


Una noche, un policía encuentra a un hombre ebrio gateando sobre sus manos y rodillas bajo una farola. El hombre ebrio le dice al oficial que está buscando su billetera. Cuando el oficial le pregunta si está seguro de que este es el lugar donde se le cayó la billetera, el hombre responde que probablemente se le cayó al otro lado de la calle. Entonces, ¿por qué está buscando aquí?, pregunta el oficial desconcertado. Porque aquí hay mejor luz, explica el hombre ebrio.
David H. Friedman, Why Scientific Studies Are So Often Wrong: The Streetlight Effect, Revista Discover, Dic. 2010
Los benchmarks son un componente fundamental de las prácticas modernas de machine learning y lo han sido durante algún tiempo, pero tienen un problema muy serio: No podemos determinar si nuestros benchmarks miden algo útil.
Este es un gran problema, y este artículo presentará parte de una solución: El AIR-Bench. Este proyecto conjunto con la Beijing Academy of Artificial Intelligence es un enfoque novedoso para las métricas de IA diseñado para mejorar la calidad y utilidad de nuestros benchmarks.


tagEl Efecto Farola
La investigación científica y operativa pone mucho énfasis en las mediciones, pero las mediciones no son algo simple. En un estudio de salud, podrías querer saber si algún medicamento o tratamiento hizo que los receptores estuvieran más sanos, vivieran más tiempo o mejoraran su condición de alguna manera. Pero la salud y la mejora en la calidad de vida son cosas difíciles de medir directamente, y puede llevar décadas averiguar si un tratamiento extendió la vida de alguien.
Así que los investigadores usan indicadores indirectos. En un estudio de salud, esto podría ser algo como la fuerza física, la reducción del dolor, la disminución de la presión arterial u otra variable que puedas medir fácilmente. Uno de los problemas con la investigación en salud es que el indicador indirecto puede no ser realmente indicativo del mejor resultado de salud que quieres que tenga un medicamento o tratamiento.
Una medición es un indicador indirecto de algo útil que te importa. Puede que no seas capaz de medir esa cosa, así que mides otra cosa, algo que sí puedes medir, que tienes razones para creer que se correlaciona con la cosa útil que realmente te importa.
El enfoque en la medición fue un desarrollo importante de la investigación operativa del siglo XX y ha tenido algunos efectos profundos y positivos. La Gestión de Calidad Total, un conjunto de doctrinas a las que se atribuye el ascenso de Japón al dominio económico en la década de 1980, trata casi completamente sobre la medición constante de variables indirectas y la optimización de prácticas sobre esa base.
Pero un enfoque en la medición plantea algunos problemas conocidos y grandes:
- Una medición puede dejar de ser un buen indicador indirecto cuando tomas decisiones basadas en ella.
- A menudo hay formas de inflar una medida que no mejoran nada, lo que lleva a la posibilidad de hacer trampa o creer que estás progresando al hacer cosas que no están ayudando.
Algunas personas creen que la mayoría de la investigación médica puede estar simplemente equivocada en parte debido a este problema. La desconexión entre las cosas que puedes medir y los objetivos reales es una de las razones citadas para la calamidad de la guerra de Estados Unidos en Vietnam.
Esto a veces se llama el "Efecto Farola", por las historias, como la del principio de esta página, del borracho que busca algo no donde lo perdió, sino donde hay mejor luz. Una medida indirecta es como buscar donde hay luz porque no hay luz sobre la cosa que queremos ver.
En literatura más técnica, el "Efecto Farola" típicamente está vinculado a la Ley de Goodhart, atribuida a las críticas del economista británico Charles Goodhart al gobierno de Thatcher, que había puesto mucho énfasis en medidas indirectas de prosperidad. La Ley de Goodhart tiene varias formulaciones, pero la siguiente es la más citada:
[C]ada medida que se convierte en un objetivo se convierte en una mala medida[…]
Keith Hoskins, 1996 The 'awful idea of accountability': inscribing people into the measurement of objects.
