



Heute freuen wir uns, jina-embeddings-v3 vorzustellen, ein wegweisendes Text-Embedding-Modell mit 570 Millionen Parametern. Es erzielt Spitzenleistungen bei **mehrsprachigen** Daten und **Long-Context** Retrieval-Aufgaben und unterstützt eine Eingabelänge von bis zu 8192 Token. Das Modell verfügt über aufgabenspezifische Low-Rank Adaptation (LoRA) Adapter, die es ermöglichen, hochwertige Embeddings für verschiedene Aufgaben wie **Query-Document Retrieval**, **Clustering**, **Klassifizierung** und **Text-Matching** zu generieren.
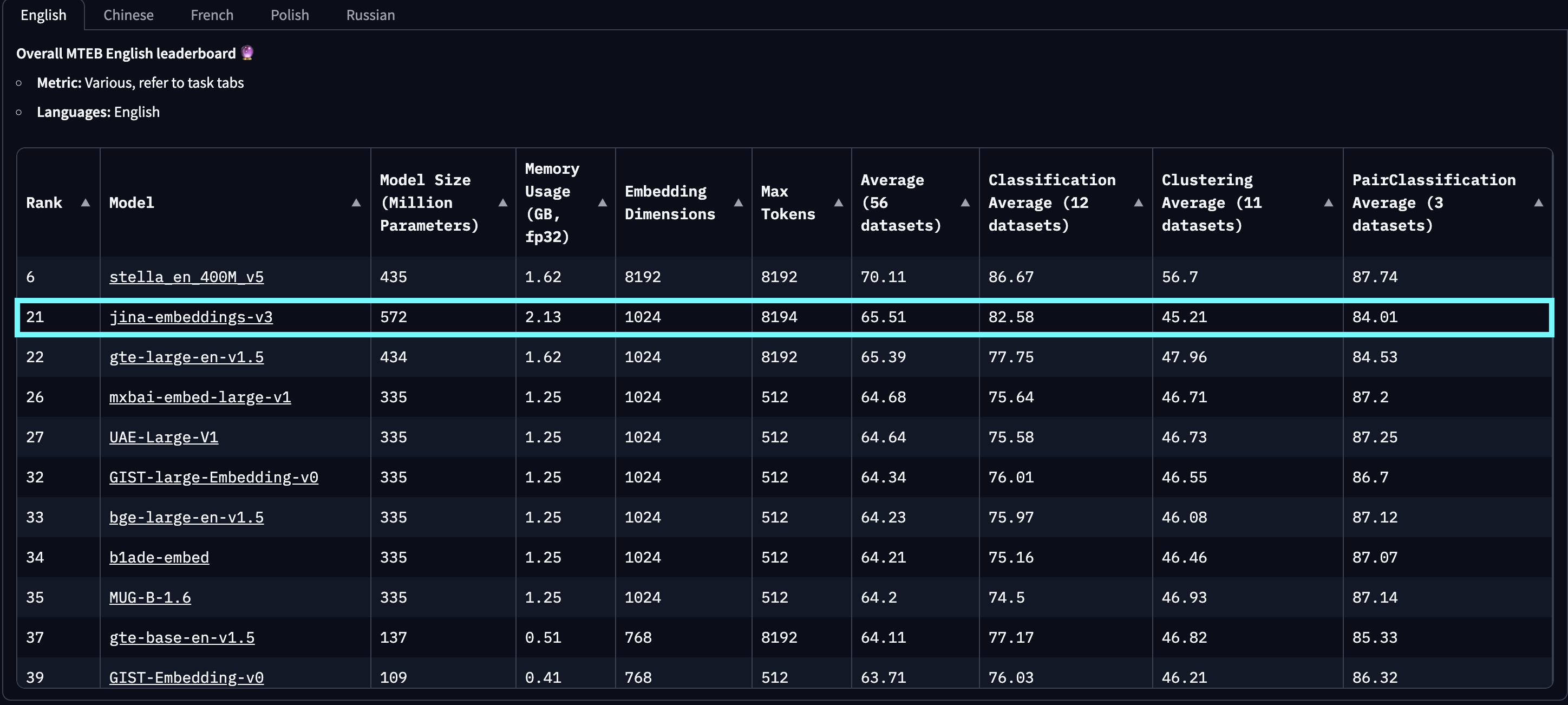
In Evaluierungen auf MTEB English, Multilingual und LongEmbed übertrifft jina-embeddings-v3 die neuesten proprietären Embeddings von OpenAI und Cohere bei englischen Aufgaben und übertrifft gleichzeitig multilingual-e5-large-instruct bei allen mehrsprachigen Aufgaben. Mit einer Standard-Ausgabedimension von 1024 können Benutzer die Embedding-Dimensionen dank der Integration von Matryoshka Representation Learning (MRL) beliebig bis auf 32 reduzieren, ohne Leistungseinbußen in Kauf nehmen zu müssen.


