



Kürzlich teilte Christoph Schuhmann, Gründer von LAION AI eine interessante Beobachtung über Text-Embedding-Modelle:
Wenn Wörter innerhalb eines Satzes zufällig umgestellt werden, bleibt die Cosinus-Ähnlichkeit zwischen ihren Text-Embeddings im Vergleich zum ursprünglichen Satz überraschend hoch.
Betrachten wir zum Beispiel zwei Sätze: Berlin is the capital of Germany und the Germany Berlin is capital of. Obwohl der zweite Satz keinen Sinn ergibt, können Text-Embedding-Modelle sie kaum unterscheiden. Mit jina-embeddings-v3 haben diese beiden Sätze einen Cosinus-Ähnlichkeitswert von 0,9295.
Die Wortstellung ist nicht das einzige, wofür Embeddings anscheinend nicht sehr sensitiv sind. Grammatikalische Transformationen können die Bedeutung eines Satzes dramatisch verändern, haben aber wenig Einfluss auf die Embedding-Distanz. Zum Beispiel haben She ate dinner before watching the movie und She watched the movie before eating dinner eine Cosinus-Ähnlichkeit von 0,9833, obwohl sie die entgegengesetzte Reihenfolge der Handlungen beschreiben.
Auch Verneinung ist ohne spezielles Training bekanntermaßen schwierig konsistent einzubetten — This is a useful model und This is not a useful model sehen im Embedding-Raum praktisch gleich aus. Oft verändert das Ersetzen von Wörtern durch andere derselben Klasse, wie etwa "today" durch "yesterday", oder die Änderung einer Verbzeit, die Embeddings nicht so stark wie man erwarten würde.
Dies hat ernsthafte Auswirkungen. Betrachten wir zwei Suchanfragen: Flight from Berlin to Amsterdam und Flight from Amsterdam to Berlin. Sie haben fast identische Embeddings, wobei jina-embeddings-v3 ihnen eine Cosinus-Ähnlichkeit von 0,9884 zuweist. Für eine reale Anwendung wie Reisesuche oder Logistik ist diese Schwäche fatal.
In diesem Artikel betrachten wir die Herausforderungen für Embedding-Modelle und untersuchen ihre anhaltenden Schwierigkeiten mit Wortstellung und Wortwahl. Wir analysieren wichtige Fehlerarten in verschiedenen linguistischen Kategorien — einschließlich direktionaler, zeitlicher, kausaler, vergleichender und verneinender Kontexte — und erforschen Strategien zur Verbesserung der Modellleistung.
tagWarum haben umgestellte Sätze überraschend ähnliche Cosinus-Werte?
Zunächst dachten wir, dies könnte daran liegen, wie das Modell Wortbedeutungen kombiniert - es erstellt ein Embedding für jedes Wort (6-7 Wörter in jedem unserer obigen Beispielsätze) und mittelt diese Embeddings dann durch Mean Pooling. Das bedeutet, dass dem finalen Embedding nur sehr wenig Information über die Wortstellung zur Verfügung steht. Ein Durchschnitt ist derselbe, egal in welcher Reihenfolge die Werte stehen.
Allerdings haben selbst Modelle, die CLS Pooling verwenden (die ein spezielles erstes Wort betrachten, um den ganzen Satz zu verstehen und sensitiver für die Wortstellung sein sollten), dasselbe Problem. Zum Beispiel gibt bge-1.5-base-en immer noch eine Cosinus-Ähnlichkeit von 0,9304 für die Sätze Berlin is the capital of Germany und the Germany Berlin is capital of.
Dies deutet auf eine Einschränkung in der Art und Weise hin, wie Embedding-Modelle trainiert werden. Während Sprachmodelle zunächst während des Pre-trainings die Satzstruktur lernen, scheinen sie einen Teil dieses Verständnisses während des kontrastiven Trainings zu verlieren — dem Prozess, den wir verwenden, um Embedding-Modelle zu erstellen.
tagWie beeinflussen Textlänge und Wortstellung die Embedding-Ähnlichkeit?
Warum haben Modelle überhaupt Probleme mit der Wortstellung? Das Erste, was einem in den Sinn kommt, ist die Länge (in Tokens) des Textes. Wenn Text an die Encoding-Funktion gesendet wird, generiert das Modell zunächst eine Liste von Token-Embeddings (d.h., jedes tokenisierte Wort hat einen eigenen Vektor, der seine Bedeutung repräsentiert) und mittelt diese dann.
