
Seit der Veröffentlichung des O1-Modells von OpenAI ist eines der meistdiskutierten Themen in der KI-Community das Skalieren der Test-Zeit-Berechnung. Dies bezieht sich auf die Zuweisung zusätzlicher Rechenressourcen während der Inferenz – der Phase, in der ein KI-Modell Ausgaben als Reaktion auf Eingaben generiert – anstatt während des Vortrainings. Ein bekanntes Beispiel ist das mehrstufige "Chain of Thought"-Reasoning, das es Modellen ermöglicht, umfangreichere interne Überlegungen anzustellen, wie etwa die Bewertung mehrerer potenzieller Antworten, tiefere Planung und Selbstreflexion, bevor eine endgültige Antwort gegeben wird. Diese Strategie verbessert die Antwortqualität, besonders bei komplexen Reasoning-Aufgaben. Alibabas kürzlich veröffentlichtes QwQ-32B-Preview Modell folgt diesem Trend der Verbesserung des KI-Reasonings durch erhöhte Test-Zeit-Berechnung.
Bei der Verwendung von OpenAIs O1-Modell können Benutzer deutlich erkennen, dass mehrstufige Inferenz zusätzliche Zeit benötigt, während das Modell Reasoning-Ketten zur Problemlösung aufbaut.
Bei Jina AI konzentrieren wir uns mehr auf Embeddings und Reranker als auf LLMs, daher ist es für uns naheliegend, die Skalierung der Test-Zeit-Berechnung in diesem Kontext zu betrachten: Wie kann der "Chain-of-Thought"-Ansatz auf Embedding-Modelle angewendet werden? Auch wenn es zunächst nicht intuitiv erscheinen mag, erkundet dieser Artikel eine neue Perspektive und zeigt, wie die Skalierung der Test-Zeit-Berechnung auf jina-clip angewendet werden kann, um Out-of-Distribution (OOD) Bilder zu klassifizieren – und damit Aufgaben zu lösen, die sonst unmöglich wären.

tagFallstudie

Unser Experiment konzentrierte sich auf Pokemon-Klassifizierung unter Verwendung des TheFusion21/PokemonCards Datensatzes, der Tausende von Pokemon-Sammelkartenbildern enthält. Die Aufgabe ist Bildklassifizierung, wobei der Input ein zugeschnittenes Pokemon-Karten-Artwork ist (ohne Text/Beschreibungen) und der Output der korrekte Pokemon-Name aus einer vordefinierten Namensliste ist. Diese Aufgabe stellt eine besonders interessante Herausforderung für CLIP Embedding-Modelle dar, weil:
- Pokemon-Namen und visuelle Darstellungen Nischenkonzepte für das Modell darstellen, was die direkte Klassifizierung erschwert
- Jedes Pokemon klare visuelle Merkmale hat, die in grundlegende Elemente zerlegt werden können (Formen, Farben, Posen), die CLIP möglicherweise besser versteht
- Die Kartenartworks ein konsistentes visuelles Format bieten, während sie durch verschiedene Hintergründe, Posen und künstlerische Stile Komplexität einbringen
- Die Aufgabe die Integration mehrerer visueller Merkmale gleichzeitig erfordert, ähnlich wie komplexe Reasoning-Ketten in Sprachmodellen

Absol G, Aerodactyl, Weedle, Caterpie, Azumarill, Bulbasaur, Venusaur, Absol, Aggron, Beedrill δ, Alakazam, Ampharos, Dratini, Ampharos, Ampharos, Arcanine, Blaine's Moltres, Aerodactyl, Celebi & Venusaur-GX, Caterpie]tagBaseline
Der Baseline-Ansatz verwendet einen einfachen direkten Vergleich zwischen Pokémon-Karten-Artwork und Namen. Zunächst beschneiden wir jedes Pokémon-Kartenbild, um alle Textinformationen (Kopfzeile, Fußzeile, Beschreibung) zu entfernen, damit das CLIP-Modell keine trivialen Vermutungen aufgrund von Pokémon-Namen in diesen Texten anstellen kann. Dann kodieren wir sowohl die beschnittenen Bilder als auch die Pokémon-Namen mit dem jina-clip-v1 und jina-clip-v2 Modell, um ihre jeweiligen Embeddings zu erhalten. Die Klassifizierung erfolgt durch Berechnung der Kosinus-Ähnlichkeit zwischen diesen Bild- und Text-Embeddings - jedes Bild wird dem Namen zugeordnet, der den höchsten Ähnlichkeitswert aufweist. Dies erzeugt eine einfache Eins-zu-eins-Zuordnung zwischen visuellem Karten-Artwork und Pokémon-Namen, ohne zusätzliche Kontext- oder Attributinformationen. Der folgende Pseudocode fasst die Baseline-Methode zusammen.
