



Jina Embeddings und Jina Reranker sind jetzt über den AWS Marketplace mit Amazon SageMaker verfügbar. Für Unternehmensanwender, die großen Wert auf Sicherheit, Zuverlässigkeit und Konsistenz in ihren Cloud-Operationen legen, bringt dies Jina AIs modernste KI in ihre privaten AWS-Deployments, wo sie alle Vorteile von AWS's etablierter, stabiler Infrastruktur genießen können.
Mit unserer vollständigen Palette an Embedding- und Reranking-Modellen im AWS Marketplace können SageMaker-Nutzer von bahnbrechenden 8k Input-Kontextfenstern und erstklassigen mehrsprachigen Embeddings on demand zu wettbewerbsfähigen Preisen profitieren. Sie müssen keine Gebühren für den Transfer von Modellen in oder aus AWS zahlen, die Preise sind transparent und Ihre Abrechnung ist in Ihr AWS-Konto integriert.
Die derzeit auf Amazon SageMaker verfügbaren Modelle umfassen:
- Jina Embeddings v2 Base - English
- Jina Embeddings v2 Small - English
- Jina Embeddings v2 Zweisprachige Modelle:
- Jina Embeddings v2 Base - Code
- Jina Reranker v1 Base - English
- Jina ColBERT v1 - English
- Jina ColBERT Reranker v1 - English
Die vollständige Liste der Modelle finden Sie auf Jina AIs Anbieterseite im AWS Marketplace, und nutzen Sie eine siebentägige kostenlose Testversion.


Dieser Artikel führt Sie durch die Erstellung einer Retrieval-augmented Generation (RAG) Anwendung ausschließlich mit Komponenten von Amazon SageMaker. Die Modelle, die wir verwenden werden, sind Jina Embeddings v2 - English, Jina Reranker v1 und das Mistral-7B-Instruct Large Language Model.
Sie können auch einem Python Notebook folgen, das Sie herunterladen oder auf Google Colab ausführen können.
tagRetrieval-Augmented Generation
Retrieval-augmented Generation ist ein alternatives Paradigma in der generativen KI. Anstatt Large Language Models (LLMs) direkt Benutzeranfragen mit dem während des Trainings Gelernten beantworten zu lassen, nutzt es deren flüssige Sprachproduktion, während die Logik und Informationsgewinnung in einen dafür besser geeigneten externen Apparat verlagert wird.
Bevor ein LLM aufgerufen wird, rufen RAG-Systeme aktiv relevante Informationen aus einer externen Datenquelle ab und speisen diese als Teil des Prompts in das LLM ein. Die Rolle des LLM besteht darin, externe Informationen zu einer kohärenten Antwort auf Benutzeranfragen zu synthetisieren, wodurch das Risiko von Halluzinationen minimiert und die Relevanz und Nützlichkeit des Ergebnisses erhöht wird.
Ein RAG-System hat schematisch mindestens vier Komponenten:
- Eine Datenquelle, typischerweise eine Vektor-Datenbank, die für KI-gestützte Informationsgewinnung geeignet ist.
- Ein Informationsgewinnungssystem, das die Benutzeranfrage als Query behandelt und relevante Daten zur Beantwortung abruft.
- Ein System, oft mit einem KI-basierten Reranker, das einige der abgerufenen Daten auswählt und zu einem Prompt für ein LLM verarbeitet.
- Ein LLM, zum Beispiel eines der GPT-Modelle oder ein Open-Source-LLM wie das von Mistral, das die Benutzeranfrage und die bereitgestellten Daten aufnimmt und eine Antwort für den Benutzer generiert.
Embedding-Modelle eignen sich gut für die Informationsgewinnung und werden häufig dafür eingesetzt. Ein Text-Embedding-Modell nimmt Texte als Eingabe und gibt ein Embedding aus – einen hochdimensionalen Vektor –, dessen räumliche Beziehung zu anderen Embeddings ihre semantische Ähnlichkeit anzeigt, d.h. ähnliche Themen, Inhalte und verwandte Bedeutungen. Sie werden oft in der Informationsgewinnung eingesetzt, weil die Wahrscheinlichkeit, dass der Benutzer mit der Antwort zufrieden ist, mit der Nähe der Embeddings steigt. Sie lassen sich auch relativ einfach fine-tunen, um ihre Leistung in bestimmten Domänen zu verbessern.
Text-Reranker-Modelle verwenden ähnliche KI-Prinzipien, um Textsammlungen mit einer Anfrage zu vergleichen und sie nach ihrer semantischen Ähnlichkeit zu sortieren. Die Verwendung eines aufgabenspezifischen Reranker-Modells anstelle eines reinen Embedding-Modells erhöht oft die Präzision der Suchergebnisse dramatisch. Der Reranker in einer RAG-Anwendung wählt einige der Ergebnisse der Informationsgewinnung aus, um die Wahrscheinlichkeit zu maximieren, dass die richtigen Informationen im Prompt für das LLM enthalten sind.

