


Tras la integración de Jina Embeddings en Deepset's Haystack 2.0 y el lanzamiento de Jina Reranker, nos complace anunciar que Jina Reranker ahora también está disponible a través de la extensión Jina Haystack.


Haystack es un framework de extremo a extremo que te acompaña en cada paso del ciclo de vida del proyecto GenAI. Ya sea que quieras realizar búsqueda de documentos, generación aumentada por recuperación (RAG), respuesta a preguntas o generación de respuestas, Haystack puede orquestar modelos de embeddings y LLMs de última generación en pipelines para construir aplicaciones NLP de extremo a extremo y resolver tu caso de uso.
En esta publicación, te mostraremos cómo usarlos para crear tu propio motor de búsqueda de tickets de Jira para optimizar tus operaciones y nunca más perder tiempo creando problemas duplicados.
Para seguir este tutorial, necesitarás una clave API de Jina Reranker. Puedes crear una con una cuota de prueba gratuita de un millón de tokens desde el sitio web de Jina Reranker.
tagRecuperando Tickets de Soporte de Jira
Cualquier equipo que maneje un proyecto complejo ha experimentado la frustración de tener un problema que quieren reportar pero sin saber si ya existe un ticket para este problema.
En el siguiente tutorial, te mostraremos cómo puedes crear fácilmente una herramienta usando Jina Reranker y pipelines de Haystack, que sugiere posibles tickets duplicados cuando se está creando uno nuevo.
- Al ingresar un ticket que necesita ser verificado contra todos los tickets existentes, el pipeline primero recuperará de la base de datos todos los problemas relacionados.
- Luego eliminará el ticket inicial de la lista (si ya existía en la base de datos) y cualquier ticket hijo (es decir, tickets cuyo ID padre corresponde al ticket original).
- La selección final ahora solo comprende problemas que podrían cubrir el mismo tema que el ticket original pero no fueron marcados como tales en la base de datos a través de sus IDs. Estos tickets son reordenados para asegurar la máxima relevancia y permitirte identificar entradas duplicadas en la base de datos.
tagObteniendo el Dataset
Para implementar nuestra solución, hemos elegido todos los tickets "En progreso" de Jira para el proyecto Apache Zookeeper. Este es un servicio de código abierto para coordinar procesos de aplicaciones distribuidas.
Hemos colocado los tickets en un archivo JSON para hacerlos más convenientes. Por favor, descarga el archivo a tu espacio de trabajo.
tagConfigurar los Prerequisitos
Para instalar los requisitos, ejecuta:
pip install --q chromadb haystack-ai jina-haystack chroma-haystack
Para ingresar la clave API, configúrala como una variable de entorno:
import os
import getpass
os.environ["JINA_API_KEY"] = getpass.getpass()
getpass.getpass() te pedirá que ingreses la clave API debajo del bloque de código correspondiente. Puedes ingresar la clave allí y presionar enter para continuar con el tutorial. Si lo prefieres, también puedes sustituir getpass.getpass() con la clave API directamente.tagConstruir el Pipeline de Indexación
El pipeline de indexación preprocesará los tickets, los convertirá en vectores y los almacenará. Usaremos el Chroma DocumentStore como nuestra base de datos vectorial para almacenar los embeddings vectoriales, a través de la integración Chroma Document Store de Haystack.
