



Jina Embeddings y Jina Reranker están ahora disponibles para su uso con Amazon SageMaker desde el AWS Marketplace. Para los usuarios empresariales que valoran altamente la seguridad, fiabilidad y consistencia en sus operaciones en la nube, esto pone la IA de vanguardia de Jina AI en sus despliegues privados de AWS, donde disfrutan de todos los beneficios de la infraestructura establecida y estable de AWS.
Con nuestra gama completa de modelos de embeddings y reranking en AWS Marketplace, los usuarios de SageMaker pueden aprovechar las revolucionarias ventanas de contexto de entrada de 8k y los embeddings multilingües de primera categoría bajo demanda a precios competitivos. No tiene que pagar por transferir modelos hacia o desde AWS, los precios son transparentes y su facturación está integrada con su cuenta de AWS.
Los modelos disponibles actualmente en Amazon SageMaker incluyen:
- Jina Embeddings v2 Base - English
- Jina Embeddings v2 Small - English
- Modelos Bilingües Jina Embeddings v2:
- Jina Embeddings v2 Base - Code
- Jina Reranker v1 Base - English
- Jina ColBERT v1 - English
- Jina ColBERT Reranker v1 - English
Para ver la lista completa de modelos, visite la página de vendedor de Jina AI en AWS Marketplace, y aproveche una prueba gratuita de siete días.


Este artículo le guiará a través de la creación de una aplicación de Generación aumentada por recuperación (RAG) utilizando exclusivamente componentes de Amazon SageMaker. Los modelos que usaremos son Jina Embeddings v2 - English, Jina Reranker v1, y el modelo de lenguaje grande Mistral-7B-Instruct.
También puede seguir con un Notebook de Python, que puede descargar o ejecutar en Google Colab.
tagGeneración Aumentada por Recuperación
La generación aumentada por recuperación es un paradigma alternativo en IA generativa. En lugar de usar modelos de lenguaje grandes (LLMs) para responder directamente a las solicitudes de los usuarios con lo que ha aprendido en el entrenamiento, aprovecha su fluida producción de lenguaje mientras reubica la lógica y la recuperación de información en un aparato externo más adecuado para ello.
Antes de invocar un LLM, los sistemas RAG recuperan activamente información relevante de alguna fuente de datos externa y luego la alimentan al LLM como parte de su prompt. El papel del LLM es sintetizar la información externa en una respuesta coherente a las solicitudes del usuario, minimizando el riesgo de alucinación y aumentando la relevancia y utilidad del resultado.
Un sistema RAG esquemáticamente tiene al menos cuatro componentes:
- Una fuente de datos, típicamente una base de datos vectorial de algún tipo, adecuada para la recuperación de información asistida por IA.
- Un sistema de recuperación de información que trata la solicitud del usuario como una consulta y recupera datos relevantes para responderla.
- Un sistema, a menudo incluyendo un reranker basado en IA, que selecciona algunos de los datos recuperados y los procesa en un prompt para un LLM.
- Un LLM, por ejemplo, uno de los modelos GPT o un LLM de código abierto como el de Mistral, que toma la solicitud del usuario y los datos proporcionados y genera una respuesta para el usuario.
Los modelos de embedding son adecuados para la recuperación de información y se utilizan frecuentemente para ese propósito. Un modelo de embedding de texto toma textos como entradas y produce un embedding — un vector de alta dimensión — cuya relación espacial con otros embeddings indica su similitud semántica, es decir, temas similares, contenidos y significados relacionados. Se utilizan a menudo en la recuperación de información porque cuanto más cercanos están los embeddings, más probable es que el usuario esté satisfecho con la respuesta. También son relativamente fáciles de afinar para mejorar su rendimiento en dominios específicos.
Los modelos de reranking de texto utilizan principios de IA similares para comparar colecciones de textos con una consulta y ordenarlos por su similitud semántica. Usar un modelo de reranker específico para la tarea, en lugar de confiar solo en un modelo de embedding, a menudo aumenta dramáticamente la precisión de los resultados de búsqueda. El reranker en una aplicación RAG selecciona algunos de los resultados de la recuperación de información para maximizar la probabilidad de que la información correcta esté en el prompt para el LLM.

tagEvaluación del Rendimiento de los Modelos de Embedding como Endpoints de SageMaker
Probamos el rendimiento y la fiabilidad del modelo Jina Embeddings v2 Base - English como endpoint de SageMaker, ejecutándose en una instancia g4dn.xlarge. En estos experimentos, generamos continuamente un nuevo usuario cada segundo, cada uno de los cuales enviaba una solicitud, esperaba su respuesta y repetía al recibirla.
- Para solicitudes de menos de 100 tokens, para hasta 150 usuarios concurrentes, los tiempos de respuesta por solicitud se mantuvieron por debajo de 100ms. Luego, los tiempos de respuesta aumentaron linealmente de 100ms a 1500ms con la generación de más usuarios concurrentes.
