





Hoy lanzamos Jina Reranker v2 (jina-reranker-v2-base-multilingual), nuestro más reciente y mejor modelo de reranking neural de la familia de fundamentos de búsqueda. Con Jina Reranker v2, los desarrolladores de sistemas RAG/búsqueda pueden disfrutar de:
- Multilingüe: Resultados de búsqueda más relevantes en más de 100 idiomas, superando a
bge-reranker-v2-m3; - Agéntico: Reranking de documentos de última generación con capacidad de llamadas a funciones y text-to-SQL para RAG agéntico;
- Recuperación de código: Máximo rendimiento en tareas de recuperación de código, y
- Ultra rápido: Procesamiento de 15 veces más documentos que
bge-reranker-v2-m3, y 6 veces más que jina-reranker-v1-base-en.
Puedes comenzar a usar Jina Reranker v2 a través de nuestra API Reranker, donde ofrecemos 1M de tokens gratuitos para todos los nuevos usuarios.

En este artículo, profundizaremos en estas nuevas características soportadas por Jina Reranker v2, mostrando cómo se desempeña nuestro modelo de reranking en comparación con otros modelos de última generación (incluido Jina Reranker v1), y explicaremos el proceso de entrenamiento que llevó a Jina Reranker v2 a alcanzar el máximo rendimiento en precisión de tareas y procesamiento de documentos.
tagRecapitulación: Por Qué Necesitas un Reranker
Si bien los modelos de embedding son el componente más utilizado y comprendido en fundamentos de búsqueda, a menudo sacrifican precisión por velocidad de recuperación. Los modelos de búsqueda basados en embeddings son típicamente modelos bi-encoder, donde cada documento se incrusta y almacena, luego las consultas también se incrustan y la recuperación se basa en la similitud del embedding de la consulta con los embeddings de los documentos. En este modelo, se pierden muchos matices de las interacciones a nivel de token entre las consultas de los usuarios y los documentos coincidentes porque la consulta original y los documentos nunca pueden "verse" entre sí – solo lo hacen sus embeddings. Esto puede tener un costo en la precisión de la recuperación – un área donde los modelos reranker de tipo cross-encoder sobresalen.

Los rerankers abordan esta falta de semántica detallada empleando una arquitectura cross-encoder, donde los pares consulta-documento se codifican juntos para producir una puntuación de relevancia en lugar de un embedding. Los estudios han demostrado que, para la mayoría de los sistemas RAG, el uso de un modelo reranker mejora la fundamentación semántica y reduce las alucinaciones.
tagSoporte Multilingüe con Jina Reranker v2
En el pasado, Jina Reranker v1 se diferenció al alcanzar un rendimiento de última generación en cuatro benchmarks clave en inglés. ¡Hoy, estamos ampliando significativamente las capacidades de reranking en Jina Reranker v2 con soporte multilingüe para más de 100 idiomas y tareas multilingües!
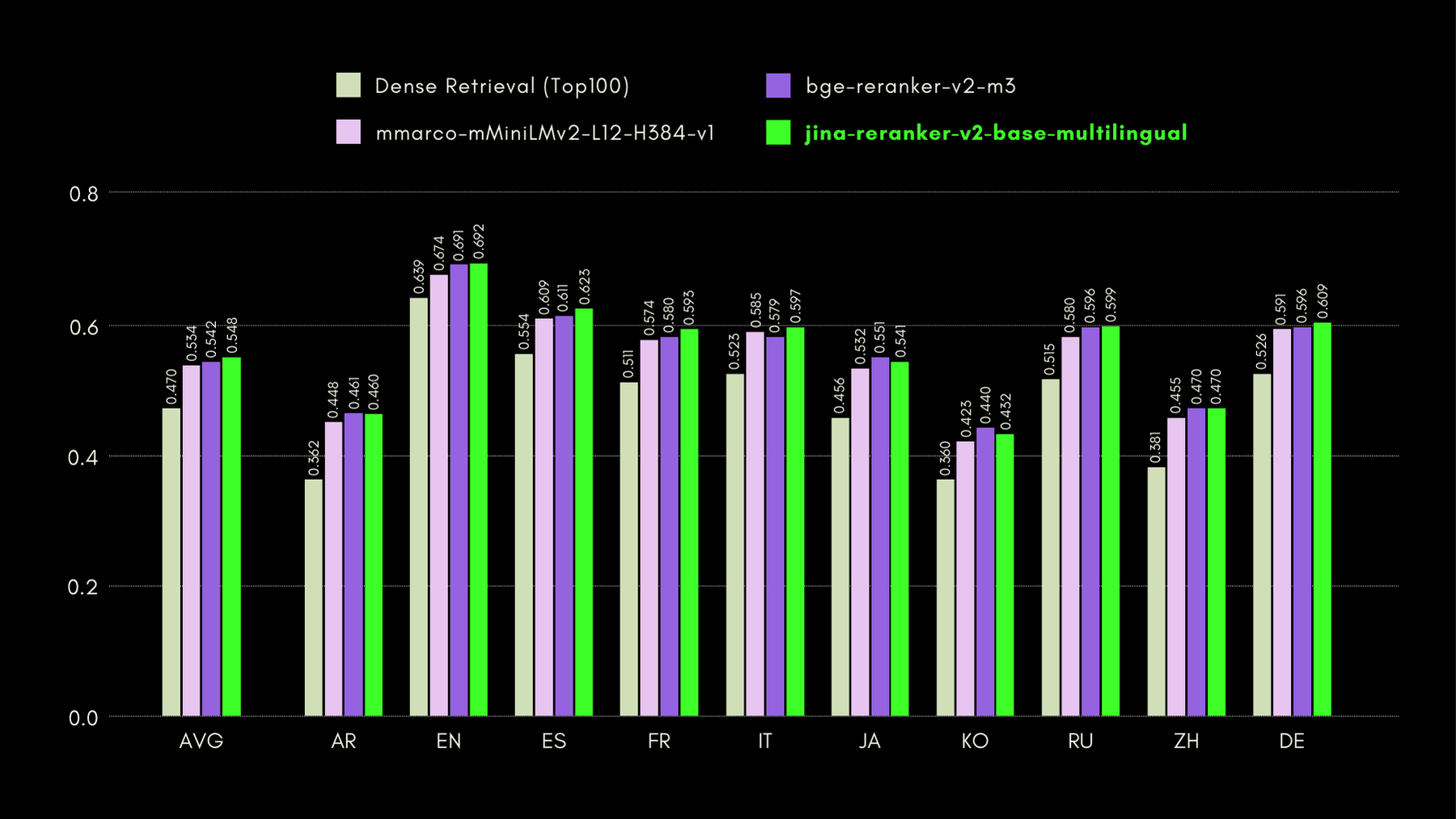
Para evaluar las capacidades multilingües y en inglés de Jina Reranker v2, comparamos su rendimiento con modelos similares de reranking, en los tres benchmarks que se enumeran a continuación:
MKQA: Preguntas y Respuestas de Conocimiento Multilingüe
Este conjunto de datos comprende preguntas y respuestas en 26 idiomas, derivadas de bases de conocimiento del mundo real, y está diseñado para evaluar el rendimiento multilingüe de los sistemas de preguntas y respuestas. MKQA consiste en consultas en inglés y sus traducciones manuales a idiomas no ingleses, junto con respuestas en múltiples idiomas, incluyendo inglés.
