



late_chunking steuert, ob das Modell das gesamte Dokument verarbeitet, bevor es in Chunks aufgeteilt wird, wodurch mehr Kontext über längere Texte hinweg erhalten bleibt. Aus Anwendersicht bleiben die Ein- und Ausgabeformate gleich, aber die Embedding-Werte spiegeln den gesamten Dokumentkontext wider, anstatt unabhängig für jeden Chunk berechnet zu werden.- Bei Verwendung von
late_chunking=Trueist die Gesamtzahl der Token (summiert über alle Chunks ininput) pro Anfrage auf 8192 beschränkt, die maximale Kontextlänge für v3. - Bei Verwendung von
late_chunking=Falsegilt diese Token-Beschränkung nicht, und die Gesamttoken werden nur durch das Ratelimit der Embedding API eingeschränkt.
Um Late Chunking zu aktivieren, übergeben Sie late_chunking=True in Ihren API-Aufrufen.
Sie können den Vorteil von Late Chunking beim Durchsuchen eines Chat-Verlaufs sehen:
history = [
"Sita, have you decided where you'd like to go for dinner this Saturday for your birthday?",
"I'm not sure. I'm not too familiar with the restaurants in this area.",
"We could always check out some recommendations online.",
"That sounds great. Let's do that!",
"What type of food are you in the mood for on your special day?",
"I really love Mexican or Italian cuisine.",
"How about this place, Bella Italia? It looks nice.",
"Oh, I've heard of that! Everyone says it's fantastic!",
"Shall we go ahead and book a table there then?",
"Yes, I think that would be a perfect choice! Let's call and reserve a spot."
]
Wenn wir mit Embeddings v2 nach What's a good restaurant? fragen, sind die Ergebnisse nicht sehr relevant:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.7675 |
| I really love Mexican or Italian cuisine. | 0.7561 |
| How about this place, Bella Italia? It looks nice. | 0.7268 |
| What type of food are you in the mood for on your special day? | 0.7217 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.7186 |
Mit v3 und ohne Late Chunking erhalten wir ähnliche Ergebnisse:
| Document | Cosine Similarity |
|---|---|
| I'm not sure. I'm not too familiar with the restaurants in this area. | 0.4005 |
| I really love Mexican or Italian cuisine. | 0.3752 |
| Sita, have you decided where you'd like to go for dinner this Saturday for your birthday? | 0.3330 |
| How about this place, Bella Italia? It looks nice. | 0.3143 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.2615 |
Allerdings sehen wir eine deutliche Leistungsverbesserung bei Verwendung von v3 und Late Chunking, wobei das relevanteste Ergebnis (ein gutes Restaurant) ganz oben steht:
| Document | Cosine Similarity |
|---|---|
| How about this place, Bella Italia? It looks nice. | 0.5061 |
| Oh, I've heard of that! Everyone says it's fantastic! | 0.4498 |
| I really love Mexican or Italian cuisine. | 0.4373 |
| What type of food are you in the mood for on your special day? | 0.4355 |
| Yes, I think that would be a perfect choice! Let's call and reserve a spot. | 0.4328 |
Wie Sie sehen können, wird auch wenn die beste Übereinstimmung das Wort "Restaurant" überhaupt nicht enthält, durch Late Chunking der ursprüngliche Kontext bewahrt und als korrekte Top-Antwort präsentiert. Es kodiert "Restaurant" in den Restaurantnamen "Bella Italia", weil es dessen Bedeutung im größeren Text erkennt.
