



Semantische Embeddings sind der Kern moderner KI-Modelle, selbst bei Chatbots und KI-Kunstmodellen. Sie sind für Benutzer manchmal verborgen, aber sie sind trotzdem da, direkt unter der Oberfläche.
Die Theorie der Embeddings hat nur zwei Teile:
- Dinge — Dinge außerhalb eines KI-Modells, wie Texte und Bilder — werden durch Vektoren repräsentiert, die von KI-Modellen aus Daten über diese Dinge erstellt werden.
- Beziehungen zwischen Dingen außerhalb eines KI-Modells werden durch räumliche Beziehungen zwischen diesen Vektoren dargestellt. Wir trainieren KI-Modelle speziell darauf, Vektoren zu erstellen, die auf diese Weise funktionieren.
Wenn wir ein multimodales Bild-Text-Modell erstellen, trainieren wir das Modell so, dass Embeddings von Bildern und Embeddings von Texten, die diese Bilder beschreiben oder sich darauf beziehen, relativ nahe beieinander liegen. Die semantischen Ähnlichkeiten zwischen den Dingen, die diese beiden Vektoren repräsentieren — ein Bild und ein Text — spiegeln sich in der räumlichen Beziehung zwischen den beiden Vektoren wider.
Zum Beispiel könnten wir vernünftigerweise erwarten, dass die Embedding-Vektoren für ein Bild einer Orange und der Text "eine frische Orange" näher beieinander liegen als dasselbe Bild und der Text "ein frischer Apfel."
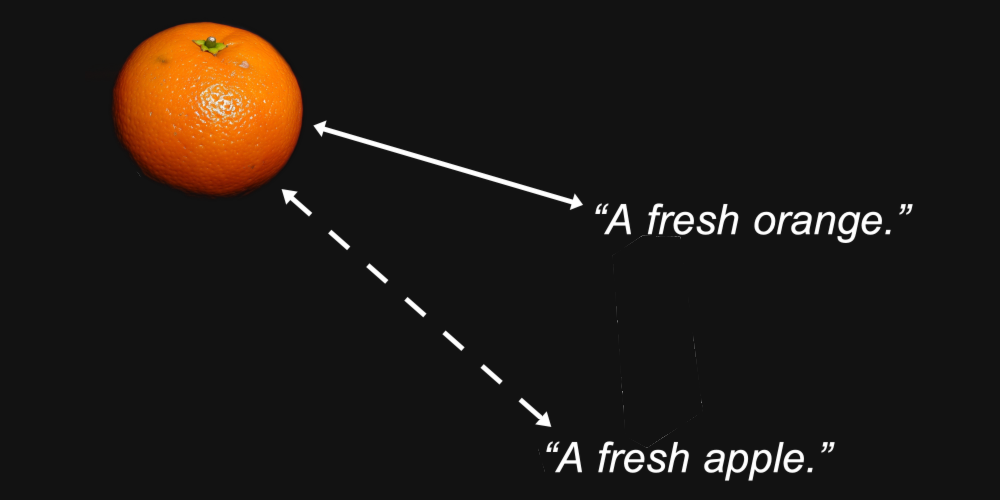
Das ist der Zweck eines Embedding-Modells: Repräsentationen zu generieren, bei denen die Eigenschaften, die uns interessieren — wie die Art der Frucht, die in einem Bild dargestellt oder in einem Text genannt wird — in der Distanz zwischen ihnen erhalten bleiben.
Aber Multimodalität bringt noch etwas anderes mit sich. Wir könnten feststellen, dass ein Bild einer Orange näher an einem Bild eines Apfels liegt als am Text "eine frische Orange", und dass der Text "ein frischer Apfel" näher an einem anderen Text liegt als an einem Bild eines Apfels.
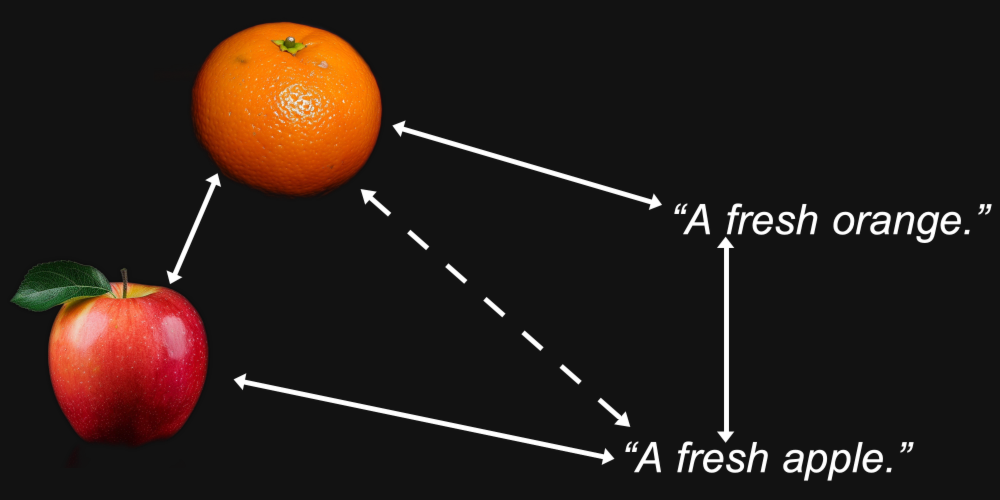
Es stellt sich heraus, dass genau dies bei multimodalen Modellen passiert, einschließlich Jina AIs eigenem Jina CLIP Modell (jina-clip-v1).
Um dies zu testen, haben wir 1.000 Text-Bild-Paare aus dem Flickr8k Testset ausgewählt. Jedes Paar enthält fünf Bildunterschriften (also technisch gesehen kein Paar) und ein einzelnes Bild, wobei alle fünf Texte dasselbe Bild beschreiben.
Zum Beispiel das folgende Bild (1245022983_fb329886dd.jpg im Flickr8k Dataset):

Seine fünf Bildunterschriften:
A child in all pink is posing nearby a stroller with buildings in the distance.
A little girl in pink dances with her hands on her hips.
A small girl wearing pink dances on the sidewalk.
The girl in a bright pink skirt dances near a stroller.
The little girl in pink has her hands on her hips.
Wir haben Jina CLIP verwendet, um die Bilder und Texte einzubetten und dann:
- Die Kosinus-Ähnlichkeiten der Bild-Embeddings mit den Embeddings ihrer Bildunterschriften verglichen.
- Die Embeddings aller fünf Bildunterschriften, die dasselbe Bild beschreiben, genommen und ihre Kosinus-Ähnlichkeiten untereinander verglichen.
