


Uno de los problemas persistentes de los modelos de IA es que las redes neuronales no explican cómo producen sus resultados. No siempre está claro cuánto es esto un problema real para la inteligencia artificial. Cuando pedimos a los humanos que expliquen su razonamiento, habitualmente racionalizan, típicamente sin ser conscientes de que lo están haciendo, dando las explicaciones más plausibles sobre sí mismos sin ninguna indicación de lo que realmente está sucediendo en sus mentes.
Ya sabemos cómo hacer que los modelos de IA inventen respuestas plausibles. Quizás la inteligencia artificial es más parecida a los humanos en ese aspecto de lo que nos gustaría admitir.
Hace cincuenta años, el filósofo estadounidense Thomas Nagel escribió un influyente ensayo llamado ¿Qué se siente ser un murciélago? Sostenía que debe haber algo que se siente al ser un murciélago: Ver el mundo como lo ve un murciélago y percibir la existencia como lo hace un murciélago. Sin embargo, según Nagel, incluso si conociéramos cada hecho cognoscible sobre cómo funcionan los cerebros, sentidos y cuerpos de los murciélagos, aún no sabríamos qué se siente ser un murciélago.
La explicabilidad de la IA es el mismo tipo de problema. Conocemos cada hecho que hay que saber sobre un modelo de IA dado. Es solo una gran cantidad de números de precisión finita organizados en una secuencia de matrices. Podemos verificar trivialmente que cada salida del modelo es el resultado de una aritmética correcta, pero esa información es inútil como explicación.
No hay una solución general para este problema en la IA más que la que hay para los humanos. Sin embargo, la arquitectura ColBERT, y particularmente cómo utiliza la "interacción tardía" cuando se usa como reordenador, te permite obtener perspectivas significativas de tus modelos sobre por qué da resultados específicos en casos particulares.
Este artículo te muestra cómo la interacción tardía permite la explicabilidad, usando el modelo Jina-ColBERT jina-colbert-v1-en y la biblioteca Python Matplotlib.
tagUna Breve Descripción de ColBERT
ColBERT fue introducido en Khattab & Zaharia (2020) como una extensión del modelo BERT presentado inicialmente en 2018 por Google. Los modelos Jina-ColBERT de Jina AI se basan en este trabajo y en la arquitectura posterior ColBERT v2 propuesta en Santhanam, et al. (2021). Los modelos tipo ColBERT pueden usarse para crear embeddings, pero tienen algunas características adicionales cuando se usan como modelo de reordenamiento. El principal beneficio es la interacción tardía, que es una forma de estructurar el problema de similitud semántica de texto diferente a los modelos de embedding estándar.
tagModelos de Embedding
En un modelo de embedding tradicional, comparamos dos textos generando vectores representativos para ellos llamados embeddings, y luego comparamos esos embeddings mediante métricas de distancia como coseno o distancia de Hamming. Cuantificar la similitud semántica de dos textos generalmente sigue un procedimiento común.
Primero, creamos embeddings para los dos textos por separado. Para cada texto:
- Un tokenizador divide el texto en fragmentos aproximadamente del tamaño de palabras.
- Cada token se mapea a un vector.
- Los vectores de tokens interactúan a través del sistema de atención y capas de convolución, añadiendo información de contexto a la representación de cada token.
- Una capa de pooling transforma estos vectores de tokens modificados en un único vector de embedding.
