

Con el reciente lanzamiento de jina-reranker-v2-multilingual, tuve algo de tiempo libre antes de mi viaje a ICML, así que decidí escribir un artículo sobre nuestro modelo reranker. Mientras buscaba ideas en internet, encontré un artículo que apareció en mis principales resultados de búsqueda, afirmando que los rerankers pueden mejorar el SEO. Suena super interesante, ¿verdad? Yo también lo pensé porque en Jina AI hacemos rerankers, y como webmaster del sitio web de nuestra empresa, siempre estoy interesado en mejorar nuestro SEO.
Sin embargo, después de leer el artículo completo, descubrí que fue completamente generado por ChatGPT. El artículo entero simplemente parafrasea repetidamente la idea de que "el Reranking es importante para tu negocio/sitio web" sin explicar nunca cómo, cuál es la matemática detrás, o cómo implementarlo. Fue una pérdida de tiempo.
No puedes casar Reranker y SEO. El desarrollador del sistema de búsqueda (o generalmente el consumidor de contenido) se preocupa por los rerankers, mientras que el creador de contenido se preocupa por el SEO y si su contenido se posiciona más alto en ese sistema. Básicamente se sientan en lados opuestos de la mesa y raramente intercambian ideas. Pedirle a un reranker que mejore el SEO es como pedirle a un herrero que mejore tu hechizo de bola de fuego o pedir sushi en un restaurante chino. No son completamente irrelevantes, pero es un objetivo obviamente equivocado.
Imagina si Google me invitara a su oficina para preguntarme mi opinión sobre si su reranker posiciona lo suficientemente alto a jina.ai. O si yo tuviera control total sobre el algoritmo de reranking de Google y codificara jina.ai para que apareciera en la parte superior cada vez que alguien busca "information retrieval". Ningún escenario tiene sentido. Entonces, ¿por qué tenemos estos artículos en primer lugar? Bueno, si le preguntas a ChatGPT, se vuelve muy obvio de dónde vino originalmente esta idea.

