

Das Chunking eines langen Dokuments hat zwei Probleme: Erstens die Bestimmung der Trennpunkte – d. h. wie das Dokument segmentiert werden soll. Man könnte feste Token-Längen, eine feste Anzahl von Sätzen oder fortgeschrittenere Techniken wie Regex oder semantische Segmentierungsmodelle in Betracht ziehen. Präzise Chunk-Grenzen verbessern nicht nur die Lesbarkeit der Suchergebnisse, sondern stellen auch sicher, dass die Chunks, die einem LLM in einem RAG-System zugeführt werden, präzise und ausreichend sind – nicht mehr und nicht weniger.
Das zweite Problem ist der Kontextverlust innerhalb jedes Chunks. Sobald das Dokument segmentiert ist, besteht der nächste logische Schritt für die meisten darin, jeden Chunk separat in einem Batch-Prozess einzubetten. Dies führt jedoch zu einem Verlust des globalen Kontexts aus dem ursprünglichen Dokument. Viele frühere Arbeiten haben sich zuerst mit dem ersten Problem befasst und argumentiert, dass eine bessere Grenzerkennung die semantische Repräsentation verbessert. Zum Beispiel gruppiert "semantisches Chunking" Sätze mit hoher Cosinus-Ähnlichkeit im Embedding-Space, um die Störung semantischer Einheiten zu minimieren.
Aus unserer Sicht sind diese beiden Probleme fast orthogonal und können separat angegangen werden. Wenn wir priorisieren müssten, würden wir sagen, dass das zweite Problem kritischer ist.
| Problem 2: Kontextuelle Information | |||
|---|---|---|---|
| Erhalten | Verloren | ||
| Problem 1: Trennpunkte | Gut | Ideales Szenario | Schlechte Suchergebnisse |
| Schlecht | Gute Suchergebnisse, aber Ergebnisse könnten für Menschen schwer lesbar oder für LLM-Reasoning ungeeignet sein | Schlimmstes Szenario |
tagLate Chunking für Kontextverlust
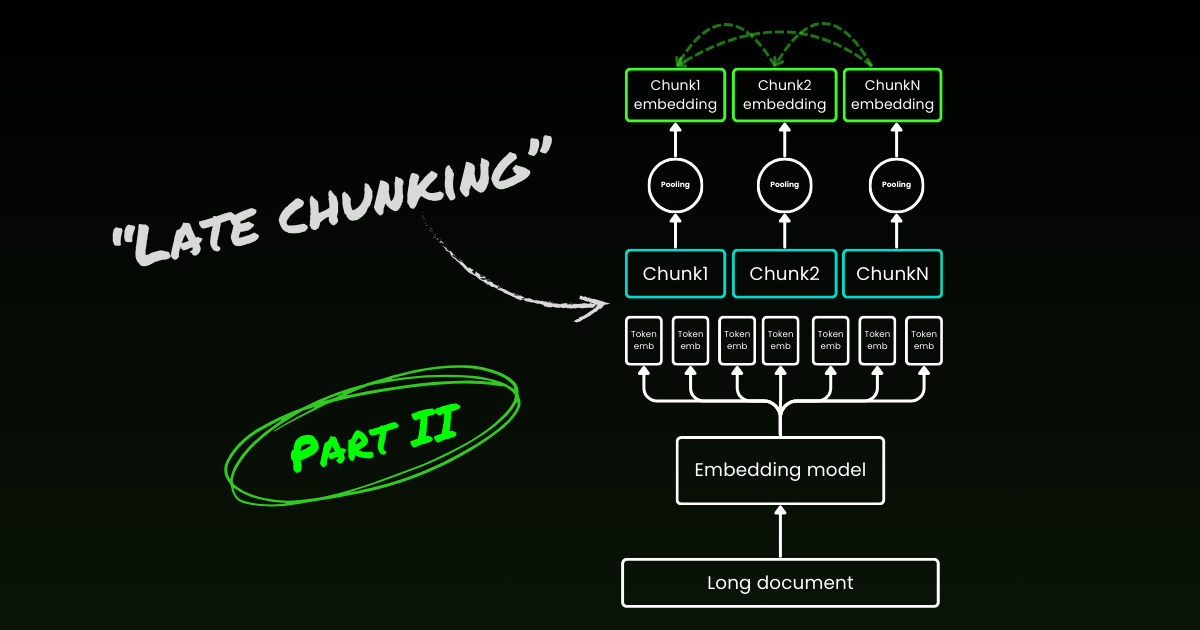
Late Chunking beginnt damit, das zweite Problem anzugehen: den Verlust des Kontexts. Es geht nicht darum, die idealen Trennpunkte oder semantischen Grenzen zu finden. Man muss immer noch Regex, Heuristiken oder andere Techniken verwenden, um ein langes Dokument in kleine Chunks zu unterteilen. Aber anstatt jeden Chunk sofort nach der Segmentierung einzubetten, codiert Late Chunking zunächst das gesamte Dokument in einem Kontextfenster (für jina-embeddings-v3 sind es 8192 Token). Dann folgt es den Grenzhinweisen, um Mean Pooling für jeden Chunk anzuwenden – daher der Begriff "late" (spät) im Late Chunking.