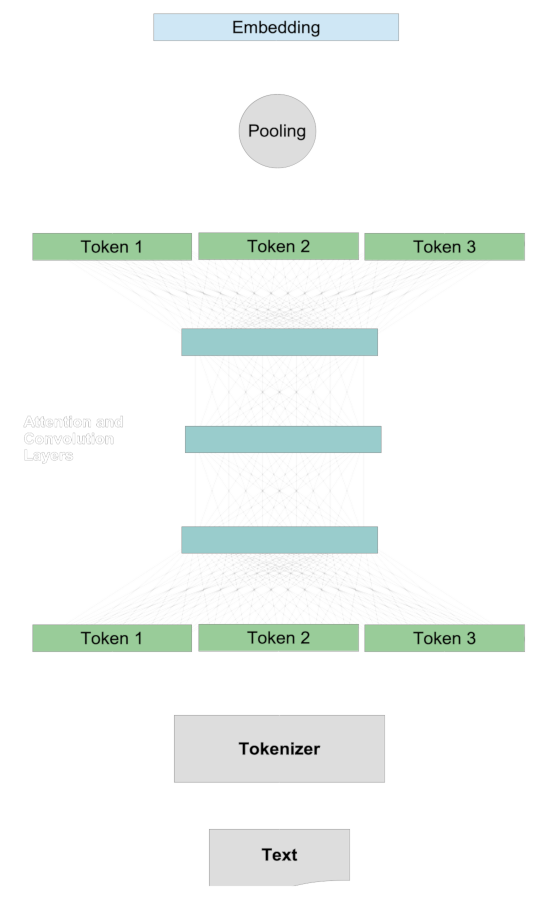
Luego, cuando hay un embedding para cada texto, los comparamos entre sí, típicamente usando la métrica del coseno o la distancia de Hamming.
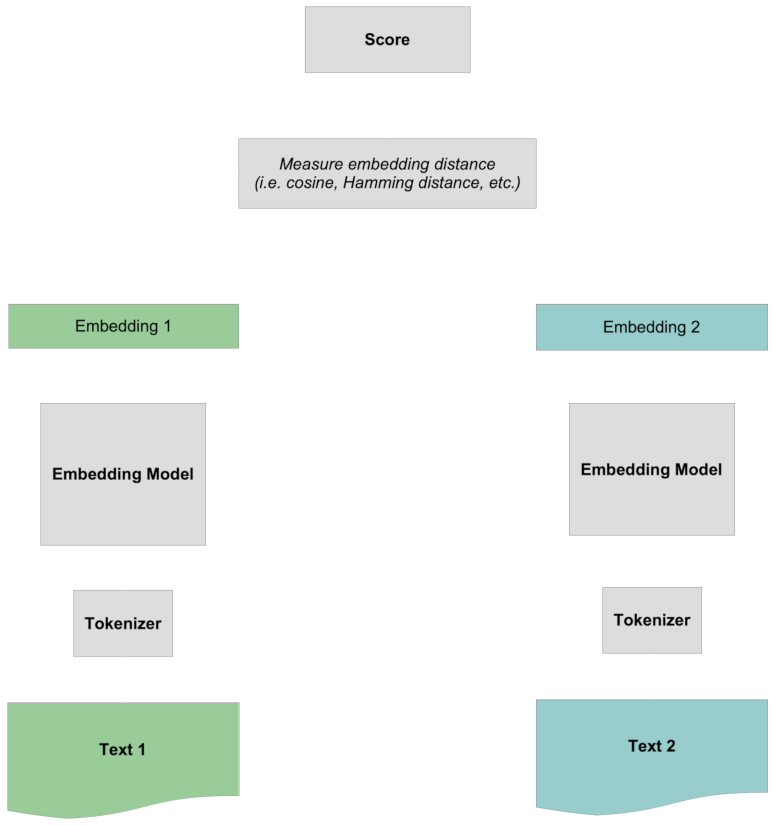
La puntuación ocurre comparando los dos embeddings completos entre sí, sin ninguna información específica sobre los tokens. Toda la interacción entre tokens es "temprana" ya que ocurre antes de que los dos textos se comparen entre sí.
tagModelos de Reordenamiento
Los modelos de reordenamiento funcionan de manera diferente.
Primero, en lugar de crear un embedding para cualquier texto, toma un texto, llamado consulta, y una colección de otros textos que llamaremos documentos objetivo y luego puntúa cada documento objetivo con respecto al texto de consulta. Estos números no están normalizados y no son como comparar embeddings, pero se pueden ordenar. Los documentos objetivo que obtienen la puntuación más alta con respecto a la consulta son los textos que están más relacionados semánticamente con la consulta según el modelo.
Veamos cómo funciona esto concretamente con el modelo reordenador jina-colbert-v1-en, usando la API de Jina Reranker y Python.
El código siguiente también está en un notebook que puedes descargar o ejecutar en Google Colab.
