


Los desarrolladores e ingenieros de operaciones valoran mucho la infraestructura que pueden configurar fácilmente, iniciar rápidamente y, posteriormente, implementar de manera eficiente en un entorno de producción escalado sin complicaciones adicionales. Por esta razón, Milvus Lite, la última base de datos vectorial ligera de nuestro socio Milvus, es una herramienta importante para que los desarrolladores de Python desarrollen rápidamente aplicaciones de búsqueda, especialmente cuando se usa junto con modelos base de búsqueda de alta calidad y fáciles de usar.
En este artículo, describiremos cómo Milvus Lite integra Jina Embeddings v2 y Jina Reranker v1 usando el ejemplo de una aplicación de Retrieval Augmented Generation (RAG) construida sobre los chats de canales públicos internos de una empresa ficticia para permitir que los empleados obtengan respuestas a sus preguntas relacionadas con la organización de manera precisa y útil.
tagDescripción general de Milvus Lite, Jina Embeddings y Jina Reranker
Milvus Lite es una nueva versión ligera de la base de datos vectorial líder Milvus, que ahora también se ofrece como una biblioteca de Python. Milvus Lite comparte la misma API que Milvus implementada en Docker o Kubernetes pero puede instalarse fácilmente mediante un comando pip de una línea, sin necesidad de configurar un servidor.
Con la integración de Jina Embeddings v2 y Jina Reranker v1 en pymilvus, el SDK de Python de Milvus, ahora tienes la opción de incrustar documentos directamente usando el mismo cliente de Python para cualquier modo de implementación de Milvus, incluido Milvus Lite. Puedes encontrar detalles de la integración de Jina Embeddings y Reranker en las páginas de documentación de pymilvus.