- Con aproximadamente 300 usuarios concurrentes, recibimos más de 5 fallos de la API y terminamos la prueba.
- Para solicitudes entre 1K y 8K tokens, para hasta 20 usuarios concurrentes, los tiempos de respuesta por solicitud se mantuvieron por debajo de 8s. Luego, los tiempos de respuesta aumentaron linealmente de 8s a 60s con la generación de más usuarios concurrentes.
- Con aproximadamente 140 usuarios concurrentes, recibimos más de 5 fallos de la API y terminamos la prueba.
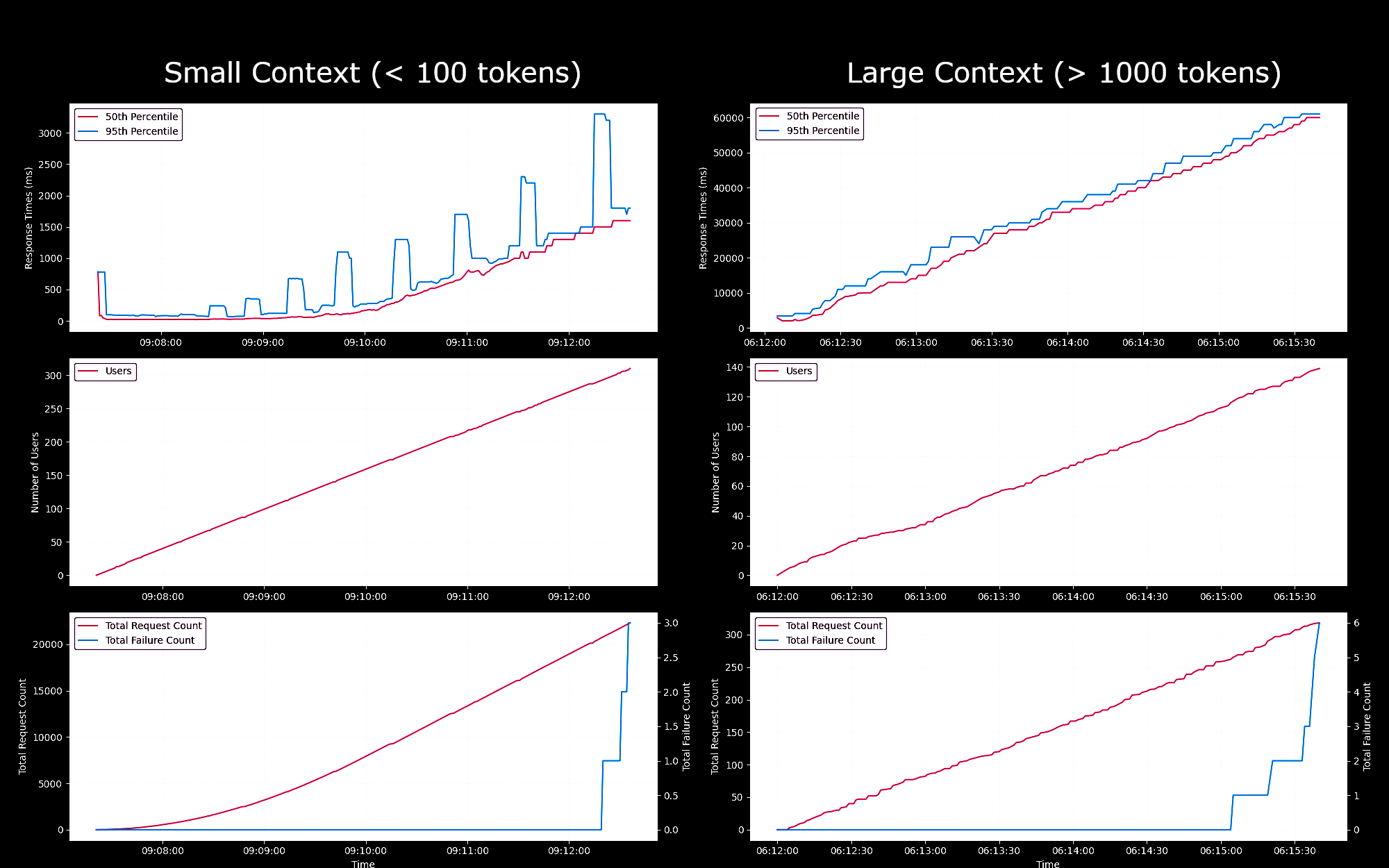
Basándonos en estos resultados, podemos concluir que para la mayoría de los usuarios con cargas de trabajo de embeddings normales, las instancias g4dn.xlarge o g5.xlarge deberían satisfacer sus necesidades diarias. Sin embargo, para trabajos de indexación grandes, que típicamente se ejecutan con mucha menos frecuencia que las tareas de búsqueda, los usuarios podrían preferir una opción más potente. Para una lista de todas las instancias Sagemaker disponibles, consulte la descripción general de EC2 de AWS.
tagConfigura tu cuenta de AWS
Primero, necesitarás tener una cuenta de AWS. Si aún no eres usuario de AWS, puedes registrarte para obtener una cuenta en el sitio web de AWS.

