


¡Nuevo! Parte II: análisis profundo de las señales de límites y conceptos erróneos.
Hace aproximadamente un año, en octubre de 2023, lanzamos el primer modelo de embeddings de código abierto del mundo con una longitud de contexto de 8K, jina-embeddings-v2-base-en. Desde entonces, ha habido bastante debate sobre la utilidad del contexto largo en los modelos de embeddings. Para muchas aplicaciones, codificar un documento de miles de palabras en una única representación de embedding no es ideal. Muchos casos de uso requieren recuperar porciones más pequeñas del texto, y los sistemas de recuperación basados en vectores densos a menudo funcionan mejor con segmentos de texto más pequeños, ya que es menos probable que la semántica esté "sobre-comprimida" en los vectores de embedding.
La Generación Aumentada por Recuperación (RAG) es una de las aplicaciones más conocidas que requiere dividir documentos en fragmentos de texto más pequeños (digamos dentro de 512 tokens). Estos fragmentos generalmente se almacenan en una base de datos vectorial, con representaciones vectoriales generadas por un modelo de embedding de texto. Durante la ejecución, el mismo modelo de embedding codifica una consulta en una representación vectorial, que luego se utiliza para identificar fragmentos de texto relevantes almacenados. Estos fragmentos se pasan posteriormente a un modelo de lenguaje grande (LLM), que sintetiza una respuesta a la consulta basada en los textos recuperados.

En resumen, embeber fragmentos más pequeños parece ser más preferible, en parte debido a los tamaños de entrada limitados de los LLM posteriores, pero también porque existe una preocupación de que la información contextual importante en un contexto largo pueda diluirse cuando se comprime en un solo vector.
Pero si la industria solo necesita modelos de embedding con una longitud de contexto de 512, ¿cuál es el punto de entrenar modelos con una longitud de contexto de 8192?
En este artículo, revisamos esta importante, aunque incómoda, pregunta explorando las limitaciones del pipeline ingenuo de fragmentación-embedding en RAG. Introducimos un nuevo enfoque llamado "Late Chunking", que aprovecha la rica información contextual proporcionada por los modelos de embedding de longitud 8192 para embeber fragmentos de manera más efectiva.
tagEl Problema del Contexto Perdido
El simple pipeline RAG de fragmentación-embedding-recuperación-generación no está exento de desafíos. Específicamente, este proceso puede destruir dependencias contextuales de largo alcance. En otras palabras, cuando la información relevante está dispersa en múltiples fragmentos, sacar segmentos de texto de contexto puede hacerlos inefectivos, haciendo que este enfoque sea particularmente problemático.
En la imagen de abajo, un artículo de Wikipedia se divide en fragmentos de oraciones. Puedes ver que frases como "su" y "la ciudad" hacen referencia a "Berlín", que solo se menciona en la primera oración. Esto hace más difícil que el modelo de embedding vincule estas referencias con la entidad correcta, produciendo así una representación vectorial de menor calidad.

