





Heute veröffentlichen wir Jina Reranker v2 (jina-reranker-v2-base-multilingual), unser neuestes und leistungsstärkstes Neural Reranker Modell aus der Search Foundation Familie. Mit Jina Reranker v2 können Entwickler von RAG/Search-Systemen folgende Vorteile nutzen:
- Mehrsprachig: Relevantere Suchergebnisse in über 100 Sprachen, übertrifft
bge-reranker-v2-m3; - Agentenfähig: State-of-the-Art Function-Calling und Text-to-SQL bewusstes Dokument-Reranking für agentisches RAG;
- Code-Retrieval: Beste Leistung bei Code-Retrieval Aufgaben, und
- Ultra-schnell: 15-facher Dokumenten-Durchsatz im Vergleich zu
bge-reranker-v2-m3und 6-facher im Vergleich zu jina-reranker-v1-base-en.
Sie können mit Jina Reranker v2 über unsere Reranker API beginnen, wo wir allen neuen Nutzern 1M kostenlose Token anbieten.

In diesem Artikel erläutern wir die neuen Funktionen von Jina Reranker v2, zeigen wie unser Reranker-Modell im Vergleich zu anderen State-of-the-Art Modellen (einschließlich Jina Reranker v1) abschneidet und erklären den Trainingsprozess, der Jina Reranker v2 zu Höchstleistungen in Aufgabengenauigkeit und Dokumentendurchsatz geführt hat.
tagRückblick: Warum Sie einen Reranker benötigen
Während Embedding-Modelle die am häufigsten verwendete und verstandene Komponente in der Search Foundation sind, opfern sie oft Präzision für Abrufgeschwindigkeit. Embedding-basierte Suchmodelle sind typischerweise Bi-Encoder Modelle, bei denen jedes Dokument eingebettet und gespeichert wird, dann werden auch Anfragen eingebettet und der Abruf basiert auf der Ähnlichkeit des Anfrage-Embeddings zu den Dokument-Embeddings. In diesem Modell gehen viele Nuancen der Token-Level-Interaktionen zwischen Benutzeranfragen und zugeordneten Dokumenten verloren, da sich die ursprüngliche Anfrage und die Dokumente nie "sehen" können – nur ihre Embeddings tun das. Dies kann auf Kosten der Abrufgenauigkeit gehen – ein Bereich, in dem Cross-Encoder Reranker-Modelle sich auszeichnen.

Reranker beheben diesen Mangel an feingranularer Semantik durch den Einsatz einer Cross-Encoder-Architektur, bei der Anfrage-Dokument-Paare gemeinsam kodiert werden, um einen Relevanzwert anstelle eines Embeddings zu erzeugen. Studien haben gezeigt, dass für die meisten RAG-Systeme die Verwendung eines Reranker-Modells die semantische Fundierung verbessert und Halluzinationen reduziert.
tagMehrsprachige Unterstützung mit Jina Reranker v2
Früher unterschied sich Jina Reranker v1 dadurch, dass er State-of-the-Art Leistung bei vier wichtigen englischsprachigen Benchmarks erreichte. Heute erweitern wir die Reranking-Fähigkeiten in Jina Reranker v2 deutlich mit mehrsprachiger Unterstützung für mehr als 100 Sprachen und sprachübergreifende Aufgaben!
Um die sprachübergreifenden und englischsprachigen Fähigkeiten von Jina Reranker v2 zu evaluieren, vergleichen wir seine Leistung mit ähnlichen Reranker-Modellen anhand der drei unten aufgeführten Benchmarks:
MKQA: Mehrsprachige Wissensfragen und Antworten
Dieser Datensatz umfasst Fragen und Antworten in 26 Sprachen, abgeleitet aus realen Wissensbasen, und ist darauf ausgelegt, die sprachübergreifende Leistung von Frage-Antwort-Systemen zu evaluieren. MKQA besteht aus englischsprachigen Anfragen und deren manuellen Übersetzungen in nicht-englische Sprachen, zusammen mit Antworten in mehreren Sprachen einschließlich Englisch.
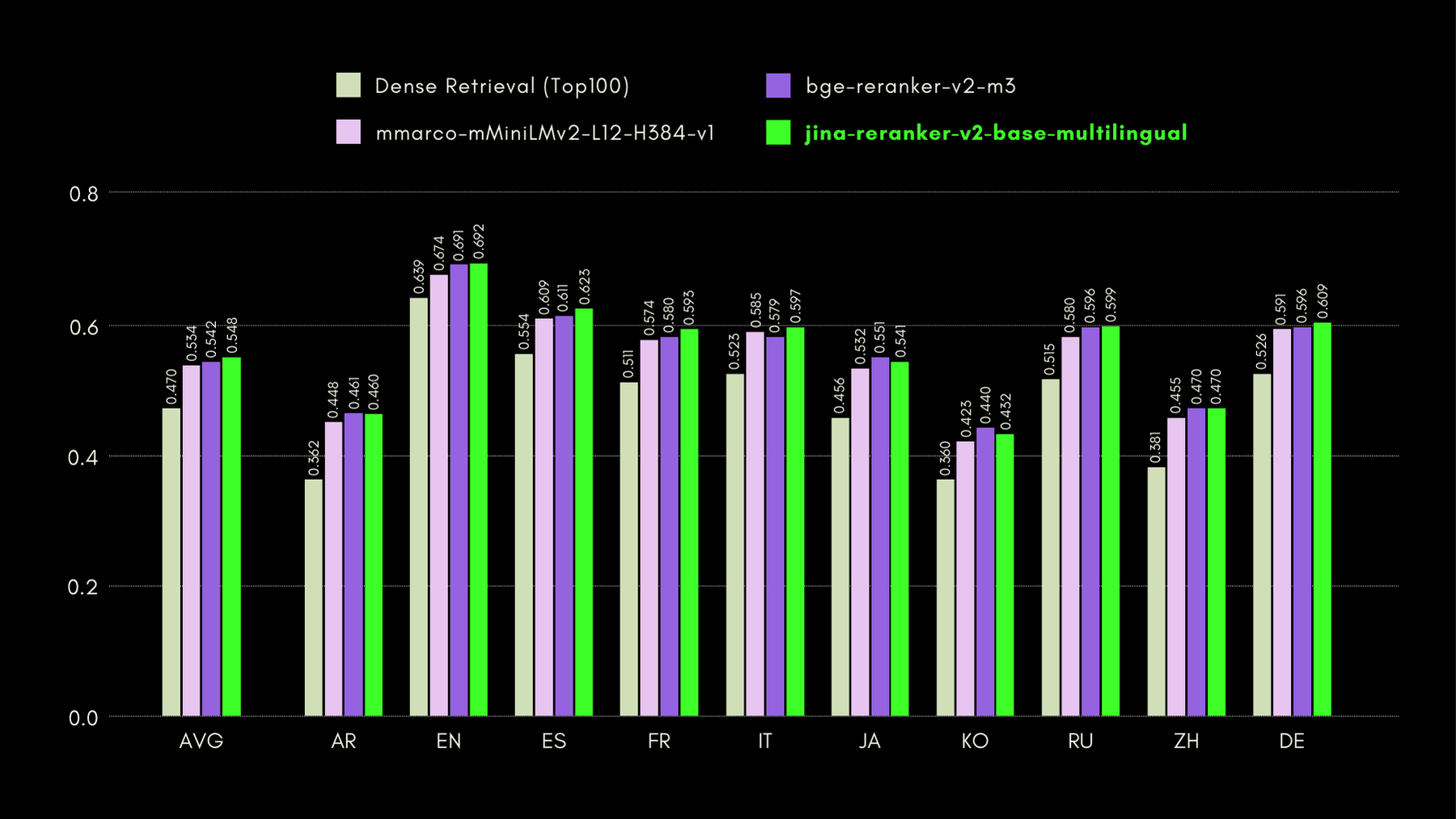
In der unten stehenden Grafik zeigen wir die Recall@10-Werte für jeden einbezogenen Reranker, einschließlich eines "Dense Retriever" als Baseline, der traditionelle Embedding-basierte Suche durchführt:
BEIR: Heterogener Benchmark für diverse IR-Aufgaben
Dieses Open-Source-Repository enthält einen Retrieval-Benchmark für viele Sprachen, aber wir konzentrieren uns nur auf die englischsprachigen Aufgaben. Diese bestehen aus 17 Datensätzen ohne Trainingsdaten, und der Fokus dieser Datensätze liegt auf der Evaluierung der Abrufgenauigkeit von neuronalen oder lexikalischen Retrievern.
