



Jina CLIP v1 (jina-clip-v1) es un nuevo modelo de embedding multimodal que extiende las capacidades del modelo CLIP original de OpenAI. Con este nuevo modelo, los usuarios tienen un único modelo de embedding que ofrece un rendimiento de última generación tanto en la recuperación de solo texto como en la recuperación multimodal texto-imagen. Jina AI ha mejorado el rendimiento de OpenAI CLIP en un 165% en la recuperación de solo texto y en un 12% en la recuperación de imagen a imagen, con un rendimiento idéntico o levemente mejor en las tareas de texto a imagen e imagen a texto. Este rendimiento mejorado hace que Jina CLIP v1 sea indispensable para trabajar con entradas multimodales.
En este artículo, primero discutiremos las limitaciones del modelo CLIP original y cómo las hemos abordado usando un método único de co-entrenamiento. Luego, demostraremos la efectividad de nuestro modelo en varios benchmarks de recuperación. Finalmente, proporcionaremos instrucciones detalladas sobre cómo los usuarios pueden comenzar con Jina CLIP v1 a través de nuestra API de Embeddings y Hugging Face.
tagLa Arquitectura CLIP para IA Multimodal
En enero de 2021, OpenAI lanzó el modelo CLIP (Contrastive Language–Image Pretraining). CLIP tiene una arquitectura sencilla pero ingeniosa: combina dos modelos de embedding, uno para textos y otro para imágenes, en un único modelo con un único espacio de embedding de salida. Sus embeddings de texto e imagen son directamente comparables entre sí, haciendo que la distancia entre un embedding de texto y uno de imagen sea proporcional a qué tan bien ese texto describe la imagen, y viceversa.
Esto ha demostrado ser muy útil en la recuperación de información multimodal y en la clasificación de imágenes zero-shot. Sin entrenamiento especial adicional, CLIP tuvo un buen desempeño al colocar imágenes en categorías con etiquetas en lenguaje natural.

