


Tras el notable éxito de los anteriores Embeddings V2, nos complace anunciar el lanzamiento de nuestro último modelo de embedding de texto bilingüe chino/inglés: jina-embeddings-v2-base-zh. Este nuevo modelo hereda la excepcional longitud de 8K tokens de Jina Embeddings V2, ahora con sólido soporte para los idiomas chino e inglés.
jina-embeddings-v2-base-zh destaca por su calidad y rendimiento excepcionales, logrados a través de un riguroso y equilibrado pre-entrenamiento con datos bilingües de alta calidad. Este enfoque asegura una reducción significativa del sesgo, frecuentemente observado en modelos entrenados con datos multilingües desequilibrados.
tagAspectos Destacados
- Modelo Bilingüe: Este modelo codifica textos tanto en inglés como en chino, permitiendo el uso de cualquiera de los dos idiomas como consulta o documento objetivo. Los textos con significados equivalentes en estos idiomas se mapean al mismo espacio de embedding, formando la base para numerosas aplicaciones multilingües.
- Longitud Extendida de 8K Tokens: Nuestro modelo es capaz de procesar pasajes de texto significativamente grandes, una característica que supera las capacidades de la mayoría de otros modelos de código abierto.
- Compacto y Eficiente: Con un tamaño de 322MB (161 millones de parámetros) y dimensiones de salida de 768, nuestro modelo está diseñado para alto rendimiento en hardware de computadora estándar sin GPU, mejorando su accesibilidad.
tagRendimiento Líder en C-MTEB
En el ranking C-MTEB chino, nuestro Jina Embeddings v2, que soporta tanto chino como inglés, destaca como uno de los mejores modelos por debajo de 0.5GB. Lo que lo distingue es su impresionante capacidad de 8K tokens, una característica única en su categoría.
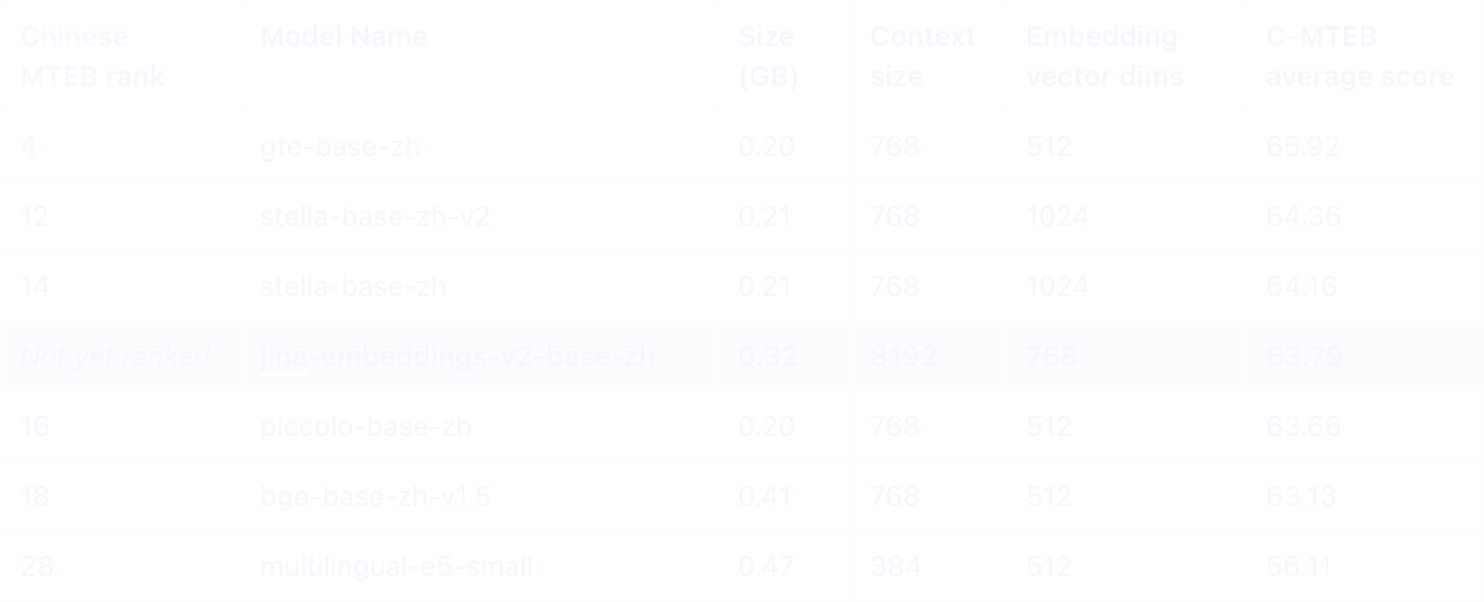
Entre los modelos chinos de tamaño similar, solo el modelo E5 Multilingual y nuestro jina-embeddings-v2-base-zh ofrecen soporte para inglés, permitiendo aplicaciones efectivas entre idiomas. Notablemente, Jina demuestra un rendimiento significativamente superior en todas las categorías que involucran el idioma chino.