Um zu sehen, wie Textlänge und Wortstellung die Embedding-Ähnlichkeit beeinflussen, haben wir einen Datensatz von 180 synthetischen Sätzen verschiedener Längen erstellt, wie etwa 3, 5, 10, 15, 20 und 30 Tokens. Wir haben auch die Tokens zufällig umgestellt, um eine Variation jedes Satzes zu erstellen:

Hier sind einige Beispiele:
| Länge (Tokens) | Originalsatz | Umgestellter Satz |
|---|---|---|
| 3 | The cat sleeps | cat The sleeps |
| 5 | He drives his car carefully | drives car his carefully He |
| 15 | The talented musicians performed beautiful classical music at the grand concert hall yesterday | in talented now grand classical yesterday The performed musicians at hall concert the music |
| 30 | The passionate group of educational experts collaboratively designed and implemented innovative teaching methodologies to improve learning outcomes in diverse classroom environments worldwide | group teaching through implemented collaboratively outcomes of methodologies across worldwide diverse with passionate and in experts educational classroom for environments now by learning to at improve from innovative The designed |
Wir werden den Datensatz mit unserem eigenen jina-embeddings-v3 Modell und dem Open-Source-Modell bge-base-en-v1.5 encodieren und dann die Cosinus-Ähnlichkeit zwischen dem Original und dem umgestellten Satz berechnen:
| Länge (Tokens) | Mittlere Cosinus-Ähnlichkeit | Standardabweichung der Cosinus-Ähnlichkeit |
|---|---|---|
| 3 | 0,947 | 0,053 |
| 5 | 0,909 | 0,052 |
| 10 | 0,924 | 0,031 |
| 15 | 0,918 | 0,019 |
| 20 | 0,899 | 0,021 |
| 30 | 0,874 | 0,025 |
Wir können nun ein Box-Plot erstellen, das den Trend in der Cosinus-Ähnlichkeit deutlicher macht:
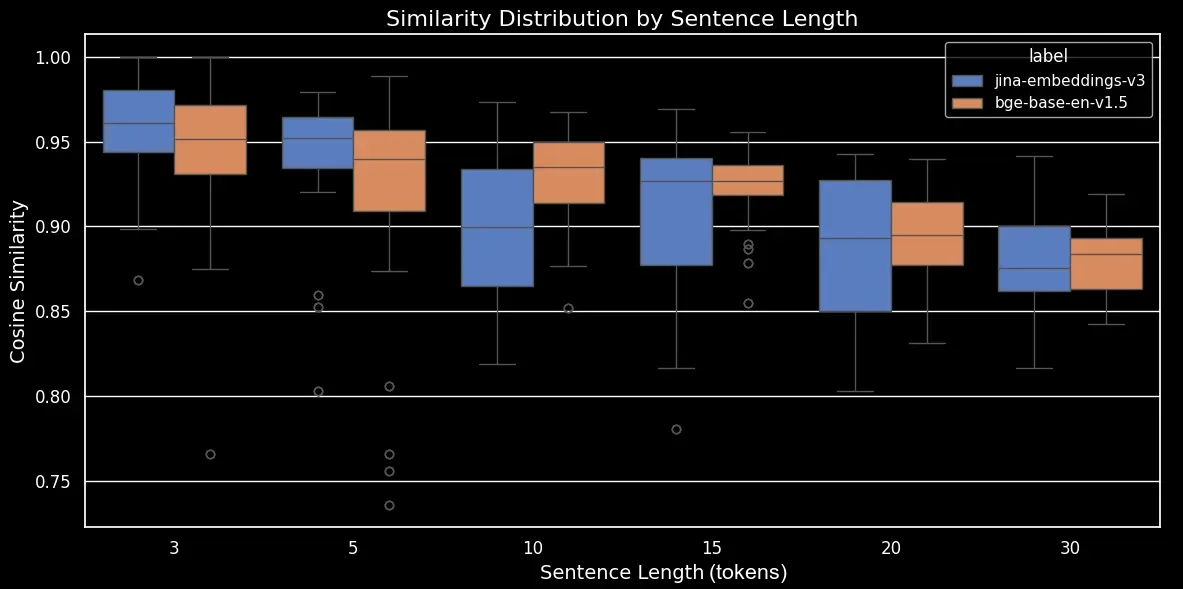
bge-base-en-1.5 (unfeinetuned)Wie wir sehen können, gibt es eine klare lineare Beziehung in der durchschnittlichen Cosinus-Ähnlichkeit der Embeddings. Je länger der Text, desto niedriger ist der durchschnittliche Cosinus-Ähnlichkeitswert zwischen den originalen und zufällig umgestellten Sätzen. Dies geschieht wahrscheinlich aufgrund der "Wortverschiebung", nämlich wie weit sich Wörter nach der zufälligen Umstellung von ihren ursprünglichen Positionen entfernt haben. In einem kürzeren Text gibt es einfach weniger "Slots", in die ein Token verschoben werden kann, sodass es sich nicht so weit bewegen kann, während ein längerer Text eine größere Anzahl möglicher Permutationen hat und Wörter sich weiter bewegen können.