Primero deberías instalar la versión más reciente de la biblioteca requests en tu entorno Python. Puedes hacerlo con el siguiente comando:
pip install requests -U
A continuación, visita la página de la API de Jina Reranker y obtén un token API gratuito, válido para hasta un millón de tokens de procesamiento de texto. Copia la clave del token API de la parte inferior de la página, como se muestra a continuación:
Usaremos el siguiente texto de consulta:
- "Elephants eat 150 kg of food per day."
Y compararemos esta consulta con tres textos:
- "Elephants eat 150 kg of food per day."
- "Every day, the average elephant consumes roughly 150 kg of plants."
- "The rain in Spain falls mainly on the plain."
El primer documento es idéntico a la consulta, el segundo es una reformulación del primero, y el último texto es completamente no relacionado.
Usa el siguiente código Python para obtener las puntuaciones, asignando tu token API de Jina Reranker a la variable jina_api_key:
import requests
url = "<https://api.jina.ai/v1/rerank>"
jina_api_key = "<YOUR JINA RERANKER API TOKEN HERE>"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {jina_api_key}"
}
data = {
"model": "jina-colbert-v1-en",
"query": "Elephants eat 150 kg of food per day.",
"documents": [
"Elephants eat 150 kg of food per day.",
"Every day, the average elephant consumes roughly 150 kg of food.",
"The rain in Spain falls mainly on the plain.",
],
"top_n": 3
}
response = requests.post(url, headers=headers, json=data)
for item in response.json()['results']:
print(f"{item['relevance_score']} : {item['document']['text']}")
Ejecutar este código desde un archivo Python o en un notebook debería producir el siguiente resultado:
11.15625 : Elephants eat 150 kg of food per day.
9.6328125 : Every day, the average elephant consumes roughly 150 kg of food.
1.568359375 : The rain in Spain falls mainly on the plain.
La coincidencia exacta tiene la puntuación más alta, como esperaríamos, mientras que la reformulación tiene la segunda más alta, y un texto completamente no relacionado tiene una puntuación mucho más baja.