# Preprocessing
cropped_images = [crop_artwork(img) for img in pokemon_cards] # Remove text, keep only art
pokemon_names = ["Absol", "Aerodactyl", ...] # Raw Pokemon names
# Get embeddings using jina-clip-v1
image_embeddings = model.encode_image(cropped_images)
text_embeddings = model.encode_text(pokemon_names)
# Classification by cosine similarity
similarities = cosine_similarity(image_embeddings, text_embeddings)
predicted_names = [pokemon_names[argmax(sim)] for sim in similarities]
# Evaluate
accuracy = mean(predicted_names == ground_truth_names)tag"Chain of Thoughts" für die Klassifizierung
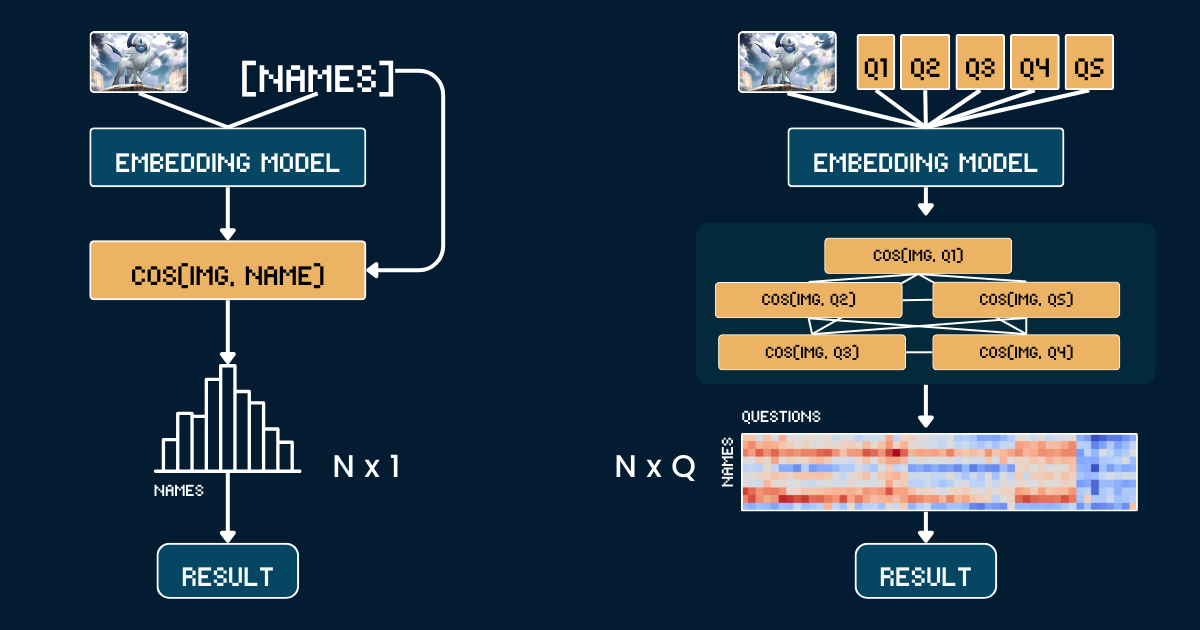
Anstatt Bilder direkt mit Namen abzugleichen, zerlegen wir die Pokémon-Erkennung in ein strukturiertes System von visuellen Attributen. Wir definieren fünf zentrale Attributgruppen: dominante Farbe (z.B. "weiß", "blau"), Grundform (z.B. "ein Wolf", "ein geflügeltes Reptil"), Hauptmerkmal (z.B. "ein einzelnes weißes Horn", "große Flügel"), Körperform (z.B. "wolfsartig auf vier Beinen", "geflügelt und schlank") und Hintergrundszene (z.B. "Weltraum", "grüner Wald").
Für jede Attributgruppe erstellen wir spezifische Text-Prompts (z.B. "Dieses Pokémon ist hauptsächlich {} in der Farbe") mit entsprechenden Optionen. Dann verwenden wir das Modell, um Ähnlichkeitswerte zwischen dem Bild und jeder Attributoption zu berechnen. Diese Werte werden mittels Softmax in Wahrscheinlichkeiten umgewandelt, um ein besser kalibriertes Maß für die Konfidenz zu erhalten.
