

La fundamentación es absolutamente esencial para las aplicaciones de GenAI.
Sin fundamentación, los LLMs son más propensos a las alucinaciones y a generar información inexacta, especialmente cuando sus datos de entrenamiento carecen de conocimientos actualizados o específicos. No importa qué tan fuerte sea la capacidad de razonamiento de un LLM, simplemente no puede proporcionar una respuesta correcta si la información fue introducida después de su fecha límite de conocimiento.
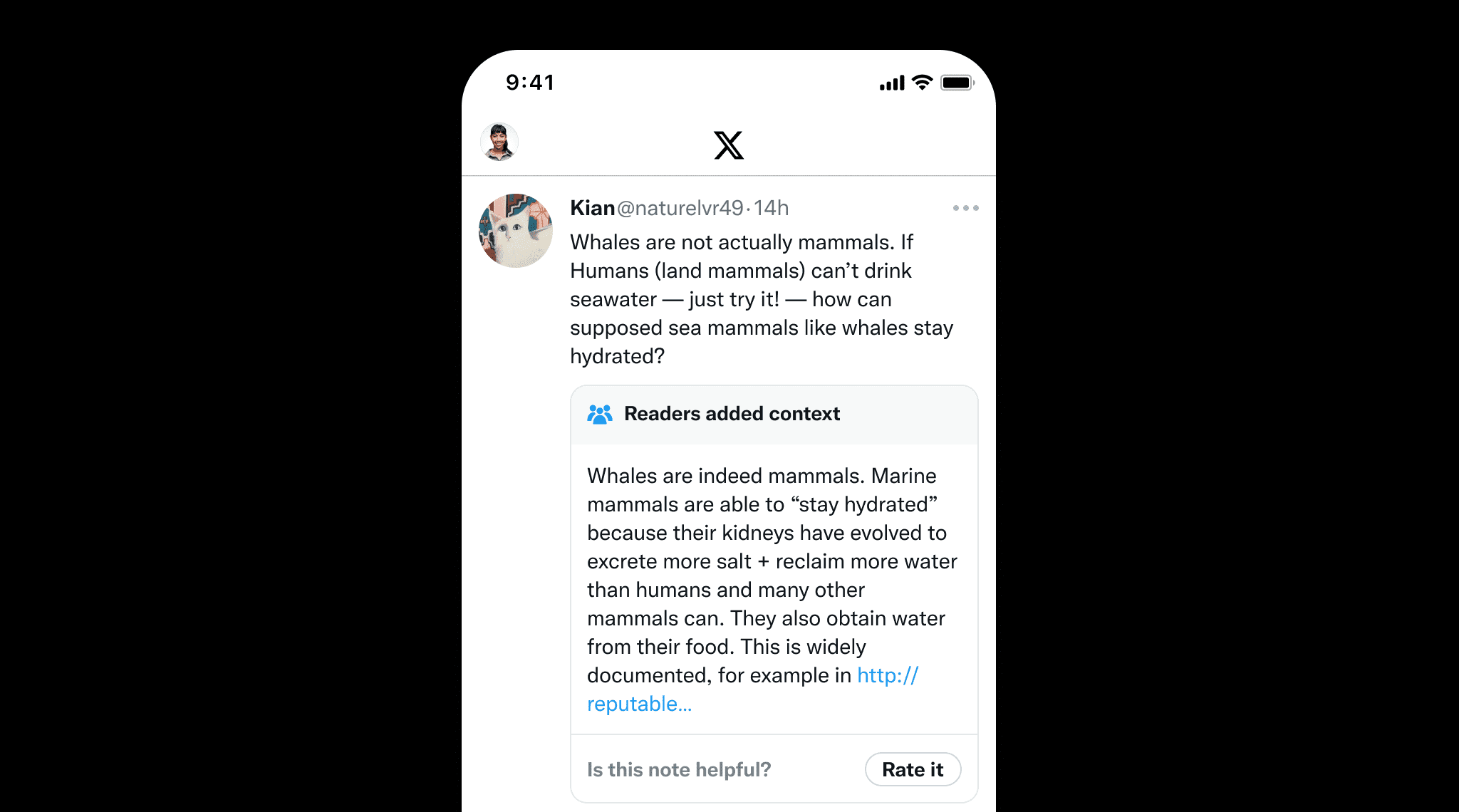
La fundamentación no solo es importante para los LLMs sino también para el contenido escrito por humanos para prevenir la desinformación. Un gran ejemplo es Community Notes de X, donde los usuarios añaden colaborativamente contexto a publicaciones potencialmente engañosas. Esto resalta el valor de la fundamentación, que asegura la precisión factual proporcionando fuentes y referencias claras, de manera similar a como Community Notes ayuda a mantener la integridad de la información.