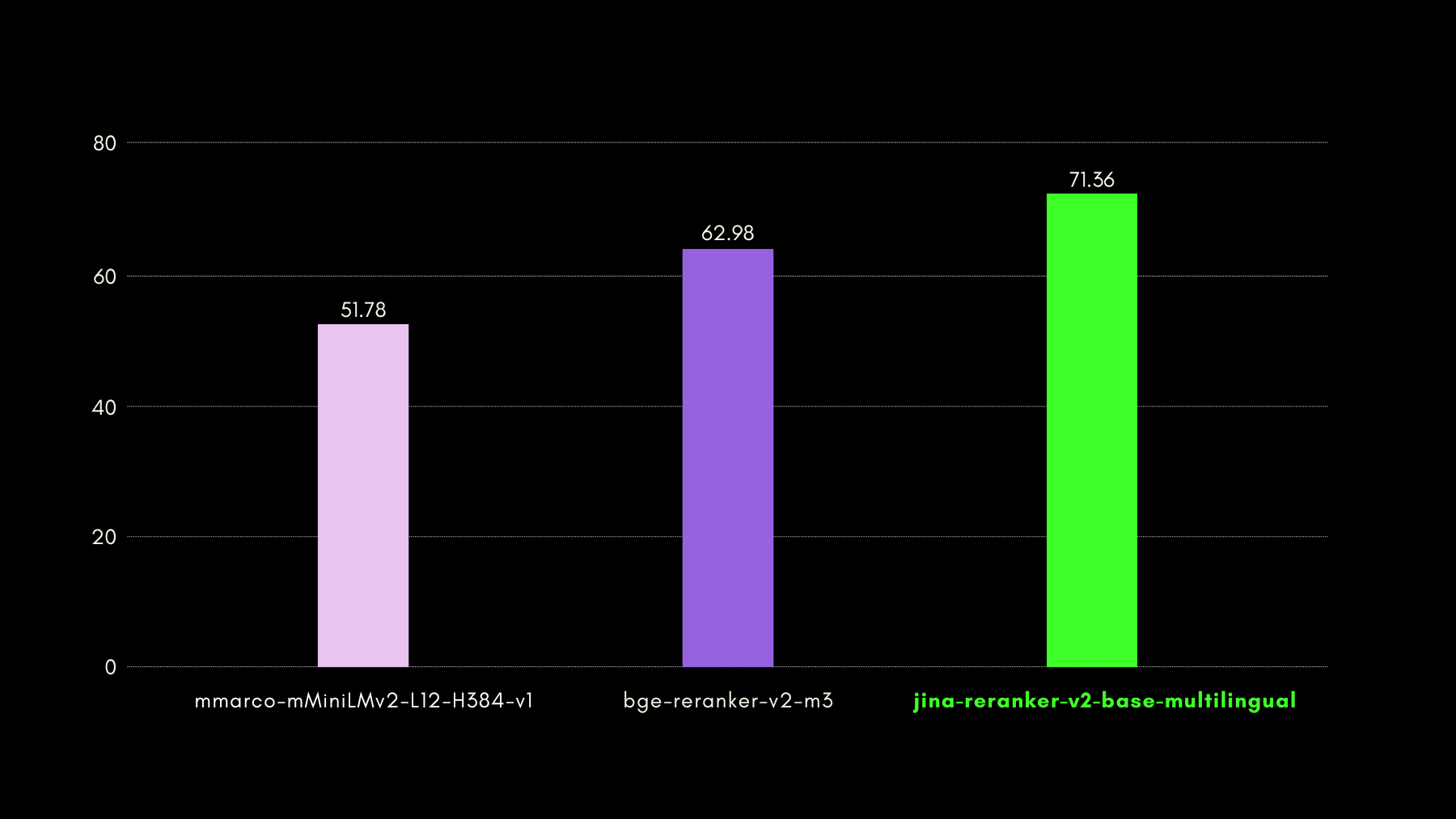
En el siguiente gráfico, mostramos las puntuaciones recall@10 para cada reranker incluido, incluyendo un "dense retriever" como línea base, realizando búsqueda tradicional basada en embeddings:
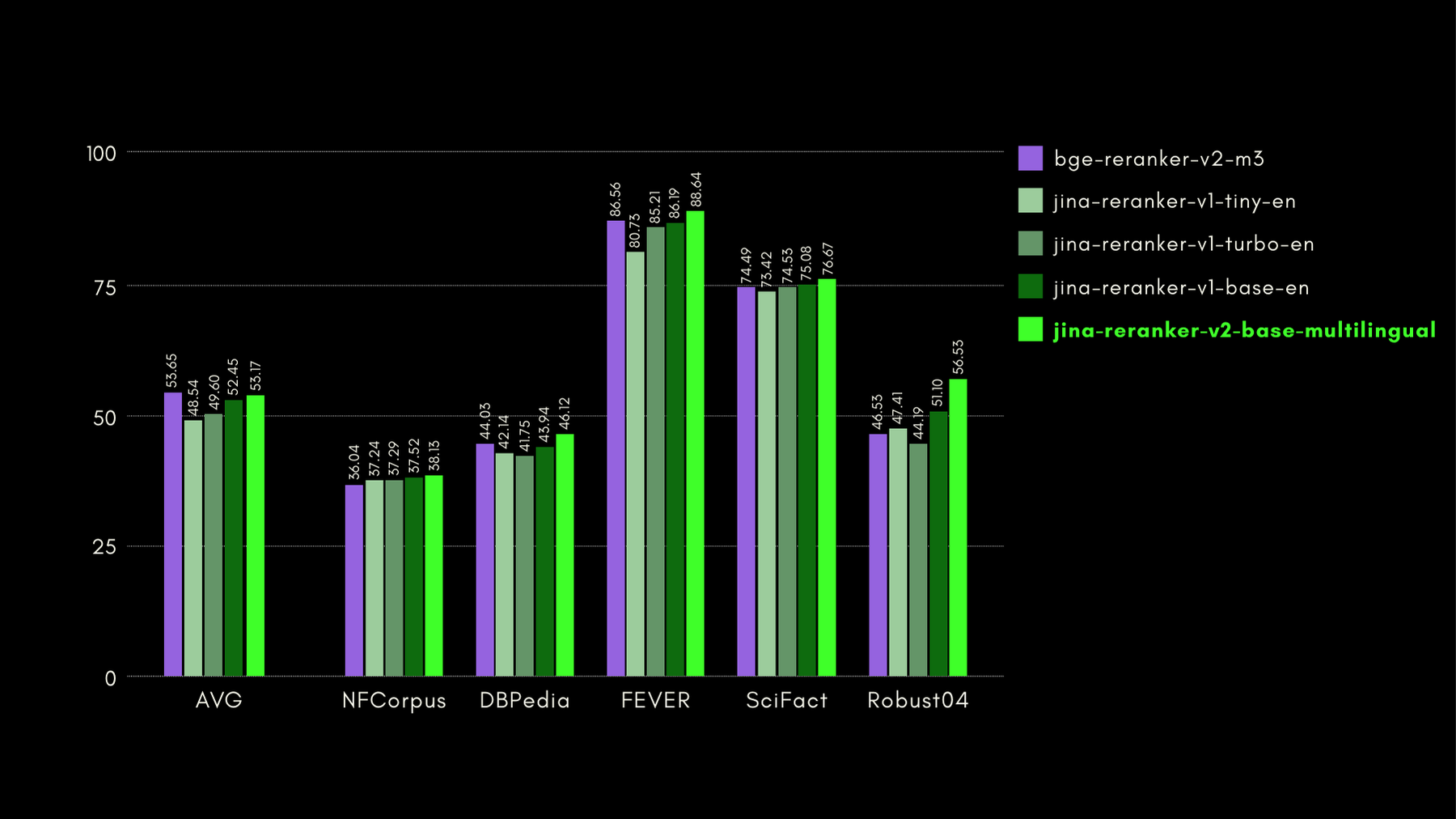
BEIR: Benchmark Heterogéneo en Diversas Tareas de IR
Este repositorio de código abierto contiene un benchmark de recuperación para muchos idiomas, pero nos enfocamos solo en las tareas en inglés. Estas consisten en 17 conjuntos de datos, sin datos de entrenamiento, y el enfoque de estos conjuntos de datos está en evaluar la precisión de recuperación de recuperadores neurales o léxicos.