Esto significa que, si dividimos un artículo largo en fragmentos de longitud de oración, como en el ejemplo anterior, un sistema RAG podría tener dificultades para responder una consulta como "¿Cuál es la población de Berlín?" Porque el nombre de la ciudad y la población nunca aparecen juntos en un solo fragmento, y sin ningún contexto de documento más amplio, un LLM presentado con uno de estos fragmentos no puede resolver referencias anafóricas como "ella" o "la ciudad".
Existen algunas heurísticas para aliviar este problema, como el remuestreo con una ventana deslizante, el uso de múltiples longitudes de ventana de contexto y la realización de escaneos de documentos en múltiples pasadas. Sin embargo, como todas las heurísticas, estos enfoques son de prueba y error; pueden funcionar en algunos casos, pero no hay garantía teórica de su efectividad.
tagLa Solución: Late Chunking
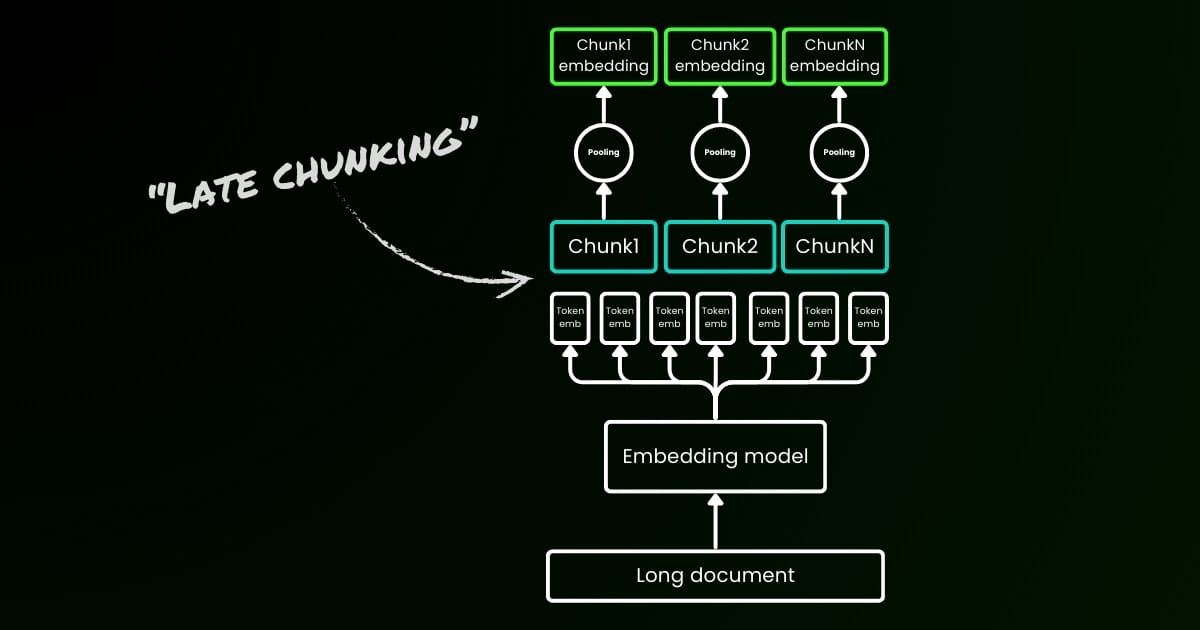
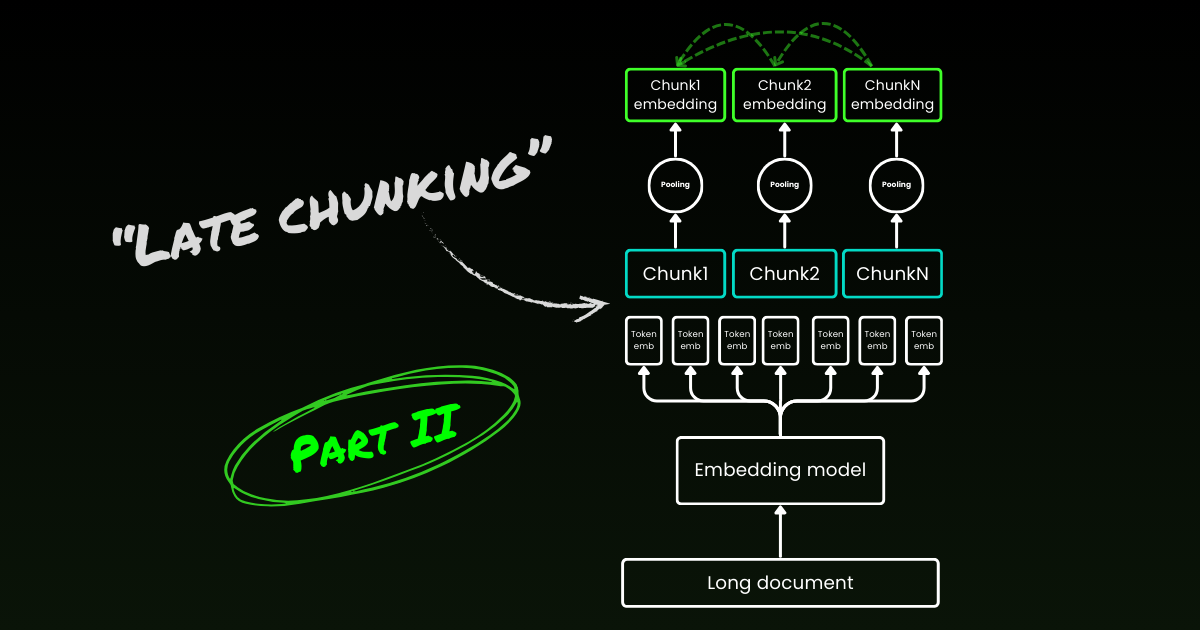
El enfoque de codificación ingenuo (como se ve en el lado izquierdo de la imagen de abajo) implica usar oraciones, párrafos o límites de longitud máxima para dividir el texto a priori. Después, un modelo de embedding se aplica repetitivamente a estos fragmentos resultantes. Para generar un solo embedding para cada fragmento, muchos modelos de embedding usan mean pooling en estos embeddings a nivel de token para producir un solo vector de embedding.

