




Im April 2024 haben wir Jina Reader veröffentlicht, eine einfache API, die jede URL mit einem simplen Präfix r.jina.ai in LLM-freundliches Markdown umwandelt. Trotz der ausgefeilten Netzwerkprogrammierung im Hintergrund ist der eigentliche "Lese"-Teil recht unkompliziert. Zunächst verwenden wir einen Headless Chrome Browser, um die Quelle der Webseite abzurufen. Dann nutzen wir Mozillas Readability Paket, um den Hauptinhalt zu extrahieren und Elemente wie Header, Footer, Navigationsleisten und Seitenleisten zu entfernen. Schließlich konvertieren wir das bereinigte HTML in Markdown unter Verwendung von Regex und der Turndown Library. Das Ergebnis ist eine gut strukturierte Markdown-Datei, die von LLMs für Grounding, Zusammenfassungen und Reasoning genutzt werden kann.
In den ersten Wochen nach der Veröffentlichung von Jina Reader erhielten wir viel Feedback, besonders zur Qualität des Inhalts. Einige Nutzer fanden es zu detailliert, während andere es nicht detailliert genug empfanden. Es gab auch Berichte, dass der Readability-Filter falsche Inhalte entfernte oder Turndown Probleme hatte, bestimmte HTML-Teile in Markdown umzuwandeln. Glücklicherweise konnten viele dieser Probleme durch das Patchen der bestehenden Pipeline mit neuen Regex-Mustern oder Heuristiken gelöst werden.
Seitdem beschäftigt uns eine Frage: Können wir dieses Problem statt mit weiteren Heuristiken und Regex (die zunehmend schwerer zu warten und nicht mehrsprachig freundlich sind) _end-to-end_ mit einem Sprachmodell lösen?
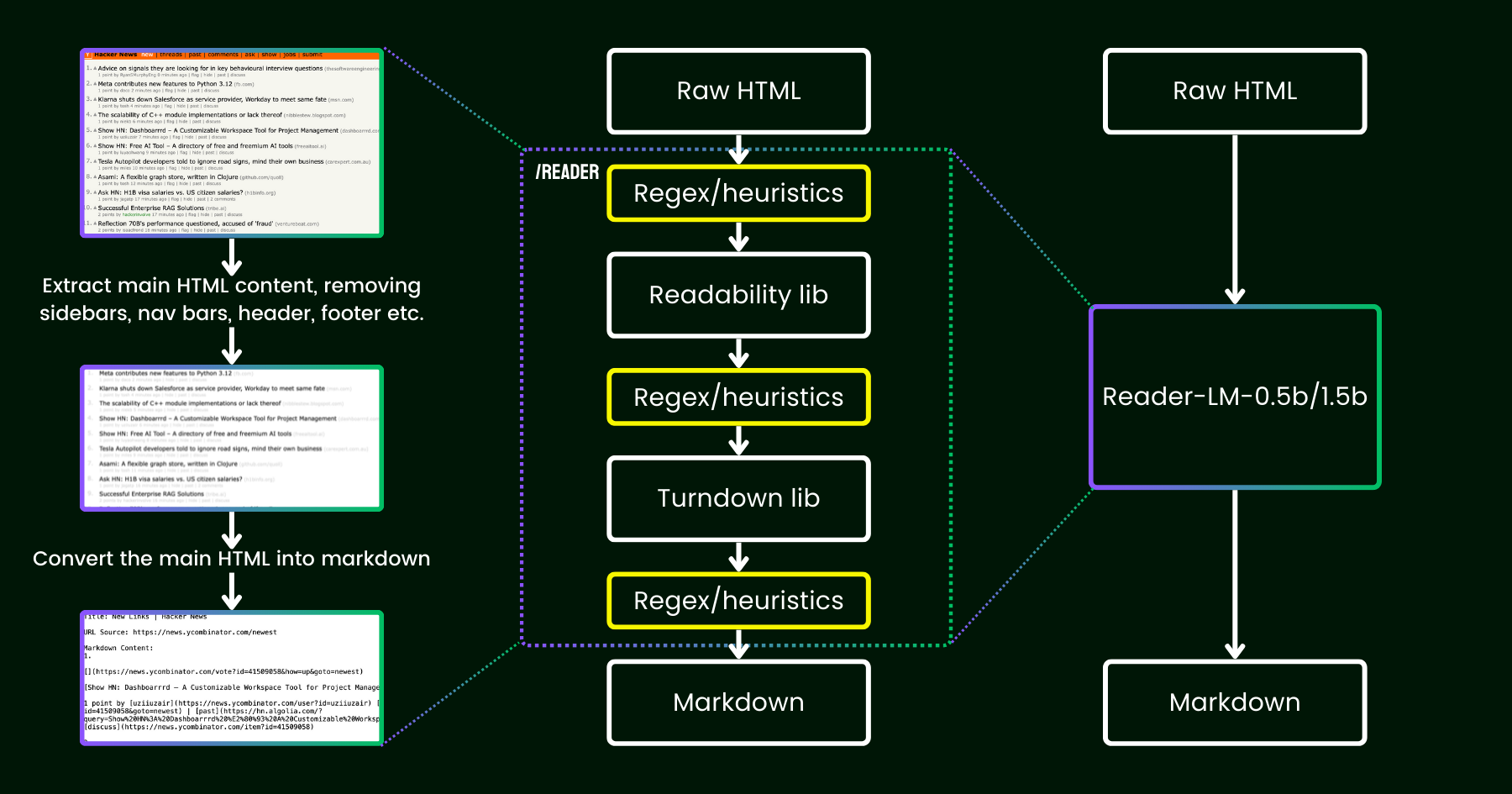