tagEffizienz und Leistung mit Matryoshka Embeddings ausbalancieren
Der Parameter dimensions in Embeddings v3 ermöglicht es Ihnen, Speichereffizienz und Leistung bei minimalen Kosten auszubalancieren. Die Matryoshka Embeddings von v3 ermöglichen es Ihnen, die vom Modell erzeugten Vektoren zu kürzen und die Dimensionen nach Bedarf zu reduzieren, während nützliche Informationen erhalten bleiben. Kleinere Embeddings sind ideal, um Platz in Vektordatenbanken zu sparen und die Abrufgeschwindigkeit zu verbessern. Sie können die Auswirkungen auf die Leistung basierend auf der Reduzierung der Dimensionen abschätzen:
data = {
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 768, # 1024 by default
"input": [
"The Force will be with you. Always.",
"力量与你同在。永远。",
"La Forza sarà con te. Sempre.",
"フォースと共にあらんことを。いつも。"
]
}
response = requests.post(url, headers=headers, json=data)
tagFAQ
tagIch chunke meine Dokumente bereits vor der Generierung von Embeddings. Bietet Late Chunking Vorteile gegenüber meinem eigenen System?
Late Chunking bietet Vorteile gegenüber Pre-Chunking, da es das gesamte Dokument zuerst verarbeitet und wichtige kontextuelle Beziehungen im Text bewahrt, bevor es in Chunks aufgeteilt wird. Dies führt zu kontextuell reichhaltigeren Embeddings, was die Abrufgenauigkeit besonders bei komplexen oder langen Dokumenten verbessern kann. Zusätzlich kann Late Chunking während der Suche oder des Abrufs relevantere Antworten liefern, da das Modell ein ganzheitliches Verständnis des Dokuments hat, bevor es segmentiert wird. Dies führt zu einer besseren Gesamtleistung im Vergleich zum Pre-Chunking, bei dem Chunks ohne vollständigen Kontext unabhängig behandelt werden.
tagWarum ist v2 besser bei der Paarklassifizierung als v3, und sollte ich besorgt sein?
Der Grund, warum die Modelle v2-base-(zh/es/de) bei der Paarklassifizierung (PC) besser abzuschneiden scheinen, liegt hauptsächlich daran, wie der Durchschnittswert berechnet wird. Bei v2 wird nur Chinesisch für die PC-Leistung berücksichtigt, wo das Modell embeddings-v2-base-zh hervorragend abschneidet, was zu einer höheren Durchschnittspunktzahl führt. Die Benchmarks von v3 umfassen vier Sprachen: Chinesisch, Französisch, Polnisch und Russisch. Dadurch erscheint die Gesamtpunktzahl niedriger im Vergleich zu v2's rein chinesischer Punktzahl. v3 entspricht oder übertrifft jedoch Modelle wie multilingual-e5 in allen Sprachen für PC-Aufgaben. Dieser breitere Umfang erklärt den wahrgenommenen Unterschied, und der Leistungsabfall sollte kein Grund zur Sorge sein, besonders bei mehrsprachigen Anwendungen, wo v3 sehr wettbewerbsfähig bleibt.
tagÜbertrifft v3 wirklich die spezifischen Sprachen der v2 bilingualen Modelle?
Beim Vergleich von v3 mit den v2 bilingualen Modellen hängt der Leistungsunterschied von den spezifischen Sprachen und Aufgaben ab.
Die v2 bilingualen Modelle wurden für ihre jeweiligen Sprachen hochoptimiert. Daher können sie in sprachspezifischen Benchmarks, wie der Paarklassifizierung (PC) im Chinesischen, überlegene Ergebnisse zeigen. Dies liegt daran, dass das Design von embeddings-v2-base-zh speziell für diese Sprache maßgeschneidert wurde und es in diesem engen Bereich hervorragend abschneidet.
v3 ist jedoch für eine breitere mehrsprachige Unterstützung konzipiert und behandelt 89 Sprachen. Es wurde für verschiedene Aufgaben mit aufgabenspezifischen LoRA-Adaptern optimiert. Das bedeutet, dass v3 zwar nicht immer v2 in jeder einzelnen Aufgabe für eine bestimmte Sprache (wie PC für Chinesisch) übertrifft, aber tendenziell insgesamt besser abschneidet, wenn es über mehrere Sprachen hinweg oder in komplexeren, aufgabenspezifischen Szenarien wie Retrieval und Klassifizierung evaluiert wird.
