


Neu! Teil II: Tiefgehende Analyse von Boundary Cues und Missverständnissen.
Vor etwa einem Jahr, im Oktober 2023, veröffentlichten wir das weltweit erste Open-Source-Embedding-Modell mit einer Kontextlänge von 8K, jina-embeddings-v2-base-en. Seitdem gab es einige Diskussionen über den Nutzen von langem Kontext in Embedding-Modellen. Für viele Anwendungen ist es nicht ideal, ein tausende Wörter langes Dokument in eine einzige Embedding-Darstellung zu kodieren. Viele Anwendungsfälle erfordern das Abrufen kleinerer Textabschnitte, und dichte vektorbasierte Retrievalsysteme funktionieren oft besser mit kleineren Textsegmenten, da die Semantik in den Embedding-Vektoren weniger wahrscheinlich "überkomprimiert" wird.
Retrieval-Augmented Generation (RAG) ist eine der bekanntesten Anwendungen, die das Aufteilen von Dokumenten in kleinere Textabschnitte (etwa innerhalb von 512 Tokens) erfordert. Diese Chunks werden üblicherweise in einer Vektordatenbank gespeichert, wobei die Vektordarstellungen von einem Text-Embedding-Modell generiert werden. Während der Laufzeit kodiert dasselbe Embedding-Modell eine Anfrage in eine Vektordarstellung, die dann verwendet wird, um relevante gespeicherte Textabschnitte zu identifizieren. Diese Abschnitte werden anschließend an ein Large Language Model (LLM) übergeben, das basierend auf den abgerufenen Texten eine Antwort auf die Anfrage synthetisiert.

Kurz gesagt scheint das Einbetten kleinerer Chunks vorzuziehen zu sein, teilweise aufgrund der begrenzten Eingabegrößen nachgelagerter LLMs, aber auch weil es die Befürchtung gibt, dass wichtige kontextuelle Informationen in einem langen Kontext verwässert werden könnten, wenn sie in einen einzigen Vektor komprimiert werden.
Aber wenn die Industrie nur Embedding-Modelle mit einer Kontextlänge von 512 benötigt, was ist dann der Sinn des Trainings von Modellen mit einer Kontextlänge von 8192 überhaupt?
In diesem Artikel greifen wir diese wichtige, wenn auch unbequeme Frage auf, indem wir die Grenzen der naiven Chunking-Embedding-Pipeline in RAG untersuchen. Wir stellen einen neuen Ansatz namens "Late Chunking" vor, der die reichhaltigen Kontextinformationen nutzt, die von 8192-Längen-Embedding-Modellen bereitgestellt werden, um Chunks effektiver einzubetten.
tagDas Problem des verlorenen Kontexts
Die einfache RAG-Pipeline von Chunking-Embedding-Retrieving-Generating ist nicht ohne Herausforderungen. Insbesondere kann dieser Prozess weitreichende kontextuelle Abhängigkeiten zerstören. Mit anderen Worten, wenn relevante Informationen über mehrere Chunks verteilt sind, kann das Herausnehmen von Textsegmenten aus dem Kontext sie unwirksam machen, was diesen Ansatz besonders problematisch macht.
Im Bild unten wird ein Wikipedia-Artikel in Satz-Chunks aufgeteilt. Man kann sehen, dass Phrasen wie "its" und "the city" sich auf "Berlin" beziehen, das nur im ersten Satz erwähnt wird. Dies macht es für das Embedding-Modell schwieriger, diese Referenzen mit der richtigen Entität zu verbinden, wodurch eine Vektordarstellung von geringerer Qualität entsteht.