En IA, un ejemplo famoso de esto es la métrica BLEU utilizada en la investigación de traducción automática. Desarrollada en 2001 en IBM, BLEU es una forma de automatizar la evaluación de sistemas de traducción automática, y fue un factor fundamental en el auge de la traducción automática de los años 00. Una vez que fue fácil dar una puntuación a tu sistema, podías trabajar en mejorarlo. Y las puntuaciones BLEU mejoraron consistentemente. Para 2010, era casi imposible que un artículo de investigación sobre traducción automática fuera aceptado en una revista o conferencia si no superaba la puntuación BLEU del estado del arte, sin importar cuán innovador fuera el artículo ni cuán bien pudiera manejar algún problema específico que otros sistemas estaban manejando pobremente.
La forma más fácil de entrar en una conferencia era encontrar alguna forma menor de ajustar los parámetros de tu modelo, obtener una puntuación BLEU fraccionalmente más alta que la de Google Translate, y luego enviar. Estos resultados eran esencialmente inútiles. Solo conseguir algunos textos nuevos para traducir mostraría que raramente eran mejores y frecuentemente peores que el estado del arte.
En lugar de usar BLEU para evaluar el progreso en traducción automática, obtener una mejor puntuación BLEU se convirtió en el objetivo. Tan pronto como eso sucedió, dejó de ser una forma útil de evaluar el progreso.
tag¿Son buenos indicadores nuestros benchmarks de IA?
El benchmark más utilizado para modelos de embedding es el conjunto de pruebas MTEB, que consiste en 56 pruebas específicas. Estas se promedian por categoría y en conjunto para producir una colección de puntuaciones específicas por clase. Al momento de escribir esto, la parte superior de la tabla de clasificación MTEB se ve así:
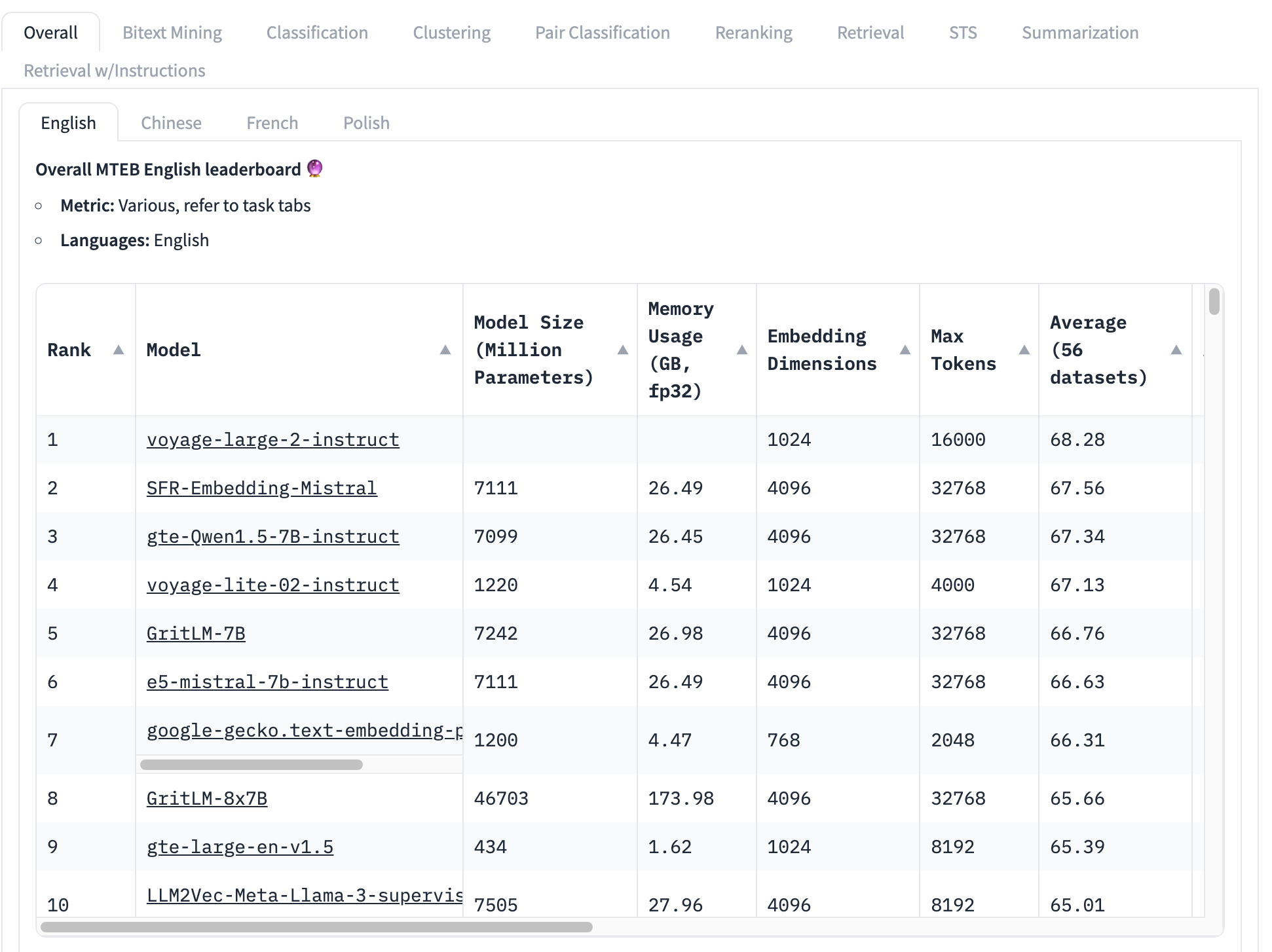