jina-embeddings-v2-(zh/es/de) auf unsere zweisprachige Modell-Suite bezieht, die nur für chinesische, spanische und deutsche monolinguale und cross-linguale Aufgaben getestet wurde, unter Ausschluss aller anderen Sprachen. Zusätzlich berichten wir keine Scores für openai-text-embedding-3-large und cohere-embed-multilingual-v3.0, da diese Modelle nicht auf der vollen Bandbreite mehrsprachiger und cross-lingualer MTEB-Aufgaben evaluiert wurden.
baai-bge-m3 als auch den ALiBi-basierten Ansatz von jina-embeddings-v2 übertreffen.Mit seiner Veröffentlichung am 18. September 2024 ist jina-embeddings-v3 **das beste** mehrsprachige Modell und belegt den **2. Platz** auf der MTEB English Leaderboard für Modelle mit weniger als 1 Milliarde Parametern. v3 unterstützt insgesamt 89 Sprachen, darunter 30 Sprachen mit der besten Leistung: Arabisch, Bengalisch, Chinesisch, Dänisch, Niederländisch, Englisch, Finnisch, Französisch, Georgisch, Deutsch, Griechisch, Hindi, Indonesisch, Italienisch, Japanisch, Koreanisch, Lettisch, Norwegisch, Polnisch, Portugiesisch, Rumänisch, Russisch, Slowakisch, Spanisch, Schwedisch, Thai, Türkisch, Ukrainisch, Urdu und Vietnamesisch.

jina-embeddings-v2 aufweist. Diese Grafik wurde durch Auswahl der Top-100 Embedding-Modelle aus der MTEB-Leaderboard erstellt, unter Ausschluss derjenigen ohne Größeninformation, typischerweise closed-source oder proprietäre Modelle. Einreichungen, die als offensichtliches Trolling identifiziert wurden, wurden ebenfalls herausgefiltert.Im Vergleich zu LLM-basierten Embeddings, die kürzlich Aufmerksamkeit erregt haben, wie e5-mistral-7b-instruct, das eine Parametergröße von 7,1 Milliarden (12x größer) und eine Ausgabedimension von 4096 (4x größer) hat, aber nur 1% Verbesserung bei MTEB English Tasks bietet, ist jina-embeddings-v3 eine weitaus kosteneffizientere Lösung, die es besser für den Produktionseinsatz und Edge-Computing geeignet macht.