Dies bedeutet, wenn wir einen langen Artikel in Satzlängen-Chunks aufteilen, wie im obigen Beispiel, könnte ein RAG-System Schwierigkeiten haben, eine Anfrage wie "Was ist die Einwohnerzahl von Berlin?" zu beantworten. Da der Stadtname und die Einwohnerzahl nie zusammen in einem einzigen Chunk erscheinen und ohne größeren Dokumentkontext kann ein LLM, dem einer dieser Chunks präsentiert wird, anaphorische Referenzen wie "es" oder "die Stadt" nicht auflösen.
Es gibt einige Heuristiken, um dieses Problem zu mildern, wie das Resampling mit einem gleitenden Fenster, die Verwendung mehrerer Kontextfensterlängen und die Durchführung mehrfacher Dokumentscans. Wie alle Heuristiken sind diese Ansätze jedoch Glückssache; sie mögen in einigen Fällen funktionieren, aber es gibt keine theoretische Garantie für ihre Wirksamkeit.
tagDie Lösung: Late Chunking
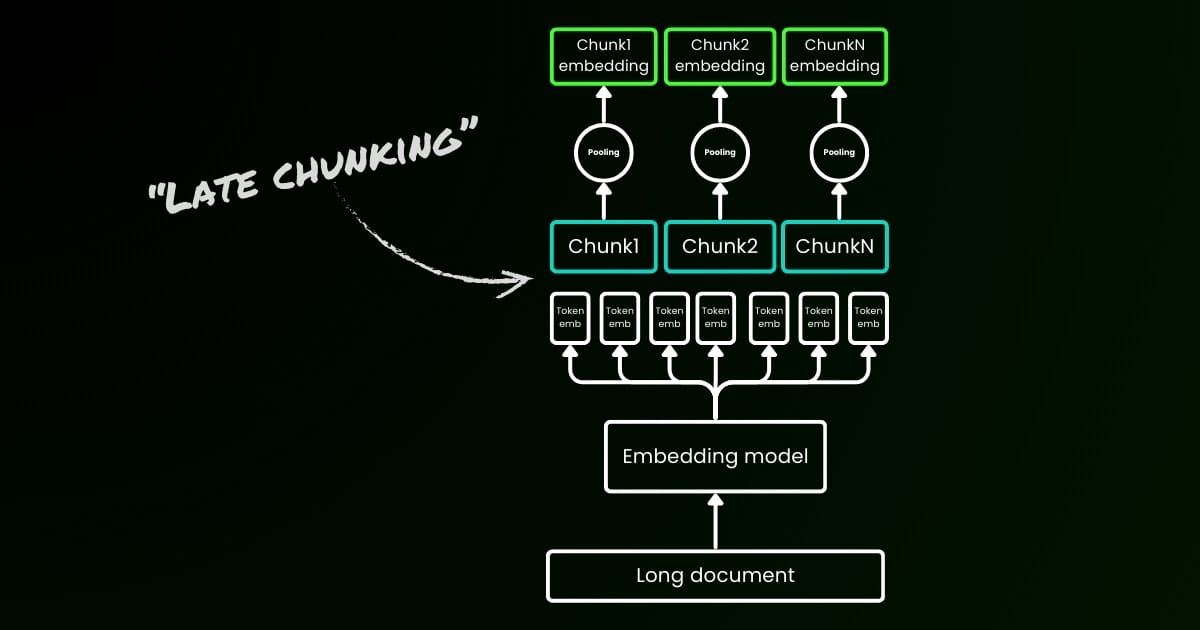
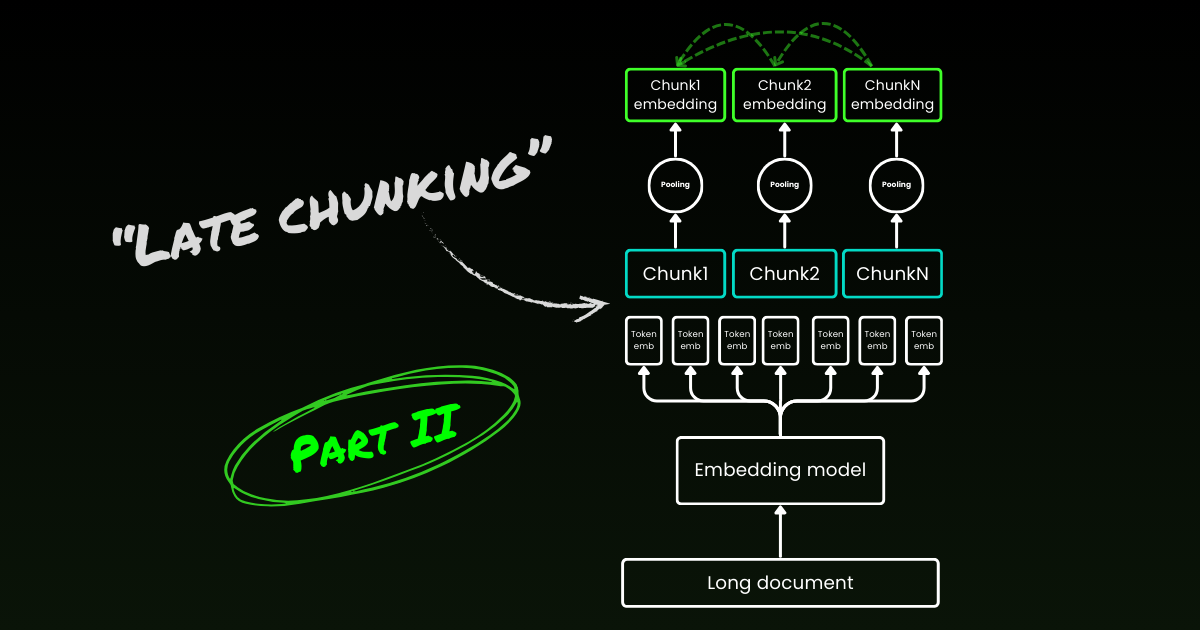
Der naive Kodierungsansatz (wie auf der linken Seite des Bildes unten zu sehen) verwendet Sätze, Absätze oder maximale Längenbeschränkungen, um den Text a priori aufzuteilen. Danach wird ein Embedding-Modell wiederholt auf diese resultierenden Chunks angewendet. Um ein einzelnes Embedding für jeden Chunk zu generieren, verwenden viele Embedding-Modelle Mean Pooling auf diesen Token-Level-Embeddings, um einen einzelnen Embedding-Vektor auszugeben.

