



La búsqueda multimodal, que combina texto e imágenes en una experiencia de búsqueda fluida, ha ganado impulso gracias a modelos como CLIP de OpenAI. Estos modelos conectan efectivamente los datos visuales y textuales, permitiéndonos relacionar imágenes con texto relevante y viceversa.
Si bien CLIP y modelos similares son potentes, tienen limitaciones notables, particularmente al procesar textos más largos o manejar relaciones textuales complejas. Aquí es donde entra jina-clip-v1.
Diseñado para abordar estos desafíos, jina-clip-v1 ofrece una mejor comprensión del texto mientras mantiene sólidas capacidades de correspondencia texto-imagen. Proporciona una solución más eficiente para aplicaciones que utilizan ambas modalidades, simplificando el proceso de búsqueda y eliminando la necesidad de alternar entre modelos separados para texto e imágenes.
En esta publicación, exploraremos lo que jina-clip-v1 aporta a las aplicaciones de búsqueda multimodal, mostrando experimentos que demuestran cómo mejora tanto la precisión como la variedad de resultados a través de embeddings integrados de texto e imagen.
tag¿Qué es CLIP?
CLIP (Contrastive Language–Image Pretraining) es una arquitectura de modelo de IA desarrollada por OpenAI que conecta texto e imágenes mediante el aprendizaje de representaciones conjuntas. CLIP es esencialmente un modelo de texto y un modelo de imagen unidos — transforma ambos tipos de entrada en un espacio de embedding compartido, donde textos e imágenes similares se posicionan cerca unos de otros. CLIP fue entrenado con un vasto conjunto de datos de pares imagen-texto, lo que le permite comprender la relación entre contenido visual y textual. Esto le permite generalizar bien a través de diferentes dominios, haciéndolo altamente efectivo en escenarios de aprendizaje zero-shot, como generar subtítulos o recuperación de imágenes.
Desde el lanzamiento de CLIP, otros modelos como SigLiP, LiT, y EvaCLIP han expandido sus fundamentos, mejorando aspectos como la eficiencia del entrenamiento, el escalado y la comprensión multimodal. Estos modelos a menudo aprovechan conjuntos de datos más grandes, arquitecturas mejoradas y técnicas de entrenamiento más sofisticadas para expandir los límites de la alineación texto-imagen, avanzando aún más en el campo de los modelos imagen-lenguaje.
Si bien CLIP puede trabajar solo con texto, enfrenta limitaciones significativas. Primero, fue entrenado solo con subtítulos cortos, no textos largos, manejando un máximo de aproximadamente 77 palabras. Segundo, CLIP sobresale en conectar texto con imágenes pero tiene dificultades al comparar texto con otro texto, como reconocer que las cadenas a crimson fruit y a red apple pueden referirse a lo mismo. Aquí es donde destacan los modelos de texto especializados, como jina-embeddings-v3.