El modelo de embedding mejor clasificado tiene una puntuación promedio general de 68.28, el siguiente más alto es 67.56. Es muy difícil, mirando esta tabla, saber si esa es una gran diferencia o no. Si es una pequeña diferencia, entonces otros factores pueden ser más importantes que cuál modelo tiene la puntuación más alta:
- Tamaño del modelo: Los modelos tienen diferentes tamaños, lo que refleja diferentes demandas de recursos computacionales. Los modelos pequeños se ejecutan más rápido, en menos memoria y requieren hardware menos costoso. Vemos, en esta lista de los 10 mejores, modelos que van desde 434 millones de parámetros hasta más de 46 mil millones — ¡una diferencia de 100 veces!
- Tamaño del embedding: Las dimensiones de embedding varían. Una dimensionalidad más pequeña hace que los vectores de embedding usen menos memoria y almacenamiento y hace que las comparaciones de vectores (el uso principal de embeddings) sean mucho más rápidas. En esta lista, vemos dimensiones de embedding desde 768 hasta 4096 — solo una diferencia de cinco veces pero aún significativa cuando se construyen aplicaciones comerciales.
- Tamaño de la ventana de contexto de entrada: Las ventanas de contexto varían tanto en tamaño como en calidad, desde 2048 tokens hasta 32768. Además, diferentes modelos utilizan diferentes enfoques para la codificación posicional y la gestión de entrada, lo que puede crear sesgos a favor de partes específicas de la entrada.
En resumen, el promedio general es una forma muy incompleta de determinar qué modelo de embedding es mejor.
Incluso si miramos las puntuaciones específicas por tarea, como las de abajo para recuperación, enfrentamos los mismos problemas una y otra vez. No importa cuál sea la puntuación de un modelo en este conjunto de pruebas, no hay manera de saber qué modelos funcionarán mejor para tu caso de uso particular y único.
