Leser
Konvertieren Sie eine URL in eine LLM-freundliche Eingabe, indem Sie einfach
r.jina.ai davor hinzufügen.Leser-API
Konvertieren Sie eine URL in eine LLM-freundliche Eingabe, indem Sie einfach
r.jina.ai davor hinzufügen.chevron_leftchevron_right
globe_book
Verwenden Sie
r.jina.ai, um eine URL zu lesen und ihren Inhalt abzurufentravel_explore
Verwenden Sie
s.jina.ai, um im Web zu suchen und SERP zu erhalten
Fügen Sie
mcp.jina.ai als Ihren MCP-Server hinzu, um in LLMs auf unsere API zuzugreifenupload
Anfrage
GET
curl "https://r.jina.ai/https://www.example.com"
Jina VLM: Kleines mehrsprachiges visuelles Sprachmodell
Ein Bild-Sprach-Modell mit 2,4 Milliarden Parametern, das unter den offenen VLMs der 2-Milliarden-Skala modernste mehrsprachige visuelle Fragebeantwortung erreicht.

ReaderLM v2: Kleines Sprachmodell für HTML zu Markdown und JSON
ReaderLM-v2 ist ein 1,5-B-Parameter-Sprachmodell, das auf die Konvertierung von HTML in Markdown und die Extraktion von HTML in JSON spezialisiert ist. Es unterstützt Dokumente mit bis zu 512.000 Token in 29 Sprachen und bietet im Vergleich zu seinem Vorgänger eine um 20 % höhere Genauigkeit.


Das Einspeisen von Webinformationen in LLMs ist ein wichtiger Schritt zur Einarbeitung, kann aber auch eine Herausforderung sein. Die einfachste Methode besteht darin, die Webseite zu scrapen und das Roh-HTML einzuspeisen. Das Scraping kann jedoch komplex und oft blockiert sein, und Roh-HTML ist mit irrelevanten Elementen wie Markups und Skripten überladen. Die Reader-API behebt diese Probleme, indem sie den Kerninhalt aus einer URL extrahiert und in sauberen, LLM-freundlichen Text umwandelt, wodurch eine qualitativ hochwertige Eingabe für Ihre Agent- und RAG-Systeme sichergestellt wird.
Rohes HTML
Reader-Ausgabe

Reader kann als SERP-API verwendet werden. Damit können Sie Ihr LLM mit dem Inhalt hinter der Seite der Suchmaschine füttern. Stellen Sie Ihrer Abfrage einfach
https://s.jina.ai/?q= voran, und Reader durchsucht das Web und gibt die fünf besten Ergebnisse mit ihren URLs und Inhalten zurück, jeweils in sauberem, LLM-freundlichem Text. Auf diese Weise können Sie Ihr LLM immer auf dem neuesten Stand halten, seine Sachlichkeit verbessern und Halluzinationen reduzieren.info Bitte beachten Sie, dass Sie im Gegensatz zur oben gezeigten Demo in der Praxis nicht die ursprüngliche Frage im Internet nach einer Grundlage durchsuchen. Häufig wird die ursprüngliche Frage umgeschrieben oder es werden Multi-Hop-Fragen verwendet. Die abgerufenen Ergebnisse werden gelesen und anschließend werden zusätzliche Abfragen erstellt, um bei Bedarf weitere Informationen zu sammeln, bevor eine endgültige Antwort gefunden wird.

Bilder auf der Webseite werden mithilfe eines Vision Language Model im Reader automatisch mit Bildunterschriften versehen und in der Ausgabe als Bild-Alt-Tags formatiert. Dadurch erhält Ihr nachgelagertes LLM gerade genug Hinweise, um diese Bilder in seine Denk- und Zusammenfassungsprozesse einzubeziehen. Das bedeutet, dass Sie Fragen zu den Bildern stellen, bestimmte Bilder auswählen oder sogar ihre URLs zur tieferen Analyse an ein leistungsfähigeres VLM weiterleiten können!