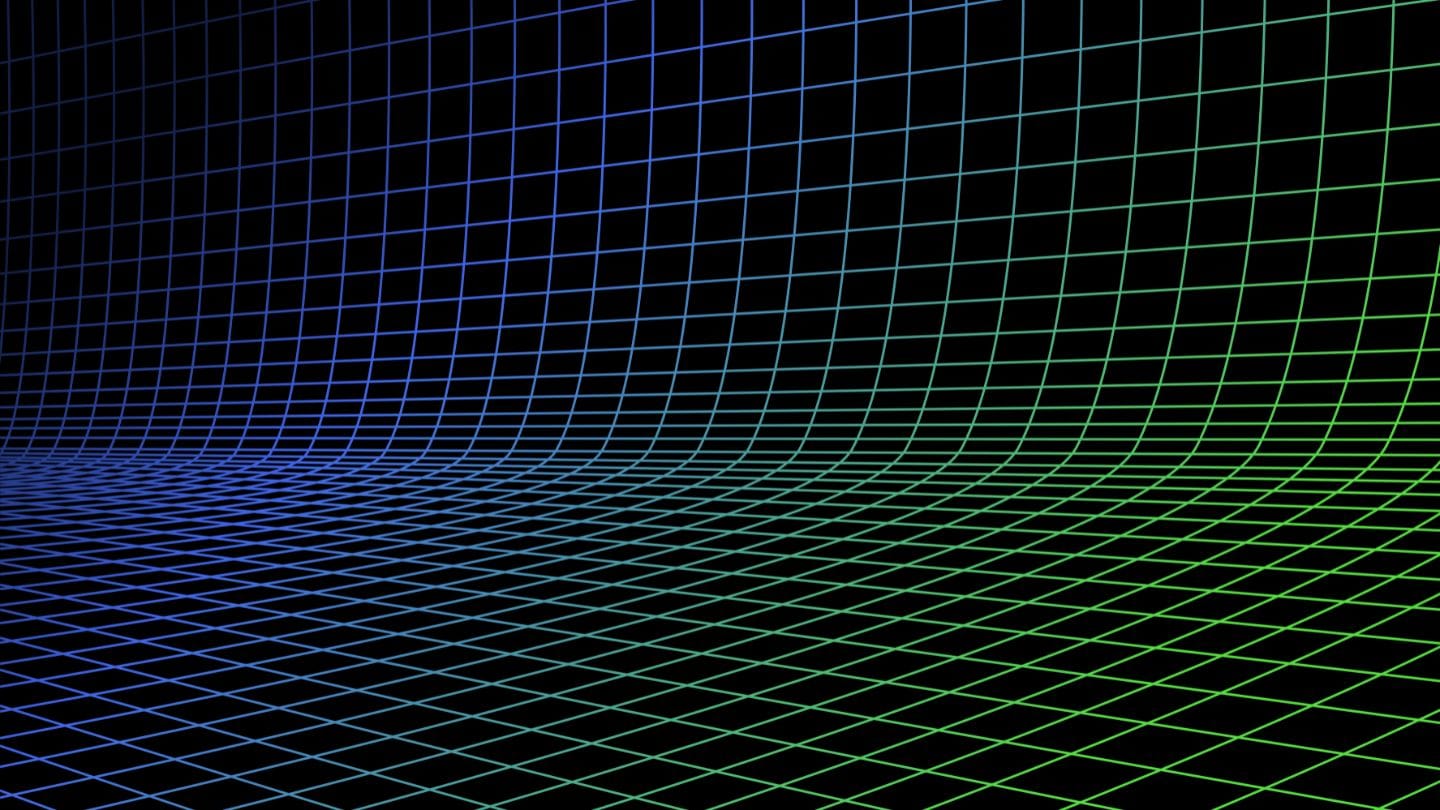
Estas limitaciones complican las tareas de búsqueda que involucran tanto texto como imágenes, por ejemplo, una tienda online "shop the look" donde un usuario puede buscar productos de moda usando tanto una cadena de texto como una imagen. Al indexar tus productos, necesitas procesar cada uno múltiples veces - una vez para la imagen, una vez para el texto, y una vez más con un modelo específico de texto. De igual manera, cuando un usuario busca un producto, tu sistema necesita buscar al menos dos veces para encontrar tanto objetivos de texto como de imagen:
tagCómo jina-clip-v1 Resuelve las Limitaciones de CLIP
Para superar las limitaciones de CLIP, creamos jina-clip-v1 para entender textos más largos y hacer coincidir más efectivamente las consultas de texto tanto con textos como con imágenes. ¿Qué hace que jina-clip-v1 sea tan especial? En primer lugar, utiliza un modelo de comprensión de texto más inteligente (JinaBERT), ayudándole a entender textos más largos y complicados (como descripciones de productos), no solo subtítulos cortos (como nombres de productos). En segundo lugar, entrenamos jina-clip-v1 para ser bueno en dos cosas a la vez: tanto en hacer coincidir texto con imágenes como en hacer coincidir texto con otros textos.