tagModellarchitektur
| Feature | Description |
|---|---|
| Base | jina-XLM-RoBERTa |
| Parameter Basis | 559M |
| Parameter mit LoRA | 572M |
| Max. Input-Token | 8192 |
| Max. Output-Dimensionen | 1024 |
| Layer | 24 |
| Vokabular | 250K |
| Unterstützte Sprachen | 89 |
| Attention | FlashAttention2, funktioniert auch ohne |
| Pooling | Mean pooling |
Die Architektur von jina-embeddings-v3 ist in der folgenden Abbildung dargestellt. Zur Implementierung der Backbone-Architektur haben wir das XLM-RoBERTa Modell mit mehreren wichtigen Modifikationen angepasst: (1) Ermöglichung der effektiven Kodierung langer Textsequenzen, (2) Erlaubnis aufgabenspezifischer Kodierung von Embeddings und (3) Verbesserung der allgemeinen Modelleffizienz mit neuesten Techniken. Wir verwenden weiterhin den originalen XLM-RoBERTa Tokenizer. Während jina-embeddings-v3 mit seinen 570 Millionen Parametern größer ist als jina-embeddings-v2 mit 137 Millionen, ist es immer noch deutlich kleiner als Embedding-Modelle, die von LLMs feinabgestimmt wurden.

jina-XLM-RoBERTa Modell mit fünf LoRA-Adaptern für vier verschiedene Aufgaben.Die wichtigste Innovation in jina-embeddings-v3 ist die Verwendung von LoRA-Adaptern. Fünf aufgabenspezifische LoRA-Adapter wurden eingeführt, um Embeddings für vier Aufgaben zu optimieren. Die Eingabe des Modells besteht aus zwei Teilen: dem Text (das lange Dokument, das eingebettet werden soll) und der Aufgabe. jina-embeddings-v3 unterstützt vier Aufgaben und implementiert fünf Adapter zur Auswahl: retrieval.query und retrieval.passage für Query- und Passage-Embeddings in asymmetrischen Retrieval-Aufgaben, separation für Clustering-Aufgaben, classification für Klassifizierungsaufgaben und text-matching für Aufgaben mit semantischer Ähnlichkeit wie STS oder symmetrisches Retrieval. Die LoRA-Adapter machen weniger als 3% der Gesamtparameter aus und fügen nur minimalen Overhead zur Berechnung hinzu.
Zur weiteren Verbesserung der Leistung und Reduzierung des Speicherverbrauchs integrieren wir FlashAttention 2, unterstützen Activation Checkpointing und verwenden das DeepSpeed-Framework für effizientes verteiltes Training.
