



Hoy, nos complace anunciar jina-embeddings-v3, un modelo de embeddings de texto de vanguardia con 570 millones de parámetros. Logra un rendimiento estado del arte en datos multilingües y tareas de recuperación de contexto largo, soportando una longitud de entrada de hasta 8192 tokens. El modelo cuenta con adaptadores Low-Rank Adaptation (LoRA) específicos por tarea, permitiéndole generar embeddings de alta calidad para varias tareas incluyendo recuperación de consultas y documentos, agrupación, clasificación y correspondencia de texto.
En evaluaciones en MTEB English, Multilingual y LongEmbed, jina-embeddings-v3 supera a los últimos embeddings propietarios de OpenAI y Cohere en tareas en inglés, mientras también supera a multilingual-e5-large-instruct en todas las tareas multilingües. Con una dimensión de salida predeterminada de 1024, los usuarios pueden truncar arbitrariamente las dimensiones de los embeddings hasta 32 sin sacrificar rendimiento, gracias a la integración del Aprendizaje de Representación Matryoshka (MRL).


jina-embeddings-v2-(zh/es/de) se refiere a nuestra suite de modelos bilingües, que solo fue probada en tareas monolingües y translingües en chino, español y alemán, excluyendo todos los demás idiomas. Además, no reportamos puntuaciones para openai-text-embedding-3-large y cohere-embed-multilingual-v3.0, ya que estos modelos no fueron evaluados en el rango completo de tareas MTEB multilingües y translingües.
baai-bge-m3 como al enfoque basado en ALiBi utilizado en jina-embeddings-v2.Desde su lanzamiento el 18 de septiembre de 2024, jina-embeddings-v3 es el mejor modelo multilingüe y ocupa el 2do lugar en la tabla de clasificación MTEB en inglés para modelos con menos de 1.000 millones de parámetros. v3 soporta 89 idiomas en total, incluyendo 30 idiomas con el mejor rendimiento: árabe, bengalí, chino, danés, holandés, inglés, finlandés, francés, georgiano, alemán, griego, hindi, indonesio, italiano, japonés, coreano, letón, noruego, polaco, portugués, rumano, ruso, eslovaco, español, sueco, tailandés, turco, ucraniano, urdu y vietnamita.
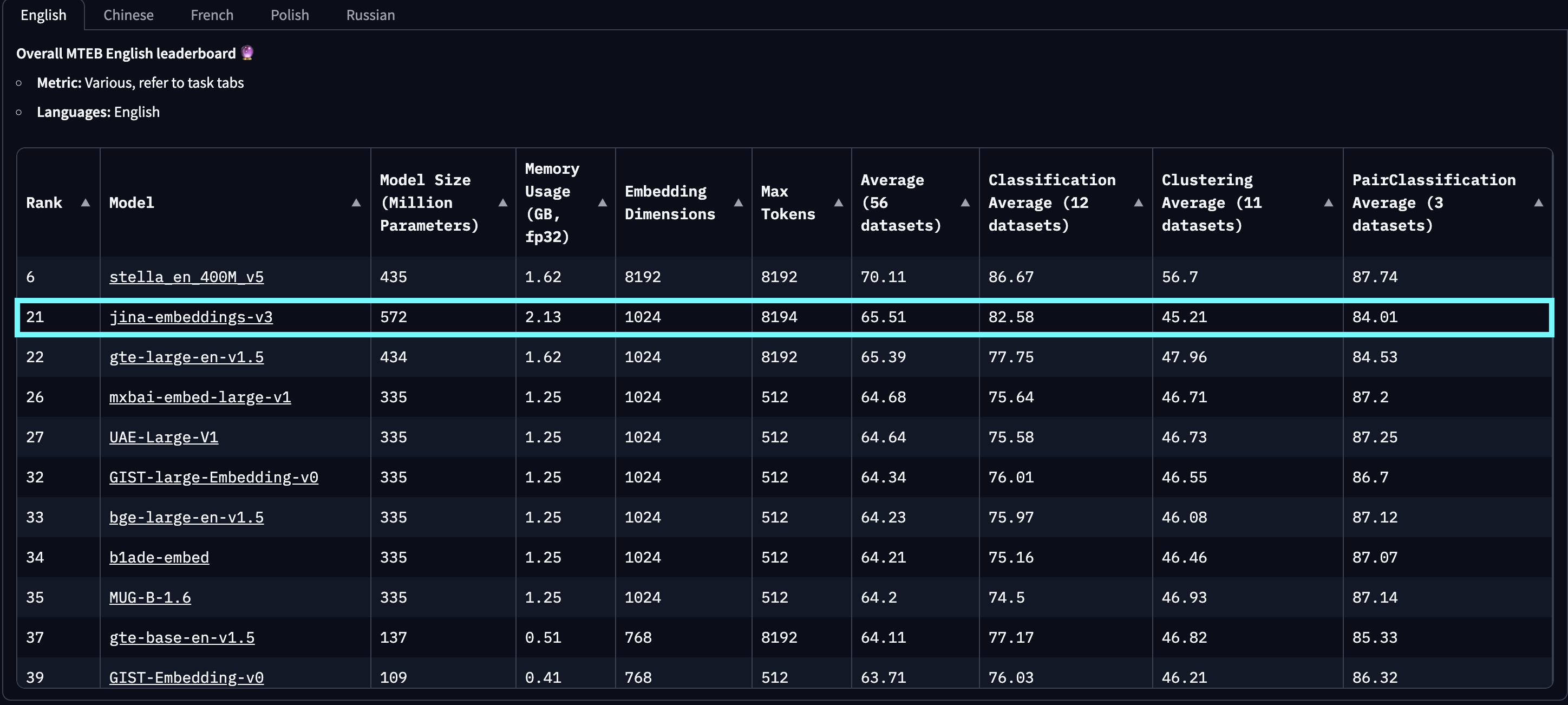

