



En los modelos multilingües, uno de los desafíos clave es el "language gap" — un fenómeno donde frases con el mismo significado en diferentes idiomas no están tan estrechamente alineadas o agrupadas como deberían. Idealmente, un texto en un idioma y su equivalente en otro deberían tener representaciones similares — es decir, embeddings que estén muy cerca uno del otro — permitiendo que las aplicaciones multilingües operen de manera idéntica en textos de diferentes idiomas. Sin embargo, los modelos a menudo representan sutilmente el idioma de un texto, creando un "language gap" que lleva a un rendimiento subóptimo entre idiomas.
En esta publicación, exploraremos este language gap y cómo impacta el rendimiento en los modelos de embeddings de texto. Hemos realizado experimentos para evaluar el alineamiento semántico de paráfrasis en el mismo idioma y para traducciones entre diferentes pares de idiomas, usando nuestro modelo jina-xlm-roberta y el más reciente jina-embeddings-v3. Estos experimentos revelan qué tan bien se agrupan las frases con significados similares o idénticos bajo diferentes condiciones de entrenamiento.

También hemos experimentado con técnicas de entrenamiento para mejorar el alineamiento semántico entre idiomas, específicamente la introducción de datos multilingües paralelos durante el aprendizaje contrastivo. En este artículo, compartiremos nuestros hallazgos y resultados.
tagEl Entrenamiento de Modelos Multilingües Crea y Reduce el Language Gap
El entrenamiento de modelos de embeddings de texto típicamente involucra un proceso de múltiples etapas con dos partes principales:
- Masked Language Modeling (MLM): El pre-entrenamiento típicamente involucra grandes cantidades de texto en las que algunos tokens son enmascarados aleatoriamente. El modelo es entrenado para predecir estos tokens enmascarados. Este procedimiento enseña al modelo los patrones del idioma o idiomas en los datos de entrenamiento, incluyendo dependencias de selección entre tokens que pueden surgir de la sintaxis, la semántica léxica y las restricciones pragmáticas del mundo real.
- Contrastive Learning: Después del pre-entrenamiento, el modelo se entrena adicionalmente con datos curados o semi-curados para acercar los embeddings de textos semánticamente similares y (opcionalmente) alejar los disímiles. Este entrenamiento puede usar pares, tripletas o incluso grupos de textos cuya similitud semántica ya es conocida o al menos estimada de manera confiable. Puede tener varias subetapas y hay una variedad de estrategias de entrenamiento para esta parte del proceso, con nueva investigación publicada frecuentemente y sin un consenso claro sobre el enfoque óptimo.
Para entender cómo surge el language gap y cómo puede cerrarse, necesitamos examinar el papel de ambas etapas.
tagPre-entrenamiento de Masked Language
Parte de la capacidad multilingüe de los modelos de embeddings de texto se adquiere durante el pre-entrenamiento.
Los cognados y las palabras prestadas hacen posible que el modelo aprenda cierto alineamiento semántico entre idiomas a partir de grandes cantidades de datos de texto. Por ejemplo, la palabra en inglés banana y la palabra en francés banane (y en alemán Banane) son frecuentes y suficientemente similares en su escritura para que un modelo de embeddings pueda aprender que las palabras que se parecen a "banan-" tienen patrones de distribución similares entre idiomas. Puede aprovechar esa información para aprender, hasta cierto punto, que otras palabras que no se parecen entre idiomas también tienen significados similares, e incluso descubrir cómo se traducen algunas estructuras gramaticales.
Sin embargo, esto ocurre sin entrenamiento explícito.