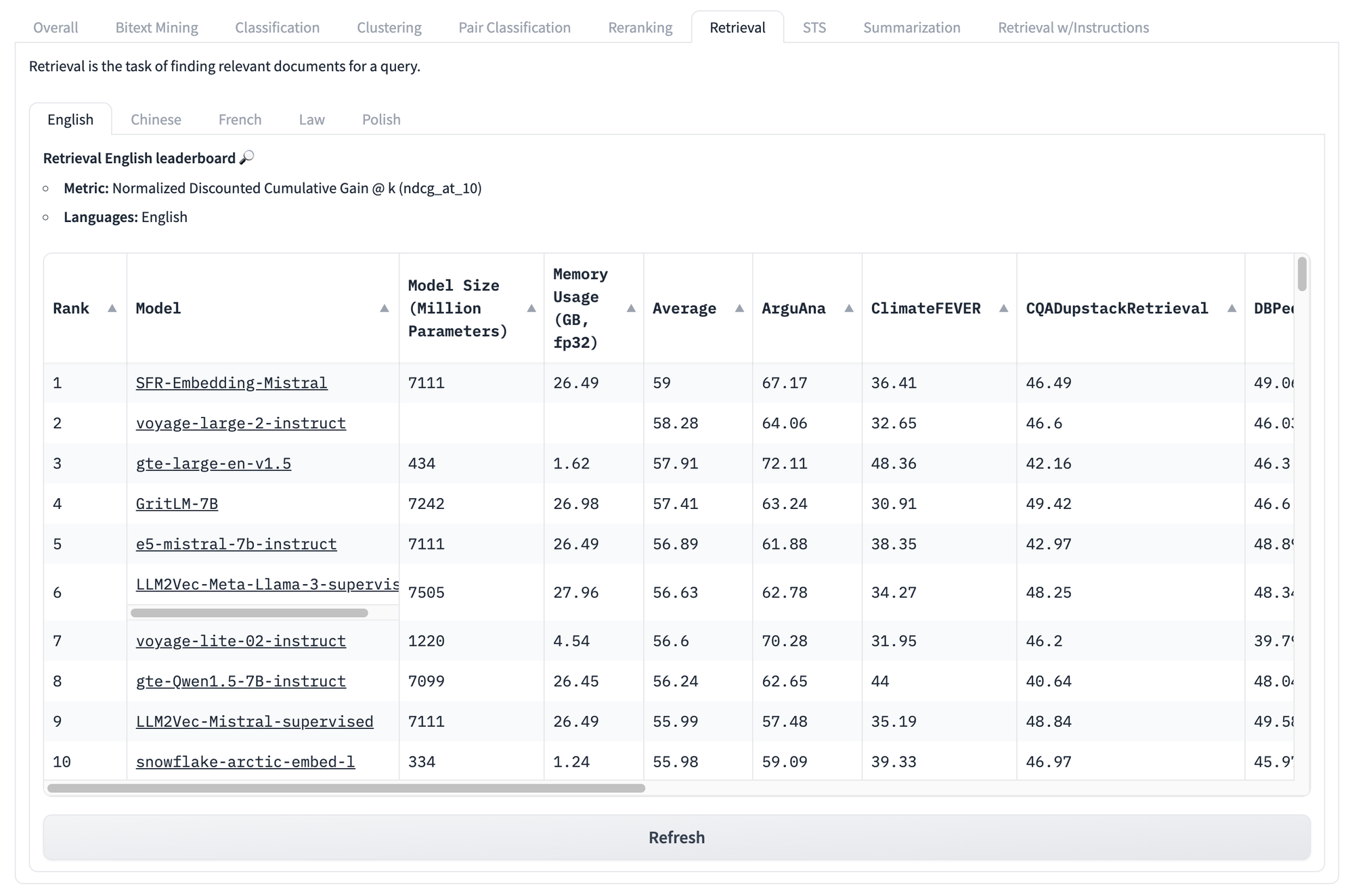
Pero los problemas con este tipo de benchmarks no terminan ahí.
La principal idea de la Ley de Goodhart es que una métrica siempre puede ser manipulada, a menudo sin intención. Por ejemplo, los benchmarks MTEB consisten en datos de fuentes públicas que probablemente estén en tus datos de entrenamiento. A menos que trabajes específicamente para intentar eliminar los datos de benchmarking de tu entrenamiento, tus puntuaciones en los benchmarks serán estadísticamente poco sólidas.
No existe una solución simple y completa. Un benchmark es un proxy y nunca podemos estar seguros de que refleje lo que queremos saber pero no podemos medir directamente.
Sin embargo, vemos tres problemas principales con los benchmarks de IA que podemos mitigar:
- Los benchmarks son fijos por naturaleza: Las mismas tareas, usando los mismos textos.
