




En abril de 2024, lanzamos Jina Reader, una API simple que convierte cualquier URL en markdown compatible con LLM con solo un prefijo simple: r.jina.ai. A pesar de la sofisticada programación de red detrás de escena, la parte central de "lectura" es bastante directa. Primero, usamos un navegador Chrome sin interfaz para obtener el código fuente de la página web. Luego, aprovechamos el paquete Readability de Mozilla para extraer el contenido principal, eliminando elementos como encabezados, pies de página, barras de navegación y barras laterales. Finalmente, convertimos el HTML limpio a markdown usando regex y la biblioteca Turndown. El resultado es un archivo markdown bien estructurado, listo para ser utilizado por LLMs para fundamentación, resumen y razonamiento.
En las primeras semanas después del lanzamiento de Jina Reader, recibimos muchos comentarios, particularmente sobre la calidad del contenido. Algunos usuarios lo encontraron demasiado detallado, mientras que otros sintieron que no era lo suficientemente detallado. También hubo reportes de que el filtro Readability eliminaba el contenido equivocado o que Turndown tenía dificultades para convertir ciertas partes del HTML a markdown. Afortunadamente, muchos de estos problemas se resolvieron exitosamente mediante parches en el pipeline existente con nuevos patrones regex o heurísticas.
Desde entonces, hemos estado reflexionando sobre una pregunta: en lugar de parchearlo con más heurísticas y regex (que se vuelve cada vez más difícil de mantener y no es amigable con múltiples idiomas), ¿podemos resolver este problema de extremo a extremo con un modelo de lenguaje?
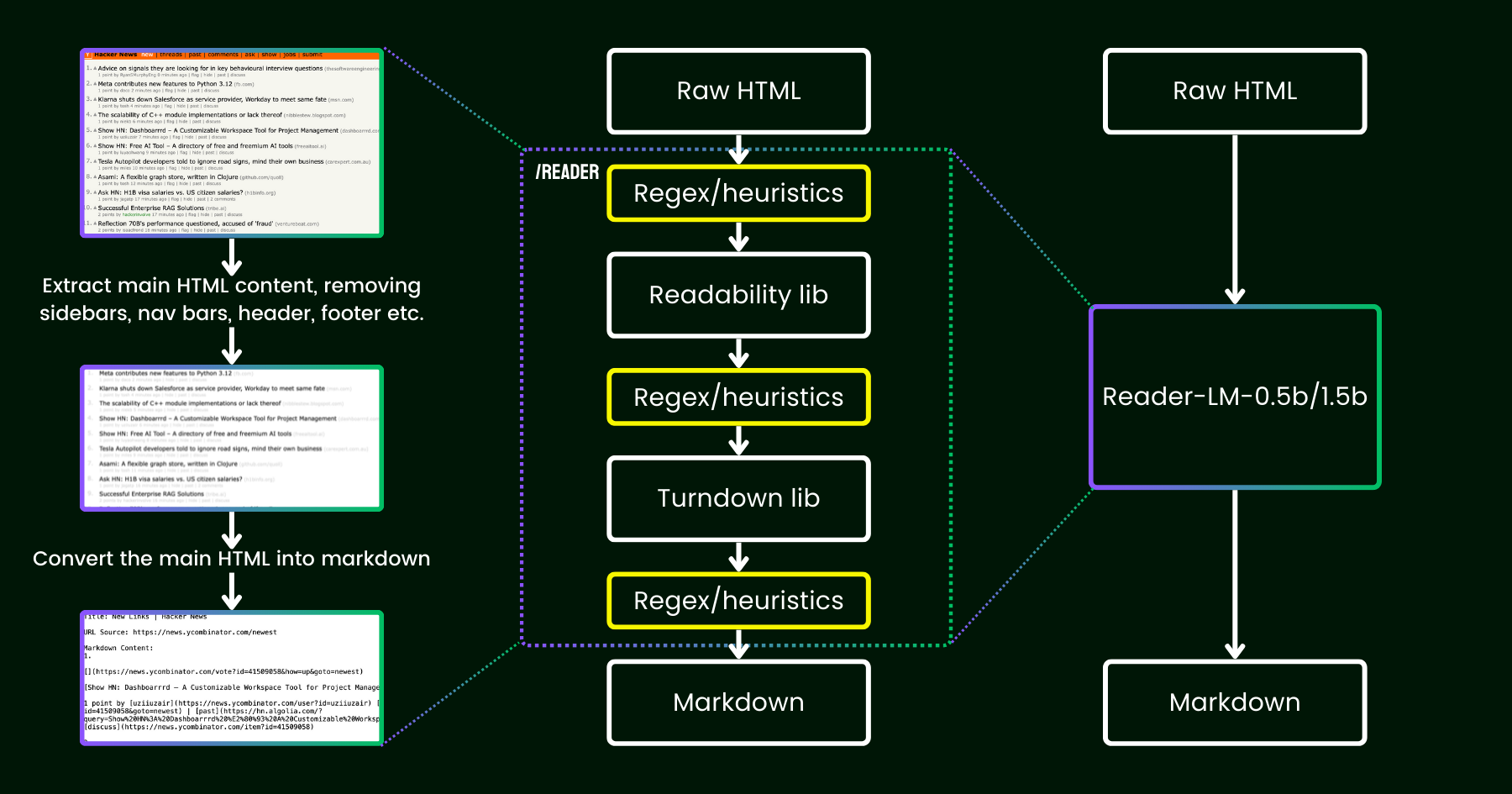
reader-lm, reemplazando el pipeline de readability+turndown+regex heurísticos usando un modelo de lenguaje pequeño.A primera vista, usar LLMs para la limpieza de datos podría parecer excesivo debido a su baja eficiencia en costos y velocidades más lentas. Pero ¿qué tal si consideramos un modelo de lenguaje pequeño (SLM) — uno con menos de 1 mil millones de parámetros que puede ejecutarse eficientemente en el borde? Eso suena mucho más atractivo, ¿verdad? Pero ¿es esto