
Desde el lanzamiento del modelo O1 de OpenAI, uno de los temas más discutidos en la comunidad de IA ha sido el escalado del cómputo en tiempo de prueba. Esto se refiere a asignar recursos computacionales adicionales durante la inferencia—la fase donde un modelo de IA genera salidas en respuesta a entradas—en lugar de durante el preentrenamiento. Un ejemplo bien conocido es el razonamiento multi-paso de "cadena de pensamiento", que permite a los modelos realizar deliberaciones internas más extensas, como evaluar múltiples respuestas potenciales, planificación más profunda y auto-reflexión antes de llegar a una respuesta final. Esta estrategia mejora la calidad de las respuestas, particularmente en tareas de razonamiento complejo. El modelo QwQ-32B-Preview recientemente lanzado por Alibaba sigue esta tendencia de mejorar el razonamiento de IA a través del incremento del cómputo en tiempo de prueba.
Cuando se usa el modelo O1 de OpenAI, los usuarios pueden notar claramente que la inferencia de múltiples pasos requiere tiempo adicional mientras el modelo construye cadenas de razonamiento para resolver problemas.
En Jina AI, nos enfocamos más en embeddings y rerankers que en LLMs, así que para nosotros es natural considerar el escalado del cómputo en tiempo de prueba en este contexto: ¿Cómo se puede aplicar la "cadena de pensamiento" a los modelos de embedding? Aunque inicialmente pueda no parecer intuitivo, este artículo explora una perspectiva novedosa y demuestra cómo se puede aplicar el escalado del cómputo en tiempo de prueba a jina-clip para clasificar imágenes fuera de distribución (OOD)—resolviendo tareas que de otro modo serían imposibles.

tagCaso de Estudio

Nuestro experimento se centró en la clasificación de Pokemon usando el dataset TheFusion21/PokemonCards, que contiene miles de imágenes de cartas de Pokemon. La tarea es clasificación de imágenes donde la entrada es una ilustración recortada de carta Pokemon (con todo el texto/descripciones eliminados) y la salida es el nombre correcto del Pokemon de un conjunto predefinido de nombres. Esta tarea presenta un desafío particularmente interesante para los modelos de embedding CLIP porque:
- Los nombres y visuales de Pokemon representan conceptos específicos fuera de distribución para el modelo, haciendo que la clasificación directa sea desafiante
- Cada Pokemon tiene rasgos visuales claros que pueden descomponerse en elementos básicos (formas, colores, poses) que CLIP podría entender mejor
- La ilustración de la carta proporciona un formato visual consistente mientras introduce complejidad a través de fondos, poses y estilos artísticos variables
- La tarea requiere integrar múltiples características visuales simultáneamente, similar a las cadenas de razonamiento complejas en modelos de lenguaje

Absol G, Aerodactyl, Weedle, Caterpie, Azumarill, Bulbasaur, Venusaur, Absol, Aggron, Beedrill δ, Alakazam, Ampharos, Dratini, Ampharos, Ampharos, Arcanine, Blaine's Moltres, Aerodactyl, Celebi & Venusaur-GX, Caterpie]tagLínea base
El enfoque base utiliza una simple comparación directa entre la ilustración de las cartas Pokémon y los nombres. Primero, recortamos cada imagen de carta Pokémon para eliminar toda la información textual (encabezado, pie de página, descripción) para evitar cualquier conjetura trivial del modelo CLIP debido a nombres de Pokémon que aparecen en esos textos. Luego codificamos tanto las imágenes recortadas como los nombres de Pokémon usando el modelo jina-clip-v1 y jina-clip-v2 para obtener sus respectivos embeddings. La clasificación se realiza calculando la similitud coseno entre estos embeddings de imagen y texto - cada imagen se empareja con el nombre que tiene el puntaje de similitud más alto. Esto crea una correspondencia uno a uno directa entre la ilustración de la carta y los nombres de Pokémon, sin ningún contexto adicional o información de atributos. El pseudo código a continuación resume el método base.