En contraste, el enfoque "Late Chunking" que proponemos en este artículo primero aplica la capa transformer del modelo de embedding a todo el texto o tanto como sea posible. Esto genera una secuencia de representaciones vectoriales para cada token que abarca información textual de todo el texto. Posteriormente, se aplica mean pooling a cada fragmento de esta secuencia de vectores de token, produciendo embeddings para cada fragmento que consideran el contexto completo del texto. A diferencia del enfoque de codificación ingenuo, que genera embeddings de fragmentos independientes e idénticamente distribuidos (i.i.d.), el late chunking crea un conjunto de embeddings de fragmentos donde cada uno está "condicionado por" los anteriores, codificando así más información contextual para cada fragmento.
Obviamente para aplicar efectivamente el late chunking, necesitamos modelos de embedding de contexto largo como jina-embeddings-v2-base-en, que soportan hasta 8192 tokens—aproximadamente diez páginas estándar de texto. Los segmentos de texto de este tamaño tienen muchas menos probabilidades de tener dependencias contextuales que requieran un contexto aún más largo para resolver.
Es importante destacar que el late chunking todavía requiere señales de límites, pero estas señales se utilizan solo después de obtener los embeddings a nivel de token—de ahí el término "late" en su nombre.
| Fragmentación Ingenua | Late Chunking | |
|---|---|---|
| La necesidad de señales de límites | Sí | Sí |
| El uso de señales de límites | Directamente en preprocesamiento | Después de obtener los embeddings a nivel de token de la capa transformer |
| Los embeddings de fragmentos resultantes | i.i.d. | Condicional |
| Información contextual de fragmentos cercanos | Perdida. Algunas heurísticas (como muestreo con superposición) para aliviar esto | Bien preservada por modelos de embedding de contexto largo |
tagImplementación y Evaluación Cualitativa


La implementación del late chunking se puede encontrar en el Google Colab enlazado arriba. Aquí, utilizamos nuestra reciente función lanzada en la API del Tokenizer, que aprovecha todas las posibles señales de límites para segmentar un documento largo en fragmentos significativos. Más discusión sobre el algoritmo detrás de esta función se puede encontrar en X.