realmente factible o solo un pensamiento ilusorio? Según la ley de escalamiento, menos parámetros generalmente conducen a capacidades reducidas de razonamiento y resumen. Entonces un SLM podría incluso tener dificultades para generar contenido significativo si su tamaño de parámetros es demasiado pequeño. Para explorar esto más a fondo, echemos un vistazo más cercano a la tarea de HTML a Markdown:
- Primero, la tarea que estamos considerando no es tan creativa o compleja como las tareas típicas de LLM. En el caso de convertir HTML a markdown, el modelo principalmente necesita copiar selectivamente de la entrada a la salida (es decir, saltarse el marcado HTML, barras laterales, encabezados, pies de página), con un esfuerzo mínimo dedicado a generar nuevo contenido (principalmente insertando sintaxis markdown). Esto contrasta fuertemente con las tareas más amplias que manejan los LLMs, como generar poemas o escribir código, donde la salida involucra mucha más creatividad y no es una copia directa de la entrada. Esta observación sugiere que un SLM podría funcionar, ya que la tarea parece más simple que la generación de texto más general.
- Segundo, necesitamos priorizar el soporte de contexto largo. El HTML moderno a menudo contiene mucho más ruido que el simple marcado
<div>. El CSS en línea y los scripts pueden fácilmente inflar el código a cientos de miles de tokens. Para que un SLM sea práctico en este escenario, la longitud del contexto debe ser suficientemente grande. Una longitud de token de 8K o 16K no es útil en absoluto.
Parece que lo que necesitamos es un SLM superficial pero ancho. "Superficial" en el sentido de que la tarea es principalmente "copiar y pegar" simple, por lo tanto se necesitan menos bloques de transformador; y "ancho" en el sentido de que requiere soporte de contexto largo para ser práctico, por lo que el mecanismo de atención necesita cierto cuidado. Investigaciones previas han demostrado que la longitud del contexto y la capacidad de razonamiento están estrechamente entrelazadas. Para un SLM, es extremadamente desafiante optimizar ambas dimensiones mientras se mantiene pequeño el tamaño del parámetro.
