

Im Oktober 2023 stellten wir jina-embeddings-v2 vor, die erste Open-Source-Embedding-Modellfamilie, die Eingaben bis zu 8.192 Token verarbeiten kann. Darauf aufbauend haben wir dieses Jahr jina-embeddings-v3 eingeführt, das die gleiche umfangreiche Eingabeunterstützung mit weiteren Verbesserungen bietet.

In diesem Beitrag werden wir uns mit Long-Context-Embeddings befassen und einige Fragen beantworten: Wann ist es praktikabel, ein so großes Textvolumen in einen einzigen Vektor zu konsolidieren? Verbessert Segmentierung das Retrieval, und wenn ja, wie? Wie können wir den Kontext aus verschiedenen Teilen eines Dokuments beim Segmentieren des Textes bewahren?
Um diese Fragen zu beantworten, werden wir verschiedene Methoden zur Generierung von Embeddings vergleichen:
- Long-Context-Embedding (Kodierung von bis zu 8.192 Token in einem Dokument) vs. Short-Context (d.h. Abschneiden bei 192 Token).
- Kein Chunking vs. naives Chunking vs. Late Chunking.
- Verschiedene Chunk-Größen sowohl beim naiven als auch beim Late Chunking.
tagIst Long Context überhaupt nützlich?
Mit der Möglichkeit, bis zu zehn Seiten Text in einem einzigen Embedding zu kodieren, eröffnen Long-Context-Embedding-Modelle neue Möglichkeiten für die Darstellung großer Textmengen. Ist das aber überhaupt nützlich? Laut vielen Leuten... nein.




Quellen: Zitat von Nils Reimer im How AI Is Built Podcast, brainlag Tweet, egorfine Hacker News Kommentar, andy99 Hacker News Kommentar
Wir werden all diese Bedenken mit einer detaillierten Untersuchung der Long-Context-Fähigkeiten, wann Long Context hilfreich ist und wann man ihn (nicht) verwenden sollte, ansprechen. Aber zunächst wollen wir uns diese Skeptiker anhören und einige der Probleme betrachten, mit denen Long-Context-Embedding-Modelle konfrontiert sind.
tagProbleme mit Long-Context-Embeddings
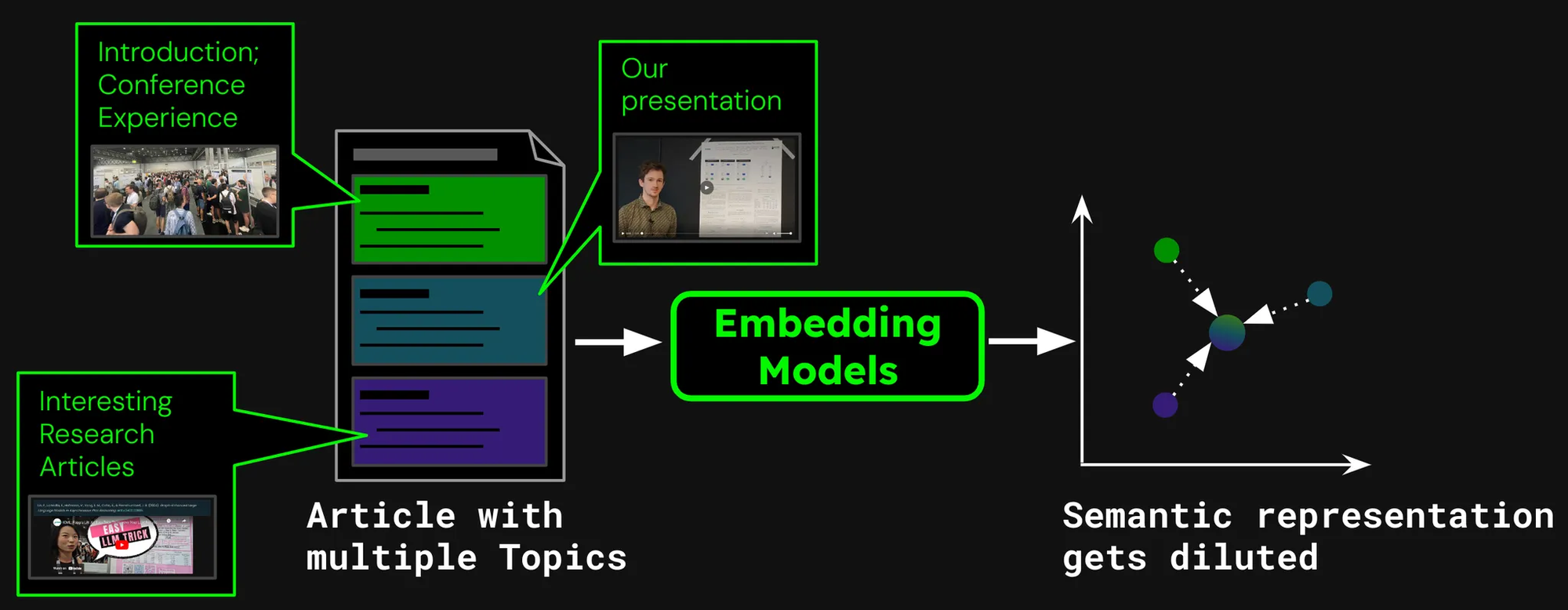
Stellen wir uns vor, wir bauen ein Dokumentensuchsystem für Artikel, wie die in unserem Jina AI Blog. Manchmal kann ein einzelner Artikel mehrere Themen abdecken, wie der Bericht über unseren Besuch der ICML 2024 Konferenz, der enthält:
- Eine Einführung mit allgemeinen Informationen über ICML (Teilnehmerzahl, Ort, Umfang, etc).