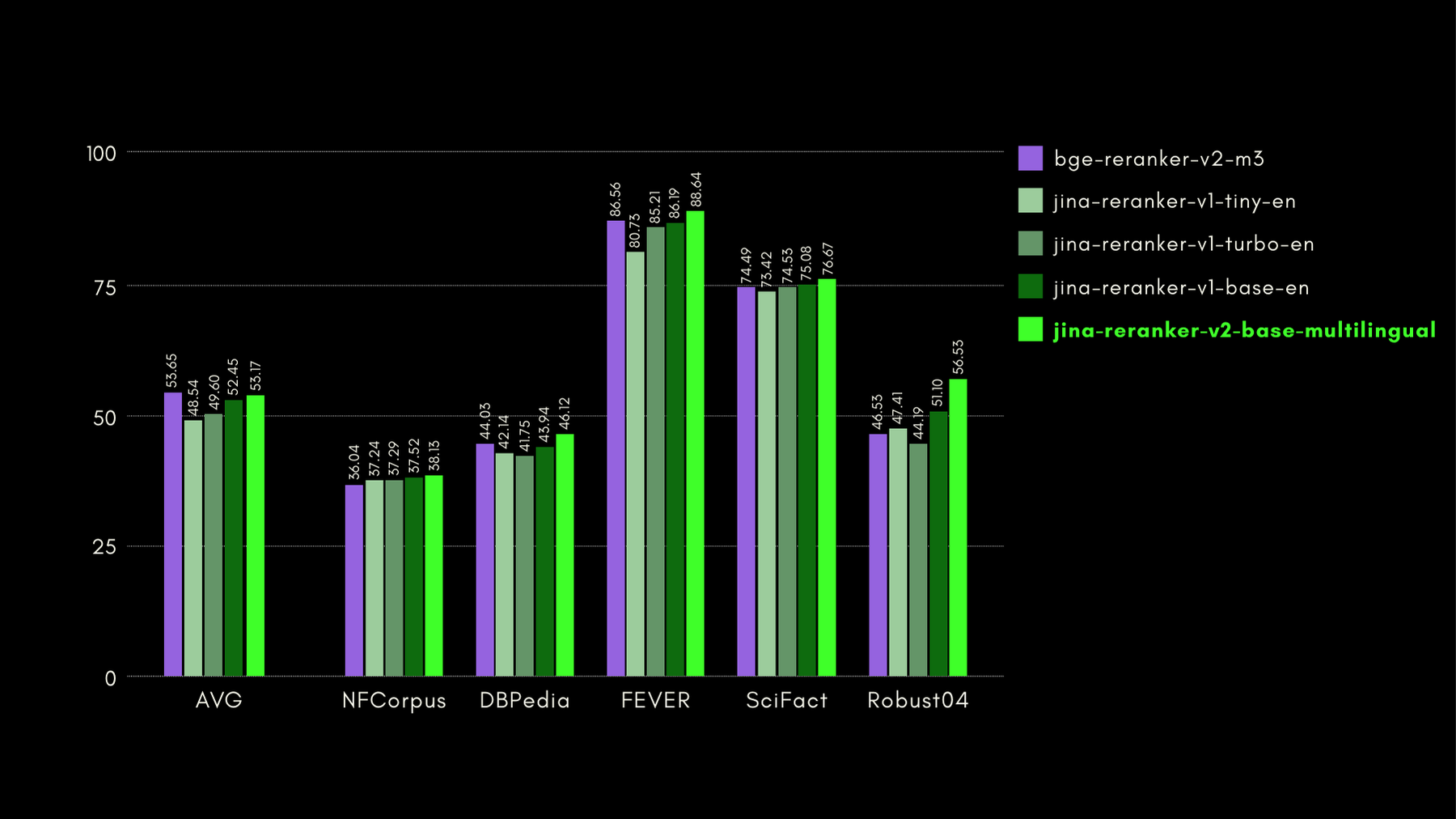
In der unten stehenden Grafik zeigen wir NDCG@10 für BEIR mit jedem einbezogenen Reranker. Die Ergebnisse auf BEIR zeigen deutlich, dass die neu eingeführten mehrsprachigen Fähigkeiten von jina-reranker-v2-base-multilingual seine englischsprachigen Retrieval-Fähigkeiten nicht beeinträchtigen, die darüber hinaus im Vergleich zu jina-reranker-v1-base-en deutlich verbessert wurden.
AirBench: Automatisierter heterogener IR-Benchmark
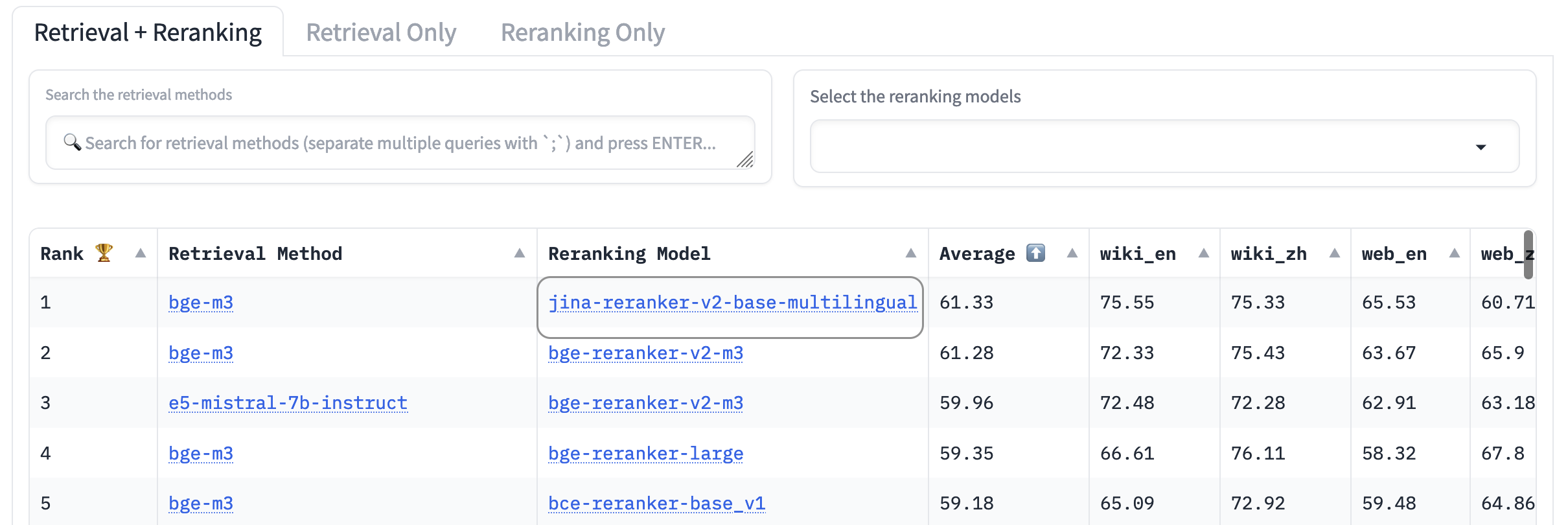
Wir haben zusammen mit BAAI den AirBench-Benchmark für RAG-Systeme mitentwickelt und veröffentlicht. Dieser Benchmark verwendet automatisch generierte synthetische Daten für spezifische Domänen und Aufgaben, ohne die Ground Truth öffentlich freizugeben, sodass die bewerteten Modelle keine Chance haben, sich an den Datensatz anzupassen.