Probamos el modelo jina-xlm-roberta, la base pre-entrenada de jina-embeddings-v3, para ver qué tan bien aprendió las equivalencias entre idiomas durante el pre-entrenamiento MLM. Graficamos representaciones de oraciones bidimensionales UMAP de un conjunto de oraciones en inglés traducidas al alemán, holandés, chino simplificado y japonés. Los resultados están en la figura siguiente:
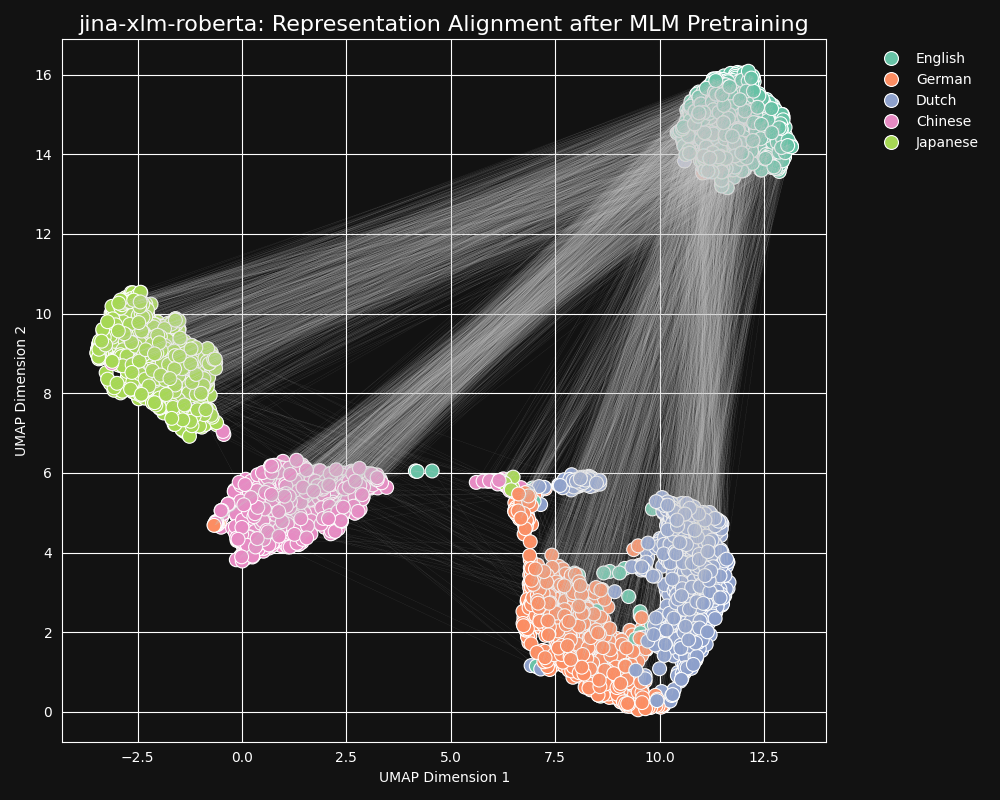
Estas oraciones tienden fuertemente a formar grupos específicos por idioma en el espacio de embeddings de
jina-xlm-roberta, aunque se pueden ver algunos valores atípicos en esta proyección que pueden ser un efecto secundario de la proyección bidimensional.Puede verse que el pre-entrenamiento ha agrupado muy fuertemente los embeddings de oraciones en el mismo idioma. Esta es una proyección en dos dimensiones de una distribución en un espacio de dimensiones mucho más alto, por lo que todavía es posible que, por ejemplo, una oración en alemán que sea una buena traducción de una en inglés pueda seguir siendo la oración en alemán cuyo embedding está más cerca del embedding de su fuente en inglés. Pero sí muestra que un embedding de una oración en inglés probablemente está más cerca de otra oración en inglés que de una semánticamente idéntica o casi idéntica en alemán.
Note también cómo el alemán y el holandés forman grupos mucho más cercanos que otros pares de idiomas. Esto no es sorprendente para dos idiomas relativamente cercanos. El alemán y el holandés son lo suficientemente similares que a veces son parcialmente mutuamente comprensibles.
El japonés y el chino también aparecen más cercanos entre sí que con otros idiomas. Aunque no están relacionados entre sí de la misma manera, el japonés escrito típicamente usa kanji (漢字), o hànzì en chino. El japonés comparte la mayoría de estos caracteres escritos con el chino, y los dos idiomas comparten muchas palabras escritas con uno o varios kanji/hànzì juntos. Desde la perspectiva del MLM, este es el mismo tipo de similitud visible que entre el holandés y el alemán.
Podemos ver este "language gap" de una manera más simple observando solo dos idiomas con dos oraciones cada uno:

Dado que MLM parece agrupar naturalmente los textos por idioma, "my dog is blue" y "my cat is red" están agrupados juntos, lejos de sus contrapartes en alemán. A diferencia del "modality gap" discutido en una publicación anterior del blog, creemos que esto surge de similitudes y diferencias superficiales entre idiomas: ortografías similares, uso de las mismas secuencias de caracteres en la escritura, y posiblemente similitudes en morfología y estructura sintáctica — órdenes comunes de palabras y formas comunes de construir palabras.
En resumen, hasta el grado en que un modelo está aprendiendo equivalencias entre idiomas en el pre-entrenamiento MLM, no es suficiente para superar un fuerte sesgo hacia agrupar textos por idioma. Deja un gran language gap.
tagContrastive Learning
Idealmente, queremos que un modelo de embeddings sea indiferente al idioma y solo codifique significados generales en sus embeddings. En un modelo así, no veríamos agrupamiento por idioma y no tendríamos language gap. Las oraciones en un idioma deberían estar muy cerca de buenas traducciones y lejos de otras oraciones que significan algo diferente, incluso en el mismo idioma, como en la figura siguiente:

El pre-entrenamiento MLM no logra eso, así que usamos técnicas adicionales de contrastive learning para mejorar la representación semántica de textos en embeddings.
El contrastive learning involucra usar pares de textos que se sabe son similares o diferentes en significado, y tripletas donde se sabe que un par es más similar que el otro. Los pesos se ajustan durante el entrenamiento para reflejar esta relación conocida entre pares y tripletas de texto.