- Die Präsentation unserer Arbeit (jina-clip-v1).
- Zusammenfassungen anderer interessanter Forschungsarbeiten, die auf der ICML vorgestellt wurden.
Wenn wir nur ein einziges Embedding für diesen Artikel erstellen, repräsentiert dieses Embedding eine Mischung aus drei verschiedenen Themen:
Dies führt zu mehreren Problemen:
- Verwässerung der Repräsentation: Während alle Themen in einem Text miteinander verwandt sein könnten, ist möglicherweise nur eines für die Suchanfrage des Nutzers relevant. Ein einzelnes Embedding (in diesem Fall das des gesamten Blogbeitrags) ist jedoch nur ein Punkt im Vektorraum. Je mehr Text zur Modelleingabe hinzugefügt wird, desto mehr verschiebt sich das Embedding, um das übergeordnete Thema des Artikels zu erfassen, wodurch es weniger effektiv wird, den in bestimmten Absätzen behandelten Inhalt zu repräsentieren.
- Begrenzte Kapazität: Embedding-Modelle erzeugen Vektoren fester Größe, unabhängig von der Eingabelänge. Je mehr Inhalt zur Eingabe hinzugefügt wird, desto schwieriger wird es für das Modell, all diese Informationen im Vektor darzustellen. Stellen Sie sich das vor wie die Skalierung eines Bildes auf 16×16 Pixel — Wenn Sie ein Bild von etwas Einfachem wie einem Apfel skalieren, können Sie aus dem skalierten Bild immer noch Bedeutung ableiten. Bei einer Straßenkarte von Berlin? Eher nicht.
- Informationsverlust: In manchen Fällen stoßen selbst Long-Context-Embedding-Modelle an ihre Grenzen; Viele Modelle unterstützen Textkodierung mit bis zu 8.192 Token. Längere Dokumente müssen vor dem Embedding gekürzt werden, was zu Informationsverlust führt. Wenn sich die für den Benutzer relevante Information am Ende des Dokuments befindet, wird sie vom Embedding überhaupt nicht erfasst.
- Textsegmentierung kann notwendig sein: Einige Anwendungen erfordern Embeddings für bestimmte Textsegmente, aber nicht für das gesamte Dokument, wie zum Beispiel das Identifizieren der relevanten Passage in einem Text.
tagLong Context vs. Abschneiden
Um zu sehen, ob Long Context überhaupt sinnvoll ist, betrachten wir die Leistung von zwei Retrieval-Szenarien:
- Kodierung von Dokumenten bis zu 8.192 Token (etwa 10 Textseiten).
- Abschneiden von Dokumenten bei 192 Token und Kodierung bis dahin.
Wir werden die Ergebnisse vergleichen mitjina-embeddings-v3 mit der nDCG@10 Retrieval-Metrik. Wir haben folgende Datensätze getestet:
| Dataset | Beschreibung | Beispiel-Query | Beispiel-Dokument | Durchschnittliche Dokumentlänge (Zeichen) |
|---|---|---|---|---|
| NFCorpus | Ein medizinischer Volltext-Retrieval-Datensatz mit 3.244 Queries und Dokumenten hauptsächlich aus PubMed. | "Using Diet to Treat Asthma and Eczema" | "Statin Use and Breast Cancer Survival: A Nationwide Cohort Study from Finland Recent studies have suggested that [...]" | 326.753 |
| QMSum | Ein query-basierter Meeting-Zusammenfassungs-Datensatz, der die Zusammenfassung relevanter Meeting-Segmente erfordert. | "The professor was the one to raise the issue and suggested that a knowledge engineering trick [...]" | "Project Manager: Is that alright now ? {vocalsound} Okay . Sorry ? Okay , everybody all set to start the meeting ? [...]" | 37.445 |
| NarrativeQA | QA-Datensatz mit langen Geschichten und entsprechenden Fragen zu spezifischen Inhalten. | "What kind of business Sophia owned in Paris?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53.336 |