tagConfigura las herramientas de AWS en tu entorno Python
Instala en tu entorno Python las herramientas y bibliotecas de AWS necesarias para este tutorial:
pip install awscli jina-sagemaker
Necesitarás obtener una clave de acceso y una clave de acceso secreta para tu cuenta de AWS. Para hacerlo, sigue las instrucciones en el sitio web de AWS.


También necesitarás elegir una región de AWS para trabajar.
Luego, establece los valores en variables de entorno. En Python o en un notebook de Python, puedes hacerlo con el siguiente código:
import os
os.environ["AWS_ACCESS_KEY_ID"] = <YOUR_ACCESS_KEY_ID>
os.environ["AWS_SECRET_ACCESS_KEY"] = <YOUR_SECRET_ACCESS_KEY>
os.environ["AWS_DEFAULT_REGION"] = <YOUR_AWS_REGION>
os.environ["AWS_DEFAULT_OUTPUT"] = "json"
Establece la salida predeterminada como json.
También puedes hacer esto a través de la aplicación de línea de comandos de AWS o configurando un archivo de configuración de AWS en tu sistema de archivos local. Consulta la documentación en el sitio web de AWS para más detalles.
tagCrea un Rol
También necesitarás un rol de AWS con permisos suficientes para usar los recursos requeridos para este tutorial.
Este rol debe:
- Tener habilitado AmazonSageMakerFullAccess.
- Ya sea:
- Tener autoridad para hacer suscripciones en AWS Marketplace y tener habilitados los tres:
- aws-marketplace:ViewSubscriptions
- aws-marketplace:Unsubscribe
- aws-marketplace:Subscribe
- O tu cuenta de AWS debe tener una suscripción a jina-embedding-model.
- Tener autoridad para hacer suscripciones en AWS Marketplace y tener habilitados los tres:
Almacena el ARN (Amazon Resource Name) del rol en la variable role:
role = <YOUR_ROLE_ARN>
Consulta la documentación sobre roles en el sitio web de AWS para más información.
tagSuscríbete a los modelos de Jina AI en AWS Marketplace
En este artículo, usaremos el modelo Jina Embeddings v2 base English. Suscríbete a él en el AWS Marketplace.
Verás la información de precios desplazándote hacia abajo en la página. AWS cobra por hora por los modelos del marketplace, por lo que se te facturará por el tiempo desde que inicias el endpoint del modelo hasta que lo detienes. Este artículo te mostrará cómo hacer ambas cosas.
También usaremos el modelo Jina Reranker v1 - English, al que necesitarás suscribirte.
Cuando te hayas suscrito a ellos, obtén los ARN de los modelos para tu región de AWS y guárdalos en las variables embedding_package_arn y reranker_package_arn respectivamente. El código en este tutorial hará referencia a ellos usando esos nombres de variables.
Si no sabes cómo obtener los ARN, coloca el nombre de tu región de Amazon en la variable region y usa el siguiente código:
region = os.environ["AWS_DEFAULT_REGION"]
def get_arn_for_model(region_name, model_name):
model_package_map = {
"us-east-1": f"arn:aws:sagemaker:us-east-1:253352124568:model-package/{model_name}",
"us-east-2": f"arn:aws:sagemaker:us-east-2:057799348421:model-package/{model_name}",
"us-west-1": f"arn:aws:sagemaker:us-west-1:382657785993:model-package/{model_name}",
"us-west-2": f"arn:aws:sagemaker:us-west-2:594846645681:model-package/{model_name}",
"ca-central-1": f"arn:aws:sagemaker:ca-central-1:470592106596:model-package/{model_name}",
"eu-central-1": f"arn:aws:sagemaker:eu-central-1:446921602837:model-package/{model_name}",
"eu-west-1": f"arn:aws:sagemaker:eu-west-1:985815980388:model-package/{model_name}",
"eu-west-2": f"arn:aws:sagemaker:eu-west-2:856760150666:model-package/{model_name}",
"eu-west-3": f"arn:aws:sagemaker:eu-west-3:843114510376:model-package/{model_name}",
"eu-north-1": f"arn:aws:sagemaker:eu-north-1:136758871317:model-package/{model_name}",
"ap-southeast-1": f"arn:aws:sagemaker:ap-southeast-1:192199979996:model-package/{model_name}",
"ap-southeast-2": f"arn:aws:sagemaker:ap-southeast-2:666831318237:model-package/{model_name}",
"ap-northeast-2": f"arn:aws:sagemaker:ap-northeast-2:745090734665:model-package/{model_name}",
"ap-northeast-1": f"arn:aws:sagemaker:ap-northeast-1:977537786026:model-package/{model_name}",
"ap-south-1": f"arn:aws:sagemaker:ap-south-1:077584701553:model-package/{model_name}",
"sa-east-1": f"arn:aws:sagemaker:sa-east-1:270155090741:model-package/{model_name}",
}
return model_package_map[region_name]
embedding_package_arn = get_arn_for_model(region, "jina-embeddings-v2-base-en")
reranker_package_arn = get_arn_for_model(region, "jina-reranker-v1-base-en")
tagCargar el Dataset
En este tutorial, vamos a utilizar una colección de videos proporcionados por el canal de YouTube TU Delft Online Learning. Este canal produce una variedad de materiales educativos en materias STEM. Su programación está bajo licencia CC-BY.