Für mehrsprachige Aufgaben oder bei der Arbeit mit mehreren Sprachen bietet v3 eine ausgewogenere und umfassendere Lösung mit besserer Generalisierung über Sprachen hinweg. Für sehr sprachspezifische Aufgaben, für die das bilinguale Modell fein abgestimmt wurde, könnte v2 jedoch einen Vorteil behalten.
In der Praxis hängt das richtige Modell von den spezifischen Anforderungen Ihrer Aufgabe ab. Wenn Sie nur mit einer bestimmten Sprache arbeiten und v2 dafür optimiert wurde, können Sie mit v2 möglicherweise weiterhin wettbewerbsfähige Ergebnisse erzielen. Für allgemeinere oder mehrsprachige Anwendungen ist v3 aufgrund seiner Vielseitigkeit und breiteren Optimierung wahrscheinlich die bessere Wahl.
tagWarum ist v2 besser bei der Zusammenfassung als v3, und muss ich mir darüber Sorgen machen?
v2-base-en schneidet bei der Zusammenfassung (SM) besser ab, weil seine Architektur für Aufgaben wie semantische Ähnlichkeit optimiert wurde, die eng mit der Zusammenfassung verwandt ist. Im Gegensatz dazu ist v3 darauf ausgelegt, ein breiteres Spektrum an Aufgaben zu unterstützen, insbesondere bei Retrieval- und Klassifizierungsaufgaben, und eignet sich besser für komplexe und mehrsprachige Szenarien.
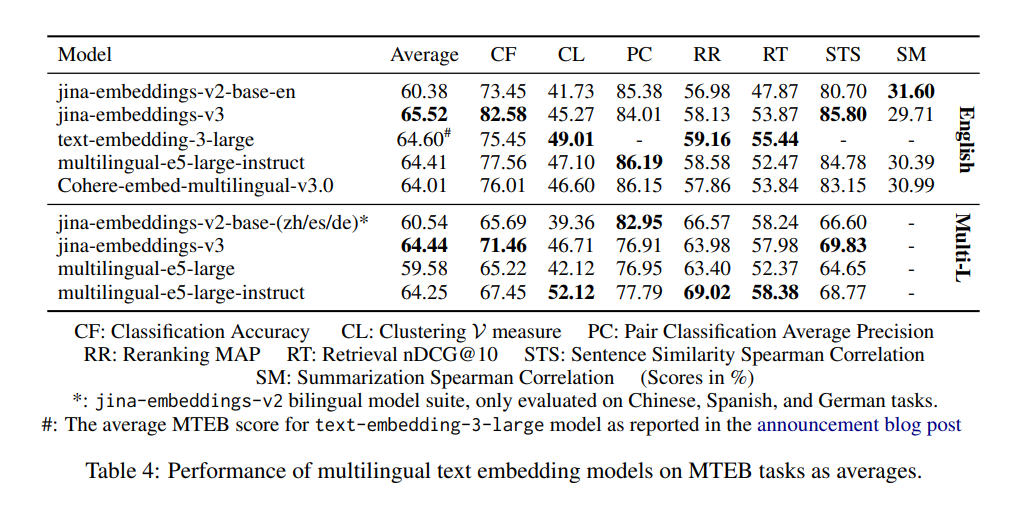
Dieser Leistungsunterschied bei SM sollte jedoch für die meisten Benutzer kein Anlass zur Sorge sein. Die SM-Evaluierung basiert nur auf einer Zusammenfassungsaufgabe, SummEval, die hauptsächlich die semantische Ähnlichkeit misst. Diese Aufgabe allein ist nicht sehr aussagekräftig oder repräsentativ für die breiteren Fähigkeiten des Modells. Da v3 in anderen kritischen Bereichen wie Retrieval hervorragend abschneidet, wird der Unterschied in der Zusammenfassung Ihre realen Anwendungsfälle wahrscheinlich nicht wesentlich beeinflussen.