Die vollständige Chain of Thought (CoT) Struktur besteht aus zwei Teilen: classification_groups, das Gruppen von Prompts beschreibt, und pokemon_rules, das definiert, welche Attributoptionen zu jedem Pokémon passen sollten. Zum Beispiel sollte Absol für Farbe "weiß" und für Form "wolfsartig" entsprechen. Die vollständige CoT wird unten gezeigt (wie diese erstellt wird, erklären wir später):
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
Die endgültige Klassifizierung kombiniert diese Attributwahrscheinlichkeiten - anstatt eines einzelnen Ähnlichkeitsvergleichs führen wir nun mehrere strukturierte Vergleiche durch und aggregieren deren Wahrscheinlichkeiten, um eine fundiertere Entscheidung zu treffen.
# Classification process
def classify_pokemon(image):
# Generate all text prompts
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# Get embeddings and similarities
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# Convert to probabilities per attribute group
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# Score each Pokemon based on matching attributes
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get)tagKomplexitätsanalyse
Nehmen wir an, wir möchten ein Bild in eine von N Pokémon-Namen klassifizieren. Der Baseline-Ansatz erfordert die Berechnung von N Text-Embeddings (eines für jeden Pokémon-Namen). Im Gegensatz dazu erfordert unser skalierter Test-Time-Compute-Ansatz die Berechnung von Q Text-Embeddings, wobei
Q ist die Gesamtzahl der Frage-Option-Kombinationen über alle Fragen hinweg. Beide Methoden erfordern die Berechnung eines Bild-Embeddings und einen abschließenden Klassifizierungsschritt, daher schließen wir diese gemeinsamen Operationen von unserem Vergleich aus. In dieser Fallstudie haben wir N=13 und Q=52.In einem Extremfall, wo Q = N, würde sich unser Ansatz im Wesentlichen auf die Baseline reduzieren. Der Schlüssel zur effektiven Skalierung der Test-Time-Berechnung ist jedoch:
- Sorgfältig gewählte Fragen konstruieren, die
Qerhöhen - Sicherstellen, dass jede Frage eindeutige, informative Hinweise auf die endgültige Antwort liefert
- Fragen so orthogonal wie möglich gestalten, um ihren gemeinsamen Informationsgewinn zu maximieren
Dieser Ansatz ist analog zum Spiel "Zwanzig Fragen", bei dem jede Frage strategisch gewählt wird, um die möglichen Antworten effektiv einzugrenzen.
tagEvaluation
Unsere Evaluation wurde mit 117 Testbildern aus 13 verschiedenen Pokémon-Klassen durchgeführt. Das Ergebnis ist wie folgt:
| Approach | jina-clip-v1 | jina-clip-v2 |
|---|---|---|
| Baseline | 31.36% | 16.10% |
| CoT | 46.61% | 38.14% |
| Improvement | +15.25% | +22.04% |
Man kann sehen, dass die gleiche CoT-Klassifikation für beide Modelle signifikante Verbesserungen (+15.25% bzw. +22.04%) bei dieser ungewöhnlichen oder OOD-Aufgabe bietet. Dies deutet auch darauf hin, dass sobald das pokemon_system konstruiert ist, dasselbe CoT-System effektiv zwischen verschiedenen Modellen übertragen werden kann; und kein Fine-Tuning oder Post-Training erforderlich ist.
Die relativ starke Baseline-Performance von v1 (31.36%) bei der Pokemon-Klassifikation ist bemerkenswert. Dieses Modell wurde auf LAION-400M trainiert, das Pokemon-bezogene Inhalte enthielt. Im Gegensatz dazu wurde v2 auf DFN-2B trainiert (Unterabtastung von 400M Instanzen), einem qualitativ hochwertigeren, aber stärker gefilterten Datensatz, der möglicherweise Pokemon-bezogene Inhalte ausgeschlossen hat, was die niedrigere Baseline-Performance von V2 (16.10%) bei dieser spezifischen Aufgabe erklärt.
tagEffektive Konstruktion des pokemon_system
Die Effektivität unseres skalierten Test-Time-Compute-Ansatzes hängt stark davon ab, wie gut wir das pokemon_system konstruieren. Es gibt verschiedene Ansätze zum Aufbau dieses Systems, von manuell bis vollautomatisch.
Manuelle Konstruktion
Der direkteste Ansatz ist die manuelle Analyse des Pokemon-Datensatzes und das Erstellen von Attributgruppen, Prompts und Regeln. Ein Domänenexperte müsste wichtige visuelle Attribute wie Farbe, Form und charakteristische Merkmale identifizieren. Anschließend würden sie natürlichsprachliche Prompts für jedes Attribut schreiben, mögliche Optionen für jede Attributgruppe aufzählen und jedes Pokemon seinen korrekten Attributoptionen zuordnen. Während dies qualitativ hochwertige Regeln liefert, ist es zeitaufwändig und skaliert nicht gut bei größerem N.