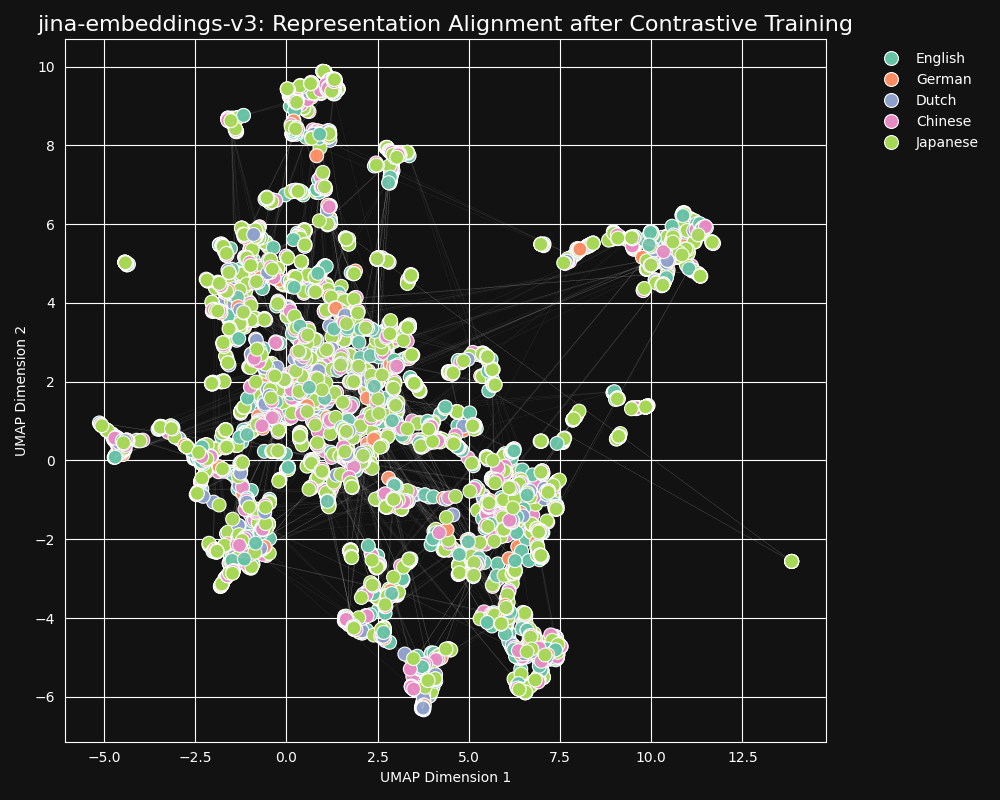
Hay 30 idiomas representados en nuestro conjunto de datos de contrastive learning, pero el 97% de los pares y tripletas están en un solo idioma, con solo 3% involucrando pares o tripletas entre idiomas. Pero este 3% es suficiente para producir un resultado dramático: Los embeddings muestran muy poco agrupamiento por idioma y los textos semánticamente similares producen embeddings cercanos independientemente de su idioma, como se muestra en la proyección UMAP de embeddings de jina-embeddings-v3.
Para confirmarlo, medimos la Correlación de Spearman de las representaciones generadas por jina-xlm-roberta y jina-embeddings-v3 en el conjunto de datos STS17.
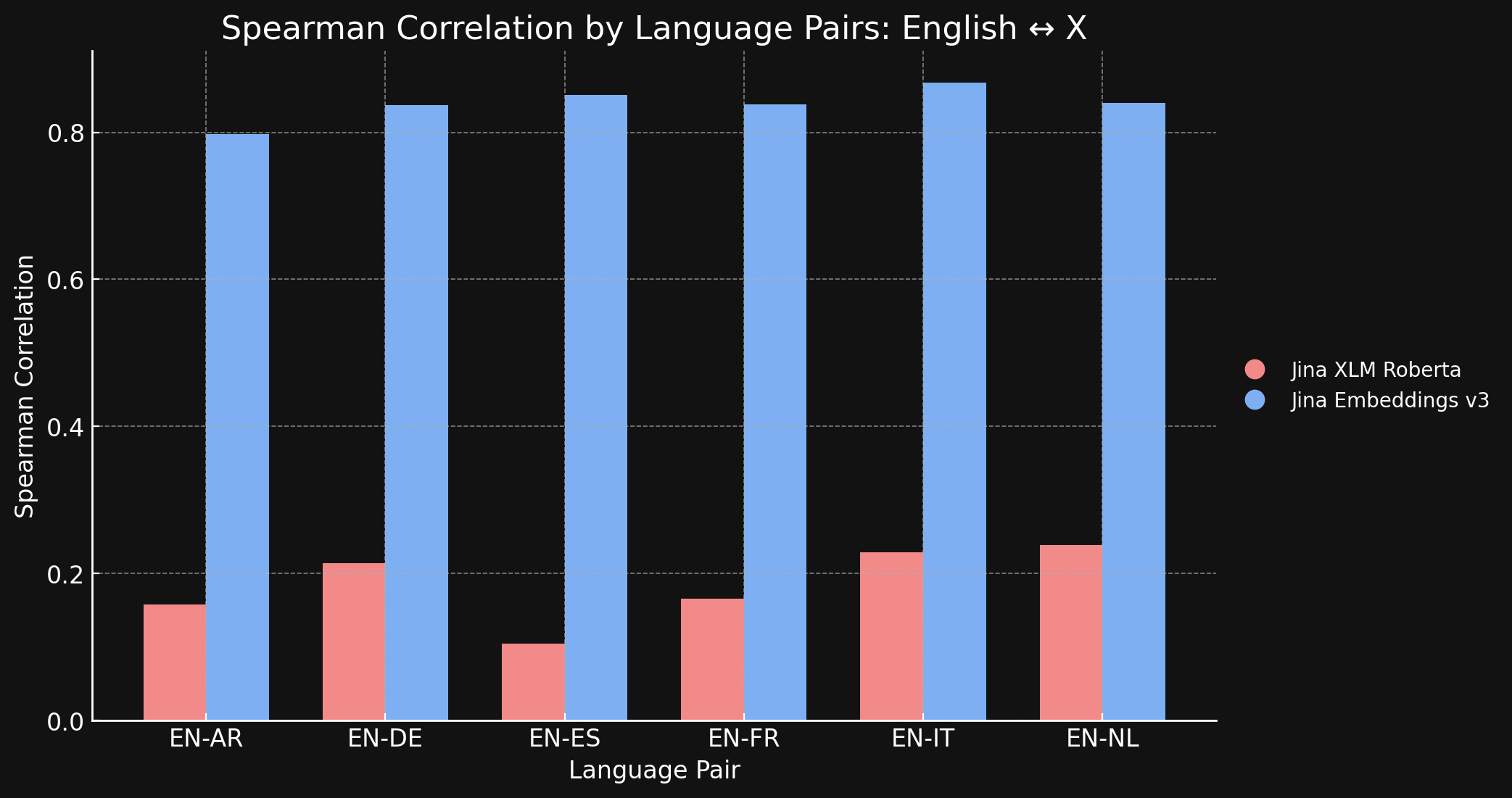
La tabla siguiente muestra la Correlación de Spearman entre clasificaciones de similitud semántica para textos traducidos en diferentes idiomas. Tomamos un conjunto de oraciones en inglés y luego medimos la similitud de sus embeddings con un embedding de una oración de referencia específica y los ordenamos desde el más similar al menos similar. Luego traducimos todas esas oraciones a otro idioma y repetimos el proceso de clasificación. En un modelo de embedding multilingüe ideal, las dos listas ordenadas serían idénticas, y la Correlación de Spearman sería 1.0.
