


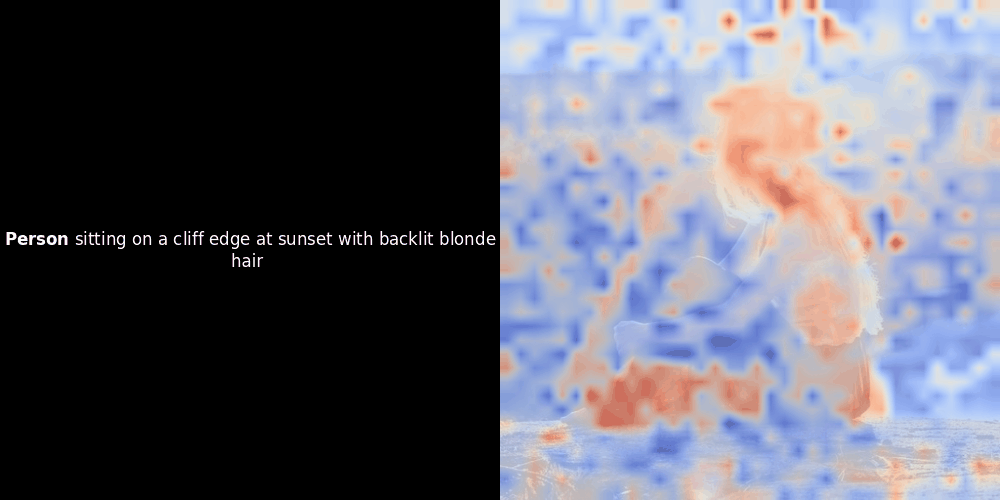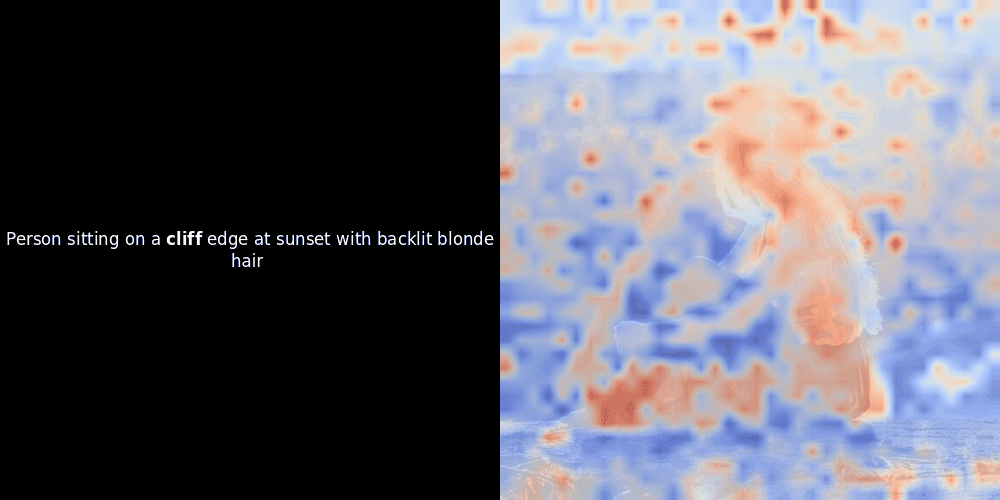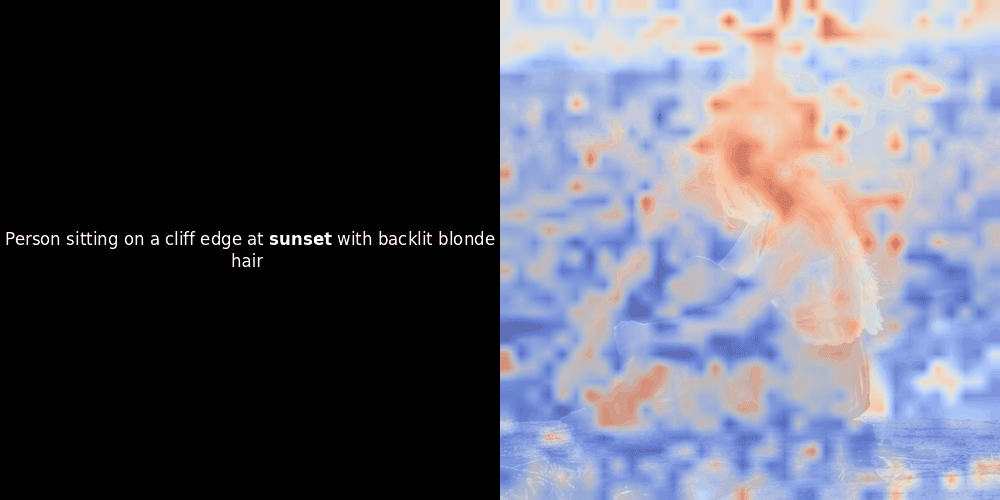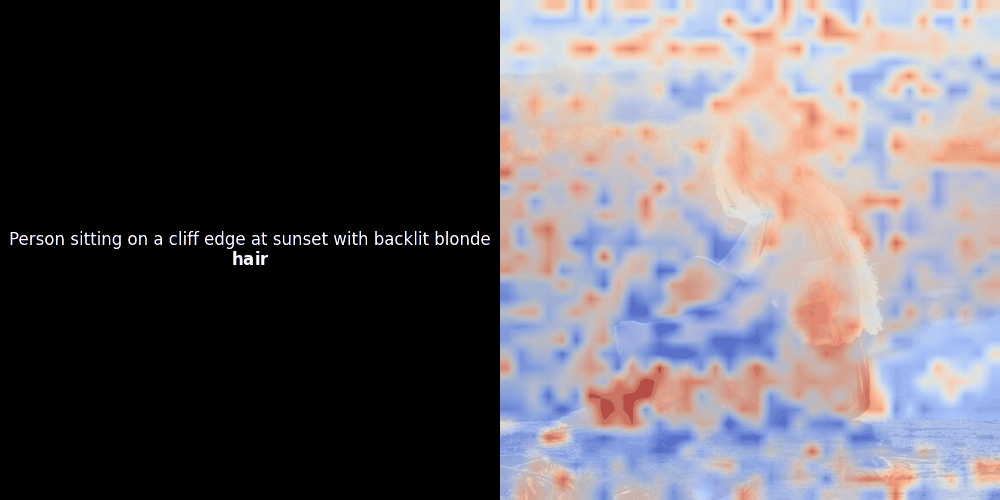
Bei Experimenten mit ColPali-style Modellen hat einer unserer Entwickler eine Visualisierung mit unserem kürzlich veröffentlichten jina-clip-v2 Modell erstellt. Er hat die Ähnlichkeit zwischen