En el siguiente gráfico, mostramos NDCG@10 para BEIR con cada reranker incluido. Los resultados en BEIR muestran claramente que las capacidades multilingües recién introducidas de jina-reranker-v2-base-multilingual no comprometen sus capacidades de recuperación en inglés, que además, mejoran significativamente respecto a jina-reranker-v1-base-en.
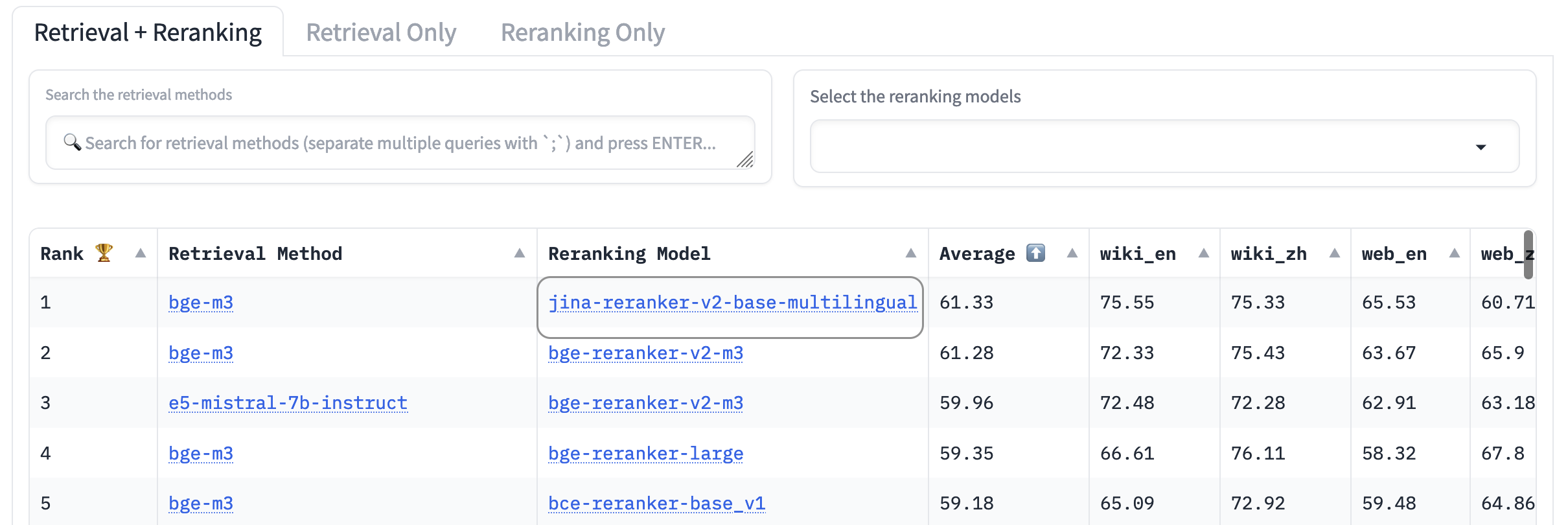
AirBench: Benchmark Heterogéneo Automatizado de IR
Junto con BAAI, hemos co-creado y publicado el benchmark AirBench para sistemas RAG. Este benchmark utiliza datos sintéticos generados automáticamente para dominios y tareas personalizadas, sin revelar públicamente la verdad fundamental para que los modelos evaluados no tengan oportunidad de sobreajustarse al conjunto de datos.
Al momento de escribir esto, jina-reranker-v2-base-multilingual supera a todos los demás modelos de reranking incluidos, ocupando el primer lugar en el ranking.
tagRecapitulación de Tooling-Agents: Enseñando a los LLMs a Usar Herramientas
Desde que comenzó el gran boom de la IA hace unos años, la gente ha visto cómo los modelos de IA tienen un rendimiento inferior en cosas en las que se supone que las computadoras son buenas. Por ejemplo, considera esta conversación con Mistral-7b-Instruct-v0.1:

Esto podría parecer correcto a primera vista, pero en realidad 203 multiplicado por 7724 es 1.567.972.
Entonces, ¿por qué el LLM se equivoca por un factor de más de diez? Es porque los LLMs no están entrenados para hacer matemáticas o cualquier otro tipo de razonamiento, y la falta de recursión interna prácticamente garantiza que no pueden resolver problemas matemáticos complejos. Están entrenados para decir cosas o realizar alguna otra tarea que no es inherentemente precisa.
Sin embargo, los LLMs no tienen problema en alucinar respuestas. Desde su perspectiva, 15.824.772 es una respuesta perfectamente plausible para 204 × 7.724. Es solo que está totalmente equivocada.
El RAG Agéntico cambia el rol de los LLMs generativos de aquello en lo que son malos — pensar y saber cosas — a aquello en lo que son buenos: comprensión lectora y síntesis de información en lenguaje natural. En lugar de simplemente generar una respuesta, RAG encuentra información relevante para responder tu solicitud en cualquier fuente de datos disponible y la presenta al modelo de lenguaje. Su trabajo no es inventar una respuesta para ti, sino presentar respuestas encontradas por un sistema diferente de forma natural y receptiva.