Zum Zeitpunkt der Veröffentlichung übertrifft jina-reranker-v2-base-multilingual alle anderen enthaltenen Reranker-Modelle und belegt den ersten Platz auf der Bestenliste.
tagRückblick auf Tooling-Agents: LLMs den Umgang mit Tools beibringen
Seit dem großen KI-Boom vor einigen Jahren hat man gesehen, dass KI-Modelle bei Dingen, die Computer eigentlich gut können sollten, unterdurchschnittlich abschneiden. Betrachten Sie zum Beispiel diese Konversation mit Mistral-7b-Instruct-v0.1:

Dies mag auf den ersten Blick richtig erscheinen, aber tatsächlich ist 203 mal 7724 1.567.972.
Warum liegt das LLM also um mehr als den Faktor zehn daneben? Weil LLMs nicht darauf trainiert sind, Mathematik oder andere Arten des logischen Denkens durchzuführen, und das Fehlen jeglicher interner Rekursion garantiert praktisch, dass sie keine komplexen mathematischen Probleme lösen können. Sie sind darauf trainiert, Dinge zu sagen oder andere Aufgaben auszuführen, die nicht von Natur aus präzise sind.
LLMs halluzinieren jedoch gerne Antworten. Aus ihrer Perspektive ist 15.824.772 eine durchaus plausible Antwort auf 204 × 7.724. Es ist nur völlig falsch.
Agentic RAG verändert die Rolle von generativen LLMs von dem, worin sie schlecht sind — Denken und Wissen — zu dem, worin sie gut sind: Leseverständnis und Synthese von Informationen in natürlicher Sprache. Anstatt einfach eine Antwort zu generieren, findet RAG in allen verfügbaren Datenquellen Informationen, die für die Beantwortung Ihrer Anfrage relevant sind, und präsentiert sie dem Sprachmodell. Seine Aufgabe ist es nicht, eine Antwort zu erfinden, sondern die von einem anderen System gefundenen Antworten in einer natürlichen und ansprechenden Form zu präsentieren.