| 2WikiMultihopQA | Ein Multi-Hop-QA-Datensatz mit bis zu 5 Reasoning-Schritten, entwickelt mit Templates zur Vermeidung von Shortcuts. | "What is the award that the composer of song The Seeker (The Who Song) earned?" | "Passage 1:\nMargaret, Countess of Brienne\nMarguerite d'Enghien (born 1365 - d. after 1394), was the ruling suo jure [...]" | 30.854 |
| SummScreenFD | Ein Drehbuch-Zusammenfassungs-Datensatz mit TV-Serien-Transkripten und Zusammenfassungen, die eine verteilte Plot-Integration erfordern. | "Penny gets a new chair, which Sheldon enjoys until he finds out that she picked it up from [...]" | "[EXT. LAS VEGAS CITY (STOCK) - NIGHT]\n[EXT. ABERNATHY RESIDENCE - DRIVEWAY -- NIGHT]\n(The lamp post light over the [...]" | 1.613 |
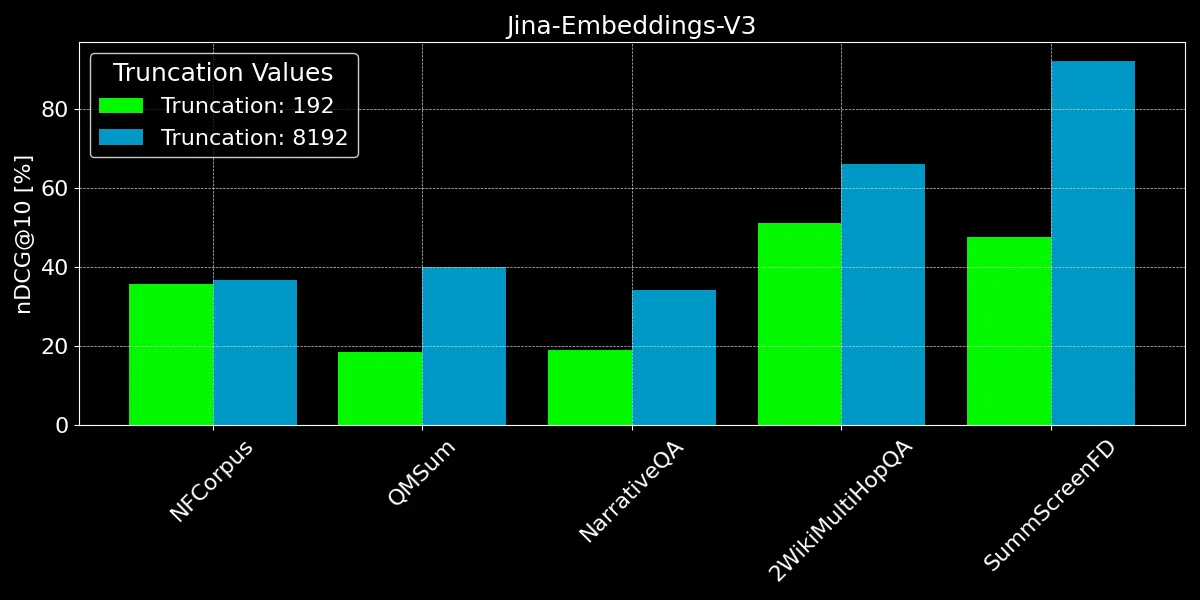
Wie wir sehen können, bringt die Kodierung von mehr als 192 Tokens bemerkenswerte Leistungsverbesserungen:
Allerdings sehen wir bei einigen Datensätzen größere Verbesserungen als bei anderen:
- Bei NFCorpus macht die Kürzung kaum einen Unterschied. Das liegt daran, dass sich die Titel und Abstracts direkt am Anfang der Dokumente befinden und diese hochrelevant für typische Benutzer-Suchbegriffe sind. Ob gekürzt oder nicht, die relevantesten Daten bleiben innerhalb des Token-Limits.
- QMSum und NarrativeQA gelten als "Leseverständnis"-Aufgaben, bei denen Benutzer typischerweise nach spezifischen Fakten innerhalb eines Textes suchen. Diese Fakten sind oft in Details verstreut, die über das Dokument verteilt sind und möglicherweise außerhalb der gekürzten 192-Token-Grenze liegen. Zum Beispiel wird im NarrativeQA-Dokument Percival Keene die Frage "Who is the bully that steals Percival's lunch?" erst weit nach dieser Grenze beantwortet. Ähnlich verhält es sich bei 2WikiMultiHopQA, wo relevante Informationen über ganze Dokumente verteilt sind und Modelle mehrere Abschnitte navigieren und synthetisieren müssen, um Anfragen effektiv zu beantworten.
- SummScreenFD ist eine Aufgabe, die darauf abzielt, das Drehbuch zu identifizieren, das zu einer bestimmten Zusammenfassung gehört. Da die Zusammenfassung Informationen enthält, die über das Drehbuch verteilt sind, verbessert die Kodierung von mehr Text die Genauigkeit beim Zuordnen der Zusammenfassung zum richtigen Drehbuch.
tagText-Segmentierung für bessere Retrieval-Leistung
• Segmentierung: Erkennen von Grenzsignalen in einem Eingabetext, zum Beispiel Sätze oder eine feste Anzahl von Tokens.
• Naives Chunking: Aufteilen des Textes in Chunks basierend auf Segmentierungssignalen vor der Kodierung.
• Late Chunking: Zuerst das Dokument kodieren und dann segmentieren (Kontext zwischen Chunks bleibt erhalten).
Anstatt ein ganzes Dokument in einen Vektor einzubetten, können wir verschiedene Methoden verwenden, um das Dokument zunächst durch Zuweisen von Grenzsignalen zu segmentieren:

Einige gängige Methoden sind:
- Segmentierung nach fester Größe: Das Dokument wird in Segmente mit einer festen Anzahl von Tokens unterteilt, die durch den Tokenizer des Embedding-Modells bestimmt wird. Dies stellt sicher, dass die Tokenisierung der Segmente der Tokenisierung des gesamten Dokuments entspricht (eine Segmentierung nach einer bestimmten Anzahl von Zeichen könnte zu einer anderen Tokenisierung führen).
- Segmentierung nach Sätzen: Das Dokument wird in Sätze segmentiert, und jeder Chunk besteht aus n Sätzen.