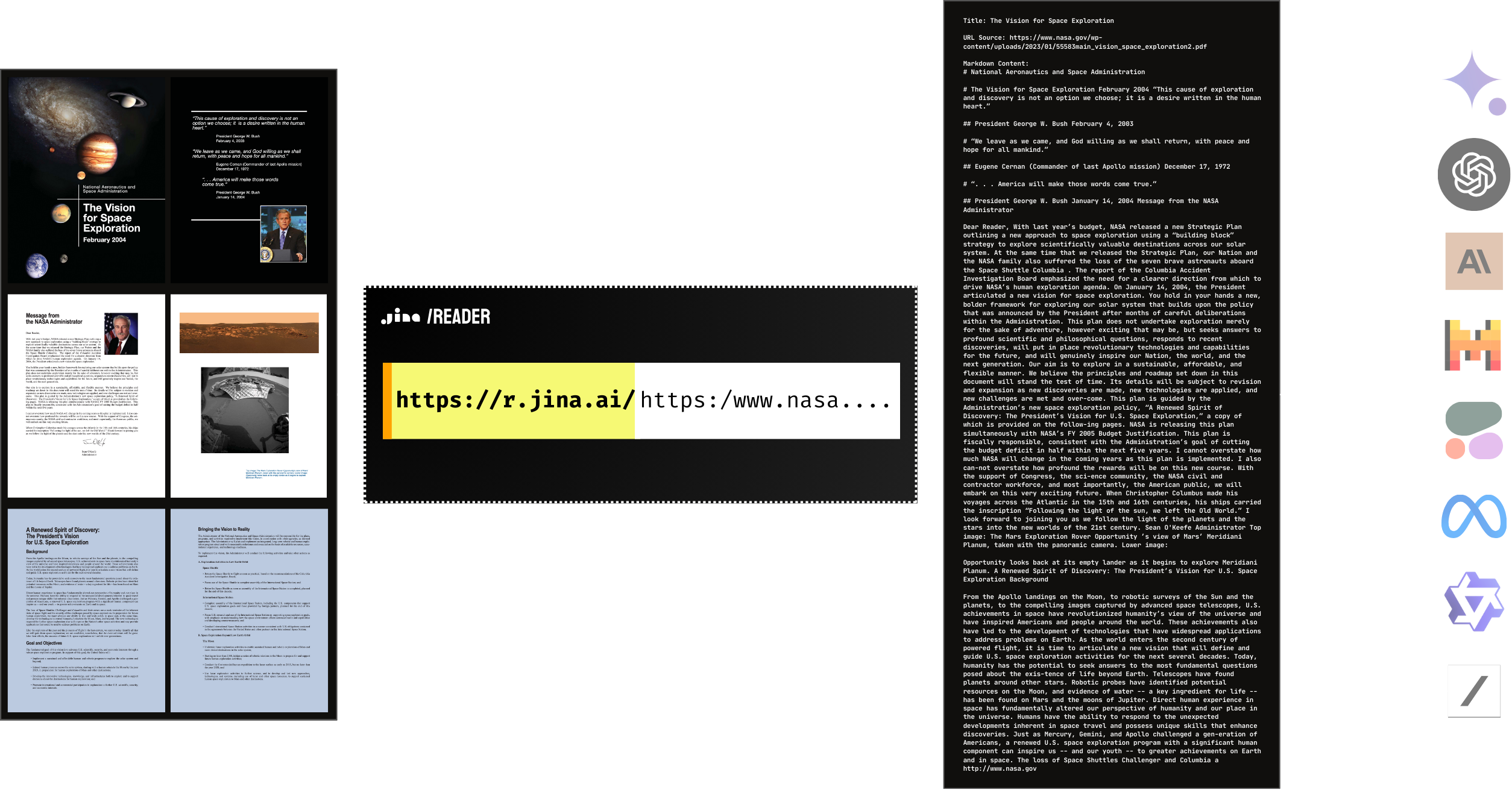
Ja, Reader unterstützt das Lesen von PDFs nativ. Es ist mit den meisten PDFs kompatibel, auch mit denen mit vielen Bildern, und es ist blitzschnell! In Kombination mit einem LLM können Sie im Handumdrehen ganz einfach eine ChatPDF- oder Dokumentenanalyse-KI erstellen.