Con OpenAI CLIP, ese no es el caso: tanto para indexar como para consultar, necesitas invocar dos modelos (CLIP para imágenes y textos cortos como subtítulos, otro embedding de texto para textos más largos como descripciones). Esto no solo añade sobrecarga, sino que ralentiza la búsqueda, una operación que debería ser realmente rápida. jina-clip-v1 hace todo eso en un solo modelo, sin sacrificar velocidad:

Este enfoque unificado abre nuevas posibilidades que eran desafiantes con modelos anteriores, potencialmente remodelando cómo abordamos la búsqueda. En esta publicación, realizamos dos experimentos:
- Mejorando los resultados de búsqueda combinando texto e imagen: ¿Podemos combinar lo que jina-clip-v1 entiende del texto con lo que entiende de las imágenes? ¿Qué sucede cuando mezclamos estos dos tipos de comprensión? ¿Agregar información visual cambia nuestros resultados de búsqueda? En resumen, ¿podemos obtener mejores resultados si buscamos con texto e imágenes al mismo tiempo?
- Usando imágenes para diversificar los resultados de búsqueda: La mayoría de los motores de búsqueda maximizan las coincidencias de texto. Pero ¿podemos usar la comprensión de imágenes de jina-clip-v1 como un "shuffle visual"? En lugar de mostrar solo los resultados más relevantes, podríamos incluir algunos visualmente diversos. No se trata de encontrar más resultados relacionados – se trata de mostrar una gama más amplia de perspectivas, incluso si están menos estrechamente relacionadas. Al hacer esto, podemos