

Berlín, Alemania - 15 de enero de 2023 – Haciendo eco del icónico 'Ich bin ein Berliner' de JFK, en Jina AI nos complace tender puentes entre idiomas a nuestra manera. Hoy, nos enorgullece anunciar nuestra última innovación: jina-embeddings-v2-base-de, un modelo de embeddings alemán/inglés. Este modelo bilingüe de última generación representa un avance significativo en la representación del lenguaje, con una longitud de contexto de 8.192 tokens. Lo que lo distingue es su notable eficiencia: logra un rendimiento de primer nivel mientras tiene solo 1/7 del tamaño de modelos comparables.
Los embeddings son cruciales para las empresas alemanas que buscan expandirse al mercado estadounidense. Según el German American Business Outlook (GABO) 2022, aproximadamente un tercio de las empresas alemanas generan más del 20% de sus ventas y ganancias globales en EE. UU., y el 93% espera un aumento en las ventas estadounidenses. Esta tendencia continúa ya que el 93% planea aumentar las inversiones de su empresa en EE. UU. en los próximos tres años, con un 85% esperando crecimiento en ventas netas y un enfoque significativo en la transformación digital. Los buenos embeddings pueden jugar un papel fundamental en esta expansión al facilitar una mejor comprensión de las preferencias del cliente, permitir una comunicación más efectiva y posicionar productos culturalmente resonantes.
Nuestro avance es particularmente beneficioso para las empresas alemanas que buscan implementar aplicaciones bilingües en países de habla inglesa. Con jina-embeddings-v2-base-de, estamos emocionados de ver cómo las empresas alemanas innovarán y prosperarán en un mundo cada vez más conectado.
tagAspectos Destacados del Modelo
- Rendimiento de Última Generación: jina-embeddings-v2-base-de se ubica constantemente en la cima de los benchmarks relevantes y lidera entre los modelos de código abierto de tamaño similar.
- Modelo Bilingüe: Este modelo codifica textos tanto en alemán como en inglés, permitiendo el uso de cualquiera de los idiomas como consulta o documento objetivo en aplicaciones de recuperación. Los textos con significados equivalentes en ambos idiomas se mapean al mismo espacio de embeddings, formando la base para aplicaciones multilingües.
- Contexto Extendido: Una longitud de 8192 tokens permite a jina-embeddings-v2-base-de admitir textos más largos y fragmentos de documentos, superando por mucho a los modelos que solo admiten unos cientos de tokens a la vez.
- Tamaño Compacto: jina-embeddings-v2-base-de está construido para alto rendimiento en hardware estándar. Con solo 161 millones de parámetros, el modelo completo es de 322MB y cabe en la memoria de computadoras comunes. Los embeddings mismos son de 768 dimensiones, un tamaño de vector relativamente pequeño comparado con muchos modelos, ahorrando espacio y tiempo de ejecución para las aplicaciones.
- Minimización de Sesgos: Investigaciones recientes muestran que los modelos multilingües sin entrenamiento específico de idioma muestran fuertes sesgos hacia estructuras gramaticales inglesas en los embeddings. Los modelos de embeddings deberían capturar significado y no favorecer pares de oraciones que son meramente similares superficialmente.
- Integración Perfecta: Los modelos Jina Embeddings v2 tienen integraciones nativas con las principales bases de datos vectoriales, incluyendo MongoDB, Qdrant, y Weaviate, así como frameworks RAG y LLM como Haystack y LlamaIndex.
tagRendimiento Líder en NLP Alemán
Hemos puesto a prueba jina-embeddings-v2-base-de contra cuatro líneas base reconocidas que también soportan alemán e inglés. Estas incluyen:
- Multilingual-E5-large y Multilingual-E5-base de Microsoft
- Cross English & German RoBERTa for Sentence Embeddings de T-Systems
- Sentence-BERT (
distiluse-base-multilingual-cased-v2)
Nuestros benchmarks incluyen las tareas MTEB para inglés y nuestro propio benchmark personalizado. Dada la falta de un conjunto completo de benchmarks para embeddings en alemán, tomamos la iniciativa de desarrollar el nuestro, inspirado en el MTEB. Nos enorgullece compartir aquí nuestros hallazgos y avances.
 jina-ai
jina-ai
tagTamaño Compacto, Resultados Superiores
jina-embeddings-v2-base-de demuestra un rendimiento excepcional, especialmente en tareas en alemán. Supera al modelo E5 base siendo menos de un tercio de su tamaño. Además, compite de igual a igual con el modelo E5 large, que es siete veces más grande, demostrando su eficiencia y potencia. Esta eficiencia hace de jina-embeddings-v2-base-de un cambio revolucionario, particularmente cuando se compara con otros modelos de embeddings bilingües y multilingües populares.
tagExcelencia en Recuperación Interlingüística Alemán-Inglés
Nuestro modelo no solo se trata de tamaño y eficiencia; también es un líder en tareas de recuperación interlingüística inglés-alemán. Esto es evidente en su rendimiento en varios benchmarks clave:
- WikiCLIR, para recuperación de inglés a alemán
- STS17, parte de la evaluación MTEB para recuperación de inglés a alemán
- STS22, para recuperación de alemán a inglés, también parte de MTEB
- BUCC, para recuperación de alemán a inglés, incluido en MTEB
El rendimiento en estos benchmarks, particularmente en las pruebas de evaluación MTEB (con la excepción de WikiCLIR), subraya la efectividad de jina-embeddings-v2-base-de en el manejo de tareas bilingües complejas.