Hoy, nos complace anunciar la primera versión de esta solución con el lanzamiento de reader-lm-0.5b y reader-lm-1.5b, dos SLMs específicamente entrenados para generar markdown limpio directamente desde HTML crudo ruidoso. Ambos modelos son multilingües y soportan una longitud de contexto de hasta 256K tokens. A pesar de su tamaño compacto, estos modelos logran un rendimiento estado del arte en esta tarea, superando a contrapartes LLM más grandes mientras son solo 1/50 de su tamaño.

A continuación se muestran las especificaciones de los dos modelos:
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| # Parámetros | 494M | 1.54B |
| Longitud de contexto | 256K | 256K |
| Tamaño oculto | 896 | 1536 |
| # Capas | 24 | 28 |
| # Cabezas de consulta | 14 | 12 |
| # Cabezas KV | 2 | 2 |
| Tamaño de cabeza | 64 | 128 |
| Tamaño intermedio | 4864 | 8960 |
| Multilingüe | Sí | Sí |
| Repositorio HuggingFace | Enlace | Enlace |
tagEmpezar con Reader-LM
tagEn Google Colab
La manera más fácil de experimentar con reader-lm es ejecutando nuestro notebook de Colab, donde demostramos cómo usar reader-lm-1.5b para convertir el sitio web de Hacker News a markdown. El notebook está optimizado para ejecutarse sin problemas en el nivel gratuito de GPU T4 de Google Colab. También puedes cargar reader-lm-0.5b o cambiar la URL a cualquier sitio web y explorar la salida. Ten en cuenta que la entrada (es decir, el prompt) al modelo es el HTML crudo—no se requiere instrucción de prefijo.

Tenga en cuenta que la GPU T4 de nivel gratuito tiene limitaciones que podrían impedir el uso de optimizaciones avanzadas durante la ejecución del modelo. Funciones como bfloat16 y flash attention no están disponibles en la T4, lo que podría resultar en un mayor uso de VRAM y un rendimiento más lento para entradas más largas. Para entornos de producción, recomendamos usar una GPU de gama alta como la RTX 3090/4090 para obtener un rendimiento significativamente mejor.
tagEn Producción: Próximamente Disponible en Azure y AWS
Reader-LM está disponible en Azure Marketplace y AWS SageMaker. Si necesita usar estos modelos más allá de estas plataformas o en las instalaciones de su empresa, tenga en cuenta que ambos modelos están licenciados bajo CC BY-NC 4.0. Para consultas sobre uso comercial, no dude en contactarnos.


tagComparativa
Para evaluar cuantitativamente el rendimiento de Reader-LM, lo comparamos con varios modelos de lenguaje grandes, incluyendo: GPT-4o, Gemini-1.5-Flash, Gemini-1.5-Pro, LLaMA-3.1-70B, Qwen2-7B-Instruct.
Los modelos fueron evaluados usando las siguientes métricas:
- ROUGE-L (mayor es mejor): Esta métrica, ampliamente utilizada para tareas de resumen y respuesta a preguntas, mide la superposición entre la salida predicha y la referencia a nivel de n-gramas.
- Tasa de Error de Tokens (TER, menor es mejor): Esta métrica calcula la tasa a la que los tokens markdown generados no aparecen en el contenido HTML original. Diseñamos esta métrica para evaluar la tasa de alucinación del modelo, ayudándonos a identificar casos donde el modelo produce contenido que no está fundamentado en el HTML. Se realizarán mejoras adicionales basadas en estudios de casos.
- Tasa de Error de Palabras (WER, menor es mejor): Comúnmente usada en tareas de OCR y ASR, WER considera la secuencia de palabras y calcula errores como inserciones (ADD), sustituciones (SUB) y eliminaciones (DEL). Esta métrica proporciona una evaluación detallada de los desajustes entre el markdown generado y la salida esperada.
Para aprovechar los LLMs para esta tarea, usamos la siguiente instrucción uniforme como prompt inicial:
Your task is to convert the content of the provided HTML file into the corresponding markdown file. You need to convert the structure, elements, and attributes of the HTML into equivalent representations in markdown format, ensuring that no important information is lost. The output should strictly be in markdown format, without any additional explanations.Los resultados se pueden encontrar en la tabla siguiente.