tagLeistungsbenchmarking von Embedding-Modellen als SageMaker Endpoints
Wir haben die Leistung und Zuverlässigkeit des Jina Embeddings v2 Base - English Modells als SageMaker Endpoint getestet, der auf einer g4dn.xlarge Instanz läuft. In diesen Experimenten haben wir kontinuierlich jede Sekunde einen neuen Benutzer hinzugefügt, der jeweils eine Anfrage sendet, auf die Antwort wartet und nach Erhalt der Antwort wiederholt.
- Bei Anfragen von weniger als 100 Token blieben die Antwortzeiten pro Anfrage für bis zu 150 gleichzeitige Benutzer unter 100ms. Danach stiegen die Antwortzeiten linear von 100ms auf 1500ms mit der Zunahme gleichzeitiger Benutzer.
- Bei etwa 300 gleichzeitigen Benutzern erhielten wir mehr als 5 Fehler von der API und beendeten den Test.
- Bei Anfragen zwischen 1K und 8K Token blieben die Antwortzeiten pro Anfrage für bis zu 20 gleichzeitige Benutzer unter 8s. Danach stiegen die Antwortzeiten linear von 8s auf 60s mit der Zunahme gleichzeitiger Benutzer.
- Bei etwa 140 gleichzeitigen Benutzern erhielten wir mehr als 5 Fehler von der API und beendeten den Test.
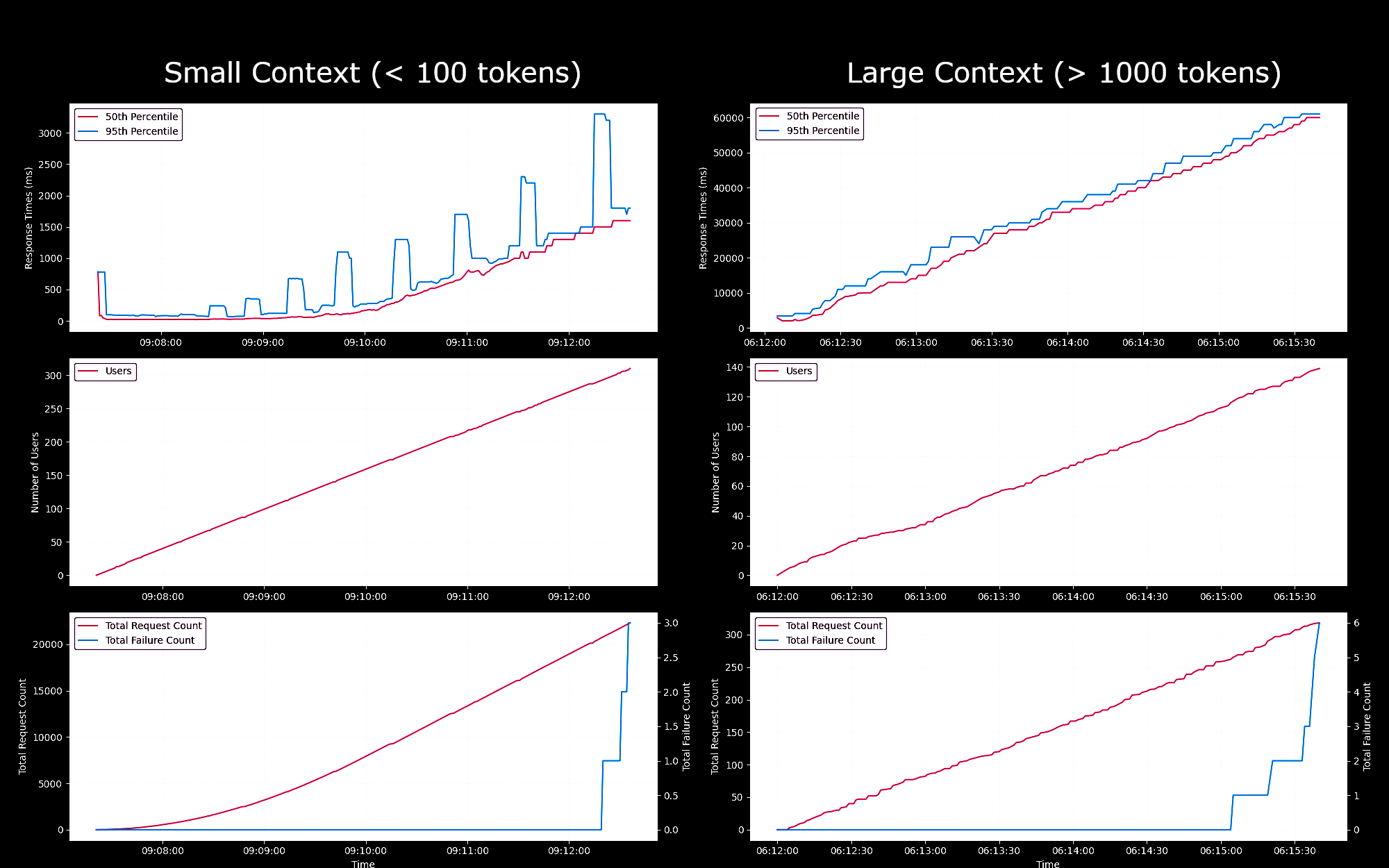
Basierend auf diesen Ergebnissen können wir schlussfolgern, dass für die meisten Benutzer mit normaler Embedding-Arbeitslast g4dn.xlarge oder g5.xlarge Instanzen ihren täglichen Bedarf decken sollten. Für große Indexierungs-Aufgaben, die typischerweise viel seltener ausgeführt werden als Such-Aufgaben, könnten Benutzer jedoch eine leistungsfähigere Option bevorzugen. Eine Liste aller verfügbaren Sagemaker-Instanzen finden Sie in der AWS-Übersicht von EC2.
tagKonfigurieren Sie Ihr AWS-Konto
Zunächst benötigen Sie ein AWS-Konto. Wenn Sie noch kein AWS-Benutzer sind, können Sie sich auf der AWS-Website für ein Konto registrieren.