tagPuntuación usando ColBERT
Lo que hace que el reordenamiento ColBERT sea diferente de la puntuación basada en embeddings es que los tokens de los dos textos se comparan entre sí durante el proceso de puntuación. Los dos textos nunca tienen sus propios embeddings.
Primero, usamos la misma arquitectura que los modelos de embedding para crear nuevas representaciones para cada token que incluyen información de contexto del texto. Luego, comparamos cada token de la consulta con cada token del documento.
Para cada token en la consulta, identificamos el token en el documento que tiene la interacción más fuerte con él, y sumamos esos puntajes de interacción para calcular un valor numérico final.
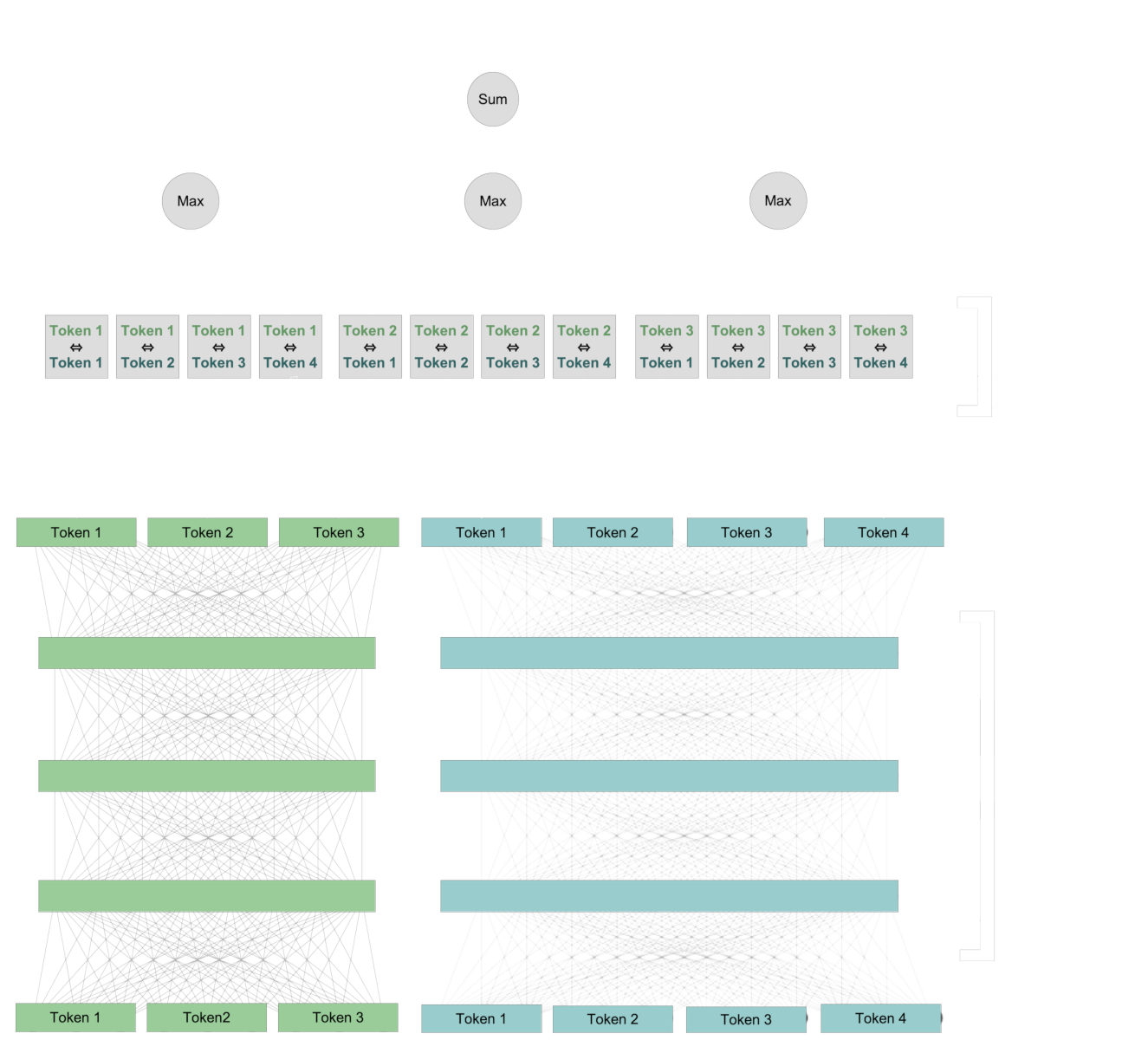
Esta interacción es "tardía": los tokens interactúan entre los dos textos cuando los comparamos entre sí. Pero recuerda, la interacción "tardía" no excluye la interacción "temprana". Los pares de vectores de tokens que se comparan ya contienen información sobre sus contextos específicos.
Este esquema de interacción tardía preserva la información a nivel de token, incluso si esa información es específica del contexto. Esto nos permite ver, en parte, cómo el modelo ColBERT calcula su puntuación porque podemos identificar qué pares de tokens contextualizados contribuyen a la puntuación final.
tagExplicando los Rankings con Mapas de Calor
Los mapas de calor son una técnica de visualización útil para ver qué está sucediendo en Jina-ColBERT cuando crea puntuaciones. En esta sección, usaremos las bibliotecas seaborn y matplotlib para crear mapas de calor desde la capa de interacción tardía de jina-colbert-v1-en, mostrando cómo los tokens de consulta interactúan con cada token del texto objetivo.
tagConfiguración
Hemos creado un archivo de biblioteca Python que contiene el código para acceder al modelo jina-colbert-v1-en y usar seaborn, matplotlib y Pillow para crear mapas de calor. Puedes descargar esta biblioteca directamente desde GitHub, o usar el notebook proporcionado en tu propio sistema, o en Google Colab.