tagErste Schritte
tagÜber die Jina AI Search Foundation API
Der einfachste Weg, jina-embeddings-v3 zu nutzen, ist ein Besuch der Jina AI Homepage und Navigation zum Search Foundation API-Bereich. Ab heute ist dieses Modell die Standardeinstellung für alle neuen Benutzer. Sie können verschiedene Parameter und Funktionen direkt von dort aus erkunden.
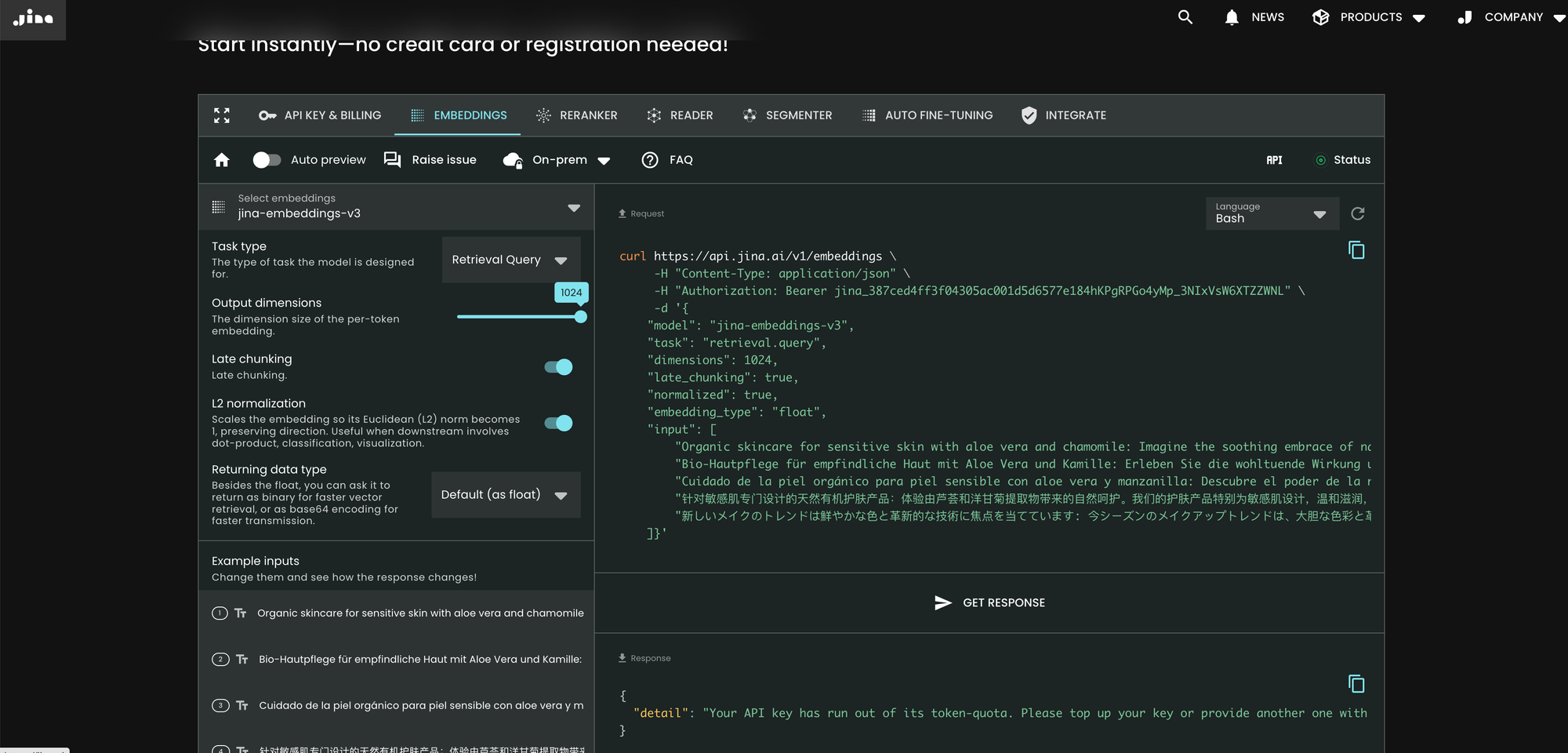
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'
Im Vergleich zu v2 führt v3 drei neue Parameter in der API ein: task, dimensions und late_chunking.
Parameter task
Der task Parameter ist entscheidend und muss entsprechend der nachgelagerten Aufgabe gesetzt werden. Die resultierenden Embeddings werden für diese spezifische Aufgabe optimiert. Weitere Details finden Sie in der Liste unten.
task Wert |
Aufgabenbeschreibung |
|---|---|
retrieval.passage |
Embedding von Dokumenten in einer Query-Dokument-Retrieval-Aufgabe |
retrieval.query |
Embedding von Anfragen in einer Query-Dokument-Retrieval-Aufgabe |
separation |
Clustering von Dokumenten, Visualisierung eines Korpus |
classification |
Textklassifikation |
text-matching |
(Standard) Semantische Textähnlichkeit, allgemeines symmetrisches Retrieval, Empfehlungen, ähnliche Elemente finden, Deduplizierung |
Beachten Sie, dass die API nicht zuerst ein generisches Meta-Embedding erzeugt und es dann mit einem zusätzlichen feinabgestimmten MLP anpasst. Stattdessen fügt sie den aufgabenspezifischen LoRA-Adapter in jede Transformer-Schicht (insgesamt 24 Schichten) ein und führt die Kodierung in einem Durchgang durch. Weitere Details finden Sie in unserem arXiv-Paper.
Parameter dimensions
Der dimensions Parameter ermöglicht es Benutzern, einen Kompromiss zwischen Speichereffizienz und Leistung zu den niedrigsten Kosten zu wählen. Dank der in jina-embeddings-v3 verwendeten MRL-Technik können Sie die Dimensionen der Embeddings beliebig reduzieren (sogar auf eine einzige Dimension!). Kleinere Embeddings sind speicherfreundlicher für Vektordatenbanken, und ihre Leistungskosten können aus der Abbildung unten abgeschätzt werden.