tagEinrichten der AWS-Tools in Ihrer Python-Umgebung
Installieren Sie in Ihrer Python-Umgebung die für dieses Tutorial benötigten AWS-Tools und Bibliotheken:
pip install awscli jina-sagemaker
Sie benötigen einen Zugriffsschlüssel und einen geheimen Zugriffsschlüssel für Ihr AWS-Konto. Folgen Sie dazu den Anweisungen auf der AWS-Website.


Sie müssen auch eine AWS-Region auswählen, in der Sie arbeiten möchten.
Setzen Sie dann die Werte in Umgebungsvariablen. In Python oder in einem Python-Notebook können Sie das mit folgendem Code tun:
import os
os.environ["AWS_ACCESS_KEY_ID"] = <YOUR_ACCESS_KEY_ID>
os.environ["AWS_SECRET_ACCESS_KEY"] = <YOUR_SECRET_ACCESS_KEY>
os.environ["AWS_DEFAULT_REGION"] = <YOUR_AWS_REGION>
os.environ["AWS_DEFAULT_OUTPUT"] = "json"
Setzen Sie die Standardausgabe auf json.
Sie können dies auch über die AWS-Kommandozeilenanwendung oder durch Einrichten einer AWS-Konfigurationsdatei auf Ihrem lokalen Dateisystem tun. Weitere Details finden Sie in der Dokumentation auf der AWS-Website.
tagErstellen Sie eine Rolle
Sie benötigen auch eine AWS-Rolle mit ausreichenden Berechtigungen für die in diesem Tutorial benötigten Ressourcen.
Diese Rolle muss:
- AmazonSageMakerFullAccess aktiviert haben.
- Entweder:
- Berechtigung haben, AWS Marketplace-Abonnements zu erstellen und alle drei der folgenden Berechtigungen aktiviert haben:
- aws-marketplace:ViewSubscriptions
- aws-marketplace:Unsubscribe
- aws-marketplace:Subscribe
- Oder Ihr AWS-Konto hat ein Abonnement für jina-embedding-model.
- Berechtigung haben, AWS Marketplace-Abonnements zu erstellen und alle drei der folgenden Berechtigungen aktiviert haben:
Speichern Sie den ARN (Amazon Resource Name) der Rolle in der Variablen role:
role = <YOUR_ROLE_ARN>
Weitere Informationen finden Sie in der Dokumentation für Rollen auf der AWS-Website.
tagAbonnieren Sie Jina AI-Modelle im AWS Marketplace
In diesem Artikel werden wir das Jina Embeddings v2 base English Modell verwenden. Abonnieren Sie es im AWS Marketplace.
Wenn Sie nach unten scrollen, sehen Sie die Preisinformationen. AWS berechnet Modelle aus dem Marketplace stundenweise, sodass Ihnen die Zeit von der Aktivierung bis zur Deaktivierung des Modell-Endpunkts in Rechnung gestellt wird. Dieser Artikel zeigt Ihnen, wie Sie beides durchführen.
Wir werden auch das Jina Reranker v1 - English Modell verwenden, das Sie ebenfalls abonnieren müssen.
Wenn Sie diese abonniert haben, holen Sie sich die ARNs der Modelle für Ihre AWS-Region und speichern Sie sie in den Variablennamen embedding_package_arn und reranker_package_arn. Der Code in diesem Tutorial wird sie unter diesen Variablennamen referenzieren.