# Preprocessing
cropped_images = [crop_artwork(img) for img in pokemon_cards] # Remove text, keep only art
pokemon_names = ["Absol", "Aerodactyl", ...] # Raw Pokemon names
# Get embeddings using jina-clip-v1
image_embeddings = model.encode_image(cropped_images)
text_embeddings = model.encode_text(pokemon_names)
# Classification by cosine similarity
similarities = cosine_similarity(image_embeddings, text_embeddings)
predicted_names = [pokemon_names[argmax(sim)] for sim in similarities]
# Evaluate
accuracy = mean(predicted_names == ground_truth_names)tag"Cadena de Pensamientos" para Clasificación
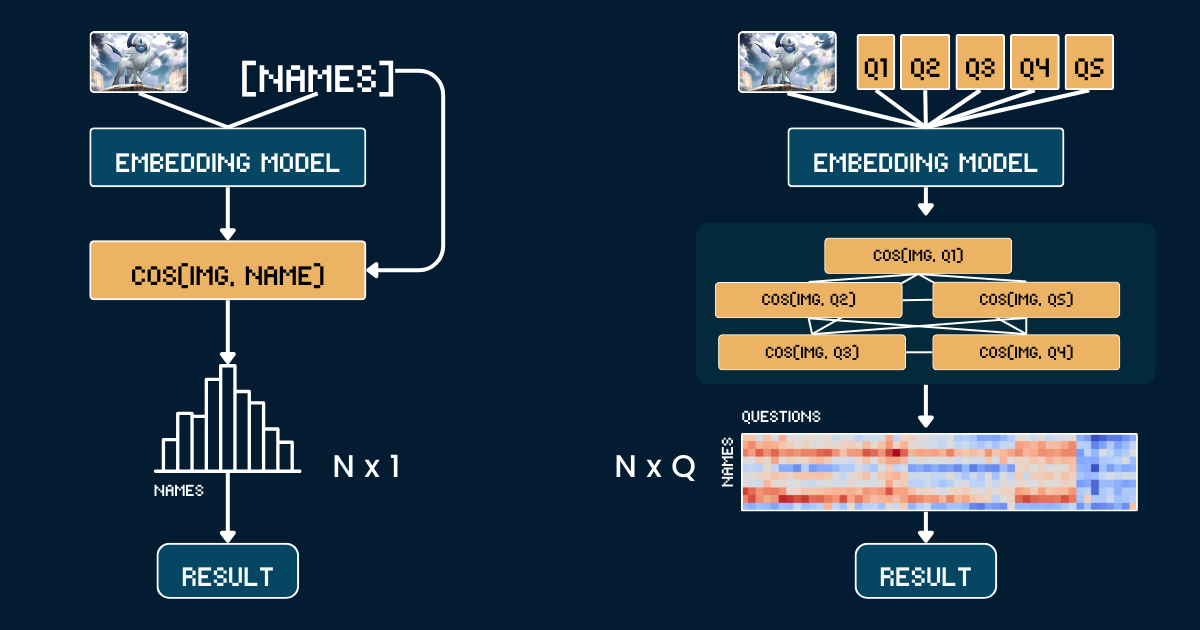
En lugar de emparejar directamente imágenes con nombres, descomponemos el reconocimiento de Pokémon en un sistema estructurado de atributos visuales. Definimos cinco grupos de atributos clave: color dominante (por ejemplo, "blanco", "azul"), forma primaria (por ejemplo, "un lobo", "un reptil alado"), rasgo característico (por ejemplo, "un solo cuerno blanco", "grandes alas"), forma del cuerpo (por ejemplo, "similar a un lobo en cuatro patas", "alado y esbelto"), y escena de fondo (por ejemplo, "espacio exterior", "bosque verde").
Para cada grupo de atributos, creamos indicaciones de texto específicas (por ejemplo, "El cuerpo de este Pokémon es principalmente de color {}") emparejadas con opciones relevantes. Luego usamos el modelo para calcular puntuaciones de similitud entre la imagen y cada opción de atributo. Estas puntuaciones se convierten en probabilidades usando softmax para obtener una medida más calibrada de confianza.