Token-Embeddings und Patch-Embeddings für bestimmte Bild-Text-Paare abgebildet und dabei Heatmap-Overlays erstellt, die einige interessante visuelle Erkenntnisse lieferten.

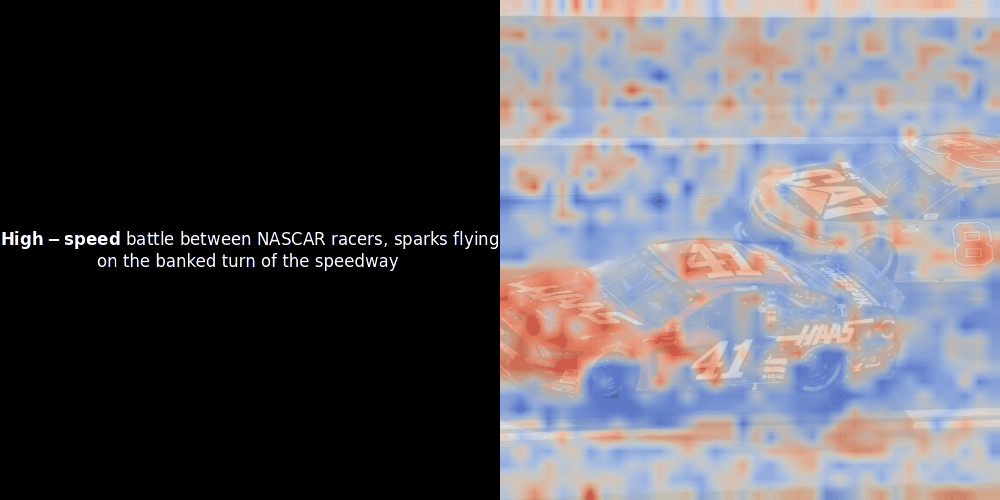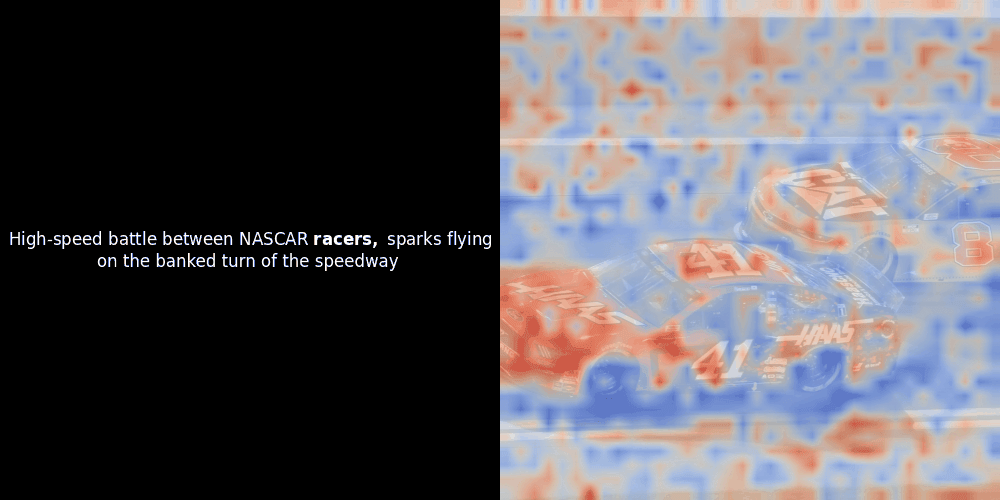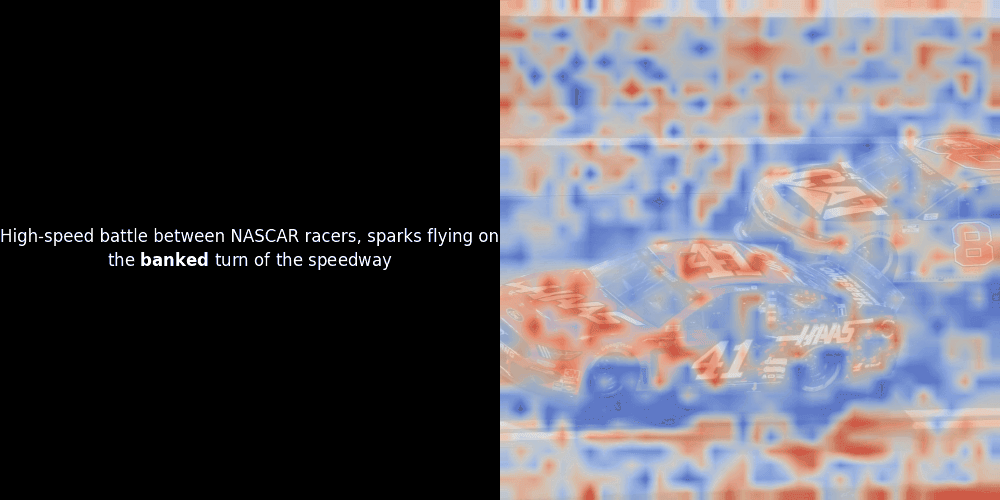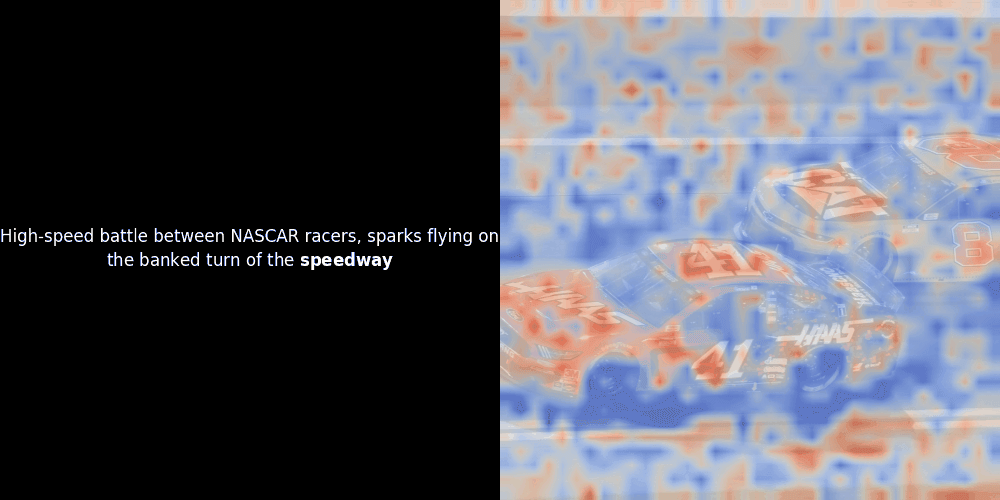
Leider ist dies nur eine heuristische Visualisierung - kein expliziter oder garantierter Mechanismus. Während CLIP-ähnliche globale kontrastive Ausrichtung zufällig grobe lokale Ausrichtungen zwischen Patches und Tokens erzeugen kann (und dies oft auch tut), ist dies ein unbeabsichtigter Nebeneffekt und kein bewusstes Ziel des Modells. Lassen Sie mich erklären warum.