Und das Beste daran? Es ist kostenlos!
Die Reader API ist kostenlos erhältlich und bietet flexible Ratenbegrenzungen und Preise. Sie basiert auf einer skalierbaren Infrastruktur und bietet hohe Zugänglichkeit, Parallelität und Zuverlässigkeit. Wir möchten Ihre bevorzugte Grundlösung für Ihre LLMs sein.
Ratenbegrenzung
Ratenbegrenzungen werden auf drei Arten verfolgt: RPM (Anfragen pro Minute) und TPM (Token pro Minute). Die Begrenzungen werden pro IP/API-Schlüssel erzwungen und ausgelöst, wenn zuerst der RPM- oder TPM-Schwellenwert erreicht wird. Wenn Sie im Anforderungsheader einen API-Schlüssel angeben, verfolgen wir die Ratenbegrenzungen nach Schlüssel und nicht nach IP-Adresse.
| Produkt | API-Endpunkt | Beschreibungarrow_upward | ohne API-Schlüsselkey_off | mit kostenlosem API-Schlüsselkey | mit kostenpflichtigem API-Schlüsselkey | mit Premium-API-Schlüsselkey | Durchschnittliche Latenz | Zählung der Token-Nutzung | Zulässige Anfrage | |
|---|---|---|---|---|---|---|---|---|---|---|
| Leser-API | https://r.jina.ai | URL in LLM-freundlichen Text konvertieren | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Zählen Sie die Anzahl der Token in der Ausgabeantwort. | GET/POST | |
| Leser-API | https://s.jina.ai | Durchsuchen Sie das Web und konvertieren Sie die Ergebnisse in LLM-freundlichen Text | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Jede Anfrage kostet eine feste Anzahl an Token, beginnend bei 10000 Token | GET/POST | |
| Einbettungs-API | https://api.jina.ai/v1/embeddings | Konvertieren Sie Text/Bilder in Vektoren mit fester Länge | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab help | Zählen Sie die Anzahl der Token in der Eingabeanforderung. | POST | |
| Reranker-API | https://api.jina.ai/v1/rerank | Ordnen Sie Dokumente nach Abfrage | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab help | Zählen Sie die Anzahl der Token in der Eingabeanforderung. | POST | |
| Klassifizierer-API | https://api.jina.ai/v1/train | Trainieren eines Klassifikators anhand gekennzeichneter Beispiele | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab | Token werden wie folgt gezählt: input_tokens × num_iters | POST | |
| Klassifizierer-API (Nullschuss) | https://api.jina.ai/v1/classify | Klassifizieren Sie Eingaben mithilfe der Zero-Shot-Klassifizierung | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab | Token werden wie folgt gezählt: input_tokens + label_tokens | POST | |
| Klassifizierer-API (Wenige Schüsse) | https://api.jina.ai/v1/classify | Klassifizieren Sie Eingaben mit einem trainierten Few-Shot-Klassifikator | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab | Token werden wie folgt gezählt: input_tokens | POST | |
| Segmenter-API | https://api.jina.ai/v1/segment | Tokenisieren und Segmentieren von Langtext | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | Token werden nicht als Nutzung gezählt. | GET/POST | |
| DeepSearch | https://deepsearch.jina.ai/v1/chat/completions | Überlegen, suchen und iterieren, um die beste Antwort zu finden | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Zählen Sie die Gesamtzahl der Token im gesamten Vorgang. | POST |





Keine Panik! Jeder neue API-Schlüssel enthält zehn Millionen kostenlose Token!
API-Preise
Die API-Preise basieren auf der Token-Nutzung. Ein API-Schlüssel gibt Ihnen Zugriff auf alle Produkte der Suchgrundlage.

Mit Jina Search Foundation API
Der einfachste Weg, auf alle unsere Produkte zuzugreifen. Laden Sie Tokens unterwegs auf.
