



Jina CLIP v1 (jina-clip-v1) ist ein neues multimodales Embedding-Modell, das die Fähigkeiten von OpenAIs originalem CLIP-Modell erweitert. Mit diesem neuen Modell haben Nutzer ein einziges Embedding-Modell, das State-of-the-Art-Leistung sowohl bei reinen Text-Retrievals als auch bei Text-Bild-Cross-Modal-Retrievals bietet. Jina AI hat die Leistung von OpenAI CLIP um 165% beim reinen Text-Retrieval und um 12% beim Bild-zu-Bild-Retrieval verbessert, bei identischer oder leicht besserer Leistung bei Text-zu-Bild- und Bild-zu-Text-Aufgaben. Diese verbesserte Leistung macht Jina CLIP v1 unverzichtbar für die Arbeit mit multimodalen Eingaben.
In diesem Artikel werden wir zunächst die Schwächen des ursprünglichen CLIP-Modells und unseren Ansatz zu deren Behebung mittels einer einzigartigen Co-Training-Methode diskutieren. Anschließend werden wir die Effektivität unseres Modells anhand verschiedener Retrieval-Benchmarks demonstrieren. Abschließend geben wir detaillierte Anleitungen, wie Nutzer mit Jina CLIP v1 über unsere Embeddings API und Hugging Face beginnen können.
tagDie CLIP-Architektur für multimodale KI
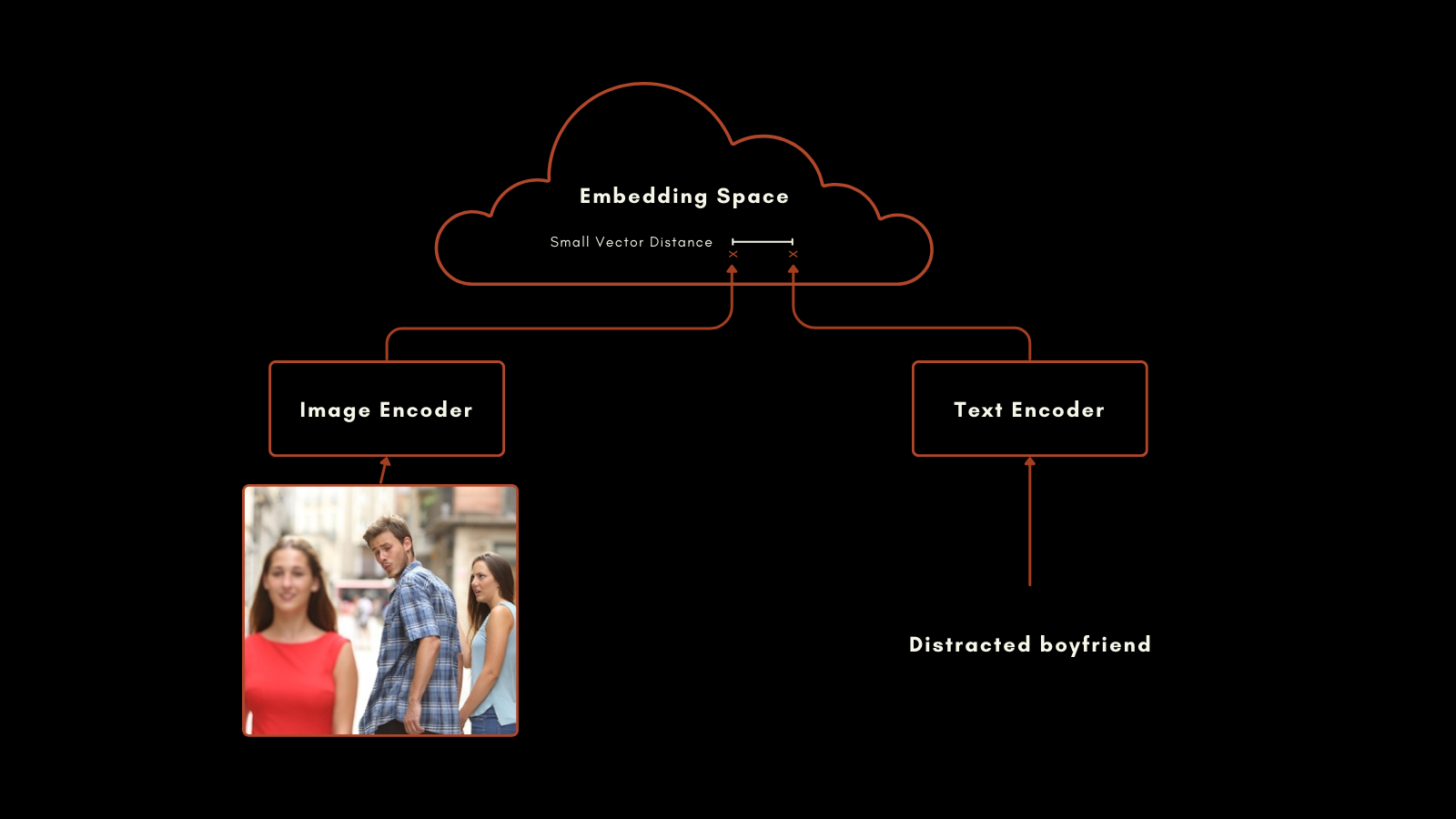
Im Januar 2021 veröffentlichte OpenAI das CLIP (Contrastive Language–Image Pretraining) Modell. CLIP hat eine einfache, aber geniale Architektur: es kombiniert zwei Embedding-Modelle, eines für Texte und eines für Bilder, in einem einzigen Modell mit einem gemeinsamen Embedding-Ausgaberaum. Seine Text- und Bild-Embeddings sind direkt miteinander vergleichbar, wodurch der Abstand zwischen einem Text-Embedding und einem Bild-Embedding proportional dazu ist, wie gut dieser Text das Bild beschreibt und umgekehrt.
Dies hat sich als sehr nützlich für multimodales Information Retrieval und Zero-Shot-Bildklassifizierung erwiesen. Ohne spezielles zusätzliches Training war CLIP in der Lage, Bilder gut in Kategorien mit natürlichsprachlichen Labels einzuordnen.