Descargamos 193 videos del canal y los procesamos con el modelo de reconocimiento de voz Whisper de OpenAI de código abierto. Utilizamos el modelo más pequeño openai/whisper-tiny para procesar los videos en transcripciones.
Las transcripciones se han organizado en un archivo CSV, que puedes descargar desde aquí.
Cada fila del archivo contiene:
- El título del video
- La URL del video en YouTube
- Una transcripción del texto del video
Para cargar estos datos en Python, primero instala pandas y requests:
pip install requests pandas
Carga los datos CSV directamente en un DataFrame de Pandas llamado tu_delft_dataframe:
import pandas
# Load the CSV file
tu_delft_dataframe = pandas.read_csv("https://raw.githubusercontent.com/jina-ai/workshops/feat-sagemaker-post/notebooks/embeddings/sagemaker/tu_delft.csv")
Puedes inspeccionar el contenido usando el método head() del DataFrame. En un notebook, debería verse algo así:
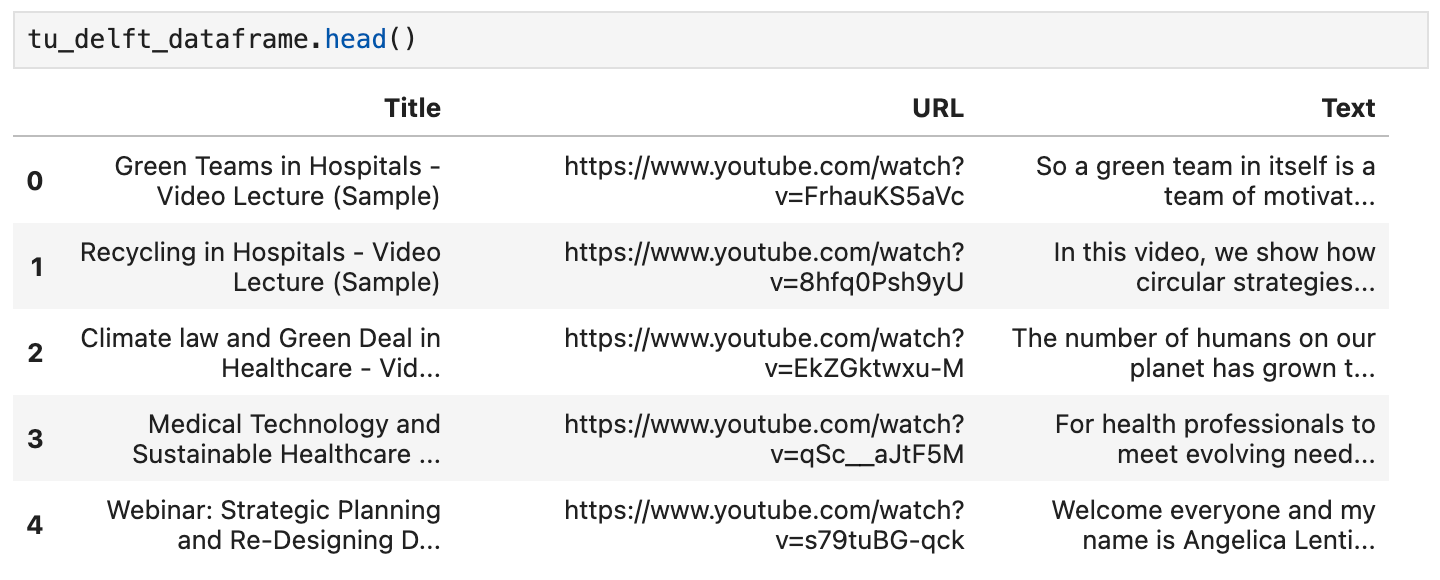
También puedes ver los videos usando las URLs proporcionadas en este dataset y verificar que el reconocimiento de voz es imperfecto pero básicamente correcto.