Das Ergebnis ist eine überraschend große Lücke, sichtbar in Abbildung 1:
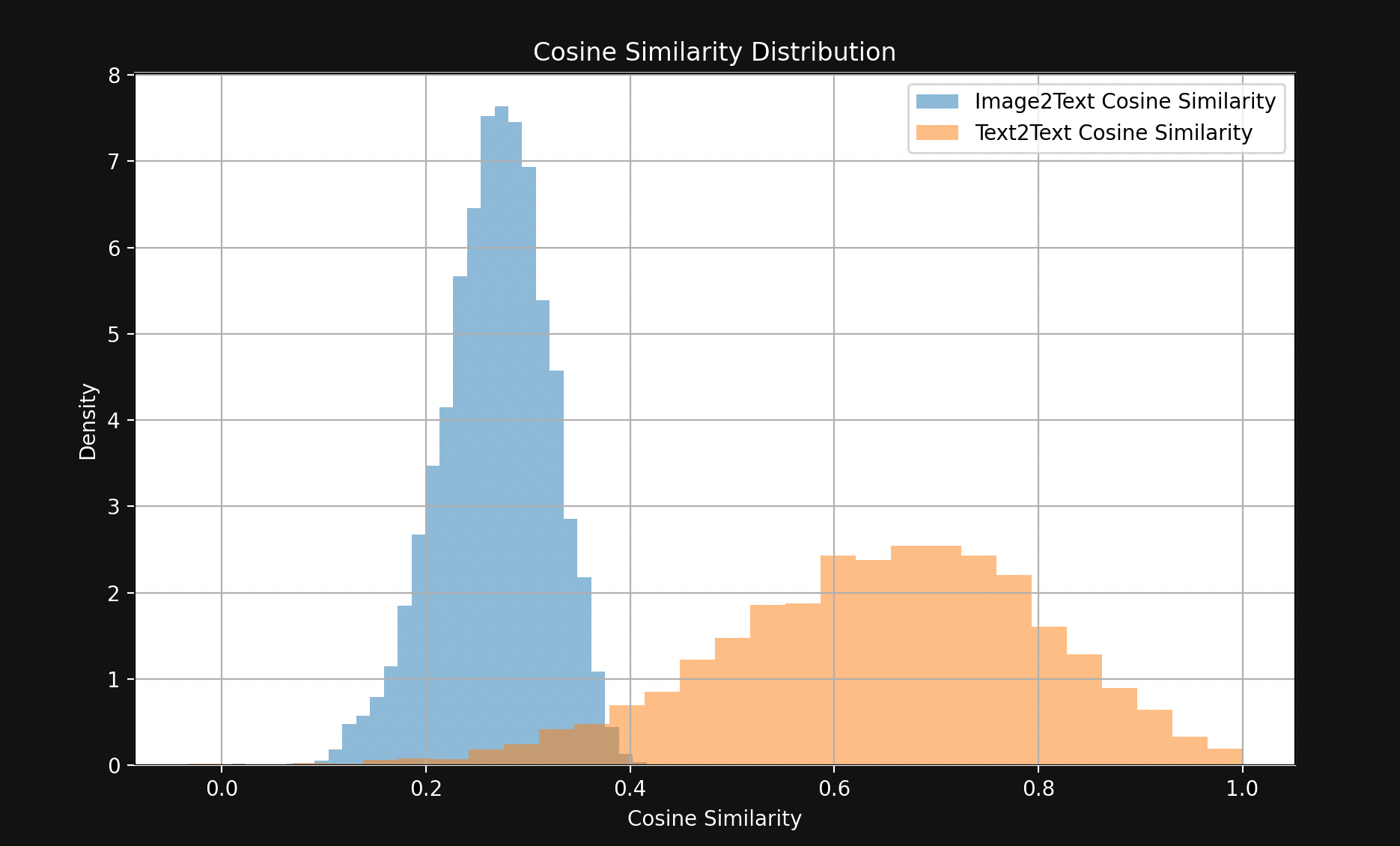
Mit wenigen Ausnahmen liegen passende Textpaare viel näher beieinander als passende Bild-Text-Paare. Dies deutet stark darauf hin, dass Jina CLIP Texte in einem Teil des Embedding-Raums und Bilder in einem weitgehend getrennten Teil relativ weit davon entfernt kodiert. Dieser Raum zwischen den Texten und den Bildern ist die multimodale Lücke.

Multimodale Embedding-Modelle kodieren mehr als nur die semantischen Informationen, die uns interessieren: Sie kodieren das Medium ihrer Eingabe. Laut Jina CLIP ist ein Bild nicht, wie es im Sprichwort heißt, tausend Worte wert. Es hat Inhalte, die keine noch so große Anzahl von Worten jemals wirklich gleichwertig ausdrücken kann. Es kodiert das Eingabemedium in die Semantik seiner Embeddings, ohne dass es jemals darauf trainiert wurde.
Dieses Phänomen wurde in der Arbeit Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning [Liang et al., 2022] untersucht, die es als "Modalitätslücke" bezeichnet. Die Modalitätslücke ist die räumliche Trennung im Embedding-Raum zwischen Eingaben in einem Medium und Eingaben in einem anderen. Obwohl Modelle nicht absichtlich darauf trainiert werden, eine solche Lücke zu haben, sind sie in multimodalen Modellen allgegenwärtig.
Unsere Untersuchungen zur Modalitätslücke in Jina CLIP basieren stark auf Liang et al. [2022].
tagWoher kommt die Modalitätslücke?
Liang et al. [2022] identifizieren drei Hauptquellen für die Modalitätslücke:
- Eine Initialisierungsverzerrung, die sie als "Kegel-Effekt" bezeichnen.
- Reduzierungen der Temperatur (Zufälligkeit) während des Trainings, die es sehr schwer machen, diese Verzerrung zu "verlernen".
- Kontrastive Lernverfahren, die in multimodalen Modellen weit verbreitet sind und unbeabsichtigt die Lücke verstärken.
Wir werden uns jeden dieser Punkte der Reihe nach ansehen.
tagKegel-Effekt
Ein Modell mit einer CLIP- oder CLIP-ähnlichen Architektur besteht eigentlich aus zwei separaten Embedding-Modellen, die miteinander verbunden sind. Bei multimodalen Bild-Text-Modellen bedeutet dies ein Modell für die Codierung von Texten und ein völlig separates für die Codierung von Bildern, wie im folgenden Schema dargestellt.
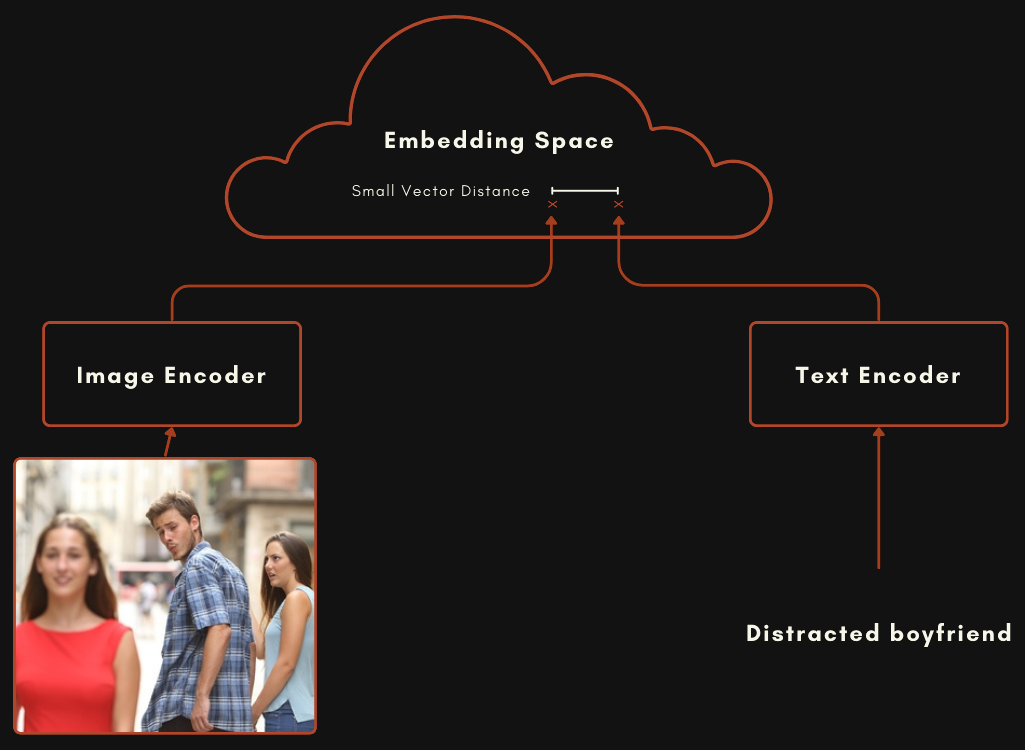
Diese beiden Modelle werden so trainiert, dass ein Bild-Embedding und ein Text-Embedding relativ nahe beieinander liegen, wenn der Text das Bild gut beschreibt.