Wie in der folgenden Abbildung (Cosine Similarity vs Average Word Displacement) zu sehen ist, gilt: Je länger der Text, desto größer die Wortverschiebung:
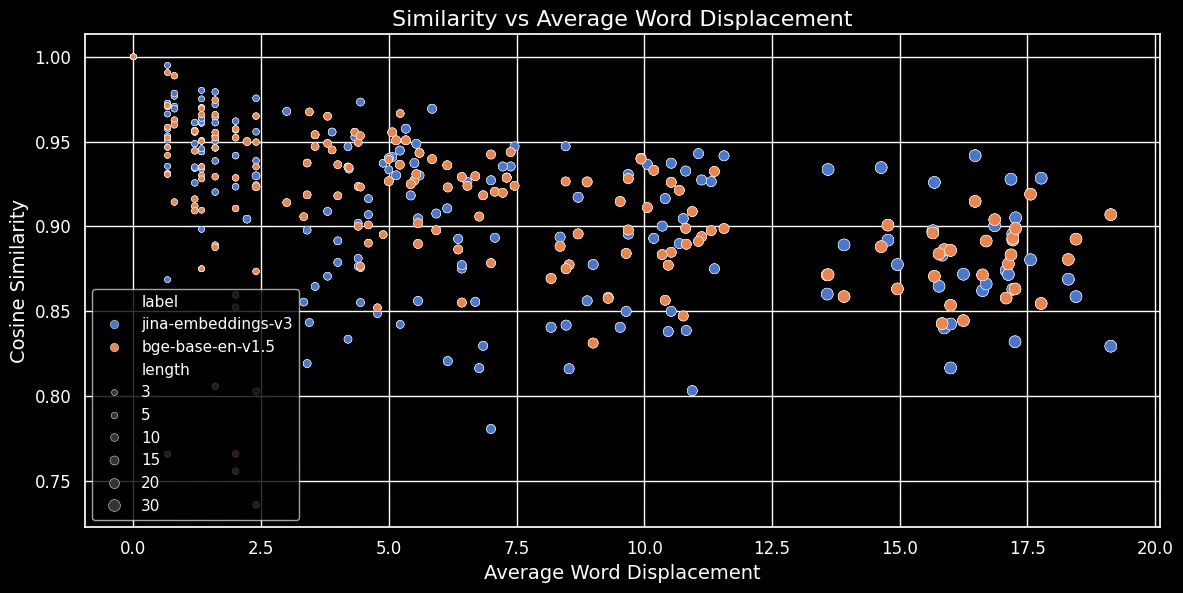
Token-Embeddings sind vom lokalen Kontext abhängig, d.h. von den ihnen am nächsten stehenden Wörtern. Bei einem kurzen Text kann die Umstellung von Wörtern diesen Kontext nicht stark verändern. Bei einem längeren Text hingegen kann ein Wort sehr weit von seinem ursprünglichen Kontext entfernt werden, was sein Token-Embedding erheblich verändern kann. Infolgedessen erzeugt das Mischen der Wörter in einem längeren Text ein stärker abweichendes Embedding als bei einem kürzeren. Die obige Abbildung zeigt, dass sowohl für jina-embeddings-v3 mit Mean Pooling als auch für bge-base-en-v1.5 mit CLS Pooling die gleiche Beziehung gilt: Das Mischen längerer Texte und das weitere Verschieben von Wörtern führt zu geringeren Ähnlichkeitswerten.
tagLösen größere Modelle das Problem?
Normalerweise ist es bei solchen Problemen eine gängige Taktik, einfach ein größeres Modell einzusetzen. Aber kann ein größeres Text-Embedding-Modell die Wortreihenfolge wirklich effektiver erfassen? Gemäß dem Skalierungsgesetz für Text-Embedding-Modelle (referenziert in unserem jina-embeddings-v3 Release-Beitrag) bieten größere Modelle generell bessere Leistung:
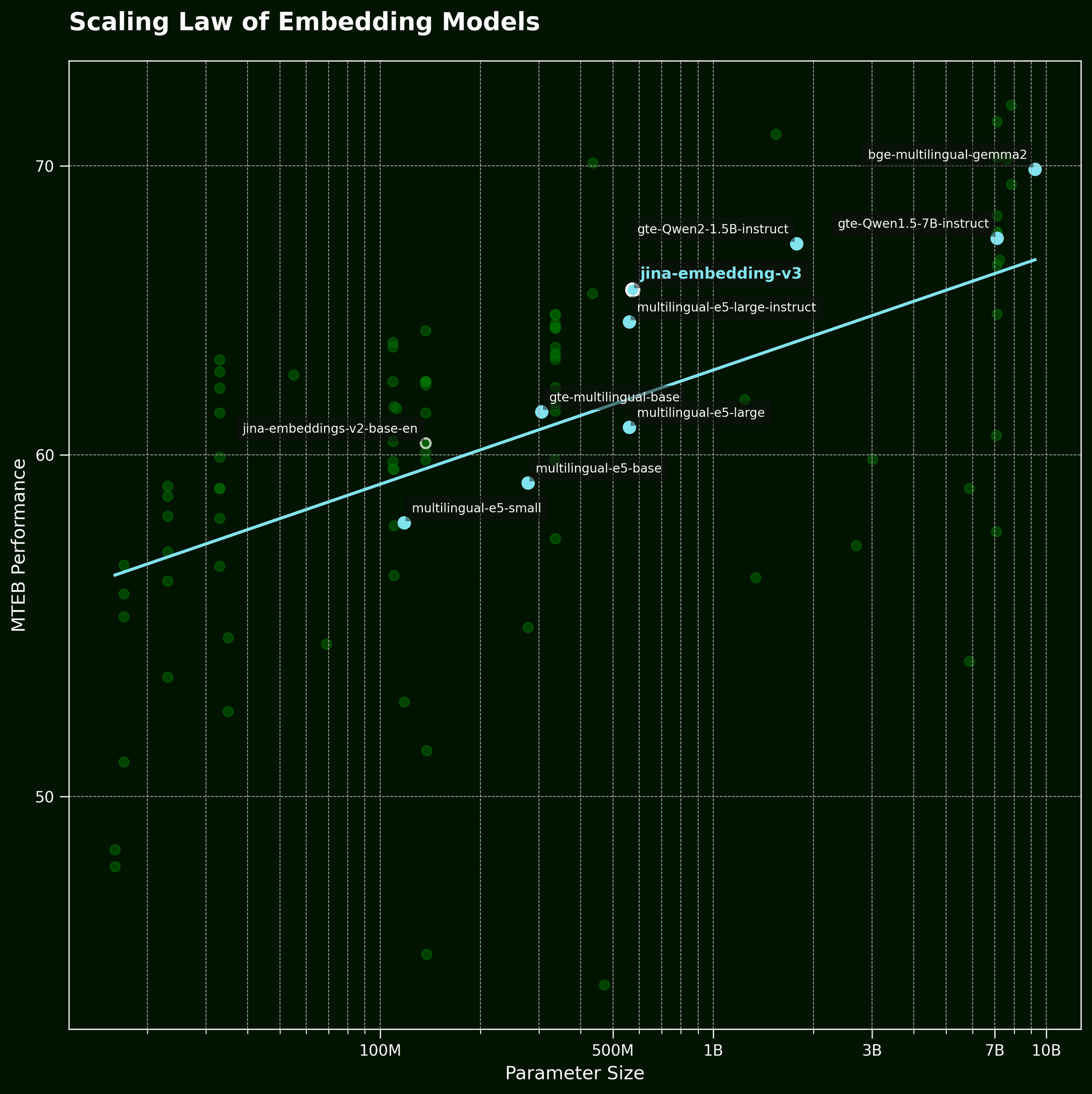
Aber kann ein größeres Modell Informationen zur Wortreihenfolge effektiver erfassen? Wir haben drei Varianten des BGE-Modells getestet: bge-small-en-v1.5, bge-base-en-v1.5 und bge-large-en-v1.5, mit Parametergrößen von 33 Millionen, 110 Millionen bzw. 335 Millionen.
Wir verwenden die gleichen 180 Sätze wie zuvor, ignorieren aber die Längeninformationen. Wir kodieren sowohl die Originalsätze als auch ihre zufälligen Mischungen mit den drei Modellvarianten und plotten die durchschnittliche Kosinus-Ähnlichkeit:
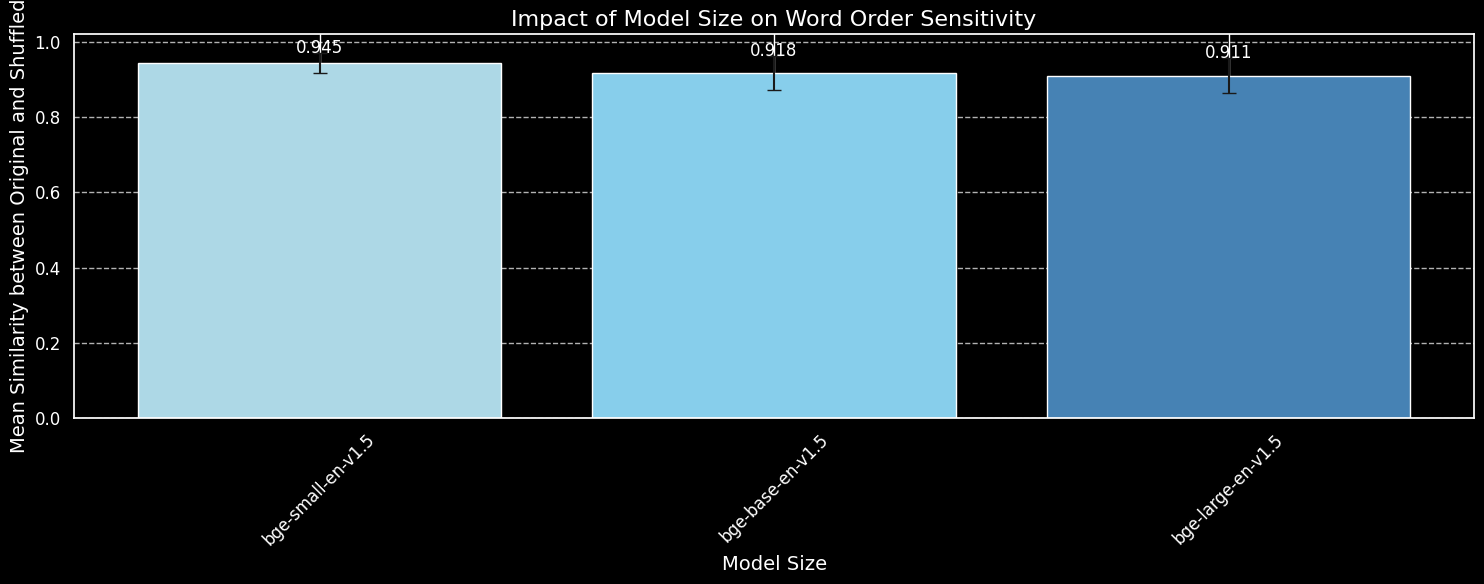
bge-small-en-v1.5, bge-base-en-v1.5 und bge-large-en-v1.5.Während wir sehen können, dass größere Modelle sensibler auf Variationen in der Wortreihenfolge reagieren, ist der Unterschied gering. Selbst das deutlich größere bge-large-en-v1.5 ist nur geringfügig besser darin, gemischte von ungemischten Sätzen zu unterscheiden. Andere Faktoren spielen eine Rolle bei der Bestimmung, wie empfindlich ein Embedding-Modell auf Wortumstellungen reagiert, insbesondere Unterschiede im Training. Darüber hinaus ist die Kosinus-Ähnlichkeit ein sehr begrenztes Werkzeug zur Messung der Unterscheidungsfähigkeit eines Modells. Wir können jedoch erkennen, dass die Modellgröße kein wesentlicher Faktor ist. Wir können das Problem nicht einfach durch ein größeres Modell lösen.