El gráfico y la tabla a continuación muestran nuestros resultados comparando el inglés y los otros seis idiomas en el benchmark STS17, usando tanto jina-xlm-roberta como jina-embeddings-v3.
| Task | jina-xlm-roberta |
jina-embeddings-v3 |
|---|---|---|
| English ↔ Arabic | 0.1581 | 0.7977 |
| English ↔ German | 0.2136 | 0.8366 |
| English ↔ Spanish | 0.1049 | 0.8509 |
| English ↔ French | 0.1659 | 0.8378 |
| English ↔ Italian | 0.2293 | 0.8674 |
| English ↔ Dutch | 0.2387 | 0.8398 |
Aquí se puede ver la enorme diferencia que hace el aprendizaje contrastivo, comparado con el pre-entrenamiento original. A pesar de tener solo un 3% de datos multilingües en su mezcla de entrenamiento, el modelo jina-embeddings-v3 ha aprendido suficiente semántica multilingüe para casi eliminar la brecha lingüística que adquirió en el pre-entrenamiento.
tagInglés vs. El Mundo: ¿Pueden otros idiomas mantenerse al día en el alineamiento?
Entrenamos jina-embeddings-v3 en 89 idiomas, con un enfoque particular en 30 idiomas escritos muy utilizados. A pesar de nuestros esfuerzos para construir un corpus de entrenamiento multilingüe a gran escala, el inglés todavía representa casi la mitad de los datos que usamos en el entrenamiento contrastivo. Otros idiomas, incluyendo lenguajes globales ampliamente utilizados para los que hay abundante material textual disponible, siguen estando relativamente subrepresentados en comparación con la enorme cantidad de datos en inglés en el conjunto de entrenamiento.
Dado este predominio del inglés, ¿están las representaciones en inglés más alineadas que las de otros idiomas? Para explorar esto, realizamos un experimento de seguimiento.
Construimos un conjunto de datos, parallel-sentences, que consiste en 1,000 pares de textos en inglés, un "ancla" y un "positivo", donde el texto positivo está lógicamente implicado por el texto ancla.

Por ejemplo, la primera fila de la tabla siguiente. Estas oraciones no son idénticas en significado, pero tienen significados compatibles. Describen informativamente la misma situación.
Luego tradujimos estos pares a cinco idiomas usando GPT-4: alemán, holandés, chino (simplificado), chino (tradicional) y japonés. Finalmente, los inspeccionamos manualmente para asegurar la calidad.
| Language | Anchor | Positive |
|---|---|---|
| English | Two young girls are playing outside in a non-urban environment. | Two girls are playing outside. |
| German | Zwei junge Mädchen spielen draußen in einer nicht urbanen Umgebung. | Zwei Mädchen spielen draußen. |
| Dutch | Twee jonge meisjes spelen buiten in een niet-stedelijke omgeving. | Twee meisjes spelen buiten. |