Wenn Sie nicht wissen, wie Sie die ARNs erhalten, setzen Sie Ihren Amazon-Regionsnamen in die Variable region und verwenden Sie den folgenden Code:
region = os.environ["AWS_DEFAULT_REGION"]
def get_arn_for_model(region_name, model_name):
model_package_map = {
"us-east-1": f"arn:aws:sagemaker:us-east-1:253352124568:model-package/{model_name}",
"us-east-2": f"arn:aws:sagemaker:us-east-2:057799348421:model-package/{model_name}",
"us-west-1": f"arn:aws:sagemaker:us-west-1:382657785993:model-package/{model_name}",
"us-west-2": f"arn:aws:sagemaker:us-west-2:594846645681:model-package/{model_name}",
"ca-central-1": f"arn:aws:sagemaker:ca-central-1:470592106596:model-package/{model_name}",
"eu-central-1": f"arn:aws:sagemaker:eu-central-1:446921602837:model-package/{model_name}",
"eu-west-1": f"arn:aws:sagemaker:eu-west-1:985815980388:model-package/{model_name}",
"eu-west-2": f"arn:aws:sagemaker:eu-west-2:856760150666:model-package/{model_name}",
"eu-west-3": f"arn:aws:sagemaker:eu-west-3:843114510376:model-package/{model_name}",
"eu-north-1": f"arn:aws:sagemaker:eu-north-1:136758871317:model-package/{model_name}",
"ap-southeast-1": f"arn:aws:sagemaker:ap-southeast-1:192199979996:model-package/{model_name}",
"ap-southeast-2": f"arn:aws:sagemaker:ap-southeast-2:666831318237:model-package/{model_name}",
"ap-northeast-2": f"arn:aws:sagemaker:ap-northeast-2:745090734665:model-package/{model_name}",
"ap-northeast-1": f"arn:aws:sagemaker:ap-northeast-1:977537786026:model-package/{model_name}",
"ap-south-1": f"arn:aws:sagemaker:ap-south-1:077584701553:model-package/{model_name}",
"sa-east-1": f"arn:aws:sagemaker:sa-east-1:270155090741:model-package/{model_name}",
}
return model_package_map[region_name]
embedding_package_arn = get_arn_for_model(region, "jina-embeddings-v2-base-en")
reranker_package_arn = get_arn_for_model(region, "jina-reranker-v1-base-en")
tagDatensatz laden
In diesem Tutorial werden wir eine Sammlung von Videos des YouTube-Kanals TU Delft Online Learning verwenden. Dieser Kanal produziert verschiedene Bildungsmaterialien in MINT-Fächern. Seine Inhalte sind CC-BY lizenziert.


Wir haben 193 Videos des Kanals heruntergeladen und mit OpenAIs Open-Source Whisper Spracherkennungsmodell verarbeitet. Wir haben das kleinste Modell openai/whisper-tiny verwendet, um die Videos in Transkripte umzuwandeln.
Die Transkripte wurden in einer CSV-Datei organisiert, die Sie hier herunterladen können.
Jede Zeile der Datei enthält:
- Den Video-Titel
- Die Video-URL auf YouTube
- Ein Texttranskript des Videos
Um diese Daten in Python zu laden, installieren Sie zunächst pandas und requests:
pip install requests pandas
Laden Sie die CSV-Daten direkt in einen Pandas DataFrame namens tu_delft_dataframe:
import pandas
# Load the CSV file
tu_delft_dataframe = pandas.read_csv("https://raw.githubusercontent.com/jina-ai/workshops/feat-sagemaker-post/notebooks/embeddings/sagemaker/tu_delft.csv")
Sie können den Inhalt mit der head()-Methode des DataFrames überprüfen. In einem Notebook sollte es etwa so aussehen:
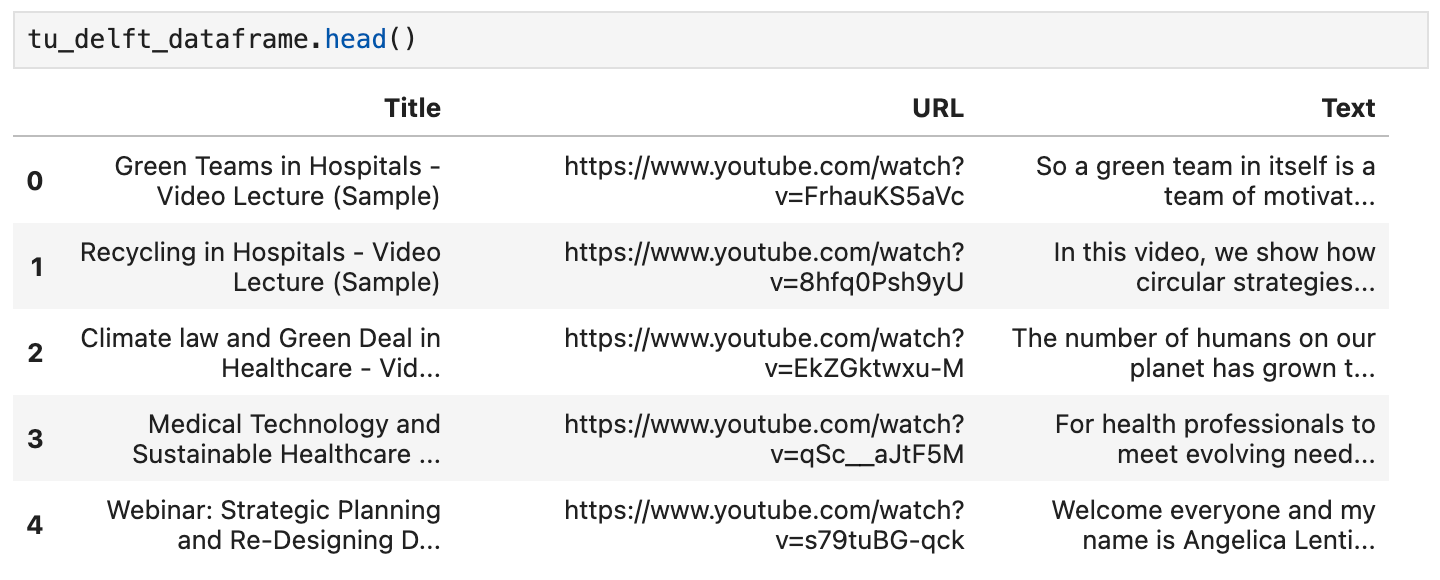
Sie können auch die Videos über die URLs in diesem Datensatz ansehen und überprüfen, dass die Spracherkennung zwar nicht perfekt, aber grundsätzlich gut funktioniert.