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
tagEstudio Cualitativo
Realizamos un estudio cualitativo inspeccionando visualmente el markdown de salida. Seleccionamos 22 fuentes HTML incluyendo artículos de noticias, posts de blog, páginas de aterrizaje, páginas de comercio electrónico y posts de foros en múltiples idiomas: inglés, alemán, japonés y chino. También incluimos la API Jina Reader como referencia, que se basa en regex, heurísticas y reglas predefinidas.
La evaluación se centró en cuatro dimensiones clave de la salida, con cada modelo calificado en una escala del 1 (más bajo) al 5 (más alto):
- Extracción de Encabezados: Evaluó qué tan bien cada modelo identificó y formateó los encabezados h1,h2,..., h6 del documento usando la sintaxis correcta de markdown.
- Extracción de Contenido Principal: Evaluó la capacidad de los modelos para convertir con precisión el texto del cuerpo, preservando párrafos, formateando listas y manteniendo la consistencia en la presentación.
- Preservación de Estructura Rica: Analizó qué tan efectivamente cada modelo mantuvo la estructura general del documento, incluyendo encabezados, subencabezados, viñetas y listas ordenadas.
- Uso de Sintaxis Markdown: Evaluó la capacidad de cada modelo para convertir correctamente elementos HTML como
<a>(enlaces),<strong>(texto en negrita) y<em>(cursivas) a sus equivalentes apropiados en markdown.
Los resultados se pueden encontrar a continuación.

Reader-LM-1.5B tiene un rendimiento consistentemente bueno en todas las dimensiones, destacando particularmente en preservación de estructura y uso de sintaxis markdown. Si bien no siempre supera a Jina Reader API, su rendimiento es competitivo con modelos más grandes como Gemini 1.5 Pro, lo que lo convierte en una alternativa altamente eficiente a los LLM más grandes. Reader-LM-0.5B, aunque más pequeño, aún ofrece un rendimiento sólido, particularmente en preservación de estructura.
tagCómo Entrenamos Reader-LM
tagPreparación de Datos
Usamos la API Jina Reader para generar pares de entrenamiento de HTML sin procesar y su markdown correspondiente. Durante el experimento, encontramos que los SLM son particularmente sensibles a la calidad de los datos de entrenamiento. Así que construimos un pipeline de datos que asegura que solo se incluyan entradas markdown de alta calidad en el conjunto de entrenamiento.
Adicionalmente, agregamos algunos HTML sintéticos y sus contrapartes markdown, generados por GPT-4o. En comparación con el HTML del mundo real, los datos sintéticos tienden a ser mucho más cortos, con estructuras más simples y predecibles, y un nivel de ruido significativamente menor.
Finalmente, concatenamos el HTML y markdown usando una plantilla de chat. Los datos de entrenamiento finales están formateados de la siguiente manera:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{{RAW_HTML}}<|im_end|>
<|im_start|>assistant
{{MARKDOWN}}<|im_end|>
Los datos de entrenamiento completos suman 2.5 mil millones de tokens.
tagEntrenamiento en Dos Etapas
Experimentamos con varios tamaños de modelos, desde 65M y 135M hasta 3B parámetros. Las especificaciones para cada modelo se pueden encontrar en la tabla siguiente.