- Semantische Segmentierung: Jedes Segment entspricht mehreren Sätzen, und ein Embedding-Modell bestimmt die Ähnlichkeit aufeinanderfolgender Sätze. Sätze mit hoher Embedding-Ähnlichkeit werden demselben Chunk zugewiesen.
Der Einfachheit halber verwenden wir in diesem Artikel die Segmentierung nach fester Größe.
tagDokument-Retrieval mit naivem Chunking
Sobald wir die Segmentierung nach fester Größe durchgeführt haben, können wir das Dokument naiv entsprechend dieser Segmente chunken:
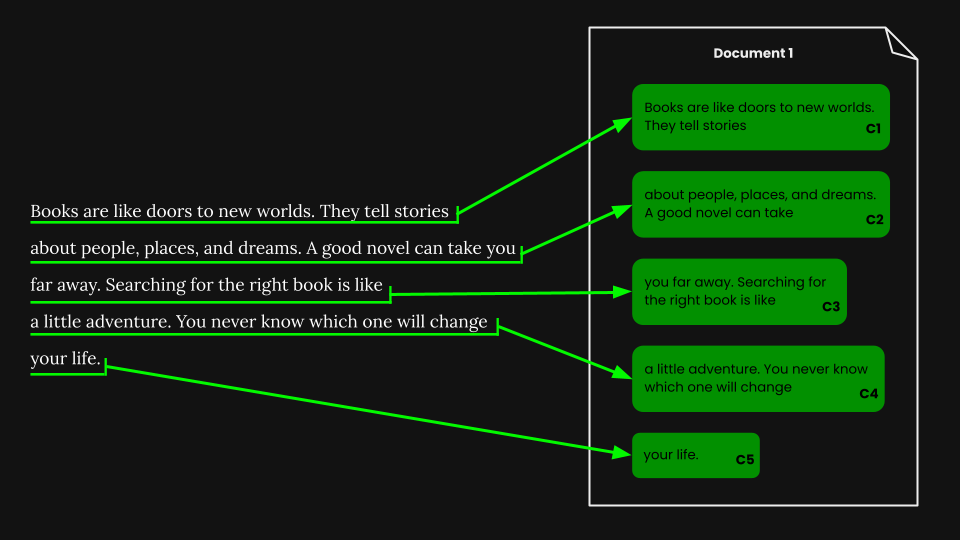
Mit jina-embeddings-v3 kodieren wir jeden Chunk in ein Embedding, das seine Semantik genau erfasst, und speichern diese Embeddings dann in einer Vektordatenbank.
Zur Laufzeit kodiert das Modell die Anfrage eines Benutzers in einen Query-Vektor. Wir vergleichen diesen mit unserer Vektordatenbank von Chunk-Embeddings, um den Chunk mit der höchsten Kosinus-Ähnlichkeit zu finden, und geben dann das entsprechende Dokument an den Benutzer zurück:
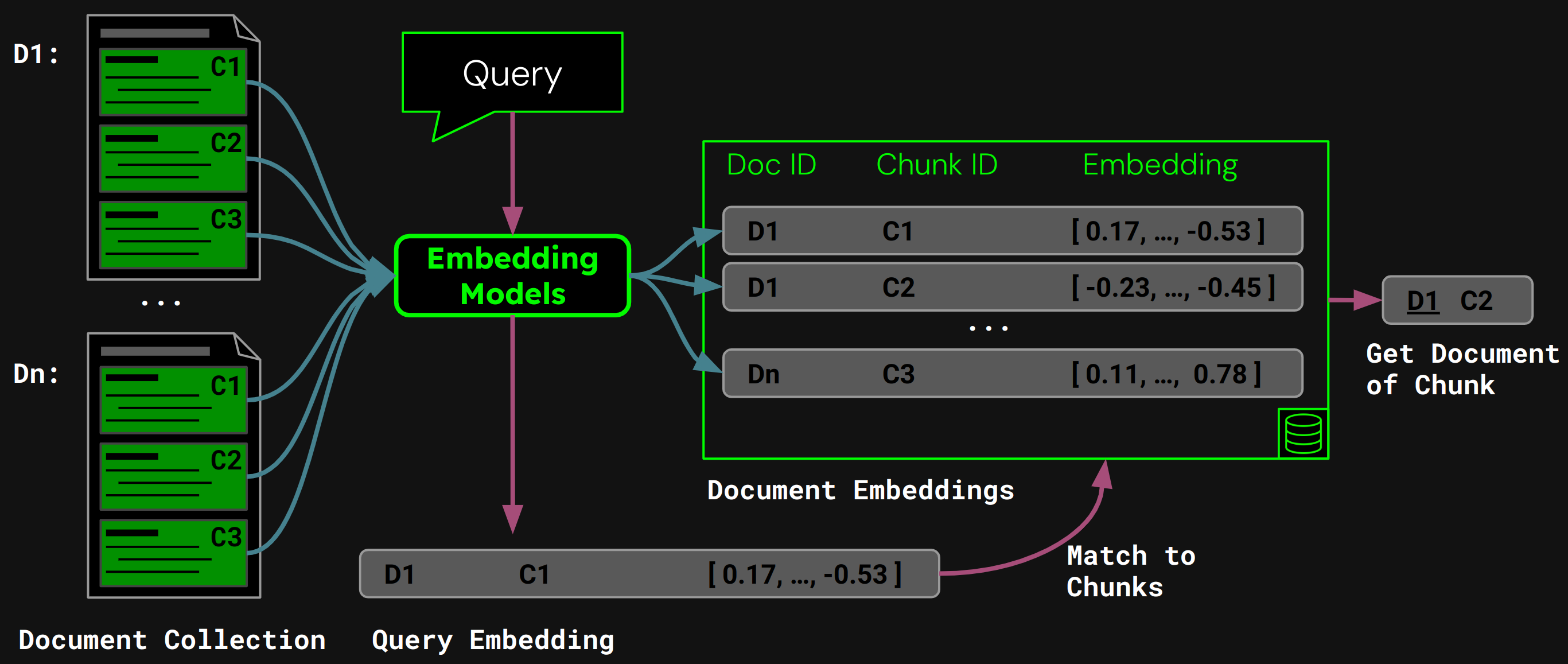
tagProbleme mit naivem Chunking

Während naives Chunking einige der Einschränkungen von Long-Context Embedding-Modellen adressiert, hat es auch seine Nachteile:
- Das große Ganze wird übersehen: Bei der Dokumentensuche können mehrere Embeddings kleinerer Chunks möglicherweise das übergreifende Thema des Dokuments nicht erfassen. Man sieht sozusagen den Wald vor lauter Bäumen nicht.