tagStarten des Jina Embeddings v2 Endpunkts
Der folgende Code wird eine Instanz von ml.g4dn.xlarge auf AWS starten, um das Embedding-Modell auszuführen. Dies kann einige Minuten dauern.
import boto3
from jina_sagemaker import Client
# Choose a name for your embedding endpoint. It can be anything convenient.
embeddings_endpoint_name = "jina_embedding"
embedding_client = Client(region_name=boto3.Session().region_name)
embedding_client.create_endpoint(
arn=embedding_package_arn,
role=role,
endpoint_name=embeddings_endpoint_name,
instance_type="ml.g4dn.xlarge",
n_instances=1,
)
embedding_client.connect_to_endpoint(endpoint_name=embeddings_endpoint_name)
Ändern Sie den instance_type, um bei Bedarf einen anderen AWS Cloud-Instanztyp auszuwählen.
tagDatensatz erstellen und indexieren
Nachdem wir die Daten geladen haben und ein Jina Embeddings v2 Modell ausführen, können wir die Daten vorbereiten und indexieren. Wir werden die Daten in einem FAISS Vector Store speichern, einer Open-Source-Vektordatenbank, die speziell für KI-Anwendungen entwickelt wurde.
Installieren Sie zunächst die restlichen Voraussetzungen für unsere RAG-Anwendung:
pip install tdqm numpy faiss-cpu
tagChunking
Wir müssen die einzelnen Transkripte in kleinere Teile, sogenannte "Chunks", aufteilen, damit wir mehrere Texte in einen Prompt für das LLM einfügen können. Der folgende Code teilt die einzelnen Transkripte an Satzgrenzen auf und stellt standardmäßig sicher, dass alle Chunks nicht mehr als 128 Wörter enthalten.
def chunk_text(text, max_words=128):
"""
Divide text into chunks where each chunk contains the maximum number
of full sentences with fewer words than `max_words`.
"""
sentences = text.split(".")
chunk = []
word_count = 0
for sentence in sentences:
sentence = sentence.strip(".")
if not sentence:
continue
words_in_sentence = len(sentence.split())
if word_count + words_in_sentence <= max_words:
chunk.append(sentence)
word_count += words_in_sentence
else:
# Yield the current chunk and start a new one
if chunk:
yield ". ".join(chunk).strip() + "."
chunk = [sentence]
word_count = words_in_sentence
# Yield the last chunk if it's not empty
if chunk:
yield " ".join(chunk).strip() + "."tagEmbeddings für jeden Chunk generieren
Wir benötigen ein Embedding für jeden Chunk, um ihn in der FAISS-Datenbank zu speichern. Um diese zu erhalten, übergeben wir die Text-Chunks an den Jina AI Embedding-Modell-Endpunkt mittels der Methode embedding_client.embed(). Dann fügen wir die Text-Chunks und Embedding-Vektoren als neue Spalten chunks und embeddings zum pandas DataFrame tu_delft_dataframe hinzu:
import numpy as np
from tqdm import tqdm
tqdm.pandas()
def generate_embeddings(text_df):
chunks = list(chunk_text(text_df["Text"]))
embeddings = []
for i, chunk in enumerate(chunks):
response = embedding_client.embed(texts=[chunk])
chunk_embedding = response[0]["embedding"]
embeddings.append(np.array(chunk_embedding))
text_df["chunks"] = chunks
text_df["embeddings"] = embeddings
return text_df
print("Embedding text chunks ...")
tu_delft_dataframe = generate_embeddings(tu_delft_dataframe)
## wenn Sie Google Colab oder ein Python Notebook verwenden, können Sie
## die obige Zeile löschen und stattdessen die folgende Zeile auskommentieren:
# tu_delft_dataframe = tu_delft_dataframe.progress_apply(generate_embeddings, axis=1)
tagSemantische Suche mit Faiss einrichten
Der folgende Code erstellt eine FAISS-Datenbank und fügt die Chunks und Embedding-Vektoren durch Iteration über tu_delft_pandas ein:
import faiss
dim = 768 # Dimension der Jina v2 Embeddings
index_with_ids = faiss.IndexIDMap(faiss.IndexFlatIP(dim))
k = 0
doc_ref = dict()
for idx, row in tu_delft_dataframe.iterrows():
embeddings = row["embeddings"]
for i, embedding in enumerate(embeddings):
normalized_embedding = np.ascontiguousarray(np.array(embedding, dtype="float32").reshape(1, -1))
faiss.normalize_L2(normalized_embedding)
index_with_ids.add_with_ids(normalized_embedding, k)
doc_ref[k] = (row["chunks"][i], idx)
k += 1
tagStarten des Jina Reranker v1 Endpunkts
Wie beim Jina Embedding v2 Modell oben wird dieser Code eine Instanz von ml.g4dn.xlarge auf AWS starten, um das Reranker-Modell auszuführen. Die Ausführung kann ebenfalls mehrere Minuten dauern.
