

Recientemente he estado investigando DSPy, un framework de vanguardia desarrollado por el grupo de NLP de Stanford dirigido a optimizar algorítmicamente los prompts de modelos de lenguaje (LM). Durante los últimos tres días, he recopilado algunas impresiones iniciales y perspectivas valiosas sobre DSPy. Ten en cuenta que mis observaciones no pretenden reemplazar la documentación oficial de DSPy. De hecho, recomiendo encarecidamente leer su documentación y README al menos una vez antes de sumergirse en esta publicación. Mi discusión aquí refleja un entendimiento preliminar de DSPy, habiendo pasado algunos días explorando sus capacidades. Hay varias funciones avanzadas, como DSPy Assertions, Typed Predictor y el ajuste de pesos de LM, que aún no he explorado a fondo.
 stanfordnlp
stanfordnlpA pesar de mi experiencia con Jina AI, que se centra principalmente en la base de búsqueda, mi interés en DSPy no fue impulsado directamente por su potencial en la Generación Aumentada por Recuperación (RAG). En cambio, me intrigó la posibilidad de aprovechar DSPy para el ajuste automático de prompts para abordar algunas tareas de generación.
Si eres nuevo en DSPy y buscas un punto de entrada accesible, o si estás familiarizado con el framework pero encuentras que la documentación oficial es confusa o abrumadora, este artículo está destinado a ti. También opto por _no_ adherirme estrictamente al estilo de DSPy, que puede parecer desalentador para los principiantes. Dicho esto, profundicemos.
tagLo que me gusta de DSPy
tagDSPy cerrando el ciclo de la ingeniería de prompts
Lo que más me emociona de DSPy es su enfoque para cerrar el ciclo del proceso de ingeniería de prompts, transformando lo que a menudo es un proceso _manual_, _artesanal_ en un flujo de trabajo de aprendizaje automático _estructurado_, _bien definido_: es decir, preparar conjuntos de datos, definir el modelo, entrenar, evaluar y probar. En mi opinión, este es el aspecto más revolucionario de DSPy.
Viajando por el Área de la Bahía y hablando con muchos fundadores de startups centrados en la evaluación de LLM, me he encontrado con frecuentes discusiones sobre métricas, alucinaciones, observabilidad y cumplimiento. Sin embargo, estas conversaciones a menudo no progresan hacia los pasos críticos siguientes: Con todas estas métricas en la mano, ¿qué hacemos después? ¿Puede considerarse un enfoque estratégico ajustar la redacción en nuestros prompts, con la esperanza de que ciertas palabras mágicas (por ejemplo, "mi abuela se está muriendo") puedan mejorar nuestras métricas? Esta pregunta ha quedado sin respuesta por parte de muchas startups de evaluación de LLM, y era una que yo tampoco podía abordar, hasta que descubrí DSPy. DSPy introduce un método claro y programático para optimizar prompts basado en métricas específicas, o incluso para optimizar todo el pipeline de LLM, incluyendo tanto los prompts como los pesos del LLM.
Harrison, el CEO de LangChain, y Logan, el ex Jefe de Relaciones con Desarrolladores de OpenAI, han declarado en el podcast Unsupervised Learning que 2024 será un año crucial para la evaluación de LLM. Es por esta razón que creo que DSPy merece más atención de la que está recibiendo actualmente, ya que DSPy proporciona la pieza crucial que faltaba en el rompecabezas.
tagDSPy separando la lógica de la representación textual
Otro aspecto de DSPy que me impresiona es que formula la ingeniería de prompts en un módulo reproducible y agnóstico del LLM. Para lograrlo, extrae la lógica del prompt, creando una clara separación de responsabilidades entre la _lógica_ y la _representación textual_, como se ilustra a continuación.