- Fehlendes Kontext-Problem: Chunks können nicht akkurat interpretiert werden, da Kontextinformationen fehlen, wie in Abbildung 6 dargestellt.
- Effizienz: Mehr Chunks benötigen mehr Speicherplatz und erhöhen die Abrufzeit.
tagLate Chunking löst das Kontext-Problem
Late Chunking funktioniert in zwei Hauptschritten:
- Zunächst nutzt es die Long-Context-Fähigkeiten des Modells, um das gesamte Dokument in Token-Embeddings zu codieren. Dies bewahrt den vollständigen Kontext des Dokuments.
- Dann erstellt es Chunk-Embeddings durch Anwendung von Mean Pooling auf bestimmte Sequenzen von Token-Embeddings, die den während der Segmentierung identifizierten Grenzmarkierungen entsprechen.
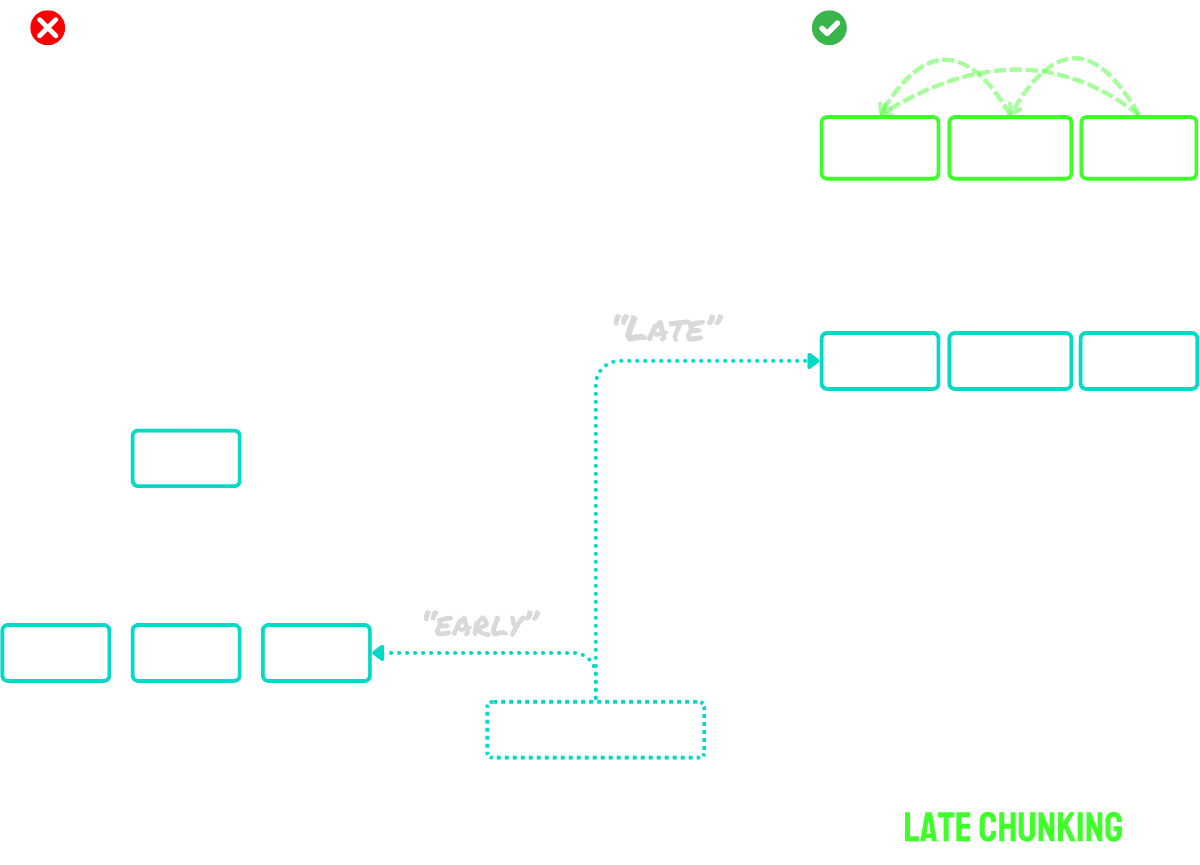
Der Hauptvorteil dieses Ansatzes ist, dass die Token-Embeddings kontextualisiert sind - das bedeutet, sie erfassen natürlich Bezüge und Beziehungen zu anderen Teilen des Dokuments. Da der Embedding-Prozess vor dem Chunking stattfindet, behält jeder Chunk das Bewusstsein für den breiteren Dokumentenkontext bei und löst damit das Problem des fehlenden Kontexts, das naive Chunking-Ansätze plagt.
