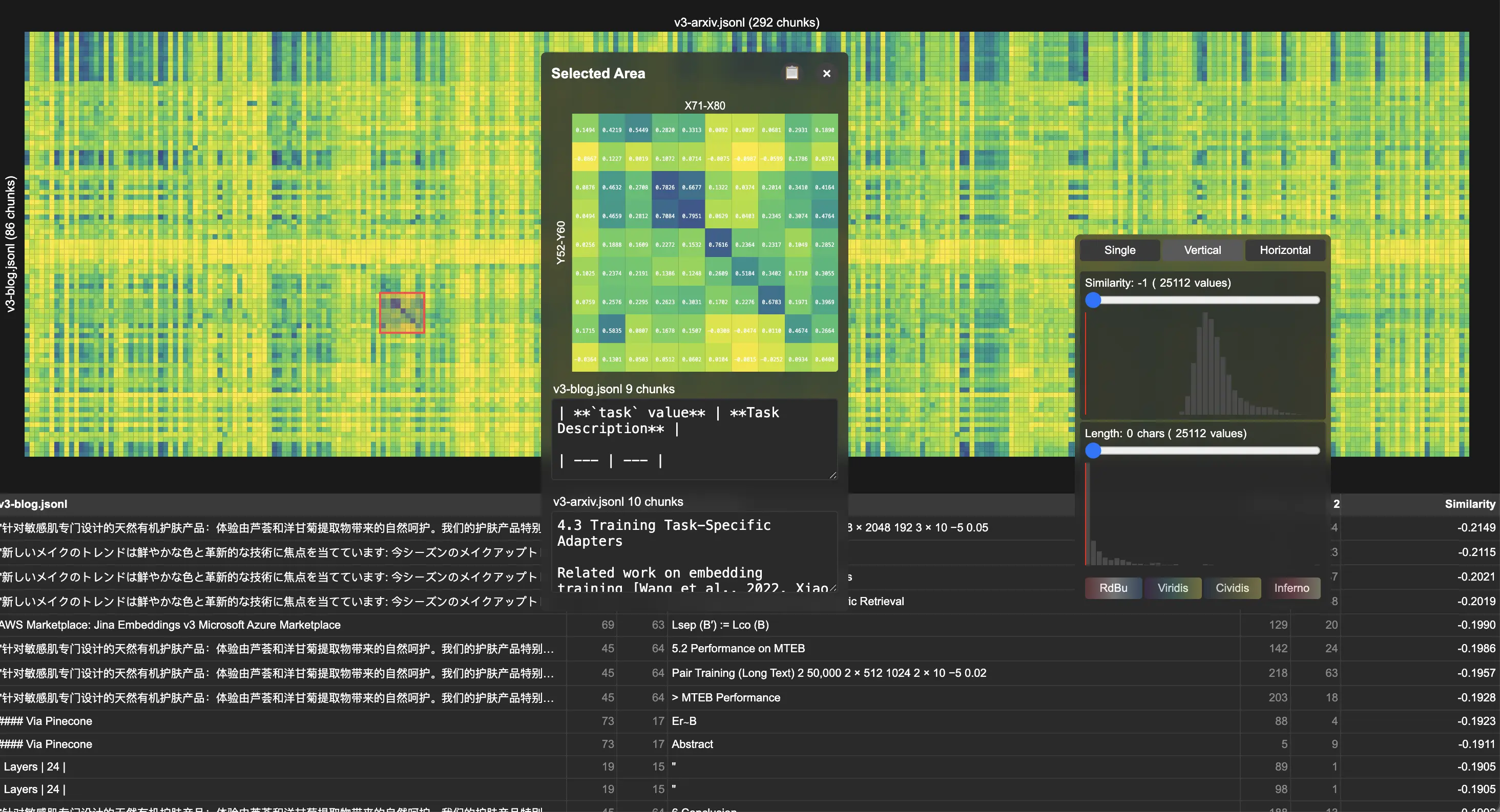


Una de las preguntas interesantes que la gente nos hace es: "¿Cómo comprueban ustedes la calidad de sus modelos de vectores (Embeddings)?" Claro, existe MTEB para una evaluación seria y cuantitativa en pruebas comparativas públicas, pero ¿qué hacen para problemas nuevos o de dominio abierto? Hoy queremos compartir una pequeña herramienta interna que utilizamos para la depuración y la visualización. Pueden llamarla nuestro kit de herramientas de prueba de calidad. Nosotros la llamamos Correlations, y es de código abierto en GitHub.