Wir haben Jina Reranker v2 darauf trainiert, empfindlich auf SQL-Datenbank-Schemas und Function-Calling zu reagieren. Dies erfordert eine andere Art von Semantik als herkömmliches Text-Retrieval. Es muss aufgaben- und codebewusst sein, und wir haben unseren Reranker speziell für diese Funktionalität trainiert.
tagJina Reranker v2 für strukturierte Datenabfragen
Während Embedding- und Reranker-Modelle unstrukturierte Daten bereits als First-Class-Citizens behandeln, fehlt bei den meisten Modellen noch die Unterstützung für strukturierte tabellarische Daten.
Jina Reranker v2 versteht die nachgelagerte Absicht, eine Quelle strukturierter Datenbanken wie MySQL oder MongoDB abzufragen, und weist einem strukturierten Tabellenschema basierend auf einer Eingabeanfrage den korrekten Relevanzwert zu.
Sie können das unten sehen, wo der Reranker die relevantesten Tabellen abruft, bevor ein LLM aufgefordert wird, eine SQL-Abfrage aus einer natürlichsprachigen Anfrage zu generieren:
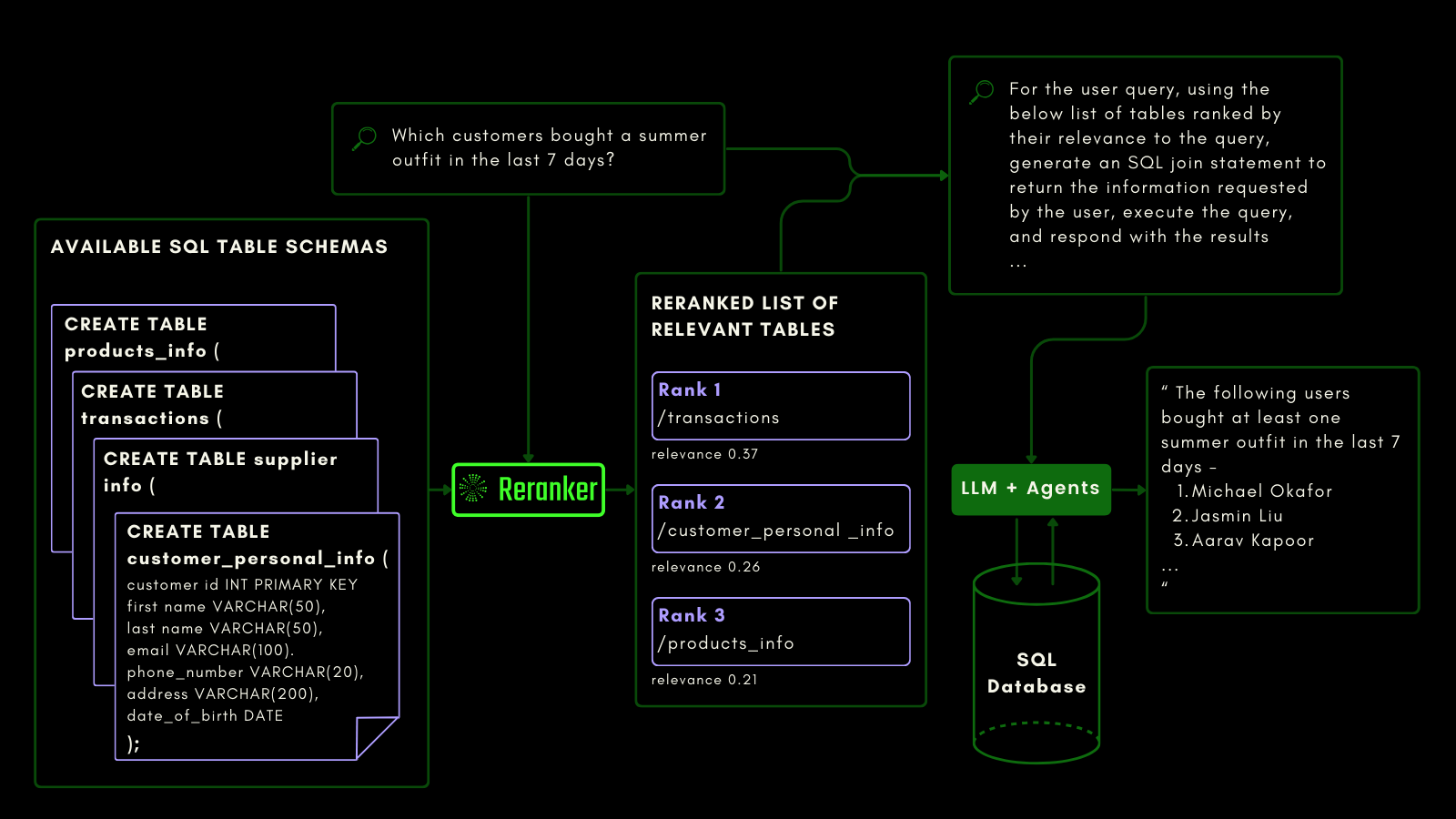
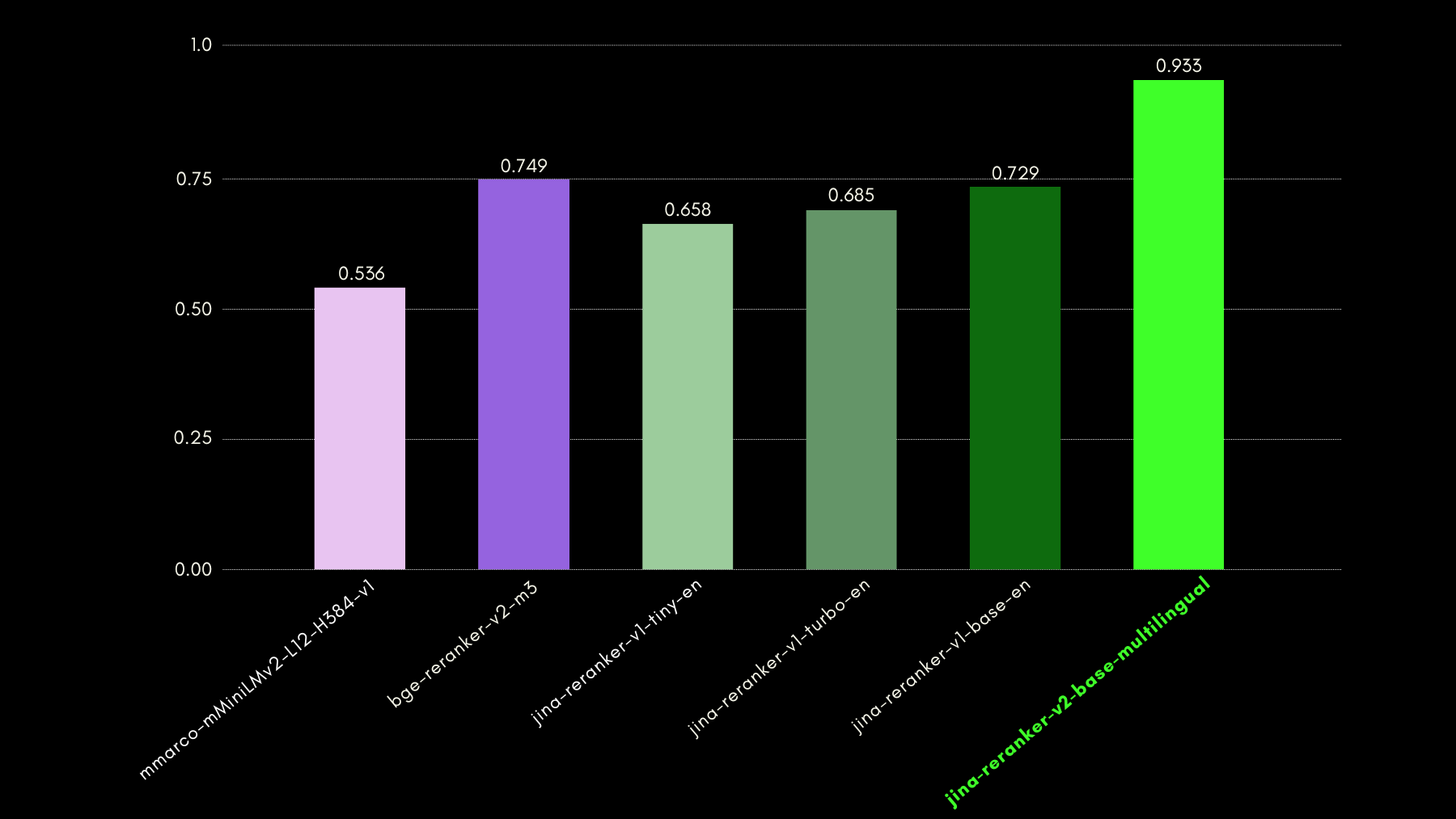
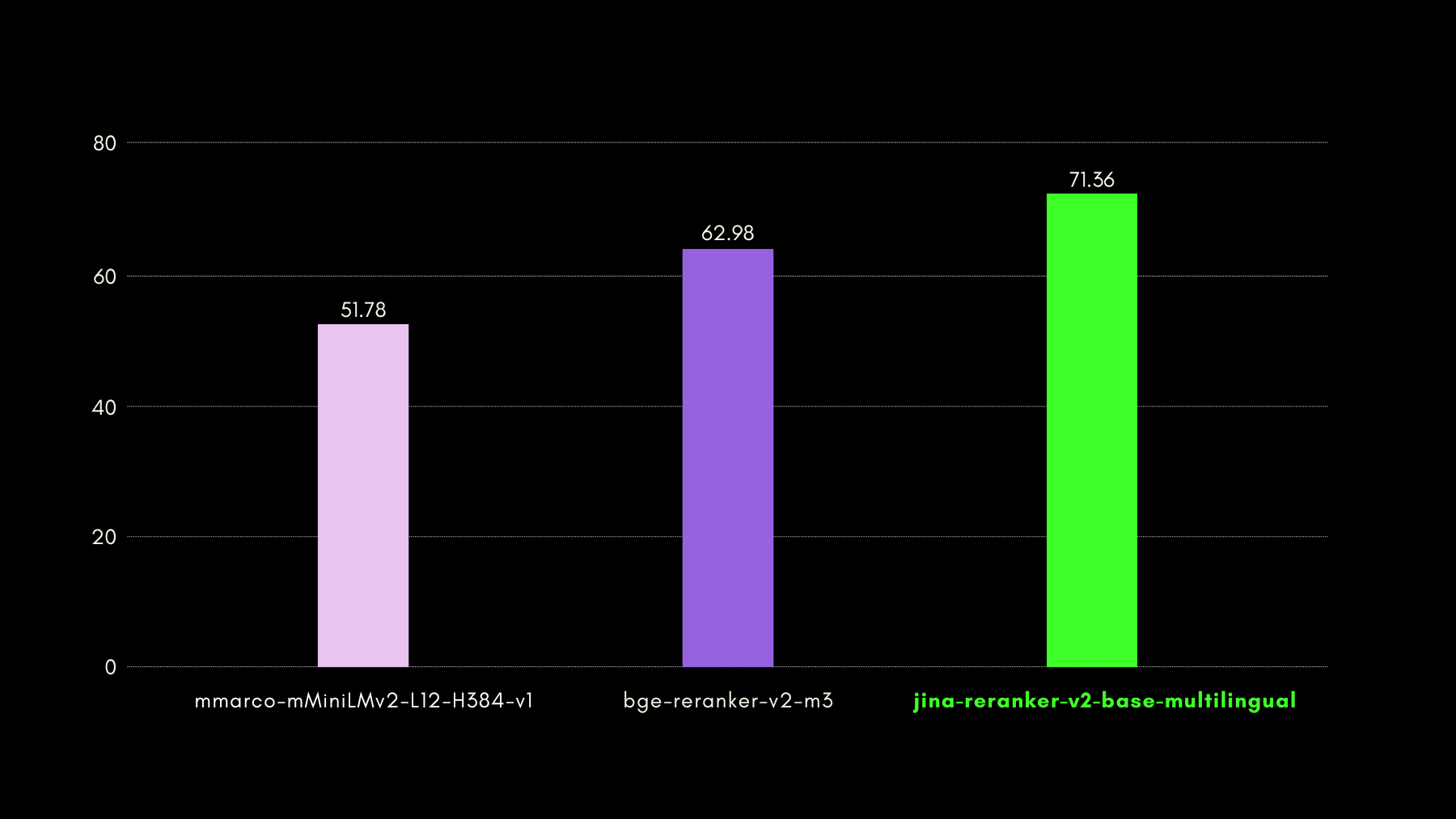
Wir haben die abfragebewussten Fähigkeiten mithilfe des NSText2SQL-Datensatz-Benchmarks evaluiert. Wir extrahieren aus der Spalte "instruction" des ursprünglichen Datensatzes in natürlicher Sprache geschriebene Anweisungen und das entsprechende Tabellenschema.