- Los benchmarks son genéricos: No son muy informativos sobre escenarios reales.
- Los benchmarks son inflexibles: No pueden responder a casos de uso diversos.
La IA crea problemas como este, pero a veces también crea soluciones. Creemos que podemos usar modelos de IA para abordar estos problemas, al menos en lo que afecta a los benchmarks de IA.
tagUsando IA para hacer Benchmark de IA: AIR-Bench
AIR-Bench es de código abierto y está disponible bajo la Licencia MIT. Puedes ver o descargar el código desde su repositorio en GitHub.
 AIR-Bench
AIR-Benchtag¿Qué hace?
AIR-Bench aporta algunas características importantes al benchmarking de IA:
- Especialización para Aplicaciones de Recuperación y RAG
Este benchmark está orientado hacia aplicaciones realistas de recuperación de información y pipelines de generación aumentada por recuperación. - Flexibilidad de Dominio y Lenguaje
AIR hace mucho más fácil crear benchmarks a partir de datos específicos de un dominio o para otro idioma, o incluso a partir de datos específicos de tu propia tarea. - Generación Automatizada de Datos
AIR-Bench genera datos de prueba y el conjunto de datos recibe actualizaciones regulares, reduciendo el riesgo de fuga de datos.
tagTabla de Clasificación de AIR-Bench en HuggingFace
Estamos operando una tabla de clasificación, similar a la de MTEB, para la versión actual de las tareas generadas por AIR-Bench. Regeneraremos regularmente los benchmarks, añadiremos nuevos y ampliaremos la cobertura a más modelos de IA.

tag¿Cómo funciona?
La idea central del enfoque AIR es que podemos usar modelos de lenguaje grandes (LLMs) para generar nuevos textos y nuevas tareas que no pueden estar en ningún conjunto de entrenamiento.
AIR-Bench aprovecha las capacidades creativas de los LLMs pidiéndoles que simulen un escenario. El usuario elige una colección de documentos — una real que puede ser parte de los datos de entrenamiento de algunos modelos — y luego imagina un usuario con un rol definido y una situación en la que necesitaría usar ese corpus de documentos.

Luego, el usuario selecciona un documento del corpus y lo pasa, junto con el perfil del usuario y la descripción de la situación, al LLM. Se le indica al LLM que cree consultas que sean apropiadas para ese usuario y situación y que deberían encontrar ese documento.
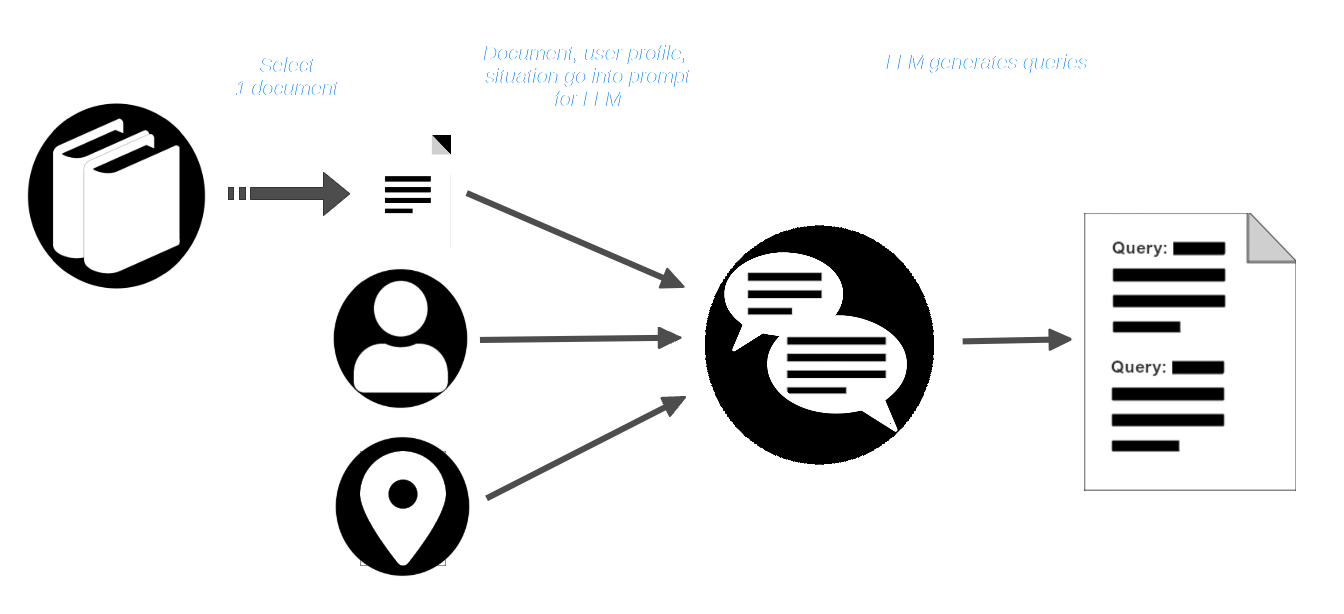
El pipeline de AIR-Bench luego indica al LLM con el documento y la consulta y crea documentos sintéticos que son similares al proporcionado pero que no deberían coincidir con la consulta.