tagDiseño
Correlations genera mapas de calor interactivos donde cada celda muestra la similitud coseno entre dos fragmentos, ya sean fragmentos de la misma colección de documentos o de diferentes, modalidades, hiperparámetros o modelos. Admite varias interacciones:
- Inspección al pasar el ratón: texto/imagen original y puntuaciones de similitud para pares de celdas individuales
- Selección de región: selección de área interactiva para el análisis enfocado de patrones de similitud
- Filtrado de umbral: filtros de puntuación de similitud y longitud de texto para reducir el ruido
La herramienta funciona a través de una canalización de dos etapas:
npm run embed: Utilizando la API de Jina Embeddings con estrategias de fragmentación configurables (nueva línea, puntuación, basada en caracteres o patrones regex)npm run corr: Interfaz de usuario basada en navegador que sirve mapas de calor de correlación con interactividad en tiempo real
Para empezar:
npm install
export JINA_API_KEY=your_jina_key_here
npm run embed -- https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model -o v3-blog.jsonl -t retrieval.query
npm run embed -- https://arxiv.org/pdf/2409.10173 -o v3-arxiv.jsonl -t retrieval.passage
npm run corr -- v3-blog.jsonl v3-arxiv.jsonlJINA_API_KEY se utiliza para incrustar y leer contenido de una URL cuando es necesario; por supuesto, se admite la lectura desde un archivo de texto local. También puede traer sus propios modelos de vectores (Embeddings) y hacer npm run corr solo para la visualización, en cuyo caso no necesita JINA_API_KEY. La herramienta admite tanto el análisis de autocorrelación (dentro de una sola colección) como el análisis de correlación cruzada (entre dos colecciones).
tagCasos de uso
tagAnálisis de alineación y deduplicación de contenido
Demostramos la utilidad de la herramienta a través del análisis de nuestras publicaciones jina-embeddings-v3. Al comparar el artículo académico con la nota de la versión, la visualización reveló distintos patrones diagonales en el mapa de calor de correlación, lo que indica una fuerte alineación fragmento a fragmento entre documentos. Un examen detallado mostró la reutilización sistemática de contenido, particularmente en las secciones técnicas que describen los tipos de tareas de LoRA.
tagValidación de citas y referencias
La herramienta demuestra ser valiosa para validar la precisión de las citas en los sistemas de generación aumentada de recuperación, donde se vuelve fundamental verificar que los pasajes recuperados realmente respaldan las afirmaciones generadas. El análisis basado en la similitud es una herramienta poderosa e intuitiva para explorar grandes conjuntos de datos, por ejemplo, para revelar patrones agrupando elementos por similitud.
tagExploración de la estrategia de fragmentación (Chunking)
La fragmentación tardía (late chunking) y otras estrategias de segmentación pueden evaluarse examinando cómo los diferentes enfoques afectan la coherencia semántica dentro y entre los segmentos de texto. La visualización ayuda a identificar el efecto de la fragmentación tardía y los límites óptimos de los fragmentos, revelando patrones de similitud que se alinean con la estructura semántica.
tagAnálisis intermodal
La herramienta se extiende más allá del texto para admitir los modelos de 向量模型 (Embeddings) de imágenes a través de jina-clip-v2, lo que permite analizar los patrones de correlación texto-imagen para aplicaciones multimodales.