| reader-lm-65m | reader-lm-135m | reader-lm-360m | reader-lm-0.5b | reader-lm-1.5b | reader-lm-1.7b | reader-lm-3b | |
|---|---|---|---|---|---|---|---|
| Hidden Size | 512 | 576 | 960 | 896 | 1536 | 2048 | 3072 |
| # Layers | 8 | 30 | 32 | 24 | 28 | 24 | 32 |
| # Query Heads | 16 | 9 | 15 | 14 | 12 | 32 | 32 |
| # KV Heads | 8 | 3 | 5 | 2 | 2 | 32 | 32 |
| Head Size | 32 | 64 | 64 | 64 | 128 | 64 | 96 |
| Intermediate Size | 2048 | 1536 | 2560 | 4864 | 8960 | 8192 | 8192 |
| Attention Bias | False | False | False | True | True | False | False |
| Embedding Tying | False | True | True | True | True | True | False |
| Vocabulary Size | 32768 | 49152 | 49152 | 151646 | 151646 | 49152 | 32064 |
| Base Model | Lite-Oute-1-65M-Instruct | SmolLM-135M | SmolLM-360M-Instruct | Qwen2-0.5B-Instruct | Qwen2-1.5B-Instruct | SmolLM-1.7B | Phi-3-mini-128k-instruct |
El entrenamiento del modelo se realizó en dos etapas:
- HTML corto y simple: En esta etapa, la longitud máxima de secuencia (HTML + markdown) se estableció en 32K tokens, con un total de 1.5 mil millones de tokens de entrenamiento.
- HTML largo y complejo: la longitud de secuencia se extendió a 128K tokens, con 1.2 mil millones de tokens de entrenamiento. Implementamos el mecanismo zigzag-ring-attention de Ring Flash Attention de Zilin Zhu (2024) para esta etapa.
Dado que los datos de entrenamiento incluían secuencias de hasta 128K tokens, creemos que el modelo puede soportar hasta 256K tokens sin problemas. Sin embargo, manejar 512K tokens puede ser desafiante, ya que extender los embeddings posicionales RoPE a cuatro veces la longitud de la secuencia de entrenamiento podría resultar en una degradación del rendimiento.
Para los modelos de 65M y 135M parámetros, observamos que podían lograr un comportamiento razonable de "copia", pero solo con secuencias cortas (menos de 1K tokens). A medida que aumentaba la longitud de entrada, estos modelos tenían dificultades para producir cualquier salida razonable. Dado que el código fuente HTML moderno puede exceder fácilmente los 100K tokens, un límite de 1K tokens está lejos de ser suficiente.
tagDegeneración y Bucles Monótonos
Uno de los principales desafíos que encontramos fue la degeneración, particularmente en forma de repetición y bucles. Después de generar algunos tokens, el modelo comenzaba a generar el mismo token repetidamente o se quedaba atascado en un bucle, repitiendo continuamente una secuencia corta de tokens hasta alcanzar la longitud máxima permitida de salida.

Para abordar este problema:
- Aplicamos la búsqueda contrastiva como método de decodificación e incorporamos pérdida contrastiva durante el entrenamiento. Según nuestros experimentos, este método redujo efectivamente la generación repetitiva en la práctica.
- Implementamos un criterio simple de detención de repetición dentro del pipeline del transformer. Este criterio detecta automáticamente cuando el modelo comienza a repetir tokens y detiene la decodificación temprano para evitar bucles monótonos. Esta idea se inspiró en esta discusión.
tagEficiencia de Entrenamiento en Entradas Largas
Para mitigar el riesgo de errores de memoria insuficiente (OOM) al manejar entradas largas, implementamos el reenvío del modelo por fragmentos. Este enfoque codifica la entrada larga con fragmentos más pequeños, reduciendo el uso de VRAM.
Mejoramos la implementación del empaquetado de datos en nuestro marco de entrenamiento, que se basa en el Transformers Trainer. Para optimizar la eficiencia del entrenamiento, múltiples textos cortos (por ejemplo, 2K tokens) se concatenan en una única secuencia larga (por ejemplo, 30K tokens), permitiendo el entrenamiento sin relleno. Sin embargo, en la implementación original, algunos ejemplos cortos se dividían en dos subtextos y se incluían en diferentes secuencias de entrenamiento largas. En tales casos, el segundo subtexto perdería su contexto (por ejemplo, el contenido HTML sin procesar en nuestro caso), lo que llevaría a datos de entrenamiento corruptos. Esto obliga al modelo a depender de sus parámetros en lugar del contexto de entrada, lo que creemos que es una fuente importante de alucinación.