Hemos entrenado Jina Reranker v2 para ser sensible a esquemas de bases de datos SQL y llamadas a funciones. Esto necesita un tipo diferente de semántica que la recuperación de texto convencional. Debe ser consciente de las tareas y del código, y hemos entrenado nuestro reranker específicamente para esta funcionalidad.
tagJina Reranker v2 en Consultas de Datos Estructurados
Mientras que los modelos de embedding y reranking ya tratan los datos no estructurados como ciudadanos de primera clase, el soporte para datos tabulares estructurados todavía es deficiente en la mayoría de los modelos.
Jina Reranker v2 comprende la intención downstream de consultar una fuente de bases de datos estructuradas, como MySQL o MongoDB, y asigna la puntuación de relevancia correcta a un esquema de tabla estructurado, dado una consulta de entrada.
Puedes ver esto a continuación, donde el reranker recupera las tablas más relevantes antes de que se solicite a un LLM generar una consulta SQL a partir de una consulta en lenguaje natural:
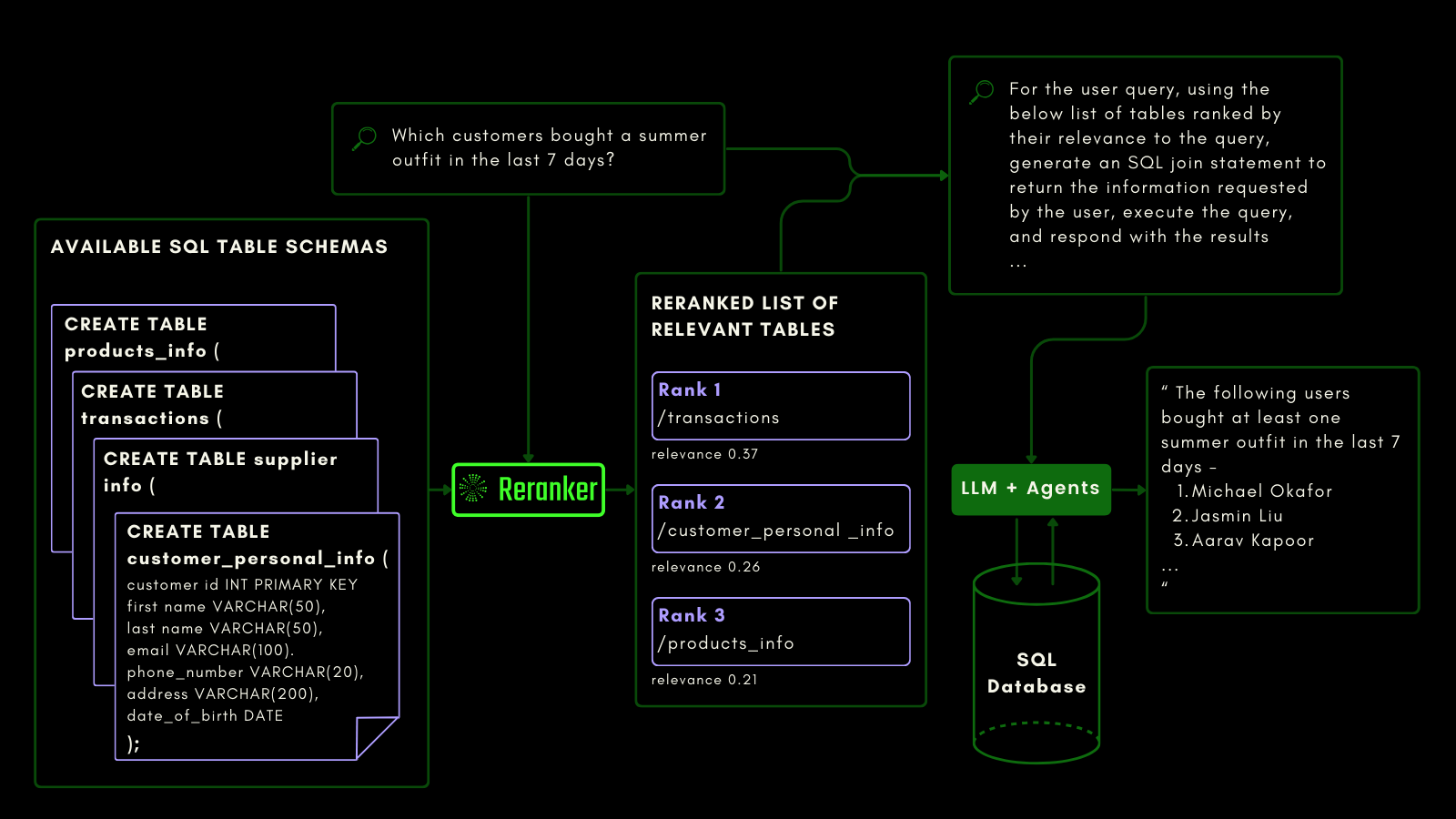
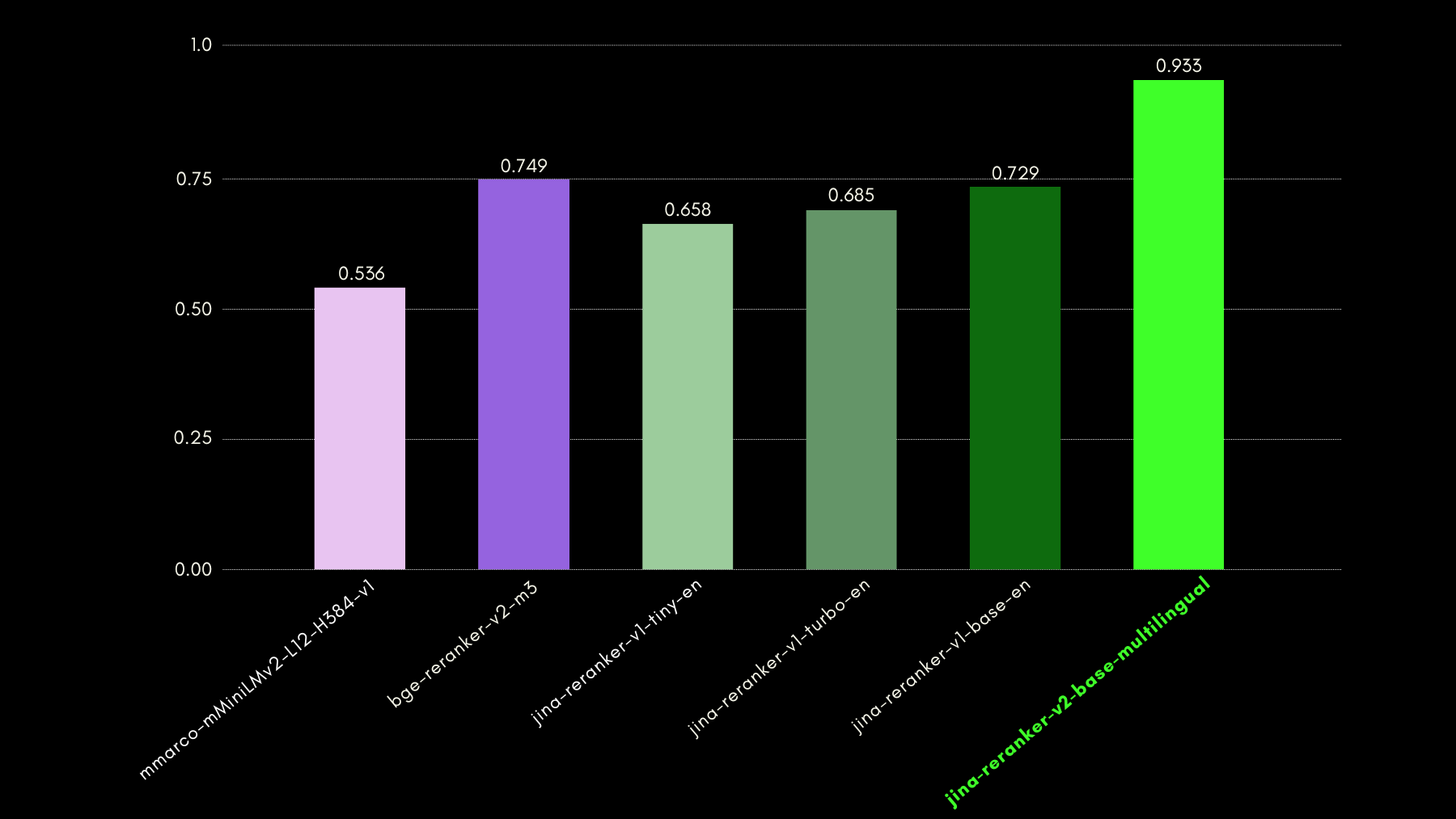
Evaluamos las capacidades conscientes de consultas usando el benchmark del conjunto de datos NSText2SQL. Extraemos, de la columna "instruction" del conjunto de datos original, instrucciones escritas en lenguaje natural y el esquema de tabla correspondiente.
El gráfico siguiente compara, usando recall@3, qué tan exitosos son los modelos de reranking en clasificar el esquema de tabla correcto correspondiente a una consulta en lenguaje natural.
tagJina Reranker v2 en Llamadas a Funciones
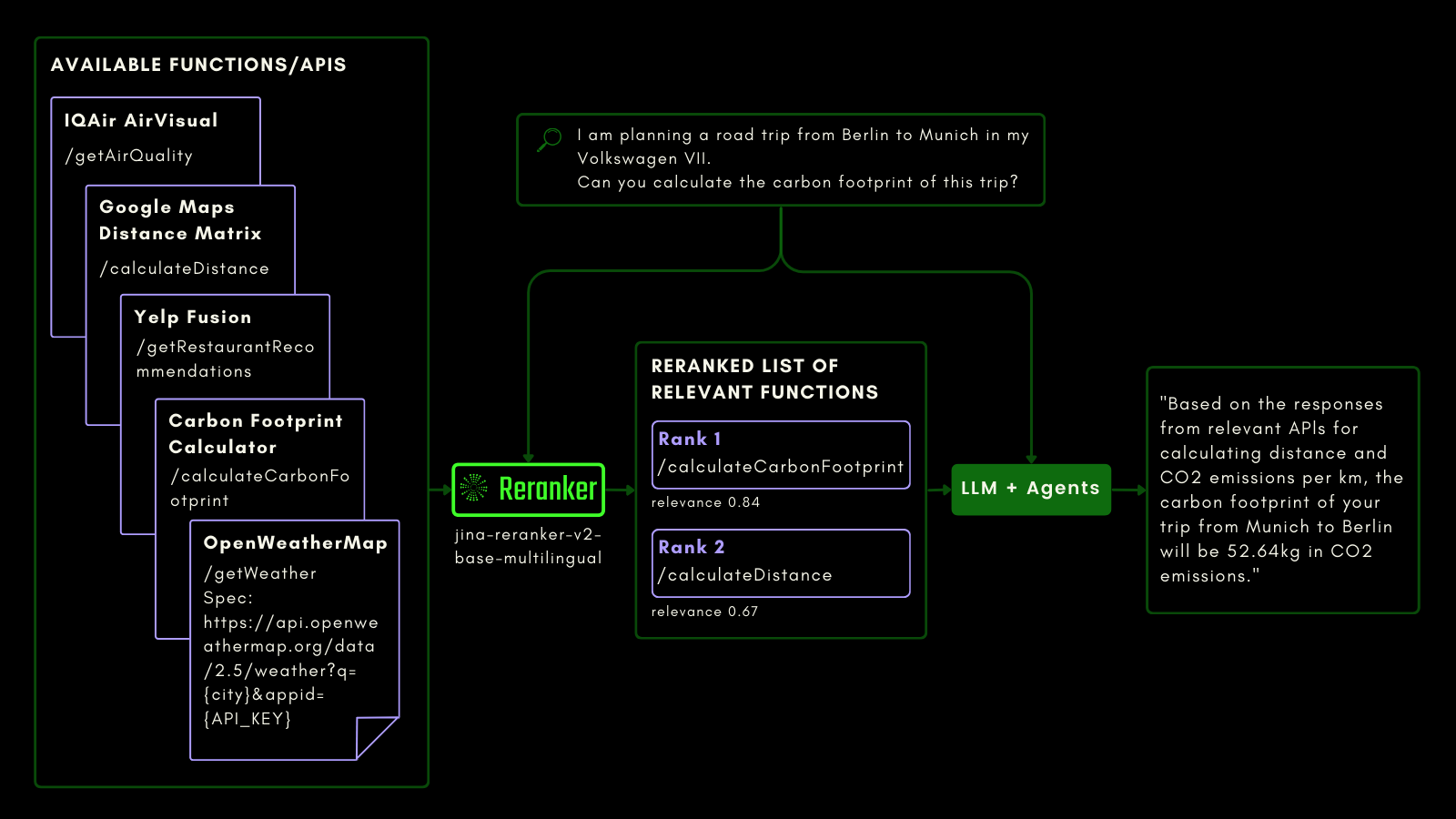
Al igual que consultar una tabla SQL, puedes usar RAG agéntico para invocar herramientas externas. Con eso en mente, integramos la llamada a funciones en Jina Reranker v2, permitiéndole entender tu intención para funciones externas y asignar puntuaciones de relevancia a las especificaciones de funciones en consecuencia.