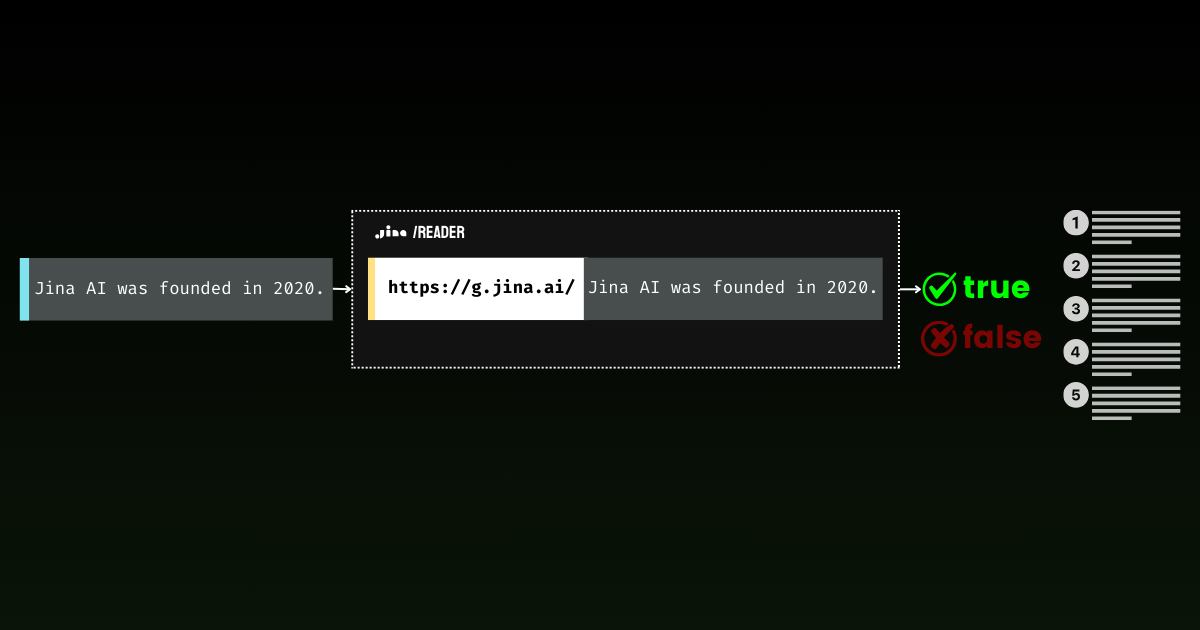
Con Jina Reader, hemos estado desarrollando activamente una solución de fundamentación fácil de usar. Por ejemplo, r.jina.ai convierte páginas web en markdown compatible con LLM, y s.jina.ai agrega resultados de búsqueda en un formato markdown unificado basado en una consulta dada.

Hoy, nos complace presentar un nuevo endpoint para esta suite: g.jina.ai. La nueva API toma una declaración dada, la fundamenta usando resultados de búsqueda web en tiempo real, y devuelve una puntuación de factualidad y las referencias exactas utilizadas. Nuestros experimentos muestran que esta API logra una puntuación F1 más alta para la verificación de hechos en comparación con modelos como GPT-4, o1-mini y Gemini 1.5 Flash & Pro con fundamentación basada en búsqueda.

Lo que distingue a g.jina.ai de la Fundamentación por Búsqueda de Gemini es que cada resultado incluye hasta 30 URLs (típicamente proporcionando al menos 10), cada una acompañada de citas directas que contribuyen a la conclusión. A continuación hay un ejemplo de fundamentación de la declaración, "The latest model released by Jina AI is jina-embeddings-v3," usando g.jina.ai (a fecha del 14 de octubre de 2024). Explora el playground de la API para descubrir todas las funcionalidades. Ten en cuenta que se aplican limitaciones:
curl -X POST https://g.jina.ai \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_JINA_TOKEN" \
-d '{
"statement":"the last model released by Jina AI is jina-embeddings-v3"
}'YOUR_JINA_TOKEN es tu clave API de Jina AI. Puedes obtener 1M de tokens gratuitos desde nuestra página principal, que permite aproximadamente tres o cuatro pruebas gratuitas. Con el precio actual de la API de 0.02USD por 1M de tokens, cada solicitud de fundamentación cuesta aproximadamente $0.006.