tagLate Chunking ist widerstandsfähig gegen schlechte Grenzhinweise
Was wirklich interessant ist: Experimente zeigen, dass Late Chunking die Notwendigkeit perfekter semantischer Grenzen eliminiert, was teilweise das erste oben erwähnte Problem löst. Tatsächlich übertrifft Late Chunking mit festen Token-Grenzen das naive Chunking mit semantischen Grenzhinweisen. Einfache Segmentierungsmodelle, wie solche mit festen Längengrenzen, schneiden in Verbindung mit Late Chunking genauso gut ab wie fortgeschrittene Grenzerkennungsalgorithmen. Wir haben drei verschiedene Größen von Embedding-Modellen getestet, und die Ergebnisse zeigen, dass alle von ihnen über alle Testdatensätze hinweg konsistent von Late Chunking profitieren. Allerdings bleibt das Embedding-Modell selbst der wichtigste Faktor für die Leistung – es gibt keinen einzigen Fall, in dem ein schwächeres Modell mit Late Chunking ein stärkeres Modell ohne Late Chunking übertrifft.

jina-embeddings-v2-small mit festen Token-Längen-Grenzhinweisen und naivem Chunking). Als Teil einer Ablationsstudie testeten wir Late Chunking mit verschiedenen Grenzhinweisen (feste Token-Länge, Satzgrenzen und semantische Grenzen) und verschiedenen Modellen (jina-embeddings-v2-small, nomic-v1 und jina-embeddings-v3). Basierend auf ihrer Leistung bei MTEB ist die Rangfolge dieser drei Embedding-Modelle: jina-embeddings-v2-small < nomic-v1 < jina-embeddings-v3. Der Fokus dieses Experiments liegt jedoch nicht darauf, die Leistung der Embedding-Modelle selbst zu bewerten, sondern zu verstehen, wie ein besseres Embedding-Modell mit Late Chunking und Boundary Cues interagiert. Für Details zum Experiment verweisen wir auf unser Forschungspapier.| Combo | SciFact | NFCorpus | FiQA | TRECCOVID |
|---|---|---|---|---|
| Baseline | 64.2 | 23.5 | 33.3 | 63.4 |
| Late | 66.1 | 30.0 | 33.8 | 64.7 |
| Nomic | 70.7 | 35.3 | 37.0 | 72.9 |
| Jv3 | 71.8 | 35.6 | 46.3 | 73.0 |
| Late + Nomic | 70.6 | 35.3 | 38.3 | 75.0 |
| Late + Jv3 | 73.2 | 36.7 | 47.6 | 77.2 |
| SentBound | 64.7 | 28.3 | 30.4 | 66.5 |
| Late + SentBound | 65.2 | 30.0 | 33.9 | 66.6 |
| Nomic + SentBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SentBound | 71.4 | 35.8 | 43.7 | 72.4 |
| Late + Nomic + SentBound | 70.5 | 35.3 | 36.9 | 76.1 |
| Late + Jv3 + SentBound | 72.4 | 36.6 | 47.6 | 76.2 |
| SemanticBound | 64.3 | 27.4 | 30.3 | 66.2 |
| Late + SemanticBound | 65.0 | 29.3 | 33.7 | 66.3 |
| Nomic + SemanticBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SemanticBound | 71.2 | 36.1 | 44.0 | 74.7 |
| Late + Nomic + SemanticBound | 70.5 | 36.9 | 36.9 | 76.1 |
| Late + Jv3 + SemanticBound | 72.4 | 36.6 | 47.6 | 76.2 |
Beachten Sie, dass Widerstandsfähigkeit gegenüber schlechten Grenzen nicht bedeutet, dass wir sie ignorieren können – sie sind immer noch wichtig für die Lesbarkeit sowohl für Menschen als auch LLMs. Unsere Sichtweise ist: Bei der Optimierung der Segmentierung, also dem zuvor genannten 1. Problem, können wir uns vollständig auf die Lesbarkeit konzentrieren, ohne uns Sorgen um semantischen/kontextuellen Verlust zu machen. Late Chunking kommt mit guten oder schlechten Breakpoints zurecht, sodass Sie sich nur um die Lesbarkeit kümmern müssen.