Si bien ambos modelos tienen un contexto de 8K tokens, jina-embeddings-v2-base-zh supera significativamente a text-embedding-ada-002 de OpenAI, especialmente en tareas que involucran el idioma chino.

tagEmpoderando a las Empresas Chinas para su Expansión Global
Nuestro modelo de embedding chino-inglés es una herramienta poderosa para las empresas chinas que buscan "globalizarse" (出海). Procesa textos en chino sin problemas, proporcionando embeddings de alta calidad que se integran fácilmente con las principales bases de datos vectoriales, sistemas de búsqueda y aplicaciones RAG.
jina-embeddings-v2-base-zh es especialmente beneficioso para desarrollar aplicaciones de IA adaptadas a contextos chino-inglés, crucial para empresas en expansión internacional. Aquí hay algunos casos de uso específicos:
- Análisis y Gestión de Documentos: Puede analizar y gestionar una amplia gama de documentos, ayudando en transacciones legales y comerciales internacionales.
- Aplicaciones de Búsqueda Impulsadas por IA: Mejora las funciones de búsqueda en entornos multilingües, facilitando que los usuarios globales encuentren información relevante en chino e inglés.
- Chatbots y Sistemas de Preguntas y Respuestas con Recuperación Aumentada: Construye bots de servicio al cliente bilingües eficientes, mejorando las interacciones con clientes en todo el mundo.
- Aplicaciones de Procesamiento de Lenguaje Natural: Esto incluye análisis de sentimiento para comprender tendencias del mercado global, modelado de temas para estrategias de marketing internacional y clasificación de texto para gestionar la comunicación global.
- Sistemas de Recomendación: Personaliza recomendaciones de productos y contenido para audiencias globales diversas, utilizando información extraída de datos en chino e inglés.
Al aprovechar este modelo, las empresas chinas pueden cerrar efectivamente la brecha lingüística en sus aplicaciones de IA, mejorando su competitividad global y alcance de mercado.
tagComienza con jina-embeddings-v2-base-zh vía API
Comienza a integrar nuestro modelo en tu flujo de trabajo inmediatamente a través de la API de Embeddings. Simplemente visita nuestro portal de Embeddings, obtén tu clave de acceso gratuita o recarga una clave existente, y luego elige jina-embeddings-v2-base-zh del menú desplegable. ¡Es así de fácil empezar!

tagPróximos Pasos: Expandiendo el Soporte de Idiomas e Integración con AWS Sagemaker
jina-embeddings-v2-base-zh estará pronto disponible a través de AWS Sagemaker y Hugging Face.



En Jina AI, nuestro compromiso de ser líderes en tecnología de embedding asequible y accesible para una audiencia global es inquebrantable. Estamos desarrollando activamente ofertas multilingües adicionales, enfocándonos en los principales idiomas europeos y otros internacionales, para ampliar nuestro alcance. Mantente atento a estas emocionantes actualizaciones, incluyendo la integración con AWS SageMaker, mientras continuamos expandiendo nuestras capacidades.
tagUn Agradecimiento Especial a Nuestros Primeros Probadores
Estamos inmensamente agradecidos con los miembros seleccionados de nuestra comunidad de usuarios chinos que probaron la versión preliminar (jina-embeddings-v2-base-zh-preview). Sus valiosos comentarios fueron cruciales para mejorar el rendimiento de esta versión oficial. Si tienes observaciones o sugerencias sobre la calidad de nuestros modelos, te invitamos cordialmente a unirte a nuestro servidor de Discord y compartir tus pensamientos con nosotros. Tu opinión es invaluable en nuestro viaje de mejora continua.