import boto3
from jina_sagemaker import Client
# Wählen Sie einen Namen für Ihren Reranker-Endpunkt. Es kann ein beliebiger Name sein.
reranker_endpoint_name = "jina_reranker"
reranker_client = Client(region_name=boto3.Session().region_name)
reranker_client.create_endpoint(
arn=reranker_package_arn,
role=role,
endpoint_name=reranker_endpoint_name,
instance_type="ml.g4dn.xlarge",
n_instances=1,
)
reranker_client.connect_to_endpoint(endpoint_name=reranker_endpoint_name)
tagAbfragefunktionen definieren
Als Nächstes definieren wir eine Funktion, die die ähnlichsten Transkript-Chunks zu einer beliebigen Textabfrage identifiziert.
Dies ist ein zweistufiger Prozess:
- Konvertieren der Benutzereingabe in einen Embedding-Vektor mittels der Methode
embedding_client.embed(), genau wie in der Vorbereitungsphase. - Übergeben des Embeddings an den FAISS-Index, um die besten Übereinstimmungen zu erhalten. In der folgenden Funktion werden standardmäßig die 20 besten Übereinstimmungen zurückgegeben, dies kann aber über den Parameter
ngesteuert werden.
Die Funktion find_most_similar_transcript_segment gibt die besten Übereinstimmungen zurück, indem sie die Kosinus-Ähnlichkeit der gespeicherten Embeddings mit dem Abfrage-Embedding vergleicht.
def find_most_similar_transcript_segment(query, n=20):
query_embedding = embedding_client.embed(texts=[query])[0]["embedding"] # Nimmt an, dass die Abfrage kurz genug ist und kein Chunking benötigt
query_embedding = np.ascontiguousarray(np.array(query_embedding, dtype="float32").reshape(1, -1))
faiss.normalize_L2(query_embedding)
D, I = index_with_ids.search(query_embedding, n) # Die besten n Übereinstimmungen erhalten
results = []
for i in range(n):
distance = D[0][i]
index_id = I[0][i]
transcript_segment, doc_idx = doc_ref[index_id]
results.append((transcript_segment, doc_idx, distance))
# Ergebnisse nach Distanz sortieren
results.sort(key=lambda x: x[2])
return [(tu_delft_dataframe.iloc[r[1]]["Title"].strip(), r[0]) for r in results]
Wir definieren auch eine Funktion, die auf den Reranker-Endpunkt reranker_client zugreift, ihm die Ergebnisse von find_most_similar_transcript_segment übergibt und nur die drei relevantesten Ergebnisse zurückgibt. Sie ruft den Reranker-Endpunkt mit der Methode reranker_client.rerank() auf.
def rerank_results(query_found, query, n=3):
ret = reranker_client.rerank(
documents=[f[1] for f in query_found],
query=query,
top_n=n,
)
return [query_found[r['index']] for r in ret[0]['results']]
tagMistral-Instruct mit JumpStart laden
Für dieses Tutorial verwenden wir das mistral-7b-instruct Modell, das über Amazon SageMaker JumpStart verfügbar ist, als LLM-Teil des RAG-Systems.

Führen Sie den folgenden Code aus, um Mistral-Instruct zu laden und zu deployen:
from sagemaker.jumpstart.model import JumpStartModel
jumpstart_model = JumpStartModel(model_id="huggingface-llm-mistral-7b-instruct", role=role)
model_predictor = jumpstart_model.deploy()
Der Endpunkt für den Zugriff auf dieses LLM wird in der Variable model_predictor gespeichert.
tagMistral-Instruct mit JumpStart
Nachfolgend der Code zur Erstellung einer Prompt-Vorlage für Mistral-Instruct für diese Anwendung unter Verwendung der eingebauten Template-String-Klasse von Python. Es wird davon ausgegangen, dass für jede Abfrage drei passende Transkript-Chunks dem Modell präsentiert werden.
Sie können mit dieser Vorlage experimentieren, um die Anwendung zu modifizieren oder zu sehen, ob Sie bessere Ergebnisse erzielen können.
from string import Template
prompt_template = Template("""
<s>[INST] Beantworte die untenstehende Frage nur anhand des gegebenen Kontexts.
Die Frage des Benutzers basiert auf Transkripten von Videos eines YouTube-Kanals.
Der Kontext wird als gerankte Liste von Informationen in der Form
(Video-Titel, Transkript-Segment) präsentiert, die für die Beantwortung
der Benutzerfrage relevant sind.
Die Antwort sollte nur den präsentierten Kontext verwenden. Wenn die Frage
anhand des Kontexts nicht beantwortet werden kann, sage dies.
Kontext:
1. Video-Titel: $title_1, Transkript-Segment: $segment_1
2. Video-Titel: $title_2, Transkript-Segment: $segment_2
3. Video-Titel: $title_3, Transkript-Segment: $segment_3
Frage: $question
Antwort: [/INST]
""")
Mit dieser Komponente haben wir nun alle Teile einer vollständigen RAG-Anwendung.
tagAbfragen des Modells
Das Abfragen des Modells ist ein dreistufiger Prozess.
- Suche nach relevanten Chunks für eine Abfrage.