tagLate Chunking ist bidirektional
Ein weiteres häufiges Missverständnis über Late Chunking ist, dass seine bedingten Chunk-Embeddings nur von vorherigen Chunks abhängen, ohne "nach vorne zu schauen". Dies ist falsch. Die bedingte Abhängigkeit in Late Chunking ist tatsächlich bi-direktional, nicht uni-direktional. Der Grund dafür ist, dass die Aufmerksamkeitsmatrix im Embedding-Modell – einem reinen Encoder-Transformer – vollständig verbunden ist, anders als die maskierte Dreiecksmatrix in auto-regressiven Modellen. Formal ausgedrückt: Das Embedding von Chunk , , statt , wobei eine Faktorisierung des Sprachmodells bezeichnet. Dies erklärt auch, warum Late Chunking nicht von der genauen Platzierung der Grenzen abhängt.

tagLate Chunking kann trainiert werden
Late Chunking erfordert kein zusätzliches Training für Embedding-Modelle. Es kann auf jedes Embedding-Modell mit langem Kontext angewendet werden, das Mean Pooling verwendet, was es für Praktiker sehr attraktiv macht. Wenn Sie allerdings an Aufgaben wie Frage-Antwort oder Query-Dokument-Retrieval arbeiten, kann die Leistung durch Fine-tuning noch weiter verbessert werden. Konkret besteht das Trainingsdatum aus Tupeln, die Folgendes enthalten:
- Eine Query (z.B. eine Frage oder ein Suchbegriff)
- Ein Dokument, das relevante Informationen zur Beantwortung der Query enthält
- Eine relevante Textpassage innerhalb des Dokuments, die den spezifischen Textabschnitt darstellt, der die Query direkt beantwortet
Das Modell wird trainiert, indem Queries mit ihren relevanten Textpassagen gepaart werden, unter Verwendung einer kontrastiven Verlustfunktion wie InfoNCE. Dies stellt sicher, dass relevante Textpassagen im Embedding-Raum eng mit der Query ausgerichtet sind, während nicht verwandte Passagen weiter entfernt werden. Dadurch lernt das Modell, sich bei der Generierung von Chunk-Embeddings auf die relevantesten Teile des Dokuments zu konzentrieren. Weitere Details finden Sie in unserem Forschungspapier.
tagLate Chunking vs. Contextual Retrieval
Kurz nach der Einführung von Late Chunking stellte Anthropic eine separate Strategie namens Contextual Retrieval vor. Anthropics Methode ist ein Brute-Force-Ansatz zur Lösung des Problems des verlorenen Kontexts und funktioniert wie folgt:
- Jeder Chunk wird zusammen mit dem vollständigen Dokument an das LLM gesendet
- Das LLM fügt jedem Chunk relevanten Kontext hinzu
- Dies führt zu reichhaltigeren und informativeren Embeddings
Unserer Ansicht nach ist dies im Wesentlichen Kontextanreicherung, bei der globaler Kontext explizit mittels eines LLM in jeden Chunk eincodiert wird, was in Bezug auf Kosten, Zeit und Speicherplatz teuer ist. Außerdem ist unklar, ob dieser Ansatz widerstandsfähig gegenüber Chunk-Grenzen ist, da das LLM auf genaue und lesbare Chunks angewiesen ist, um den Kontext effektiv anzureichern. Im Gegensatz dazu ist Late Chunking, wie oben gezeigt, hochgradig widerstandsfähig gegenüber Boundary Cues. Es erfordert keinen zusätzlichen Speicherplatz, da die Embedding-Größe gleich bleibt. Obwohl es die volle Kontextlänge des Embedding-Modells nutzt, ist es immer noch deutlich schneller als die Verwendung eines LLM zur Generierung von Anreicherungen. In der qualitativen Studie unseres Forschungspapiers zeigen wir, dass Anthropics Context Retrieval ähnlich wie Late Chunking funktioniert. Late Chunking bietet jedoch eine grundlegendere, generischere und natürlichere Lösung, indem es die inhärenten Mechanismen des Encoder-only Transformers nutzt.