Primero, instala los requisitos. Necesitarás la última versión de la biblioteca requests en tu entorno Python. Así que, si aún no lo has hecho, ejecuta:
pip install requests -U
Luego, instala las bibliotecas principales:
pip install matplotlib seaborn torch Pillow
A continuación, descarga jina_colbert_heatmaps.py desde GitHub. Puedes hacerlo a través de un navegador web o desde la línea de comandos si tienes instalado wget:
wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/heatmaps/jina_colbert_heatmaps.py
Con las bibliotecas instaladas, solo necesitamos declarar una función para el resto de este artículo:
from jina_colbert_heatmaps import JinaColbertHeatmapMaker
def create_heatmap(query, document, figsize=None):
heat_map_maker = JinaColbertHeatmapMaker(jina_api_key=jina_api_key)
# get token embeddings for the query
query_emb = heat_map_maker.embed(query, is_query=True)
# get token embeddings for the target document
document_emb = heat_map_maker.embed(document, is_query=False)
return heat_map_maker.compute_heatmap(document_emb[0], query_emb[0], figsize)
tagResultados
Ahora que podemos crear mapas de calor, hagamos algunos y veamos qué nos dicen.
Ejecuta el siguiente comando en Python:
create_heatmap("Elephants eat 150 kg of food per day.", "Elephants eat 150 kg of food per day.")El resultado será un mapa de calor que se verá así:
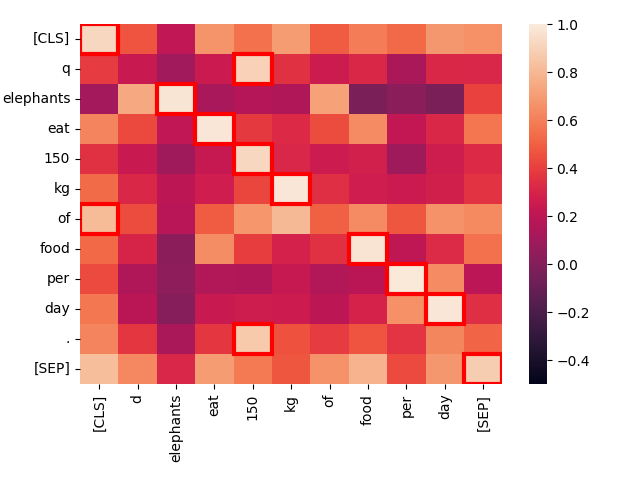
Este es un mapa de calor de los niveles de activación entre pares de tokens cuando comparamos dos textos idénticos. Cada cuadrado muestra la interacción entre dos tokens, uno de cada texto. Los tokens adicionales [CLS] y [SEP] indican el principio y el final del texto respectivamente, y q y d se insertan justo después del token [CLS] en consultas y documentos objetivo respectivamente. Esto permite que el modelo tenga en cuenta las interacciones entre tokens y el principio y final de los textos, pero también permite que las representaciones de tokens sean sensibles a si están en consultas u objetivos.
Cuanto más brillante sea el cuadrado, más interacción hay entre los dos tokens, lo que indica que están semánticamente relacionados. La puntuación de interacción de cada par de tokens está en el rango de -1.0 a 1.0. Los cuadrados resaltados por un marco rojo son los que cuentan para la puntuación final: Para cada token en la consulta, su nivel de interacción más alto con cualquier token del documento es el valor que cuenta.
Las mejores coincidencias — los puntos más brillantes — y los valores máximos enmarcados en rojo están casi todos exactamente en la diagonal, y tienen una interacción muy fuerte. Las únicas excepciones son los tokens "técnicos" [CLS], q, y d, así como la palabra "of" que es una "palabra vacía" de alta frecuencia en inglés que lleva muy poca información independiente.