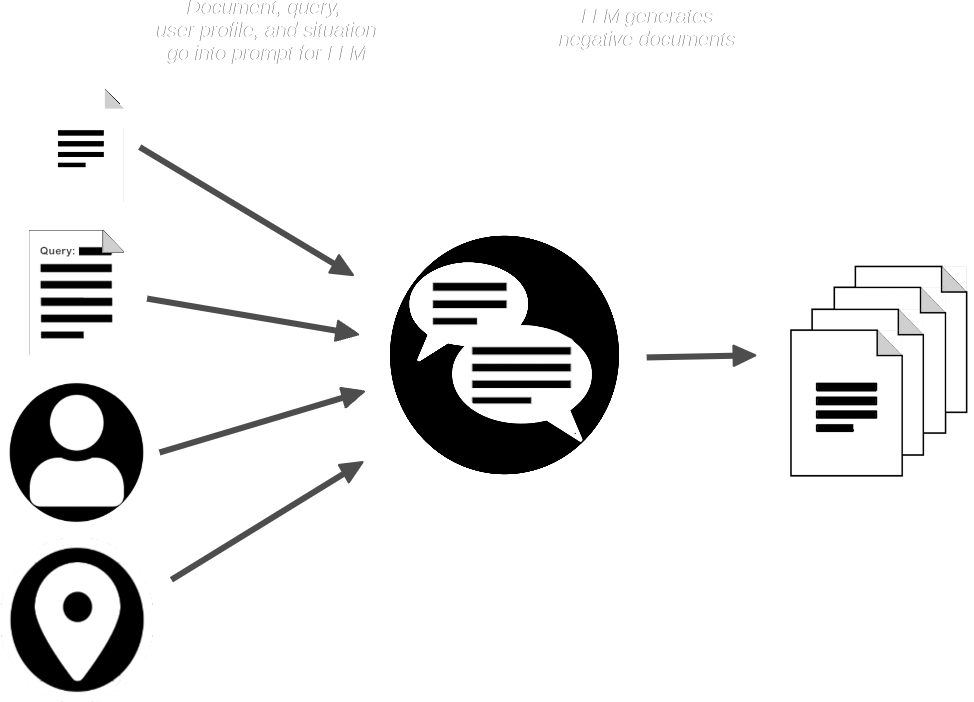
Ahora tenemos:
- Una colección de consultas
- Un documento real coincidente para cada consulta
- Una pequeña colección de documentos sintéticos que se espera que no coincidan
AIR-Bench combina los documentos sintéticos con la colección de documentos reales y luego usa uno o más modelos de embedding y reranking para verificar que las consultas deberían poder recuperar los documentos coincidentes. También usa el LLM para verificar que cada consulta es relevante para los documentos que debería recuperar.
Para más detalles sobre este proceso de generación y control de calidad centrado en IA, lee la documentación de Generación de Datos en el repositorio de AIR-Bench en GitHub.