{
"code": 200,
"status": 20000,
"data": {
"factuality": 0.95,
"result": true,
"reason": "The majority of the references explicitly support the statement that the last model released by Jina AI is jina-embeddings-v3. Multiple sources, such as the arXiv paper, Jina AI's news, and various model documentation pages, confirm this assertion. Although there are a few references to the jina-embeddings-v2 model, they do not provide evidence contradicting the release of a subsequent version (jina-embeddings-v3). Therefore, the statement that 'the last model released by Jina AI is jina-embeddings-v3' is well-supported by the provided documentation.",
"references": [
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "arXiv September 18, 2024 jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://arxiv.org/abs/2409.10173",
"keyQuote": "We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens.",
"isSupportive": true
},
{
"url": "https://azuremarketplace.microsoft.com/en-us/marketplace/apps/jinaai.jina-embeddings-v3?tab=Overview",
"keyQuote": "jina-embeddings-v3 is a multilingual multi-task text embedding model designed for a variety of NLP applications.",
"isSupportive": true
},
{
"url": "https://docs.pinecone.io/models/jina-embeddings-v3",
"keyQuote": "Jina Embeddings v3 is the latest iteration in the Jina AI's text embedding model series, building upon Jina Embedding v2.",
"isSupportive": true
},
{
"url": "https://haystack.deepset.ai/integrations/jina",
"keyQuote": "Recommended Model: jina-embeddings-v3 : We recommend jina-embeddings-v3 as the latest and most performant embedding model from Jina AI.",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "The embedding model was trained using 512 sequence length, but extrapolates to 8k sequence length (or even longer) thanks to ALiBi.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "With a standard size of 137 million parameters, the model enables fast inference while delivering better performance than our small model.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v2-base-en",
"keyQuote": "We offer an `encode` function to deal with this.",
"isSupportive": false
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jinaai/jina-embeddings-v3 Feature Extraction • Updated 3 days ago • 278k • 375",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "the latest version (3.1.0) of [SentenceTransformers] also supports jina-embeddings-v3",
"isSupportive": true
},
{
"url": "https://huggingface.co/jinaai/jina-embeddings-v3",
"keyQuote": "jina-embeddings-v3: Multilingual Embeddings With Task LoRA",
"isSupportive": true
},
{
"url": "https://jina.ai/embeddings/",
"keyQuote": "v3: Frontier Multilingual Embeddings is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model",
"keyQuote": "Jina Embeddings v3: A Frontier Multilingual Embedding Model jina-embeddings-v3 is a frontier multilingual text embedding model with 570M parameters and 8192 token-length, outperforming the latest proprietary embeddings from OpenAI and Cohere on MTEB.",
"isSupportive": true
},
{
"url": "https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model/",
"keyQuote": "As of its release on September 18, 2024, jina-embeddings-v3 is the best multilingual model ...",
"isSupportive": true
}
],
"usage": {
"tokens": 112073
}
}
}La respuesta de la fundamentación de la declaración "The latest model released by Jina AI is jina-embeddings-v3," usando g.jina.ai (a fecha del 14 de octubre de 2024).
tag¿Cómo Funciona?
En su núcleo, g.jina.ai envuelve s.jina.ai y r.jina.ai , añadiendo razonamiento de múltiples pasos a través de Chain of Thought (CoT). Este enfoque asegura que cada declaración fundamentada sea analizada minuciosamente con la ayuda de búsquedas en línea y lectura de documentos.