La estructura completa de Cadena de Pensamiento (CoT) consiste en dos partes: classification_groups que describe grupos de indicaciones, y pokemon_rules que define qué opciones de atributos debe coincidir cada Pokémon. Por ejemplo, Absol debe coincidir con "blanco" para el color y "similar a un lobo" para la forma. La CoT completa se muestra a continuación (explicaremos cómo se construye más adelante):
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
La clasificación final combina estas probabilidades de atributos - en lugar de una única comparación de similitud, ahora estamos haciendo múltiples comparaciones estructuradas y agregando sus probabilidades para tomar una decisión más informada.
# Classification process
def classify_pokemon(image):
# Generate all text prompts
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# Get embeddings and similarities
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# Convert to probabilities per attribute group
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# Score each Pokemon based on matching attributes
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get)tagAnálisis de Complejidad
Supongamos que queremos clasificar una imagen en uno de los N nombres de Pokémon. El enfoque base requiere calcular N embeddings de texto (uno para cada nombre de Pokémon). En contraste, nuestro enfoque de cálculo escalado en tiempo de prueba requiere calcular Q embeddings de texto, donde
Q es el número total de combinaciones de preguntas y opciones en todas las preguntas. Ambos métodos requieren calcular una incrustación de imagen y realizar un paso final de clasificación, por lo que excluimos estas operaciones comunes de nuestra comparación. En este caso de estudio, nuestro N=13 y Q=52.En un caso extremo donde Q = N, nuestro enfoque esencialmente se reduciría al punto de referencia. Sin embargo, la clave para escalar efectivamente el cómputo en tiempo de prueba es:
- Construir preguntas cuidadosamente elegidas que aumenten
Q - Asegurar que cada pregunta proporcione pistas distintas e informativas sobre la respuesta final
- Diseñar preguntas para que sean lo más ortogonales posible para maximizar su ganancia de información conjunta.
Este enfoque es análogo al juego de "Veinte Preguntas", donde cada pregunta se elige estratégicamente para reducir eficazmente las posibles respuestas.
tagEvaluación
Nuestra evaluación se realizó en 117 imágenes de prueba que abarcan 13 clases diferentes de Pokémon. Y el resultado es el siguiente:
| Approach | jina-clip-v1 | jina-clip-v2 |
|---|---|---|
| Baseline | 31.36% | 16.10% |
| CoT | 46.61% | 38.14% |
| Improvement | +15.25% | +22.04% |
Se puede ver que la misma clasificación CoT ofrece mejoras significativas para ambos modelos (+15.25% y +22.04% respectivamente) en esta tarea poco común o OOD. Esto también sugiere que una vez que se construye el pokemon_system, el mismo sistema CoT puede transferirse efectivamente entre diferentes modelos; y no se requiere ajuste fino ni entrenamiento posterior.
El rendimiento relativamente fuerte de la línea base de v1 (31.36%) en la clasificación de Pokémon es notable. Este modelo fue entrenado en LAION-400M, que incluía contenido relacionado con Pokémon. En contraste, v2 fue entrenado en DFN-2B (submuestreando 400M instancias), un conjunto de datos de mayor calidad pero más filtrado que puede haber excluido contenido relacionado con Pokémon, lo que explica el menor rendimiento base de V2 (16.10%) en esta tarea específica.
tagConstruyendo pokemon_system Efectivamente
La efectividad de nuestro enfoque de cómputo escalado en tiempo de prueba depende en gran medida de qué tan bien construyamos el pokemon_system. Hay diferentes enfoques para construir este sistema, desde manual hasta completamente automatizado.
Construcción Manual
El enfoque más directo es analizar manualmente el conjunto de datos de Pokémon y crear grupos de atributos, prompts y reglas. Un experto en el dominio necesitaría identificar atributos visuales clave como color, forma y características distintivas. Luego escribiría prompts en lenguaje natural para cada atributo, enumeraría las opciones posibles para cada grupo de atributos y mapearía cada Pokémon a sus opciones de atributos correctas. Si bien esto proporciona reglas de alta calidad, consume mucho tiempo y no escala bien para N más grandes.