descubrir aspectos de un tema que no habíamos considerado antes. Por ejemplo, en el contexto de búsqueda de moda, si un usuario busca "vestido de cóctel multicolor", ¿quieren que los primeros resultados se vean todos iguales (es decir, coincidencias muy cercanas), o una mayor variedad para elegir (mediante shuffle visual)?
Ambos enfoques son valiosos en una variedad de casos de uso donde los usuarios podrían buscar con texto o imágenes, como en comercio electrónico, medios, arte y diseño, imágenes médicas y más allá.
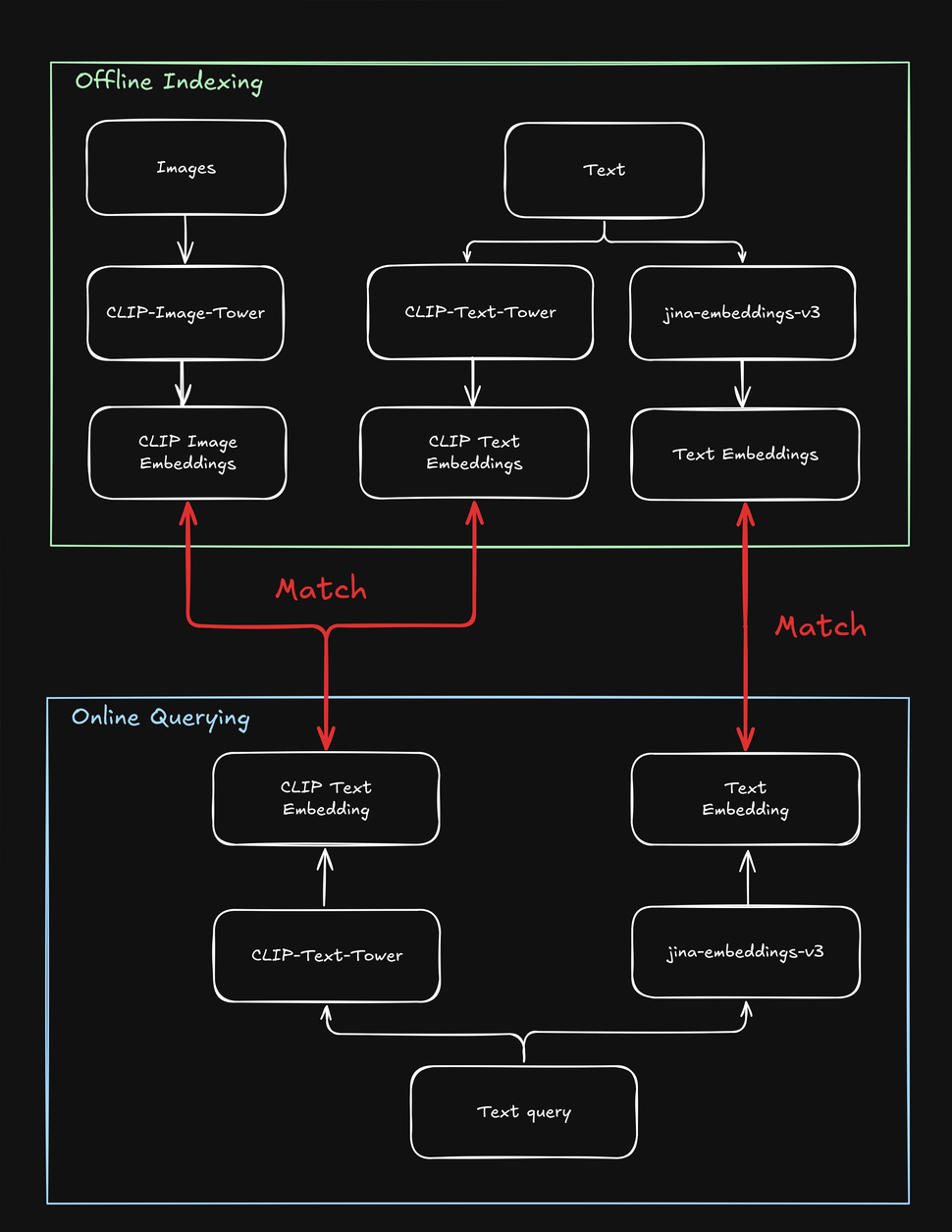
tagPromediando Embeddings de Texto e Imagen para un Rendimiento Superior al Promedio
Cuando un usuario envía una consulta (generalmente como una cadena de texto), podemos usar la torre de texto de jina-clip-v1 para codificar la consulta en un embedding de texto. La fortaleza de jina-clip-v1 radica en su capacidad para entender tanto texto como imágenes al alinear señales texto-a-texto y texto-a-imagen en el mismo espacio semántico.
¿Podemos mejorar los resultados de recuperación si combinamos los embeddings preindexados de texto e imagen de cada producto promediándolos?
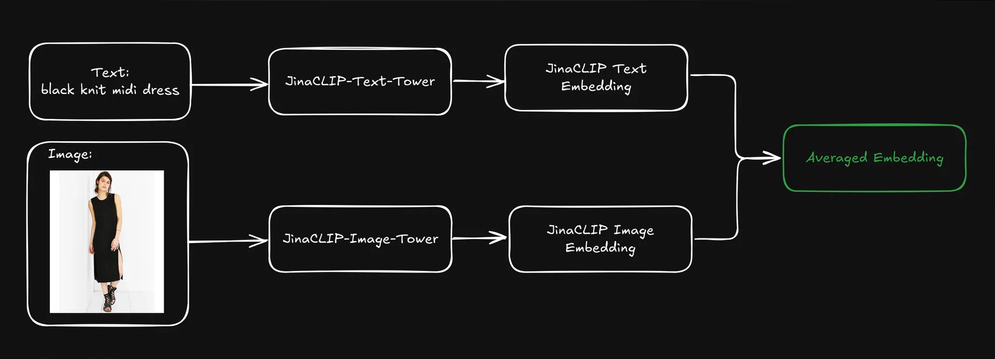
Esto crea una representación única que incluye tanto información textual (por ejemplo, descripción del producto) como información visual (por ejemplo, imagen del producto). Luego podemos usar el embedding de la consulta de texto para buscar estas representaciones combinadas. ¿Cómo afecta esto a nuestros resultados de búsqueda?