El esquema siguiente explica (con un ejemplo) cómo los LLMs pueden usar Reranker para mejorar las capacidades de llamada a funciones y, en última instancia, la experiencia de usuario de IA agéntica.
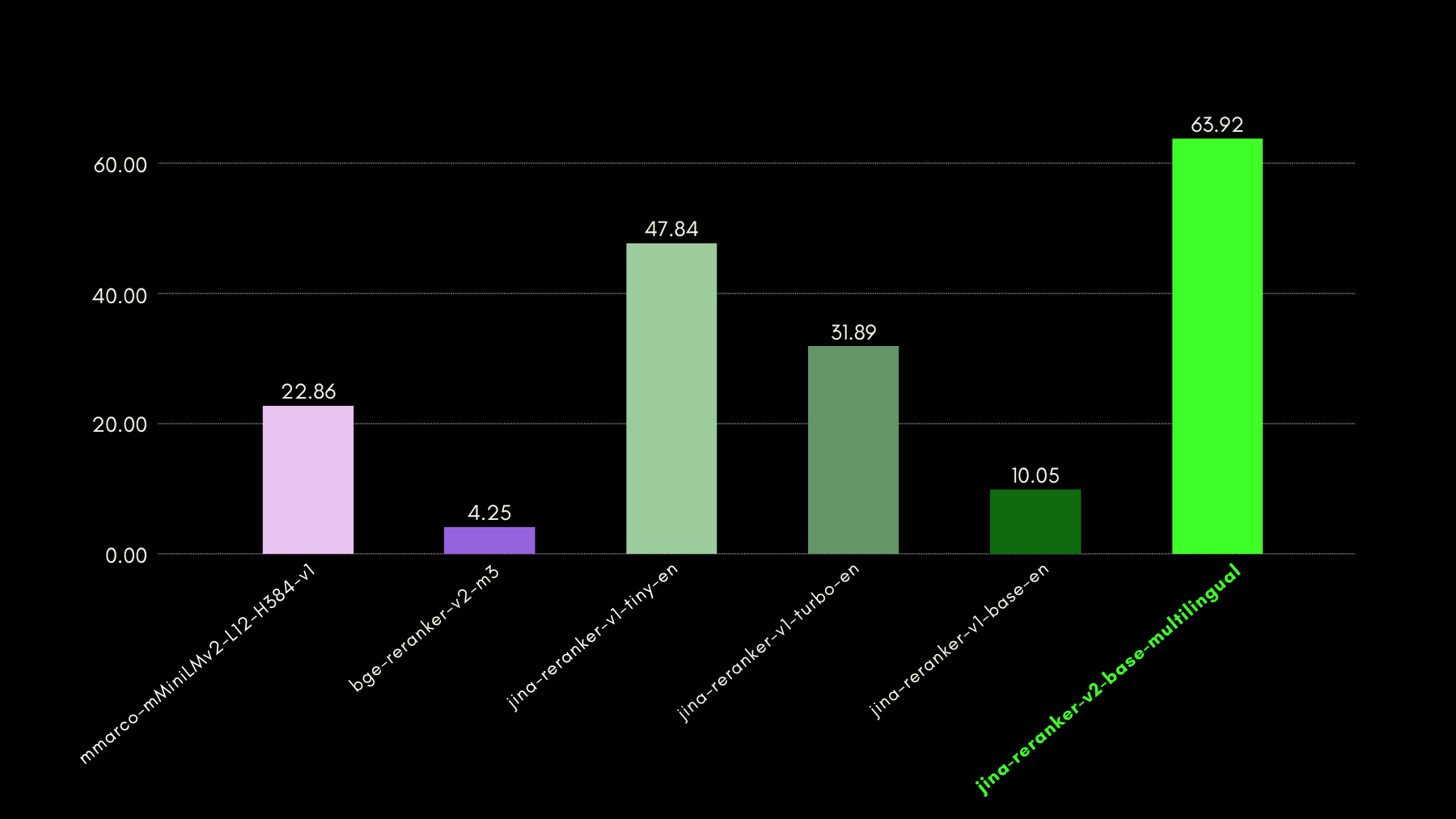
Evaluamos las capacidades conscientes de funciones con el benchmark ToolBench. El benchmark recopila más de 16 mil APIs públicas y las correspondientes instrucciones generadas sintéticamente para usarlas en configuraciones de API única y múltiple.
Aquí están los resultados (métrica recall@3) comparados con otros modelos de reranking:
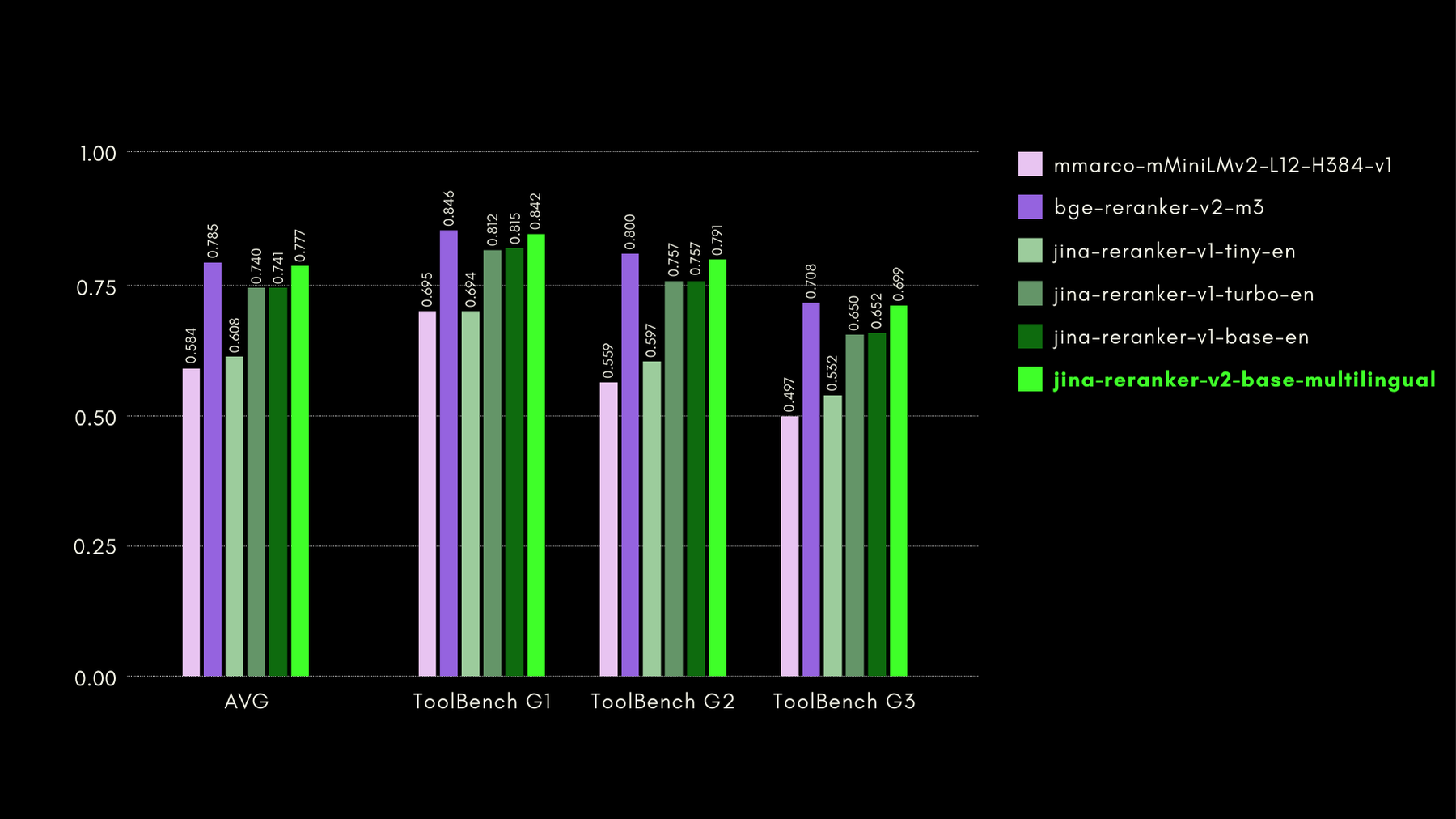
Como también mostraremos en las secciones posteriores, el rendimiento casi estado del arte de jina-reranker-v2-base-multilingual viene con el beneficio de ser la mitad del tamaño de bge-reranker-v2-m3 y casi 15 veces más rápido.