LLM-unterstützte Konstruktion
Wir können LLMs nutzen, um diesen Prozess zu beschleunigen, indem wir sie auffordern, das Klassifikationssystem zu generieren. Ein gut strukturierter Prompt würde Attributgruppen basierend auf visuellen Eigenschaften, natürlichsprachliche Prompt-Templates, umfassende und sich gegenseitig ausschließende Optionen sowie Zuordnungsregeln für jedes Pokemon anfordern. Das LLM kann schnell einen ersten Entwurf generieren, auch wenn seine Ausgabe möglicherweise überprüft werden muss.
I need help creating a structured system for Pokemon classification. For each Pokemon in this list: [Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...], create a classification system with:
1. Classification groups that cover these visual attributes:
- Dominant color of the Pokemon
- What type of creature it appears to be (primary form)
- Its most distinctive visual feature
- Overall body shape
- What kind of background/environment it's typically shown in
2. For each group:
- Create a natural language prompt template using "{}" for the option
- List all possible options that could apply to these Pokemon
- Make sure options are mutually exclusive and comprehensive
3. Create rules that map each Pokemon to exactly one option per attribute group, using indices to reference the options
Please output this as a Python dictionary with two main components:
- "classification_groups": containing prompts and options for each attribute
- "pokemon_rules": mapping each Pokemon to its correct attribute indices
Example format:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # index for "white"
...
},
...
}
}Ein robusterer Ansatz kombiniert LLM-Generierung mit menschlicher Validierung. Zuerst generiert das LLM ein initiales System. Dann überprüfen und korrigieren menschliche Experten die Attributgruppierungen, Vollständigkeit der Optionen und Regelgenauigkeit. Das LLM verfeinert das System basierend auf diesem Feedback, und der Prozess wird iteriert, bis eine zufriedenstellende Qualität erreicht ist. Dieser Ansatz balanciert Effizienz mit Genauigkeit.
Automatisierte Konstruktion mit DSPy
Für einen vollautomatischen Ansatz können wir DSPy verwenden, um das pokemon_system iterativ zu optimieren. Der Prozess beginnt mit einem einfachen pokemon_system, das entweder manuell oder von LLMs als initialer Prompt geschrieben wurde. Jede Version wird auf einem Hold-out-Set evaluiert, wobei die Genauigkeit als Feedback-Signal für DSPy dient. Basierend auf dieser Performance werden optimierte Prompts (d.h. neue Versionen des pokemon_system) generiert. Dieser Zyklus wiederholt sich bis zur Konvergenz, und während des gesamten Prozesses bleibt das Embedding-Modell vollständig fixiert.
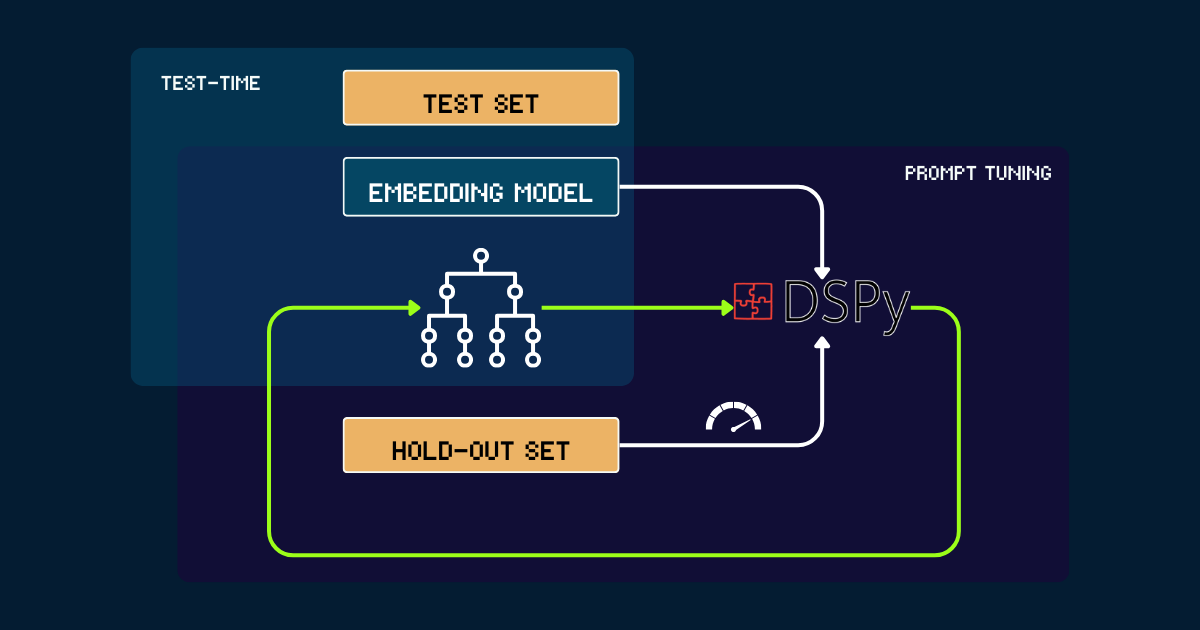
pokemon_system CoT-Designs; der Tuning-Prozess muss nur einmal für jede Aufgabe durchgeführt werden.tagWarum Test-Time-Compute für Embedding-Modelle skalieren?