Distribución de Puntuación Mejorada vs. jina-embeddings-v2-base-zh-preview
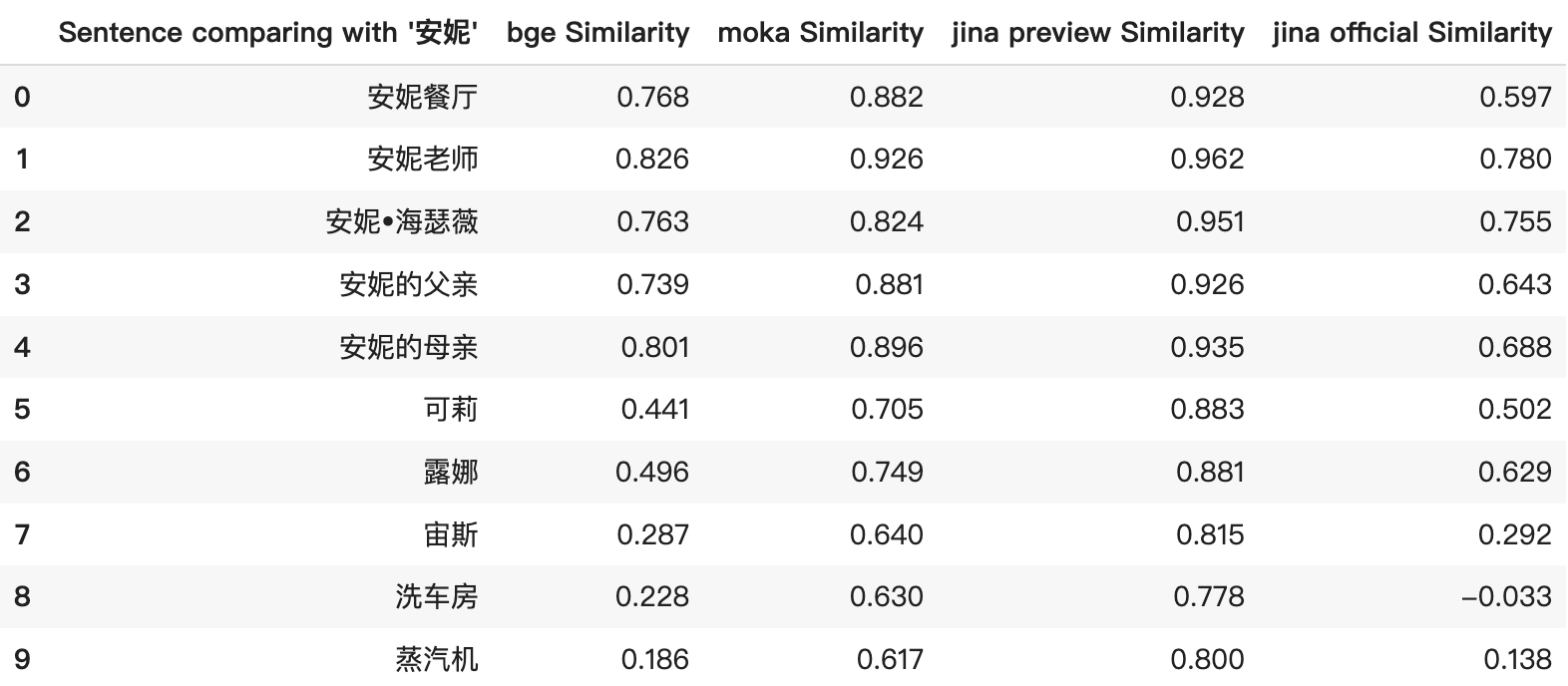
jina-embeddings-v2-base-zh-preview sufría de puntuaciones de similitud infladas, produciendo altos puntajes de coseno incluso para elementos no relacionados. Esto era particularmente evidente en los 5 primeros resultados de la captura de pantalla a continuación. Las puntuaciones de similitud eran consistentemente altas y no reflejaban con precisión la verdadera relación entre elementos. Por ejemplo, la comparación entre "安妮" y "蒸汽机" recibió puntuaciones de similitud engañosamente altas.