El modelo de embedding de texto en el CLIP original era una red neuronal personalizada con solo 63 millones de parámetros. En el lado de la imagen, OpenAI lanzó CLIP con una selección de modelos ResNet y ViT. Cada modelo fue pre-entrenado para su modalidad individual y luego entrenado con imágenes con subtítulos para producir embeddings similares para pares preparados de imagen-texto.
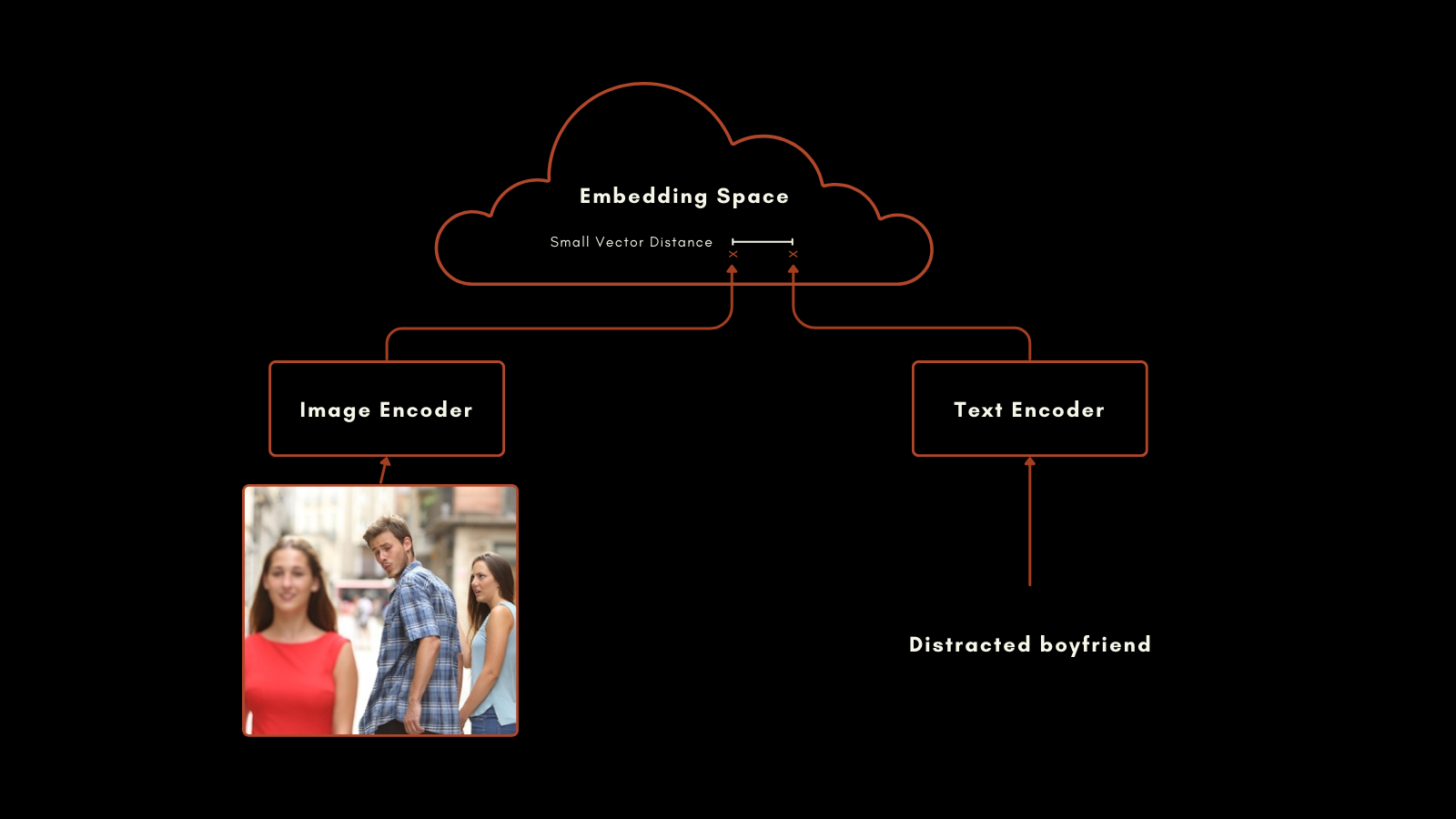
Este enfoque produjo resultados impresionantes. Particularmente notable es su rendimiento en clasificación zero-shot. Por ejemplo, aunque los datos de entrenamiento no incluían imágenes etiquetadas de astronautas, CLIP podía identificar correctamente imágenes de astronautas basándose en su comprensión de conceptos relacionados en textos e imágenes.
Sin embargo, CLIP de OpenAI tiene dos importantes desventajas:
- La primera es su capacidad muy limitada de entrada de texto. Puede tomar un máximo de 77 tokens de entrada, pero el análisis empírico muestra que en la práctica no usa más de 20 tokens para producir sus embeddings. Esto es porque CLIP fue entrenado con imágenes con subtítulos, y los subtítulos tienden a ser muy cortos. Esto contrasta con los modelos actuales de embedding de texto que soportan varios miles de tokens.
- Segundo, el rendimiento de sus embeddings de texto en escenarios de recuperación de solo texto es muy pobre. Los subtítulos de imágenes son un tipo muy limitado de texto y no reflejan la amplia gama de casos de uso que se esperaría que un modelo de embedding de texto soporte.
En la mayoría de los casos de uso reales, la recuperación de solo texto y texto-imagen se combinan o al menos ambos están disponibles para las tareas. Mantener un segundo modelo de embeddings para tareas de solo texto efectivamente duplica el tamaño y la complejidad de tu marco de IA.
El nuevo modelo de Jina AI aborda estos problemas directamente, y jina-clip-v1 aprovecha el progreso realizado en los últimos años para proporcionar un rendimiento de última generación en tareas que involucran todas las combinaciones de modalidades de texto e imagen.
tagPresentando Jina CLIP v1
Jina CLIP v1 mantiene el esquema original de OpenAI CLIP: dos modelos co-entrenados para producir salidas en el mismo espacio de embedding.