Das Text-Embedding-Modell im ursprünglichen CLIP war ein spezielles neuronales Netzwerk mit nur 63 Millionen Parametern. Auf der Bildseite veröffentlichte OpenAI CLIP mit einer Auswahl von ResNet und ViT-Modellen. Jedes Modell wurde für seine individuelle Modalität vortrainiert und dann mit beschrifteten Bildern trainiert, um ähnliche Embeddings für vorbereitete Bild-Text-Paare zu erzeugen.
Dieser Ansatz lieferte beeindruckende Ergebnisse. Besonders bemerkenswert ist die Zero-Shot-Klassifizierungsleistung. Auch wenn die Trainingsdaten keine beschrifteten Bilder von Astronauten enthielten, konnte CLIP Bilder von Astronauten basierend auf seinem Verständnis verwandter Konzepte in Texten und Bildern korrekt identifizieren.
Allerdings hat OpenAIs CLIP zwei wichtige Nachteile:
- Erstens ist die Texteingabekapazität sehr begrenzt. Es kann maximal 77 Token als Eingabe verarbeiten, aber empirische Analysen zeigen, dass es in der Praxis nicht mehr als 20 Token zur Erzeugung seiner Embeddings nutzt. Dies liegt daran, dass CLIP mit Bildern und Bildunterschriften trainiert wurde, und Bildunterschriften tendenziell sehr kurz sind. Dies steht im Gegensatz zu aktuellen Text-Embedding-Modellen, die mehrere tausend Token unterstützen.
- Zweitens ist die Leistung seiner Text-Embeddings bei reinen Text-Retrieval-Szenarien sehr schlecht. Bildunterschriften sind eine sehr eingeschränkte Art von Text und spiegeln nicht das breite Spektrum an Anwendungsfällen wider, die ein Text-Embedding-Modell unterstützen sollte.
In den meisten realen Anwendungsfällen werden reines Text- und Bild-Text-Retrieval kombiniert oder zumindest beide für Aufgaben zur Verfügung gestellt. Die Pflege eines zweiten Embeddings-Modells für reine Text-Aufgaben verdoppelt effektiv die Größe und Komplexität Ihres KI-Frameworks.
Das neue Modell von Jina AI adressiert diese Probleme direkt, und jina-clip-v1 nutzt die Fortschritte der letzten Jahre, um State-of-the-Art-Leistung für Aufgaben mit allen Kombinationen von Text- und Bildmodalitäten zu bieten.
tagEinführung in Jina CLIP v1
Jina CLIP v1 behält das ursprüngliche CLIP-Schema von OpenAI bei: zwei Modelle, die co-trainiert werden, um Ausgaben im gleichen Embedding-Raum zu erzeugen.