- Zusammenstellung des Prompts.
- Senden des Prompts an das Mistral-Instruct-Modell und Rückgabe seiner Antwort.
Um nach relevanten Chunks zu suchen, verwenden wir die oben definierte Funktion find_most_similar_transcript_segment.
question = "Wann wurde der erste Offshore-Windpark in Betrieb genommen?"
search_results = find_most_similar_transcript_segment(question)
reranked_results = rerank_results(search_results, question)
Sie können die Suchergebnisse in neu sortierter Reihenfolge inspizieren:
for title, text, _ in reranked_results:
print(title + "\n" + text + "\n")
Ergebnis:
Offshore Wind Farm Technology - Course Introduction
Since the first offshore wind farm commissioned in 1991 in Denmark, scientists and engineers have adapted and improved the technology of wind energy to offshore conditions. This is a rapidly evolving field with installation of increasingly larger wind turbines in deeper waters. At sea, the challenges are indeed numerous, with combined wind and wave loads, reduced accessibility and uncertain-solid conditions. My name is Axel Vire, I'm an assistant professor in Wind Energy at U-Delf and specializing in offshore wind energy. This course will touch upon the critical aspect of wind energy, how to integrate the various engineering disciplines involved in offshore wind energy. Each week we will focus on a particular discipline and use it to design and operate a wind farm.
Offshore Wind Farm Technology - Course Introduction
I'm a researcher and lecturer at the Wind Energy and Economics Department and I will be your moderator throughout this course. That means I will answer any questions you may have. I'll strengthen the interactions between the participants and also I'll get you in touch with the lecturers when needed. The course is mainly developed for professionals in the field of offshore wind energy. We want to broaden their knowledge of the relevant technical disciplines and their integration. Professionals with a scientific background who are new to the field of offshore wind energy will benefit from a high-level insight into the engineering aspects of wind energy. Overall, the course will help you make the right choices during the development and operation of offshore wind farms.
Offshore Wind Farm Technology - Course Introduction
Designed wind turbines that better withstand wind, wave and current loads Identify great integration strategies for offshore wind turbines and gain understanding of the operational and maintenance of offshore wind turbines and farms We also hope that you will benefit from the course and from interaction with other learners who share your interest in wind energy And therefore we look forward to meeting you online.
Wir können diese Informationen direkt in der Prompt-Vorlage verwenden:
prompt_for_llm = prompt_template.substitute(
question = question,
title_1 = search_results[0][0],
segment_1 = search_results[0][1],
title_2 = search_results[1][0],
segment_2 = search_results[1][1],
title_3 = search_results[2][0],
segment_3 = search_results[2][1],
)
Geben Sie die resultierende Zeichenkette aus, um zu sehen, welcher Prompt tatsächlich an das LLM gesendet wird:
print(prompt_for_llm)
<s>[INST] Answer the question below only using the given context.
The question from the user is based on transcripts of videos from a YouTube
channel.
The context is presented as a ranked list of information in the form of
(video-title, transcript-segment), that is relevant for answering the
user's question.
The answer should only use the presented context. If the question cannot be
answered based on the context, say so.
Context:
1. Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: Since the first offshore wind farm commissioned in 1991 in Denmark, scientists and engineers have adapted and improved the technology of wind energy to offshore conditions. This is a rapidly evolving field with installation of increasingly larger wind turbines in deeper waters. At sea, the challenges are indeed numerous, with combined wind and wave loads, reduced accessibility and uncertain-solid conditions. My name is Axel Vire, I'm an assistant professor in Wind Energy at U-Delf and specializing in offshore wind energy. This course will touch upon the critical aspect of wind energy, how to integrate the various engineering disciplines involved in offshore wind energy. Each week we will focus on a particular discipline and use it to design and operate a wind farm.
2. Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: For example, we look at how to characterize the wind and wave conditions at a given location. How to best place the wind turbines in a farm and also how to retrieve the electricity back to shore. We look at the main design drivers for offshore wind turbines and their components. We'll see how these aspects influence one another and the best choices to reduce the cost of energy. This course is organized by the two-delfd wind energy institute, an interfaculty research organization focusing specifically on wind energy. You will therefore benefit from the expertise of the lecturers in three different faculties of the university. Aerospace engineering, civil engineering and electrical engineering. Hi, my name is Ricardo Pareda.
3. Video-title: Systems Analysis for Problem Structuring part 1B the mono actor perspective example, transcript-segment: So let's assume the demarcation of the problem and the analysis of objectives has led to the identification of three criteria. The security of supply, the percentage of offshore power generation and the costs of energy provision. We now reason backwards to explore what factors have an influence on these system outcomes. Really, the offshore percentage is positively influenced by the installed Wind Power capacity at sea, a key system factor. Capacity at sea in turn is determined by both the size and the number of wind farms at sea. The Ministry of Economic Affairs cannot itself invest in new wind farms but hopes to simulate investors and energy companies by providing subsidies and by expediting the granting process of licenses as needed.
Question: When was the first offshore wind farm commissioned?