Parameter late_chunking
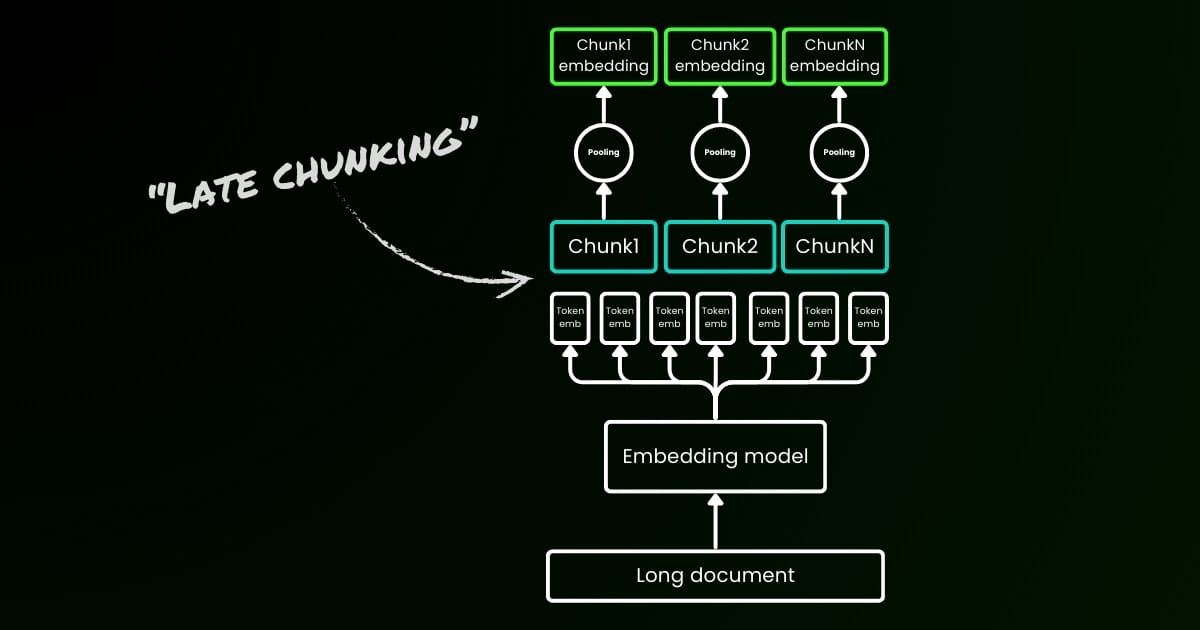
Schließlich steuert der late_chunking Parameter, ob die neue Chunking-Methode verwendet werden soll, die wir letzten Monat eingeführt haben, um einen Batch von Sätzen zu kodieren. Wenn auf true gesetzt, wird unsere API alle Sätze im input Feld verknüpfen und sie als einzelnen String an das Modell übergeben. Mit anderen Worten, wir behandeln die Sätze in der Eingabe so, als ob sie ursprünglich aus demselben Abschnitt, Absatz oder Dokument stammen. Intern bettet das Modell diesen langen verknüpften String ein und führt dann spätes Chunking durch, wobei eine Liste von Embeddings zurückgegeben wird, die der Größe der Eingabeliste entspricht. Jedes Embedding in der Liste ist daher von den vorherigen Embeddings abhängig.
Aus Benutzersicht ändert das Setzen von late_chunking nicht das Ein- oder Ausgabeformat. Sie werden nur eine Änderung in den Embedding-Werten bemerken, da diese nun basierend auf dem gesamten vorherigen Kontext berechnet werden und nicht unabhängig voneinander. Was wichtig ist zu wissen bei der Verwendung vonlate_chunking=True bedeutet, dass die Gesamtanzahl der Tokens (durch Summierung aller Tokens in input) pro Anfrage auf 8192 beschränkt ist, was der maximalen Kontextlänge für jina-embeddings-v3 entspricht. Bei late_chunking=False gibt es keine solche Beschränkung; die Gesamtanzahl der Tokens unterliegt nur dem Rate-Limit der Embedding-API.