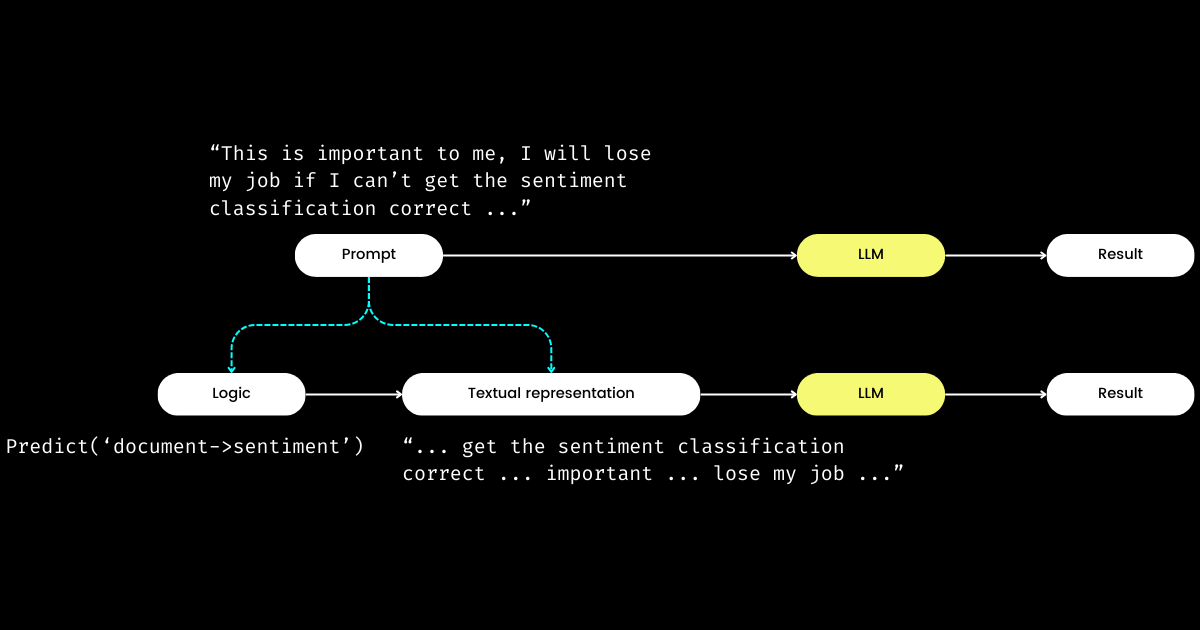
dspy.Module,) y su representación textual. La lógica es inmutable, reproducible, comprobable y agnóstica del LLM. La representación textual es solo la consecuencia de la lógica.El concepto de DSPy de la lógica como la "causa" inmutable, comprobable y agnóstica del LLM, con la representación textual simplemente como su "consecuencia", puede parecer desconcertante al principio. Esto es especialmente cierto a la luz de la creencia generalizada de que "el futuro de los lenguajes de programación es el lenguaje natural". Abrazando la idea de que "la ingeniería de prompts es el futuro", uno podría experimentar un momento de confusión al encontrarse con la filosofía de diseño de DSPy. Contrario a la expectativa de simplificación, DSPy introduce una serie de módulos y sintaxis de firmas, ¡aparentemente regresando el prompting en lenguaje natural a la complejidad de la programación en C!
Pero ¿por qué adoptar este enfoque? Mi entendimiento es que en el corazón de la programación de prompts se encuentra la lógica central, con la comunicación sirviendo como un amplificador, potencialmente mejorando o disminuyendo su efectividad. La directiva "Hacer clasificación de sentimientos" representa la lógica central, mientras que una frase como "Sigue estas demostraciones o te despediré" es una forma de comunicarlo. Análogamente a las interacciones de la vida real, las dificultades para lograr las cosas a menudo no provienen de una lógica defectuosa sino de comunicaciones problemáticas. Esto explica por qué muchos, particularmente los no nativos, encuentran desafiante la ingeniería de prompts. He observado a ingenieros de software altamente competentes en mi empresa luchar con la ingeniería de prompts, no debido a una falta de lógica, sino porque no "hablan el lenguaje". Al separar la lógica del prompt, DSPy permite la programación determinista de la lógica a través de dspy.Module, permitiendo a los desarrolladores centrarse en la lógica de la misma manera que lo harían en la ingeniería tradicional, independientemente del LLM utilizado.