jina-embeddings-v2. Este gráfico fue creado seleccionando los 100 mejores modelos de embeddings de la tabla de clasificación MTEB, excluyendo aquellos sin información de tamaño, típicamente modelos cerrados o propietarios. También se filtraron las presentaciones identificadas como trolleo obvio.Además, comparado con los embeddings basados en LLM que recientemente han ganado atención, como e5-mistral-7b-instruct, que tiene un tamaño de parámetros de 7.1 mil millones (12 veces más grande) y una dimensión de salida de 4096 (4 veces más grande) pero ofrece solo una mejora del 1% en tareas MTEB en inglés, jina-embeddings-v3 es una solución mucho más eficiente en costos, haciéndola más adecuada para producción y computación en el borde.
tagArquitectura del Modelo
| Característica | Descripción |
|---|---|
| Base | jina-XLM-RoBERTa |
| Parámetros Base | 559M |
| Parámetros con LoRA | 572M |
| Máximo de tokens de entrada | 8192 |
| Dimensiones máximas de salida | 1024 |
| Capas | 24 |
| Vocabulario | 250K |
| Idiomas soportados | 89 |
| Atención | FlashAttention2, también funciona sin él |
| Agrupación | Mean pooling |
La arquitectura de jina-embeddings-v3 se muestra en la figura siguiente. Para implementar la arquitectura base, adaptamos el modelo XLM-RoBERTa con varias modificaciones clave: (1) permitiendo la codificación efectiva de secuencias largas de texto, (2) permitiendo la codificación de embeddings específica para cada tarea, y (3) mejorando la eficiencia general del modelo con las técnicas más recientes. Seguimos usando el tokenizador original de XLM-RoBERTa. Si bien jina-embeddings-v3, con sus 570 millones de parámetros, es más grande que jina-embeddings-v2 que tiene 137 millones, sigue siendo mucho más pequeño que los modelos de embedding ajustados a partir de LLMs.

jina-XLM-RoBERTa, con cinco adaptadores LoRA para cuatro tareas diferentes.La innovación clave en jina-embeddings-v3 es el uso de adaptadores LoRA. Se introducen cinco adaptadores LoRA específicos para optimizar embeddings para cuatro tareas. La entrada del modelo consta de dos partes: el texto (el documento largo a embeber) y la tarea. jina-embeddings-v3 soporta cuatro tareas e implementa cinco adaptadores para elegir: retrieval.query y retrieval.passage para embeddings de consultas y pasajes en tareas de recuperación asimétrica, separation para tareas de agrupamiento, classification para tareas de clasificación, y text-matching para tareas que involucran similitud semántica, como STS o recuperación simétrica. Los adaptadores LoRA representan menos del 3% del total de parámetros, añadiendo una sobrecarga mínima al cómputo.