Für die Textkodierung haben wir die Jina BERT v2 Architektur adaptiert, die in den Jina Embeddings v2 Modellen verwendet wird. Diese Architektur unterstützt ein State-of-the-Art 8k Token Eingabefenster und gibt 768-dimensionale Vektoren aus, die genauere Embeddings aus längeren Texten erzeugen. Dies ist mehr als das 100-fache der 77 Token Eingabe, die im ursprünglichen CLIP-Modell unterstützt wurden.
Für Bild-Embeddings verwenden wir das neueste Modell der Beijing Academy for Artificial Intelligence: das EVA-02 Modell. Wir haben empirisch verschiedene Bild-KI-Modelle verglichen, sie in cross-modalen Kontexten mit ähnlichem Pre-Training getestet, und EVA-02 übertraf die anderen deutlich. Es ist auch in der Modellgröße vergleichbar mit der Jina BERT Architektur, sodass die Rechenlasten für Bild- und Textverarbeitungsaufgaben ungefähr identisch sind.
Diese Entscheidungen bringen wichtige Vorteile für Benutzer:
- Bessere Leistung bei allen Benchmarks und allen modalen Kombinationen, und besonders große Verbesserungen bei der reinen Text-Embedding-Leistung.
- Die empirisch überlegene Leistung von
EVA-02sowohl bei Bild-Text- als auch bei reinen Bildaufgaben, mit dem zusätzlichen Vorteil von Jina AIs zusätzlichem Training, das die reine Bildleistung verbessert. - Unterstützung für viel längere Texteingaben. Die 8k Token Eingabeunterstützung von Jina Embeddings ermöglicht es, detaillierte Textinformationen zu verarbeiten und mit Bildern zu korrelieren.
- Eine große Nettoeinsparung bei Speicherplatz, Rechenleistung, Code-Wartung und Komplexität, da dieses multimodale Modell auch in nicht-multimodalen Szenarien sehr leistungsfähig ist.
tagTraining
Ein Teil unseres Rezepts für hochleistungsfähige multimodale KI sind unsere Trainingsdaten und -prozedur. Wir stellen fest, dass die sehr kurze Länge der Texte in Bildunterschriften die Hauptursache für die schlechte reine Textleistung in CLIP-artigen Modellen ist, und unser Training ist explizit darauf ausgerichtet, dies zu beheben.
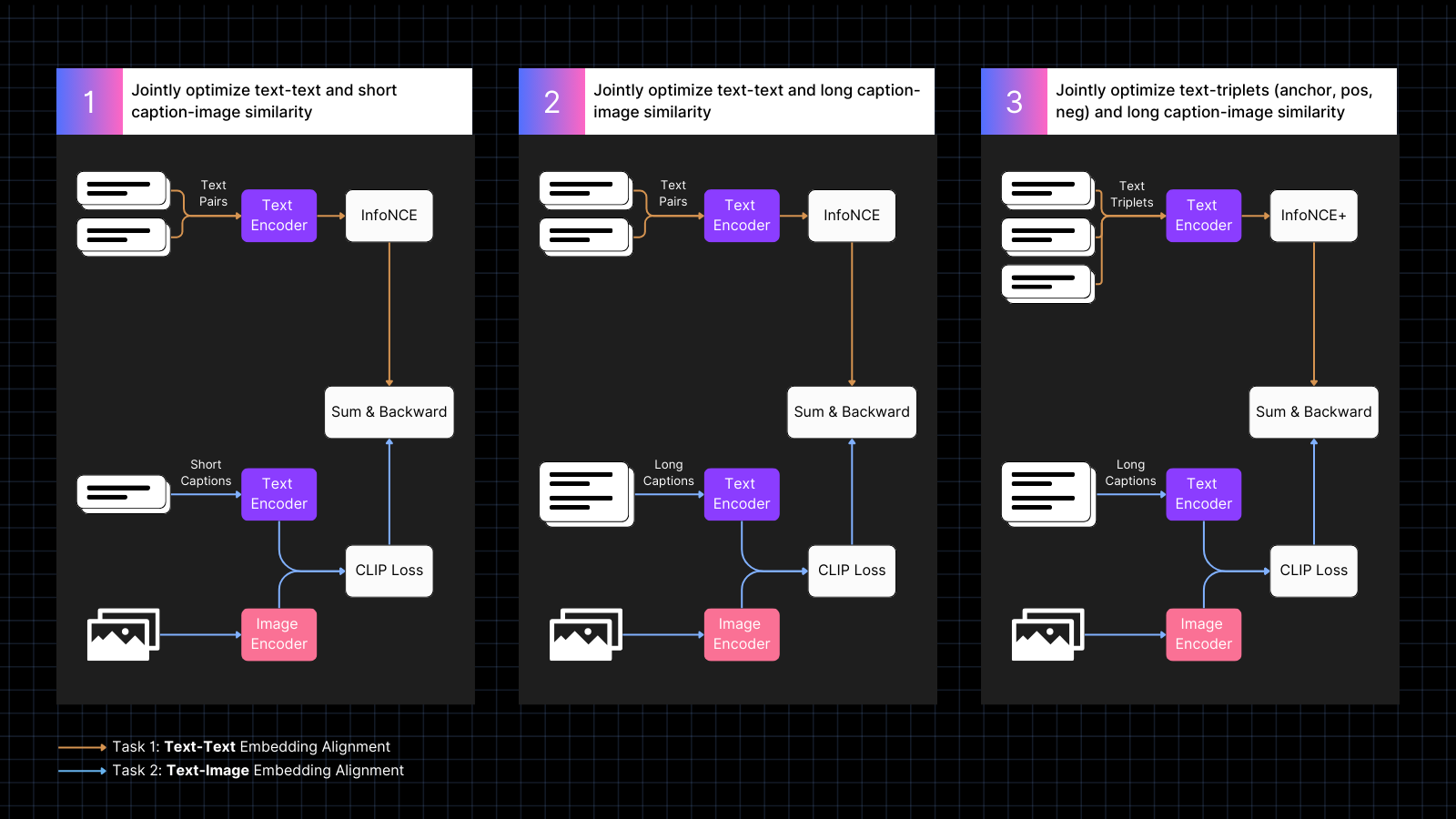
Das Training erfolgt in drei Schritten:
- Verwendung von Daten mit beschrifteten Bildern, um Bild- und Text-Embeddings anzugleichen, durchsetzt mit Textpaaren mit ähnlichen Bedeutungen. Dieses Co-Training optimiert gemeinsam für die beiden Arten von Aufgaben. Die reine Textleistung des Modells nimmt während dieser Phase ab, aber nicht so stark wie wenn wir nur mit Bild-Text-Paaren trainiert hätten.
- Training mit synthetischen Daten, die Bilder mit längeren, von einem KI-Modell generierten Texten verbinden, die das Bild beschreiben. Gleichzeitiges Weitertraining mit reinen Textpaaren. Während dieser Phase lernt das Modell, längere Texte in Verbindung mit Bildern zu verarbeiten.
- Verwendung von Text-Triplets mit schwierigen Negativbeispielen, um die reine Textleistung durch das Erlernen feinerer semantischer Unterscheidungen weiter zu verbessern. Gleichzeitig wird das Training mit synthetischen Paaren von Bildern und langen Texten fortgesetzt. Während dieser Phase verbessert sich die reine Textleistung dramatisch, ohne dass das Modell seine Bild-Text-Fähigkeiten verliert.
Weitere Informationen zu den Details des Trainings und der Modellarchitektur finden Sie in unserem aktuellen Paper:
tagNeuer State-of-the-Art bei multimodalen Einbettungen
Wir haben die Leistung von Jina CLIP v1 bei reinen Text-, reinen Bild- und Cross-Modal-Aufgaben mit beiden Eingabemodalitäten evaluiert. Wir verwendeten den MTEB Retrieval Benchmark zur Evaluierung der reinen Textleistung. Für reine Bildaufgaben verwendeten wir den CIFAR-100 Benchmark. Für Cross-Model-Aufgaben evaluieren wir auf Flickr8k, Flickr30K und MSCOCO Captions, die im CLIP Benchmark enthalten sind.
Die Ergebnisse sind in der folgenden Tabelle zusammengefasst:
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| % increase vs OpenAI CLIP |
165% | 2% | 6% | 12% |
Wie Sie aus diesen Ergebnissen ersehen können, übertrifft jina-clip-v1 OpenAIs ursprüngliches CLIP in allen Kategorien und ist bei reinem Text- und Bild-Retrieval deutlich besser. Über alle Kategorien gemittelt ist dies eine 46%ige Leistungsverbesserung.
Eine detailliertere Auswertung finden Sie in unserem aktuellen Paper.
tagErste Schritte mit der Embeddings API
Sie können Jina CLIP v1 einfach in Ihre Anwendungen integrieren, indem Sie die Jina Embeddings API verwenden.