Para la codificación de texto, adaptamos la arquitectura Jina BERT v2 utilizada en los modelos Jina Embeddings v2. Esta arquitectura soporta una ventana de entrada de 8k tokens de última generación y produce vectores de 768 dimensiones, generando embeddings más precisos a partir de textos más largos. Esto es más de 100 veces los 77 tokens de entrada soportados en el modelo CLIP original.
Para los embeddings de imágenes, estamos usando el último modelo de la Academia de Inteligencia Artificial de Beijing: el modelo EVA-02. Hemos comparado empíricamente varios modelos de IA de imágenes, probándolos en contextos multimodales con pre-entrenamiento similar, y EVA-02 superó claramente a los demás. También es comparable a la arquitectura Jina BERT en tamaño de modelo, por lo que las cargas de cómputo para tareas de procesamiento de imagen y texto son aproximadamente idénticas.
Estas elecciones producen beneficios importantes para los usuarios:
- Mejor rendimiento en todos los benchmarks y todas las combinaciones modales, y especialmente grandes mejoras en el rendimiento de embedding de solo texto.
- El rendimiento empíricamente superior de
EVA-02tanto en tareas de imagen-texto como de solo imagen, con el beneficio adicional del entrenamiento adicional de Jina AI, mejorando el rendimiento de solo imagen. - Soporte para entradas de texto mucho más largas. El soporte de entrada de 8k tokens de Jina Embeddings hace posible procesar información textual detallada y correlacionarla con imágenes.
- Un gran ahorro neto en espacio, cómputo, mantenimiento de código y complejidad porque este modelo multimodal es altamente eficiente incluso en escenarios no multimodales.
tagEntrenamiento
Parte de nuestra receta para una IA multimodal de alto rendimiento son nuestros datos y procedimiento de entrenamiento. Notamos que la longitud muy corta de los textos utilizados en los subtítulos de imágenes es la causa principal del pobre rendimiento de solo texto en los modelos tipo CLIP, y nuestro entrenamiento está explícitamente diseñado para remediar esto.
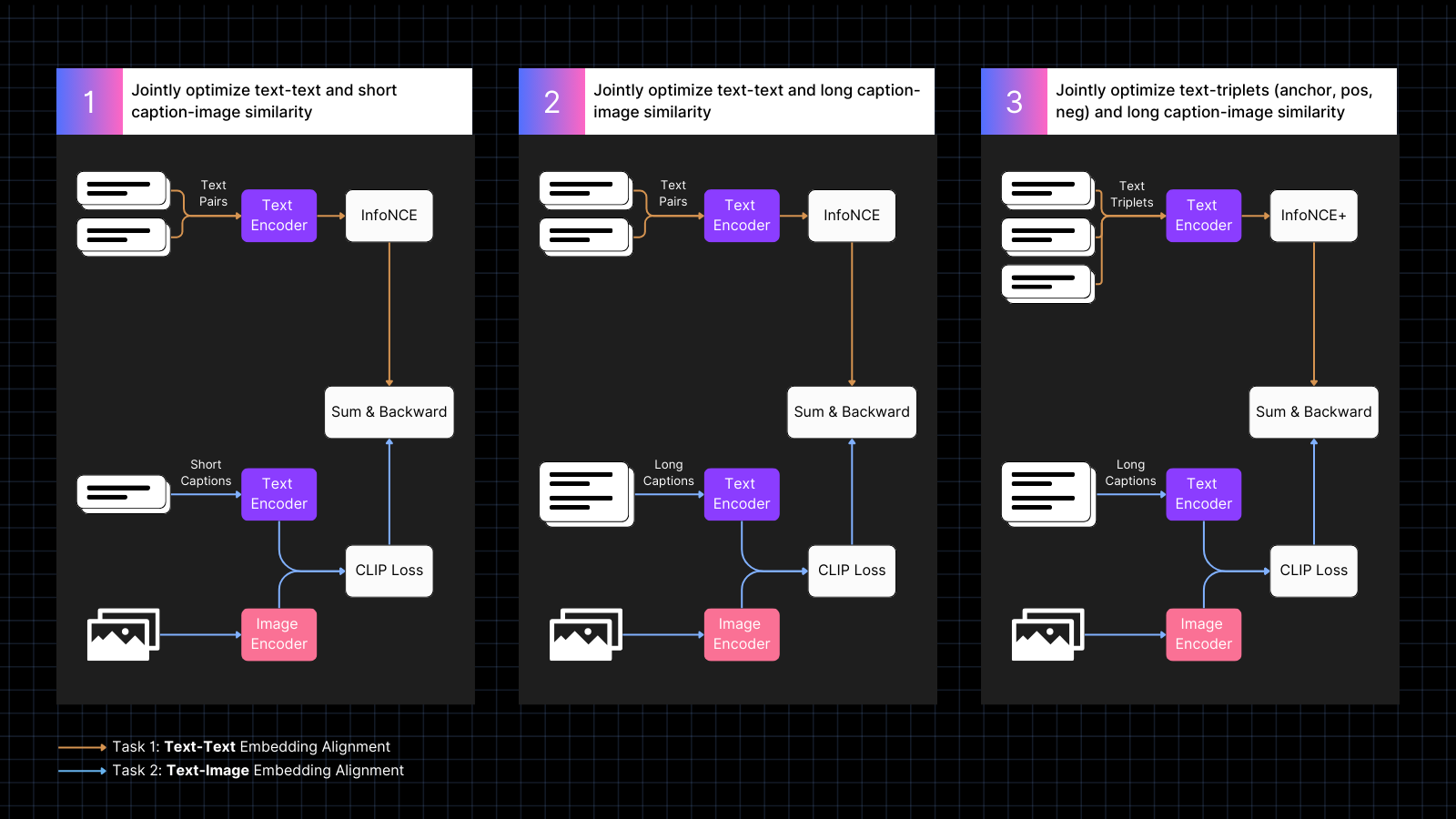