Para mejorar aún más el rendimiento y reducir el consumo de memoria, integramos FlashAttention 2, soportamos puntos de control de activación y usamos el framework DeepSpeed para entrenamiento distribuido eficiente.
tagPrimeros Pasos
tagA través de la API Search Foundation de Jina AI
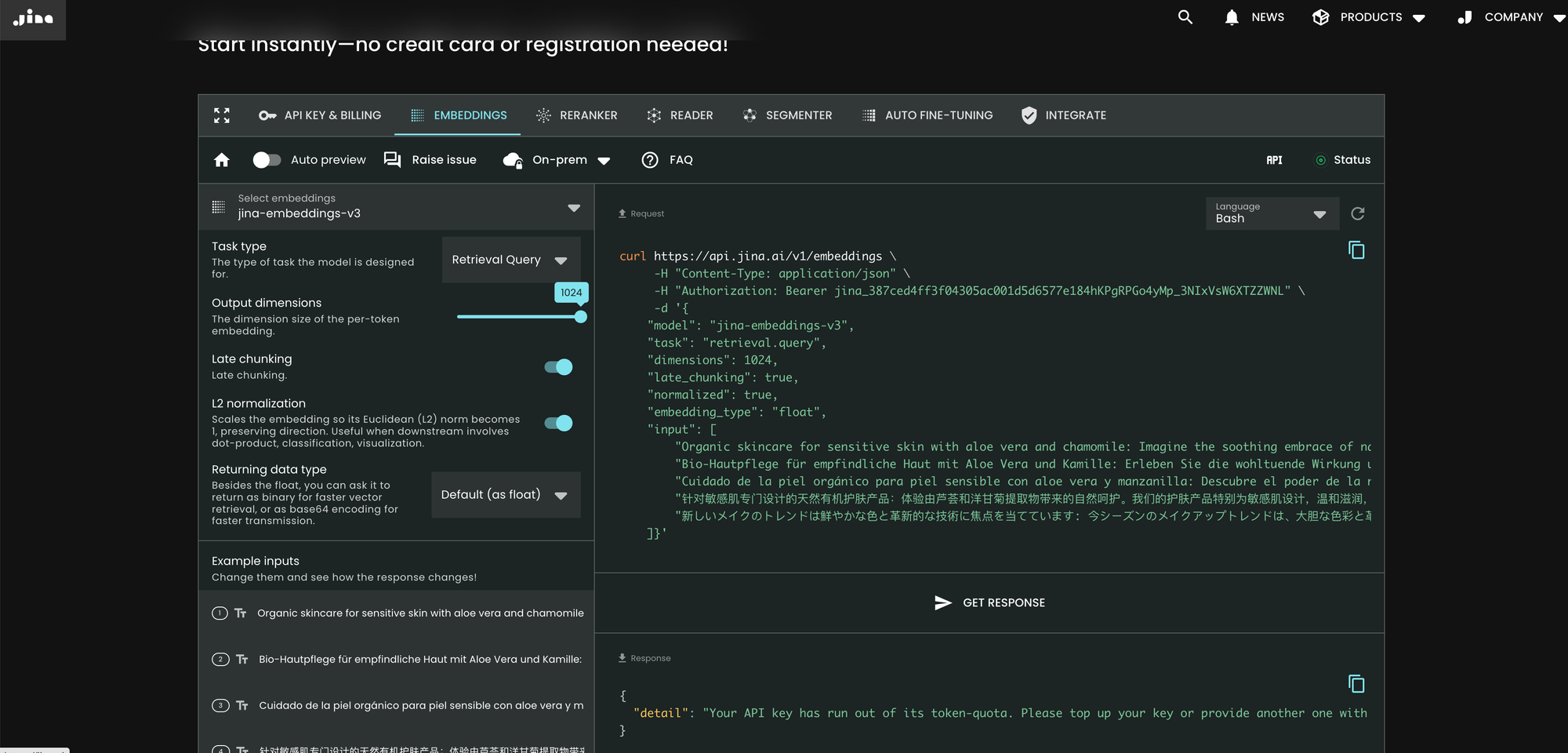
La forma más fácil de usar jina-embeddings-v3 es visitar la página principal de Jina AI y navegar a la sección de Search Foundation API. A partir de hoy, este modelo está establecido como predeterminado para todos los nuevos usuarios. Puedes explorar diferentes parámetros y características directamente desde allí.