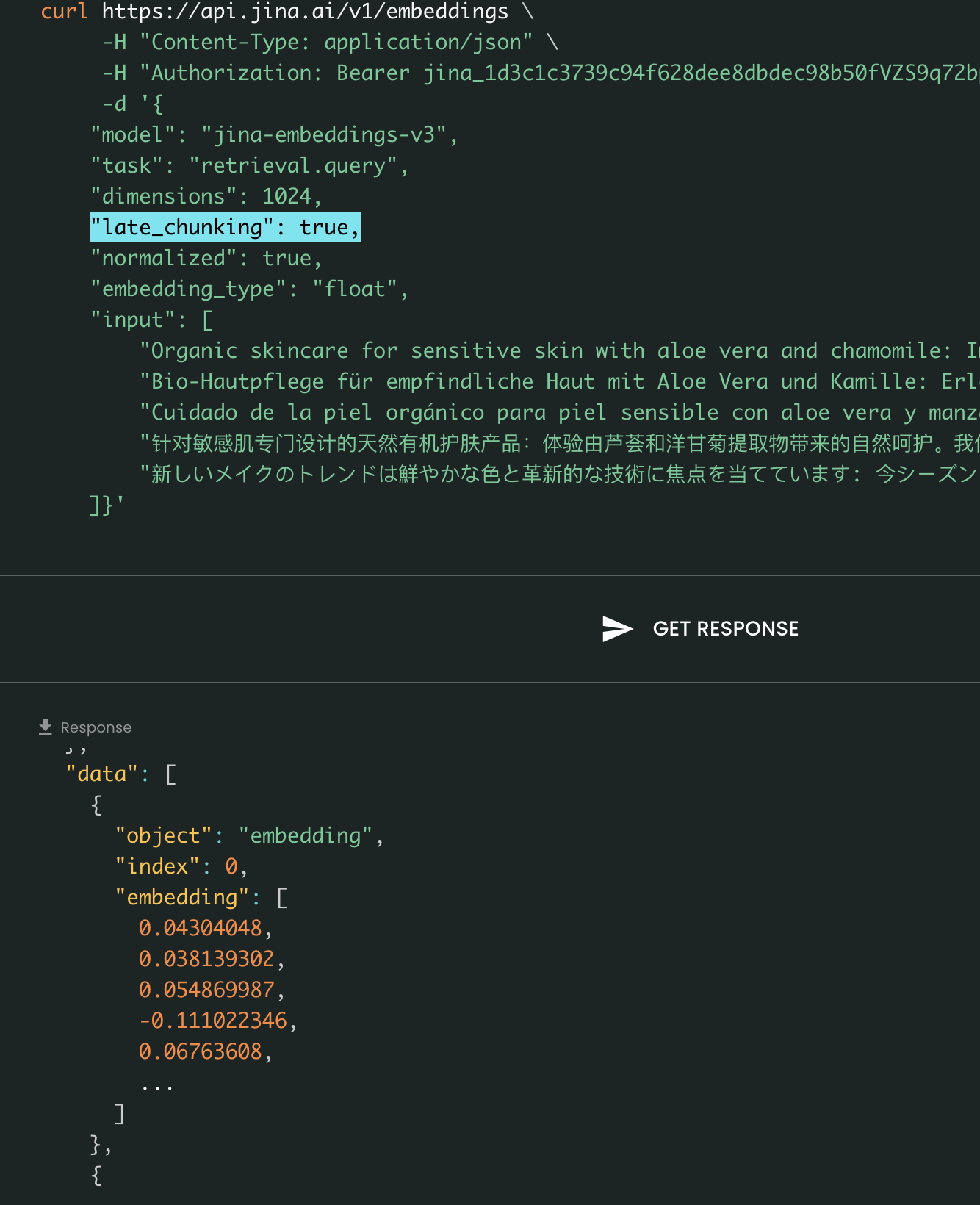
Late Chunking Ein vs. Aus: Das Ein- und Ausgabeformat bleibt gleich, der einzige Unterschied liegt in den Embedding-Werten. Wenn late_chunking aktiviert ist, werden die Embeddings vom gesamten vorherigen Kontext in input beeinflusst, während ohne dies die Embeddings unabhängig berechnet werden.