reader-lm, das die Pipeline aus Readability+Turndown+Regex-Heuristiken durch ein kleines Sprachmodell ersetzt.Auf den ersten Blick mag die Verwendung von LLMs für Datenbereinigung aufgrund ihrer geringen Kosteneffizienz und langsameren Geschwindigkeit übertrieben erscheinen. Aber was, wenn wir ein kleines Sprachmodell (SLM) in Betracht ziehen – eines mit weniger als 1 Milliarde Parametern, das effizient am Edge laufen kann? Das klingt schon attraktiver, oder? Aber ist das wirklich machbar oder nur Wunschdenken? Nach dem Skalierungsgesetz führen weniger Parameter generell zu reduzierten Reasoning- und Zusammenfassungsfähigkeiten. Ein SLM könnte also sogar Schwierigkeiten haben, überhaupt bedeutungsvolle Inhalte zu generieren, wenn seine Parametergröße zu klein ist. Schauen wir uns die HTML-zu-Markdown-Aufgabe genauer an:
- Erstens ist die Aufgabe, die wir betrachten, nicht so kreativ oder komplex wie typische LLM-Aufgaben. Bei der Konvertierung von HTML zu Markdown muss das Modell hauptsächlich selektiv kopieren vom Input zum Output (d.h. HTML-Markup, Seitenleisten, Header, Footer überspringen), mit minimalem Aufwand für die Generierung neuer Inhalte (hauptsächlich Einfügen von Markdown-Syntax). Dies unterscheidet sich stark von den breiteren Aufgaben, die LLMs bewältigen, wie das Generieren von Gedichten oder das Schreiben von Code, bei denen der Output viel mehr Kreativität erfordert und nicht direkt aus dem Input kopiert wird. Diese Beobachtung deutet darauf hin, dass ein SLM funktionieren könnte, da die Aufgabe _einfacher_ erscheint als allgemeinere Textgenerierung.