En la versión oficial, hemos ajustado el modelo para producir puntuaciones de similitud más distintivas y lógicas, asegurando una representación más precisa de las relaciones entre elementos. Por ejemplo, la puntuación revisada ahora presenta un rango más amplio, ofreciendo una visión más clara de la similitud relativa entre elementos.
Además, Jina Embeddings ahora se destaca como el único modelo de embeddings de código abierto que soporta 8192 tokens. Esta característica resalta su capacidad para procesar una amplia variedad de tipos de datos, desde documentos extensos hasta frases breves, o incluso palabras/nombres individuales como "安妮" vs "露娜".
tag¡Nuevo modelo bilingüe chino-inglés de vectores 8K, imprescindible para empresas con expansión global!
Después de recibir elogios generalizados por nuestro Embeddings V2, hoy lanzamos nuestro nuevo modelo de vectores de texto bilingüe chino-inglés: jina-embeddings-v2-base-zh. Este modelo no solo hereda todas las ventajas de V2, pudiendo procesar textos de hasta ocho mil tokens, sino que también maneja contenido bilingüe chino-inglés con fluidez, dando alas a las aplicaciones multilingües.
El excelente rendimiento de jina-embeddings-v2-base-zh se debe a un conjunto de datos bilingüe de alta calidad y a nuestro riguroso y equilibrado proceso de pre-entrenamiento, ajuste fino de primer orden y ajuste fino de segundo orden. Este enfoque de tres pasos no solo generaliza las capacidades bilingües del modelo, sino que también reduce eficazmente el sesgo del modelo, resolviendo el problema común de "desequilibrio" que enfrentan los modelos multilingües.
tagCaracterísticas destacadas del modelo
Característica 1: Integración bilingüe perfecta
El modelo jina-embeddings-v2-base-zh puede procesar textos en chino e inglés sin problemas, ya sea como consultas de búsqueda o documentos objetivo. Los contenidos con significados similares en chino e inglés se mapean al mismo espacio vectorial, estableciendo una base sólida para aplicaciones multilingües.
Característica 2: Soporte para textos extra largos de 8k Tokens
Nuestro modelo admite el procesamiento de textos de hasta 8K Tokens, una característica única entre los modelos de vectores de código abierto, ofreciendo una ventaja significativa en el procesamiento de párrafos más largos.
Característica 3: Estructura del modelo eficiente y compacta
El modelo jina-embeddings-v2-base-zh, con un tamaño ligero de 322MB (incluyendo 161 millones de parámetros) y una dimensión de salida de 768, puede ejecutarse eficientemente en hardware de computadora común sin necesidad de GPU, mejorando enormemente su practicidad y conveniencia.
tagRendimiento excepcional del modelo
En la competitiva clasificación CMTEB, nuestro modelo Jina Embeddings v2 destaca en la categoría de modelos por debajo de 0.5GB, no solo admitiendo texto en chino e inglés, sino también procesando textos de hasta 8K Tokens, una capacidad rara entre modelos similares.
Entre los modelos de tamaño similar que admiten chino, Multilingual E5 y nuestro jina-embeddings-v2-base-zh son los únicos dos modelos que pueden procesar inglés, haciendo posibles las aplicaciones multilingües.
Actualmente, a nivel mundial, solo el modelo cerrado text-embedding-ada-002 de OpenAI y Jina Embeddings pueden admitir entrada de texto largo de 8k Tokens. En cuanto al procesamiento de tareas en chino, Jina Embeddings muestra ventajas significativas de rendimiento.
tagApoyo a las empresas chinas en la expansión global
Nuestro modelo de vectores bilingüe chino-inglés jina-embeddings-v2-base-zh es un poderoso aliado para las empresas chinas que buscan expandirse en mercados internacionales. Puede procesar texto bilingüe chino-inglés sin problemas, proporcionar representaciones vectoriales de texto de alta calidad e integrarse fácilmente en bases de datos vectoriales avanzadas, sistemas de búsqueda y aplicaciones RAG.