Weil die Skalierung des Pretrainings letztendlich wirtschaftlich untragbar wird.
Seit der Veröffentlichung der Jina Embeddings Suite—einschließlich jina-embeddings-v1, v2, v3, jina-clip-v1, v2 und jina-ColBERT-v1, v2—ist jedes Modell-Upgrade durch skaliertes Pretraining mit höheren Kosten verbunden. Zum Beispiel hatte unser erstes Modell, jina-embeddings-v1, das im Juni 2023 veröffentlicht wurde, 110M Parameter. Das Training kostete damals je nach Messung zwischen 10.000. Mit jina-embeddings-v3 sind die Verbesserungen signifikant, aber sie stammen hauptsächlich aus den erhöhten investierten Ressourcen. Die Kostentrajektorie für Frontier-Modelle ist von Tausenden zu Zehntausenden Dollar und für größere KI-Unternehmen heute sogar zu Hunderten Millionen gestiegen. Während mehr Geld, Ressourcen und Daten ins Pretraining zu besseren Modellen führen, machen die abnehmenden Grenzerträge weitere Skalierung wirtschaftlich unhaltbar.

Andererseits werden moderne Embedding-Modelle immer leistungsfähiger: mehrsprachig, multitask, multimodal und fähig zu starker Zero-Shot- und Anweisungsbefolgungsleistung. Diese Vielseitigkeit lässt viel Raum für algorithmische Verbesserungen und die Skalierung von Test-Time-Compute.
Die Frage ist dann: Welche Kosten sind Benutzer bereit für eine Anfrage zu zahlen, die ihnen sehr wichtig ist? Wenn die Tolerierung längerer Inferenzzeiten bei fixen Pretraining-Modellen die Qualität der Ergebnisse signifikant verbessert, würden viele das für lohnenswert halten. Aus unserer Sicht gibt es erhebliches ungenutztes Potenzial in der Skalierung von Test-Time-Compute für Embedding-Modelle. Dies stellt eine Verschiebung dar von der bloßen Erhöhung der Modellgröße während des Trainings hin zur Verbesserung des Rechenaufwands während der Inferenzphase, um bessere Leistung zu erzielen.
tagFazit
Unsere Fallstudie zum Test-Time-Compute von jina-clip-v1/v2 zeigt mehrere wichtige Erkenntnisse:
- Wir erzielten bessere Leistung bei ungewöhnlichen oder Out-of-Distribution (OOD) Daten ohne jegliches Fine-Tuning oder Post-Training der Embeddings.
- Das System traf nuanciertere Unterscheidungen durch iterative Verfeinerung von Ähnlichkeitssuchen und Klassifikationskriterien.
- Durch die Einbeziehung dynamischer Prompt-Anpassungen und iterativen Schlussfolgerns verwandelten wir den Inferenzprozess des Embedding-Modells von einer einzelnen Abfrage in eine sophistiziertere Gedankenkette.
Diese Fallstudie kratzt nur an der Oberfläche dessen, was mit Test-Time-Compute möglich ist. Es bleibt erheblicher Raum für algorithmische Skalierung. Zum Beispiel könnten wir Methoden entwickeln, um iterativ Fragen auszuwählen, die den Antwortbereich am effizientesten eingrenzen, ähnlich der optimalen Strategie im Spiel "Zwanzig Fragen". Durch die Skalierung von Test-Time-Compute können wir Embedding-Modelle über ihre aktuellen Grenzen hinaus pushen und sie befähigen, komplexere, nuanciertere Aufgaben zu bewältigen, die einst außer Reichweite schienen.