Man kann ein solches Modell trainieren, indem man die Gewichtungen in beiden Modellen zufällig verteilt und dann Bild-Text-Paare gemeinsam präsentiert, wobei das Training von Grund auf darauf abzielt, die Distanz zwischen den beiden Outputs zu minimieren. Das ursprüngliche OpenAI CLIP-Modell wurde auf diese Weise trainiert. Dies erfordert jedoch viele Bild-Text-Paare und ein rechenintensives Training. Für das erste CLIP-Modell hat OpenAI 400 Millionen Bild-Text-Paare aus beschriftetem Material im Internet extrahiert.
Neuere CLIP-ähnliche Modelle verwenden vortrainierte Komponenten. Das bedeutet, dass jede Komponente separat als gutes Single-Mode-Embedding-Modell trainiert wird, eines für Texte und eines für Bilder. Diese beiden Modelle werden dann gemeinsam mit Bild-Text-Paaren weiter trainiert, ein Prozess, der als Contrastive Tuning bezeichnet wird. Aufeinander abgestimmte Bild-Text-Paare werden verwendet, um die Gewichtungen langsam so zu „verschieben", dass übereinstimmende Text- und Bild-Embeddings näher zusammenrücken und nicht übereinstimmende weiter auseinander.
Dieser Ansatz erfordert im Allgemeinen weniger Bild-Text-Paar-Daten, die schwierig und kostspielig zu beschaffen sind, und große Mengen an reinen Texten und Bildern ohne Beschriftungen, die viel einfacher zu beschaffen sind. Jina CLIP (jina-clip-v1) wurde mit dieser letzteren Methode trainiert. Wir haben ein JinaBERT v2 Modell für die Textcodierung mit allgemeinen Textdaten vortrainiert und einen vortrainierten EVA-02 Image Encoder verwendet, und diese dann mit verschiedenen kontrastiven Trainingstechniken weiter trainiert, wie in Koukounas et al. [2024] beschrieben
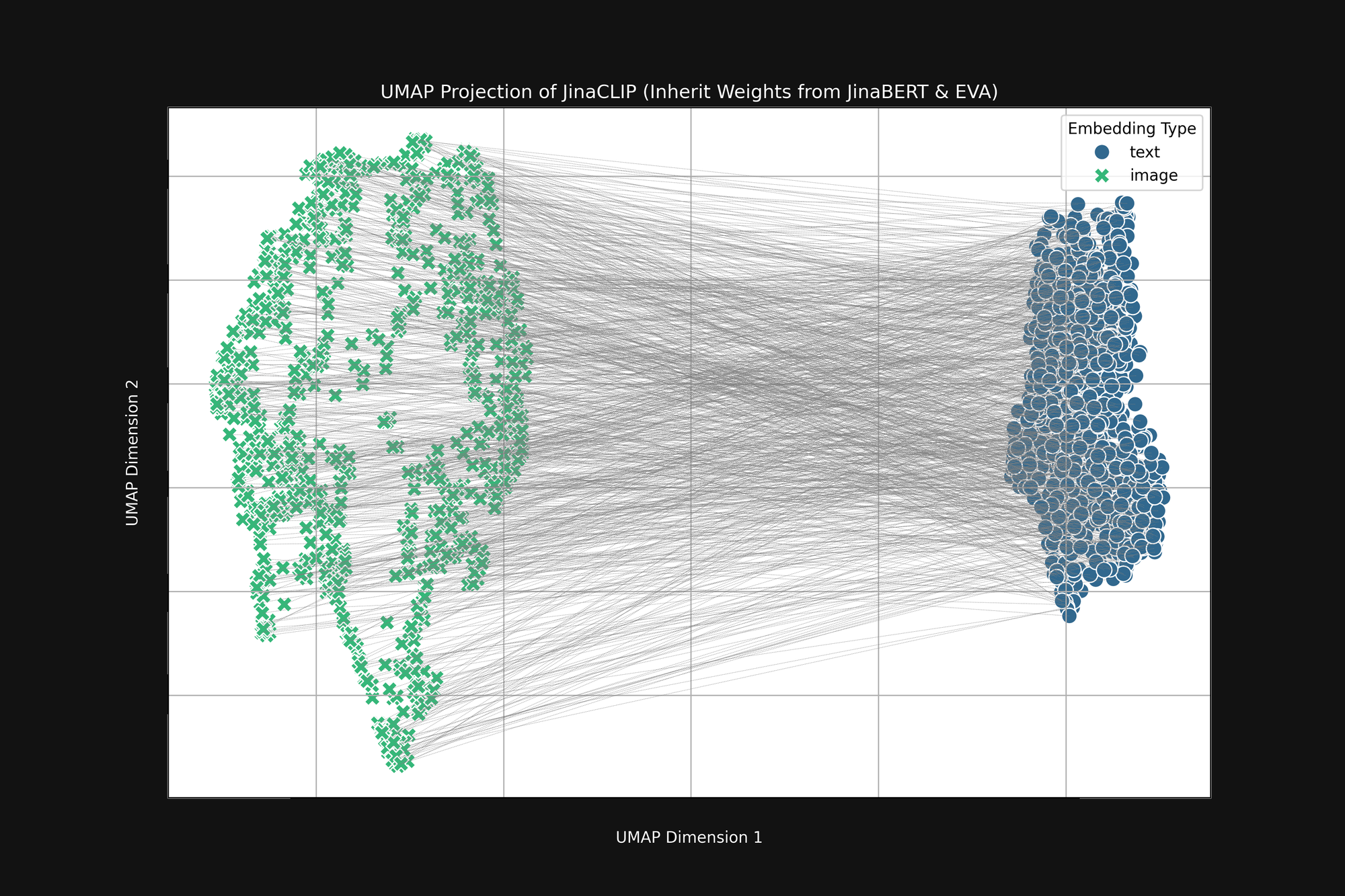
Wenn wir diese beiden vortrainierten Modelle nehmen und ihre Ausgabe betrachten, bevor wir sie mit Bild-Text-Paaren trainieren, fällt uns etwas Wichtiges auf. Abbildung 2 (oben) ist eine UMAP-Projektion in zwei Dimensionen der Bild-Embeddings, die vom vortrainierten EVA-02 Encoder erzeugt wurden, und der Text-Embeddings, die vom vortrainierten JinaBERT v2 erzeugt wurden, wobei die grauen Linien übereinstimmende Bild-Text-Paare anzeigen. Dies ist vor jeglichem modalitätsübergreifenden Training.