tagDen Code verstehen

Lassen Sie uns auf hoher Ebene analysieren, was der Code macht. Beachten Sie, dass jina-clip-v2 standardmäßig keine API für den Zugriff auf Token-Level oder Patch-Level Embeddings bereitstellt - diese Visualisierung erforderte einige nachträgliche Anpassungen.
Word-Level Embeddings berechnen
Durch Setzen von model.text_model.output_tokens = True gibt text_model(x=...,)[1] ein zweites Element (batch_size, seq_len, embed_dim) für die Token-Embeddings zurück. Es nimmt also einen Eingabesatz, tokenisiert ihn mit dem Jina CLIP Tokenizer und gruppiert dann Subword-Tokens wieder zu "Wörtern", indem die entsprechenden Token-Embeddings gemittelt werden. Es erkennt den Beginn eines neuen Wortes durch Prüfung, ob der Token-String mit dem Zeichen _ beginnt (typisch für SentencePiece-basierte Tokenizer). Es erzeugt eine Liste von Word-Level Embeddings und eine Liste von Wörtern (sodass "Hund" ein Embedding ist, "und" ein Embedding ist, usw.).
Patch-Level Embeddings berechnen
Für den Image Tower gibt vision_model(..., return_all_features=True) (batch_size, n_patches+1, embed_dim) zurück, wobei das erste Token der [CLS] Token ist. Daraus extrahiert der Code die Embeddings für jeden Patch (d.h. die Patch-Tokens des Vision Transformers). Diese Patch-Embeddings werden dann in ein 2D-Gitter umgeformt, patch_side × patch_side, das dann auf die ursprüngliche Bildauflösung hochskaliert wird.
Word-Patch Ähnlichkeit visualisieren
Die Ähnlichkeitsberechnung und die anschließende Heatmap-Generierung sind Standard "Post-hoc" Interpretationstechniken: Man wählt ein Text-Embedding, berechnet die Kosinus-Ähnlichkeit mit jedem Patch-Embedding und generiert dann eine Heatmap, die zeigt, welche Patches die höchste Ähnlichkeit zu diesem spezifischen Token-Embedding haben. Schließlich durchläuft es jeden Token im Satz, hebt diesen Token links fett hervor und überlagert die ähnlichkeitsbasierte Heatmap rechts auf dem Originalbild. Alle Frames werden zu einem animierten GIF zusammengefügt.
tagIst es eine aussagekräftige Erklärbarkeit?
Vom reinen Code Standpunkt aus: ja, die Logik ist kohärent und wird eine Heatmap für jeden Token erzeugen. Sie erhalten eine Reihe von Frames, die Patch-Ähnlichkeiten hervorheben, der Code "macht also, was draufsteht".