| Chinese (Simplified) | 两个年轻女孩在非城市环境中玩耍。 | 两个女孩在外面玩。 |
| Chinese (Traditional) | 兩個年輕女孩在非城市環境中玩耍。 | 兩個女孩在外面玩。 |
| Japanese | 2人の若い女の子が都市環境ではない場所で遊んでいます。 | 二人の少女が外で遊んでいます。 |
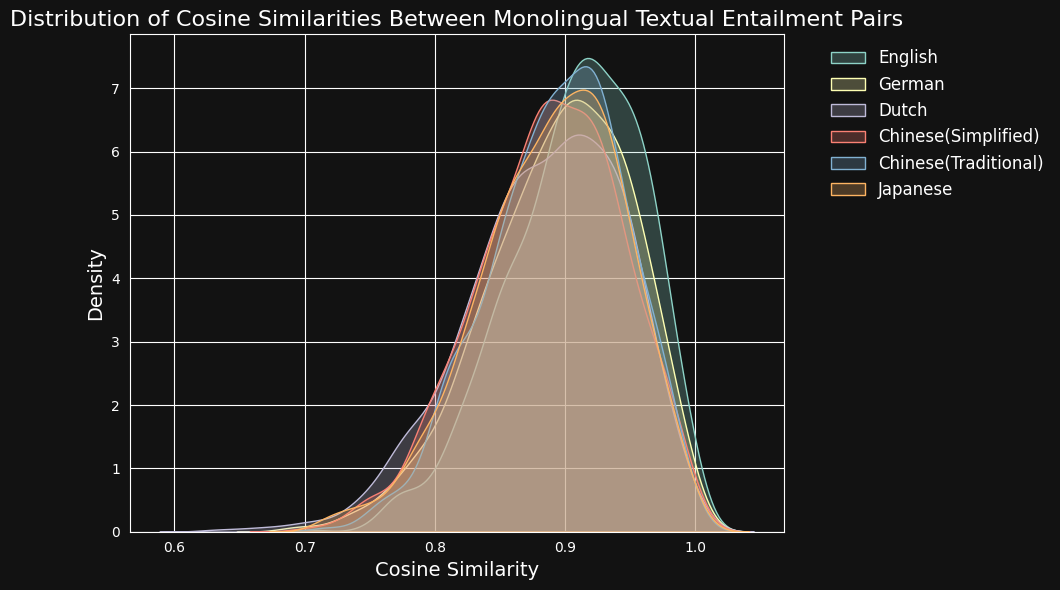
Luego codificamos cada par de textos con jina-embeddings-v3 y calculamos la similitud del coseno entre ellos. La figura y la tabla siguiente muestran la distribución de las puntuaciones de similitud del coseno para cada idioma, y la similitud promedio:
| Language | Average Cosine Similarity |
|---|---|
| English | 0.9078 |
| German | 0.8949 |
| Dutch | 0.8844 |
| Chinese (Simplified) | 0.8876 |
| Chinese (Traditional) | 0.8933 |
| Japanese | 0.8895 |
A pesar del predominio del inglés en los datos de entrenamiento, jina-embeddings-v3 reconoce la similitud semántica en alemán, holandés, japonés y ambas formas de chino casi tan bien como lo hace en inglés.
tagRompiendo las Barreras Lingüísticas: Alineamiento Multilingüe Más Allá del Inglés
Los estudios de alineación de representaciones entre idiomas típicamente estudian pares de idiomas que incluyen el inglés. Este enfoque podría, en teoría, ocultar lo que realmente está sucediendo. Un modelo podría simplemente optimizarse para representar todo lo más cerca posible a su equivalente en inglés, sin examinar si otros pares de idiomas están adecuadamente soportados.
Para explorar esto, realizamos algunos experimentos usando el dataset parallel-sentences, enfocándonos en la alineación entre idiomas más allá de solo pares bilingües con inglés.
La tabla siguiente muestra la distribución de similitudes de coseno entre textos equivalentes en diferentes pares de idiomas — textos que son traducciones de una fuente común en inglés. Idealmente, todos los pares deberían tener un coseno de 1 — es decir, embeddings semánticos idénticos. En la práctica, esto nunca podría ocurrir, pero esperaríamos que un buen modelo tenga valores de coseno muy altos para pares de traducción.
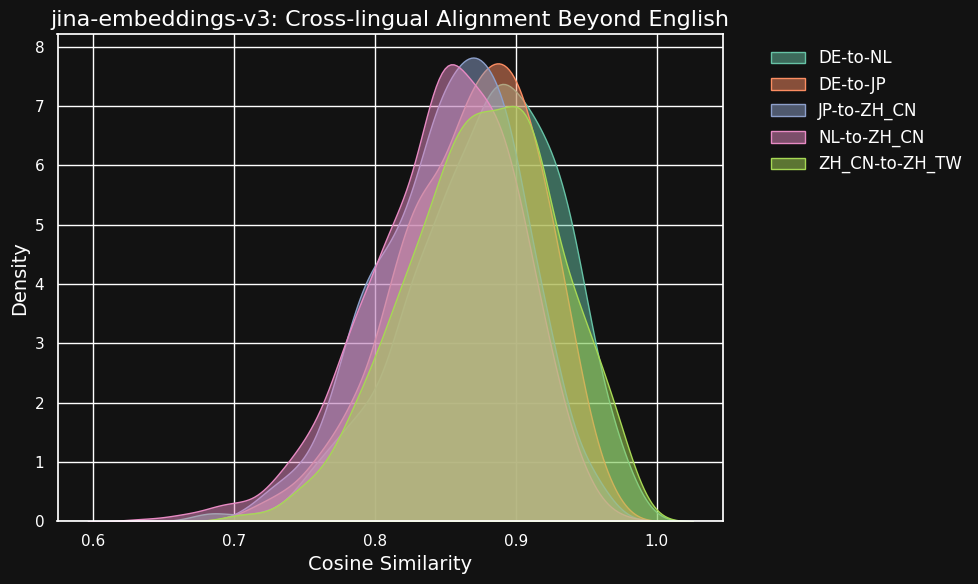
| Language Pair | Average Cosine Similarity |
|---|---|
| German ↔ Dutch | 0.8779 |
| German ↔ Japanese | 0.8664 |
| Chinese (Simplified) ↔ Japanese | 0.8534 |
| Dutch ↔ Chinese (Simplified) | 0.8479 |
| Chinese (Simplified) ↔ Chinese (Traditional) | 0.8758 |
Aunque las puntuaciones de similitud entre diferentes idiomas son un poco más bajas que para textos compatibles en el mismo idioma, siguen siendo muy altas. La similitud de coseno de las traducciones entre holandés y alemán es casi tan alta como entre textos compatibles en alemán.