Laden Sie diesen API-Schlüssel mit weiteren Token auf
Bitte geben Sie zum Aufladen den richtigen API-Schlüssel ein
Verstehen Sie die Ratenbegrenzung
Ratenbegrenzungen sind die maximale Anzahl von Anfragen, die pro Minute pro IP-Adresse/API-Schlüssel (RPM) an eine API gestellt werden können. Nachfolgend erfahren Sie mehr über die Ratenbegrenzungen für jedes Produkt und jede Stufe.
keyboard_arrow_down

Welche Kosten sind mit der Nutzung der Reader-API verbunden?
keyboard_arrow_down
Wie funktioniert die Reader-API?
keyboard_arrow_down
Ist die Reader-API Open Source?
keyboard_arrow_down
Wie hoch ist die typische Latenz für die Reader-API?
keyboard_arrow_down
Warum sollte ich die Reader-API verwenden, anstatt die Seite selbst zu scrapen?
keyboard_arrow_down
Unterstützt die Reader-API mehrere Sprachen?
keyboard_arrow_down
Was soll ich tun, wenn eine Website die Reader-API blockiert?
keyboard_arrow_down
Kann die Reader-API Inhalte aus PDF-Dateien extrahieren?
keyboard_arrow_down
Kann die Reader-API Medieninhalte von Webseiten verarbeiten?
keyboard_arrow_down
Ist es möglich, die Reader-API auf lokale HTML-Dateien anzuwenden?
keyboard_arrow_down
Speichert die Reader-API den Inhalt im Cache?
keyboard_arrow_down
Kann ich die Reader-API verwenden, um auf Inhalte hinter einer Anmeldung zuzugreifen?
keyboard_arrow_down
Kann ich die Reader-API verwenden, um auf arXiv auf PDF zuzugreifen?
keyboard_arrow_down
Wie funktionieren Bildunterschriften im Reader?
keyboard_arrow_down
Wie skalierbar ist der Reader? Kann ich ihn in der Produktion einsetzen?
keyboard_arrow_down
Wie hoch ist die Ratenbegrenzung der Reader-API?
keyboard_arrow_down
Was ist Reader-LM? Wie kann ich es verwenden?
keyboard_arrow_down
Wie extrahiere ich strukturierte Daten von Webseiten?
keyboard_arrow_down
Umgeht Reader aktiv den Anti-Bot-Schutz der Website?
keyboard_arrow_down
Erhalte ich durch das Upgrade von einem kostenlosen auf einen kostenpflichtigen API-Schlüssel Zugriff auf mehr Websites?
keyboard_arrow_down
Ratenbegrenzung
Ratenbegrenzungen werden auf drei Arten verfolgt: RPM (Anfragen pro Minute) und TPM (Token pro Minute). Die Begrenzungen werden pro IP/API-Schlüssel erzwungen und ausgelöst, wenn zuerst der RPM- oder TPM-Schwellenwert erreicht wird. Wenn Sie im Anforderungsheader einen API-Schlüssel angeben, verfolgen wir die Ratenbegrenzungen nach Schlüssel und nicht nach IP-Adresse.