tagMotivación
Si ese artículo generado por IA se posiciona en la parte superior de Google, me gustaría escribir un artículo mejor y de mayor calidad para tomar su lugar. No quiero engañar ni a humanos ni a ChatGPT, así que mi punto en este artículo es muy claro:
Específicamente, en este artículo, analizaremos consultas de búsqueda reales exportadas de Google Search Console y veremos si su relación semántica con el artículo sugiere algo sobre sus impresiones y clics en Google Search. Examinaremos tres formas diferentes de puntuar la relación semántica: frecuencia de términos, modelo de embedding (jina-embeddings-v2-base-en), y modelo reranker (jina-reranker-v2-multilingual). Como cualquier investigación académica, definamos primero las preguntas que queremos estudiar:
- ¿Está la puntuación semántica (consulta, documento) relacionada con las impresiones o clics del artículo?
- ¿Es un modelo más profundo un mejor predictor de tal relación? ¿O es suficiente la frecuencia de términos?
tagConfiguración Experimental
En este experimento, usamos datos reales del sitio web jina.ai/news exportados de Google Search Console (GSC). GSC es una herramienta para webmasters que te permite analizar el tráfico de búsqueda orgánica de los usuarios de Google, como cuántas personas abren tu publicación de blog a través de Google Search y cuáles son las consultas de búsqueda. Hay muchas métricas que puedes extraer de GSC, pero para este experimento, nos enfocamos en tres: consultas, impresiones y clics. Las consultas son lo que los usuarios ingresan en el cuadro de búsqueda de Google. Las impresiones miden cuántas veces Google muestra tu enlace en los resultados de búsqueda, dando a los usuarios la oportunidad de verlo. Los clics miden cuántas veces los usuarios realmente lo abren. Ten en cuenta que podrías obtener muchas impresiones si el "modelo de recuperación" de Google asigna a tu artículo una puntuación de relevancia alta en relación con la consulta del usuario. Sin embargo, si los usuarios encuentran otros elementos en esa lista de resultados más interesantes, tu página aún podría obtener cero clics.
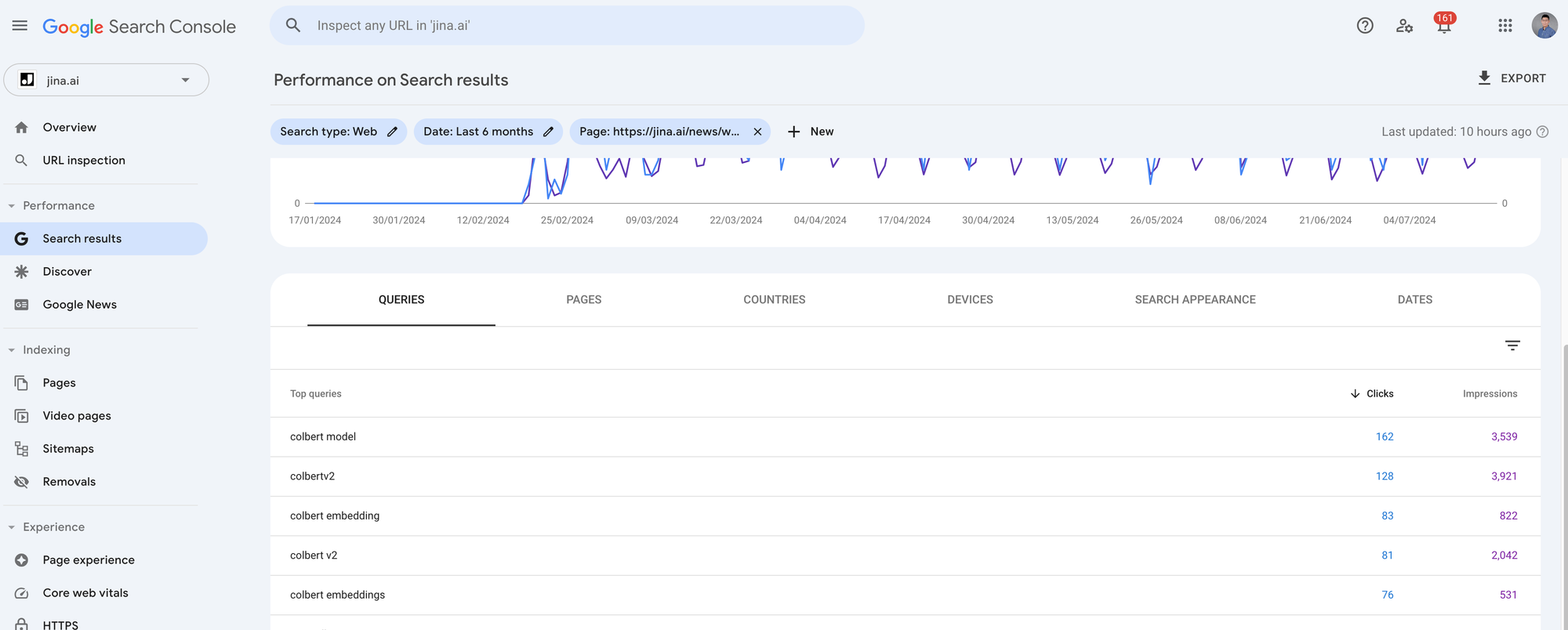
Exporté los últimos 4 meses de métricas de GSC para los 7 posts de blog más buscados de jina.ai/news. Cada artículo tiene alrededor de 1,000 a 5,000 clics y 10,000 a 90,000 impresiones. Como queremos analizar la semántica consulta-artículo para cada búsqueda en relación con sus artículos correspondientes, necesitas hacer clic en cada artículo en GSC y exportar los datos haciendo clic en el botón Exportar en la parte superior derecha. Te dará un archivo zip, y cuando lo descomprimas, encontrarás un archivo Queries.csv. Este es el archivo que necesitamos.
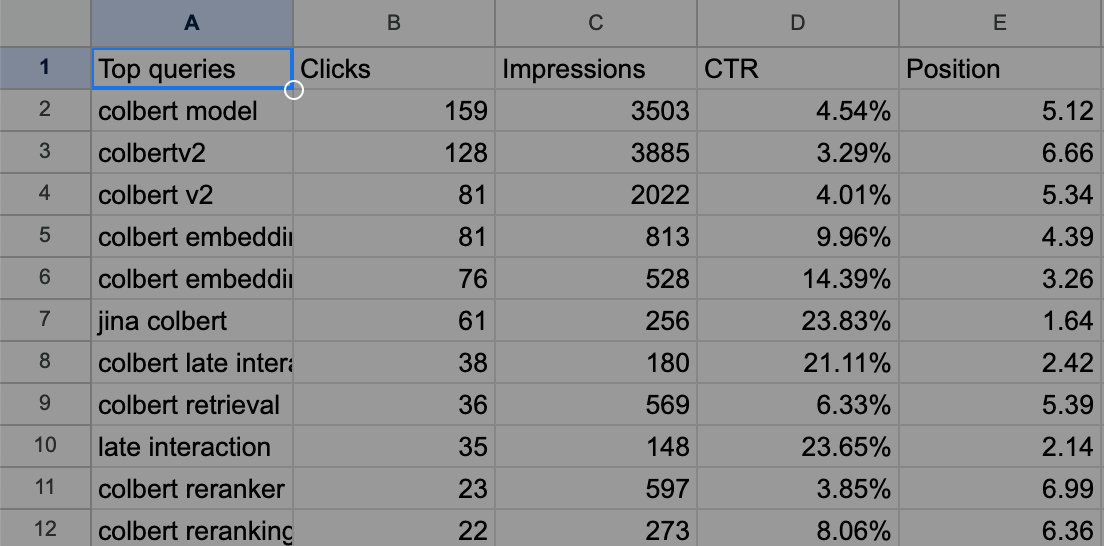
Como ejemplo, el Queries.csv exportado se ve así para nuestro post sobre ColBERT.
tagMetodología
Bien, entonces los datos están listos, ¿y qué queremos hacer de nuevo?
Queremos verificar si la relación semántica entre una consulta y el artículo (denotada como ) se correlaciona con sus impresiones y clics. Las impresiones pueden considerarse como el modelo secreto de recuperación de Google, . En otras palabras, queremos usar métodos públicos como frecuencia de términos, modelos de embedding y modelos reranker para modelar y ver si se aproxima a este privado.
¿Qué hay de los clics? Los clics también pueden considerarse como parte del modelo secreto de recuperación de Google, pero están influenciados por factores humanos indeterministas. Intuitivamente, los clics son más difíciles de modelar.
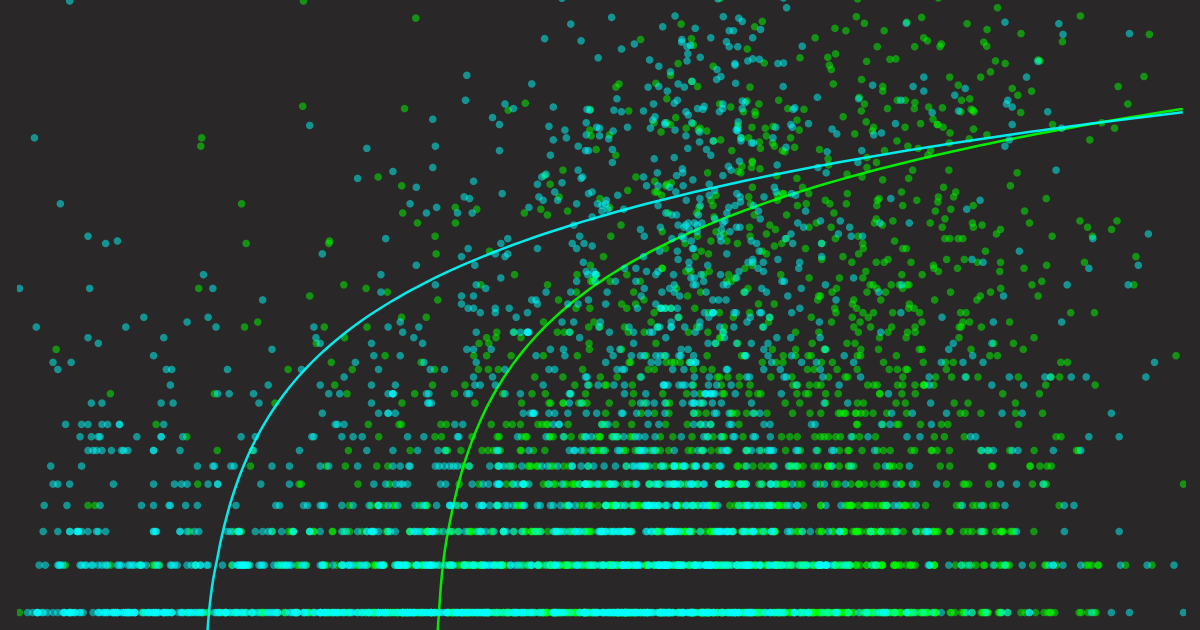
De cualquier manera, alinear con es nuestro objetivo. Esto significa que nuestro debería puntuar alto cuando es alto y bajo cuando es bajo. Esto se puede visualizar mejor con un gráfico de dispersión, colocando en el eje X y en el eje Y. Al graficar los valores y de cada consulta, podemos ver intuitivamente qué tan bien nuestro modelo de recuperación se alinea con el modelo de recuperación de Google. Superponer una línea de tendencia puede ayudar a revelar patrones confiables.
Entonces, permítanme resumir el método aquí antes de mostrar los resultados:
- Queremos verificar si la relación semántica entre una consulta y un artículo se correlaciona con las impresiones y clics en Google Search.
- El algoritmo que Google usa para determinar la relevancia de un documento para una consulta es desconocido (), al igual que los factores detrás de los clics. Sin embargo, podemos observar estos números desde GSC, es decir, las impresiones y clics para cada consulta.
- Nuestro objetivo es ver si los métodos públicos de recuperación () como la frecuencia de términos, los modelos de embeddings y los modelos de re-ranking, que proporcionan formas únicas de puntuar la relevancia consulta-documento, son buenas aproximaciones de . De alguna manera, ya sabemos que no son buenas aproximaciones; de lo contrario, todos podrían ser Google. Pero queremos entender qué tan lejos están.
- Visualizaremos los resultados en un gráfico de dispersión para un análisis cualitativo.
tagImplementación
La implementación completa se puede encontrar en el Google Colab a continuación.