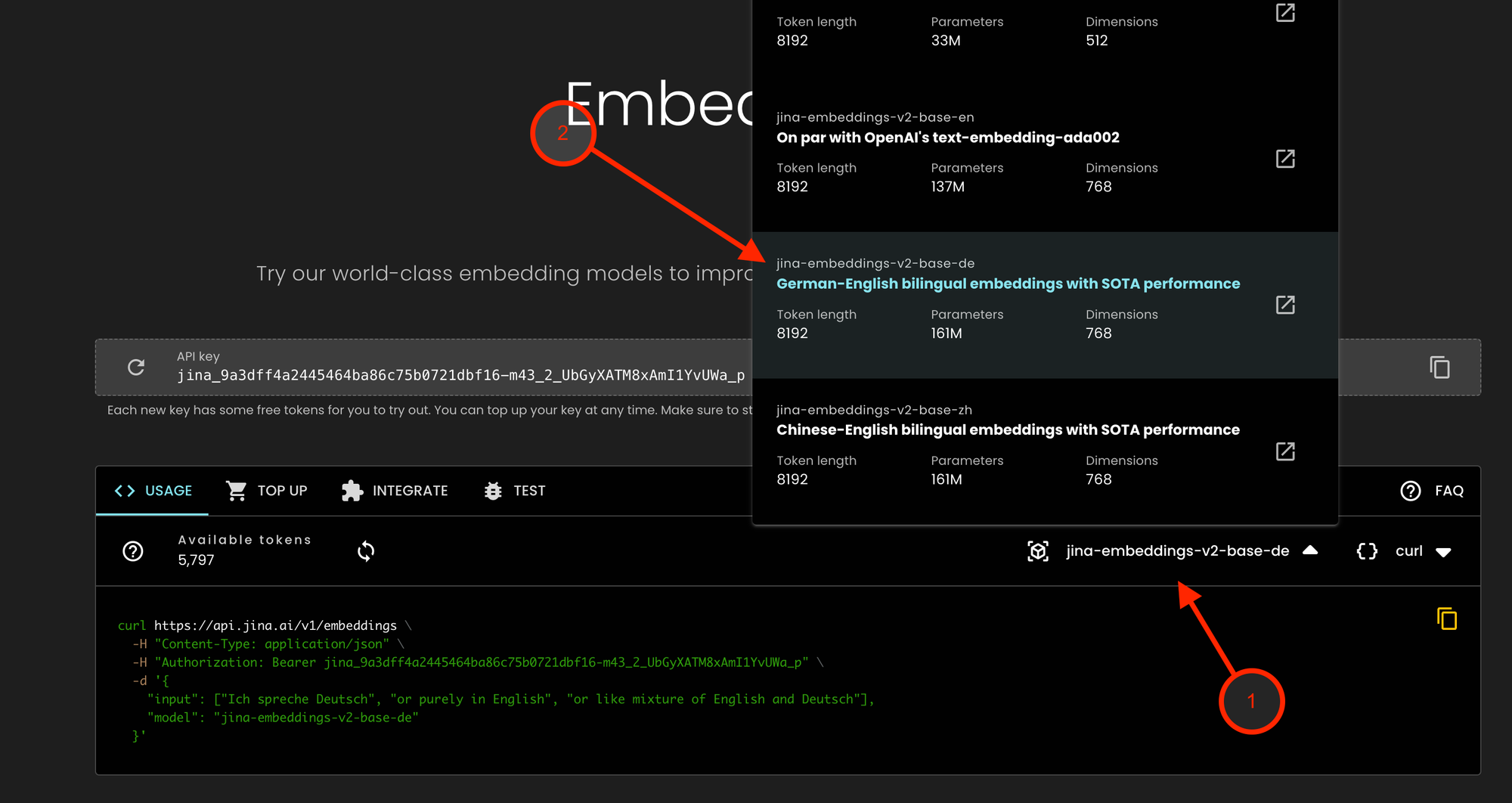
tagObtener Acceso a la API
Nuestras ofertas para usuarios empresariales que valoran la privacidad y el cumplimiento de datos, incluyendo jina-embeddings-v2-base-de, están accesibles a través de la API de Jina Embeddings:
- Visite Jina Embeddings API y haga clic en el menú desplegable de modelos
- Seleccione jina-embeddings-v2-base-de

Pronto pondremos este modelo a disposición en el marketplace de AWS Sagemaker para usuarios de Amazon cloud y para descarga en HuggingFace.
tagJina 8K Embeddings: La piedra angular de diversas aplicaciones de IA
Los embeddings son cruciales para una amplia gama de aplicaciones de IA, incluyendo recuperación de información, control de calidad de datos, clasificación y recomendación. Son fundamentales para mejorar numerosas tareas de IA.
Jina AI está comprometida con el avance del estado del arte en tecnología de embeddings, manteniendo nuestros componentes principales de IA transparentes, accesibles y asequibles para empresas de todos los tipos y tamaños que valoran la privacidad y el cumplimiento de datos. Además de jina-embeddings-v2-base-de, Jina AI ha lanzado modelos de embeddings de última generación para chino y modelos monolingües de alto rendimiento en inglés. Esto es parte de nuestra misión de hacer que la tecnología de IA sea más inclusiva y globalmente aplicable.
Valoramos sus comentarios. Únase a nuestro canal comunitario para aportar feedback y mantenerse informado sobre nuestros avances. Juntos, estamos dando forma a un futuro de IA más robusto e inclusivo.