Die folgende Grafik vergleicht anhand von recall@3, wie erfolgreich Reranker-Modelle bei der Bewertung des korrekten Tabellenschemas entsprechend einer natürlichsprachigen Anfrage sind.
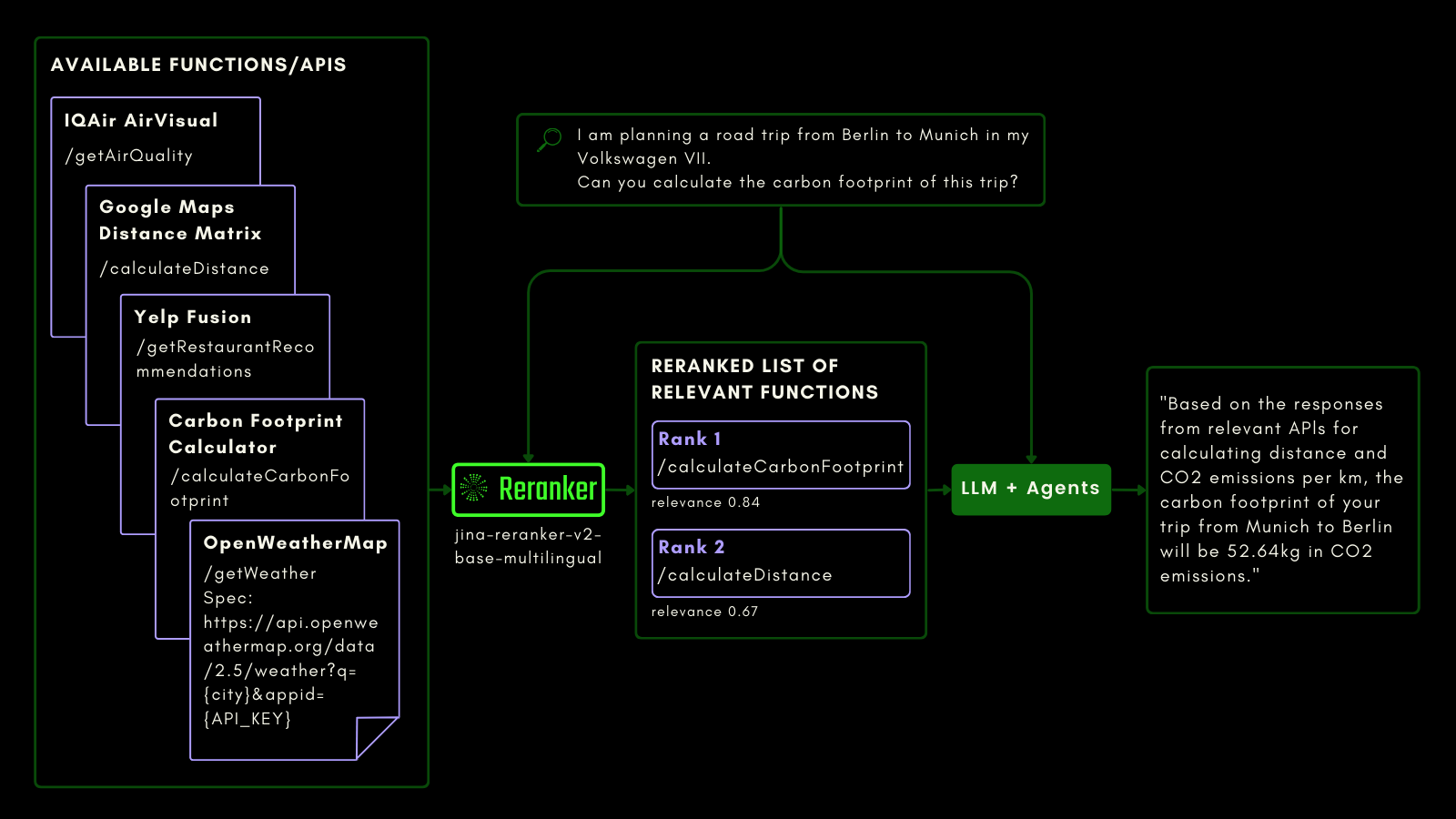
tagJina Reranker v2 für Function Calling
Wie bei der Abfrage einer SQL-Tabelle können Sie Agentic RAG verwenden, um externe Tools aufzurufen. Mit diesem Gedanken haben wir Function Calling in Jina Reranker v2 integriert, wodurch es Ihre Absicht für externe Funktionen versteht und Funktionsspezifikationen entsprechend Relevanzwerte zuweist.
Das folgende Schema erklärt (mit einem Beispiel), wie LLMs Reranker nutzen können, um Function-Calling-Fähigkeiten und letztendlich die Benutzerfahrung mit agentischer KI zu verbessern.
Wir haben die funktionsbewussten Fähigkeiten mit dem ToolBench-Benchmark evaluiert. Der Benchmark sammelt über 16.000 öffentliche APIs und entsprechende synthetisch generierte Anweisungen für deren Verwendung in Einzel- und Multi-API-Umgebungen.