El entrenamiento se realiza en tres pasos:
- Usar datos de imágenes con subtítulos para aprender a alinear embeddings de imagen y texto, intercalados con pares de texto con significados similares. Este co-entrenamiento optimiza conjuntamente para los dos tipos de tareas. El rendimiento de solo texto del modelo disminuye durante esta fase, pero no tanto como si hubiéramos entrenado solo con pares de imagen-texto.
- Entrenar usando datos sintéticos que alinean imágenes con textos más largos, generados por un modelo de IA, que describe la imagen. Continuar entrenando con pares de solo texto al mismo tiempo. Durante esta fase, el modelo aprende a atender textos más largos en conjunto con imágenes.
- Usar tripletes de texto con negativos difíciles para mejorar aún más el rendimiento de solo texto aprendiendo a hacer distinciones semánticas más finas. Al mismo tiempo, continuar entrenando usando pares sintéticos de imágenes y textos largos. Durante esta fase, el rendimiento de solo texto mejora dramáticamente sin que el modelo pierda ninguna capacidad de imagen-texto.
Para más información sobre los detalles del entrenamiento y la arquitectura del modelo, por favor lee nuestro artículo reciente:
tagNuevo Estado del Arte en Embeddings Multimodales
Evaluamos el rendimiento de Jina CLIP v1 en tareas de solo texto, solo imagen y tareas multimodales que involucran ambas modalidades de entrada. Utilizamos el benchmark de recuperación MTEB para evaluar el rendimiento de solo texto. Para tareas de solo imagen, usamos el benchmark CIFAR-100. Para tareas multimodales, evaluamos en Flickr8k, Flickr30K, y MSCOCO Captions, que están incluidos en el Benchmark CLIP.
Los resultados se resumen en la siguiente tabla:
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| % increase vs OpenAI CLIP |
165% | 2% | 6% | 12% |
Como puede verse en estos resultados, jina-clip-v1 supera al CLIP original de OpenAI en todas las categorías, y es dramáticamente mejor en recuperación de solo texto y solo imagen. Promediando todas las categorías, esto representa una mejora del 46% en rendimiento.