- Zweitens müssen wir die Unterstützung für lange Kontexte priorisieren. Modernes HTML enthält oft viel mehr Rauschen als einfaches
<div>Markup. Inline CSS und Scripts können den Code leicht auf hunderttausende von Tokens aufblähen. Damit ein SLM in diesem Szenario praktikabel ist, muss die Kontextlänge ausreichend groß sein. Token-Längen wie 8K oder 16K sind _überhaupt nicht_ nützlich.
Es scheint, dass wir ein flaches-aber-breites SLM benötigen. "Flach" in dem Sinne, dass die Aufgabe hauptsächlich einfaches "Kopieren-Einfügen" ist, daher werden weniger Transformer-Blöcke benötigt; und "breit" in dem Sinne, dass es Unterstützung für lange Kontexte erfordert, um praktikabel zu sein, sodass der Aufmerksamkeitsmechanismus sorgfältig gestaltet werden muss. Frühere Forschungen haben gezeigt, dass Kontextlänge und Reasoning-Fähigkeit eng miteinander verwoben sind. Für ein SLM ist es äußerst herausfordernd, beide Dimensionen zu optimieren und dabei die Parametergröße klein zu halten.
Heute freuen wir uns, die erste Version dieser Lösung mit der Veröffentlichung von reader-lm-0.5b und reader-lm-1.5b anzukündigen, zwei SLMs, die speziell darauf trainiert wurden, sauberes Markdown direkt aus verrauschtem rohem HTML zu generieren. Beide Modelle sind mehrsprachig und unterstützen eine Kontextlänge von bis zu 256K Tokens. Trotz ihrer kompakten Größe erreichen diese Modelle State-of-the-Art-Leistung bei dieser Aufgabe und übertreffen größere LLM-Gegenstücke, während sie nur 1/50 ihrer Größe haben.

Hier sind die Spezifikationen der beiden Modelle:
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| # Parameter | 494M | 1.54B |
| Kontextlänge | 256K | 256K |
| Hidden Size | 896 | 1536 |
| # Layers | 24 | 28 |
| # Query Heads | 14 | 12 |
| # KV Heads | 2 | 2 |
| Head Size | 64 | 128 |
| Intermediate Size | 4864 | 8960 |
| Mehrsprachig | Ja | Ja |
| HuggingFace Repo | Link | Link |
tagErste Schritte mit Reader-LM
tagAuf Google Colab
Der einfachste Weg, reader-lm auszuprobieren, ist über unser Colab Notebook, in dem wir demonstrieren, wie man reader-lm-1.5b verwendet, um die Hacker News Website in Markdown zu konvertieren. Das Notebook ist optimiert, um reibungslos auf Google Colabs kostenloser T4 GPU-Tier zu laufen. Sie können auch reader-lm-0.5b laden oder die URL zu einer beliebigen Website ändern und die Ausgabe erkunden. Beachten Sie, dass der Input (d.h. der Prompt) für das Modell das rohe HTML ist – keine Präfix-Anweisung ist erforderlich.

Bitte beachten Sie, dass die kostenlose T4 GPU Einschränkungen hat, die die Verwendung fortgeschrittener Optimierungen während der Modellausführung verhindern könnten. Features wie bfloat16 und Flash Attention sind auf der T4 nicht verfügbar, was zu höherem VRAM-Verbrauch und langsamerer Leistung bei längeren Eingaben führen kann. Für Produktionsumgebungen empfehlen wir die Verwendung einer High-End-GPU wie der RTX 3090/4090 für deutlich bessere Leistung.
tagIn Produktion: Bald verfügbar auf Azure & AWS
Reader-LM ist im Azure Marketplace und AWS SageMaker verfügbar. Wenn Sie diese Modelle über diese Plattformen hinaus oder On-Premises in Ihrem Unternehmen nutzen möchten, beachten Sie, dass beide Modelle unter CC BY-NC 4.0 lizenziert sind. Für kommerzielle Nutzungsanfragen kontaktieren Sie uns gerne.