Das Ergebnis ist eine Art abgeschnittener „Kegel", mit Bild-Embeddings an einem Ende und Text-Embeddings am anderen. Diese Kegelform lässt sich nur schlecht in zweidimensionale Projektionen übersetzen, aber Sie können sie im Bild oben grob erkennen. Alle Texte clustern sich in einem Teil des Embedding-Raums und alle Bilder in einem anderen Teil. Wenn nach dem Training Texte immer noch ähnlicher zu anderen Texten sind als zu passenden Bildern, ist dieser Anfangszustand ein wichtiger Grund dafür. Das Ziel der besten Übereinstimmung von Bildern mit Texten, Texten mit Texten und Bildern mit Bildern ist vollständig kompatibel mit dieser Kegelform.
Das Modell ist von Geburt an voreingenommen und was es lernt, ändert daran nichts. Abbildung 3 (unten) zeigt die gleiche Analyse des Jina CLIP-Modells nach der Veröffentlichung, nach vollständigem Training mit Bild-Text-Paaren. Die multimodale Lücke ist sogar noch ausgeprägter.
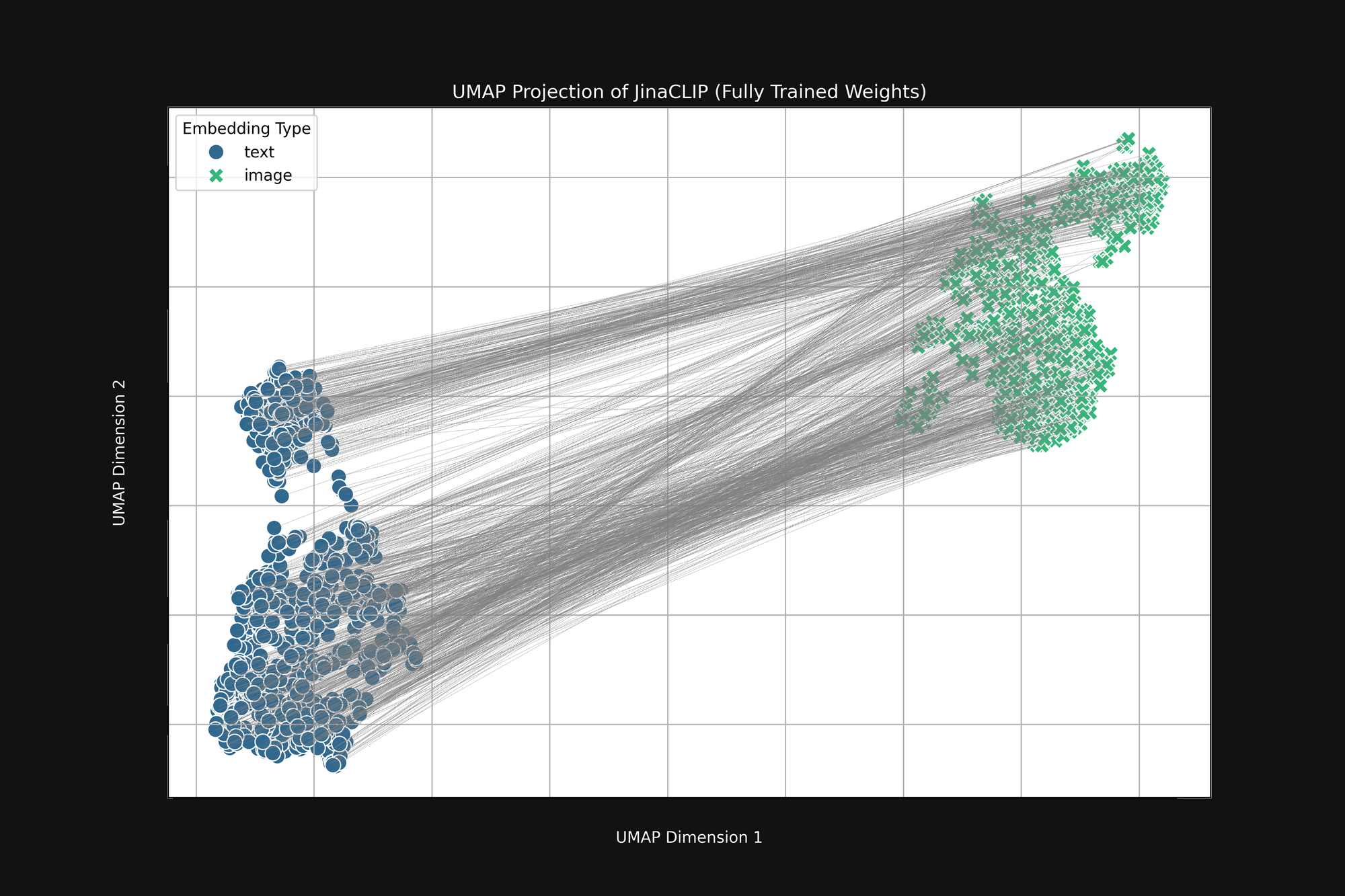
Auch nach umfangreichem Training codiert Jina CLIP das Medium immer noch als Teil der Nachricht.