Para averiguarlo, utilizamos el conjunto de datos Fashion200k, un conjunto de datos a gran escala creado específicamente para tareas relacionadas con la recuperación de imágenes de moda y la comprensión multimodal. Consiste en más de 200,000 imágenes de artículos de moda, como ropa, zapatos y accesorios, junto con sus correspondientes descripciones de producto y metadatos.
 xthan
xthanClasificamos cada elemento en una categoría amplia (por ejemplo, dress) y una categoría detallada (como knit midi dress).
tagAnálisis de Tres Métodos de Recuperación
Para ver si promediar los embeddings de texto e imagen producía mejores resultados de recuperación, experimentamos con tres tipos de búsqueda, cada uno utilizando una cadena de texto (por ejemplo, red dress) como consulta:
- Consulta a Descripción usando embeddings de texto: Buscar descripciones de productos basadas en embeddings de texto.
- Consulta a Imagen usando búsqueda cross-modal: Buscar imágenes de productos basadas en embeddings de imagen.
- Consulta a Embedding Promedio: Buscar embeddings promediados tanto de descripciones como de imágenes de productos.
Primero indexamos todo el conjunto de datos y luego generamos aleatoriamente 1,000 consultas para evaluar el rendimiento. Codificamos cada consulta en un embedding de texto y realizamos la coincidencia por separado, según los métodos descritos anteriormente. Medimos la precisión por qué tan bien las categorías de los productos devueltos coincidían con la consulta de entrada.
Cuando usamos la consulta multicolor henley t-shirt dress, la búsqueda de Consulta a Descripción logró la mayor precisión top-5, pero los últimos tres vestidos mejor clasificados eran visualmente idénticos. Esto es menos que ideal, ya que una búsqueda efectiva debería equilibrar relevancia y diversidad para captar mejor la atención del usuario.

La búsqueda cross-modal de Consulta a Imagen usó la misma consulta y tomó el enfoque opuesto, presentando una colección altamente diversa de vestidos. Si bien coincidió con dos de cinco resultados en la categoría amplia correcta, ninguno coincidió con la categoría detallada.

La búsqueda con embeddings promediados de texto e imagen produjo el mejor resultado: los cinco resultados coincidieron con la categoría amplia, y dos de cinco coincidieron con la categoría detallada. Además, se eliminaron los elementos visualmente duplicados, proporcionando una selección más variada. Usar embeddings de texto para buscar en embeddings promediados de texto e imagen parece mantener la calidad de la búsqueda mientras incorpora señales visuales, lo que lleva a resultados más diversos y completos.

tagEscalando: Evaluación con Más Consultas
Para ver si esto funcionaría a mayor escala, continuamos ejecutando el experimento con categorías amplias y detalladas adicionales. Ejecutamos varias iteraciones, recuperando un número diferente de resultados ("valores k") cada vez.
Tanto en categorías amplias como detalladas, la Consulta a Embedding Promedio logró consistentemente la mayor precisión en todos los valores k (10, 20, 50, 100). Esto muestra que combinar embeddings de texto e imagen proporciona los resultados más precisos para recuperar elementos relevantes, independientemente de si la categoría es amplia o específica:

| k | Search Type | Broad Category Precision (cosine similarity) | Fine-grained Category Precision (cosine similarity) |
|---|---|---|---|
| 10 | Query to Description | 0.9026 | 0.2314 |
| 10 | Query to Image | 0.7614 | 0.2037 |
| 10 | Query to Avg Embedding | 0.9230 | 0.2711 |
| 20 | Query to Description | 0.9150 | 0.2316 |
| 20 | Query to Image | 0.7523 | 0.1964 |
| 20 | Query to Avg Embedding | 0.9229 | 0.2631 |
| 50 | Query to Description | 0.9134 | 0.2254 |
| 50 | Query to Image | 0.7418 | 0.1750 |
| 50 | Query to Avg Embedding | 0.9226 | 0.2390 |
| 100 | Query to Description | 0.9092 | 0.2139 |
| 100 | Query to Image | 0.7258 | 0.1675 |
| 100 | Query to Avg Embedding | 0.9150 | 0.2286 |
- La Consulta a Descripción usando embeddings de texto funcionó bien en ambas categorías pero quedó ligeramente por detrás del enfoque de embedding promediado. Esto sugiere que las descripciones textuales por sí solas proporcionan información valiosa, particularmente para categorías más amplias como "dress", pero pueden carecer de la sutileza necesaria para una clasificación detallada precisa (por ejemplo, distinguir entre diferentes tipos de vestidos).