Esto podría no ser sorprendente porque el alemán y el holandés son idiomas muy similares. De manera similar, las dos variedades de chino probadas aquí no son realmente dos idiomas diferentes, sino formas estilísticamente diferentes del mismo idioma. Pero se puede ver que incluso pares de idiomas muy diferentes como el holandés y el chino o el alemán y el japonés siguen mostrando una similitud muy fuerte entre textos semánticamente equivalentes.
Consideramos la posibilidad de que estos valores de similitud tan altos pudieran ser un efecto secundario del uso de ChatGPT como traductor. Para probarlo, descargamos transcripciones traducidas por humanos de charlas TED en inglés y alemán y verificamos si las oraciones traducidas alineadas tendrían la misma alta correlación.
El resultado fue incluso más fuerte que para nuestros datos traducidos por máquina, como se puede ver en la figura siguiente.
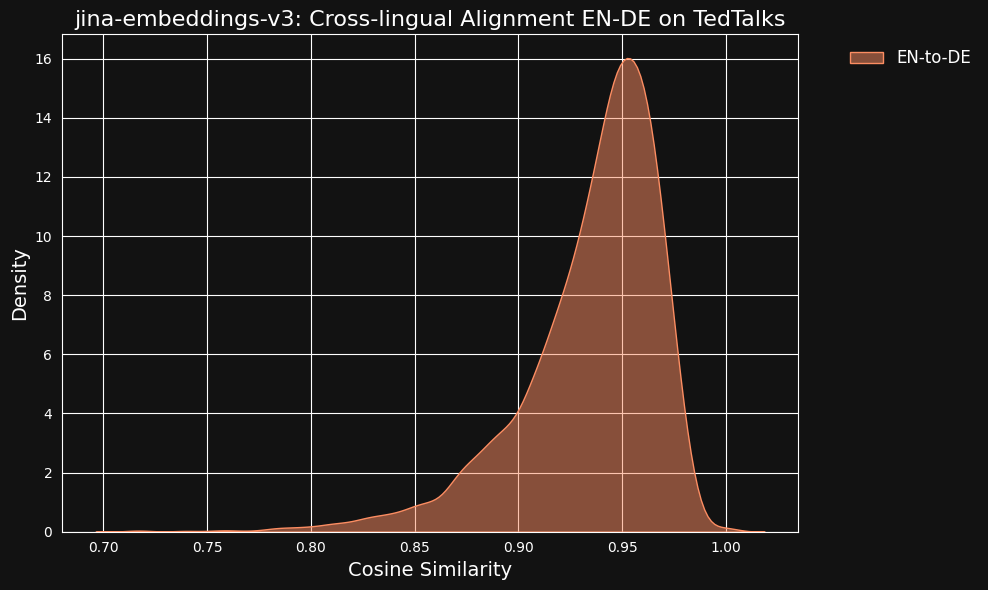
tag¿Cuánto Contribuyen los Datos Multilingües a la Alineación Entre Idiomas?
La brecha lingüística desvaneciente y el alto nivel de rendimiento entre idiomas parecen desproporcionados en comparación con la muy pequeña parte de los datos de entrenamiento que era explícitamente multilingüe. Solo el 3% de los datos de entrenamiento contrastivo específicamente enseña al modelo cómo hacer alineaciones entre idiomas.
Así que hicimos una prueba para ver si los datos multilingües estaban haciendo alguna contribución.
Reentrenar completamente jina-embeddings-v3 sin ningún dato multilingüe sería prohibitivamente costoso para un pequeño experimento, así que descargamos el modelo xlm-roberta-base de Hugging Face y lo entrenamos más con aprendizaje contrastivo, usando un subconjunto de los datos que usamos para entrenar jina-embeddings-v3. Específicamente ajustamos la cantidad de datos multilingües para probar dos casos: Uno sin datos multilingües, y otro donde el 20% de los pares eran multilingües. Puedes ver los metaparámetros de entrenamiento en la tabla siguiente:
| Backbone | % Cross-Language | Learning Rate | Loss Function | Temperature |
xlm-roberta-base without X-language data | 0% | 5e-4 | InfoNCE | 0.05 |
xlm-roberta-base with X-language data | 20% | 5e-4 | InfoNCE | 0.05 |
Luego evaluamos el rendimiento multilingüe de ambos modelos usando los benchmarks STS17 y STS22 del MTEB y la Correlación de Spearman. Presentamos los resultados a continuación:
tagSTS17
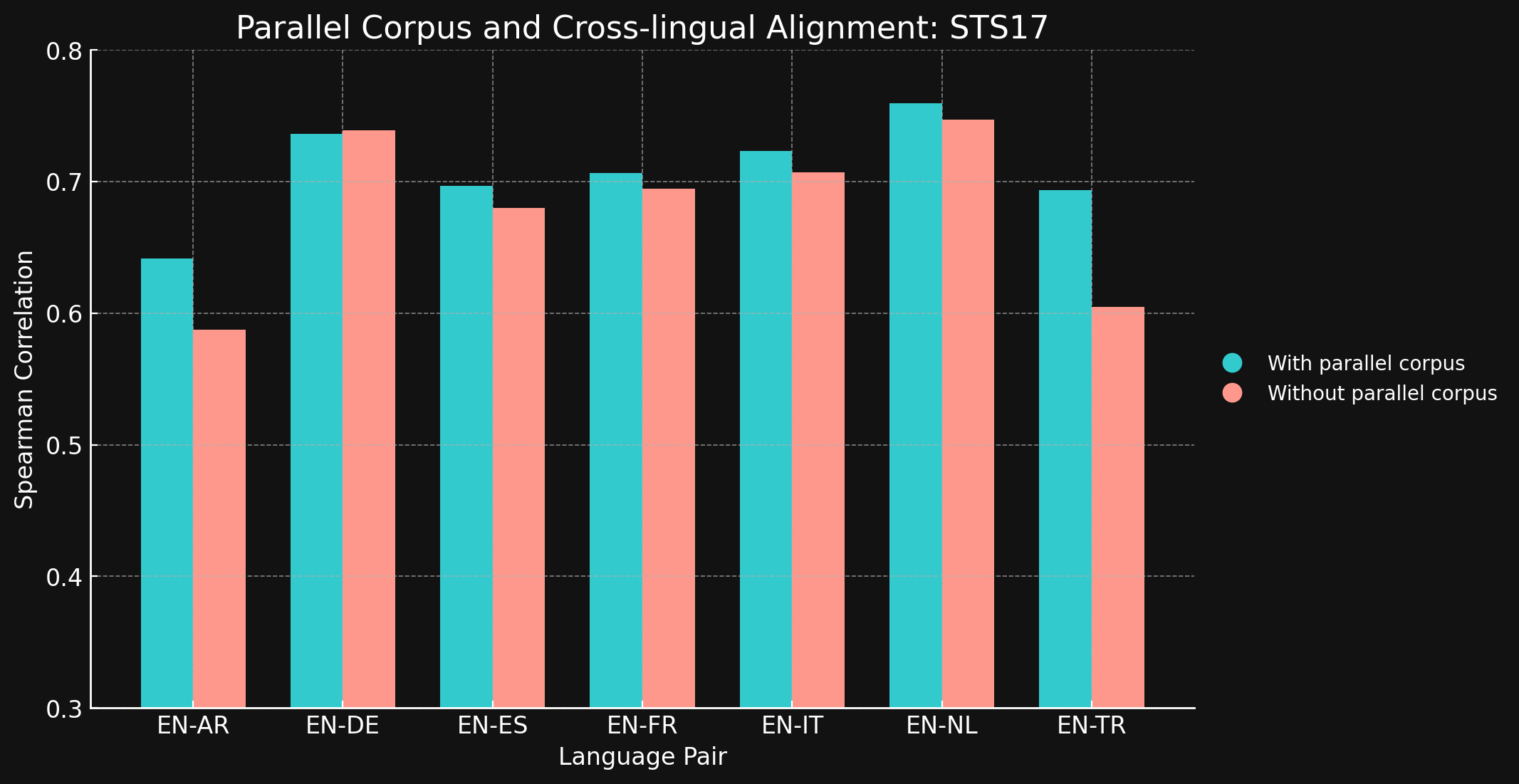
| Language Pair | With parallel corpora | Without parallel corpora |
| English ↔ Arabic | 0.6418 | 0.5875 |
| English ↔ German | 0.7364 | 0.7390 |
| English ↔ Spanish | 0.6968 | 0.6799 |
| English ↔ French | 0.7066 | 0.6944 |
| English ↔ Italian | 0.7232 | 0.7070 |
| English ↔ Dutch | 0.7597 | 0.7468 |
| English ↔ Turkish | 0.6933 | 0.6050 |
tagSTS22
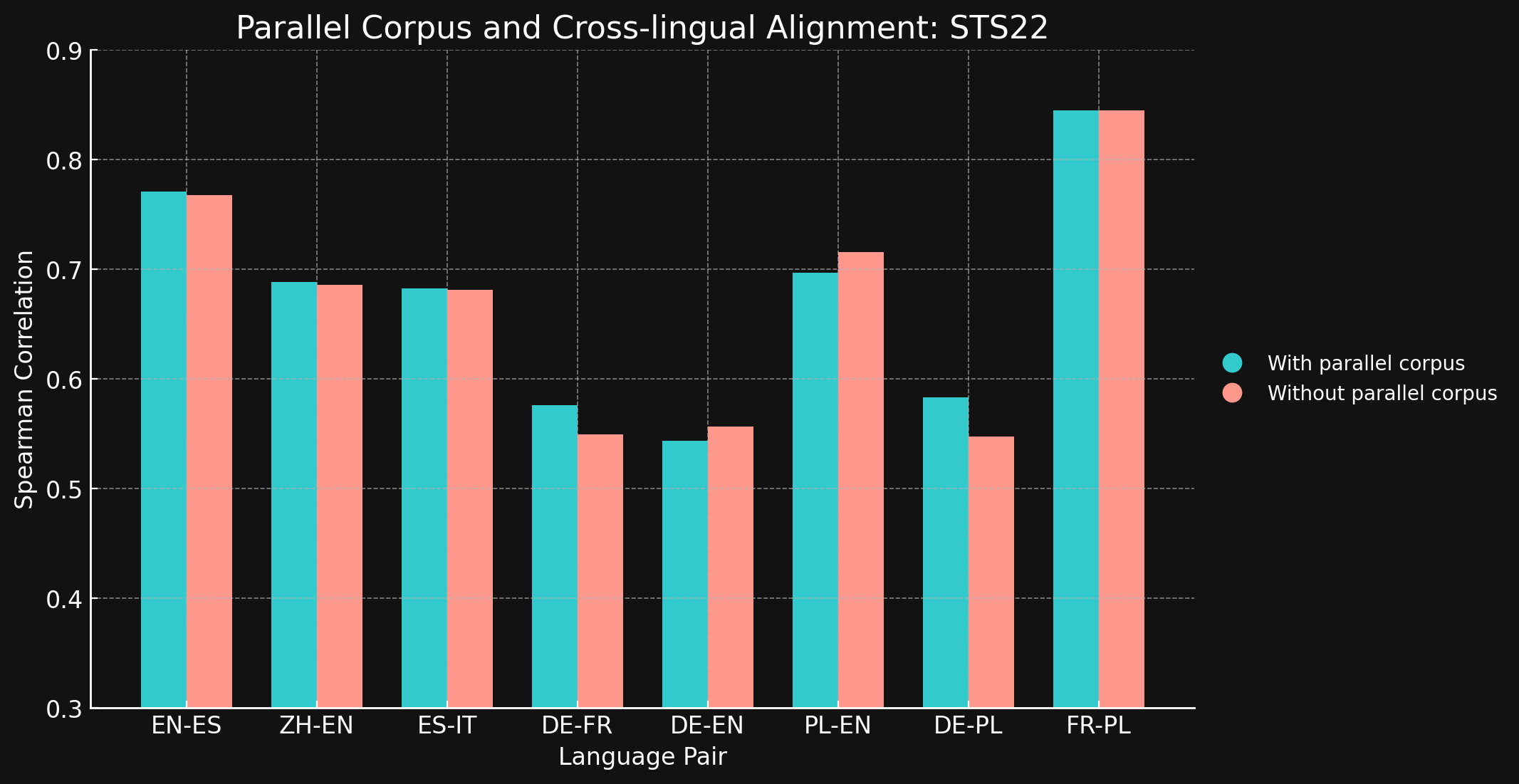
| Par de idiomas | Con corpus paralelos | Sin corpus paralelos |
| Inglés ↔ Español | 0.7710 | 0.7675 |
| Chino simplificado ↔ Inglés | 0.6885 | 0.6860 |
| Español ↔ Italiano | 0.6829 | 0.6814 |
| Alemán ↔ Francés | 0.5763 | 0.5496 |
| Alemán ↔ Inglés | 0.5439 | 0.5566 |
| Polaco ↔ Inglés | 0.6966 | 0.7156 |
| Alemán ↔ Inglés | 0.5832 | 0.5478 |
| Francés ↔ Polaco | 0.8451 | 0.8451 |
Nos sorprendió ver que para la mayoría de los pares de idiomas que probamos, los datos de entrenamiento interlingüístico aportaron poca o ninguna mejora. Es difícil asegurar que esto seguiría siendo cierto para modelos completamente entrenados con conjuntos de datos más grandes, pero ciertamente ofrece evidencia de que el entrenamiento explícito entre idiomas no aporta mucho.
Sin embargo, hay que tener en cuenta que STS17 incluye pares de inglés/árabe e inglés/turco. Estos son idiomas mucho menos representados en nuestros datos de entrenamiento. El modelo XML-RoBERTa que utilizamos fue pre-entrenado con datos que contenían un 2,25% en árabe y un 2,32% en turco, mucho menos que los otros idiomas que probamos. El pequeño conjunto de datos de aprendizaje contrastivo que utilizamos en este experimento solo contenía un 1,7% de árabe y un 1,8% de turco.