tagBenchmark
Zur quantitativen Bewertung der Leistung von Reader-LM haben wir es mit mehreren großen Sprachmodellen verglichen, darunter: GPT-4o, Gemini-1.5-Flash, Gemini-1.5-Pro, LLaMA-3.1-70B, Qwen2-7B-Instruct.
Die Modelle wurden anhand folgender Metriken bewertet:
- ROUGE-L (höher ist besser): Diese Metrik, die häufig für Zusammenfassungs- und Frage-Antwort-Aufgaben verwendet wird, misst die Überlappung zwischen der vorhergesagten Ausgabe und der Referenz auf N-Gram-Ebene.
- Token Error Rate (TER, niedriger ist besser): Diese Metrik berechnet die Rate, mit der die generierten Markdown-Token nicht im ursprünglichen HTML-Inhalt erscheinen. Wir haben diese Metrik entwickelt, um die Halluzinationsrate des Modells zu bewerten und Fälle zu identifizieren, in denen das Modell Inhalte produziert, die nicht im HTML begründet sind. Weitere Verbesserungen werden basierend auf Fallstudien vorgenommen.
- Word Error Rate (WER, niedriger ist besser): WER wird häufig bei OCR- und ASR-Aufgaben verwendet und berücksichtigt die Wortsequenz und berechnet Fehler wie Einfügungen (ADD), Ersetzungen (SUB) und Löschungen (DEL). Diese Metrik bietet eine detaillierte Bewertung der Unterschiede zwischen dem generierten Markdown und der erwarteten Ausgabe.
Um LLMs für diese Aufgabe zu nutzen, verwendeten wir die folgende einheitliche Anweisung als Prefix-Prompt:
Your task is to convert the content of the provided HTML file into the corresponding markdown file. You need to convert the structure, elements, and attributes of the HTML into equivalent representations in markdown format, ensuring that no important information is lost. The output should strictly be in markdown format, without any additional explanations.Die Ergebnisse finden Sie in der folgenden Tabelle.
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
tagQualitative Studie
Wir führten eine qualitative Studie durch, indem wir die Markdown-Ausgabe visuell inspizierten. Wir wählten 22 HTML-Quellen aus, darunter Nachrichtenartikel, Blogbeiträge, Landing Pages, E-Commerce-Seiten und Forenbeiträge in mehreren Sprachen: Englisch, Deutsch, Japanisch und Chinesisch. Wir haben auch die Jina Reader API als Baseline einbezogen, die auf Regex, Heuristiken und vordefinierten Regeln basiert.
Die Bewertung konzentrierte sich auf vier Schlüsseldimensionen der Ausgabe, wobei jedes Modell auf einer Skala von 1 (niedrigste) bis 5 (höchste) bewertet wurde:
- Header-Extraktion: Bewertete, wie gut jedes Modell die h1,h2,..., h6 Header des Dokuments identifizierte und mit korrekter Markdown-Syntax formatierte.
- Hauptinhalt-Extraktion: Bewertete die Fähigkeit der Modelle, Fließtext genau zu konvertieren, Absätze zu erhalten, Listen zu formatieren und die Konsistenz in der Darstellung zu bewahren.
- Erhaltung der reichen Struktur: Analysierte, wie effektiv jedes Modell die Gesamtstruktur des Dokuments beibehielt, einschließlich Überschriften, Unterüberschriften, Aufzählungszeichen und geordnete Listen.
- Markdown-Syntax-Nutzung: Bewertete die Fähigkeit jedes Modells, HTML-Elemente wie
<a>(Links),<strong>(fetter Text) und<em>(kursiver Text) korrekt in ihre entsprechenden Markdown-Äquivalente zu konvertieren.
Die Ergebnisse finden Sie unten.