Construcción Asistida por LLM
Podemos aprovechar los LLMs para acelerar este proceso pidiéndoles que generen el sistema de clasificación. Un prompt bien estructurado solicitaría grupos de atributos basados en características visuales, plantillas de prompt en lenguaje natural, opciones completas y mutuamente excluyentes, y reglas de mapeo para cada Pokémon. El LLM puede generar rápidamente un primer borrador, aunque su salida puede necesitar verificación.
I need help creating a structured system for Pokemon classification. For each Pokemon in this list: [Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...], create a classification system with:
1. Classification groups that cover these visual attributes:
- Dominant color of the Pokemon
- What type of creature it appears to be (primary form)
- Its most distinctive visual feature
- Overall body shape
- What kind of background/environment it's typically shown in
2. For each group:
- Create a natural language prompt template using "{}" for the option
- List all possible options that could apply to these Pokemon
- Make sure options are mutually exclusive and comprehensive
3. Create rules that map each Pokemon to exactly one option per attribute group, using indices to reference the options
Please output this as a Python dictionary with two main components:
- "classification_groups": containing prompts and options for each attribute
- "pokemon_rules": mapping each Pokemon to its correct attribute indices
Example format:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # index for "white"
...
},
...
}
}Un enfoque más robusto combina la generación por LLM con la validación humana. Primero, el LLM genera un sistema inicial. Luego, los expertos humanos revisan y corrigen las agrupaciones de atributos, la completitud de las opciones y la precisión de las reglas. El LLM refina el sistema basándose en esta retroalimentación, y el proceso se itera hasta alcanzar una calidad satisfactoria. Este enfoque equilibra la eficiencia con la precisión.
Construcción Automatizada con DSPy
Para un enfoque completamente automatizado, podemos usar DSPy para optimizar iterativamente pokemon_system. El proceso comienza con un pokemon_system simple escrito ya sea manualmente o por LLMs como prompt inicial. Cada versión se evalúa en un conjunto de retención, usando la precisión como señal de retroalimentación para DSPy. Basándose en este rendimiento, se generan prompts optimizados (es decir, nuevas versiones de pokemon_system). Este ciclo se repite hasta la convergencia, y durante todo el proceso, el modelo de incrustación permanece completamente fijo.
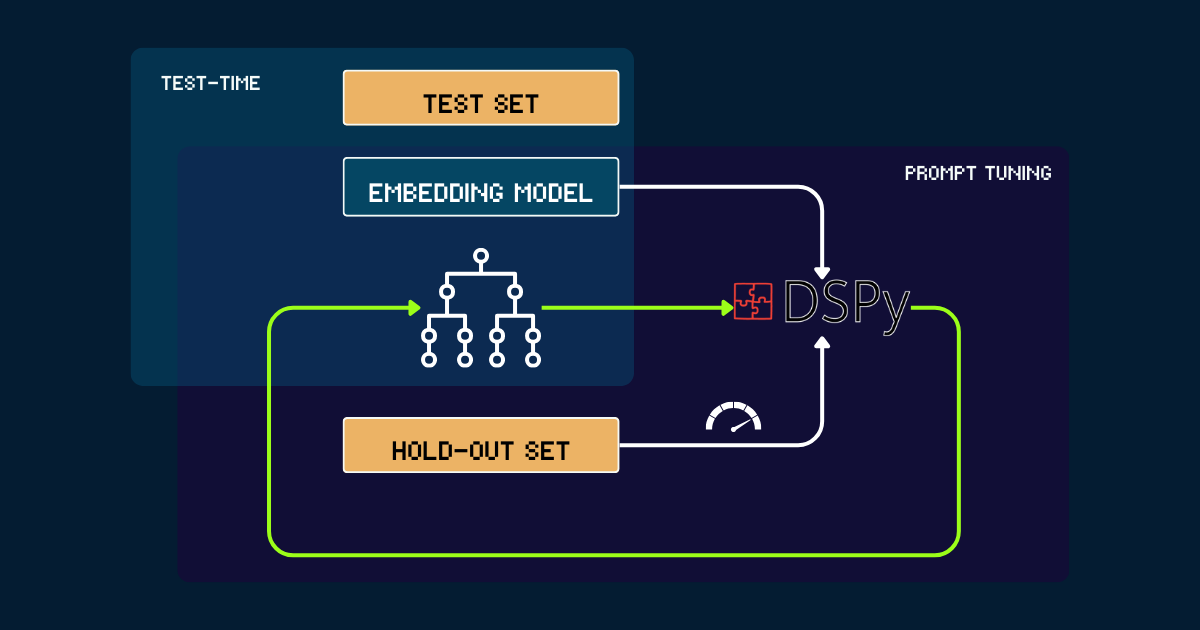
pokemon_system; el proceso de ajuste necesita hacerse solo una vez para cada tarea.tag¿Por qué Escalar el Cómputo en Tiempo de Prueba para Modelos de Incrustación?