Für Dokumente, die die maximale Eingabegröße des Modells überschreiten, können wir „Long Late Chunking" verwenden:
- Zunächst teilen wir das Dokument in überlappende „Macro-Chunks" auf. Jeder Macro-Chunk ist so dimensioniert, dass er in die maximale Kontextlänge des Modells passt (zum Beispiel 8.192 Token).
- Das Modell verarbeitet diese Macro-Chunks, um Token-Embeddings zu erstellen.
- Sobald wir die Token-Embeddings haben, fahren wir mit dem Standard-Late-Chunking fort - wir wenden Mean Pooling an, um die finalen Chunk-Embeddings zu erstellen.
Dieser Ansatz ermöglicht es uns, Dokumente beliebiger Länge zu verarbeiten und dabei die Vorteile des Late Chunking zu bewahren. Man kann es sich als zweistufigen Prozess vorstellen: Zunächst wird das Dokument für das Modell verdaulich gemacht, dann wird das reguläre Late-Chunking-Verfahren angewendet.
Kurz gesagt:
- Naives Chunking: Das Dokument in kleine Chunks segmentieren, dann jeden Chunk separat codieren.
- Late Chunking: Das gesamte Dokument auf einmal codieren, um Token-Embeddings zu erstellen, dann Chunk-Embeddings durch Pooling der Token-Embeddings basierend auf Segmentgrenzen erstellen.
- Long Late Chunking: Große Dokumente in überlappende Macro-Chunks aufteilen, die in das Kontextfenster des Modells passen, diese codieren, um Token-Embeddings zu erhalten, dann Late Chunking wie gewohnt anwenden.
Für eine ausführlichere Beschreibung der Idee werfen Sie einen Blick in unser Paper oder die oben erwähnten Blog-Posts.
tagChunking oder kein Chunking?
Wir haben bereits gesehen, dass Long-Context Embedding im Allgemeinen bessere Leistung als kürzere Text-Embeddings erbringt, und einen Überblick über naive und Late-Chunking-Strategien gegeben. Die Frage ist nun: Ist Chunking besser als Long-Context Embedding?
Um einen fairen Vergleich durchzuführen, kürzen wir Textwerte auf die maximale Sequenzlänge des Modells (8.192 Token), bevor wir mit der Segmentierung beginnen. Wir verwenden eine Segmentierung fester Größe mit 64 Token pro Segment (sowohl für naive Segmentierung als auch für Late Chunking). Vergleichen wir drei Szenarien:
- Keine Segmentierung: Wir codieren jeden Text in ein einzelnes Embedding. Dies führt zu den gleichen Ergebnissen wie im vorherigen Experiment (siehe Abbildung 2), aber wir nehmen sie hier zum besseren Vergleich auf.
- Naives Chunking: Wir segmentieren die Texte und wenden dann naives Chunking basierend auf den Grenzmarkierungen an.
- Late Chunking: Wir segmentieren die Texte und verwenden dann Late Chunking zur Bestimmung der Embeddings.
Sowohl bei Late Chunking als auch bei naiver Segmentierung verwenden wir Chunk-Retrieval zur Bestimmung des relevanten Dokuments (wie in Abbildung 5 weiter oben in diesem Beitrag gezeigt).