s.jina.ai y r.jina.ai, añadiendo CoT para planificación y razonamiento. tagExplicación Paso a Paso
Veamos todo el proceso para entender mejor cómo g.jina.ai maneja la verificación desde la entrada hasta la salida final:
- Declaración de Entrada:
El proceso comienza cuando un usuario proporciona una declaración que desea verificar, como "El último modelo lanzado por Jina AI es jina-embeddings-v3." Nota, no es necesario agregar ninguna instrucción de verificación de hechos antes de la declaración. - Generar Consultas de Búsqueda:
Se emplea un LLM para generar una lista de consultas de búsqueda únicas que son relevantes para la declaración. Estas consultas buscan abordar diferentes elementos factuales, asegurando que la búsqueda cubra todos los aspectos clave de la declaración de manera integral. - Llamar a
s.jina.aipara Cada Consulta:
Para cada consulta generada,g.jina.airealiza una búsqueda web usandos.jina.ai. Los resultados de búsqueda consisten en un conjunto diverso de sitios web o documentos relacionados con las consultas. Detrás de escena,s.jina.aillama ar.jina.aipara obtener el contenido de la página. - Extraer Referencias de los Resultados de Búsqueda:
De cada documento recuperado durante la búsqueda, un LLM extrae las referencias clave. Estas referencias incluyen:url: La dirección web de la fuente.keyQuote: Una cita directa o extracto del documento.isSupportive: Un valor booleano que indica si la referencia apoya o contradice la declaración original.
- Agregar y Recortar Referencias:
Todas las referencias de los documentos recuperados se combinan en una sola lista. Si el número total de referencias excede 30, el sistema selecciona 30 referencias aleatorias para mantener una salida manejable. - Evaluar la Declaración:
El proceso de evaluación implica usar un LLM para evaluar la declaración basándose en las referencias recopiladas (hasta 30). Además de estas referencias externas, el conocimiento interno del modelo también juega un papel en la evaluación. El resultado final incluye:factuality: Una puntuación entre 0 y 1 que estima la precisión factual de la declaración.result: Un valor booleano que indica si la declaración es verdadera o falsa.reason: Una explicación detallada de por qué la declaración se juzga como correcta o incorrecta, haciendo referencia a las fuentes que la apoyan o contradicen.
- Generar el Resultado:
Una vez que la declaración ha sido completamente evaluada, se genera la salida. Esto incluye la puntuación de factualidad, la afirmación de la declaración, un razonamiento detallado, y una lista de referencias con citas y URLs. Las referencias se limitan a la cita, URL y si apoyan o no la declaración, manteniendo la salida clara y concisa.
tagEvaluación Comparativa
Recopilamos manualmente 100 declaraciones con etiquetas de verdad de true (62 declaraciones) o false (38 declaraciones) y utilizamos diferentes métodos para determinar si podían ser verificadas. Este proceso esencialmente convierte la tarea en un problema de clasificación binaria, donde el rendimiento final se mide por la precisión, recuperación y puntuación F1—cuanto más alto, mejor.
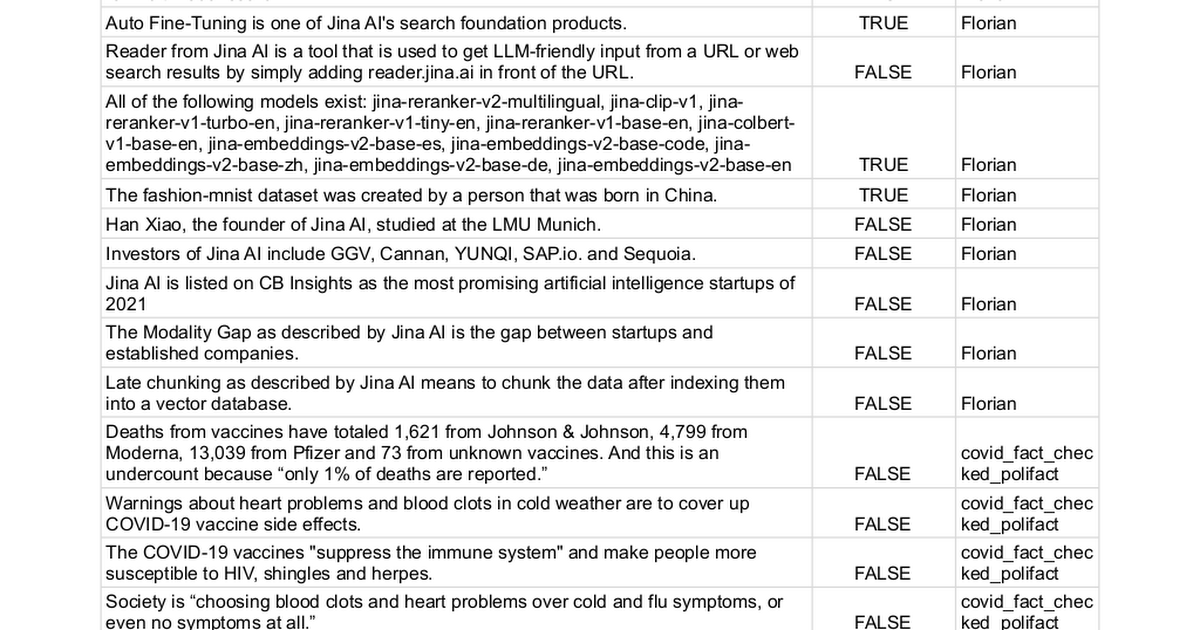
La lista completa de declaraciones puede encontrarse aquí.