Hier sind die Ergebnisse (recall@3-Metrik) im Vergleich zu anderen Reranker-Modellen:
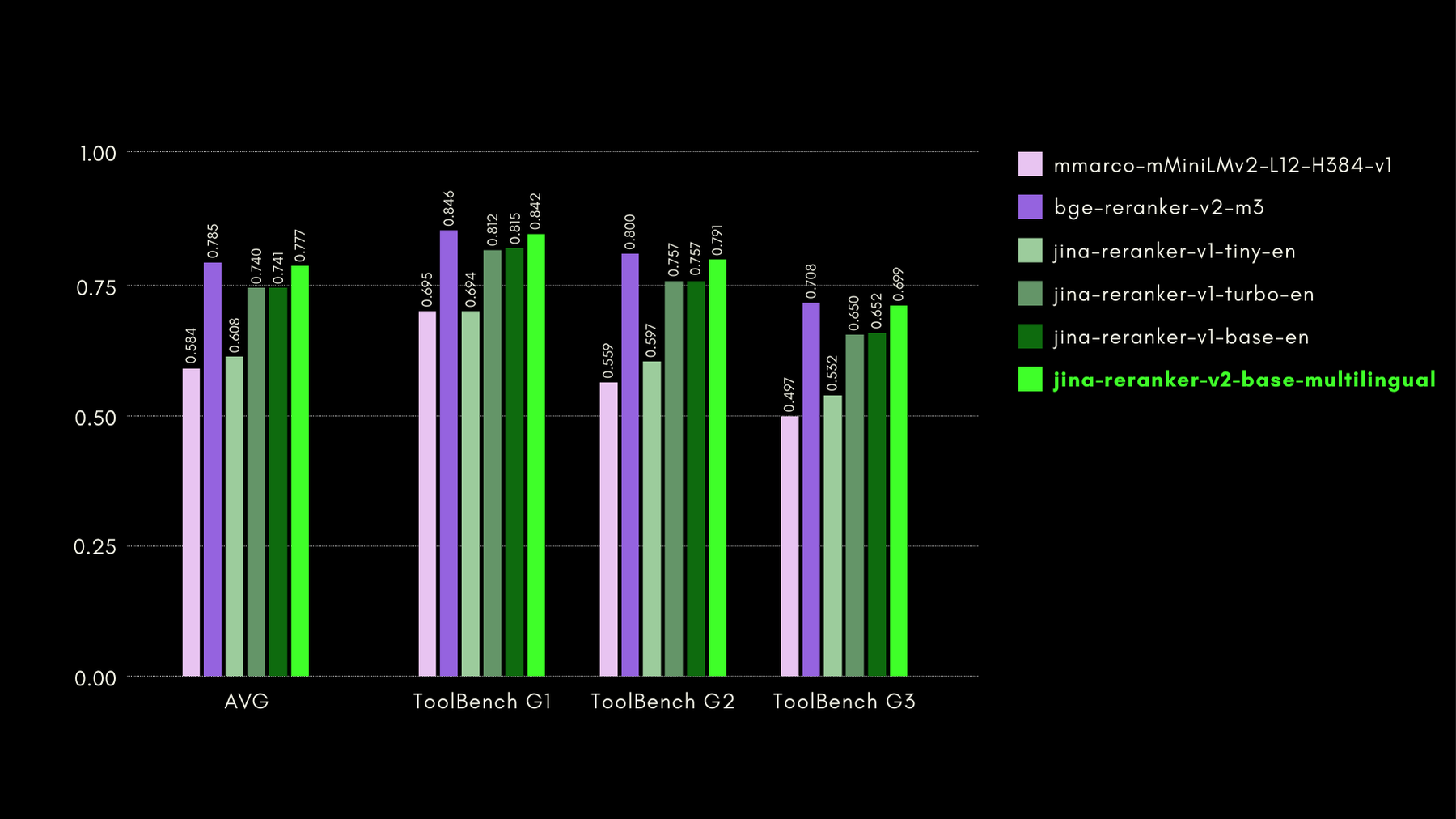
Wie wir auch in den späteren Abschnitten zeigen werden, kommt die nahezu State-of-the-Art-Leistung von jina-reranker-v2-base-multilingual mit dem Vorteil, dass es nur halb so groß wie bge-reranker-v2-m3 und fast 15-mal schneller ist.
tagJina Reranker v2 beim Code Retrieval
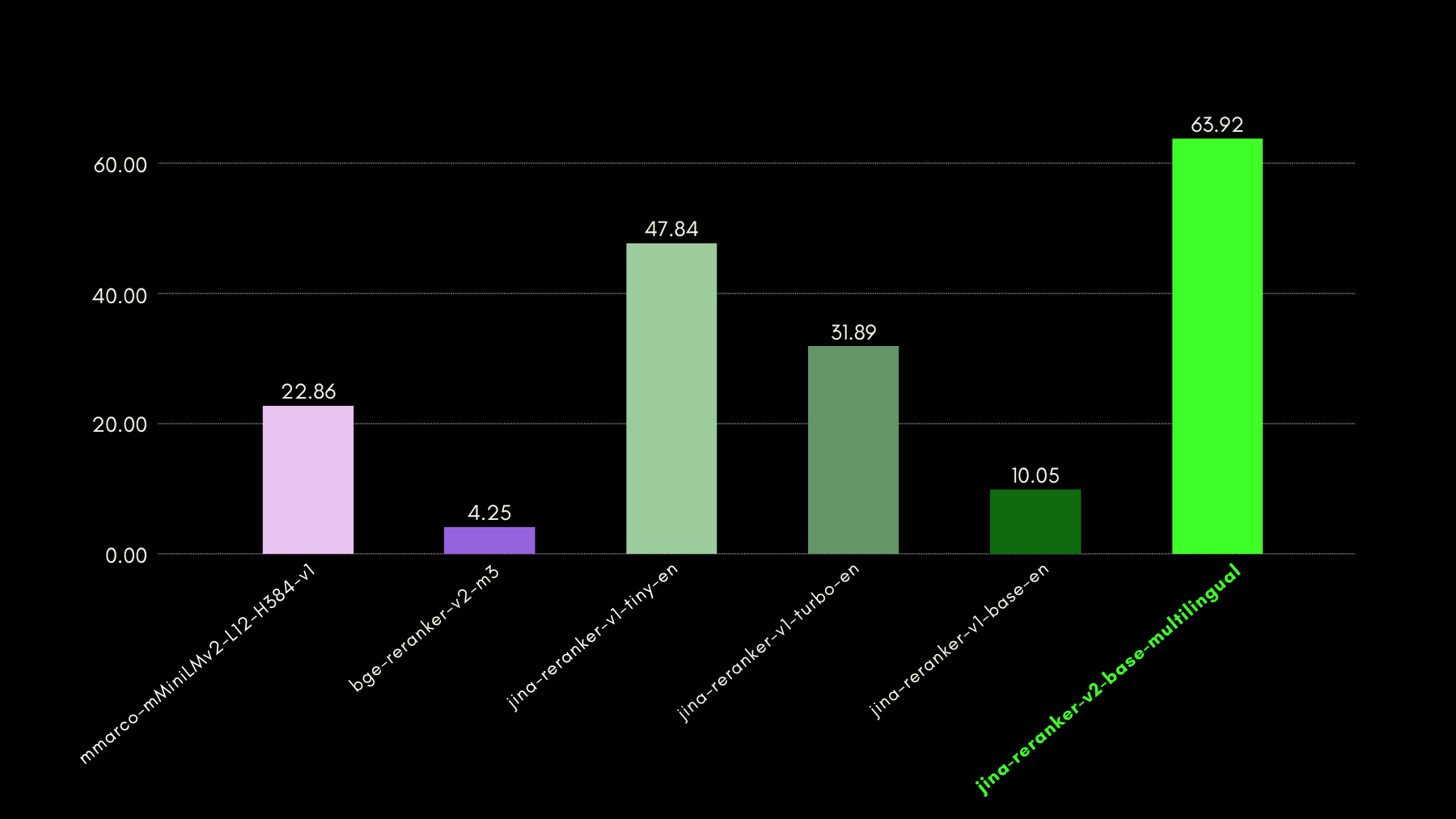
Jina Reranker v2 wurde nicht nur für Funktionsaufrufe und strukturierte Datenabfragen trainiert, sondern verbessert auch das Code Retrieval im Vergleich zu konkurrierenden Modellen ähnlicher Größe. Wir haben seine Code-Retrieval-Fähigkeiten mit dem CodeSearchNet Benchmark evaluiert. Der Benchmark ist eine Kombination aus Abfragen im Docstring- und natürlichsprachlichen Format, mit markierten Code-Segmenten, die für die Abfragen relevant sind.