Der aufwändigere OpenAI-Ansatz mit rein zufälliger Initialisierung beseitigt diese Voreingenommenheit nicht. Wir haben die ursprüngliche OpenAI CLIP-Architektur genommen und alle Gewichte vollständig randomisiert, dann die gleiche Analyse wie oben durchgeführt. Das Ergebnis ist immer noch eine abgeschnittene Kegelform, wie in Abbildung 4 zu sehen:
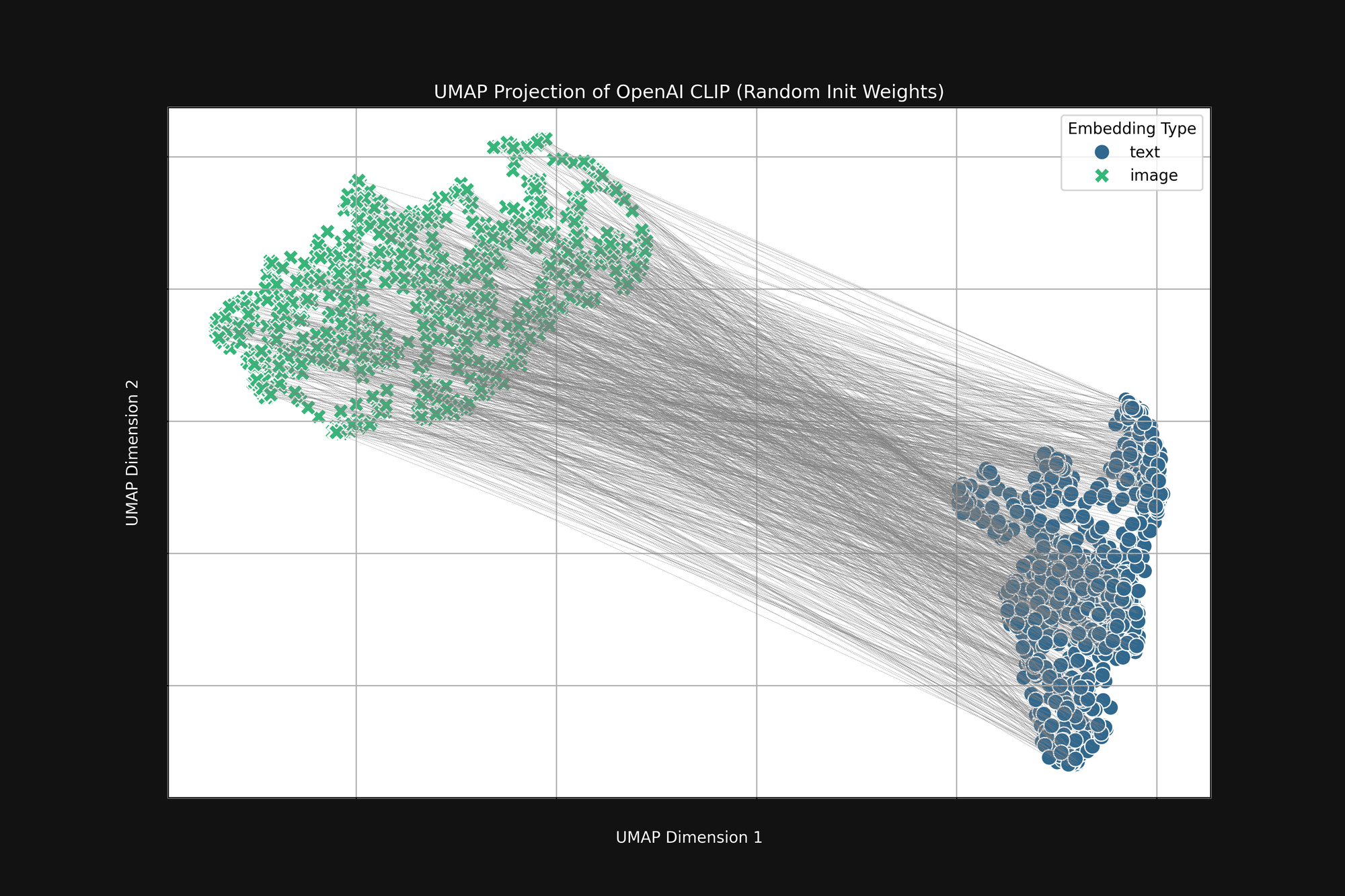
Diese Voreingenommenheit ist ein strukturelles Problem und hat möglicherweise keine Lösung. Wenn dem so ist, können wir nur nach Wegen suchen, sie während des Trainings zu korrigieren oder abzumildern.
tagTraining Temperature
Während des AI-Modell-Trainings fügen wir typischerweise etwas Zufälligkeit zum Prozess hinzu. Wir berechnen, wie stark ein Batch von Trainingsbeispielen die Gewichte im Modell verändern sollte, und fügen dann einen kleinen Zufallsfaktor zu diesen Änderungen hinzu, bevor wir die Gewichte tatsächlich ändern. Wir nennen den Grad der Zufälligkeit die Temperatur, in Analogie zur Art und Weise, wie wir Zufälligkeit in der Thermodynamik verwenden.
Hohe Temperaturen erzeugen sehr schnell große Veränderungen in Modellen, während niedrige Temperaturen die Möglichkeit eines Modells reduzieren, sich bei jedem Trainingsbeispiel zu verändern. Das Ergebnis ist, dass sich bei hohen Temperaturen einzelne Embeddings während des Trainings stark im Embedding-Raum bewegen können, während sie sich bei niedrigen Temperaturen viel langsamer bewegen.
Die beste Praxis beim Training von KI-Modellen ist, mit einer hohen Temperatur zu beginnen und diese dann progressiv zu senken. Dies hilft dem Modell, am Anfang große Lernsprünge zu machen, wenn die Gewichte entweder zufällig oder weit von ihrem Ziel entfernt sind, und lässt es dann die Details stabiler lernen.
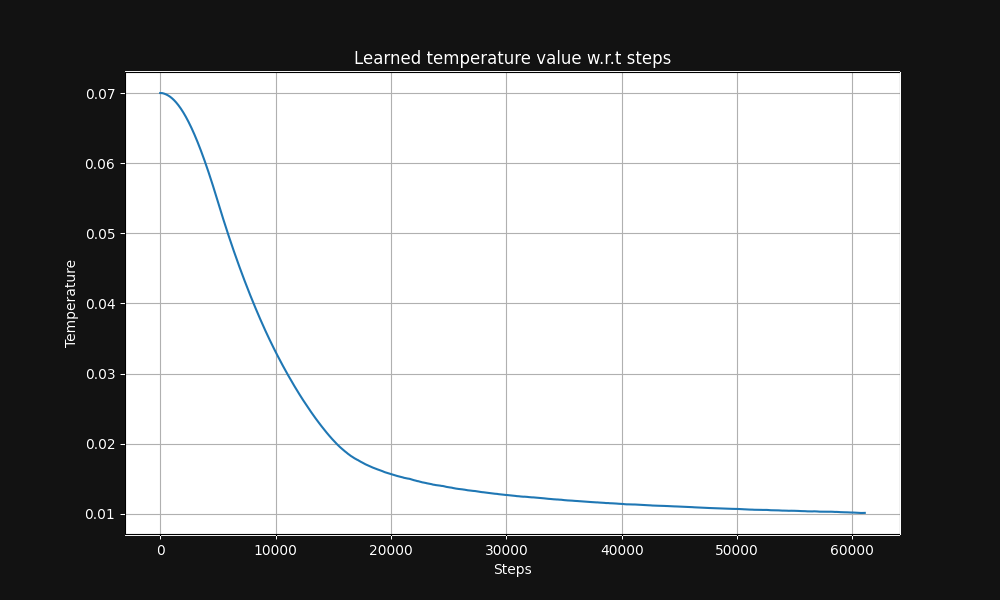