tagIniciar el Endpoint de Jina Embeddings v2
El código siguiente lanzará una instancia de ml.g4dn.xlarge en AWS para ejecutar el modelo de embedding. Esto puede tardar varios minutos en completarse.
import boto3
from jina_sagemaker import Client
# Choose a name for your embedding endpoint. It can be anything convenient.
embeddings_endpoint_name = "jina_embedding"
embedding_client = Client(region_name=boto3.Session().region_name)
embedding_client.create_endpoint(
arn=embedding_package_arn,
role=role,
endpoint_name=embeddings_endpoint_name,
instance_type="ml.g4dn.xlarge",
n_instances=1,
)
embedding_client.connect_to_endpoint(endpoint_name=embeddings_endpoint_name)
Cambia el instance_type para seleccionar un tipo diferente de instancia en la nube de AWS si es apropiado.
tagConstruir e Indexar el Dataset
Ahora que hemos cargado los datos y estamos ejecutando un modelo Jina Embeddings v2, podemos preparar e indexar los datos. Almacenaremos los datos en un almacén de vectores FAISS, una base de datos de vectores de código abierto diseñada específicamente para aplicaciones de IA.
Primero, instala los requisitos restantes para nuestra aplicación RAG:
pip install tdqm numpy faiss-cpu
tagFragmentación
Necesitaremos tomar las transcripciones individuales y dividirlas en partes más pequeñas, es decir, "fragmentos", para que podamos ajustar múltiples textos en un prompt para el LLM. El código siguiente divide las transcripciones individuales en los límites de las oraciones, asegurando que todos los fragmentos no tengan más de 128 palabras por defecto.
def chunk_text(text, max_words=128):
"""
Divide text into chunks where each chunk contains the maximum number
of full sentences with fewer words than `max_words`.
"""
sentences = text.split(".")
chunk = []
word_count = 0
for sentence in sentences:
sentence = sentence.strip(".")
if not sentence:
continue
words_in_sentence = len(sentence.split())
if word_count + words_in_sentence <= max_words:
chunk.append(sentence)
word_count += words_in_sentence
else:
# Yield the current chunk and start a new one
if chunk:
yield ". ".join(chunk).strip() + "."
chunk = [sentence]
word_count = words_in_sentence
# Yield the last chunk if it's not empty
if chunk:
yield " ".join(chunk).strip() + "."tagObtener Embeddings para Cada Fragmento
Necesitamos un embedding para cada fragmento para almacenarlo en la base de datos FAISS. Para obtenerlos, pasamos los fragmentos de texto al endpoint del modelo de embedding de Jina AI, usando el método embedding_client.embed(). Luego, agregamos los fragmentos de texto y los vectores de embedding al dataframe de pandas tu_delft_dataframe como las nuevas columnas chunks y embeddings:
import numpy as np
from tqdm import tqdm
tqdm.pandas()
def generate_embeddings(text_df):
chunks = list(chunk_text(text_df["Text"]))
embeddings = []
for i, chunk in enumerate(chunks):
response = embedding_client.embed(texts=[chunk])
chunk_embedding = response[0]["embedding"]
embeddings.append(np.array(chunk_embedding))
text_df["chunks"] = chunks
text_df["embeddings"] = embeddings
return text_df
print("Embedding text chunks ...")
tu_delft_dataframe = generate_embeddings(tu_delft_dataframe)
## si estás usando Google Colab o un notebook de Python, puedes
## eliminar la línea anterior y descomentar la siguiente línea:
# tu_delft_dataframe = tu_delft_dataframe.progress_apply(generate_embeddings, axis=1)
tagConfigurar Búsqueda Semántica Usando Faiss
El código siguiente crea una base de datos FAISS e inserta los fragmentos y vectores de embedding iterando sobre tu_delft_pandas:
import faiss
dim = 768 # dimensión de los embeddings de Jina v2
index_with_ids = faiss.IndexIDMap(faiss.IndexFlatIP(dim))
k = 0
doc_ref = dict()
for idx, row in tu_delft_dataframe.iterrows():
embeddings = row["embeddings"]
for i, embedding in enumerate(embeddings):
normalized_embedding = np.ascontiguousarray(np.array(embedding, dtype="float32").reshape(1, -1))
faiss.normalize_L2(normalized_embedding)
index_with_ids.add_with_ids(normalized_embedding, k)
doc_ref[k] = (row["chunks"][i], idx)
k += 1
tagIniciar el Endpoint de Jina Reranker v1
Al igual que con el modelo Jina Embedding v2 anterior, este código lanzará una instancia de ml.g4dn.xlarge en AWS para ejecutar el modelo reranker. De manera similar, puede tardar varios minutos en ejecutarse.
import boto3
from jina_sagemaker import Client
# Elige un nombre para tu endpoint reranker. Puede ser cualquier nombre conveniente.
reranker_endpoint_name = "jina_reranker"
reranker_client = Client(region_name=boto3.Session().region_name)
reranker_client.create_endpoint(
arn=reranker_package_arn,
role=role,
endpoint_name=reranker_endpoint_name,
instance_type="ml.g4dn.xlarge",
n_instances=1,
)
reranker_client.connect_to_endpoint(endpoint_name=reranker_endpoint_name)
tagDefinir Funciones de Consulta
A continuación, definiremos una función que identifica los fragmentos de transcripción más similares a cualquier consulta de texto.