tagWortreihenfolge und Wortwahl in der realen Welt
jina-embeddings-v2 (nicht unser neuestes Modell, jina-embeddings-v3), da v2 mit 137m Parametern deutlich kleiner und damit schneller auf unseren lokalen GPUs zu experimentieren ist als v3 mit 580m Parametern.Wie wir in der Einleitung erwähnt haben, ist die Wortreihenfolge nicht die einzige Herausforderung für Embedding-Modelle. Eine realistischere Herausforderung in der realen Welt betrifft die Wortwahl. Es gibt viele Möglichkeiten, Wörter in einem Satz auszutauschen – Möglichkeiten, die sich in den Embeddings nicht gut widerspiegeln. Wir können "Sie flog von Paris nach Tokio" zu "Sie fuhr von Tokio nach Paris" ändern, und die Embeddings bleiben ähnlich. Wir haben dies über mehrere Kategorien von Änderungen hinweg abgebildet:
| Kategorie | Beispiel - Links | Beispiel - Rechts | Kosinus-Ähnlichkeit (jina) |
|---|---|---|---|
| Richtungsbezogen | Sie flog von Paris nach Tokio | Sie fuhr von Tokio nach Paris | 0.9439 |
| Zeitlich | Sie aß zu Abend, bevor sie den Film sah | Sie sah den Film, bevor sie zu Abend aß | 0.9833 |
| Kausal | Die steigende Temperatur schmolz den Schnee | Der schmelzende Schnee kühlte die Temperatur | 0.8998 |
| Vergleichend | Kaffee schmeckt besser als Tee | Tee schmeckt besser als Kaffee | 0.9457 |
| Verneinung | Er steht am Tisch | Er steht weit vom Tisch entfernt | 0.9116 |
Die obige Tabelle zeigt eine Liste von "Fehlerfällen", bei denen ein Text-Embedding-Modell subtile Wortänderungen nicht erfassen kann. Dies entspricht unseren Erwartungen: Text-Embedding-Modellen fehlt die Fähigkeit zum logischen Denken. Zum Beispiel versteht das Modell nicht die Beziehung zwischen "von" und "nach". Text-Embedding-Modelle führen semantisches Matching durch, wobei die Semantik typischerweise auf Token-Ebene erfasst und nach dem Pooling in einen einzelnen dichten Vektor komprimiert wird. Im Gegensatz dazu zeigen LLMs (autoregressive Modelle), die auf größeren Datensätzen im Billionen-Token-Bereich trainiert wurden, erste emergente Fähigkeiten zum logischen Denken.
Das brachte uns auf die Frage: Können wir das Embedding-Modell mit kontrastivem Lernen unter Verwendung von Triplets fein-tunen, um die Abfrage und das Positive näher zusammenzubringen und gleichzeitig die Abfrage und das Negative weiter auseinanderzutreiben?