Este modelo es especialmente adecuado para crear aplicaciones de IA adaptadas a escenarios bilingües chino-inglés, y su valor es incalculable para las empresas que buscan un desarrollo global. Aquí hay algunos casos de aplicación práctica:
- Análisis y gestión de documentos: Analizar y gestionar documentos masivos para facilitar transacciones legales y comerciales internacionales.
- Aplicaciones de búsqueda impulsadas por IA: mejora del rendimiento de búsqueda en entornos multilingües, ayudando a usuarios globales a encontrar fácilmente información en chino e inglés.
- Chatbots y sistemas de preguntas y respuestas mejorados: creación de chatbots de servicio al cliente bilingües eficientes, optimizando la experiencia de comunicación con clientes globales.
- Aplicaciones de procesamiento del lenguaje natural: incluye modelado temático para análisis de tendencias de mercado global y estrategias de mercado internacional, así como clasificación de texto para gestión de comunicaciones globales.
- Sistemas de recomendación: utilización de insights de datos en chino e inglés para ofrecer recomendaciones personalizadas de productos y contenido a audiencias globales diversas.
Con este modelo, las empresas chinas pueden superar las barreras lingüísticas en aplicaciones de IA y tomar la delantera en la competencia del mercado global.
tagEmpezar fácilmente con jina-embeddings-v2-base-zh
¿Quiere integrar rápidamente nuestro modelo de vectores bilingüe en su flujo de trabajo? Solo necesita unos simples pasos: visite https://jina.ai/embeddings, obtenga su clave API gratuita o actualice la existente, luego seleccione jina-embeddings-v2-base-zh en el menú desplegable, ¡y su modelo estará listo para explorar y usar!
tagMirando al futuro: Soporte multilingüe e integración profunda con AWS SageMaker
jina-embeddings-v2-base-zh estará pronto disponible en AWS SageMaker y HuggingFace, proporcionando un servicio más conveniente para los usuarios.
Estamos trabajando activamente en modelos de vectores multilingües, especialmente en el soporte para idiomas europeos y otros internacionales, para satisfacer las diversas necesidades de los usuarios globales. Estén atentos a nuestras emocionantes actualizaciones próximas, incluyendo la integración profunda con AWS SageMaker, mientras continuamos profundizando y ampliando nuestro alcance de servicios.
tagAgradecimientos: Gracias por las valiosas contribuciones de los primeros probadores
Agradecemos sinceramente a los miembros de la comunidad china que participaron en las pruebas de jina-embeddings-v2-base-zh-preview. Sus valiosos comentarios jugaron un papel importante en la optimización de nuestro modelo. Si tiene alguna sugerencia o idea durante el uso, no dude en compartirla con nosotros. Cada uno de sus comentarios es el motor de nuestra mejora continua.
La versión oficial resuelve el problema de inflación de puntuaciones de la versión preliminar
En comparación con la versión preliminar anterior, el modelo oficial proporciona puntuaciones de similitud más dispersas y razonables. Durante las pruebas de la versión preliminar, nuestro modelo mostró un fenómeno de inflación en las puntuaciones de similitud, donde incluso palabras completamente no relacionadas, como 'Annie' y 'máquina de vapor', obtenían una alta similitud de coseno. En la versión oficial, hemos optimizado el modelo para garantizar que las puntuaciones de similitud sean más razonables, reflejando así con mayor precisión las relaciones entre contenidos.
Además, Jina Embeddings ahora admite el procesamiento de texto de hasta 8192 Tokens, demostrando su potente capacidad para manejar varios tipos de datos, ya sean largos ensayos, frases cortas o incluso palabras o nombres individuales (como la comparación entre "Annie" y "Luna"). Esta mejora no solo aumenta la precisión del modelo, sino que también mejora su flexibilidad y utilidad al manejar datos diversos.