Con su ventana de contexto de 8k tokens y capacidades multilingües, Jina Embeddings v2 codifica la semántica amplia del texto y asegura una recuperación precisa. Al agregar Jina Reranker v1 al pipeline, puedes refinar aún más tus resultados mediante la codificación cruzada de los resultados recuperados directamente con la consulta para una comprensión contextual más profunda.
tagMilvus y modelos de Jina AI en acción
Este tutorial se centrará en un caso de uso práctico: Consultar el historial de chat de Slack de una empresa para responder una amplia gama de preguntas basadas en conversaciones anteriores.
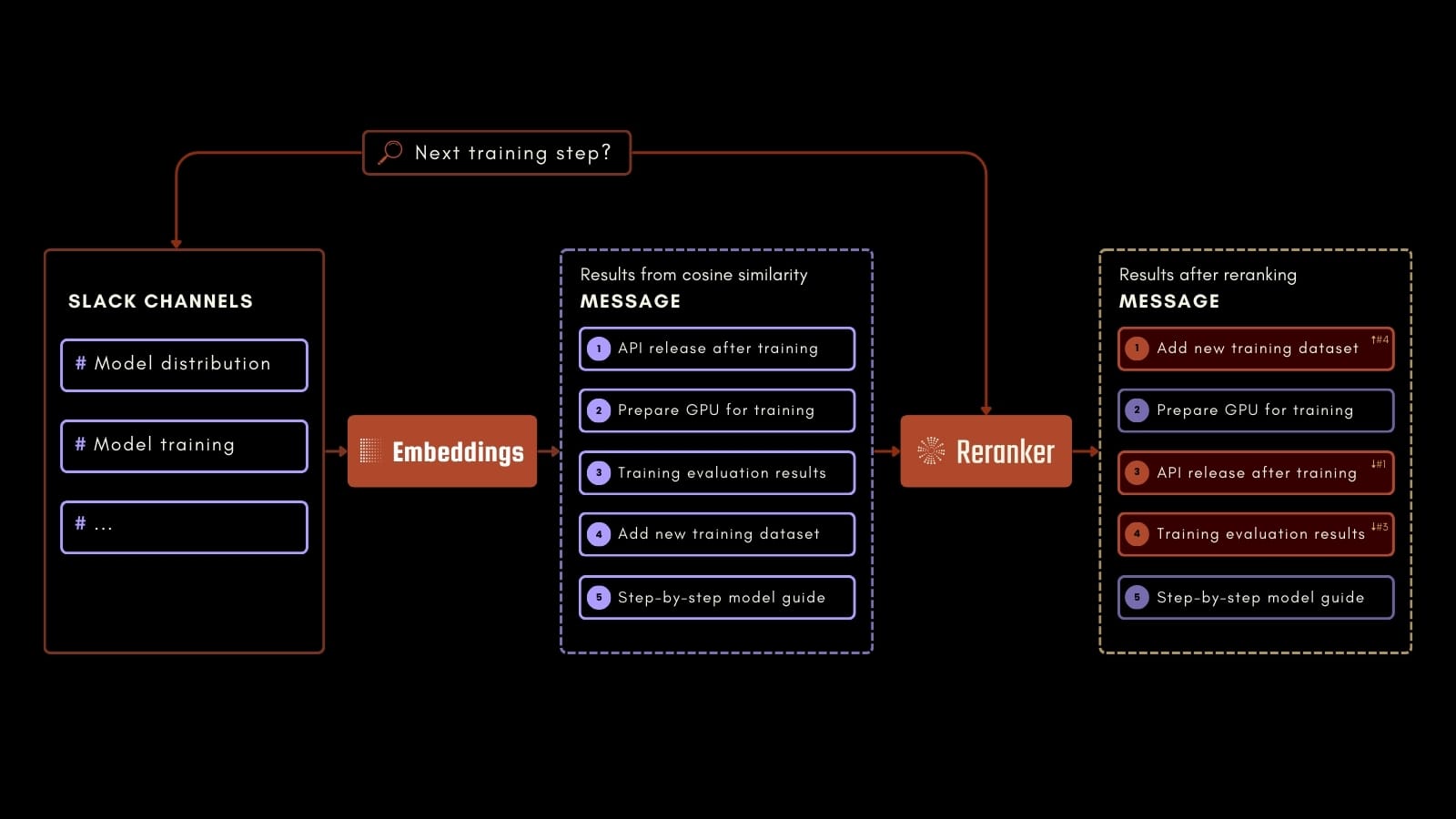
Por ejemplo, un empleado podría preguntar sobre el siguiente paso en algún proceso de entrenamiento de IA, como en el esquema del proceso anterior. Usando Jina Embeddings, Jina Reranker y Milvus, podemos identificar con precisión la información relevante en los mensajes de Slack registrados. Esta aplicación puede mejorar la productividad en el lugar de trabajo facilitando el acceso a información valiosa de comunicaciones anteriores.
Para generar las respuestas, usaremos Mixtral 7B Instruct a través de la integración de HuggingFace en Langchain. Para usar el modelo, necesitas un token de acceso de HuggingFace que puedes generar como se describe aquí.
Puedes seguir el tutorial en Colab o descargando el notebook.


tagSobre el conjunto de datos
El conjunto de datos utilizado en este tutorial fue generado usando GPT-4 y está destinado a replicar los historiales de chat de los canales de Slack de Blueprint AI. Blueprint es una startup de IA ficticia que desarrolla sus propios modelos fundamentales. Puedes descargar el conjunto de datos aquí.