Entonces, si los desarrolladores se centran en la lógica, ¿quién gestiona la representación textual? DSPy asume este rol, utilizando tus datos y métricas de evaluación para refinar la representación textual—todo, desde determinar el enfoque narrativo hasta optimizar las pistas y elegir buenas demostraciones. Sorprendentemente, DSPy incluso puede usar métricas de evaluación para ajustar los pesos del LLM!
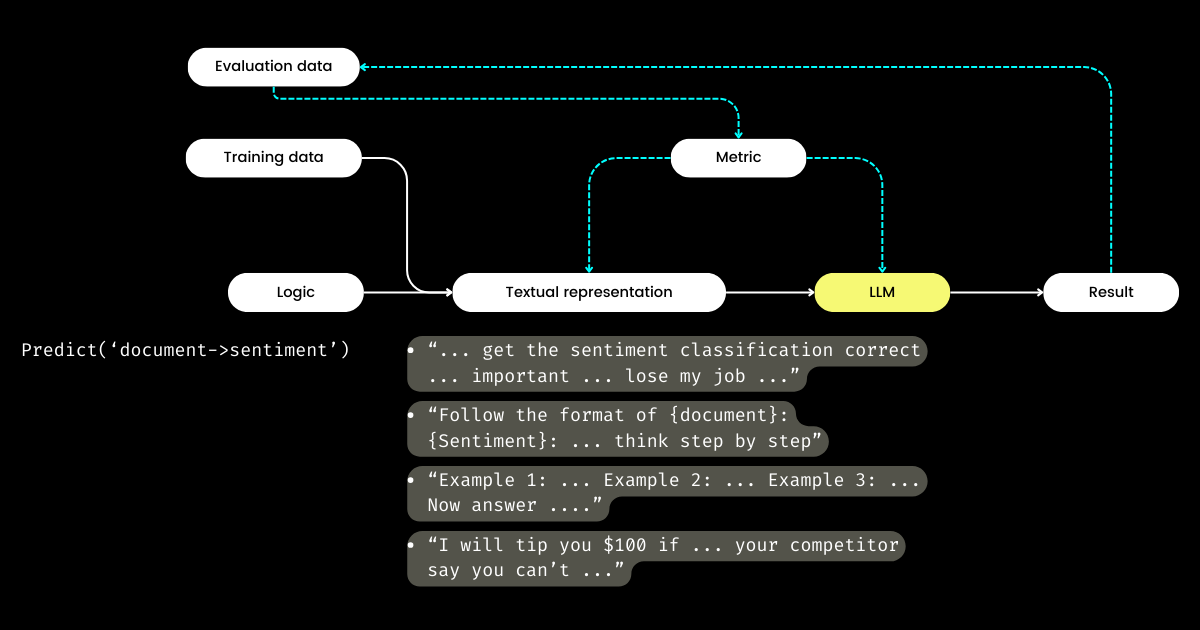
Para mí, las contribuciones clave de DSPy—cerrar el ciclo de entrenamiento y evaluación en la ingeniería de prompts y separar la lógica de la representación textual—subrayan su potencial significativo para los sistemas LLM/Agent. ¡Una visión ambiciosa sin duda, pero definitivamente necesaria!
tagLo que creo que DSPy puede mejorar
Primero, DSPy presenta una curva de aprendizaje pronunciada para los principiantes debido a sus modismos. Términos como signature, module, program, teleprompter, optimization, y compile pueden ser abrumadores. Incluso para aquellos competentes en ingeniería de prompts, navegar por estos conceptos dentro de DSPy puede ser un laberinto desafiante.
Esta complejidad refleja mi experiencia con Jina 1.0, donde introdujimos una serie de conceptos como chunk, document, driver, executor, pea, pod, querylang y flow (¡incluso diseñamos adorables stickers para ayudar a los usuarios a recordarlos!).