Primero extraemos el contenido del post del blog usando la API de Jina Reader. La frecuencia de términos de las consultas se determina mediante un conteo básico sin distinción entre mayúsculas y minúsculas. Para el modelo de embeddings, empaquetamos el contenido del blog y todas las consultas de búsqueda en una gran solicitud, así: [[blog1_content], [q1], [q2], [q3], ..., [q481]], y la enviamos a la API de Embeddings. Después de recibir la respuesta, calculamos la similitud basada en coseno entre el primer embedding y todos los demás embeddings para obtener la puntuación semántica por consulta.
Para el modelo de re-ranking, construimos la solicitud de una manera ligeramente compleja: {query: [blog1_content], documents: [[q1], [q2], [q3], ..., [q481]]} y enviamos esta gran solicitud a la API de Reranker. La puntuación devuelta puede usarse directamente como relevancia semántica. Llamo a esta construcción compleja porque, normalmente, los re-rankers se usan para clasificar documentos dada una consulta. En este caso, invertimos los roles de documento y consulta y usamos el re-ranker para clasificar consultas dado un documento.
Ten en cuenta que tanto en la API de Embeddings como en la de Reranker, no tienes que preocuparte por la longitud del artículo (las consultas siempre son cortas, así que no hay problema) porque ambas APIs admiten hasta 8K de longitud de entrada (de hecho, nuestra API de Reranker admite longitud "infinita"). Todo se puede hacer rápidamente en solo unos segundos, y puedes obtener una clave de API gratuita de 1M de tokens desde nuestro sitio web para este experimento.
tagResultados
Finalmente, los resultados. Pero antes de mostrarlos, me gustaría primero demostrar cómo se ven los gráficos de referencia. Debido al gráfico de dispersión y la escala logarítmica en el eje Y que vamos a usar, puede ser difícil imaginar cómo se verían un perfectamente bueno y uno terriblemente malo. Construí dos referencias ingenuas: una donde es (verdad fundamental), y otra donde (aleatorio). Veamos sus visualizaciones.
tagReferencias