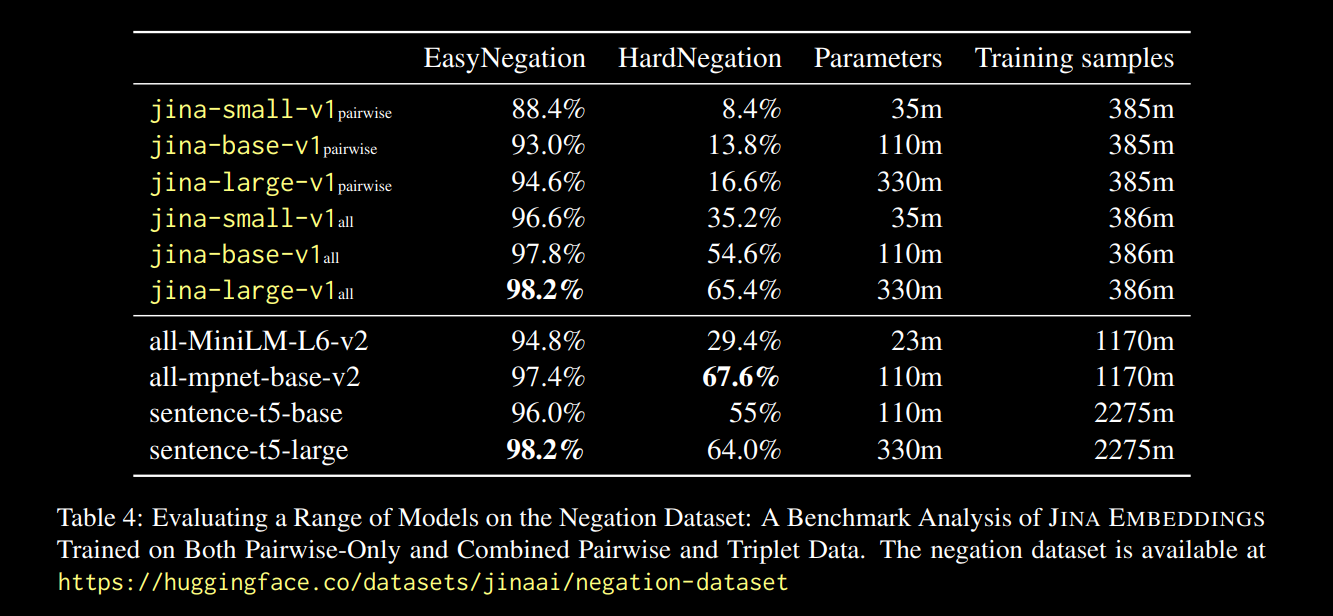
Zum Beispiel könnte "Flug von Amsterdam nach Berlin" als negatives Paar zu "Flug von Berlin nach Amsterdam" betrachtet werden. Tatsächlich haben wir in dem jina-embeddings-v1 technischen Bericht (Michael Guenther, et al.) dieses Problem bereits in kleinem Maßstab behandelt: Wir haben das jina-embeddings-v1 Modell auf einem Negations-Datensatz mit 10.000 von Large Language Models generierten Beispielen feingetunt.

Die im obigen Bericht dokumentierten Ergebnisse waren vielversprechend:
Wir beobachten, dass über alle Modellgrößen hinweg das Fine-Tuning auf Triplet-Daten (einschließlich unseres Negations-Trainingsdatensatzes) die Leistung drastisch verbessert, insbesondere bei der HardNegation-Aufgabe.
jina-embeddings Modellen mit paarweisem und kombiniertem Triplet/paarweisem Training.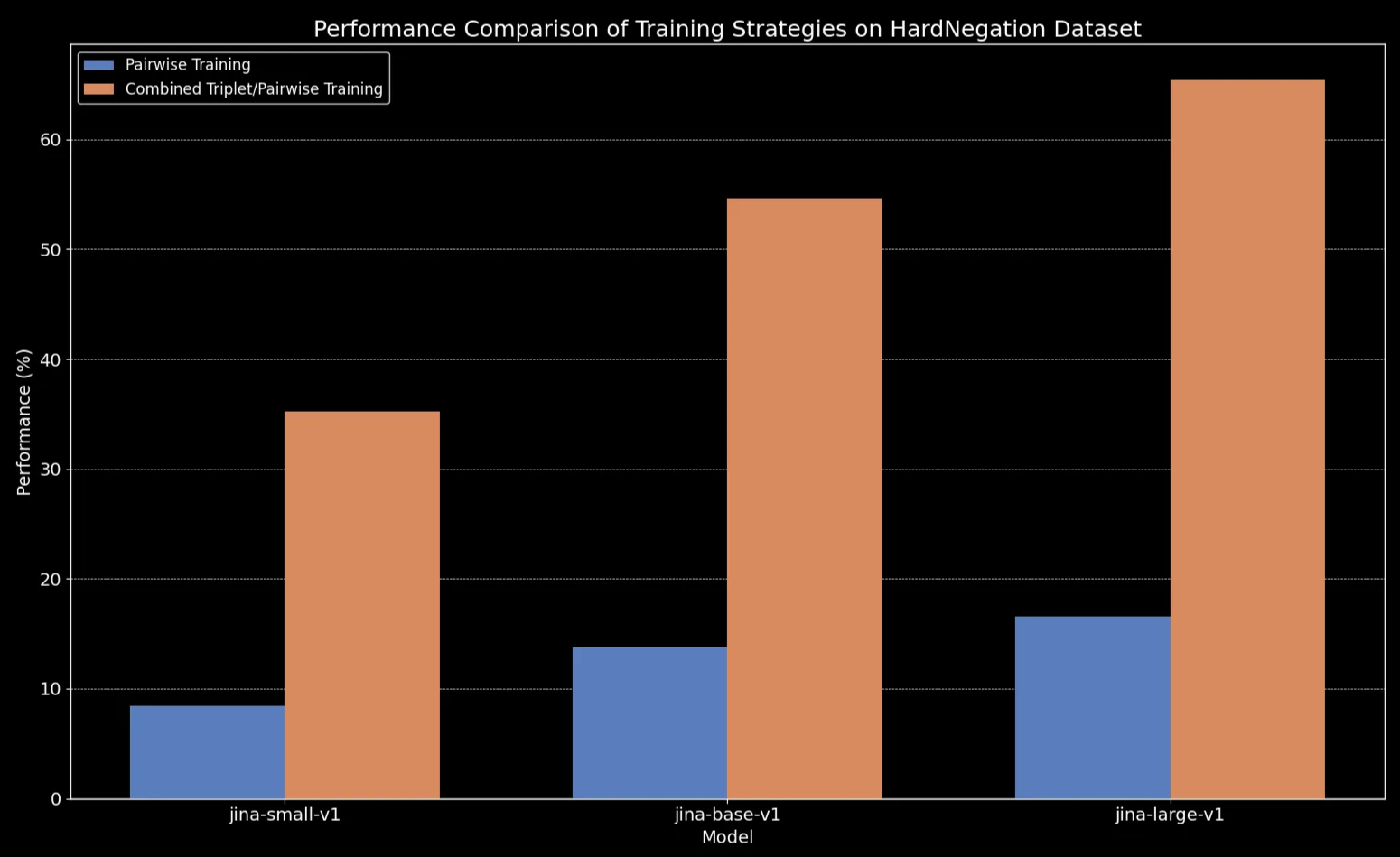
jina-embeddings.tagFine-Tuning von Text-Embedding-Modellen mit kuratierten Datensätzen
In den vorherigen Abschnitten haben wir mehrere wichtige Beobachtungen zu Text-Embeddings untersucht:
- Kürzere Texte sind anfälliger für Fehler bei der Erfassung der Wortreihenfolge.
- Die Vergrößerung des Text-Embedding-Modells verbessert nicht unbedingt das Verständnis der Wortreihenfolge.
- Kontrastives Lernen könnte eine potenzielle Lösung für diese Probleme bieten.
Mit diesem Wissen haben wir jina-embeddings-v2-base-en und bge-base-en-1.5 auf unseren Negations- und Wortreihenfolge-Datensätzen feingetunt (insgesamt etwa 11.000 Trainingsbeispiele):


Zur Evaluierung des Fine-Tunings haben wir einen Datensatz von 1.000 Triplets erstellt, bestehend aus einer query, einem positive (pos) und einem negative (neg) Fall:

Hier ist ein Beispiel einer Zeile:
| Anchor | The river flows from the mountains to the sea |