La mayoría de estos conceptos iniciales fueron eliminados en posteriores refactorizaciones de Jina. Hoy, solo Executor, Document y Flow han sobrevivido a "la gran purga". Agregamos un nuevo concepto, Deployment, en Jina 3.0; así que eso equilibra las cosas. 🤷
Este problema no es exclusivo de DSPy o Jina; recordemos la multitud de conceptos y abstracciones introducidos por TensorFlow entre las versiones 0.x y 1.x. Creo que este problema surge a menudo en las primeras etapas de los frameworks de software, donde hay un impulso por reflejar las notaciones académicas directamente en el código para garantizar la máxima precisión y reproducibilidad. Sin embargo, no todos los usuarios valoran tales abstracciones granulares, con preferencias que varían desde el deseo de líneas simples hasta demandas de mayor flexibilidad. Discutí extensamente este tema de la abstracción en frameworks de software en una publicación de blog de 2020, que los lectores interesados podrían encontrar útil.


En segundo lugar, la documentación de DSPy a veces carece de consistencia. Términos como module y program, teleprompter y optimizer, o optimize y compile (a veces referidos como training o bootstrapping) se usan indistintamente, aumentando la confusión. En consecuencia, pasé mis primeras horas con DSPy tratando de descifrar exactamente qué optimiza y qué implica el proceso de bootstrapping.
A pesar de estos obstáculos, a medida que profundizas en DSPy y revisas la documentación, probablemente experimentarás momentos de claridad donde todo comienza a tener sentido, revelando las conexiones entre su terminología única y las construcciones familiares vistas en frameworks como PyTorch. Sin embargo, DSPy sin duda tiene margen de mejora en futuras versiones, particularmente en hacer el framework más accesible para ingenieros de prompts sin experiencia en PyTorch.
tagObstáculos Comunes para Principiantes en DSPy
En las siguientes secciones, he compilado una lista de preguntas que inicialmente obstaculizaron mi progreso con DSPy. Mi objetivo es compartir estas ideas con la esperanza de que puedan aclarar desafíos similares para otros estudiantes.
tag¿Qué son teleprompter, optimization y compile? ¿Qué se optimiza exactamente en DSPy?
En DSPy, "Teleprompters" es el optimizador (y parece que @lateinteraction está actualizando la documentación y el código para aclarar esto). La función compile actúa en el corazón de este optimizador, similar a llamar optimizer.optimize(). Piensa en ello como el equivalente al entrenamiento en DSPy. Este proceso compile() busca ajustar:
- las demostraciones de few-shot,
- las instrucciones,
- los pesos del LLM
Sin embargo, la mayoría de los tutoriales básicos de DSPy no profundizan en el ajuste de pesos e instrucciones, lo que lleva a la siguiente pregunta.
tag¿De qué se trata el bootstrap en DSPy?
Bootstrap se refiere a la creación de demostraciones autogeneradas para el aprendizaje few-shot en contexto, una parte crucial del proceso compile() (es decir, optimización/entrenamiento como mencioné arriba). Estas demostraciones few-shot se generan a partir de datos etiquetados proporcionados por el usuario; y una demostración a menudo consiste en entrada, salida, razonamiento (por ejemplo, en Cadenas de Pensamiento), y entradas y salidas intermedias (para prompts de múltiples etapas). Por supuesto, las demostraciones few-shot de calidad son clave para la excelencia de la salida. Para ello, DSPy permite funciones métricas definidas por el usuario para asegurar que solo se elijan las demostraciones que cumplan ciertos criterios, lo que lleva a la siguiente pregunta.
tag¿Qué es la función métrica de DSPy?