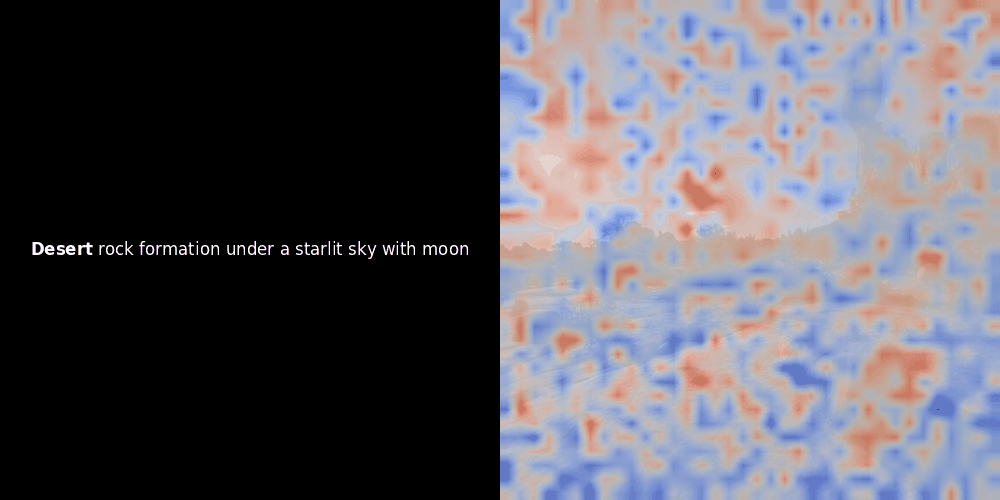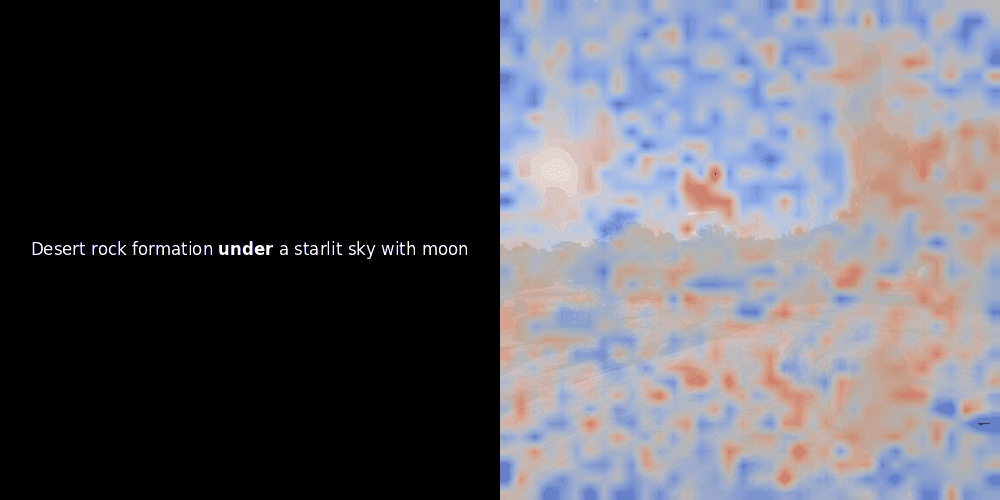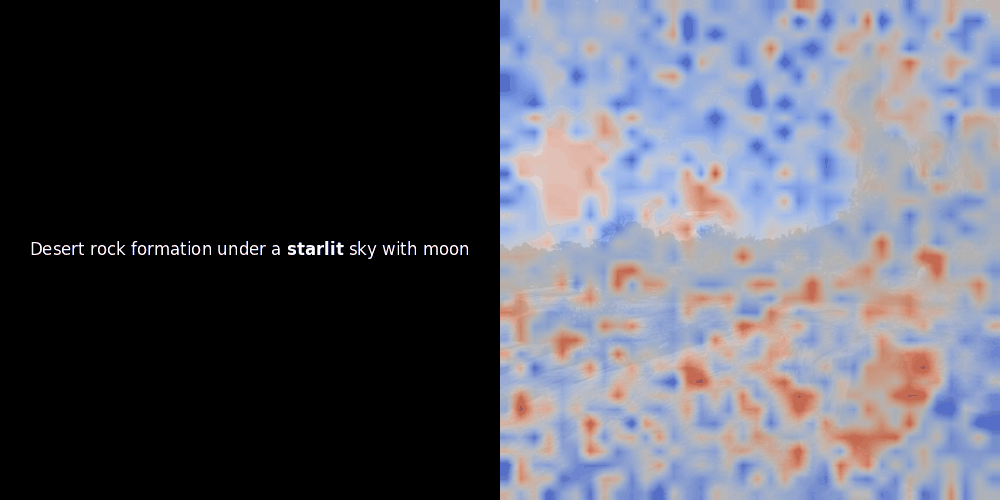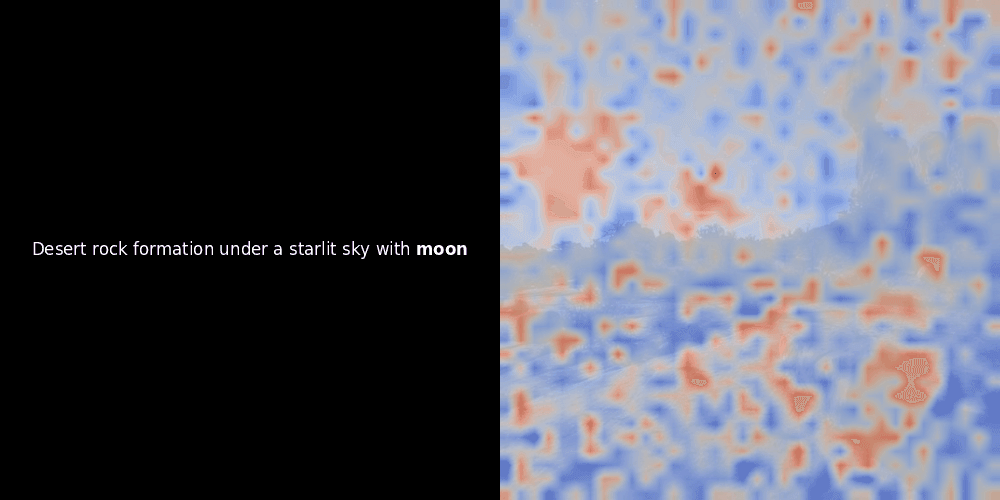

Wenn wir uns die obigen Beispiele ansehen, stellen wir fest, dass Wörter wie moon und branches gut mit ihren entsprechenden visuellen Patches im Originalbild übereinzustimmen scheinen. Aber hier ist die entscheidende Frage: Ist dies eine bedeutungsvolle Ausrichtung oder sehen wir nur einen glücklichen Zufall?