Reader-LM-1.5B zeigt durchgängig gute Leistungen in allen Dimensionen und überzeugt besonders bei der Strukturerhaltung und Markdown-Syntax-Nutzung. Auch wenn es nicht immer die Jina Reader API übertrifft, ist seine Leistung vergleichbar mit größeren Modellen wie Gemini 1.5 Pro, was es zu einer hocheffizienten Alternative zu größeren LLMs macht. Reader-LM-0.5B bietet, obwohl kleiner, immer noch solide Leistung, besonders bei der Strukturerhaltung.
tagWie wir Reader-LM trainiert haben
tagDatenvorbereitung
Wir nutzten die Jina Reader API, um Trainingspaare aus rohem HTML und entsprechendem Markdown zu generieren. Während des Experiments stellten wir fest, dass SLMs besonders empfindlich auf die Qualität der Trainingsdaten reagieren. Daher haben wir eine Datenpipeline entwickelt, die sicherstellt, dass nur hochwertige Markdown-Einträge in den Trainingsdatensatz aufgenommen werden.
Zusätzlich fügten wir einige synthetische HTML-Dateien und ihre Markdown-Entsprechungen hinzu, die von GPT-4o generiert wurden. Im Vergleich zu realen HTML-Daten sind synthetische Daten meist viel kürzer, mit einfacheren und vorhersehbareren Strukturen und einem deutlich niedrigeren Rauschpegel.
Schließlich verknüpften wir das HTML und Markdown mit einer Chat-Vorlage. Die endgültigen Trainingsdaten sind wie folgt formatiert:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{{RAW_HTML}}<|im_end|>
<|im_start|>assistant
{{MARKDOWN}}<|im_end|>
Die gesamten Trainingsdaten umfassen 2,5 Milliarden Token.
tagZweistufiges Training
Wir führten Experimente mit verschiedenen Modellgrößen durch, von 65M und 135M bis hin zu 3B Parametern. Die Spezifikationen für jedes Modell sind in der nachfolgenden Tabelle aufgeführt.
| reader-lm-65m | reader-lm-135m | reader-lm-360m | reader-lm-0.5b | reader-lm-1.5b | reader-lm-1.7b | reader-lm-3b | |
|---|---|---|---|---|---|---|---|
| Hidden Size | 512 | 576 | 960 | 896 | 1536 | 2048 | 3072 |
| # Layers | 8 | 30 | 32 | 24 | 28 | 24 | 32 |
| # Query Heads | 16 | 9 | 15 | 14 | 12 | 32 | 32 |
| # KV Heads | 8 | 3 | 5 | 2 | 2 | 32 | 32 |
| Head Size | 32 | 64 | 64 | 64 | 128 | 64 | 96 |
| Intermediate Size | 2048 | 1536 | 2560 | 4864 | 8960 | 8192 | 8192 |
| Attention Bias | False | False | False | True | True | False | False |
| Embedding Tying | False | True | True | True | True | True | False |
| Vocabulary Size | 32768 | 49152 | 49152 | 151646 | 151646 | 49152 | 32064 |
| Base Model | Lite-Oute-1-65M-Instruct | SmolLM-135M | SmolLM-360M-Instruct | Qwen2-0.5B-Instruct | Qwen2-1.5B-Instruct | SmolLM-1.7B | Phi-3-mini-128k-instruct |
Das Modelltraining wurde in zwei Phasen durchgeführt:
- Kurzer und einfacher HTML: In dieser Phase wurde die maximale Sequenzlänge (HTML + Markdown) auf 32K Token festgelegt, mit insgesamt 1,5 Milliarden Trainings-Token.
- Langer und komplexer HTML: Die Sequenzlänge wurde auf 128K Token erweitert, mit 1,2 Milliarden Trainings-Token. Wir implementierten den Zigzag-Ring-Attention-Mechanismus aus Zilin Zhus „Ring Flash Attention" (2024) für diese Phase.
Da die Trainingsdaten Sequenzen von bis zu 128K Token enthielten, gehen wir davon aus, dass das Modell bis zu 256K Token ohne Probleme verarbeiten kann. Die Verarbeitung von 512K Token könnte jedoch schwierig sein, da die Erweiterung von RoPE-Positionseinbettungen auf das Vierfache der Trainingssequenzlänge zu Leistungseinbußen führen könnte.