tagTrabajos relacionados en la visualización de 向量模型 (Embedding)
El desafío de la interpretabilidad es particularmente agudo cuando se trabaja con 向量模型 (embeddings) de alta dimensión. El panorama de las técnicas de visualización de 向量模型 (embedding) ha evolucionado significativamente, y los diferentes enfoques se pueden clasificar como:
- Basados en la reducción de dimensionalidad: Enfoques tradicionales que utilizan PCA, t-SNE, UMAP que proyectan espacios de alta dimensión a 2D/3D
- Basados en la exploración interactiva: Herramientas como Parallax y TextEssence que permiten la manipulación y la exploración directas
- Soluciones específicas del dominio: Herramientas especializadas como Clustergrammer para datos biológicos
- Visualización directa de la similitud: Nuestro enfoque y métodos similares basados en mapas de calor que preservan toda la información relacional
| Método | Enfoque | Casos de uso |
|---|---|---|
| Correlations | Mapas de calor de similitud por pares directos | Depuración de la similitud de texto, análisis de alineación |
| Embedding Projector | PCA, t-SNE y proyecciones lineales personalizadas | Visualización e interpretación interactivas |
| Parallax | Fórmulas algebraicas para la exploración semántica | Comprensión de las relaciones semánticas |
| TextEssence | Análisis comparativo de corpus | Análisis diacrónico, comparación de corpus |
| Nomic Atlas | Visualización escalable basada en la nube | Conjuntos de datos a gran escala, colaboración |
| Clustergrammer | Mapa de calor interactivo con agrupación | Datos biológicos de alta dimensión |
| t-SNE | Visualización no lineal de clústeres | Depuración de modelos, identificación de confusiones |
| UMAP | Preservación de la estructura local y global | Conjuntos de datos medianos-grandes, análisis general |
| PCA | Reducción lineal de la dimensionalidad | Exploración inicial, comparación de referencia |
tagLimitaciones de los enfoques puntuales
Las herramientas de visualización existentes se centran principalmente en representaciones puntuales en espacios 2D, lo que puede provocar la pérdida de información crítica sobre las relaciones por pares. Además, la mayoría de las herramientas están diseñadas para el análisis de un solo espacio de 向量模型 (embedding) en lugar de la evaluación comparativa entre diferentes fuentes, modalidades o estrategias de 向量模型 (embedding) (por ejemplo, la fragmentación tardía activada frente a desactivada).
Por ejemplo, recientemente nos encontramos con dos casos de uso en Jina. El primero implica la verificación cruzada de citas en DeepSearch, donde necesitamos hacer coincidir el informe generado con los extractos originales del material de referencia. El segundo es la recuperación multimodal, donde necesitamos verificar la alineación imagen-texto e imagen-imagen en nuevos datos no etiquetados. En ambos casos, necesitamos explorar las relaciones entre dos colecciones de 向量模型 (embeddings). Por lo tanto, utilizamos Correlations para tener una idea de cuán bien se alinean las coincidencias y para validar si las correlaciones más altas corresponden consistentemente a las coincidencias correctas.
tagConclusión
Más allá de la verificación del ambiente, correlations puede proporcionar información más profunda sobre las relaciones semánticas. Como punto de partida, se pueden extraer varias estadísticas clave de la matriz de correlación:
- Densidad de la matriz: La proporción de correlaciones por encima de los umbrales especificados, lo que indica la cohesión semántica general
- Distribución de valores propios: El análisis de componentes principales revela los patrones dominantes en la estructura de similitud
- Rango de la matriz: Indica la dimensionalidad efectiva de las relaciones de similitud
- Número de condición: Mide la estabilidad numérica y los posibles problemas de multicolinealidad
El análisis avanzado también puede implicar la extracción de submatrices significativas que representen regiones semánticas coherentes. La extracción de una submatriz principal de suma máxima de orden k de una matriz real de orden n es un problema típico de optimización combinatoria que puede identificar los segmentos más altamente correlacionados.