Este es un proceso de dos pasos:
- Convertir la entrada del usuario en un vector de embedding usando el método
embedding_client.embed(), igual que hicimos en la etapa de preparación de datos. - Pasar el embedding al índice FAISS para recuperar las mejores coincidencias. En la función siguiente, el valor predeterminado es devolver las 20 mejores coincidencias, pero puedes controlarlo con el parámetro
n.
La función find_most_similar_transcript_segment devolverá las mejores coincidencias comparando los cosenos de los embeddings almacenados con el embedding de la consulta.
def find_most_similar_transcript_segment(query, n=20):
query_embedding = embedding_client.embed(texts=[query])[0]["embedding"] # Asumiendo que la consulta es lo suficientemente corta para no necesitar fragmentación
query_embedding = np.ascontiguousarray(np.array(query_embedding, dtype="float32").reshape(1, -1))
faiss.normalize_L2(query_embedding)
D, I = index_with_ids.search(query_embedding, n) # Obtener las n mejores coincidencias
results = []
for i in range(n):
distance = D[0][i]
index_id = I[0][i]
transcript_segment, doc_idx = doc_ref[index_id]
results.append((transcript_segment, doc_idx, distance))
# Ordenar los resultados por distancia
results.sort(key=lambda x: x[2])
return [(tu_delft_dataframe.iloc[r[1]]["Title"].strip(), r[0]) for r in results]
También definiremos una función que accede al endpoint reranker reranker_client, le pasa los resultados de find_most_similar_transcript_segment y devuelve solo los tres resultados más relevantes. Llama al endpoint reranker con el método reranker_client.rerank().
def rerank_results(query_found, query, n=3):
ret = reranker_client.rerank(
documents=[f[1] for f in query_found],
query=query,
top_n=n,
)
return [query_found[r['index']] for r in ret[0]['results']]
tagUsar JumpStart para Cargar Mistral-Instruct
Para este tutorial, usaremos el modelo mistral-7b-instruct, que está disponible a través de Amazon SageMaker JumpStart, como la parte LLM del sistema RAG.

Ejecuta el siguiente código para cargar e implementar Mistral-Instruct:
from sagemaker.jumpstart.model import JumpStartModel
jumpstart_model = JumpStartModel(model_id="huggingface-llm-mistral-7b-instruct", role=role)
model_predictor = jumpstart_model.deploy()
El endpoint para acceder a este LLM se almacena en la variable model_predictor.
tagMistral-Instruct con JumpStart
A continuación se muestra el código para crear una plantilla de prompt para Mistral-Instruct para esta aplicación usando la clase template de cadenas incorporada de Python. Asume que para cada consulta hay tres fragmentos de transcripción coincidentes que se presentarán al modelo.
Puedes experimentar con esta plantilla por tu cuenta para modificar esta aplicación o ver si puedes obtener mejores resultados.
from string import Template
prompt_template = Template("""
<s>[INST] Responde la pregunta siguiente usando solo el contexto proporcionado.
La pregunta del usuario está basada en transcripciones de videos de un canal
de YouTube.
El contexto se presenta como una lista ordenada de información en forma de
(título-del-video, segmento-de-transcripción), que es relevante para responder
la pregunta del usuario.
La respuesta debe usar solo el contexto presentado. Si la pregunta no puede
responderse basándose en el contexto, dilo.
Contexto:
1. Título-del-video: $title_1, segmento-de-transcripción: $segment_1
2. Título-del-video: $title_2, segmento-de-transcripción: $segment_2
3. Título-del-video: $title_3, segmento-de-transcripción: $segment_3
Pregunta: $question
Respuesta: [/INST]
""")
Con este componente en su lugar, ahora tenemos todas las partes de una aplicación RAG completa.
tagConsultando el Modelo
Consultar el modelo es un proceso de tres pasos.
- Buscar fragmentos relevantes dada una consulta.
- Ensamblar el prompt.
- Enviar el prompt al modelo Mistral-Instruct y devolver su respuesta.