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
document_store = ChromaDocumentStore()
Comenzaremos definiendo nuestro preprocesador de datos personalizado para considerar solo los campos relevantes del documento y eliminar todas las entradas vacías:
import json
from typing import List
from haystack import Document, component
relevant_keys = ['Summary', 'Issue key', 'Issue id', 'Parent id', 'Issue type', 'Status', 'Project lead', 'Priority', 'Assignee', 'Reporter', 'Creator', 'Created', 'Updated', 'Last Viewed', 'Due Date', 'Labels',
'Description', 'Comment', 'Comment__1', 'Comment__2', 'Comment__3', 'Comment__4', 'Comment__5', 'Comment__6', 'Comment__7', 'Comment__8', 'Comment__9', 'Comment__10', 'Comment__11', 'Comment__12',
'Comment__13', 'Comment__14', 'Comment__15']
@component
class RemoveKeys:
@component.output_types(documents=List[Document])
def run(self, file_name: str):
with open(file_name, 'r') as file:
tickets = json.load(file)
cleaned_tickets = []
for t in tickets:
t = {k: v for k, v in t.items() if k in relevant_keys and v}
cleaned_tickets.append(t)
return {'documents': cleaned_tickets}
Luego necesitamos crear un convertidor JSON personalizado para transformar los tickets en objetos Document que Haystack pueda entender:
@component
class JsonConverter:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document]):
tickets_documents = []
for t in tickets:
if 'Parent id' in t:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': t['Parent id']})
else:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': ''})
tickets_documents.append(t)
return {'documents': tickets_documents}
Finalmente, incrustamos los Documents y escribimos estos embeddings en el ChromaDocumentStore:
from haystack import Pipeline
from haystack.components.writers import DocumentWriter
from haystack_integrations.components.retrievers.chroma import ChromaEmbeddingRetriever
from haystack.document_stores.types import DuplicatePolicy
from haystack_integrations.components.embedders.jina import JinaDocumentEmbedder
retriever = ChromaEmbeddingRetriever(document_store=document_store)
retriever_reranker = ChromaEmbeddingRetriever(document_store=document_store)
indexing_pipeline = Pipeline()
indexing_pipeline.add_component('cleaner', RemoveKeys())
indexing_pipeline.add_component('converter', JsonConverter())
indexing_pipeline.add_component('embedder', JinaDocumentEmbedder(model='jina-embeddings-v2-base-en'))
indexing_pipeline.add_component('writer', DocumentWriter(document_store=document_store, policy=DuplicatePolicy.SKIP))
indexing_pipeline.connect('cleaner', 'converter')
indexing_pipeline.connect('converter', 'embedder')
indexing_pipeline.connect('embedder', 'writer')
indexing_pipeline.run({'cleaner': {'file_name': 'tickets.json'}})
Esto debería crear una barra de progreso y mostrar un breve JSON que contiene información sobre lo que se ha almacenado:
Calculating embeddings: 100%|██████████| 1/1 [00:01<00:00, 1.21s/it]
{'embedder': {'meta': {'model': 'jina-embeddings-v2-base-en',
'usage': {'total_tokens': 20067, 'prompt_tokens': 20067}}},
'writer': {'documents_written': 31}}tagConstruir el Pipeline de Consulta
Vamos a crear un pipeline de consulta para poder comenzar a comparar tickets. En Haystack 2.0, los retrievers están estrechamente acoplados a los DocumentStores. Si pasamos el document store en el retriever que inicializamos anteriormente, este pipeline puede acceder a los documentos que generamos y pasarlos al reranker. El reranker entonces compara estos documentos directamente con la pregunta y los clasifica según su relevancia.