Porque escalar el preentrenamiento eventualmente se vuelve económicamente intratable.
Desde el lanzamiento de la suite de incrustaciones de Jina—incluyendo jina-embeddings-v1, v2, v3, jina-clip-v1, v2, y jina-ColBERT-v1, v2—cada actualización de modelo a través del preentrenamiento escalado ha venido con más costos. Por ejemplo, nuestro primer modelo, jina-embeddings-v1, lanzado en junio de 2023 con 110M parámetros. Entrenarlo en ese momento costó entre 10,000 dependiendo de cómo se mida. Con jina-embeddings-v3, las mejoras son significativas, pero provienen principalmente de los mayores recursos invertidos. La trayectoria de costos para modelos de frontera ha pasado de miles a decenas de miles de dólares y, para empresas de IA más grandes, incluso cientos de millones hoy. Si bien aportar más dinero, recursos y datos al preentrenamiento produce mejores modelos, los retornos marginales eventualmente hacen que un mayor escalamiento sea económicamente insostenible.

Por otro lado, los modelos de incrustación modernos se están volviendo cada vez más poderosos: multilingües, multitarea, multimodales y capaces de un fuerte rendimiento zero-shot y de seguimiento de instrucciones. Esta versatilidad deja mucho espacio para mejoras algorítmicas y escalamiento del cómputo en tiempo de prueba.
La pregunta entonces se convierte en: ¿cuál es el costo que los usuarios están dispuestos a pagar por una consulta que les importa profundamente? Si tolerar tiempos de inferencia más largos para modelos de preentrenamiento fijos mejora significativamente la calidad de los resultados, muchos lo encontrarían valioso. En nuestra opinión, hay un potencial sustancial sin explotar en el escalamiento del cómputo en tiempo de prueba para modelos de incrustación. Esto representa un cambio de simplemente aumentar el tamaño del modelo durante el entrenamiento a mejorar el esfuerzo computacional durante la fase de inferencia para lograr un mejor rendimiento.
tagConclusión
Nuestro caso de estudio sobre el cómputo en tiempo de prueba de jina-clip-v1/v2 muestra varios hallazgos clave:
- Logramos un mejor rendimiento en datos poco comunes o fuera de distribución (OOD) sin ningún ajuste fino o post-entrenamiento en las incrustaciones.
- El sistema hizo distinciones más matizadas al refinar iterativamente las búsquedas de similitud y los criterios de clasificación.
- Al incorporar ajustes dinámicos de prompts y razonamiento iterativo, transformamos el proceso de inferencia del modelo de incrustación de una sola consulta en una cadena de pensamiento más sofisticada.
Este caso de estudio apenas rasca la superficie de lo que es posible con el cómputo en tiempo de prueba. Queda espacio sustancial para escalar algorítmicamente. Por ejemplo, podríamos desarrollar métodos para seleccionar iterativamente preguntas que reduzcan más eficientemente el espacio de respuestas, similar a la estrategia óptima en el juego de "Veinte Preguntas". Al escalar el cómputo en tiempo de prueba, podemos empujar los modelos de incrustación más allá de sus limitaciones actuales y permitirles abordar tareas más complejas y matizadas que una vez parecían fuera de alcance.