Después de la experiencia práctica con DSPy, he llegado a creer que la función métrica necesita mucho más énfasis que lo que proporciona la documentación actual. La función métrica en DSPy juega un papel crucial tanto en las fases de evaluación como de entrenamiento, actuando también como función de "pérdida", gracias a su naturaleza implícita (controlada por trace=None):
def keywords_match_jaccard_metric(example, pred, trace=None):
# Jaccard similarity between example keywords and predicted keywords
A = set(normalize_text(example.keywords).split())
B = set(normalize_text(pred.keywords).split())
j = len(A & B) / len(A | B)
if trace is not None:
# act as a "loss" function
return j
return j > 0.8 # act as evaluationEste enfoque difiere significativamente del aprendizaje automático tradicional, donde la función de pérdida suele ser continua y diferenciable (por ejemplo, hinge/MSE), mientras que la métrica de evaluación puede ser completamente diferente y discreta (por ejemplo, NDCG). En DSPy, las funciones de evaluación y pérdida están unificadas en la función métrica, que puede ser discreta y la mayoría de las veces devuelve un valor booleano. ¡La función métrica también puede integrar un LLM! En el ejemplo siguiente, implementé una coincidencia aproximada usando LLM para determinar si el valor predicho y la respuesta estándar son similares en magnitud, por ejemplo, "1 millón de dólares" y "$1M" devolverían verdadero.
class Assess(dspy.Signature):
"""Assess the if the prediction is in the same magnitude to the gold answer."""
gold_answer = dspy.InputField(desc='number, could be in natural language')
prediction = dspy.InputField(desc='number, could be in natural language')
assessment = dspy.OutputField(desc='yes or no, focus on the number magnitude, not the unit or exact value or wording')
def same_magnitude_correct(example, pred, trace=None):
return dspy.Predict(Assess)(gold_answer=example.answer, prediction=pred.answer).assessment.lower() == 'yes'Por poderosa que sea, la función métrica influye significativamente en la experiencia del usuario de DSPy, determinando no solo la evaluación final de calidad sino también afectando los resultados de la optimización. Una función métrica bien diseñada puede llevar a prompts optimizados, mientras que una mal elaborada puede hacer que la optimización falle. Al abordar un nuevo problema con DSPy, podrías encontrarte dedicando tanto tiempo a diseñar la lógica (es decir, DSPy.Module) como a la función métrica. Este doble enfoque en lógica y métricas puede ser intimidante para los principiantes.
tag"Bootstrapped 0 full traces after 20 examples in round 0" ¿qué significa esto?
Este mensaje que aparece silenciosamente durante compile() merece tu máxima atención, ya que esencialmente significa que la optimización/compilación falló, y el prompt que obtienes no es mejor que un simple few-shot. ¿Qué salió mal? He resumido algunos consejos para ayudarte a depurar tu programa DSPy cuando encuentres este mensaje:
Tu Función Métrica es Incorrecta
¿Está la función your_metric, usada en BootstrapFewShot(metric=your_metric), correctamente implementada? Realiza algunas pruebas unitarias. ¿Tu your_metric devuelve alguna vez True, o siempre devuelve False? Ten en cuenta que devolver True es crucial porque es el criterio para que DSPy considere el ejemplo bootstrapped como un "éxito". Si devuelves cada evaluación como True, ¡entonces cada ejemplo es considerado un "éxito" en el bootstrapping! Esto no es ideal, por supuesto, pero es cómo puedes ajustar la rigurosidad de la función métrica para cambiar el resultado "Bootstrapped 0 full traces". Ten en cuenta que aunque DSPy documenta que las métricas también pueden devolver valores escalares, después de revisar el código subyacente, no lo recomendaría para principiantes.
Tu Lógica (DSPy.Module) es Incorrecta
Si la función métrica es correcta, entonces necesitas verificar si tu lógica dspy.Module está correctamente implementada. Primero, verifica que la firma DSPy está correctamente asignada para cada paso. Las firmas en línea, como dspy.Predict('question->answer'), son fáciles de usar, pero por calidad, sugiero fuertemente implementar con firmas basadas en clases. Específicamente, agrega algunas docstrings descriptivas a la clase, completa los campos desc para InputField y OutputField—todo esto proporciona pistas al LM sobre cada campo. A continuación implementé dos DSPy.Module multi-etapa para resolver problemas de Fermi, uno con firma en línea, otro con firma basada en clases.