Tomemos una oración estructuralmente similar — "Cats eat 50 g of food per day." — y veamos cómo interactúan los tokens:
create_heatmap("Elephants eat 150 kg of food per day.", "Cats eat 50 g of food per day.")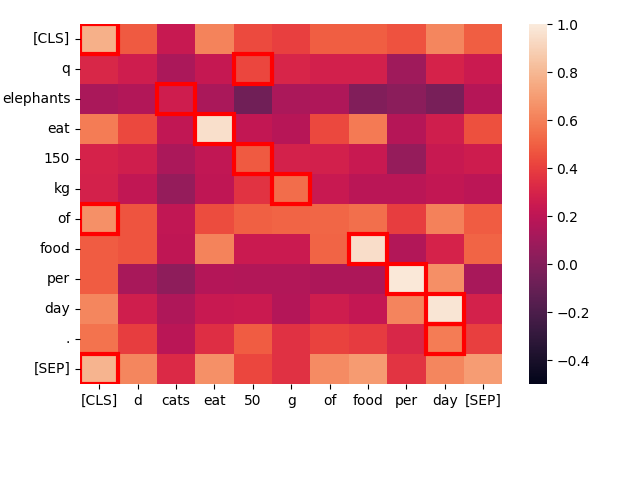
Una vez más, las mejores coincidencias están principalmente en la diagonal porque las palabras son frecuentemente las mismas y la estructura de la oración es casi idéntica. Incluso "cats" y "elephants" coinciden, debido a sus contextos comunes, aunque no muy bien.
Cuanto menos similar es el contexto, peor es la coincidencia. Considera el texto "Employees eat at the company canteen."
create_heatmap("Elephants eat 150 kg of food per day.", "Employees eat at the company canteen.")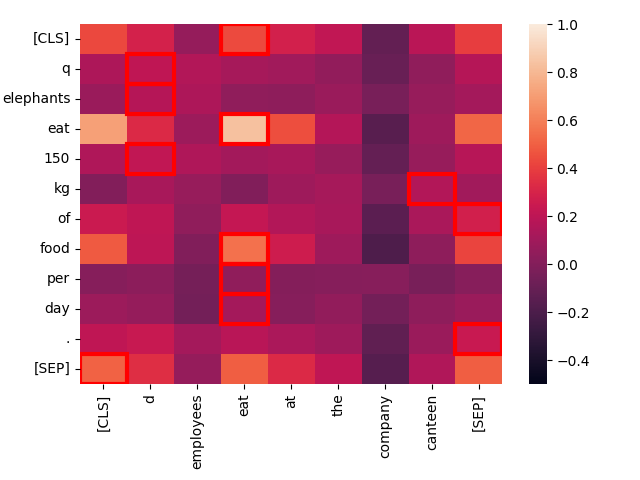
Aunque estructuralmente similar, la única coincidencia fuerte aquí es entre las dos instancias de "eat". Temáticamente, estas son oraciones muy diferentes, incluso si sus estructuras son altamente paralelas.
Observando la oscuridad de los colores en los cuadrados enmarcados en rojo, podemos ver cómo el modelo las clasificaría como coincidencias para "Elephants eat 150 kg of food per day", y jina-colbert-v1-en confirma esta intuición:
| Score | Text |
|---|---|
| 11.15625 | Elephants eat 150 kg of food per day. |
| 8.3671875 | Cats eat 50 g of food per day. |
| 3.734375 | Employees eat at the company canteen. |
Ahora, comparemos "Elephants eat 150 kg of food per day." con una oración que tiene esencialmente el mismo significado pero una formulación diferente: "Every day, the average elephant consumes roughly 150 kg of food."
create_heatmap("Elephants eat 150 kg of food per day.", "Every day, the average elephant consumes roughly 150 kg of food.")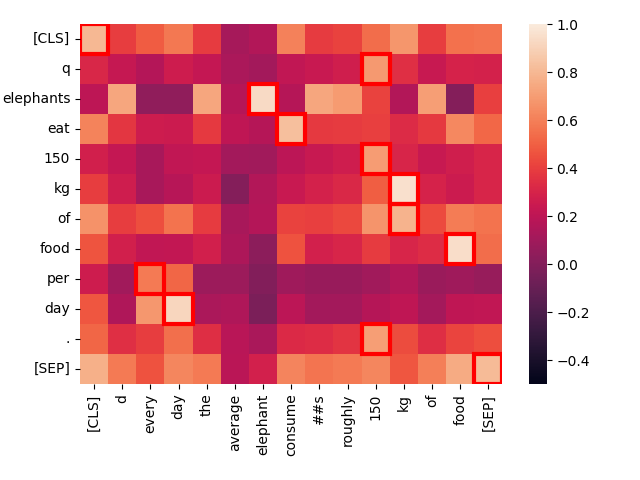
Observe la fuerte interacción entre "eat" en la primera oración y "consume" en la segunda. La diferencia en el vocabulario no impide que Jina-ColBERT reconozca el significado común.