tagJina Reranker v2 en la Recuperación de Código
Jina Reranker v2, además de estar entrenado en llamadas a funciones y consultas de datos estructurados, también mejora la recuperación de código en comparación con modelos competidores de tamaño similar. Evaluamos sus capacidades de recuperación de código utilizando el benchmark CodeSearchNet. El benchmark es una combinación de consultas en formatos de docstring y lenguaje natural, con segmentos de código etiquetados relevantes para las consultas.
Aquí están los resultados, usando MRR@10, comparados con otros modelos de reranking:
tagInferencia Ultra Rápida con Jina Reranker v2
Si bien los rerankers neuronales de estilo cross-encoder sobresalen en predecir la relevancia de un documento recuperado, ofrecen una inferencia más lenta que los modelos de embedding. Es decir, comparar una consulta con n documentos uno por uno es mucho más lento que HNSW o cualquier otro método de recuperación rápida en la mayoría de las bases de datos vectoriales. Solucionamos esta lentitud con Jina Reranker v2.
- Nuestras perspectivas únicas de entrenamiento (descritas en la siguiente sección) resultaron en que nuestro modelo alcanzara un rendimiento de vanguardia en precisión con solo 278M parámetros. Comparado con, por ejemplo,
bge-reranker-v2-m3, con 567M parámetros, Jina Reranker v2 es solo la mitad del tamaño. Esta reducción es la primera razón para mejorar el rendimiento (documentos procesados por 50ms). - Incluso con un tamaño de modelo comparable, Jina Reranker v2 presenta 6 veces el rendimiento de nuestro anterior modelo estado del arte Jina Reranker v1 para inglés. Esto se debe a que implementamos Jina Reranker v2 con Flash Attention 2, que introduce optimizaciones de memoria y computación en la capa de atención de los modelos basados en transformers.
Puedes ver el resultado de los pasos anteriores, en términos del rendimiento de Jina Reranker v2:
tagCómo Entrenamos Jina Reranker v2
Entrenamos jina-reranker-v2-base-multilingual en cuatro etapas:
- Preparación con Datos en Inglés: Preparamos la primera versión del modelo entrenando un modelo base con datos solo en inglés, incluyendo pares (entrenamiento contrastivo) o tripletes (consulta, respuesta correcta, respuesta incorrecta), pares de esquema consulta-función y pares de esquema consulta-tabla.
- Adición de Datos Multilingües: En la siguiente etapa, agregamos conjuntos de datos de pares y tripletes multilingües para mejorar las capacidades multilingües del modelo base específicamente en tareas de recuperación.
- Adición de todos los Datos Multilingües: En esta etapa, nos centramos principalmente en asegurar que el modelo vea la mayor cantidad posible de nuestros datos. Ajustamos el punto de control del modelo de la segunda etapa con todos los conjuntos de datos de pares y tripletes, de más de 100 idiomas de recursos bajos y altos.
- Ajuste Fino con Negativos Difíciles Minados: Después de observar el rendimiento de reranking de la tercera etapa, ajustamos el modelo agregando más datos de tripletes con específicamente más ejemplos de negativos difíciles para consultas existentes - respuestas que parecen superficialmente relevantes para la consulta, pero que de hecho son incorrectas.
Este enfoque de entrenamiento en cuatro etapas se basó en la idea de que incluir funciones y esquemas tabulares en el proceso de entrenamiento lo antes posible permitió que el modelo fuera particularmente consciente de estos casos de uso y aprendiera a centrarse más en la semántica de los documentos candidatos que en las construcciones del lenguaje.
tagJina Reranker v2 en la Práctica
tagA través de Nuestra API de Reranker
La forma más rápida y fácil de comenzar con Jina Reranker v2 es usar la API de Jina Reranker.
Dirígete a la sección de API de esta página para integrar jina-reranker-v2-base-multilingual usando el lenguaje de programación de tu elección.