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'
En comparación con v2, v3 introduce tres nuevos parámetros en la API: task, dimensions, y late_chunking.
Parámetro task
El parámetro task es crucial y debe establecerse según la tarea posterior. Los embeddings resultantes serán optimizados para esa tarea específica. Para más detalles, consulta la lista siguiente.
Valor de task |
Descripción de la Tarea |
|---|---|
retrieval.passage |
Embedding de documentos en una tarea de recuperación consulta-documento |
retrieval.query |
Embedding de consultas en una tarea de recuperación consulta-documento |
separation |
Agrupamiento de documentos, visualización de corpus |
classification |
Clasificación de texto |
text-matching |
(Predeterminado) Similitud semántica de texto, recuperación simétrica general, recomendación, búsqueda de elementos similares, deduplicación |
Ten en cuenta que la API no genera primero un meta-embedding genérico y luego lo adapta con un MLP adicional ajustado. En su lugar, inserta el adaptador LoRA específico para la tarea en cada capa del transformador (un total de 24 capas) y realiza la codificación de una sola vez. Más detalles se pueden encontrar en nuestro artículo en arXiv.
Parámetro dimensions
El parámetro dimensions permite a los usuarios elegir un equilibrio entre eficiencia espacial y rendimiento al menor costo. Gracias a la técnica MRL utilizada en jina-embeddings-v3, puedes reducir las dimensiones de los embeddings tanto como desees (¡incluso a una sola dimensión!). Los embeddings más pequeños son más eficientes en términos de almacenamiento para bases de datos vectoriales, y su costo de rendimiento puede estimarse a partir de la figura siguiente.

Parámetro late_chunking
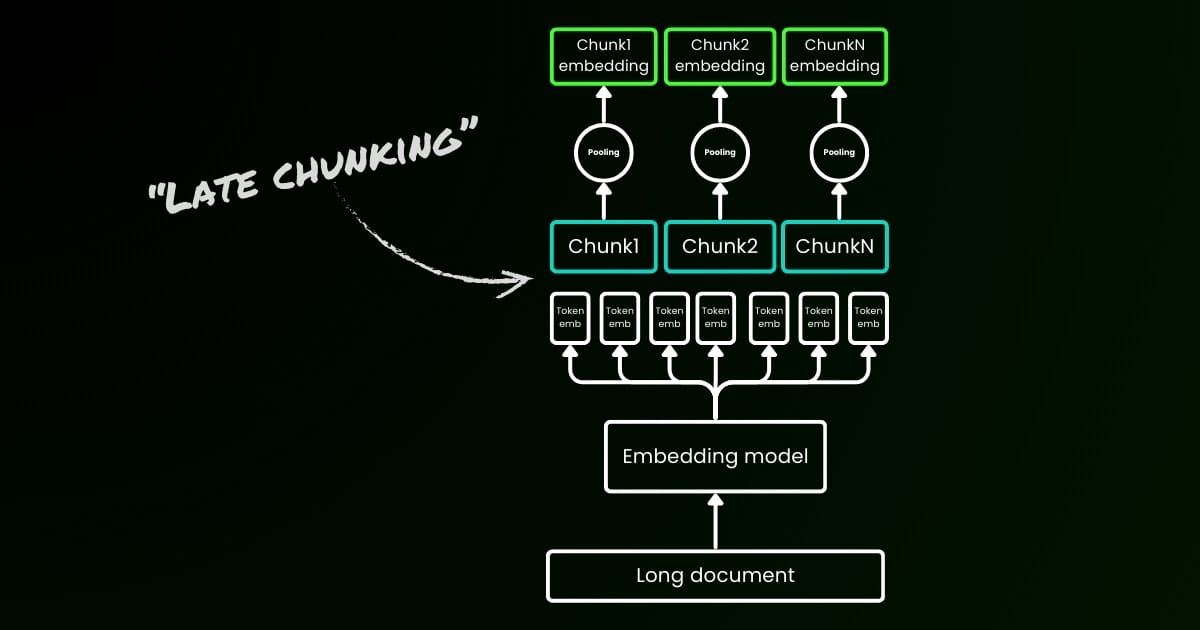
Finalmente, el parámetro late_chunking controla si se usa el nuevo método de segmentación que introdujimos el mes pasado para codificar un lote de oraciones. Cuando se establece en true, nuestra API concatenará todas las oraciones en el campo input y las alimentará como una única cadena al modelo. En otras palabras, tratamos las oraciones en la entrada como si originalmente vinieran de la misma sección, párrafo o documento. Internamente, el modelo embebe esta larga cadena concatenada y luego realiza la segmentación tardía, devolviendo una lista de embeddings que coincide con el tamaño de la lista de entrada. Cada embedding en la lista está por lo tanto condicionado a los embeddings previos.