Al final, seleccionamos los modelos de 0.5B y 1.5B para su publicación. El modelo de 0.5B es el más pequeño capaz de lograr el comportamiento deseado de "copia selectiva" en entradas de contexto largo, mientras que el modelo de 1.5B es el modelo más grande más pequeño que mejora significativamente el rendimiento sin alcanzar rendimientos decrecientes en relación con el tamaño de los parámetros.
tagArquitectura Alternativa: Modelo Solo-Codificador
En los primeros días de este proyecto, también exploramos el uso de una arquitectura solo-codificador para abordar esta tarea. Como se mencionó anteriormente, la tarea de conversión de HTML a Markdown parece ser principalmente una tarea de "copia selectiva". Dado un par de entrenamiento (HTML sin procesar y markdown), podemos etiquetar los tokens que existen tanto en la entrada como en la salida como 1, y el resto como 0. Esto convierte el problema en una tarea de clasificación de tokens, similar a lo que se usa en el Reconocimiento de Entidades Nombradas (NER).
Si bien este enfoque parecía lógico, presentó desafíos significativos en la práctica. Primero, el HTML sin procesar de fuentes del mundo real es extremadamente ruidoso y largo, haciendo que las etiquetas 1 sean extremadamente escasas y por lo tanto difíciles de aprender para el modelo. Segundo, codificar sintaxis especial de markdown en un esquema 0-1 resultó problemático, ya que símbolos como ## title, *bold*, y | table | no existen en la entrada HTML sin procesar. Tercero, los tokens de salida no siempre siguen estrictamente el orden de la entrada. A menudo ocurren reordenamientos menores, particularmente con tablas y enlaces, lo que hace difícil representar tales comportamientos de reordenamiento en un esquema simple 0-1. El reordenamiento de corta distancia podría potencialmente manejarse con programación dinámica o algoritmos de alineamiento-deformación introduciendo etiquetas como -1, -2, +1, +2 para representar desplazamientos de distancia, transformando el problema de clasificación binaria en una tarea de clasificación de tokens multiclase.
En resumen, resolver el problema con una arquitectura solo-codificador y tratarlo como una tarea de clasificación de tokens tiene su encanto, especialmente porque las secuencias de entrenamiento son mucho más cortas en comparación con un modelo solo-decodificador, haciéndolo más amigable con la VRAM. Sin embargo, el principal desafío radica en preparar buenos datos de entrenamiento. Cuando nos dimos cuenta de que el tiempo y esfuerzo dedicados al preprocesamiento de los datos—usando programación dinámica y heurísticas para crear secuencias perfectas de etiquetado a nivel de token—era abrumador, decidimos descontinuar este enfoque.
tagConclusión
Reader-LM es un novedoso modelo de lenguaje pequeño (SLM) diseñado para la extracción y limpieza de datos en la web abierta. Inspirado en Jina Reader, nuestro objetivo era crear una solución de modelo de lenguaje de extremo a extremo capaz de convertir HTML en bruto y ruidoso a markdown limpio. Al mismo tiempo, nos centramos en la eficiencia de costos, manteniendo el tamaño del modelo pequeño para asegurar que Reader-LM siga siendo práctico y utilizable. También es el primer modelo decodificador de contexto largo entrenado en Jina AI.
Aunque inicialmente la tarea pueda parecer un simple problema de "copia selectiva", convertir y limpiar HTML a markdown está lejos de ser fácil. Específicamente, requiere que el modelo sobresalga en el razonamiento basado en contexto y consciente de la posición, lo que exige un tamaño de parámetros mayor, particularmente en las capas ocultas. En comparación, aprender la sintaxis de markdown es relativamente sencillo.
Durante nuestros experimentos, también descubrimos que entrenar un SLM desde cero es particularmente desafiante. Comenzar con un modelo preentrenado y continuar con el entrenamiento específico de la tarea mejoró significativamente la eficiencia del entrenamiento. Todavía hay mucho margen de mejora en términos de eficiencia y calidad: expandir la longitud del contexto, acelerar la decodificación y agregar soporte para instrucciones en la entrada, lo que permitiría a Reader-LM extraer partes específicas de una página web en markdown.