tagÜber Azure & AWS
jina-embeddings-v3 ist jetzt auf AWS SageMaker und im Azure Marketplace verfügbar.


Falls Sie es über diese Plattformen hinaus oder On-Premises in Ihrem Unternehmen nutzen möchten, beachten Sie, dass das Modell unter CC BY-NC 4.0 lizenziert ist. Für kommerzielle Nutzungsanfragen kontaktieren Sie uns gerne.
tagÜber Vektordatenbanken & Partner
Wir arbeiten eng mit Vektordatenbank-Anbietern wie Pinecone, Qdrant und Milvus sowie LLM-Orchestrierungs-Frameworks wie LlamaIndex, Haystack und Dify zusammen. Zum Zeitpunkt der Veröffentlichung freuen wir uns bekannt zu geben, dass Pinecone, Qdrant, Milvus und Haystack bereits die Unterstützung für jina-embeddings-v3 integriert haben, einschließlich der drei neuen Parameter: task, dimensions und late_chunking. Andere Partner, die bereits die v2 API integriert haben, sollten auch v3 unterstützen, indem sie einfach den Modellnamen zu jina-embeddings-v3 ändern. Allerdings unterstützen sie möglicherweise noch nicht die in v3 neu eingeführten Parameter.
Über Pinecone

Über Qdrant

Über Milvus

Über Haystack

tagFazit
Im Oktober 2023 veröffentlichten wir jina-embeddings-v2-base-en, das weltweit erste Open-Source-Embedding-Modell mit einer 8K-Kontextlänge. Es war das einzige Text-Embedding-Modell, das langen Kontext unterstützte und mit OpenAIs text-embedding-ada-002 mithalten konnte. Heute, nach einem Jahr des Lernens, Experimentierens und wertvoller Erkenntnisse, sind wir stolz darauf, jina-embeddings-v3 zu veröffentlichen—einen neuen Meilenstein in Text-Embedding-Modellen und einen großen Meilenstein für unser Unternehmen.
Mit dieser Veröffentlichung bleiben wir weiterhin führend in dem, wofür wir bekannt sind: lange Kontext-Embeddings, während wir gleichzeitig die am häufigsten nachgefragte Funktion sowohl aus der Industrie als auch aus der Community adressieren—multilinguale Embeddings. Gleichzeitig treiben wir die Leistung auf ein neues Niveau. Mit neuen Funktionen wie aufgabenspezifischem LoRA, MRL und Late Chunking glauben wir, dass jina-embeddings-v3 wirklich als grundlegendes Embedding-Modell für verschiedene Anwendungen dienen wird, einschließlich RAG, Agents und mehr. Im Vergleich zu neueren LLM-basierten Embeddings wie NV-embed-v1/v2 ist unser Modell hochgradig parametereffizient, was es für die Produktion und Edge-Geräte viel besser geeignet macht.
In Zukunft planen wir, uns auf die Evaluierung und Verbesserung der jina-embeddings-v3-Leistung bei ressourcenarmen Sprachen zu konzentrieren und systemische Fehler aufgrund begrenzter Datenverfügbarkeit weiter zu analysieren. Darüber hinaus werden die Modellgewichte von jina-embeddings-v3, zusammen mit seinen innovativen Funktionen und neuen Ansätzen, als Grundlage für unsere kommenden Modelle dienen, einschließlich jina-clip-v2,jina-reranker-v3 und reader-lm-v2.