class FermiSolver(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict('question -> initial_guess')
self.step2 = dspy.Predict('question, initial_guess -> calculated_estimation')
self.step3 = dspy.Predict('question, initial_guess, calculated_estimation -> variables_and_formulae')
self.step4 = dspy.ReAct('question, initial_guess, calculated_estimation, variables_and_formulae -> gathering_data')
self.step5 = dspy.Predict('question, initial_guess, calculated_estimation, variables_and_formulae, gathering_data -> answer')
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Solucionador de problemas Fermi usando solo firma en línea
class FermiStep1(dspy.Signature):
question = dspy.InputField(desc='Fermi problems involve the use of estimation and reasoning')
initial_guess = dspy.OutputField(desc='Have a guess – don't do any calculations yet')
class FermiStep2(FermiStep1):
initial_guess = dspy.InputField(desc='Have a guess – don't do any calculations yet')
calculated_estimation = dspy.OutputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
class FermiStep3(FermiStep2):
calculated_estimation = dspy.InputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
variables_and_formulae = dspy.OutputField(desc='Write a formula or procedure to solve your problem')
class FermiStep4(FermiStep3):
variables_and_formulae = dspy.InputField(desc='Write a formula or procedure to solve your problem')
gathering_data = dspy.OutputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
class FermiStep5(FermiStep4):
gathering_data = dspy.InputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
answer = dspy.OutputField(desc='the final answer, must be a numerical value')
class FermiSolver2(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict(FermiStep1)
self.step2 = dspy.Predict(FermiStep2)
self.step3 = dspy.Predict(FermiStep3)
self.step4 = dspy.Predict(FermiStep4)
self.step5 = dspy.Predict(FermiStep5)
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5Solucionador de problemas Fermi usando firma basada en clases con descripción más completa de cada campo.
Además, revisa la parte def forward(self, ). Para Modules multi-etapa, asegúrate de que la salida (o todas las salidas como en FermiSolver) del último paso se alimenta como entrada al siguiente paso.
Tu Problema es Simplemente Demasiado Difícil
Si tanto la métrica como el módulo parecen correctos, entonces es posible que tu problema sea simplemente demasiado desafiante y la lógica que implementaste no sea suficiente para resolverlo. Por lo tanto, DSPy encuentra que es inviable hacer bootstrap de cualquier demo dada tu lógica y función métrica. En este punto, aquí hay algunas opciones que puedes considerar:
- Usar un LM más potente. Por ejemplo, reemplazar
gpt-35-turbo-instructcongpt-4-turbocomo el LM del estudiante, usar un LM más fuerte como profesor. Esto puede ser bastante efectivo. Después de todo, un modelo más fuerte significa mejor comprensión de los prompts. - Mejorar tu lógica. Agregar o reemplazar algunos pasos en tu
dspy.Modulecon otros más complicados. Por ejemplo, reemplazarPredictporChainOfThoughtProgramOfThought, agregando el pasoRetrieval. - Agregar más ejemplos de entrenamiento. Si 20 ejemplos no son suficientes, ¡apunta a 100! Entonces puedes esperar que un ejemplo pase la verificación métrica y sea seleccionado por
BootstrapFewShot. - Reformular el problema. A menudo, un problema se vuelve irresoluble cuando la formulación es incorrecta. Pero si cambias el ángulo para mirarlo, las cosas podrían ser mucho más fáciles y obvias.
En la práctica, el proceso involucra una mezcla de prueba y error. Por ejemplo, abordé un problema particularmente desafiante: generar un icono SVG similar a los iconos de Google Material Design basado en dos o tres palabras clave. Mi estrategia inicial fue utilizar un simple DSPy.Module que usa dspy.ChainOfThought('keywords -> svg'), emparejado con una función métrica que evaluaba la similitud visual entre el SVG generado y el SVG de Material Design de referencia, similar a un algoritmo pHash. Comencé con 20 ejemplos de entrenamiento, pero después de la primera ronda, terminé con "Bootstrapped 0 full traces after 20 examples in round 0", indicando que la optimización había fallado. Al aumentar el conjunto de datos a 100 ejemplos, revisar mi módulo para incorporar múltiples etapas y ajustar el umbral de la función métrica, finalmente logré 2 demostraciones bootstrapped y conseguí obtener algunos prompts optimizados.