- La Consulta a Imagen usando búsqueda cross-modal tuvo consistentemente la precisión más baja en ambas categorías. Esto sugiere que mientras las características visuales pueden ayudar a identificar categorías amplias, son menos efectivas para capturar las distinciones detalladas de elementos específicos de moda. El desafío de distinguir categorías detalladas puramente desde características visuales es particularmente evidente, donde las diferencias visuales pueden ser sutiles y requerir contexto adicional proporcionado por el texto.
- En general, combinar información textual y visual (mediante embeddings promediados) logró alta precisión tanto en tareas de recuperación de moda amplias como detalladas. Las descripciones textuales juegan un papel importante, especialmente en la identificación de categorías amplias, mientras que las imágenes por sí solas son menos efectivas en ambos casos.
En general, la precisión fue mucho más alta para categorías amplias en comparación con categorías detalladas, principalmente debido a que los elementos en categorías amplias (por ejemplo, dress) están más representados en el conjunto de datos que las categorías detalladas (por ejemplo, henley dress), simplemente porque la última es un subconjunto de la primera. Por su propia naturaleza, una categoría amplia es más fácil de generalizar que una categoría detallada. Fuera del ejemplo de la moda, es sencillo identificar que algo, en general, es un pájaro. Es mucho más difícil identificarlo como un Vogelkop Superb Bird of Paradise.
Otro aspecto a tener en cuenta es que la información en una consulta de texto coincide más fácilmente con otros textos (como nombres de productos o descripciones), que con características visuales. Por lo tanto, si se usa un texto como entrada, los textos son una salida más probable que las imágenes. Obtenemos los mejores resultados combinando tanto imágenes como texto (mediante el promedio de los embeddings) en nuestro índice.
tagRecuperar Resultados con Texto; Diversificarlos con Imágenes
En la sección anterior, tocamos el tema de los resultados de búsqueda visualmente duplicados. En la búsqueda, la precisión por sí sola no siempre es suficiente. En muchos casos, mantener una lista clasificada concisa pero altamente relevante y diversa es más efectivo, especialmente cuando la consulta del usuario es ambigua (por ejemplo, si un usuario buscablack jacket — ¿se refieren a una chaqueta de motociclista negra, una bomber, un blazer u otro tipo?)
Ahora, en lugar de aprovechar la capacidad multimodal de jina-clip-v1, usaremos los embeddings de texto de su torre de texto para la búsqueda inicial, y luego aplicaremos los embeddings de imagen de la torre de imagen como un "reordenador visual" para diversificar los resultados de búsqueda. Esto se ilustra en el diagrama siguiente:
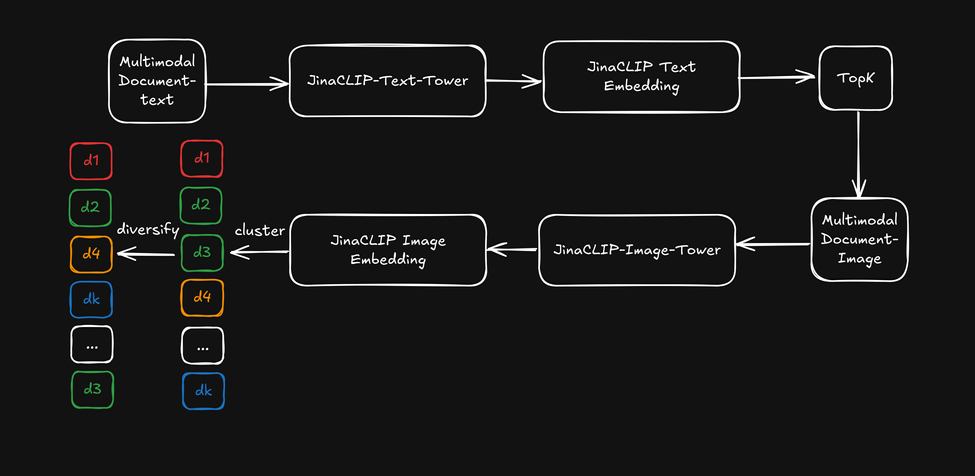
- Primero, recuperar los k primeros resultados de búsqueda basados en embeddings de texto.