| Positive | Water travels from mountain peaks to ocean |
| Negative | The river flows from the sea to the mountains |
Diese Triplets sind so gestaltet, dass sie verschiedene Fehlerfälle abdecken, einschließlich direktionaler, zeitlicher und kausaler Bedeutungsverschiebungen aufgrund von Wortreihenfolgeänderungen.
Wir können die Modelle nun auf drei verschiedenen Evaluierungssets testen:
- Das Set von 180 synthetischen Sätzen (von früher in diesem Beitrag), zufällig gemischt.
- Fünf manuell überprüfte Beispiele (aus der obigen Richtungs-/Kausal-/etc-Tabelle).
- 94 kuratierte Triplets aus unserem gerade erstellten Triplet-Datensatz.
Hier ist der Unterschied für gemischte Sätze vor und nach dem Fine-Tuning:
| Satzlänge (Tokens) | Mittlere Cosinus-Ähnlichkeit (jina) |
Mittlere Cosinus-Ähnlichkeit (jina-ft) |
Mittlere Cosinus-Ähnlichkeit (bge) |
Mittlere Cosinus-Ähnlichkeit (bge-ft) |
|---|---|---|---|---|
| 3 | 0.970 | 0.927 | 0.929 | 0.899 |
| 5 | 0.958 | 0.910 | 0.940 | 0.916 |
| 10 | 0.953 | 0.890 | 0.934 | 0.910 |
| 15 | 0.930 | 0.830 | 0.912 | 0.875 |
| 20 | 0.916 | 0.815 | 0.901 | 0.879 |
| 30 | 0.927 | 0.819 | 0.877 | 0.852 |
Das Ergebnis scheint eindeutig: Trotz eines nur fünfminütigen Fine-Tuning-Prozesses sehen wir eine dramatische Verbesserung der Leistung auf dem Datensatz mit zufällig gemischten Sätzen:
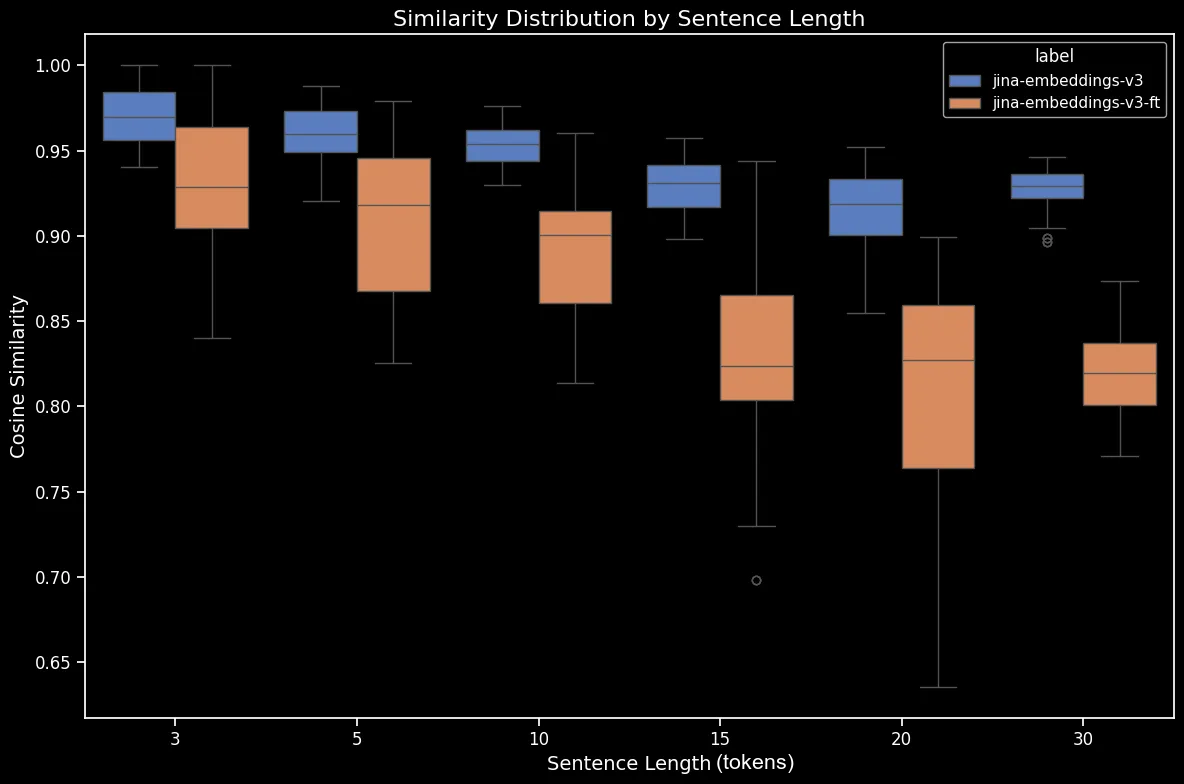
bge-base-en-1.5 (feinabgestimmt).Wir sehen auch Verbesserungen bei direktionalen, temporalen, kausalen und vergleichenden Fällen. Das Modell zeigt eine erhebliche Leistungsverbesserung, die sich in einem Rückgang der durchschnittlichen Cosinus-Ähnlichkeit widerspiegelt. Die größte Leistungssteigerung zeigt sich beim Negationsfall, da unser Fine-Tuning-Datensatz 10.000 Negationstrainingsbeispiele enthielt.