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| Jina AI Grounding API (g.jina.ai) | 0.96 | 0.88 | 0.92 |
| Gemini-flash-1.5-002 w/ grounding | 1.00 | 0.73 | 0.84 |
| Gemini-pro-1.5-002 w/ grounding | 0.98 | 0.71 | 0.82 |
| gpt-o1-mini | 0.87 | 0.66 | 0.75 |
| gpt-4o | 0.95 | 0.58 | 0.72 |
| Gemini-pro-1.5-001 w/ grounding | 0.97 | 0.52 | 0.67 |
| Gemini-pro-1.5-001 | 0.95 | 0.32 | 0.48 |
Nota: en la práctica, algunos LLMs devuelven una tercera clase, No lo sé, en sus predicciones. Para la evaluación, estas instancias se excluyen del cálculo de la puntuación. Este enfoque evita penalizar la incertidumbre tan severamente como las respuestas incorrectas. Es preferible admitir la incertidumbre a adivinar, para desalentar a los modelos de hacer predicciones inciertas.
tagLimitaciones
A pesar de los resultados prometedores, nos gustaría destacar algunas limitaciones de la versión actual del API de grounding:
- Alta Latencia y Consumo de Tokens: Una sola llamada a
g.jina.aipuede tomar alrededor de 30 segundos y usar hasta 300K tokens, debido a la búsqueda web activa, lectura de páginas y razonamiento multi-hop por el LLM. Con una clave API gratuita de 1M de tokens, esto significa que solo puedes probarlo unas tres o cuatro veces. Para mantener la disponibilidad del servicio para usuarios pagados, también hemos implementado un límite de tasa conservador parag.jina.ai. Con nuestro precio actual de API de $0.02 por 1M de tokens, cada solicitud de verificación cuesta aproximadamente 0.006 USD. - Restricciones de Aplicabilidad: No toda declaración puede o debe ser verificada. Las opiniones o experiencias personales, como "Me siento perezoso", no son adecuadas para verificación. De manera similar, eventos futuros o declaraciones hipotéticas no aplican. Hay muchos casos donde la verificación sería irrelevante o sin sentido. Para evitar llamadas API innecesarias, recomendamos a los usuarios enviar selectivamente solo oraciones o secciones que realmente requieren verificación de hechos. En el lado del servidor, hemos implementado un conjunto completo de códigos de error para explicar por qué una declaración podría ser rechazada para verificación.
- Dependencia de la Calidad de Datos Web: La precisión del API de grounding es tan buena como la calidad de las fuentes que recupera. Si los resultados de búsqueda contienen información de baja calidad o sesgada, el proceso de verificación podría reflejar eso, potencialmente llevando a conclusiones inexactas o engañosas. Para prevenir este problema, permitimos a los usuarios especificar manualmente el parámetro
referencesy restringir las URLs contra las que el sistema busca. Esto da a los usuarios más control sobre las fuentes utilizadas para la verificación, asegurando un proceso de verificación de hechos más enfocado y relevante.
tagConclusión
El API de grounding ofrece una experiencia de verificación de hechos de principio a fin en tiempo casi real. Los investigadores pueden usarla para encontrar referencias que apoyen o desafíen sus hipótesis, añadiendo credibilidad a su trabajo. En reuniones empresariales, asegura que las estrategias se construyan sobre información precisa y actualizada mediante la validación de suposiciones y datos. En discusiones políticas, verifica rápidamente las afirmaciones, aportando más responsabilidad a los debates.
De cara al futuro, planeamos mejorar el API integrando fuentes de datos privadas como informes internos, bases de datos y PDFs para una verificación de hechos más personalizada. También buscamos expandir el número de fuentes verificadas por solicitud para evaluaciones más profundas. Mejorar la respuesta a preguntas multi-hop añadirá profundidad al análisis, y aumentar la consistencia es una prioridad para asegurar que las solicitudes repetidas produzcan resultados más confiables y consistentes.