Hier sind die Ergebnisse im Vergleich zu anderen Reranker-Modellen, gemessen in MRR@10:
tagUltraschnelle Inferenz mit Jina Reranker v2
Während Cross-Encoder-basierte neuronale Reranker bei der Vorhersage der Relevanz eines abgerufenen Dokuments hervorragend sind, bieten sie eine langsamere Inferenz als Embedding-Modelle. Insbesondere ist der Vergleich einer Abfrage mit n Dokumenten nacheinander in den meisten Vektordatenbanken viel langsamer als HNSW oder andere schnelle Retrieval-Methoden. Mit Jina Reranker v2 haben wir diese Langsamkeit behoben.
- Unsere einzigartigen Trainingserkenntnisse (die im folgenden Abschnitt beschrieben werden) führten dazu, dass unser Modell mit nur 278M Parametern State-of-the-Art-Genauigkeit erreicht. Im Vergleich zu beispielsweise
bge-reranker-v2-m3mit 567M Parametern ist Jina Reranker v2 nur halb so groß. Diese Reduzierung ist der erste Grund für den verbesserten Durchsatz (verarbeitete Dokumente pro 50ms). - Selbst bei vergleichbarer Modellgröße bietet Jina Reranker v2 6-mal höheren Durchsatz als unser vorheriges State-of-the-Art Jina Reranker v1 Modell für Englisch. Dies liegt daran, dass wir Jina Reranker v2 mit Flash Attention 2 implementiert haben, das Speicher- und Berechnungsoptimierungen in der Attention-Schicht von Transformer-basierten Modellen einführt.
Sie können das Ergebnis der oben genannten Schritte in Bezug auf die Durchsatzleistung von Jina Reranker v2 sehen:
tagWie wir Jina Reranker v2 trainiert haben
Wir haben jina-reranker-v2-base-multilingual in vier Phasen trainiert:
- Vorbereitung mit englischen Daten: Wir haben die erste Version des Modells vorbereitet, indem wir ein Basismodell nur mit englischsprachigen Daten trainiert haben, einschließlich Paaren (kontrastives Training) oder Tripeln (Abfrage, korrekte Antwort, falsche Antwort), Abfrage-Funktionsschema-Paaren und Abfrage-Tabellenschema-Paaren.
- Hinzufügung von sprachübergreifenden Daten: In der nächsten Phase haben wir sprachübergreifende Paare und Tripel-Datensätze hinzugefügt, um die mehrsprachigen Fähigkeiten des Basismodells speziell bei Retrieval-Aufgaben zu verbessern.
- Hinzufügung aller mehrsprachigen Daten: In dieser Phase konzentrierten wir uns darauf, dass das Modell die größtmögliche Menge unserer Daten sieht. Wir haben den Modell-Checkpoint aus der zweiten Phase mit allen Paar- und Tripel-Datensätzen aus über 100 ressourcenarmen und -reichen Sprachen feinabgestimmt.
- Feinabstimmung mit gemeinten Hard-Negatives: Nach Beobachtung der Reranking-Leistung aus der dritten Phase haben wir das Modell durch Hinzufügen weiterer Tripel-Daten mit spezifisch mehr Beispielen von Hard-Negatives für existierende Abfragen feinabgestimmt - Antworten, die oberflächlich relevant für die Abfrage erscheinen, aber tatsächlich falsch sind.
Dieser vierstufige Trainingsansatz basierte auf der Erkenntnis, dass die Einbeziehung von Funktionen und tabellarischen Schemata im Trainingsprozess so früh wie möglich es dem Modell ermöglichte, besonders auf diese Anwendungsfälle zu achten und sich mehr auf die Semantik der Kandidatendokumente als auf die Sprachkonstrukte zu konzentrieren.
tagJina Reranker v2 in der Praxis
tagÜber unsere Reranker API
Der schnellste und einfachste Weg, mit Jina Reranker v2 zu beginnen, ist die Verwendung der Jina Reranker API.
Gehen Sie zum API-Abschnitt dieser Seite, um jina-reranker-v2-base-multilingual mit der Programmiersprache Ihrer Wahl zu integrieren.
Beispiel 1: Ranking von Funktionsaufrufen
Um die relevanteste externe Funktion/Tool zu ranken, formatieren Sie die Abfrage und Dokumente (Funktionsschemata) wie unten gezeigt:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "I am planning a road trip from Berlin to Munich in my Volkswagen VII. Can you calculate the carbon footprint of this trip?",
"documents": [
"{'\''Name'\'': '\''getWeather'\'', '\''Specification'\'': '\''Provides current weather information for a specified city'\'', '\''spec'\'': '\''https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}'\'', '\''example'\'': '\''https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateDistance'\'', '\''Specification'\'': '\''Calculates the driving distance and time between multiple locations'\'', '\''spec'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}'\'', '\''example'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateCarbonFootprint'\'', '\''Specification'\'': '\''Estimates the carbon footprint for various activities, including transportation'\'', '\''spec'\'': '\''https://www.carboninterface.com/api/v1/estimates'\'', '\''example'\'': '\''{type: vehicle, distance: distance, vehicle_model_id: car}'\''}"
]
}'Denken Sie daran, <YOUR JINA AI TOKEN HERE> durch Ihren persönlichen Reranker API-Token zu ersetzen
Sie sollten erhalten:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 383,
"prompt_tokens": 383
},
"results": [
{
"index": 2,
"document": {
"text": "{'Name': 'calculateCarbonFootprint', 'Specification': 'Estimates the carbon footprint for various activities, including transportation', 'spec': 'https://www.carboninterface.com/api/v1/estimates', 'example': '{type: vehicle, distance: distance, vehicle_model_id: car}'}"
},
"relevance_score": 0.5422876477241516
},
{
"index": 1,
"document": {
"text": "{'Name': 'calculateDistance', 'Specification': 'Calculates the driving distance and time between multiple locations', 'spec': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}', 'example': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'}"
},
"relevance_score": 0.23283305764198303
},
{
"index": 0,
"document": {
"text": "{'Name': 'getWeather', 'Specification': 'Provides current weather information for a specified city', 'spec': 'https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}', 'example': 'https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'}"
},
"relevance_score": 0.05033063143491745
}
]
}Beispiel 2: Ranking von SQL-Abfragen
Ebenso können Sie die folgenden Beispiel-API-Aufrufe verwenden, um Relevanzwerte für strukturierte Tabellenschemata für Ihre Abfrage zu erhalten:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "which customers bought a summer outfit in the past 7 days?",
"documents": [
"CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));",
"CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));",
"CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));",
"CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
]
}'Die erwartete Antwort ist:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 253,
"prompt_tokens": 253
},
"results": [
{
"index": 2,
"document": {
"text": "CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));"
},
"relevance_score": 0.2789437472820282
},
{
"index": 0,
"document": {
"text": "CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));"
},
"relevance_score": 0.06477169692516327
},
{
"index": 3,
"document": {
"text": "CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
},
"relevance_score": 0.027742892503738403
},
{
"index": 1,
"document": {
"text": "CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));"
},
"relevance_score": 0.025516605004668236
}
]
}tagÜber RAG/LLM Frameworks
Jina Rerankers bestehende Integrationen mit LLM- und RAG-Orchestrierungs-Frameworks sollten bereits out-of-the-box funktionieren, indem Sie den Modellnamen jina-reranker-v2-base-multilingual verwenden. Sehen Sie in den jeweiligen Dokumentationsseiten nach, um mehr darüber zu erfahren, wie Sie Jina Reranker v2 in Ihre Anwendungen integrieren können.