Bei den Modellen mit 65M und 135M Parametern haben wir beobachtet, dass sie ein angemessenes „Kopierverhalten" erreichen konnten, allerdings nur bei kurzen Sequenzen (weniger als 1K Token). Mit zunehmender Eingabelänge hatten diese Modelle Schwierigkeiten, vernünftige Ausgaben zu produzieren. Da moderner HTML-Quellcode leicht 100K Token überschreiten kann, ist eine Beschränkung auf 1K Token bei weitem nicht ausreichend.
tagDegeneration und monotone Schleifen
Eine der größten Herausforderungen war die Degeneration, insbesondere in Form von Wiederholungen und Schleifen. Nach der Generierung einiger Token begann das Modell, dasselbe Token wiederholt zu generieren oder blieb in einer Schleife stecken, wobei es kontinuierlich eine kurze Sequenz von Token wiederholte, bis die maximal erlaubte Ausgabelänge erreicht war.

Um dieses Problem zu lösen:
- Wir verwendeten Contrastive Search als Decodierungsmethode und integrierten kontrastive Verluste während des Trainings. Unseren Experimenten zufolge reduzierte diese Methode repetitive Generierung in der Praxis effektiv.
- Wir implementierten ein einfaches Wiederholungs-Stopp-Kriterium innerhalb der Transformer-Pipeline. Dieses Kriterium erkennt automatisch, wenn das Modell beginnt, Token zu wiederholen, und stoppt die Decodierung frühzeitig, um monotone Schleifen zu vermeiden. Diese Idee wurde von dieser Diskussion inspiriert.
tagTrainingseffizienz bei langen Eingaben
Um das Risiko von Out-of-Memory (OOM)-Fehlern bei der Verarbeitung langer Eingaben zu minimieren, implementierten wir eine chunk-weise Modellweiterleitung. Dieser Ansatz kodiert die lange Eingabe mit kleineren Chunks und reduziert so den VRAM-Verbrauch.
Wir verbesserten die Datenpackungs-Implementierung in unserem Trainingsframework, das auf dem Transformers Trainer basiert. Zur Optimierung der Trainingseffizienz werden mehrere kurze Texte (z.B. 2K Token) zu einer einzigen langen Sequenz (z.B. 30K Token) zusammengefügt, was ein padding-freies Training ermöglicht. In der ursprünglichen Implementierung wurden jedoch einige kurze Beispiele in zwei Subtexte aufgeteilt und in verschiedene lange Trainingssequenzen aufgenommen. In solchen Fällen würde der zweite Subtext seinen Kontext verlieren (z.B. den rohen HTML-Inhalt in unserem Fall), was zu korrupten Trainingsdaten führt. Dies zwingt das Modell, sich eher auf seine Parameter als auf den Eingabekontext zu verlassen, was unserer Meinung nach eine Hauptquelle für Halluzinationen ist.
Letztendlich wählten wir die 0,5B- und 1,5B-Modelle zur Veröffentlichung aus. Das 0,5B-Modell ist das kleinste Modell, das das gewünschte „selektive Kopierverhalten" bei Eingaben mit langem Kontext erreichen kann, während das 1,5B-Modell das kleinste größere Modell ist, das die Leistung deutlich verbessert, ohne in Bezug auf die Parametergröße abnehmende Erträge zu erzielen.
tagAlternative Architektur: Encoder-Only-Modell
In der Anfangsphase dieses Projekts erforschten wir auch die Verwendung einer Encoder-Only-Architektur für diese Aufgabe. Wie bereits erwähnt, scheint die HTML-zu-Markdown-Konvertierung hauptsächlich eine „selektive Kopieraufgabe" zu sein. Bei einem Trainingspaar (rohes HTML und Markdown) können wir Token, die sowohl in der Eingabe als auch in der Ausgabe existieren, als 1 markieren und den Rest als 0. Dies wandelt das Problem in eine Token-Klassifizierungsaufgabe um, ähnlich wie bei der Named Entity Recognition (NER).
