


Sonntagabend. Sie klicken auf "Veröffentlichen" bei dem Artikel, in den Sie das ganze Wochenende Ihr Herz gesteckt haben. Jedes Wort, jede Idee - einzigartig Ihre. Ein paar Likes tröpfeln ein. Nicht viral, aber es ist Ihrer.
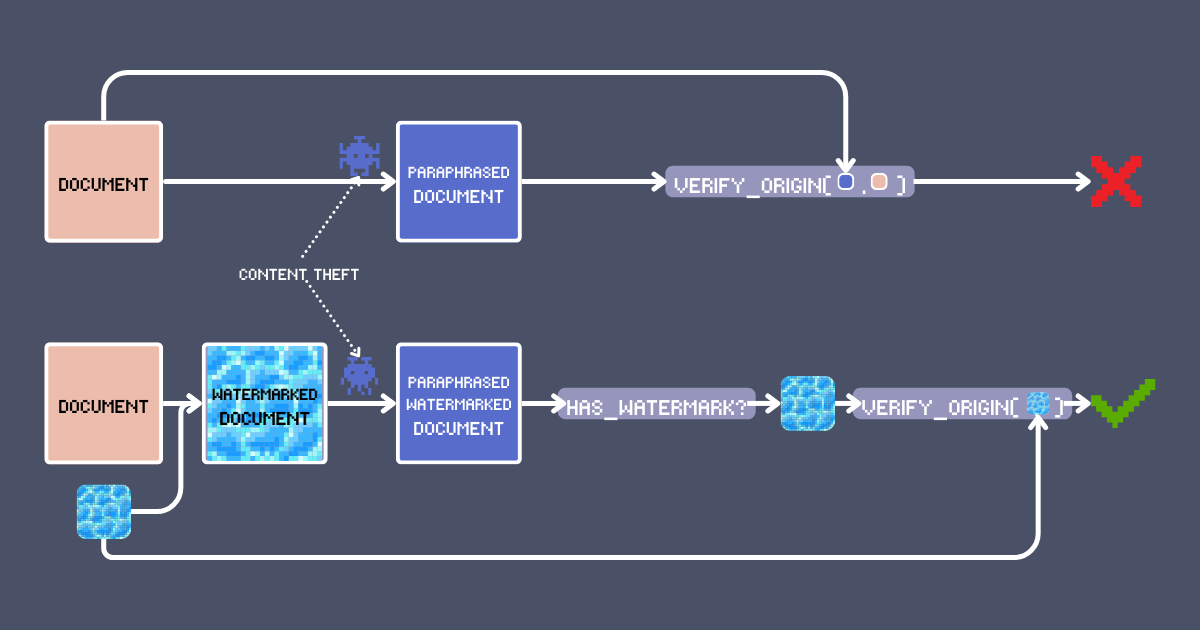
Drei Tage später, beim Scrollen durch Ihren Feed, sehen Sie es: Die Seele Ihres Artikels in einem fremden Körper! Die Worte wurden umgestellt, aber Sie erkennen Ihre eigene Kreation. Das Schlimmste? Deren Version ist überall, viraler Erfolg aufgebaut auf Ihrer gestohlenen Kreativität. Das ist nicht die kreative Wirtschaft, für die wir uns angemeldet haben.
Die offensichtliche Lösung ist, Ihren Namen auf Ihre Arbeit zu setzen. Aber seien wir ehrlich - das ist auch am einfachsten zu entfernen. Können wir es besser machen? In diesem Artikel zeigen wir Ihnen eine Watermarking-Technik mit Embedding-Modellen, die sowohl originale Inhalte signieren als auch erkennen kann. Dies ist nicht nur ein weiteres Search/RAG-Klischee - es nutzt einzigartige Funktionen von jina-embeddings-v3 wie Long-Context und Cross-Lingual Alignment, um ein robustes Authentifizierungssystem zu schaffen und ermöglicht uns eine zuverlässige Inhaltsverifizierung über Transformationen wie LLM-Paraphrasierung oder sogar Übersetzung hinweg.
tagText-Wasserzeichen verstehen
Digitale Wasserzeichen sind seit Jahren ein Grundpfeiler des Inhaltsschutzes. Wenn Sie ein Meme mit einem halbtransparenten Logo darüber finden, sehen Sie die grundlegendste Form des Bild-Watermarking. Moderne Watermarking-Techniken haben sich weit über einfache visuelle Overlays hinaus entwickelt – viele sind für menschliche Betrachter nun nicht wahrnehmbar, bleiben aber maschinenlesbar.