Primero definimos el limpiador personalizado para eliminar los tickets recuperados que contengan el mismo ID de problema o ID padre que el problema pasado como consulta:
from typing import Optional
@component
class RemoveRelated:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document], query_id: Optional[str]):
retrieved_tickets = []
for t in tickets:
if not t.meta['Issue id'] == query_id and not t.meta['Parent id'] == query_id:
retrieved_tickets.append(t)
return {'documents': retrieved_tickets}
Luego incrustamos la consulta, recuperamos documentos relevantes, limpiamos la selección y finalmente la reordenamos:
from haystack_integrations.components.embedders.jina import JinaTextEmbedder
from haystack_integrations.components.rankers.jina import JinaRanker
query_pipeline_reranker = Pipeline()
query_pipeline_reranker.add_component('query_embedder_reranker', JinaTextEmbedder(model='jina-embeddings-v2-base-en'))
query_pipeline_reranker.add_component('query_retriever_reranker', retriever_reranker)
query_pipeline_reranker.add_component('query_cleaner_reranker', RemoveRelated())
query_pipeline_reranker.add_component('query_ranker_reranker', JinaRanker())
query_pipeline_reranker.connect('query_embedder_reranker.embedding', 'query_retriever_reranker.query_embedding')
query_pipeline_reranker.connect('query_retriever_reranker', 'query_cleaner_reranker')
query_pipeline_reranker.connect('query_cleaner_reranker', 'query_ranker_reranker')
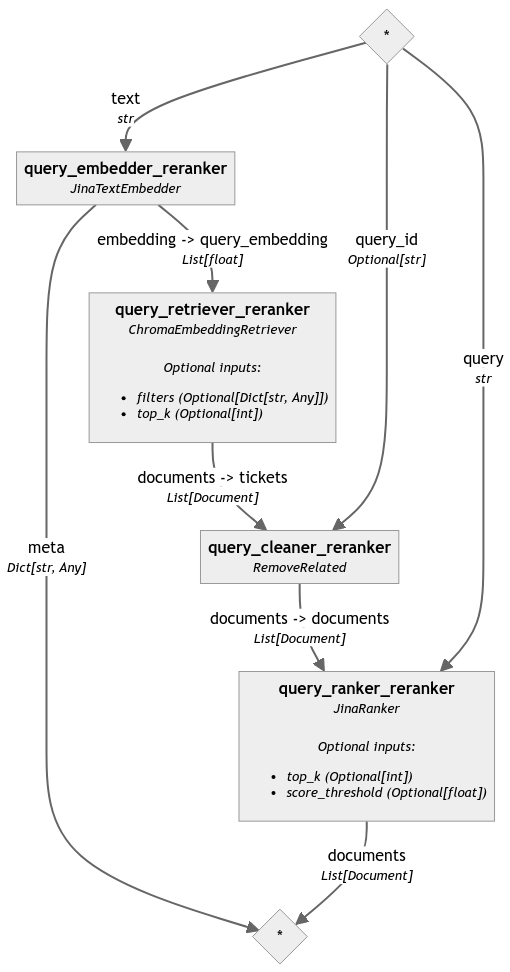
Para resaltar la diferencia causada por el reranker, analizamos el mismo pipeline sin el paso final de reordenamiento (el código correspondiente se omitió en esta publicación por legibilidad pero se puede encontrar en el notebook):
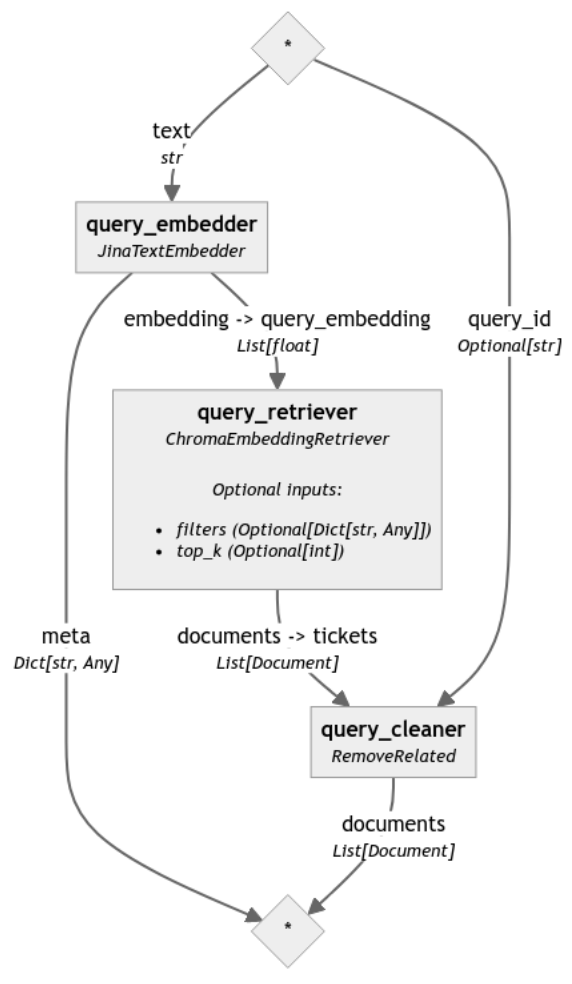
Para comparar los resultados de estos dos pipelines, ahora definimos nuestra consulta en forma de un ticket existente, en este caso "ZOOKEEPER-3282":
query_ticket_key = 'ZOOKEEPER-3282'
with open('tickets.json', 'r') as file:
tickets = json.load(file)
for ticket in tickets:
if ticket['Issue key'] == query_ticket_key:
query = str(ticket)
query_ticket_id = ticket['Issue id']
Se trata de "una gran refactorización de la documentacion" [sic]. Verás que, a pesar del error ortográfico, Jina Reranker recuperará correctamente tickets similares.