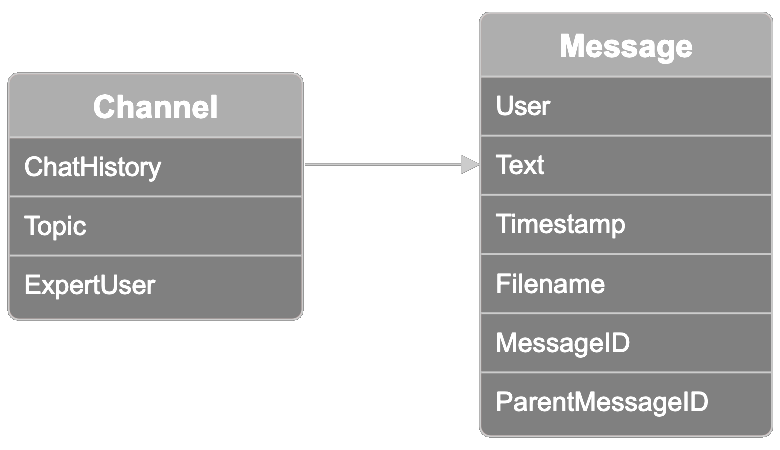
Los datos están organizados en canales, cada uno representativo de una colección de hilos de Slack relacionados. Cada canal tiene una etiqueta de tema, una de diez opciones de tema: distribución de modelos, entrenamiento de modelos, ajuste fino de modelos, ética y mitigación de sesgos, retroalimentación de usuarios, ventas, marketing, incorporación de modelos, diseño creativo y gestión de productos. Un participante es conocido como el "usuario experto". Puedes usar este campo para validar los resultados de la búsqueda del usuario más experto en un tema, lo cual te mostraremos cómo hacer más adelante.
Cada canal también contiene un historial de chat con hilos de conversación de hasta 100 mensajes por canal. Cada mensaje en el conjunto de datos contiene la siguiente información:
- El usuario que envió el mensaje
- El texto del mensaje enviado por el usuario
- La marca de tiempo del mensaje
- El nombre del archivo que el usuario pudo haber adjuntado al mensaje
- El ID del mensaje
- El ID del mensaje padre si el mensaje estaba dentro de un hilo originado de otro mensaje
tagConfigurar el entorno
Para comenzar, instala todos los componentes necesarios:
pip install -U pymilvus
pip install -U "pymilvus[model]"
pip install langchain
pip install langchain-community
Descarga el conjunto de datos:
import os
if not os.path.exists("chat_history.json"):
!wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/embeddings/milvus/chat_history.jsonEstablece tu clave API de Jina AI en una variable de entorno. Puedes generar una aquí.
import os
import getpass
os.environ["JINAAI_API_KEY"] = getpass.getpass(prompt="Jina AI API Key: ")Haz lo mismo con tu Token de Hugging Face. Puedes encontrar cómo generar uno aquí. Asegúrate de que esté configurado como READ para acceder al Hugging Face Hub.
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass.getpass(prompt="Hugging Face Token: ")tagCrear la Colección de Milvus
Crea la Colección de Milvus para indexar los datos:
from pymilvus import MilvusClient, DataType
# Especifique un nombre de archivo local como parámetro uri de MilvusClient para usar Milvus Lite
client = MilvusClient("milvus_jina.db")
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, description="The Primary Key", is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, description="The Embedding Vector", dim=768)
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
client.create_collection(collection_name="milvus_jina", schema=schema, index_params=index_params)tagPreparar los Datos
Analizar el historial de chat y extraer los metadatos:
import json
with open("chat_history.json", "r", encoding="utf-8") as file:
chat_data = json.load(file)
messages = []
metadatas = []
for channel in chat_data:
chat_history = channel["chat_history"]
chat_topic = channel["topic"]
chat_expert = channel["expert_user"]
for message in chat_history:
text = f"""{message["user"]}: {message["message"]}"""
messages.append(text)
meta = {
"time_stamp": message["time_stamp"],
"file_name": message["file_name"],
"parent_message_nr": message["parent_message_nr"],
"channel": chat_topic,
"expert": True if message["user"] == chat_expert else False
}
metadatas.append(meta)
tagEmbeber los Datos del Chat
Crear embeddings para cada mensaje usando Jina Embeddings v2 para recuperar información relevante del chat:
from pymilvus.model.dense import JinaEmbeddingFunction
jina_ef = JinaEmbeddingFunction("jina-embeddings-v2-base-en")
embeddings = jina_ef.encode_documents(messages)tagIndexar los Datos del Chat
Indexar los mensajes, sus embeddings y los metadatos relacionados:
collection_data = [{
"message": message,
"embedding": embedding,