Das Jina CLIP Bild-Text-Paar-Training beginnt mit einer Temperatur von 0,07 (dies ist eine relativ hohe Temperatur) und senkt sie exponentiell im Verlauf des Trainings auf 0,01, wie in Abbildung 5 unten gezeigt, einer Grafik der Temperatur versus Trainingsschritte:
Wir wollten wissen, ob eine Erhöhung der Temperatur – das Hinzufügen von Zufälligkeit – den Kegeleffekt reduzieren und die Bild-Embeddings und Text-Embeddings insgesamt näher zusammenbringen würde. Also trainierten wir Jina CLIP mit einer festen Temperatur von 0,1 (ein sehr hoher Wert) neu. Nach jeder Trainingsepoche überprüften wir die Verteilung der Abstände zwischen Bild-Text-Paaren und Text-Text-Paaren, genau wie in Abbildung 1. Die Ergebnisse sind unten in Abbildung 6 dargestellt:
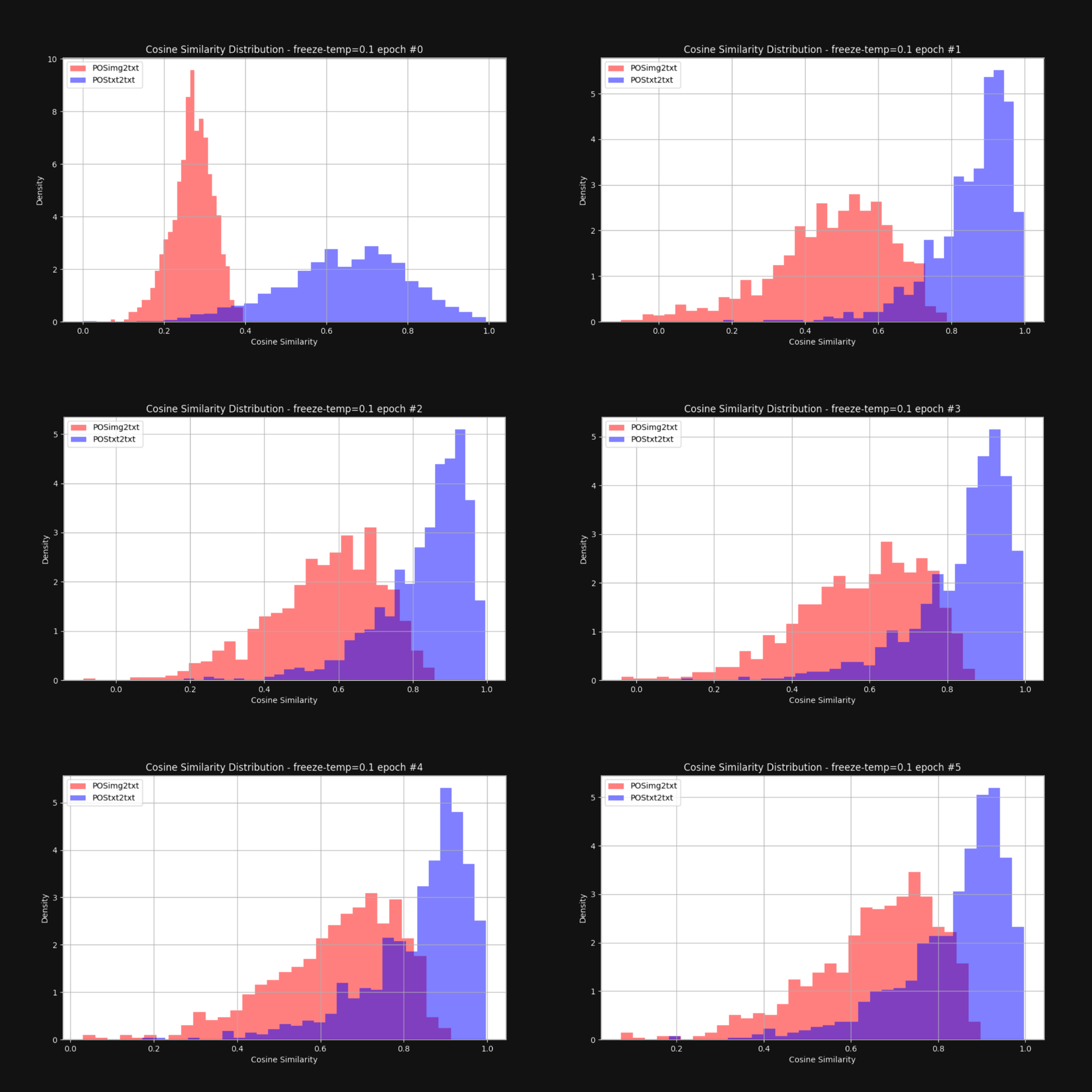
Wie Sie sehen können, schließt eine hohe Temperatur die multimodale Lücke dramatisch. Wenn man den Embeddings erlaubt, sich während des Trainings stark zu bewegen, hilft das erheblich dabei, die anfängliche Verzerrung in der Embedding-Verteilung zu überwinden.
Dies hat jedoch seinen Preis. Wir haben die Leistung des Modells mit sechs verschiedenen Retrieval-Tests geprüft: Drei Text-Text-Retrieval-Tests und drei Text-Bild-Retrieval-Tests aus den Datensätzen MS-COCO, Flickr8k und Flickr30k. In allen Tests sehen wir zu Beginn des Trainings einen starken Leistungsabfall und dann einen sehr langsamen Anstieg, wie in Abbildung 7 zu sehen ist:
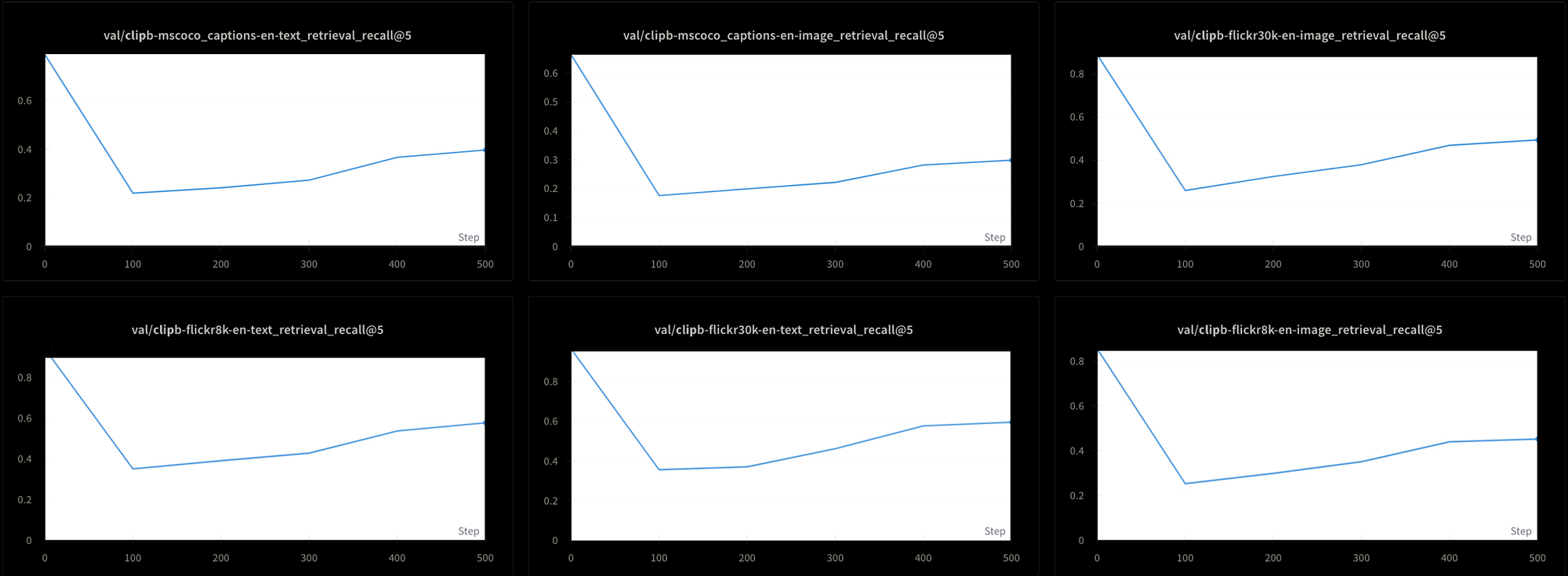
Es wäre wahrscheinlich extrem zeit- und kostenaufwendig, ein Modell wie Jina CLIP mit dieser konstant hohen Temperatur zu trainieren. Obwohl theoretisch machbar, ist dies keine praktische Lösung.
tagKontrastives Lernen und das False-Negative-Problem
Liang et al. [2022] entdeckten auch, dass Standard-Praktiken des kontrastiven Lernens – der Mechanismus, den wir zum Training von CLIP-artigen multimodalen Modellen verwenden – dazu neigen, die multimodale Lücke zu verstärken.