Die Ergebnisse zeigen keinen klaren Gewinner:
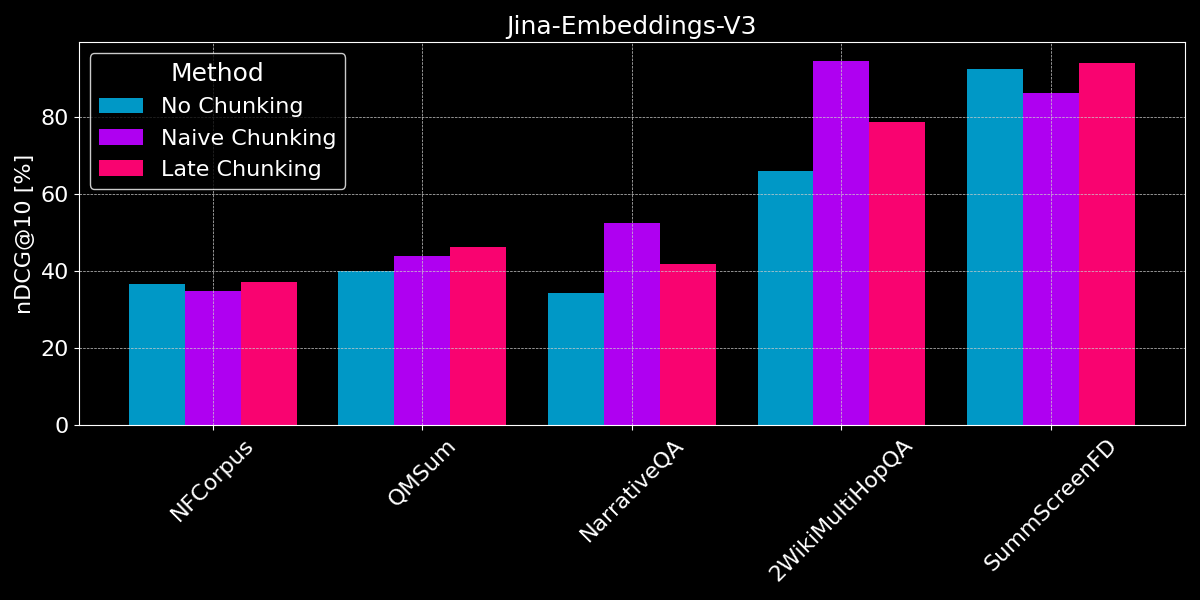
- Für Faktensuche funktioniert naives Chunking besser: Für die Datensätze QMSum, NarrativeQA und 2WikiMultiHopQA muss das Modell relevante Passagen im Dokument identifizieren. Hier ist naives Chunking deutlich besser als die Codierung von allem in ein einzelnes Embedding, da wahrscheinlich nur wenige Chunks relevante Informationen enthalten und diese Chunks sie viel besser erfassen als ein einzelnes Embedding des gesamten Dokuments.
- Late Chunking funktioniert am besten bei kohärenten Dokumenten mit relevantem Kontext: Bei Dokumenten, die ein zusammenhängendes Thema behandeln und bei denen Benutzer eher nach übergeordneten Themen als nach spezifischen Fakten suchen (wie bei NFCorpus), schneidet Late Chunking etwas besser ab als kein Chunking, da es dokumentweiten Kontext mit lokalen Details ausbalanciert. Während Late Chunking im Allgemeinen durch die Kontexterhaltung besser funktioniert als naives Chunking, kann dieser Vorteil zum Nachteil werden, wenn nach isolierten Fakten in Dokumenten mit überwiegend irrelevanten Informationen gesucht wird - wie die Leistungsrückgänge bei NarrativeQA und 2WikiMultiHopQA zeigen, wo der zusätzliche Kontext eher ablenkt als hilft.
tagMacht die Chunk-Größe einen Unterschied?
Die Effektivität von Chunking-Methoden hängt stark vom Dataset ab, was zeigt, wie wichtig die Inhaltsstruktur ist:
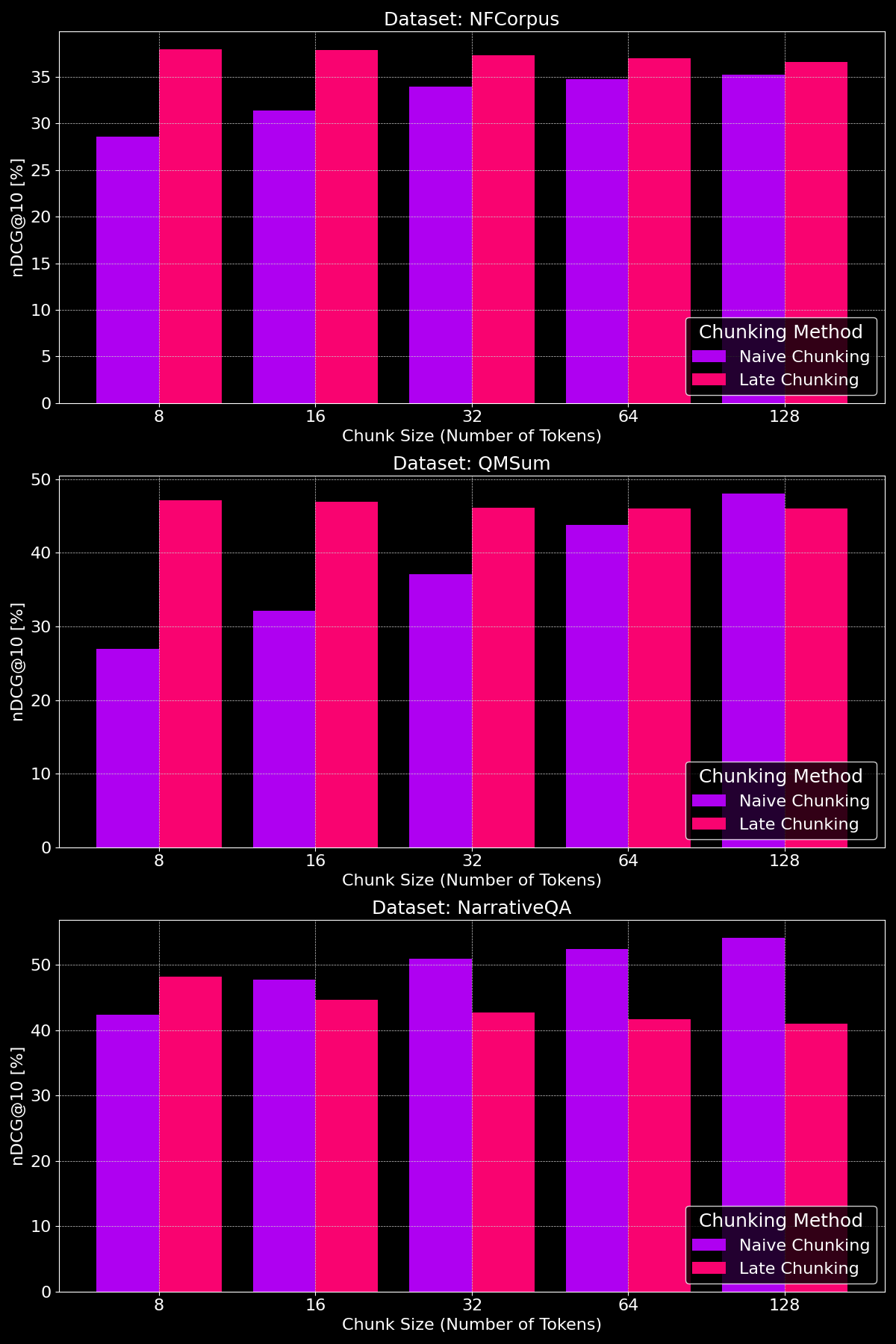
Wie wir sehen können, übertrifft Late Chunking bei kleineren Chunk-Größen generell das naive Chunking, da kleinere naive Chunks zu wenig Kontext enthalten, während kleinere Late Chunks den Kontext des gesamten Dokuments bewahren und dadurch semantisch aussagekräftiger sind. Die Ausnahme bildet das NarrativeQA Dataset, bei dem es einfach so viel irrelevanten Kontext gibt, dass Late Chunking zurückfällt. Bei größeren Chunk-Größen zeigt naives Chunking deutliche Verbesserungen (und übertrifft gelegentlich Late Chunking) aufgrund des erhöhten Kontexts, während die Leistung von Late Chunking allmählich abnimmt.
tagErkenntnisse: Wann verwendet man was?
In diesem Beitrag haben wir verschiedene Arten von Dokumenten-Retrieval-Aufgaben untersucht, um besser zu verstehen, wann Segmentierung und wann Late Chunking hilft. Was haben wir also gelernt?
tagWann sollte ich Long-Context Embedding verwenden?