- Haystack von deepset: Jina Reranker v2 kann mit der JinaRanker-Klasse in Haystack verwendet werden:
from haystack import Document
from haystack_integrations.components.rankers.jina import JinaRanker
docs = [Document(content="Paris"), Document(content="Berlin")]
ranker = JinaRanker(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>")
ranker.run(query="City in France", documents=docs, top_k=1)
- LlamaIndex: Jina Reranker v2 kann als JinaRerank node postprocessor Modul verwendet werden, indem man es initialisiert:
import os
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>", top_n=1)
- Langchain: Nutzen Sie die Jina Rerank Integration, um Jina Reranker 2 in Ihrer bestehenden Anwendung zu verwenden. Das JinaRerank-Modul sollte mit dem richtigen Modellnamen initialisiert werden:
from langchain_community.document_compressors import JinaRerank
reranker = JinaRerank(model="jina-reranker-v2-base-multilingual", jina_api_key="<YOUR JINA AI API KEY HERE>")
tagÜber HuggingFace
Wir öffnen auch den Zugang (unter CC-BY-NC-4.0) zum jina-reranker-v2-base-multilingual Modell auf Hugging Face für Forschungs- und Evaluierungszwecke.

Um das Modell von Hugging Face herunterzuladen und auszuführen, installieren Sie die transformers und einops Bibliotheken:
pip install transformers einops
pip install ninja
pip install flash-attn --no-build-isolation
Melden Sie sich über die Hugging Face CLI-Anmeldung mit Ihrem Hugging Face Zugriffstoken bei Ihrem Hugging Face-Konto an:
huggingface-cli login --token <"HF-Access-Token">
Laden Sie das vortrainierte Modell herunter:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
'jinaai/jina-reranker-v2-base-multilingual',
torch_dtype="auto",
trust_remote_code=True,
)
model.to('cuda') # oder 'cpu' wenn keine GPU verfügbar ist
model.eval()
Definieren Sie die Abfrage und die neu zu ordnenden Dokumente:
query = "Organic skincare products for sensitive skin"
documents = [
"Organic skincare for sensitive skin with aloe vera and chamomile.",
"New makeup trends focus on bold colors and innovative techniques",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille",
"Neue Make-up-Trends setzen auf kräftige Farben und innovative Techniken",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla",
"Las nuevas tendencias de maquillaje se centran en colores vivos y técnicas innovadoras",
"针对敏感肌专门设计的天然有机护肤产品",
"新的化妆趋势注重鲜艳的颜色和创新的技巧",
"敏感肌のために特別に設計された天然有機スキンケア製品",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています",
]
Konstruieren Sie Satzpaare und berechnen Sie die Relevanzwerte:
sentence_pairs = [[query, doc] for doc in documents]
scores = model.compute_score(sentence_pairs, max_length=1024)
Die Scores werden eine Liste von Fließkommazahlen sein, wobei jede Zahl die Relevanz des entsprechenden Dokuments zur Abfrage darstellt. Höhere Werte bedeuten höhere Relevanz.
Alternativ können Sie die rerank-Funktion verwenden, um große Texte neu zu ordnen, indem die Abfrage und die Dokumente automatisch basierend auf max_query_length und
max_length. Jeder Block wird individuell bewertet und die Bewertungen der einzelnen Blöcke werden dann kombiniert, um die endgültigen Neuordnungsergebnisse zu erstellen:results = model.rerank(
query,
documents,
max_query_length=512,
max_length=1024,
top_n=3
)
Diese Funktion gibt nicht nur die Relevanzwertung für jedes Dokument zurück, sondern auch deren Inhalt und Position in der ursprünglichen Dokumentenliste.
tagÜber Private Cloud-Bereitstellung
Vorgefertigte Pakete für die private Bereitstellung von Jina Reranker v2 für AWS- und Azure-Konten werden in Kürze auf unseren Verkäuferseiten im AWS Marketplace und Azure Marketplace zu finden sein.
tagWichtige Erkenntnisse zu Jina Reranker v2
Jina Reranker v2 stellt eine wichtige Erweiterung der Fähigkeiten für Search Foundation dar:
- Modernste Retrieval-Technologie durch Cross-Encoding eröffnet eine Vielzahl neuer Anwendungsbereiche.
- Verbesserte mehrsprachige und sprachübergreifende Funktionalität beseitigt Sprachbarrieren in Ihren Anwendungsfällen.
- Branchenführende Unterstützung für Function Calling zusammen mit der Berücksichtigung strukturierter Datenabfragen bringt Ihre agentenbasierten RAG-Fähigkeiten auf die nächste Präzisionsstufe.
- Besseres Retrieval von Computercode und computerformatierten Daten geht weit über die reine Textinformationssuche hinaus.
- Deutlich höherer Dokumentendurchsatz stellt sicher, dass Sie unabhängig von der Retrieval-Methode jetzt viel mehr abgerufene Dokumente schneller neu ordnen und den Großteil der feingranularen Relevanzberechnung an jina-reranker-v2-base-multilingual auslagern können.
RAG-Systeme sind mit Reranker v2 wesentlich präziser und helfen Ihren bestehenden Informationsverwaltungslösungen, mehr und bessere verwertbare Ergebnisse zu produzieren. Die sprachübergreifende Unterstützung macht all dies direkt für multinationale und mehrsprachige Unternehmen verfügbar, mit einer benutzerfreundlichen API zu einem erschwinglichen Preis.
Durch Tests mit Benchmarks aus realen Anwendungsfällen können Sie selbst sehen, wie Jina Reranker v2 modernste Leistung bei geschäftsrelevanten Aufgaben in einem einzigen KI-Modell beibehält und dabei Ihre Kosten senkt und Ihren Technologie-Stack vereinfacht.