| Kategorie | Beispiel - Links | Beispiel - Rechts | Mittlere Cosinus-Ähnlichkeit (jina) |
Mittlere Cosinus-Ähnlichkeit (jina-ft) |
Mittlere Cosinus-Ähnlichkeit (bge) |
Mittlere Cosinus-Ähnlichkeit (bge-ft) |
|---|---|---|---|---|---|---|
| Direktional | She flew from Paris to Tokyo. | She drove from Tokyo to Paris | 0.9439 | 0.8650 | 0.9319 | 0.8674 |
| Temporal | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 | 0.9263 | 0.9683 | 0.9331 |
| Kausal | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 | 0.7937 | 0.8874 | 0.8371 |
| Vergleichend | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 | 0.8759 | 0.9723 | 0.9030 |
| Negation | He is standing by the table | He is standing far from the table | 0.9116 | 0.4478 | 0.8329 | 0.4329 |
tagFazit
In diesem Beitrag tauchen wir in die Herausforderungen ein, mit denen Text-Embedding-Modelle konfrontiert sind, insbesondere ihre Schwierigkeiten bei der effektiven Handhabung der Wortreihenfolge. Im Einzelnen haben wir fünf Hauptfehlertypen identifiziert: Direktional, Temporal, Kausal, Vergleichend und Negation. Dies sind die Arten von Abfragen, bei denen die Wortreihenfolge wirklich wichtig ist, und wenn Ihr Anwendungsfall eine dieser Kategorien beinhaltet, ist es wichtig, die Grenzen dieser Modelle zu kennen.
Wir haben auch ein schnelles Experiment durchgeführt, bei dem wir einen negationsfokussierten Datensatz um alle fünf Fehlerkategorien erweitert haben. Die Ergebnisse waren vielversprechend: Das Fine-Tuning mit sorgfältig ausgewählten "harten Negativbeispielen" verbesserte die Fähigkeit des Modells zu erkennen, welche Elemente zusammengehören und welche nicht. Allerdings gibt es noch mehr zu tun. Zukünftige Schritte beinhalten eine tiefergehende Untersuchung, wie sich die Größe und Qualität des Datensatzes auf die Leistung auswirken.