Im Allgemeinen schadet es der Retrieval-Genauigkeit nicht, so viel Text wie möglich aus Ihren Dokumenten als Input für Ihr Embedding-Modell zu verwenden. Allerdings konzentrieren sich Long-Context Embedding-Modelle oft auf den Anfang von Dokumenten, da diese Inhalte wie Titel und Einleitung enthalten, die für die Beurteilung der Relevanz wichtiger sind, aber die Modelle könnten Inhalte in der Mitte des Dokuments übersehen.
tagWann sollte ich naives Chunking verwenden?
Wenn Dokumente mehrere Aspekte abdecken oder Benutzeranfragen auf spezifische Informationen innerhalb eines Dokuments abzielen, verbessert Chunking im Allgemeinen die Retrieval-Leistung.
Letztendlich hängen Segmentierungsentscheidungen von Faktoren ab wie der Notwendigkeit, Teiltext für Benutzer anzuzeigen (z.B. wie Google die relevanten Passagen in den Vorschauen der Suchergebnisse präsentiert), was Segmentierung unerlässlich macht, oder Einschränkungen bei Rechenleistung und Speicher, wo Segmentierung aufgrund erhöhten Retrieval-Overheads und Ressourcenverbrauchs weniger vorteilhaft sein kann.
tagWann sollte ich Late Chunking verwenden?
Durch das Encodieren des vollständigen Dokuments vor der Erstellung von Chunks löst Late Chunking das Problem, dass Textsegmente durch fehlenden Kontext ihre Bedeutung verlieren. Dies funktioniert besonders gut bei kohärenten Dokumenten, bei denen jeder Teil mit dem Ganzen zusammenhängt. Unsere Experimente zeigen, dass Late Chunking besonders effektiv ist, wenn Text in kleinere Chunks unterteilt wird, wie in unserem Paper demonstriert. Es gibt jedoch einen Vorbehalt: Wenn Teile des Dokuments nicht miteinander zusammenhängen, kann das Einbeziehen dieses breiteren Kontexts die Retrieval-Leistung tatsächlich verschlechtern, da es Rauschen zu den Embeddings hinzufügt.
tagFazit
Die Wahl zwischen Long-Context Embedding, naivem Chunking und Late Chunking hängt von den spezifischen Anforderungen Ihrer Retrieval-Aufgabe ab. Long-Context Embeddings sind wertvoll für kohärente Dokumente mit allgemeinen Anfragen, während Chunking in Fällen excellt, in denen Benutzer nach spezifischen Fakten oder Informationen innerhalb eines Dokuments suchen. Late Chunking verbessert das Retrieval weiter, indem es die kontextuelle Kohärenz innerhalb kleinerer Segmente beibehält. Letztendlich wird das Verständnis Ihrer Daten und Retrieval-Ziele den optimalen Ansatz bestimmen, der Genauigkeit, Effizienz und kontextuelle Relevanz ausbalanciert.
Wenn Sie diese Strategien erkunden, erwägen Sie jina-embeddings-v3 auszuprobieren—seine fortgeschrittenen Long-Context-Fähigkeiten, Late Chunking und Flexibilität machen es zu einer ausgezeichneten Wahl für verschiedene Retrieval-Szenarien.