Ejemplo 1: Clasificación de Llamadas a Funciones
Para clasificar la función/herramienta externa más relevante, formatea la consulta y los documentos (esquemas de función) como se muestra a continuación:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <TU TOKEN DE JINA AI AQUÍ>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "I am planning a road trip from Berlin to Munich in my Volkswagen VII. Can you calculate the carbon footprint of this trip?",
"documents": [
"{'\''Name'\'': '\''getWeather'\'', '\''Specification'\'': '\''Provides current weather information for a specified city'\'', '\''spec'\'': '\''https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}'\'', '\''example'\'': '\''https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateDistance'\'', '\''Specification'\'': '\''Calculates the driving distance and time between multiple locations'\'', '\''spec'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}'\'', '\''example'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateCarbonFootprint'\'', '\''Specification'\'': '\''Estimates the carbon footprint for various activities, including transportation'\'', '\''spec'\'': '\''https://www.carboninterface.com/api/v1/estimates'\'', '\''example'\'': '\''{type: vehicle, distance: distance, vehicle_model_id: car}'\''}"
]
}'Recuerda sustituir <TU TOKEN DE JINA AI AQUÍ> con tu token personal de la API de Reranker
Deberías obtener:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 383,
"prompt_tokens": 383
},
"results": [
{
"index": 2,
"document": {
"text": "{'Name': 'calculateCarbonFootprint', 'Specification': 'Estimates the carbon footprint for various activities, including transportation', 'spec': 'https://www.carboninterface.com/api/v1/estimates', 'example': '{type: vehicle, distance: distance, vehicle_model_id: car}'}"
},
"relevance_score": 0.5422876477241516
},
{
"index": 1,
"document": {
"text": "{'Name': 'calculateDistance', 'Specification': 'Calculates the driving distance and time between multiple locations', 'spec': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}', 'example': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'}"
},
"relevance_score": 0.23283305764198303
},
{
"index": 0,
"document": {
"text": "{'Name': 'getWeather', 'Specification': 'Provides current weather information for a specified city', 'spec': 'https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}', 'example': 'https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'}"
},
"relevance_score": 0.05033063143491745
}
]
}Ejemplo 2: Clasificación de consultas SQL
Del mismo modo, para obtener puntuaciones de relevancia para esquemas de tablas estructuradas para tu consulta, puedes usar el siguiente ejemplo de llamada a la API:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "which customers bought a summer outfit in the past 7 days?",
"documents": [
"CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));",
"CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));",
"CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));",
"CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
]
}'La respuesta esperada es:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 253,
"prompt_tokens": 253
},
"results": [
{
"index": 2,
"document": {
"text": "CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));"
},
"relevance_score": 0.2789437472820282
},
{
"index": 0,
"document": {
"text": "CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));"
},
"relevance_score": 0.06477169692516327
},
{
"index": 3,
"document": {
"text": "CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
},
"relevance_score": 0.027742892503738403
},
{
"index": 1,
"document": {
"text": "CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));"
},
"relevance_score": 0.025516605004668236
}
]
}tagA través de frameworks RAG/LLM
Las integraciones existentes de Jina Reranker con frameworks de orquestación LLM y RAG deberían funcionar de inmediato usando el nombre del modelo jina-reranker-v2-base-multilingual. Consulta sus respectivas páginas de documentación para aprender más sobre cómo integrar Jina Reranker v2 en tus aplicaciones.
- Haystack de deepset: Jina Reranker v2 puede usarse con la clase JinaRanker en Haystack:
from haystack import Document
from haystack_integrations.components.rankers.jina import JinaRanker
docs = [Document(content="Paris"), Document(content="Berlin")]
ranker = JinaRanker(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>")
ranker.run(query="City in France", documents=docs, top_k=1)
- LlamaIndex: Jina Reranker v2 puede usarse como un módulo JinaRerank node postprocessor iniciándolo:
import os
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>", top_n=1)
- Langchain: Utiliza la integración Jina Rerank para usar Jina Reranker 2 en tu aplicación existente. El módulo JinaRerank debe inicializarse con el nombre correcto del modelo:
from langchain_community.document_compressors import JinaRerank
reranker = JinaRerank(model="jina-reranker-v2-base-multilingual", jina_api_key="<YOUR JINA AI API KEY HERE>")
tagA través de HuggingFace
También estamos abriendo el acceso (bajo CC-BY-NC-4.0) al modelo jina-reranker-v2-base-multilingual en Hugging Face para fines de investigación y evaluación.

Para descargar y ejecutar el modelo desde Hugging Face, instala las bibliotecas transformers y einops:
pip install transformers einops
pip install ninja
pip install flash-attn --no-build-isolation
Inicia sesión en tu cuenta de Hugging Face a través del inicio de sesión CLI de Hugging Face usando tu token de acceso de Hugging Face:
huggingface-cli login --token <"HF-Access-Token">
Descarga el modelo pre-entrenado:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
'jinaai/jina-reranker-v2-base-multilingual',
torch_dtype="auto",
trust_remote_code=True,
)
model.to('cuda') # o 'cpu' si no hay GPU disponible
model.eval()
Define la consulta y los documentos a reclasificar:
query = "Organic skincare products for sensitive skin"
documents = [
"Organic skincare for sensitive skin with aloe vera and chamomile.",
"New makeup trends focus on bold colors and innovative techniques",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille",
"Neue Make-up-Trends setzen auf kräftige Farben und innovative Techniken",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla",
"Las nuevas tendencias de maquillaje se centran en colores vivos y técnicas innovadoras",
"针对敏感肌专门设计的天然有机护肤产品",
"新的化妆趋势注重鲜艳的颜色和创新的技巧",
"敏感肌のために特別に設計された天然有機スキンケア製品",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています",
]
Construye pares de oraciones y calcula las puntuaciones de relevancia:
sentence_pairs = [[query, doc] for doc in documents]
scores = model.compute_score(sentence_pairs, max_length=1024)
Las puntuaciones serán una lista de números flotantes, donde cada número representa la puntuación de relevancia del documento correspondiente para la consulta. Puntuaciones más altas significan mayor relevancia.
Alternativamente, usa la función rerank para reclasificar textos largos dividiendo automáticamente la consulta y los documentos según max_query_length y
max_length respectivamente. Cada fragmento se evalúa individualmente y las puntuaciones de cada fragmento se combinan para producir los resultados finales del reordenamiento:results = model.rerank(
query,
documents,
max_query_length=512,
max_length=1024,
top_n=3
)
Esta función no solo devuelve la puntuación de relevancia para cada documento, sino también su contenido y posición en la lista original de documentos.
tagA través de implementación en nube privada
Los paquetes precompilados para la implementación privada de Jina Reranker v2 en cuentas AWS y Azure pronto estarán disponibles en nuestras páginas de vendedor en AWS Marketplace y Azure Marketplace, respectivamente.
tagPuntos clave de Jina Reranker v2
Jina Reranker v2 representa una importante expansión de capacidades para search foundation:
- Recuperación de última generación utilizando cross-encoding abre una amplia gama de nuevas áreas de aplicación.
- Funcionalidad multilingüe y entre idiomas mejorada elimina las barreras lingüísticas de tus casos de uso.
- El mejor soporte para function calling de su clase, junto con el conocimiento de consultas de datos estructurados, lleva tus capacidades de RAG agéntico al siguiente nivel de precisión.
- Una mejor recuperación de código informático y datos con formato informático puede ir mucho más allá de la simple recuperación de información textual.
- Un rendimiento mucho más rápido en el procesamiento de documentos asegura que, independientemente del método de recuperación, ahora puedes reordenar muchos más documentos recuperados más rápidamente y delegar la mayor parte del cálculo de relevancia detallado a jina-reranker-v2-base-multilingual.
Los sistemas RAG son mucho más precisos con Reranker v2, ayudando a que tus soluciones existentes de gestión de información produzcan más y mejores resultados accionables. El soporte multilingüe hace que todo esto esté directamente disponible para empresas multinacionales y multilingües, con una API fácil de usar a un precio asequible.
Al probarlo con benchmarks derivados de casos de uso reales, puedes ver por ti mismo cómo Jina Reranker v2 mantiene un rendimiento de vanguardia en tareas relevantes para modelos de negocio reales, todo en un solo modelo de IA, manteniendo tus costos bajos y tu stack tecnológico más simple.