Kontrastives Lernen ist im Grunde ein einfaches Konzept. Wir haben ein Bild-Embedding und ein Text-Embedding, und wir wissen, dass sie näher zusammenliegen sollten, also passen wir die Gewichte im Modell während des Trainings entsprechend an. Wir gehen langsam vor, passen die Gewichte in kleinen Schritten an, und wir passen sie proportional dazu an, wie weit die beiden Embeddings voneinander entfernt sind: Je näher sie beieinanderliegen, desto kleiner ist die Änderung.
Diese Technik funktioniert viel besser, wenn wir die Embeddings nicht nur näher zusammenbringen, wenn sie übereinstimmen, sondern sie auch weiter auseinander bewegen, wenn sie nicht übereinstimmen. Wir wollen nicht nur Bild-Text-Paare haben, die zusammengehören, sondern auch Paare, von denen wir wissen, dass sie nicht zusammengehören.
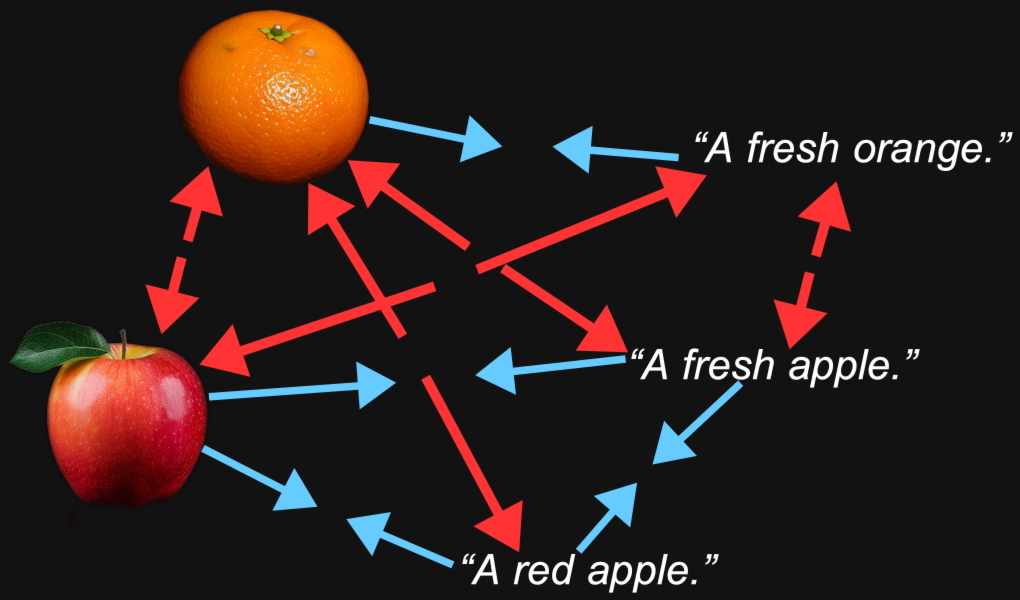
Dies wirft einige Probleme auf:
- Unsere Datenquellen bestehen ausschließlich aus übereinstimmenden Paaren. Niemand würde eine Datenbank mit Texten und Bildern erstellen, bei denen ein Mensch überprüft hat, dass sie nicht zusammengehören, noch könnte man eine solche durch Web-Scraping oder andere unüberwachte oder semi-überwachte Techniken erstellen.
- Selbst Bild-Text-Paare, die oberflächlich völlig unzusammenhängend erscheinen, sind es nicht unbedingt. Wir haben keine Semantiktheorie, die es uns erlaubt, solche negativen Urteile objektiv zu fällen. Zum Beispiel ist ein Bild einer Katze, die auf einer Veranda liegt, keine völlig negative Übereinstimmung für den Text "ein Mann, der auf einem Sofa schläft". Beide beinhalten das Liegen auf etwas.
Idealerweise würden wir mit Bild-Text-Paaren trainieren, von denen wir mit Sicherheit wissen, dass sie verwandt UND unverwandt sind, aber es gibt keine offensichtliche Möglichkeit, bekanntermaßen unverwandte Paare zu erhalten. Es ist möglich, Menschen zu fragen "Beschreibt dieser Satz dieses Bild?" und konsistente Antworten zu erwarten. Es ist viel schwieriger, konsistente Antworten zu bekommen, wenn man fragt "Hat dieser Satz nichts mit diesem Bild zu tun?"