Während dieser Ansatz logisch erschien, stellte er in der Praxis erhebliche Herausforderungen dar. Erstens ist rohes HTML aus realen Quellen extrem verrauscht und lang, was die 1-Labels extrem spärlich und damit schwer für das Modell erlernbar macht. Zweitens erwies sich die Kodierung spezieller Markdown-Syntax in einem 0-1-Schema als problematisch, da Symbole wie ## title, *bold* und | table | nicht im rohen HTML-Input existieren. Drittens folgen die Ausgabe-Token nicht immer strikt der Reihenfolge der Eingabe. Kleinere Umordnungen treten häufig auf, besonders bei Tabellen und Links, was es schwierig macht, solche Umordnungsverhalten in einem einfachen 0-1-Schema darzustellen. Kurzstrecken-Umordnungen könnten potenziell mit dynamischer Programmierung oder Alignment-Warping-Algorithmen behandelt werden, indem Labels wie -1, -2, +1, +2 eingeführt werden, um Distanz-Offsets darzustellen, wodurch das binäre Klassifizierungsproblem in eine Token-Klassifizierungsaufgabe mit mehreren Klassen umgewandelt wird.
Zusammenfassend lässt sich sagen, dass die Lösung des Problems mit einer Encoder-Only-Architektur und die Behandlung als Token-Klassifizierungsaufgabe ihren Reiz hat, besonders da die Trainingssequenzen im Vergleich zu einem Decoder-Only-Modell viel kürzer sind, was sie VRAM-freundlicher macht. Allerdings liegt die größte Herausforderung in der Vorbereitung guter Trainingsdaten. Als wir erkannten, dass der Zeit- und Arbeitsaufwand für die Vorverarbeitung der Daten – mit dynamischer Programmierung und Heuristiken zur Erstellung perfekter Token-Level-Markierungssequenzen – überwältigend war, beschlossen wir, diesen Ansatz einzustellen.
tagFazit
Reader-LM ist ein neuartiges kleines Sprachmodell (SLM), das für die Datenextraktion und -bereinigung im offenen Web entwickelt wurde. Inspiriert von Jina Reader war unser Ziel, eine End-to-End-Sprachmodelllösung zu schaffen, die rohes, verrauschtes HTML in sauberes Markdown umwandeln kann. Gleichzeitig haben wir uns auf Kosteneffizienz konzentriert und die Modellgröße klein gehalten, um sicherzustellen, dass Reader-LM praktisch und nutzbar bleibt. Es ist auch das erste Decoder-only Long-Context-Modell, das bei Jina AI trainiert wurde.
Obwohl die Aufgabe zunächst als einfaches "selektives Kopieren" erscheinen mag, ist die Umwandlung und Bereinigung von HTML zu Markdown alles andere als einfach. Konkret muss das Modell bei positions- und kontextbasiertem Reasoning hervorragend sein, was eine größere Parameteranzahl erfordert, insbesondere in den Hidden Layers. Im Vergleich dazu ist das Erlernen der Markdown-Syntax relativ unkompliziert.
Während unserer Experimente stellten wir auch fest, dass das Training eines SLM von Grund auf besonders herausfordernd ist. Der Start mit einem vortrainierten Modell und die Fortsetzung mit aufgabenspezifischem Training verbesserte die Trainingseffizienz erheblich. Es gibt noch viel Raum für Verbesserungen sowohl bei der Effizienz als auch bei der Qualität: Erweiterung der Kontextlänge, Beschleunigung der Dekodierung und Hinzufügen von Unterstützung für Anweisungen in der Eingabe, was es Reader-LM ermöglichen würde, bestimmte Teile einer Webseite in Markdown zu extrahieren.