Para buscar fragmentos relevantes, usamos la función find_most_similar_transcript_segment que definimos anteriormente.
question = "¿Cuándo se puso en servicio el primer parque eólico marino?"
search_results = find_most_similar_transcript_segment(question)
reranked_results = rerank_results(search_results, question)
Puedes inspeccionar los resultados de búsqueda en orden reordenado:
for title, text, _ in reranked_results:
print(title + "\n" + text + "\n")
Resultado:
Offshore Wind Farm Technology - Course Introduction
Since the first offshore wind farm commissioned in 1991 in Denmark, scientists and engineers have adapted and improved the technology of wind energy to offshore conditions. This is a rapidly evolving field with installation of increasingly larger wind turbines in deeper waters. At sea, the challenges are indeed numerous, with combined wind and wave loads, reduced accessibility and uncertain-solid conditions. My name is Axel Vire, I'm an assistant professor in Wind Energy at U-Delf and specializing in offshore wind energy. This course will touch upon the critical aspect of wind energy, how to integrate the various engineering disciplines involved in offshore wind energy. Each week we will focus on a particular discipline and use it to design and operate a wind farm.
Offshore Wind Farm Technology - Course Introduction
I'm a researcher and lecturer at the Wind Energy and Economics Department and I will be your moderator throughout this course. That means I will answer any questions you may have. I'll strengthen the interactions between the participants and also I'll get you in touch with the lecturers when needed. The course is mainly developed for professionals in the field of offshore wind energy. We want to broaden their knowledge of the relevant technical disciplines and their integration. Professionals with a scientific background who are new to the field of offshore wind energy will benefit from a high-level insight into the engineering aspects of wind energy. Overall, the course will help you make the right choices during the development and operation of offshore wind farms.
Offshore Wind Farm Technology - Course Introduction
Designed wind turbines that better withstand wind, wave and current loads Identify great integration strategies for offshore wind turbines and gain understanding of the operational and maintenance of offshore wind turbines and farms We also hope that you will benefit from the course and from interaction with other learners who share your interest in wind energy And therefore we look forward to meeting you online.
Podemos usar esta información directamente en la plantilla del prompt:
prompt_for_llm = prompt_template.substitute(
question = question,
title_1 = search_results[0][0],
segment_1 = search_results[0][1],
title_2 = search_results[1][0],
segment_2 = search_results[1][1],
title_3 = search_results[2][0],
segment_3 = search_results[2][1],
)
Imprime la cadena resultante para ver qué prompt se envía realmente al LLM:
print(prompt_for_llm)
<s>[INST] Answer the question below only using the given context.
The question from the user is based on transcripts of videos from a YouTube
channel.
The context is presented as a ranked list of information in the form of
(video-title, transcript-segment), that is relevant for answering the
user's question.
The answer should only use the presented context. If the question cannot be
answered based on the context, say so.
Context:
1. Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: Since the first offshore wind farm commissioned in 1991 in Denmark, scientists and engineers have adapted and improved the technology of wind energy to offshore conditions. This is a rapidly evolving field with installation of increasingly larger wind turbines in deeper waters. At sea, the challenges are indeed numerous, with combined wind and wave loads, reduced accessibility and uncertain-solid conditions. My name is Axel Vire, I'm an assistant professor in Wind Energy at U-Delf and specializing in offshore wind energy. This course will touch upon the critical aspect of wind energy, how to integrate the various engineering disciplines involved in offshore wind energy. Each week we will focus on a particular discipline and use it to design and operate a wind farm.
2. Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: For example, we look at how to characterize the wind and wave conditions at a given location. How to best place the wind turbines in a farm and also how to retrieve the electricity back to shore. We look at the main design drivers for offshore wind turbines and their components. We'll see how these aspects influence one another and the best choices to reduce the cost of energy. This course is organized by the two-delfd wind energy institute, an interfaculty research organization focusing specifically on wind energy. You will therefore benefit from the expertise of the lecturers in three different faculties of the university. Aerospace engineering, civil engineering and electrical engineering. Hi, my name is Ricardo Pareda.
3. Video-title: Systems Analysis for Problem Structuring part 1B the mono actor perspective example, transcript-segment: So let's assume the demarcation of the problem and the analysis of objectives has led to the identification of three criteria. The security of supply, the percentage of offshore power generation and the costs of energy provision. We now reason backwards to explore what factors have an influence on these system outcomes. Really, the offshore percentage is positively influenced by the installed Wind Power capacity at sea, a key system factor. Capacity at sea in turn is determined by both the size and the number of wind farms at sea. The Ministry of Economic Affairs cannot itself invest in new wind farms but hopes to simulate investors and energy companies by providing subsidies and by expediting the granting process of licenses as needed.
Question: When was the first offshore wind farm commissioned?
Answer: [/INST]
Pasa este prompt al endpoint del LLM — model_predictor — a través del método model_predictor.predict():
answer = model_predictor.predict({"inputs": prompt_for_llm})
Esto devuelve una lista, pero como solo pasamos un prompt, será una lista con una entrada. Cada entrada es un dict con el texto de respuesta bajo la clave generated_text:
answer = answer[0]['generated_text']
print(answer)
Resultado:
The first offshore wind farm was commissioned in 1991. (Context: Video-title: Offshore Wind Farm Technology - Course Introduction, transcript-segment: Since the first offshore wind farm commissioned in 1991 in Denmark, ...)