- Para cada resultado principal de búsqueda, extraer características visuales y agruparlas usando embeddings de imagen.
- Reordenar los resultados de búsqueda seleccionando un elemento de cada grupo y presentar una lista diversificada al usuario.
Después de recuperar los cincuenta primeros resultados, aplicamos un agrupamiento k-means ligero (k=5) a los embeddings de imagen, luego seleccionamos elementos de cada grupo. La precisión de categoría se mantuvo consistente con el rendimiento de Consulta-a-Descripción, ya que usamos la categoría de consulta-a-producto como métrica de medición. Sin embargo, los resultados clasificados comenzaron a cubrir más aspectos diferentes (como tela, corte y patrón) con la diversificación basada en imágenes. Como referencia, aquí está el ejemplo del vestido tipo camiseta henley multicolor de antes:

Ahora veamos cómo la diversificación afecta los resultados de búsqueda usando la búsqueda por embedding de texto combinada con embedding de imagen como reordenador de diversificación:

Los resultados clasificados provienen de la búsqueda basada en texto pero comienzan a cubrir "aspectos" más diversos dentro de los cinco primeros ejemplos. Esto logra un efecto similar al promedio de embeddings sin realmente promediarlos.
Sin embargo, esto tiene un costo: tenemos que aplicar un paso adicional de agrupamiento después de recuperar los k primeros resultados, lo que añade algunos milisegundos extra, dependiendo del tamaño de la clasificación inicial. Además, determinar el valor de k para el agrupamiento k-means implica algunas conjeturas heurísticas. ¡Ese es el precio que pagamos por una mejor diversificación de resultados!
tagConclusión
jina-clip-v1 cierra efectivamente la brecha entre la búsqueda de texto e imagen unificando ambas modalidades en un solo modelo eficiente. Nuestros experimentos han demostrado que su capacidad para procesar textos más largos y complejos junto con imágenes ofrece un rendimiento de búsqueda superior en comparación con modelos tradicionales como CLIP.
Nuestras pruebas cubrieron varios métodos, incluyendo la coincidencia de texto con descripciones, imágenes y embeddings promediados. Los resultados mostraron consistentemente que la combinación de embeddings de texto e imagen produjo los mejores resultados, mejorando tanto la precisión como la diversidad de los resultados de búsqueda. También descubrimos que usar embeddings de imagen como un "reordenador visual" mejoró la variedad de resultados mientras mantenía la relevancia.
Estos avances tienen implicaciones significativas para aplicaciones del mundo real donde los usuarios buscan usando tanto descripciones de texto como imágenes. Al entender ambos tipos de datos simultáneamente, jina-clip-v1 optimiza el proceso de búsqueda, entregando resultados más relevantes y permitiendo recomendaciones de productos más diversas. Esta capacidad de búsqueda unificada se extiende más allá del comercio electrónico para beneficiar la gestión de activos multimedia, bibliotecas digitales y curación de contenido visual, facilitando el descubrimiento de contenido relevante en diferentes formatos.
Si bien jina-clip-v1 actualmente solo admite inglés, estamos trabajando en jina-clip-v2. Siguiendo los pasos de jina-embeddings-v3 y jina-colbert-v2, esta nueva versión será un recuperador multimodal multilingüe de última generación que admitirá 89 idiomas. Esta actualización abrirá nuevas posibilidades para tareas de búsqueda y recuperación en diferentes mercados e industrias, convirtiéndolo en un modelo de embedding más potente para aplicaciones globales en comercio electrónico, medios y más allá.