Im Gegensatz dazu wendet der "Late Chunking"-Ansatz, den wir in diesem Artikel vorschlagen, zunächst die Transformer-Schicht des Embedding-Modells auf den gesamten Text oder so viel wie möglich davon an. Dies erzeugt eine Sequenz von Vektordarstellungen für jeden Token, die Textinformationen aus dem gesamten Text umfasst. Anschließend wird Mean Pooling auf jeden Chunk dieser Sequenz von Token-Vektoren angewendet, wodurch Embeddings für jeden Chunk entstehen, die den Kontext des gesamten Textes berücksichtigen. Im Gegensatz zum naiven Kodierungsansatz, der unabhängige und identisch verteilte (i.i.d.) Chunk-Embeddings generiert, erzeugt Late Chunking eine Reihe von Chunk-Embeddings, bei denen jedes auf den vorherigen "bedingt" ist und dadurch mehr kontextuelle Informationen für jeden Chunk kodiert.
Offensichtlich benötigen wir für die effektive Anwendung von Late Chunking Langkontext-Embedding-Modelle wie jina-embeddings-v2-base-en, die bis zu 8192 Tokens unterstützen—ungefähr zehn Standardseiten Text. Textsegmente dieser Größe haben mit viel geringerer Wahrscheinlichkeit kontextuelle Abhängigkeiten, die einen noch längeren Kontext zur Auflösung benötigen würden.
Es ist wichtig hervorzuheben, dass Late Chunking immer noch Boundary Cues benötigt, aber diese Cues werden erst nach dem Erhalt der Token-Level-Embeddings verwendet—daher der Begriff "late" in seiner Bezeichnung.
| Naive Chunking | Late Chunking | |
|---|---|---|
| Die Notwendigkeit von Boundary Cues | Ja | Ja |
| Die Verwendung von Boundary Cues | Direkt in der Vorverarbeitung | Nach Erhalt der Token-Level-Embeddings aus der Transformer-Schicht |
| Die resultierenden Chunk-Embeddings | i.i.d. | Bedingt |
| Kontextuelle Informationen benachbarter Chunks | Verloren. Einige Heuristiken (wie Overlap Sampling) zur Milderung | Gut erhalten durch Langkontext-Embedding-Modelle |
tagImplementierung und qualitative Evaluierung


Die Implementierung von Late Chunking finden Sie im oben verlinkten Google Colab. Hier nutzen wir unsere kürzlich veröffentlichte Funktion in der Tokenizer API, die alle möglichen Boundary Cues verwendet, um ein langes Dokument in sinnvolle Chunks zu segmentieren. Weitere Diskussionen über den Algorithmus hinter dieser Funktion finden Sie auf X.