Dies ist eine tiefergehende Frage. Um die Einschränkungen zu verstehen, erinnern wir uns daran, wie CLIP trainiert wird:

- CLIP verwendet eine globale kontrastive Ausrichtung zwischen einem gesamten Bild und einem gesamten Text. Während des Trainings erzeugt der Bildencoder einen einzelnen Vektor (gepoolte Repräsentation) und der Textencoder einen weiteren einzelnen Vektor; CLIP wird so trainiert, dass diese für übereinstimmende Text-Bild-Paare übereinstimmen und andernfalls nicht übereinstimmen.
- Es gibt keine explizite Überwachung auf der Ebene 'Patch X entspricht Token Y'. Das Modell wird nicht direkt darauf trainiert hervorzuheben "dieser Bereich des Bildes ist der Hund, dieser Bereich ist die Katze" usw. Stattdessen wird ihm beigebracht, dass die gesamte Bildrepräsentation mit der gesamten Textrepräsentation übereinstimmen sollte.
- Da CLIPs Architektur auf der Bildseite ein Vision Transformer und auf der Textseite ein Text-Transformer ist - die beide separate Encoder bilden - gibt es kein Cross-Attention-Modul, das nativ Patches an Tokens ausrichtet. Stattdessen erhält man reine Self-Attention in jedem Tower plus eine finale Projektion für die globalen Bild- oder Text-Embeddings.
Kurz gesagt, dies ist eine heuristische Visualisierung. Die Tatsache, dass ein bestimmtes Patch-Embedding einem bestimmten Token-Embedding nahe oder fern sein könnte, ist gewissermaßen emergent. Es ist eher ein Post-hoc Interpretationstrick als eine robuste oder offizielle "Attention" des Modells.
tagWarum könnte lokale Ausrichtung entstehen?
Warum könnten wir manchmal Wort-Patch-Level lokale Ausrichtungen erkennen? Hier ist der Punkt: Obwohl CLIP auf einem globalen Bild-Text kontrastiven Ziel trainiert wird, verwendet es dennoch Self-Attention (in ViT-basierten Bildencodern) und Transformer-Layer (für Text). Innerhalb dieser Self-Attention-Layer können verschiedene Teile von Bildrepräsentationen miteinander interagieren, genau wie Wörter in Textrepräsentationen. Durch das Training auf massiven Bild-Text-Datensätzen entwickelt das Modell natürlich interne latente Strukturen, die ihm helfen, Gesamtbilder ihren entsprechenden Textbeschreibungen zuzuordnen.