Desde la perspectiva del usuario, establecer late_chunking no cambia el formato de entrada o salida. Solo notarás un cambio en los valores de embedding, ya que ahora se calculan basándose en todo el contexto previo en lugar de independientemente. Lo que es importante saber al usarlate_chunking=True significa que el número total de tokens (sumando todos los tokens en input) por solicitud está restringido a 8192, que es la longitud máxima de contexto permitida para jina-embeddings-v3. Cuando late_chunking=False, no existe tal restricción; el número total de tokens solo está sujeto a el límite de tasa de la API de Embedding.
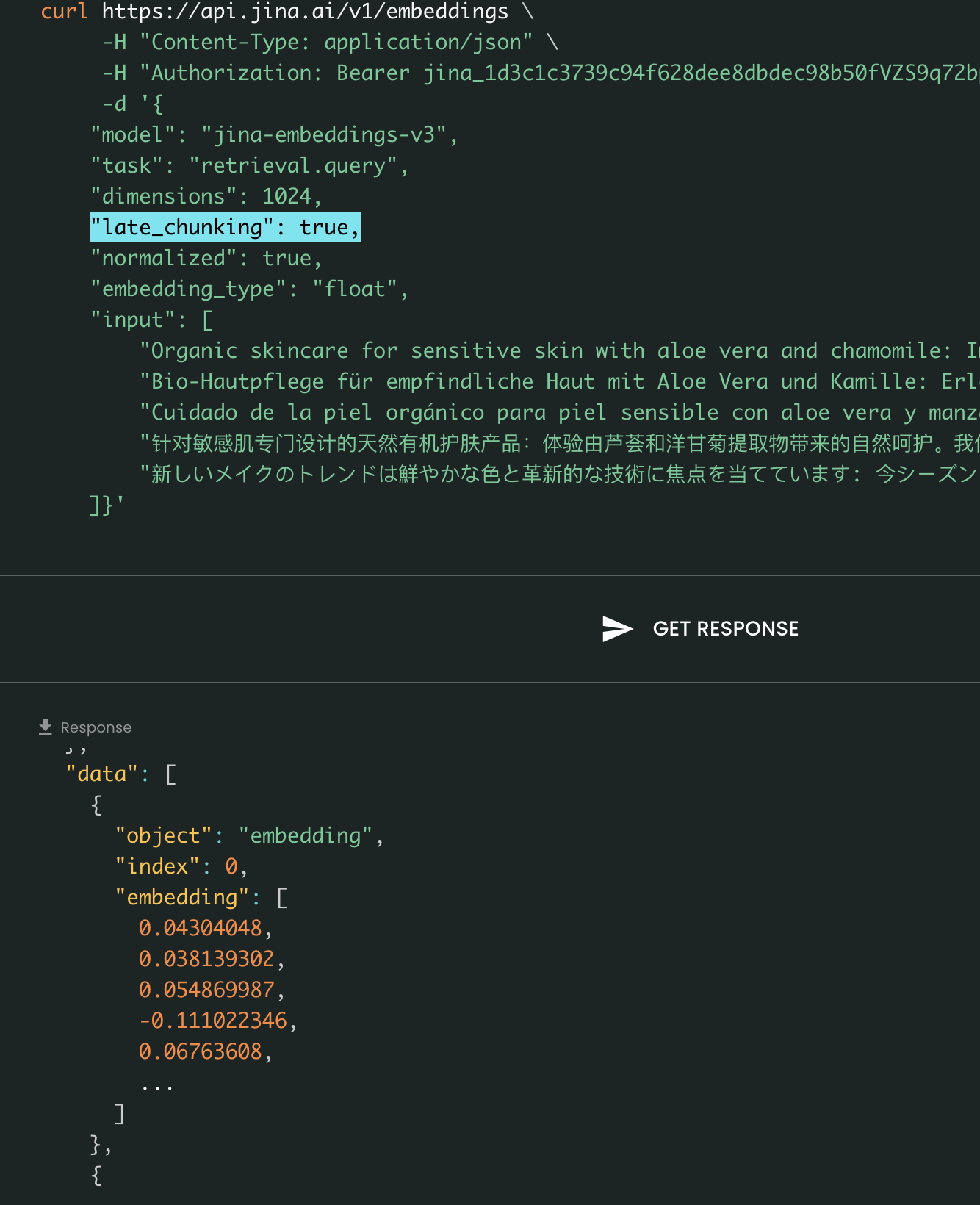
Late Chunking activado vs desactivado: El formato de entrada y salida permanece igual, siendo la única diferencia los valores de embedding. Cuando late_chunking está habilitado, los embeddings están influenciados por todo el contexto previo en input, mientras que sin él, los embeddings se calculan de forma independiente.
tagA través de Azure y AWS
jina-embeddings-v3 está ahora disponible en AWS SageMaker y Azure Marketplace.


Si necesitas utilizarlo más allá de estas plataformas o en las instalaciones de tu empresa, ten en cuenta que el modelo está licenciado bajo CC BY-NC 4.0. Para consultas sobre uso comercial, no dudes en contactarnos.
tagA través de Bases de Datos Vectoriales y Socios
Colaboramos estrechamente con proveedores de bases de datos vectoriales como Pinecone, Qdrant y Milvus, así como con frameworks de orquestación de LLM como LlamaIndex, Haystack y Dify. Al momento del lanzamiento, nos complace anunciar que Pinecone, Qdrant, Milvus y Haystack ya han integrado soporte para jina-embeddings-v3, incluyendo los tres nuevos parámetros: task, dimensions y late_chunking. Otros socios que ya se han integrado con la API v2 también deberían soportar v3 simplemente cambiando el nombre del modelo a jina-embeddings-v3. Sin embargo, es posible que aún no soporten los nuevos parámetros introducidos en v3.