Además, "every day" coincide fuertemente con "per day", aunque estén en lugares completamente diferentes. Solo la palabra de bajo valor "of" es una coincidencia anómala.
Ahora, comparemos la misma consulta con un texto totalmente no relacionado: "The rain in Spain falls mainly on the plain."
create_heatmap("Elephants eat 150 kg of food per day.", "The rain in Spain falls mainly on the plain.")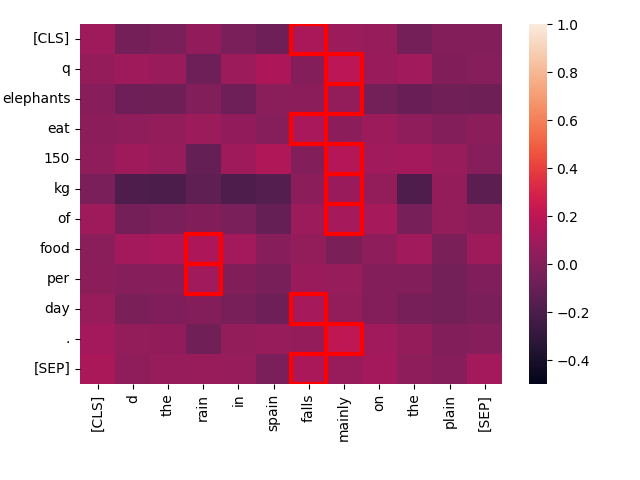
Puede ver que las interacciones de "mejor coincidencia" tienen una puntuación mucho más baja para este par, y hay muy poca interacción entre las palabras de los dos textos. Intuitivamente, esperaríamos que obtuviera una puntuación baja en comparación con "Every day, the average elephant consumes roughly 150 kg of food", y jina-colbert-v1-en está de acuerdo:
| Score | Text |
|---|---|
| 9.6328125 | Every day, the average elephant consumes roughly 150 kg of food. |
| 1.568359375 | The rain in Spain falls mainly on the plain. |
tagTextos largos
Estos son ejemplos sencillos para demostrar el funcionamiento de los modelos de reclasificación estilo ColBERT. En contextos de recuperación de información, como la generación aumentada por recuperación, las consultas tienden a ser textos cortos mientras que los documentos candidatos a coincidir tienden a ser más largos, a menudo tan largos como la ventana de contexto de entrada del modelo.
Los modelos Jina-ColBERT admiten contextos de entrada de 8192 tokens, equivalentes a aproximadamente 16 páginas estándar de texto a espacio simple.
También podemos generar mapas de calor para estos casos asimétricos. Por ejemplo, tomemos la primera sección de la página de Wikipedia sobre Elefantes Indios:
Para ver esto como texto plano, como se pasa a jina-colbert-v1-en, haga clic en este enlace.
