwendigen Komponenten:
pip install -U pymilvus
pip install -U "pymilvus[model]"
pip install langchain
pip install langchain-community
Laden Sie den Datensatz herunter:
import os
if not os.path.exists("chat_history.json"):
!wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/embeddings/milvus/chat_history.jsonSetzen Sie Ihren Jina AI API Key als Umgebungsvariable. Sie können einen hier generieren.
import os
import getpass
os.environ["JINAAI_API_KEY"] = getpass.getpass(prompt="Jina AI API Key: ")Machen Sie dasselbe für Ihren Hugging Face Token. Wie Sie einen generieren können, erfahren Sie hier. Stellen Sie sicher, dass er auf READ gesetzt ist, um auf den Hugging Face Hub zugreifen zu können.
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass.getpass(prompt="Hugging Face Token: ")tagErstellen der Milvus Collection
Erstellen Sie die Milvus Collection zum Indexieren der Daten:
from pymilvus import MilvusClient, DataType
# Specify a local file name as uri parameter of MilvusClient to use Milvus Lite
client = MilvusClient("milvus_jina.db")
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, description="The Primary Key", is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, description="The Embedding Vector", dim=768)
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
client.create_collection(collection_name="milvus_jina", schema=schema, index_params=index_params)tagDaten vorbereiten
Chat-Verlauf parsen und Metadaten extrahieren:
import json
with open("chat_history.json", "r", encoding="utf-8") as file:
chat_data = json.load(file)
messages = []
metadatas = []
for channel in chat_data:
chat_history = channel["chat_history"]
chat_topic = channel["topic"]
chat_expert = channel["expert_user"]
for message in chat_history:
text = f"""{message["user"]}: {message["message"]}"""
messages.append(text)
meta = {
"time_stamp": message["time_stamp"],
"file_name": message["file_name"],
"parent_message_nr": message["parent_message_nr"],
"channel": chat_topic,
"expert": True if message["user"] == chat_expert else False
}
metadatas.append(meta)
tagChat-Daten einbetten
Erstellen von Embeddings für jede Nachricht mit Jina Embeddings v2, um relevante Chat-Informationen abzurufen:
from pymilvus.model.dense import JinaEmbeddingFunction
jina_ef = JinaEmbeddingFunction("jina-embeddings-v2-base-en")
embeddings = jina_ef.encode_documents(messages)tagChat-Daten indizieren
Indizieren der Nachrichten, ihrer Embeddings und der zugehörigen Metadaten:
collection_data = [{
"message": message,
"embedding": embedding,
"metadata": metadata
} for message, embedding, metadata in zip(messages, embeddings, metadatas)]
data = client.insert(
collection_name="milvus_jina",
data=collection_data
)tagChat-Verlauf abfragen
Zeit für eine Frage:
query = "Who knows the most about encryption protocols in my team?"Nun die Abfrage einbetten und relevante Nachrichten abrufen. Hier rufen wir die fünf relevantesten Nachrichten ab und ordnen sie mit Jina Reranker v1 neu:
from pymilvus.model.reranker import JinaRerankFunction
query_vectors = jina_ef.encode_queries([query])
results = client.search(
collection_name="milvus_jina",
data=query_vectors,
limit=5,
)
results = results[0]
ids = [results[i]["id"] for i in range(len(results))]
results = client.get(
collection_name="milvus_jina",
ids=ids,
output_fields=["id", "message", "metadata"]
)
jina_rf = JinaRerankFunction("jina-reranker-v1-base-en")
documents = [results[i]["message"] for i in range(len(results))]
reranked_documents = jina_rf(query, documents)
reranked_messages = []
for reranked_document in reranked_documents:
idx = reranked_document.index
reranked_messages.append(results[idx])Zuletzt generieren wir eine Antwort auf die Abfrage mit Mixtral 7B Instruct und den neu geordneten Nachrichten als Kontext:
from langchain.prompts import PromptTemplate
from langchain_community.llms import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(repo_id="mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = """<s>[INST] Context information is below.\\n
It includes the five most relevant messages to the query, sorted based on their relevance to the query.\\n
---------------------\\n
{context_str}\\\\n
---------------------\\n
Given the context information and not prior knowledge,
answer the query. Please be brief, concise, and complete.\\n
If the context information does not contain an answer to the query,
respond with \\"No information\\".\\n
Query: {query_str}[/INST] </s>"""
prompt = PromptTemplate(template=prompt, input_variables=["query_str", "context_str"])
llm_chain = prompt | llm
answer = llm_chain.invoke({"query_str":query, "context_str":reranked_messages})
print(f"\n\nANSWER:\n\n{answer}")Die Antwort auf unsere Frage lautet:
"Basierend auf den Kontextinformationen scheint User5 der Sachkundigste in Bezug auf Verschlüsselungsprotokolle in Ihrem Team zu sein. Sie haben erwähnt, dass die neuen Protokolle die Datensicherheit deutlich verbessern, besonders bei Cloud-Deployments."
Wenn Sie die Nachrichten in chat_history.json durchlesen, können Sie selbst überprüfen, ob User5 tatsächlich der Experte ist.
tagZusammenfassung
Wir haben gesehen, wie man Milvus Lite einrichtet, Chat-Daten mit Jina Embeddings v2 einbettet und Suchergebnisse mit Jina Reranker v1 verfeinert – alles im Rahmen eines praktischen Anwendungsfalls zur Durchsuchung eines Slack-Chat-Verlaufs. Milvus Lite vereinfacht die Python-basierte Anwendungsentwicklung ohne die Notwendigkeit komplexer Server-Setups. Die Integration mit Jina Embeddings und Reranker zielt darauf ab, die Produktivität zu steigern, indem der Zugriff auf wertvolle Informationen am Arbeitsplatz erleichtert wird.
tagNutzen Sie jetzt Jina AI Models und Milvus
Milvus Lite mit integrierten Jina Embeddings und Reranker bietet Ihnen eine komplette Verarbeitungspipeline, die mit nur wenigen Codezeilen einsatzbereit ist.
Wir würden gerne von Ihren Anwendungsfällen hören und darüber sprechen, wie die Jina AI Milvus-Erweiterung Ihre geschäftlichen Anforderungen erfüllen kann. Kontaktieren Sie uns über unsere Website oder unseren Discord-Kanal, um Ihr Feedback zu teilen und über unsere neuesten Modelle auf dem Laufenden zu bleiben. Für Fragen zur Integration von Milvus und Jina AI treten Sie der Milvus-Community bei.