Answer: [/INST]
Übergeben Sie diesen Prompt an den LLM-Endpunkt — model_predictor — über die Methode model_predictor.predict():
answer = model_predictor.predict({"inputs": prompt_for_llm})
Dies gibt eine Liste zurück, aber da wir nur einen Prompt übergeben haben, wird es eine Liste mit einem Eintrag sein. Jeder Eintrag ist ein dict mit dem Antworttext unter dem Schlüssel generated_text:
answer = answer[0]['generated_text']
print(answer)
Ergebnis:
The first offshore wind farm was commissioned in 1991. (Context: Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: Since the first offshore wind farm commissioned in 1991 in Denmark, ...)
Vereinfachen wir die Abfrage, indem wir eine Funktion schreiben, die alle Schritte ausführt: Sie nimmt die String-Frage als Parameter und gibt die Antwort als String zurück:
def ask_rag(question):
search_results = find_most_similar_transcript_segment(question)
reranked_results = rerank_results(search_results, question)
prompt_for_llm = prompt_template.substitute(
question = question,
title_1 = search_results[0][0],
segment_1 = search_results[0][1],
title_2 = search_results[1][0],
segment_2 = search_results[1][1],
title_3 = search_results[2][0],
segment_3 = search_results[2][1],
)
answer = model_predictor.predict({"inputs": prompt_for_llm})
return answer[0]["generated_text"]
Jetzt können wir einige weitere Fragen stellen. Die Antworten hängen vom Inhalt der Videotranskripte ab. Zum Beispiel können wir detaillierte Fragen stellen, wenn die Antwort in den Daten vorhanden ist, und eine Antwort erhalten:
ask_rag("What is a Kaplan Meyer estimator?")
The Kaplan Meyer estimator is a non-parametric estimator for the survival
function, defined for both censored and not censored data. It is represented
as a series of declining horizontal steps that approaches the truths of the
survival function if the sample size is sufficiently large enough. The value
of the empirical survival function obtained is assumed to be constant between
two successive distinct observations.
ask_rag("Who is Reneville Solingen?")
Reneville Solingen is a professor at Delft University of Technology in Global
Software Engineering. She is also a co-author of the book "The Power of Scrum."
answer = ask_rag("What is the European Green Deal?")
print(answer)
The European Green Deal is a policy initiative by the European Union to combat
climate change and decarbonize the economy, with a goal to make Europe carbon
neutral by 2050. It involves the use of green procurement strategies in various
sectors, including healthcare, to reduce carbon emissions and promote corporate
social responsibility.
Wir können auch Fragen stellen, die außerhalb des Umfangs der verfügbaren Informationen liegen:
ask_rag("What countries export the most coffee?")
Based on the context provided, there is no clear answer to the user's
question about which countries export the most coffee as the context
only discusses the Delft University's cafeteria discounts and sustainable
coffee options, as well as lithium production and alternatives for use in
electric car batteries.
ask_rag("How much wood could a woodchuck chuck if a woodchuck could chuck wood?")
The context does not provide sufficient information to answer the question.
The context is about thermit welding of rails, stress concentration factors,
and a lyrics video. There is no mention of woodchucks or the ability of
woodchuck to chuck wood in the context.
Probieren Sie Ihre eigenen Abfragen aus. Sie können auch die Art und Weise ändern, wie das LLM aufgefordert wird, um zu sehen, ob das Ihre Ergebnisse verbessert.
tagHerunterfahren
Da Sie stundenweise für die verwendeten Modelle und die AWS-Infrastruktur bezahlen, ist es sehr wichtig, alle drei AI-Modelle zu stoppen, wenn Sie dieses Tutorial beenden:
- Den Embedding-Modell-Endpunkt
embedding_client - Den Reranker-Modell-Endpunkt
reranker_client - Den Large Language Model-Endpunkt
model_predictor
Um alle drei Modell-Endpunkte herunterzufahren, führen Sie den folgenden Code aus:
# shut down the embedding endpoint
embedding_client.delete_endpoint()
embedding_client.close()
# shut down the reranker endpoint
reranker_client.delete_endpoint()
reranker_client.close()
# shut down the LLM endpoint
model_predictor.delete_model()
model_predictor.delete_endpoint()
tagStarten Sie jetzt mit Jina AI Modellen auf dem AWS Marketplace
Mit unseren Embedding- und Reranking-Modellen auf SageMaker haben Enterprise-AI-Nutzer auf AWS jetzt sofortigen Zugriff auf Jina AIs herausragendes Wertversprechen, ohne die Vorteile ihrer bestehenden Cloud-Operationen zu gefährden. Die gesamte Sicherheit, Zuverlässigkeit, Konsistenz und vorhersehbare Preisgestaltung von AWS ist integriert.
Bei Jina AI arbeiten wir hart daran, den neuesten Stand der Technik zu Unternehmen zu bringen, die von der Integration von KI in ihre bestehenden Prozesse profitieren können. Wir streben danach, solide, zuverlässige und leistungsstarke Modelle zu zugänglichen Preisen über bequeme und praktische Schnittstellen anzubieten und dabei Ihre Investitionen in KI zu minimieren und Ihre Rendite zu maximieren.
Besuchen Sie Jina AIs AWS Marketplace-Seite für eine Liste aller Embedding- und Reranker-Modelle, die wir anbieten, und um unsere Modelle sieben Tage kostenlos zu testen.