tagWelche Embedding-Modelle unterstützen Late Chunking?
Late Chunking ist nicht exklusiv für jina-embeddings-v3 oder v2. Es ist ein ziemlich generischer Ansatz, der auf jedes Embedding-Modell mit langem Kontext angewendet werden kann, das Mean Pooling verwendet. Zum Beispiel zeigen wir in diesem Beitrag, dass auch nomic-v1 es unterstützt. Wir begrüßen alle Embedding-Anbieter herzlich, die Unterstützung für Late Chunking in ihren Lösungen zu implementieren.
Als Modellanwender können Sie diese Schritte befolgen, um zu prüfen, ob ein neues Embedding-Modell oder eine API Late Chunking unterstützen könnte:
- Single Output: Liefert das Modell/die API nur ein finales Embedding pro Satz anstelle von Token-Level-Embeddings? Falls ja, dann kann es wahrscheinlich kein Late Chunking unterstützen (besonders bei Web-APIs).
- Long-Context Support: Kann das Modell/die API Kontexte von mindestens 8192 Tokens verarbeiten? Falls nein, ist Late Chunking nicht anwendbar – oder genauer gesagt, es macht keinen Sinn, Late Chunking für ein Modell mit kurzem Kontext zu adaptieren. Falls ja, stellen Sie sicher, dass es tatsächlich gut mit langen Kontexten funktioniert und nicht nur behauptet, diese zu unterstützen. Diese Informationen finden Sie normalerweise im technischen Bericht des Modells, wie etwa in Evaluierungen auf LongMTEB oder anderen Long-Context-Benchmarks.
- Mean Pooling: Prüfen Sie bei selbst gehosteten Modellen oder APIs, die Token-Level-Embeddings vor dem Pooling bereitstellen, ob die Standard-Pooling-Methode Mean Pooling ist. Modelle, die CLS oder Max Pooling verwenden, sind nicht kompatibel mit Late Chunking.
Zusammenfassend lässt sich sagen, wenn ein Embedding-Modell Long-Context unterstützt und standardmäßig Mean Pooling verwendet, kann es problemlos Late Chunking unterstützen. Schauen Sie sich unser GitHub-Repository für Implementierungsdetails und weitere Diskussionen an.
tagFazit
Was ist also Late Chunking? Late Chunking ist eine unkomplizierte Methode zur Generierung von Chunk-Embeddings unter Verwendung von Long-Context-Embedding-Modellen. Es ist schnell, unempfindlich gegenüber Boundary-Cues und hocheffektiv. Es ist keine Heuristik oder Over-Engineering – es ist ein durchdachtes Design, das auf einem tiefen Verständnis des Transformer-Mechanismus basiert.
Der Hype um LLMs ist heute unbestreitbar. In vielen Fällen werden Probleme, die effizient von kleineren Modellen wie BERT gelöst werden könnten, stattdessen an LLMs weitergegeben, getrieben von der Anziehungskraft größerer, komplexerer Lösungen. Es ist keine Überraschung, dass große LLM-Anbieter für eine stärkere Nutzung ihrer Modelle werben, während Embedding-Anbieter für Embeddings eintreten – beide spielen ihre kommerziellen Stärken aus. Aber letztendlich geht es nicht um den Hype, sondern um das Handeln, darum, was wirklich funktioniert. Lassen Sie die Community, die Industrie und vor allem die Zeit zeigen, welcher Ansatz wirklich schlanker, effizienter und nachhaltiger ist.
Lesen Sie unbedingt unser Forschungspapier, und wir ermutigen Sie, Late Chunking in verschiedenen Szenarien zu testen und uns Ihr Feedback mitzuteilen.