{
"Summary": "a big refactor for the documetations"
"Issue key": "ZOOKEEPER-3282"
"Issue id:: 13216608
"Parent id": ""
"Issue Type": "Task"
"Status": "In Progress"
"Project lead": "phunt"
"Priority": "Major"
"Assignee": "maoling"
"Reporter": "maoling"
"Creator": "maoling"
"Created": "19/Feb/19 11:50"
"Updated": "04/Aug/19 12:48"
"Last Viewed": "12/Mar/24 11:56"
"Description": "Hi guys: I'am working on doing a big refactor for the documetations.it aims to - 1.make a better reading experiences and help users know more about zookeeper quickly,as good as other projects' doc(e.g redis,hbase). - 2.have less changes to diff with the original docs as far as possible. - 3.solve the problem when we have some new features or improvements,but cannot find a good place to doc it. The new catalog may looks kile this: * is new one added. ** is the one to keep unchanged as far as possible. *** is the one modified. -------------------------------------------------------------- |---Overview |---Welcome ** [1.1] |---Overview ** [1.2] |---Getting Started ** [1.3] |---Release Notes ** [1.4] |---Developer |---API *** [2.1] |---Programmer's Guide ** [2.2] |---Recipes *** [2.3] |---Clients * [2.4] |---Use Cases * [2.5] |---Admin & Ops |---Administrator's Guide ** [3.1] |---Quota Guide ** [3.2] |---JMX ** [3.3] |---Observers Guide ** [3.4] |---Dynamic Reconfiguration ** [3.5] |---Zookeeper CLI * [3.6] |---Shell * [3.7] |---Configuration flags * [3.8] |---Troubleshooting & Tuning * [3.9] |---Contributor Guidelines |---General Guidelines * [4.1] |---ZooKeeper Internals ** [4.2] |---Miscellaneous |---Wiki ** [5.1] |---Mailing Lists ** [5.2] -------------------------------------------------------------- The Roadmap is: 1.(I pick up it : D) 1.1 write API[2.1], which includes the: 1.1.1 original API Docs which is a Auto-generated java doc,just give a link. 1.1.2. Restful-api (the apis under the /zookeeper-contrib-rest/src/main/java/org/apache/zookeeper/server/jersey/resources) 1.2 write Clients[2.4], which includes the: 1.2.1 C client 1.2.2 zk-python, kazoo 1.2.3 Curator etc....... look at an example from: https://redis.io/clients # write Recipes[2.3], which includes the: - integrate "Java Example" and "Barrier and Queue Tutorial"(Since some bugs in the examples and they are obsolete,we may delete something) into it. - suggest users to use the recipes implements of Curator and link to the Curator's recipes doc. # write Zookeeper CLI[3.6], which includes the: - about how to use the zk command line interface [./zkCli.sh] e.g ls /; get ; rmr;create -e -p etc....... - look at an example from redis: https://redis.io/topics/rediscli # write shell[3.7], which includes the: - list all usages of the shells under the zookeeper/bin. (e.g zkTxnLogToolkit.sh,zkCleanup.sh) # write Configuration flags[3.8], which includes the: - list all usages of configurations properties(e.g zookeeper.snapCount): - move the original Advanced Configuration part of zookeeperAdmin.md into it. look at an example from:https://coreos.com/etcd/docs/latest/op-guide/configuration.html # write Troubleshooting & Tuning[3.9], which includes the: - move the original "Gotchas: Common Problems and Troubleshooting" part of Administrator's Guide.md into it. - move the original "FAQ" into into it. - add some new contents (e.g https://www.yumpu.com/en/document/read/29574266/building-an-impenetrable-zookeeper-pdf-github). look at an example from:https://redis.io/topics/problems https://coreos.com/etcd/docs/latest/tuning.html # write General Guidelines[4.1], which includes the: - move the original "Logging" part of ZooKeeper Internals into it as the logger specification. - write specifications about code, git commit messages,github PR etc ... look at an example from: http://hbase.apache.org/book.html#hbase.commit.msg.format # write Use Cases[2.5], which includes the: - just move the context from: https://cwiki.apache.org/confluence/display/ZOOKEEPER/PoweredBy into it. - add some new contents.(e.g Apache Projects:Spark;Companies:twitter,fb) -------------------------------------------------------------- BTW: - Any insights or suggestions are very welcomed.After the dicussions,I will create a series of tickets(An umbrella) - Since these works can be done parallelly, if you are interested in them, please don't hesitate,just assign to yourself, pick it up. (Notice: give me a ping to avoid the duplicated work)."