A través de Pinecone

A través de Qdrant

A través de Milvus

A través de Haystack

tagConclusión
En octubre de 2023, lanzamos jina-embeddings-v2-base-en, el primer modelo de embedding de código abierto del mundo con una longitud de contexto de 8K. Era el único modelo de embedding de texto que soportaba contexto largo y se equiparaba a text-embedding-ada-002 de OpenAI. Hoy, después de un año de aprendizaje, experimentación y valiosas lecciones, nos enorgullece lanzar jina-embeddings-v3—una nueva frontera en modelos de embedding de texto y un gran hito para nuestra empresa.
Con este lanzamiento, continuamos destacando en lo que somos conocidos: embeddings de contexto largo, mientras también abordamos la característica más solicitada tanto por la industria como por la comunidad—embeddings multilingües. Al mismo tiempo, llevamos el rendimiento a un nuevo nivel. Con nuevas características como LoRA específico por tarea, MRL y late chunking, creemos que jina-embeddings-v3 servirá verdaderamente como el modelo de embedding fundamental para diversas aplicaciones, incluyendo RAG, agentes y más. Comparado con embeddings recientes basados en LLM como NV-embed-v1/v2, nuestro modelo es altamente eficiente en parámetros, haciéndolo mucho más adecuado para producción y dispositivos edge.
En el futuro, planeamos enfocarnos en evaluar y mejorar el rendimiento de jina-embeddings-v3 en idiomas con recursos limitados y analizar más a fondo los fallos sistemáticos causados por la disponibilidad limitada de datos. Además, los pesos del modelo de jina-embeddings-v3, junto con sus características innovadoras y perspectivas interesantes, servirán como base para nuestros próximos modelos, incluyendo jina-clip-v2,jina-reranker-v3, y reader-lm-v2.