Esos dos pares de idiomas son los únicos probados donde el entrenamiento con datos interlingüísticos marcó una clara diferencia. Creemos que los datos interlingüísticos explícitos son más efectivos para idiomas que están menos representados en los datos de entrenamiento, pero necesitamos explorar más esta área antes de sacar una conclusión. El papel y la efectividad de los datos interlingüísticos en el entrenamiento contrastivo es un área donde Jina AI está realizando investigación activa.
tagConclusión
Los métodos convencionales de pre-entrenamiento de lenguaje, como el Modelado de Lenguaje Enmascarado, dejan una "brecha lingüística", donde textos semánticamente similares en diferentes idiomas no se alinean tan estrechamente como deberían. Hemos demostrado que el régimen de aprendizaje contrastivo de Jina Embeddings es muy efectivo para reducir o incluso eliminar esta brecha.
Las razones por las que esto funciona no están completamente claras. Utilizamos pares de texto explícitamente interlingüísticos en el entrenamiento contrastivo, pero solo en cantidades muy pequeñas, y no está claro qué papel juegan realmente en asegurar resultados interlingüísticos de alta calidad. Nuestros intentos de mostrar un efecto claro usando condiciones más controladas no produjeron un resultado inequívoco.
Sin embargo, está claro que jina-embeddings-v3 ha superado la brecha lingüística del pre-entrenamiento, convirtiéndose en una herramienta poderosa para aplicaciones multilingües. Está listo para usar en cualquier tarea que requiera un rendimiento fuerte e idéntico en múltiples idiomas.
Puedes usar jina-embeddings-v3 a través de nuestra API de Embeddings (con un millón de tokens gratuitos) o a través de AWS o Azure. Si quieres usarlo fuera de estas plataformas o en las instalaciones de tu empresa, ten en cuenta que está licenciado bajo CC BY-NC 4.0. Contáctanos si estás interesado en el uso comercial.