| Produkt | API-Endpunkt | Beschreibungarrow_upward | ohne API-Schlüsselkey_off | mit kostenlosem API-Schlüsselkey | mit kostenpflichtigem API-Schlüsselkey | mit Premium-API-Schlüsselkey | Durchschnittliche Latenz | Zählung der Token-Nutzung | Zulässige Anfrage | |
|---|---|---|---|---|---|---|---|---|---|---|
| Leser-API | https://r.jina.ai | URL in LLM-freundlichen Text konvertieren | 20 RPM | 500 RPM | 500 RPM | trending_up5000 RPM | 7.9s | Zählen Sie die Anzahl der Token in der Ausgabeantwort. | GET/POST | |
| Leser-API | https://s.jina.ai | Durchsuchen Sie das Web und konvertieren Sie die Ergebnisse in LLM-freundlichen Text | block | 100 RPM | 100 RPM | trending_up1000 RPM | 2.5s | Jede Anfrage kostet eine feste Anzahl an Token, beginnend bei 10000 Token | GET/POST | |
| Einbettungs-API | https://api.jina.ai/v1/embeddings | Konvertieren Sie Text/Bilder in Vektoren mit fester Länge | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab help | Zählen Sie die Anzahl der Token in der Eingabeanforderung. | POST | |
| Reranker-API | https://api.jina.ai/v1/rerank | Ordnen Sie Dokumente nach Abfrage | block | 100 RPM & 100,000 TPM | 500 RPM & 2,000,000 TPM | trending_up5,000 RPM & 50,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab help | Zählen Sie die Anzahl der Token in der Eingabeanforderung. | POST | |
| Klassifizierer-API | https://api.jina.ai/v1/train | Trainieren eines Klassifikators anhand gekennzeichneter Beispiele | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab | Token werden wie folgt gezählt: input_tokens × num_iters | POST | |
| Klassifizierer-API (Nullschuss) | https://api.jina.ai/v1/classify | Klassifizieren Sie Eingaben mithilfe der Zero-Shot-Klassifizierung | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab | Token werden wie folgt gezählt: input_tokens + label_tokens | POST | |
| Klassifizierer-API (Wenige Schüsse) | https://api.jina.ai/v1/classify | Klassifizieren Sie Eingaben mit einem trainierten Few-Shot-Klassifikator | block | 25 RPM & 25,000 TPM | 125 RPM & 500,000 TPM | 1,250 RPM & 12,000,000 TPM | ssid_chart hängt von der Eingangsgröße ab | Token werden wie folgt gezählt: input_tokens | POST | |
| Segmenter-API | https://api.jina.ai/v1/segment | Tokenisieren und Segmentieren von Langtext | 20 RPM | 200 RPM | 200 RPM | 1,000 RPM | 0.3s | Token werden nicht als Nutzung gezählt. | GET/POST | |
| DeepSearch | https://deepsearch.jina.ai/v1/chat/completions | Überlegen, suchen und iterieren, um die beste Antwort zu finden | block | 50 RPM | 50 RPM | 500 RPM | 56.7s | Zählen Sie die Gesamtzahl der Token im gesamten Vorgang. | POST |
Häufige Fragen zu APIs
code
Kann ich denselben API-Schlüssel für Reader-, Einbettungs-, Neurang-, Klassifizierungs- und Feinabstimmungs-APIs verwenden?
keyboard_arrow_down
code
Kann ich die Token-Nutzung meines API-Schlüssels überwachen?
keyboard_arrow_down
code
Was soll ich tun, wenn ich meinen API-Schlüssel vergesse?
keyboard_arrow_down
code
Laufen API-Schlüssel ab?
keyboard_arrow_down
code
Kann ich Token zwischen API-Schlüsseln übertragen?
keyboard_arrow_down
code
Kann ich meinen API-Schlüssel widerrufen?
keyboard_arrow_down
code
Warum ist die erste Anfrage für einige Modelle langsam?
keyboard_arrow_down
code
Werden meine API-Daten zum Trainieren Ihrer Modelle verwendet?
keyboard_arrow_down
code
Welche Ratenbegrenzungen gelten für Jina-APIs?
keyboard_arrow_down
code
Gibt es Beschränkungen hinsichtlich der Batchgröße für die APIs?
keyboard_arrow_down
Häufige Fragen zur Abrechnung
attach_money
Erfolgt die Abrechnung nach der Anzahl der Sätze bzw. Anfragen?
keyboard_arrow_down
attach_money
Gibt es eine kostenlose Testversion für neue Benutzer?
keyboard_arrow_down
attach_money
Werden für fehlgeschlagene Anfragen Token berechnet?
keyboard_arrow_down
attach_money
Welche Zahlungsmethoden werden akzeptiert?
keyboard_arrow_down
attach_money
Ist eine Rechnungsstellung für Token-Käufe verfügbar?
keyboard_arrow_down