"metadata": metadata
} for message, embedding, metadata in zip(messages, embeddings, metadatas)]
data = client.insert(
collection_name="milvus_jina",
data=collection_data
)tagConsultar el Historial del Chat
Es momento de hacer una pregunta:
query = "Who knows the most about encryption protocols in my team?"Ahora embebemos la consulta y recuperamos los mensajes relevantes. Aquí recuperamos los cinco mensajes más relevantes y los reordenamos usando Jina Reranker v1:
from pymilvus.model.reranker import JinaRerankFunction
query_vectors = jina_ef.encode_queries([query])
results = client.search(
collection_name="milvus_jina",
data=query_vectors,
limit=5,
)
results = results[0]
ids = [results[i]["id"] for i in range(len(results))]
results = client.get(
collection_name="milvus_jina",
ids=ids,
output_fields=["id", "message", "metadata"]
)
jina_rf = JinaRerankFunction("jina-reranker-v1-base-en")
documents = [results[i]["message"] for i in range(len(results))]
reranked_documents = jina_rf(query, documents)
reranked_messages = []
for reranked_document in reranked_documents:
idx = reranked_document.index
reranked_messages.append(results[idx])Por último, generamos una respuesta a la consulta usando Mixtral 7B Instruct y los mensajes reordenados como contexto:
from langchain.prompts import PromptTemplate
from langchain_community.llms import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(repo_id="mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = """<s>[INST] Context information is below.\\n
It includes the five most relevant messages to the query, sorted based on their relevance to the query.\\n
---------------------\\n
{context_str}\\\\n
---------------------\\n
Given the context information and not prior knowledge,
answer the query. Please be brief, concise, and complete.\\n
If the context information does not contain an answer to the query,
respond with \\"No information\\".\\n
Query: {query_str}[/INST] </s>"""
prompt = PromptTemplate(template=prompt, input_variables=["query_str", "context_str"])
llm_chain = prompt | llm
answer = llm_chain.invoke({"query_str":query, "context_str":reranked_messages})
print(f"\n\nANSWER:\n\n{answer}")La respuesta a nuestra pregunta es:
"Basado en la información del contexto, User5 parece ser el más conocedor sobre protocolos de encriptación en tu equipo. Han mencionado que los nuevos protocolos mejoran significativamente la seguridad de los datos, especialmente para implementaciones en la nube."
Si lees los mensajes en chat_history.json, puedes verificar por ti mismo si User5 es el usuario más experto.
tagResumen
Hemos visto cómo configurar Milvus Lite, embeber datos de chat usando Jina Embeddings v2, y refinar los resultados de búsqueda con Jina Reranker v1, todo dentro de un caso de uso práctico de búsqueda en un historial de chat de Slack. Milvus Lite simplifica el desarrollo de aplicaciones basadas en Python sin necesidad de configuraciones complejas de servidor. Su integración con Jina Embeddings y Reranker busca aumentar la productividad al facilitar el acceso a información valiosa de tu lugar de trabajo.
tagUsa los Modelos de Jina AI y Milvus Ahora
Milvus Lite con Jina Embeddings y Reranker integrados te proporciona un pipeline de procesamiento completo, listo para usar con solo unas pocas líneas de código.
Nos encantaría conocer tus casos de uso y hablar sobre cómo la extensión Jina AI Milvus puede adaptarse a las necesidades de tu negocio. Contáctanos a través de nuestro sitio web o nuestro canal de Discord para compartir tus comentarios y mantenerte al día con nuestros últimos modelos. Para preguntas sobre la integración de Milvus y Jina AI, únete a la comunidad Milvus.