Ahora tenemos una intuición de cómo se ven los predictores "perfectamente buenos" y "terriblemente malos". Ten en mente estos dos gráficos junto con las siguientes conclusiones que pueden ser bastante útiles para la inspección visual:
- El gráfico de dispersión de un buen predictor debe seguir la línea de tendencia logarítmica desde la parte inferior izquierda hasta la superior derecha.
- La línea de tendencia de un buen predictor debe abarcar completamente el eje X y el eje Y (veremos más adelante que algunos predictores no responden de esta manera).
- El área de varianza de un buen predictor debe ser pequeña (representada como un área opaca alrededor de la línea de tendencia).
A continuación, mostraré todos los gráficos juntos, cada predictor con dos gráficos: uno que muestra qué tan bien predice las impresiones y otro que muestra qué tan bien predice los clics. Ten en cuenta que agregué datos de los 7 posts del blog, así que en total hay 3620 consultas, es decir, 3620 puntos de datos en cada gráfico de dispersión.
Por favor, tómate unos minutos para desplazarte arriba y abajo y examinar estos gráficos, compararlos y prestar atención a los detalles. Déjalo que se asiente, y en la siguiente sección, concluiré los hallazgos.
tagFrecuencia de Términos como Predictor


tagModelo de Embeddings como Predictor


tagModelo de Reranker como Predictor


tagHallazgos
Pongamos todos los gráficos en un solo lugar para facilitar la comparación. Aquí hay algunas observaciones y explicaciones:



Diferentes predictores sobre las impresiones. Cada punto representa una consulta, el eje X representa la puntuación semántica consulta-artículo; el eje Y es el número de impresiones exportado desde GSC.



Diferentes predictores de clics. Cada punto representa una consulta, el eje X representa la puntuación semántica consulta-artículo; el eje Y es el número de clics exportado desde GSC.
- En general, todos los gráficos de dispersión de clics son más dispersos que sus gráficos de impresiones, aunque ambos se basan en los mismos datos. Esto se debe a que, como se mencionó anteriormente, un alto número de impresiones no garantiza ningún clic.
- Los gráficos de frecuencia de términos son más dispersos que los demás. Esto se debe a que la mayoría de las consultas de búsqueda reales de Google no aparecen exactamente en el artículo, por lo que su valor X es cero. Sin embargo, todavía tienen impresiones y clics. Por eso se puede ver que el punto inicial de la línea de tendencia de frecuencia de términos no parte de Y-cero. Uno podría esperar que cuando ciertas consultas aparecen múltiples veces en el artículo, las impresiones y clics probablemente aumenten. La línea de tendencia lo confirma, pero la varianza de la línea de tendencia también crece, lo que sugiere una falta de datos de respaldo. En general, la frecuencia de términos no es un buen predictor.
- Comparando el predictor de frecuencia de términos con los gráficos de dispersión del modelo de embedding y del modelo reranker, estos últimos se ven mucho mejor: los puntos de datos están mejor distribuidos y la varianza de la línea de tendencia parece razonable. Sin embargo, si los comparas con la línea de tendencia de la verdad fundamental mostrada arriba, notarás una diferencia significativa: ninguna línea de tendencia comienza desde X-cero. Esto significa que incluso si obtienes una similitud semántica muy alta del modelo, es muy probable que Google te asigne cero impresiones/clics. Esto se vuelve más obvio en el gráfico de dispersión de clics, donde el punto inicial está aún más empujado hacia la derecha que su contraparte de impresiones. En resumen, Google no está usando nuestro modelo de embedding y modelo reranker, ¡gran sorpresa!
- Finalmente, si tuviera que elegir el mejor predictor entre estos tres, se lo daría al modelo reranker. Por dos razones:
- La línea de tendencia del modelo reranker tanto en impresiones como en clics está mejor distribuida a lo largo del eje X en comparación con la línea de tendencia del modelo de embedding, dándole más "rango dinámico", lo que la hace más cercana a la línea de tendencia de la verdad fundamental.
- La puntuación está bien distribuida entre 0 y 1. Ten en cuenta que esto es principalmente porque nuestro último modelo Reranker v2 está calibrado, mientras que nuestro anterior jina-embeddings-v2-base-en lanzado en octubre de 2023 no lo estaba, por lo que puedes ver sus valores distribuidos entre 0.60 y 0.90. Dicho esto, esta segunda razón no tiene nada que ver con su aproximación a ; es solo que una puntuación semántica bien calibrada entre 0 y 1 es más intuitiva de entender y comparar.
tagPensamientos Finales
Entonces, ¿cuál es la conclusión para SEO aquí? ¿Cómo impacta esto en tu estrategia SEO? Honestamente, no mucho.
Los elegantes gráficos anteriores sugieren un principio básico de SEO que probablemente ya conoces: escribe contenido que los usuarios estén buscando y asegúrate de que se relacione con consultas populares. Si tienes un buen predictor como Reranker V2, tal vez puedas usarlo como una especie de "copiloto SEO" para guiar tu escritura.
O tal vez no. Tal vez solo escribe por el bien del conocimiento, escribe para mejorarte a ti mismo, no para complacer a Google o a alguien más. Porque si piensas sin escribir, solo crees que estás pensando.