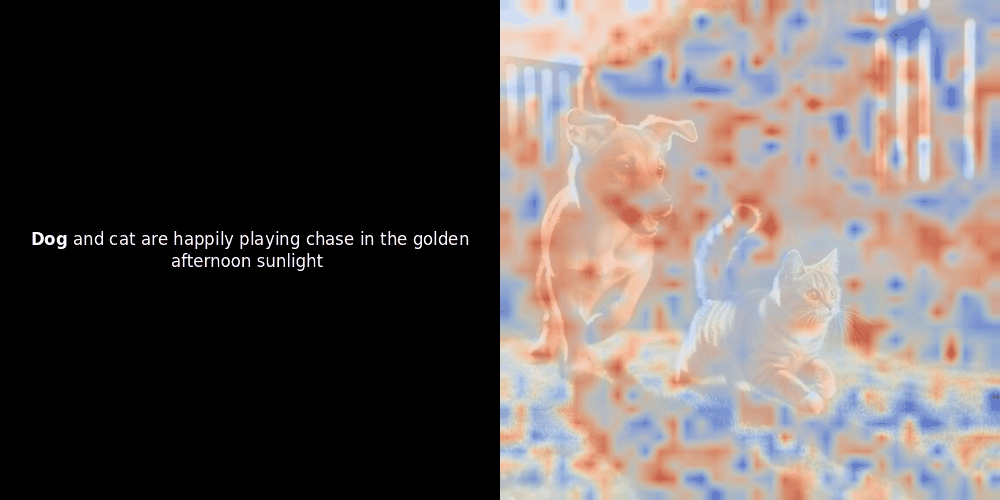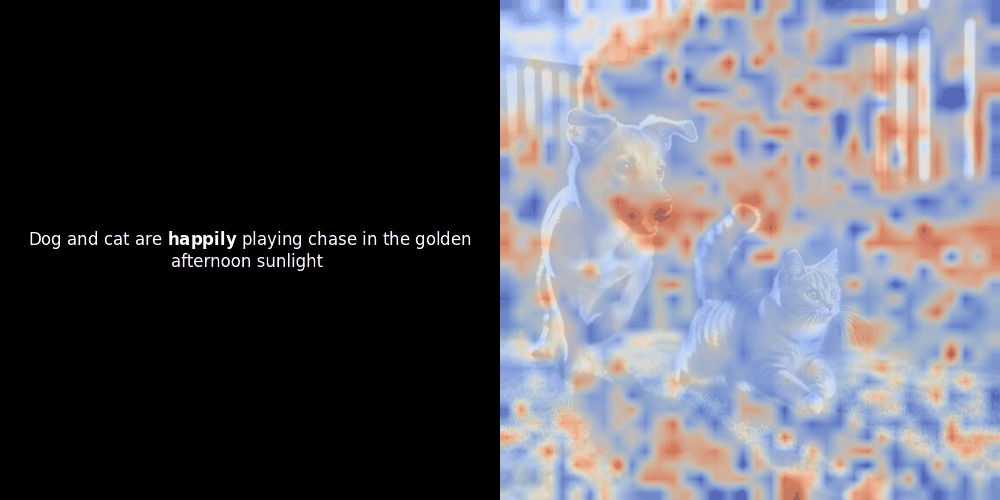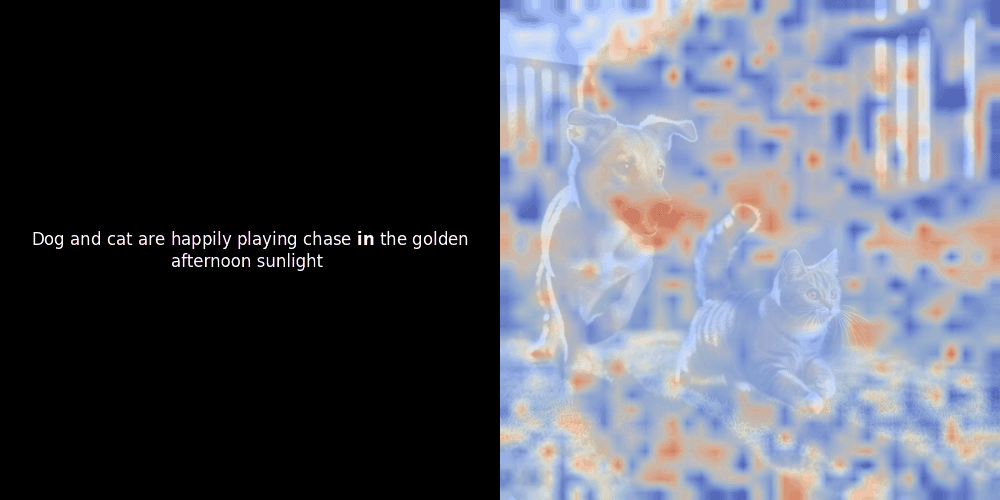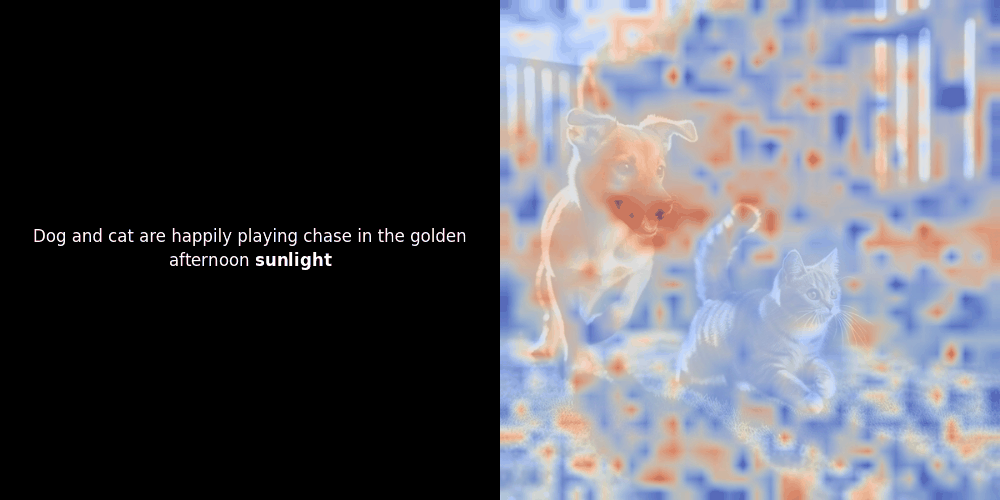
Lokale Ausrichtung kann in diesen latenten Repräsentationen aus mindestens zwei Gründen auftreten:
- Co-Occurrence Muster: Wenn ein Modell viele Bilder von "Hunden" neben vielen Bildern von "Katzen" sieht (oft mit diesen Wörtern beschriftet oder beschrieben), kann es latente Features lernen, die ungefähr diesen Konzepten entsprechen. So könnte das Embedding für "Hund" nahe an lokalen Patches liegen, die eine hundeähnliche Form oder Textur zeigen. Dies wird nicht explizit auf Patch-Ebene überwacht, sondern entsteht aus der wiederholten Assoziation zwischen Hunde-Bild/Text-Paaren.
- Self-Attention: In Vision Transformers beachten die Patches einander. Markante Patches (wie ein Hundegesicht) können eine konsistente latente "Signatur" entwickeln, da das Modell versucht, eine einzige global akkurate Repräsentation der gesamten Szene zu erzeugen. Wenn dies hilft, den gesamten kontrastiven Verlust zu minimieren, wird es verstärkt.
tagTheoretische Analyse
CLIPs kontrastives Lernziel strebt an, die Kosinus-Ähnlichkeit zwischen passenden Bild-Text-Paaren zu maximieren und gleichzeitig für nicht passende Paare zu minimieren. Angenommen, die Text- und Bild-Encoder erzeugen Token- und Patch-Embeddings:
Globale Ähnlichkeit kann als Aggregat lokaler Ähnlichkeiten dargestellt werden:
Wenn bestimmte Token-Patch-Paare häufig in den Trainingsdaten gemeinsam auftreten, verstärkt das Modell ihre Ähnlichkeit durch kumulative Gradienten-Updates:
, wobei die Anzahl der gemeinsamen Auftreten ist. Dies führt dazu, dass signifikant zunimmt und eine stärkere lokale Ausrichtung für diese Paare fördert. Der kontrastive Verlust verteilt jedoch Gradienten-Updates über alle Token-Patch-Paare, was die Stärke der Updates für einzelne Paare begrenzt:
Dies verhindert eine signifikante Verstärkung einzelner Token-Patch-Ähnlichkeiten.
tagFazit
CLIPs Token-Patch-Visualisierungen nutzen eine beiläufige, emergente Ausrichtung zwischen Text- und Bildrepräsentationen. Diese Ausrichtung ist zwar interessant, stammt aber aus CLIPs globalem kontrastiven Training und verfügt nicht über die strukturelle Robustheit, die für präzise und zuverlässige Erklärbarkeit erforderlich ist. Die resultierenden Visualisierungen zeigen oft Rauschen und Inkonsistenz, was ihren Nutzen für tiefgehende interpretative Anwendungen einschränkt.

Late Interaction Modelle wie ColBERT und ColPali adressieren diese Einschränkungen, indem sie architektonisch explizite, feingranulare Ausrichtungen zwischen Text-Tokens und Bild-Patches einbetten. Indem sie Modalitäten unabhängig verarbeiten und gezielte Ähnlichkeitsberechnungen in einer späteren Phase durchführen, stellen diese Modelle sicher, dass jedes Text-Token bedeutungsvoll mit relevanten Bildregionen assoziiert wird.