Text-Watermarking folgt ähnlichen Prinzipien, operiert aber im semantischen Raum. Statt Pixel zu verändern, modifiziert ein Text-Wasserzeichen den Inhalt subtil auf eine Weise, die die ursprüngliche Bedeutung bewahrt, während eine erkennbare Signatur eingebettet wird. Die Schlüsselanforderungen für ein effektives Text-Wasserzeichen sind also:
- Semantische Erhaltung: Der mit Wasserzeichen versehene Text sollte seine ursprüngliche Bedeutung und Lesbarkeit bewahren, genauso wie ein visuelles Wasserzeichen die Schlüsselelemente eines Bildes nicht verdecken sollte.
- Unauffälligkeit: Das Wasserzeichen sollte für menschliche Leser nicht bemerkbar sein, damit sie es während der Inhaltstranzformation nicht absichtlich erhalten oder entfernen können.
- Maschinell erkennbar: Während das Wasserzeichen für menschliche Leser subtil sein mag, sollte es klare, messbare Muster erzeugen, die Algorithmen zuverlässig identifizieren können.
- Transformationsinvariant: Jede Inhaltstransformation (wie Paraphrasierung oder Übersetzung), ob absichtlich oder unbewusst der Existenz des Wasserzeichens, sollte entweder das Wasserzeichen erhalten oder so substanzielle Änderungen erfordern, dass sie die Struktur oder Bedeutung des ursprünglichen Inhalts grundlegend verändert.
tagEmbeddings für Text-Watermarking nutzen
Lassen Sie uns ein Text-Watermarking-System mit Embeddings aufbauen. Definieren wir zunächst die Hauptkomponenten dieses Systems:
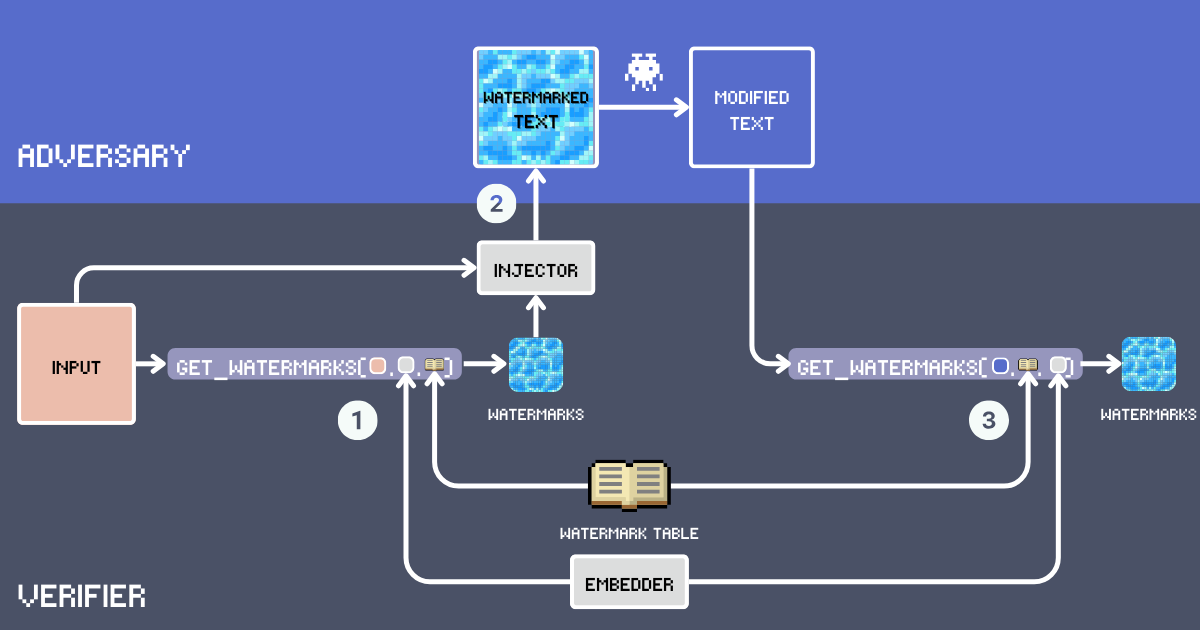
- Input: Der originale Text, der mit Wasserzeichen versehen werden soll.