Al aplicar el chunking tardío al ejemplo de Wikipedia anterior, se puede ver inmediatamente una mejora en la similitud semántica. Por ejemplo, en el caso de "la ciudad" y "Berlín" dentro de un artículo de Wikipedia, los vectores que representan "la ciudad" ahora contienen información que la vincula con la mención previa de "Berlín", lo que la convierte en una coincidencia mucho mejor para consultas relacionadas con ese nombre de ciudad.
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
Puedes observar esto en los resultados numéricos anteriores, que comparan el embedding del término "Berlin" con varias oraciones del artículo sobre Berlín usando similitud del coseno. La columna "Sim. on IID chunk embeddings" muestra los valores de similitud entre el embedding de consulta de "Berlin" y los embeddings usando chunking a priori, mientras que "Sim. under contextual chunk embedding" representa los resultados con el método de chunking tardío.
tagEvaluación Cuantitativa en BEIR
Para verificar la efectividad del chunking tardío más allá de un ejemplo de juguete, lo probamos usando algunos de los benchmarks de recuperación de BeIR. Estas tareas de recuperación consisten en un conjunto de consultas, un corpus de documentos de texto y un archivo QRels que almacena información sobre los IDs de documentos relevantes para cada consulta.
Para identificar los documentos relevantes para una consulta, los documentos se dividen en chunks, se codifican en un índice de embeddings y se determinan los chunks más similares para cada embedding de consulta usando k-vecinos más cercanos (kNN). Como cada chunk corresponde a un documento, el ranking kNN de chunks se puede convertir en un ranking kNN de documentos (manteniendo solo la primera aparición de documentos que aparecen múltiples veces en el ranking). Este ranking resultante se compara luego con el ranking proporcionado por el archivo QRels de ground-truth, y se calculan métricas de recuperación como nDCG@10. Este procedimiento se ilustra a continuación, y el script de evaluación se puede encontrar en este repositorio para reproducibilidad.
 jina-ai
jina-aiEjecutamos esta evaluación en varios conjuntos de datos de BeIR, comparando el chunking ingenuo con nuestro método de chunking tardío. Para obtener las señales de límites, usamos una regex que divide los textos en cadenas de aproximadamente 256 tokens. Tanto la evaluación ingenua como la tardía utilizaron jina-embeddings-v2-small-en como modelo de embedding; una versión más pequeña del modelo v2-base-en que aún admite longitudes de hasta 8192 tokens. Los resultados se pueden encontrar en la tabla siguiente.
| Dataset | Avg. Document Length (characters) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) | No Chunking (nDCG@10) |
|---|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% | 63.89% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% | 65.18% |
| FiQA2018 | 767.2 | 33.25% | 33.84% | 33.43% |
| NFCorpus | 1589.8 | 23.46% | 29.98% | 30.40% |
| Quora | 62.2 | 87.19% | 87.19% | 87.19% |
En todos los casos, el chunking tardío mejoró las puntuaciones en comparación con el enfoque ingenuo. En algunos casos, también superó la codificación del documento completo en un solo embedding, mientras que en otros conjuntos de datos, no realizar chunking en absoluto produjo los mejores resultados (Por supuesto, no hacer chunking solo tiene sentido si no hay necesidad de clasificar chunks, lo cual es raro en la práctica). Si graficamos la brecha de rendimiento entre el enfoque ingenuo y el chunking tardío contra la longitud del documento, se hace evidente que la longitud promedio de los documentos se correlaciona con mayores mejoras en las puntuaciones nDCG a través del chunking tardío. En otras palabras, cuanto más largo es el documento, más efectiva se vuelve la estrategia de chunking tardío.

tagConclusión
En este artículo, presentamos un enfoque simple llamado "chunking tardío" para embeber chunks cortos aprovechando el poder de los modelos de embedding de contexto largo. Demostramos cómo el embedding de chunks i.i.d. tradicional falla en preservar la información contextual, llevando a una recuperación subóptima; y cómo el chunking tardío ofrece una solución simple pero altamente efectiva para mantener y condicionar la información contextual dentro de cada chunk. La efectividad del chunking tardío se vuelve cada vez más significativa en documentos más largos—una capacidad posible solo gracias a modelos avanzados de embedding de contexto largo como jina-embeddings-v2-base-en. Esperamos que este trabajo no solo valide la importancia de los modelos de embedding de contexto largo sino que también inspire más investigación sobre este tema.
Continúa leyendo la parte II: inmersión profunda en las señales de límites y conceptos erróneos.