Este texto tiene 364 palabras, por lo que nuestro mapa de calor no se verá muy cuadrado:
create_heatmap("Elephants eat 150 kg of food per day.", wikipedia_elephants, figsize=(50,7))
Vemos que "elephants" coincide en muchos lugares del texto. Esto no es sorprendente en un texto sobre elefantes. Pero también podemos ver un área donde hay una interacción mucho más fuerte:
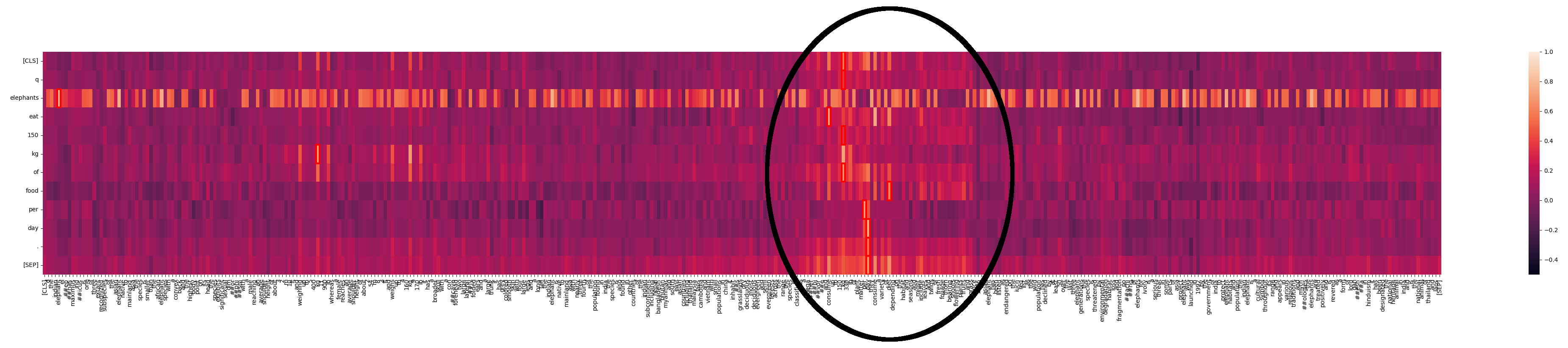
¿Qué está pasando aquí? Con Jina-ColBERT, podemos encontrar la parte del texto más largo que corresponde a esto. Resulta que es la cuarta oración del segundo párrafo:
The species is classified as a megaherbivore and consume up to 150 kg (330 lb) of plant matter per day.
Esto reafirma la misma información que en el texto de consulta. Si miramos el mapa de calor solo para esta oración, podemos ver las coincidencias fuertes:
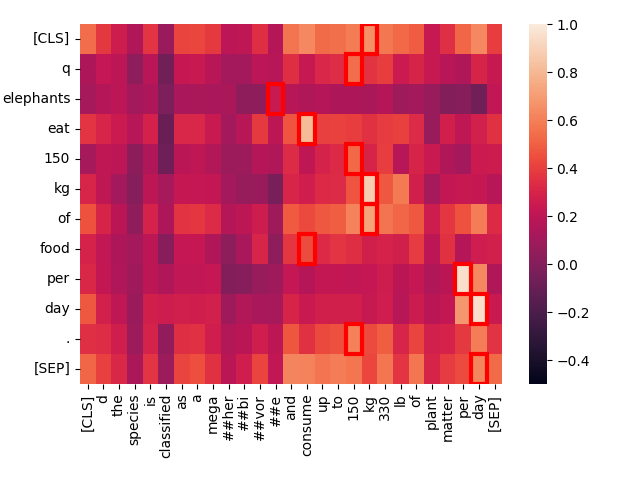
Jina-ColBERT te proporciona los medios para ver exactamente qué áreas en un texto largo causaron que coincidiera con la consulta. Esto lleva a una mejor depuración, pero también a una mayor explicabilidad. No se necesita ninguna sofisticación para ver cómo se hace una coincidencia.
tagExplicando los resultados de IA con Jina-ColBERT
Los embeddings son una tecnología central en la IA moderna. Casi todo lo que hacemos se basa en la idea de que las relaciones complejas y aprendibles en los datos de entrada pueden expresarse en la geometría de espacios de alta dimensión. Sin embargo, es muy difícil para los simples humanos dar sentido a las relaciones espaciales en miles a millones de dimensiones.
ColBERT es un paso atrás desde ese nivel de abstracción. No es una respuesta completa al problema de explicar lo que hace un modelo de IA, pero nos señala directamente qué partes de nuestros datos son responsables de nuestros resultados.
A veces, la IA tiene que ser una caja negra. Las matrices gigantes que hacen todo el trabajo pesado son demasiado grandes para que cualquier humano las mantenga en su cabeza. Pero la arquitectura ColBERT ilumina un poco la caja y demuestra que es posible más.
El modelo Jina-ColBERT está actualmente disponible solo para inglés (jina-colbert-v1-en) pero más idiomas y contextos de uso están en camino. Esta línea de modelos, que no solo realiza recuperación de información de última generación sino que también puede decirte por qué coincidió algo, demuestra el compromiso de Jina AI de hacer que las tecnologías de IA sean tanto accesibles como útiles.