- Watermark Table: Ein geheimes Lexikon mit Kandidaten-Wasserzeichenwörtern. Für optimale Watermarking-Effektivität sollten die Wörter häufig genug sein, um natürlich in verschiedene Kontexte zu passen. Das Vokabular schließt Funktionswörter, Eigennamen und seltene Wörter aus, die unpassend erscheinen könnten, z.B. sind
delve into,embarkgute Kandidaten, währendgoodeinfach zu häufig ist. Unten werden wir unsere WatermarkTable mit Wörtern aus fortgeschrittenem englischen Vokabular aufbauen. - Embedder: Ein Embedding-Modell, das zwei Zwecke erfüllt: Es wählt semantisch passende Wörter aus der
WatermarkTablebasierend auf deminputText und hilft bei der Erkennung von Wasserzeichen in potenziell paraphrasierten Texten. Wir verwenden jina-embeddings-v3, weil es sowohl sehr lange Texte als auch verschiedene Sprachen gut handhabt. Das bedeutet, wir können lange Dokumente mit Wasserzeichen versehen und Plagiatoren auch dann erwischen, wenn sie den Text übersetzen. - Watermarks: Wörter, die aus der WatermarkTable ausgewählt werden, indem die Cosinus-Ähnlichkeit zwischen dem Input-Text-Embedding und den Embeddings in der Tabelle berechnet wird. Die Anzahl der Wörter wird durch ein Einfügungsverhältnis bestimmt, typischerweise 12% der Input-Wortanzahl.
- Injector: Ein anweisungsfolgendes LLM, das die Wasserzeichenwörter in den Input-Text integriert, während es Kohärenz, faktische Genauigkeit, natürlichen Fluss und gleichmäßige Verteilung der Wasserzeichenwörter im Text beibehält.
- Watermarked Text: Die Ausgabe nachdem der Injector die Wasserzeichenwörter in den
inputeingefügt hat. - Adversary (Content Theft): Eine Entität, die versucht, den mit Wasserzeichen versehenen Text ohne Attribution weiterzuverwenden, typischerweise durch Paraphrasierung, Übersetzung oder kleinere Bearbeitungen. Heute bedeutet das einfach die Verwendung eines LLM mit dem Prompt
Paraphrase [text]für automatisches Umschreiben. - Modified Text: Das Ergebnis nach den Modifikationen des Angreifers am wasserzeichenversehenen Text. Dies ist der Text, den wir auf Wasserzeichen überprüfen müssen.
tagAlgorithmus


tagFazit
Anhand dieser Beispiele können wir erkennen, dass unser einbettungsbasiertes Wasserzeichen selbst mit diesem grundlegenden Setup ziemlich robust ist. Besonders bemerkenswert ist, dass die Wasserzeichen auch nach der Übersetzung nachweisbar bleiben. Diese sprachübergreifende Robustheit wird durch die leistungsstarken mehrsprachigen Fähigkeiten des jina-embeddings-v3 Modells ermöglicht; ohne starke multilinguale und sprachübergreifende Fähigkeiten wäre eine solche Beständigkeit durch Übersetzungen nicht erreichbar.
Es gibt mehrere Möglichkeiten, die Genauigkeit und Robustheit dieses Wasserzeichensystems zu verbessern. Erstens könnte die Wasserzeichentabelle erweitert und sorgfältig konstruiert werden, um Vielfalt zu gewährleisten. Dies ist wichtig, da ein größeres, vielfältigeres Vokabular eine bessere Abdeckung semantischer Räume bietet und es einfacher macht, kontextuell passende Wasserzeichen für jeden beliebigen Text zu finden, während das Risiko sich wiederholender oder offensichtlicher Muster reduziert wird.
Die Injector-Komponente könnte durch die Implementierung ausgereifterer Einfügestrategien verbessert werden. Zum Beispiel könnte sie angewiesen werden, Wasserzeichen gleichmäßig über den Text zu verteilen, um die Unauffälligkeit zu bewahren. Zusätzlich könnten wir die Late-Chunking-Technik einsetzen, um Wasserzeichen für einzelne Segmente oder Sätze zu generieren, wodurch der Injector nuanciertere Entscheidungen über die Platzierung der Wasserzeichen treffen kann. Dies würde dazu beitragen, sowohl die allgemeine Unauffälligkeit als auch die semantische Kohärenz im endgültigen Text zu bewahren.
Für Leser, die sich tiefer gehend damit beschäftigen möchten, präsentiert "POSTMARK: A Robust Blackbox Watermark for Large Language Models" (Chang et al., EMNLP 2024) ein umfassendes Framework einschließlich mathematischer Formulierungen und ausführlicher Experimente. Die Autoren untersuchen systematisch die Konstruktion des Wasserzeichenvokabulars, optimale Einfügestrategien und die Robustheit gegen verschiedene Angriffe. Sie analysieren auch gründlich den Kompromiss zwischen Wasserzeichenerkennung und Textqualität durch sowohl automatisierte als auch menschliche Bewertung.