Puede encontrar una evaluación más detallada en nuestro artículo reciente.
tagComenzando con la API de Embeddings
Puede integrar fácilmente Jina CLIP v1 en sus aplicaciones usando la API de Embeddings de Jina.
El código a continuación muestra cómo llamar a la API para obtener embeddings de textos e imágenes, usando el paquete requests en Python. Pasa una cadena de texto y una URL a una imagen al servidor de Jina AI y devuelve ambas codificaciones.
<YOUR_JINA_AI_API_KEY> con una clave API de Jina activada. Puede obtener una clave de prueba con un millón de tokens gratuitos desde la página web de Jina Embeddings.import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")
tagIntegración con Principales Frameworks de LLM
Jina CLIP v1 ya está disponible para LlamaIndex y LangChain:
- LlamaIndex: Use
JinaEmbeddingcon la clase baseMultimodalEmbedding, y llame aget_image_embeddingsoget_text_embeddings. - LangChain: Use
JinaEmbeddings, y llame aembed_imagesoembed_documents.
tagPrecios
Tanto las entradas de texto como de imagen se cobran por consumo de tokens.
Para texto en inglés, hemos calculado empíricamente que en promedio necesitará 1.1 tokens por cada palabra.
Para imágenes, contamos el número de mosaicos de 224x224 píxeles necesarios para cubrir su imagen. Algunos de estos mosaicos pueden estar parcialmente en blanco pero cuentan igual. Cada mosaico cuesta 1,000 tokens para procesar.
Ejemplo
Para una imagen con dimensiones de 750x500 píxeles:
- La imagen se divide en mosaicos de 224x224 píxeles.
- Para calcular el número de mosaicos, tome el ancho en píxeles y divida por 224, luego redondee al entero más cercano.
750/224 ≈ 3.35 → 4 - Repita para la altura en píxeles:
500/224 ≈ 2.23 → 3
- Para calcular el número de mosaicos, tome el ancho en píxeles y divida por 224, luego redondee al entero más cercano.
- El número total de mosaicos requeridos en este ejemplo es:
4 (horizontal) x 3 (vertical) = 12 mosaicos - El costo será 12 x 1,000 = 12,000 tokens
tagSoporte Empresarial
Estamos introduciendo un nuevo beneficio para usuarios que compren el plan de Despliegue en Producción con 11 mil millones de tokens. Esto incluye:
- Tres horas de consultoría con nuestros equipos de producto e ingeniería para discutir sus casos de uso específicos y requisitos.
- Un notebook Python personalizado diseñado para su caso de uso de RAG (Generación Aumentada por Recuperación) o búsqueda vectorial, demostrando cómo integrar los modelos de Jina AI en su aplicación.
- Asignación a un ejecutivo de cuenta y soporte prioritario por email para asegurar que sus necesidades sean atendidas de manera rápida y eficiente.
tagJina CLIP v1 de Código Abierto en Hugging Face
Jina AI está comprometida con una base de búsqueda de código abierto, y por ese propósito, estamos haciendo este modelo disponible gratuitamente bajo una licencia Apache 2.0, en Hugging Face.
Puede encontrar código de ejemplo para descargar y ejecutar este modelo en su propio sistema o instalación en la nube en la página del modelo en Hugging Face para jina-clip-v1.

tagResumen
El último modelo de Jina AI — jina-clip-v1 — representa un avance significativo en modelos de embedding multimodales, ofreciendo mejoras sustanciales de rendimiento sobre CLIP de OpenAI. Con mejoras notables en tareas de recuperación de solo texto y solo imagen, así como un rendimiento competitivo en tareas de texto a imagen e imagen a texto, se presenta como una solución prometedora para casos de uso complejos de embeddings.
Actualmente, este modelo solo admite textos en inglés debido a limitaciones de recursos. Estamos trabajando para expandir sus capacidades a más idiomas.