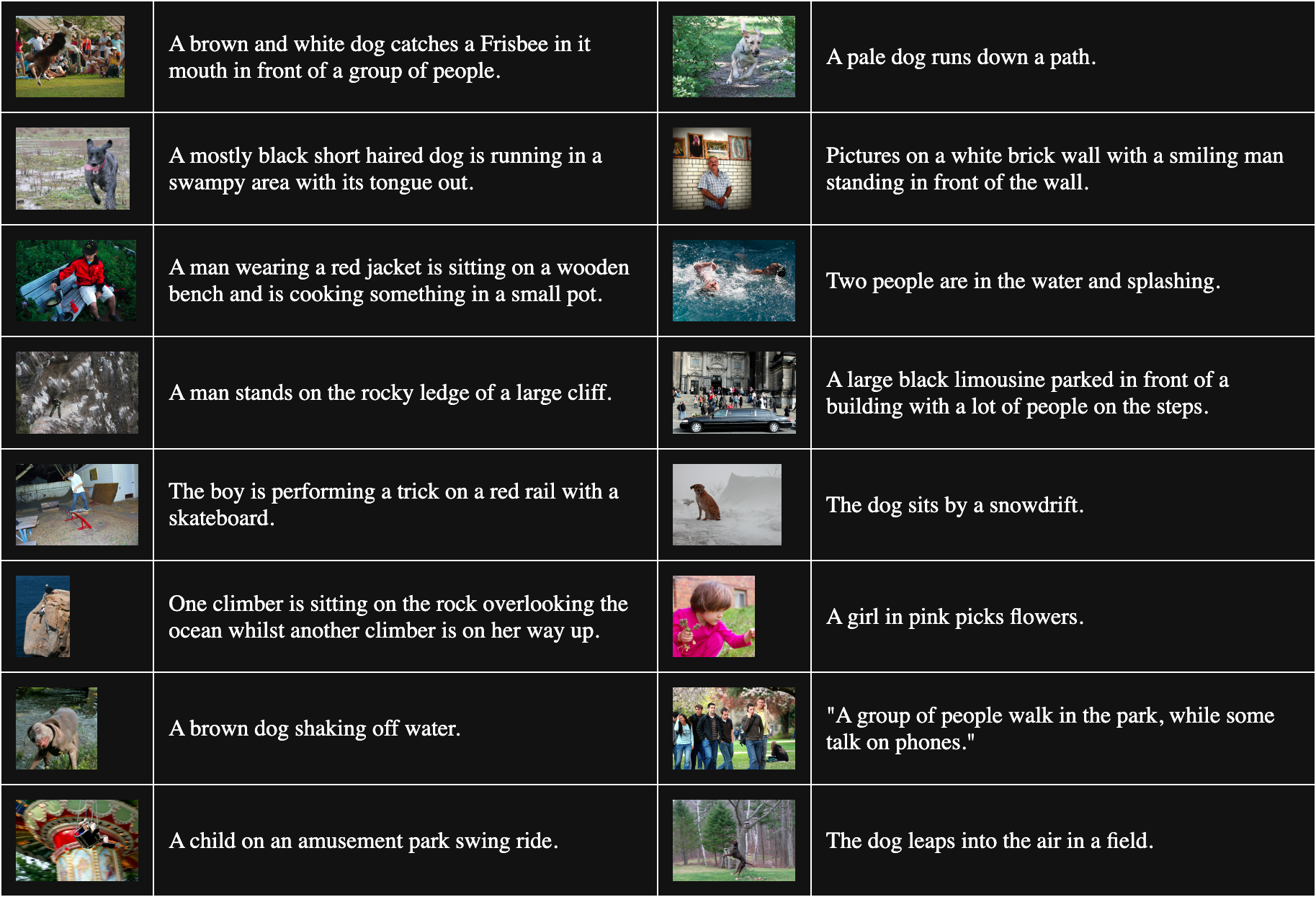
Stattdessen erhalten wir nicht zusammengehörende Bild-Text-Paare, indem wir zufällig Bilder und Texte aus unseren Trainingsdaten auswählen, in der Erwartung, dass sie praktisch nie gut zueinander passen. In der Praxis funktioniert das so, dass wir unsere Trainingsdaten in Batches aufteilen. Für das Training von Jina CLIP verwendeten wir Batches mit 32.000 übereinstimmenden Bild-Text-Paaren, aber für dieses Experiment waren die Batch-Größen nur 16.
Die folgende Tabelle zeigt 16 zufällig ausgewählte Bild-Text-Paare aus Flickr8k:
Um nicht übereinstimmende Paare zu erhalten, kombinieren wir jedes Bild im Batch mit jedem Text AUSSER dem, zu dem es passt. Zum Beispiel ist das folgende Paar ein nicht übereinstimmendes Bild und Text:

Beschriftung: Ein Mädchen in Rosa pflückt Blumen.
Aber dieses Verfahren geht davon aus, dass alle Texte, die zu anderen Bildern passen, gleich schlechte Übereinstimmungen sind. Das stimmt nicht immer. Zum Beispiel:

Beschriftung: Der Hund sitzt an einer Schneewehe.
Obwohl der Text dieses Bild nicht beschreibt, haben sie einen Hund gemeinsam. Wenn man dieses Paar als nicht übereinstimmend behandelt, wird das Wort "Hund" tendenziell von jedem Bild eines Hundes weggeschoben.
Liang et al. [2022] zeigen, dass diese unvollkommenen nicht übereinstimmenden Paare alle Bilder und Texte voneinander wegschieben.
Wir machten uns daran, ihre Behauptung mit einem vollständig zufällig initialisierten vit-b-32 Bildmodell und einem ähnlich randomisierten JinaBERT v2 Textmodell zu überprüfen, wobei die Trainingstemperatur auf einen konstanten Wert von 0,02 (eine moderat niedrige Temperatur) eingestellt wurde. Wir erstellten zwei Sätze von Trainingsdaten:
- Einer mit zufälligen Batches aus Flickr8k, wobei nicht übereinstimmende Paare wie oben beschrieben konstruiert wurden.
- Einer, bei dem die Batches absichtlich mit mehreren Kopien desselben Bildes mit unterschiedlichen Texten in jedem Batch konstruiert wurden. Dies garantiert, dass eine signifikante Anzahl von "nicht übereinstimmenden" Paaren tatsächlich korrekte Übereinstimmungen füreinander sind.
Wir trainierten dann zwei Modelle für eine Epoche, eines mit jedem Trainingsdatensatz, und maßen den durchschnittlichen Kosinus-Abstand zwischen 1.000 Text-Bild-Paaren im Flickr8k-Datensatz für jedes Modell. Das mit zufälligen Batches trainierte Modell hatte einen durchschnittlichen Kosinus-Abstand von 0,7521, während das mit vielen absichtlich übereinstimmenden "nicht übereinstimmenden" Paaren trainierte einen durchschnittlichen Kosinus-Abstand von 0,7840 hatte. Der Effekt der falschen "nicht übereinstimmenden" Paare ist ziemlich signifikant. Angesichts dessen, dass das reale Modelltraining viel länger dauert und viel mehr Daten verwendet, können wir sehen, wie dieser Effekt wachsen und die Lücke zwischen Bildern und Texten als Ganzes vergrößern würde.
tagDas Medium ist die Botschaft
Der kanadische Kommunikationstheoretiker Marshall McLuhan prägte 1964 in seinem Buch Understanding Media: The Extensions of Man den Ausdruck "Das Medium ist die Botschaft", um zu betonen, dass Botschaften nicht autonom sind. Sie erreichen uns in einem Kontext, der ihre Bedeutung stark beeinflusst, und er behauptete bekanntlich, dass einer der wichtigsten Teile dieses Kontexts die Art des Kommunikationsmediums ist.
Die Multimodalitätslücke bietet uns eine einzigartige Gelegenheit, eine Klasse emergenter semantischer Phänomene in KI-Modellen zu untersuchen. Niemand hat Jina CLIP beigebracht, das Medium der Trainingsdaten zu codieren - es tat es einfach trotzdem. Auch wenn wir das Problem für multimodale Modelle noch nicht gelöst haben, haben wir zumindest ein gutes theoretisches Verständnis davon, woher das Problem kommt.
Wir sollten davon ausgehen, dass unsere Modelle aufgrund der gleichen Art von Bias andere Dinge codieren, nach denen wir noch nicht gesucht haben. Zum Beispiel haben wir wahrscheinlich das gleiche Problem bei mehrsprachigen Embedding-Modellen. Das gemeinsame Training mit zwei oder mehr Sprachen führt vermutlich zur gleichen Lücke zwischen den Sprachen, besonders da ähnliche Trainingsmethoden weit verbreitet sind. Lösungen für das Lückenproblem könnten sehr weitreichende Auswirkungen haben.
Eine Untersuchung des Initialisierungs-Bias in einer breiteren Palette von Modellen wird wahrscheinlich auch zu neuen Erkenntnissen führen. Wenn das Medium für ein Embedding-Modell die Botschaft ist, wer weiß, was sonst noch ohne unser Wissen in unsere Modelle codiert wird?