Vamos a simplificar las consultas escribiendo una función que haga todos los pasos: tomando la pregunta como cadena de texto como parámetro y devolviendo la respuesta como cadena:
def ask_rag(question):
search_results = find_most_similar_transcript_segment(question)
reranked_results = rerank_results(search_results, question)
prompt_for_llm = prompt_template.substitute(
question = question,
title_1 = search_results[0][0],
segment_1 = search_results[0][1],
title_2 = search_results[1][0],
segment_2 = search_results[1][1],
title_3 = search_results[2][0],
segment_3 = search_results[2][1],
)
answer = model_predictor.predict({"inputs": prompt_for_llm})
return answer[0]["generated_text"]
Ahora podemos hacer algunas preguntas más. Las respuestas dependerán del contenido de las transcripciones de video. Por ejemplo, podemos hacer preguntas detalladas cuando la respuesta está presente en los datos y obtener una respuesta:
ask_rag("What is a Kaplan Meyer estimator?")
The Kaplan Meyer estimator is a non-parametric estimator for the survival
function, defined for both censored and not censored data. It is represented
as a series of declining horizontal steps that approaches the truths of the
survival function if the sample size is sufficiently large enough. The value
of the empirical survival function obtained is assumed to be constant between
two successive distinct observations.
ask_rag("Who is Reneville Solingen?")
Reneville Solingen is a professor at Delft University of Technology in Global
Software Engineering. She is also a co-author of the book "The Power of Scrum."
answer = ask_rag("What is the European Green Deal?")
print(answer)
The European Green Deal is a policy initiative by the European Union to combat
climate change and decarbonize the economy, with a goal to make Europe carbon
neutral by 2050. It involves the use of green procurement strategies in various
sectors, including healthcare, to reduce carbon emissions and promote corporate
social responsibility.
También podemos hacer preguntas que están fuera del alcance de la información disponible:
ask_rag("What countries export the most coffee?")
Based on the context provided, there is no clear answer to the user's
question about which countries export the most coffee as the context
only discusses the Delft University's cafeteria discounts and sustainable
coffee options, as well as lithium production and alternatives for use in
electric car batteries.
ask_rag("How much wood could a woodchuck chuck if a woodchuck could chuck wood?")
The context does not provide sufficient information to answer the question.
The context is about thermit welding of rails, stress concentration factors,
and a lyrics video. There is no mention of woodchucks or the ability of
woodchuck to chuck wood in the context.
Prueba tus propias consultas. También puedes cambiar la forma en que se hace el prompt al LLM para ver si eso mejora tus resultados.
tagApagado
Debido a que se te factura por hora por los modelos que usas y por la infraestructura de AWS para ejecutarlos, es muy importante detener los tres modelos de IA cuando termines este tutorial:
- El endpoint del modelo de embedding
embedding_client - El endpoint del modelo de reranking
reranker_client - El endpoint del modelo de lenguaje grande
model_predictor
Para apagar los tres endpoints de modelos, ejecuta el siguiente código:
# shut down the embedding endpoint
embedding_client.delete_endpoint()
embedding_client.close()
# shut down the reranker endpoint
reranker_client.delete_endpoint()
reranker_client.close()
# shut down the LLM endpoint
model_predictor.delete_model()
model_predictor.delete_endpoint()
tagEmpieza ahora con los modelos de Jina AI en AWS Marketplace
Con nuestros modelos de embedding y reranking en SageMaker, los usuarios empresariales de IA en AWS ahora tienen acceso instantáneo a la excepcional propuesta de valor de Jina AI sin comprometer los beneficios de sus operaciones en la nube existentes. Toda la seguridad, confiabilidad, consistencia y precios predecibles de AWS vienen incluidos.
En Jina AI, trabajamos arduamente para llevar el estado del arte a las empresas que pueden beneficiarse de incorporar IA en sus procesos existentes. Nos esforzamos por ofrecer modelos sólidos, confiables y de alto rendimiento a precios accesibles a través de interfaces convenientes y prácticas, minimizando sus inversiones en IA mientras maximiza sus retornos.
Visita la página de Jina AI en AWS Marketplace para ver una lista de todos los modelos de embeddings y reranking que ofrecemos y para probar nuestros modelos gratis durante siete días.
Nos encantaría conocer sus casos de uso y hablar sobre cómo los productos de Jina AI pueden adaptarse a las necesidades de su negocio. Contáctenos a través de nuestro sitio web o nuestro canal de Discord para compartir sus comentarios y mantenerse al día con nuestros últimos modelos.