Bei der Anwendung von Late Chunking auf das obige Wikipedia-Beispiel sieht man sofort eine Verbesserung der semantischen Ähnlichkeit. Zum Beispiel enthalten im Fall von „the city" und „Berlin" in einem Wikipedia-Artikel die Vektoren, die „the city" repräsentieren, nun Informationen, die es mit der vorherigen Erwähnung von „Berlin" verbinden, was es zu einer viel besseren Übereinstimmung für Anfragen mit diesem Stadtnamen macht.
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
Dies kann man in den numerischen Ergebnissen oben beobachten, die das Embedding des Begriffs „Berlin" mit verschiedenen Sätzen aus dem Artikel über Berlin mittels Cosinus-Ähnlichkeit vergleichen. Die Spalte „Sim. on IID chunk embeddings" zeigt die Ähnlichkeitswerte zwischen dem Query-Embedding von „Berlin" und den Embeddings mit a priori Chunking, während „Sim. under contextual chunk embedding" die Ergebnisse mit der Late-Chunking-Methode darstellt.
tagQuantitative Evaluation auf BEIR
Um die Effektivität von Late Chunking über ein Spielbeispiel hinaus zu verifizieren, haben wir es anhand einiger Retrieval-Benchmarks aus BeIR getestet. Diese Retrieval-Aufgaben bestehen aus einem Query-Set, einem Korpus von Textdokumenten und einer QRels-Datei, die Informationen über die IDs der für jede Anfrage relevanten Dokumente speichert.
Um die relevanten Dokumente für eine Anfrage zu identifizieren, werden die Dokumente gechunkt, in einen Embedding-Index kodiert und die ähnlichsten Chunks für jedes Query-Embedding mittels k-nächste Nachbarn (kNN) bestimmt. Da jeder Chunk einem Dokument entspricht, kann das kNN-Ranking der Chunks in ein kNN-Ranking der Dokumente umgewandelt werden (wobei nur das erste Vorkommen für Dokumente beibehalten wird, die mehrfach im Ranking erscheinen). Dieses resultierende Ranking wird dann mit dem Ranking aus der Ground-Truth QRels-Datei verglichen und Retrieval-Metriken wie nDCG@10 werden berechnet. Dieses Verfahren ist unten dargestellt, und das Evaluierungsskript ist in diesem Repository zur Reproduzierbarkeit verfügbar.
 jina-ai
jina-aiWir haben diese Evaluierung auf verschiedenen BeIR-Datensätzen durchgeführt und dabei naives Chunking mit unserer Late-Chunking-Methode verglichen. Für die Boundary Cues verwendeten wir einen Regex, der die Texte in Strings von etwa 256 Tokens aufteilt. Sowohl die naive als auch die Late-Chunking-Evaluierung verwendeten jina-embeddings-v2-small-en als Embedding-Modell; eine kleinere Version des v2-base-en Modells, das immer noch eine Länge von bis zu 8192 Tokens unterstützt. Die Ergebnisse sind in der Tabelle unten zu finden.
| Dataset | Avg. Document Length (characters) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) | No Chunking (nDCG@10) |
|---|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% | 63.89% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% | 65.18% |
| FiQA2018 | 767.2 | 33.25% | 33.84% | 33.43% |
| NFCorpus | 1589.8 | 23.46% | 29.98% | 30.40% |
| Quora | 62.2 | 87.19% | 87.19% | 87.19% |
In allen Fällen verbesserte Late Chunking die Ergebnisse im Vergleich zum naiven Ansatz. In einigen Fällen übertraf es sogar die Kodierung des gesamten Dokuments in ein einzelnes Embedding, während in anderen Datensätzen gar kein Chunking die besten Ergebnisse lieferte (Natürlich macht kein Chunking nur dann Sinn, wenn keine Notwendigkeit besteht, Chunks zu ranken, was in der Praxis selten vorkommt). Wenn wir die Leistungslücke zwischen dem naiven Ansatz und Late Chunking gegen die Dokumentenlänge auftragen, wird deutlich, dass die durchschnittliche Länge der Dokumente mit größeren Verbesserungen der nDCG-Werte durch Late Chunking korreliert. Mit anderen Worten: Je länger das Dokument, desto effektiver wird die Late-Chunking-Strategie.

tagFazit
In diesem Artikel haben wir einen einfachen Ansatz namens „Late Chunking" vorgestellt, um kurze Chunks unter Nutzung der Leistungsfähigkeit von Long-Context-Embedding-Modellen einzubetten. Wir haben gezeigt, wie traditionelles i.i.d. Chunk-Embedding keine kontextuellen Informationen bewahrt und zu suboptimalem Retrieval führt, und wie Late Chunking eine einfache, aber hocheffektive Lösung bietet, um kontextuelle Informationen innerhalb jedes Chunks zu erhalten und zu konditionieren. Die Effektivität von Late Chunking wird bei längeren Dokumenten zunehmend bedeutsamer – eine Fähigkeit, die nur durch fortgeschrittene Long-Context-Embedding-Modelle wie jina-embeddings-v2-base-en möglich wird. Wir hoffen, dass diese Arbeit nicht nur die Bedeutung von Long-Context-Embedding-Modellen validiert, sondern auch zu weiterer Forschung auf diesem Gebiet inspiriert.
Lesen Sie weiter in Teil II: Tiefer Einblick in Boundary Cues und Missverständnisse.