Der folgende Code zeigt, wie Sie die API aufrufen können, um Einbettungen für Texte und Bilder zu erhalten, unter Verwendung des requests Pakets in Python. Er übergibt einen Textstring und eine URL zu einem Bild an den Jina AI Server und gibt beide Kodierungen zurück.
<YOUR_JINA_AI_API_KEY> durch einen aktivierten Jina API-Schlüssel zu ersetzen. Sie können einen Test-Schlüssel mit einer Million kostenlosen Tokens von der Jina Embeddings Webseite erhalten.import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")
tagIntegration mit wichtigen LLM-Frameworks
Jina CLIP v1 ist bereits verfügbar für LlamaIndex und LangChain:
- LlamaIndex: Verwenden Sie
JinaEmbeddingmit derMultimodalEmbeddingBasisklasse und rufen Sieget_image_embeddingsoderget_text_embeddingsauf. - LangChain: Verwenden Sie
JinaEmbeddingsund rufen Sieembed_imagesoderembed_documentsauf.
tagPreisgestaltung
Sowohl Text- als auch Bildeingaben werden nach Token-Verbrauch berechnet.
Für englische Texte haben wir empirisch berechnet, dass im Durchschnitt 1,1 Token pro Wort benötigt werden.
Bei Bildern zählen wir die Anzahl der 224x224 Pixel-Kacheln, die benötigt werden, um Ihr Bild abzudecken. Einige dieser Kacheln können teilweise leer sein, zählen aber genauso. Jede Kachel kostet 1.000 Token zur Verarbeitung.
Beispiel
Für ein Bild mit den Abmessungen 750x500 Pixel:
- Das Bild wird in 224x224 Pixel-Kacheln aufgeteilt.
- Um die Anzahl der Kacheln zu berechnen, nehmen Sie die Breite in Pixeln und teilen Sie durch 224, dann runden Sie auf die nächste ganze Zahl auf.
750/224 ≈ 3,35 → 4 - Wiederholen Sie dies für die Höhe in Pixeln:
500/224 ≈ 2,23 → 3
- Um die Anzahl der Kacheln zu berechnen, nehmen Sie die Breite in Pixeln und teilen Sie durch 224, dann runden Sie auf die nächste ganze Zahl auf.
- Die Gesamtzahl der benötigten Kacheln in diesem Beispiel ist:
4 (horizontal) x 3 (vertikal) = 12 Kacheln - Die Kosten betragen 12 x 1.000 = 12.000 Token
tagEnterprise-Support
Wir führen einen neuen Vorteil für Benutzer ein, die den Production Deployment Plan mit 11 Milliarden Token erwerben. Dies beinhaltet:
- Drei Stunden Beratung mit unseren Produkt- und Engineering-Teams, um Ihre spezifischen Anwendungsfälle und Anforderungen zu besprechen.
- Ein angepasstes Python-Notebook für Ihren RAG (Retrieval-Augmented Generation) oder Vektorsuche-Anwendungsfall, das zeigt, wie Sie Jina AIs Modelle in Ihre Anwendung integrieren können.
- Zuweisung eines Account Executive und priorisierter E-Mail-Support, um sicherzustellen, dass Ihre Bedürfnisse zeitnah und effizient erfüllt werden.
tagOpen-Source Jina CLIP v1 auf Hugging Face
Jina AI ist einer Open-Source-Suchgrundlage verpflichtet und stellt dieses Modell daher kostenlos unter einer Apache 2.0 Lizenz auf Hugging Face zur Verfügung.
Beispielcode zum Herunterladen und Ausführen dieses Modells auf Ihrem eigenen System oder Ihrer Cloud-Installation finden Sie auf der Hugging Face Modellseite für jina-clip-v1.

tagZusammenfassung
Jina AIs neuestes Modell — jina-clip-v1 — stellt einen bedeutenden Fortschritt bei multimodalen Einbettungsmodellen dar und bietet erhebliche Leistungsverbesserungen gegenüber OpenAIs CLIP. Mit bemerkenswerten Verbesserungen bei reinen Text- und Bild-Retrieval-Aufgaben sowie wettbewerbsfähiger Leistung bei Text-zu-Bild- und Bild-zu-Text-Aufgaben ist es eine vielversprechende Lösung für komplexe Einbettungsanwendungsfälle.
Dieses Modell unterstützt aufgrund von Ressourcenbeschränkungen derzeit nur englischsprachige Texte. Wir arbeiten daran, seine Fähigkeiten auf weitere Sprachen auszuweiten.