}
Finalmente, ejecutamos el pipeline de consulta. En este caso, recupera 20 tickets, elimina las entradas relacionadas por ID, las reordena y genera la selección final de los 10 problemas más relevantes.
Antes del paso de reordenamiento, la salida incluye 17 tickets:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13191544 | ZOOKEEPER-3170 | Umbrella for eliminating ZooKeeper flaky tests |
| 2 | 13400622 | ZOOKEEPER-4375 | Quota cannot limit the specify value when multiply clients create/set znodes |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 13295073 | ZOOKEEPER-3775 | Wrong message in IOException |
| 5 | 13268474 | ZOOKEEPER-3617 | ZK digest ACL permissions gets overridden |
| 6 | 13296971 | ZOOKEEPER-3787 | Apply modernizer-maven-plugin to build |
| 7 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 8 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
| 9 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 10 | 13262130 | ZOOKEEPER-3578 | Add a new CLI: multi |
| 11 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 12 | 13262494 | ZOOKEEPER-3583 | Add new apis to get node type and ttl time info |
| 13 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 14 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 15 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 16 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 17 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
Después de incluir el reordenador, ahora ejecutamos el pipeline de consulta:
result = query_pipeline_reranker.run(data={'query_embedder_reranker':{'text': query},
'query_retriever_reranker': {'top_k': 20},
'query_cleaner_reranker': {'query_id': query_ticket_id},
'query_ranker_reranker': {'query': query, 'top_k': 10}
}
)
for idx, res in enumerate(result['query_ranker_reranker']['documents']):
print('Doc {}:'.format(idx + 1), res)
La salida final son los 10 tickets más relevantes:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 2 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
| 5 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 6 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 7 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 8 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 9 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 10 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
tagVentajas de Jina Embeddings y Reranker
Para resumir este tutorial, construimos una herramienta de identificación de tickets duplicados basada en Jina Embeddings, Jina Reranker y Haystack 2.0. Los resultados anteriores muestran claramente la necesidad tanto de Jina Embeddings para recuperar documentos relevantes a través de búsqueda vectorial, como de Jina Reranker para obtener finalmente el contenido más relevante.
Si tomamos, por ejemplo, los dos problemas relacionados con la adición de documentación, es decir, "ZOOKEEPER-3585" y "ZOOKEEPER-3587", vemos que después del paso de recuperación, ambos están incluidos correctamente en las posiciones 11 y 9 respectivamente. Después de reordenar los documentos, ahora ambos están dentro de los 5 documentos más relevantes en las posiciones 5 y 1 respectivamente, mostrando una mejora significativa.
Al integrar ambos modelos en los pipelines de Haystack, la herramienta completa está lista para usar. Esta combinación hace que la extensión Jina Haystack sea la solución perfecta para tu aplicación.
